眾所周知,計算機中運行的指令是由二進制編碼的0和1組成,最早的程式員通過在紙帶上打孔來撰寫程式,有孔表示1,無孔表示0,經過光電掃描輸入電腦,這種0和1序列我們稱之為機器語言,

0和1看的人頭都大了,人們厭煩這種復雜且易出錯的編碼方式,進而發明了匯編語言,匯編語言只是充當一個助記符的作用,但好歹人們不用寫010101010,而是可以用mov、add這種人們一看就知道其含義的符號來書寫程式,久而久之,人們在匯編語言的基礎上又發展了高級語言,也就是我們現在看到的各種語言,如C、C++、Python等,不論是面向物件的還是面向程序的,都可以歸結到高級語言,

人們用高級語言來作業、編程,但機器只識別機器語言,這中間肯定就存在一個轉換的程序,這個程序平時在我們編程式的程序中并不會注意,我們常用的編程環境如VS、dev c++、Delphi等這種IDE(集成開發環境)都為我們封裝好了一切,只要我們點擊運行或構建按鈕,源程式就會變成可以在機器上運行的機器代碼,而這個被忽略的程序就是我們今天的重點,
我們會以C語言的經典程式HelloWorld作為例子,參考《程式員的自我修養——鏈接、裝載和庫》的內容,通過實操為讀者一步步展現這個程序的具體步驟,
在Linux中,當我們使用GCC來編譯該程式時,只需要用最簡單的命令
$ gcc hello.c
$ ./a.out
hello world
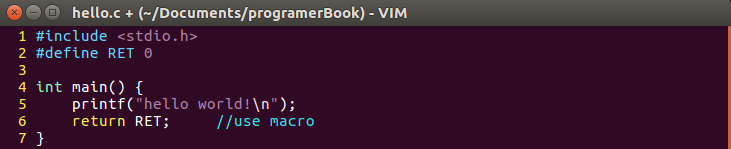
事實上,這個程序可以分解為4個步驟,分別是預處理(Preprocess)、編譯(Compilation)、匯編(Assembly)和鏈接(Linking),順便提一句,轉化為機器代碼后,當我們運行該程式還涉及到將機器代碼加載到記憶體中執行的程序,這個程序我們稱之為裝載,但我們本文不進行詳細闡述,
預處理
我們在撰寫C和C++程式的時候,經常會用到#號開頭的陳述句,如#include、#define、#ifdef等陳述句,這些陳述句在預處理程序中就發揮著重要作用,
源檔案hello.c和相關的頭檔案被預編譯器cpp預編譯為一個后綴為.i的檔案
$ gcc -E hello.c -o hello.i
或者
$ cpp hello.c > hello.i
生成結果如下:
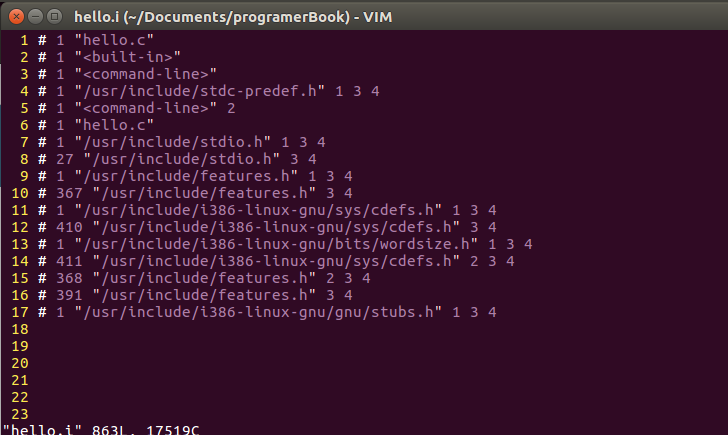
我們可以看到,一個本來不到十行的程式,經過預處理后,已經變成了一個863行的程式,說明前處理器向程式中加了許多的內容,我們原先的幾行代碼也被放在了最后,
預編譯程序主要處理那些源檔案中的以"#"開始的預編譯指令,主要處理規則如下:
-
將所有的
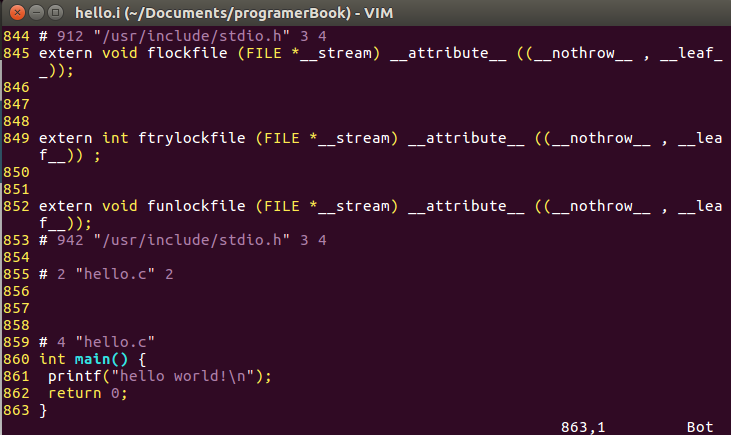
#define洗掉,并將所有的宏定義進行展開,程式中我們的RET宏被替換為了0, -
處理所有的條件預編譯指令,比如
#ifdef、#elif等, -
處理#include預編譯指令,將被包含的檔案插入到該預編譯指令的位置,注意,這個程序是遞回進行的,也就是說被包含的檔案可能還包含其他檔案,
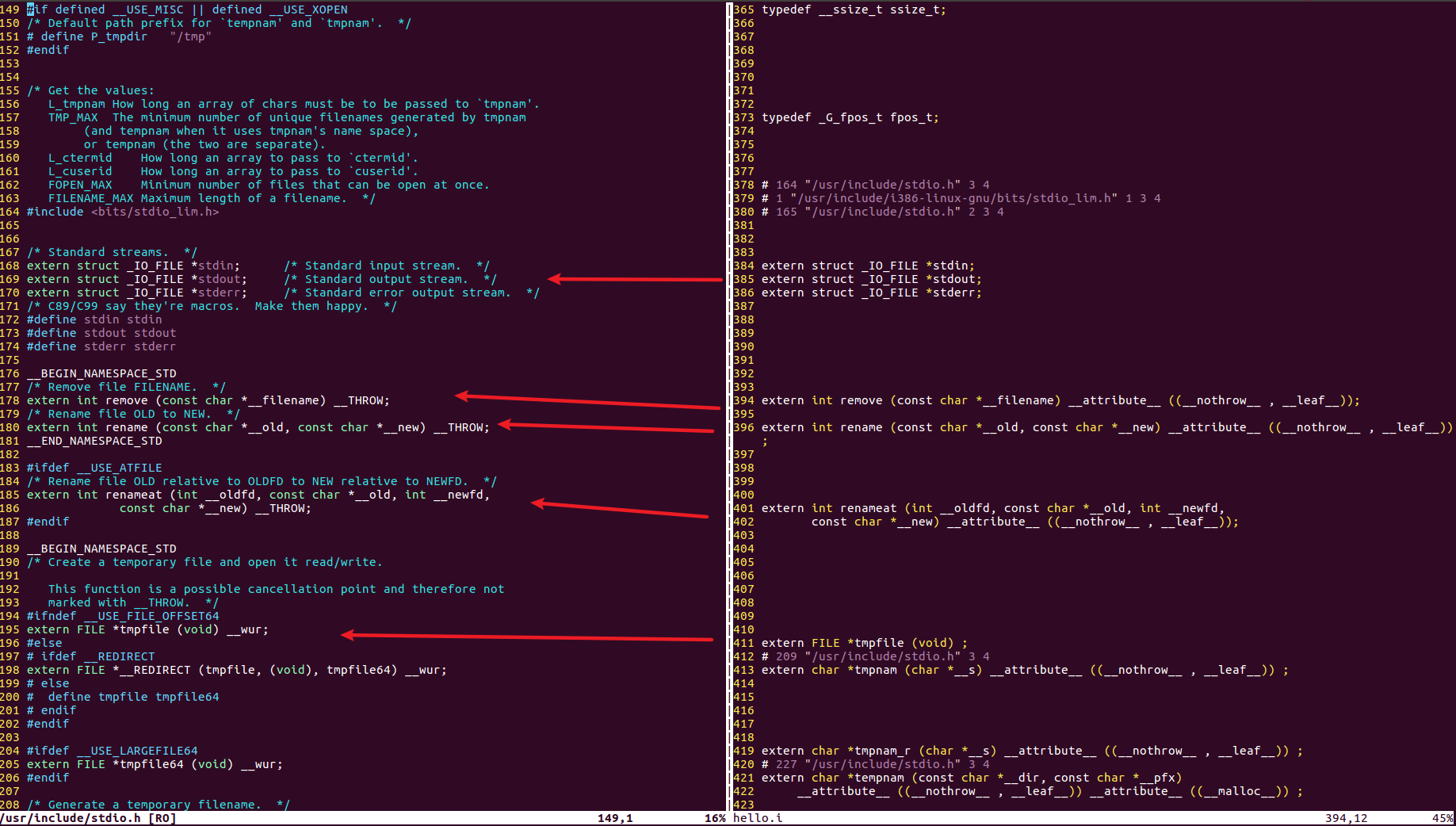
左側為stdio.h的內容,右側為hello.i的內容,可以看到stdio.h檔案的內容經過預處理后直接拷貝到了hello.i檔案中,
-
洗掉所有的注釋"//"和"/* */",hello.c程式中//use macro這條注釋在hello.i中已經消失了,
-
添加行號和檔案名標識,比如#2 "hello.c" 2,以便編譯時編譯器產生除錯用的行號資訊以及用于編譯時產生編譯錯誤或警告時可以顯示行號,
-
保留所有的#pragma編譯器指令,因為編譯器需要使用他們,(比如在vs中我們常用的#pragma warning (disable : 4996)來禁止編譯器產生對使用不安全函式的警告)
記得上過的課上又提到過,由于宏的不規范定義會導致一些錯誤,而預處理后的程式所有宏均被替代,因此可以通過查看預處理后的.i檔案來判斷宏定義是否正確或頭檔案包含是否正確,
編譯
編譯程序就是把預處理完的檔案進行一系列詞法分析、語法分析、語意分析及優化后生成相應的匯編檔案,
$ gcc -S hello.i -o hello.s
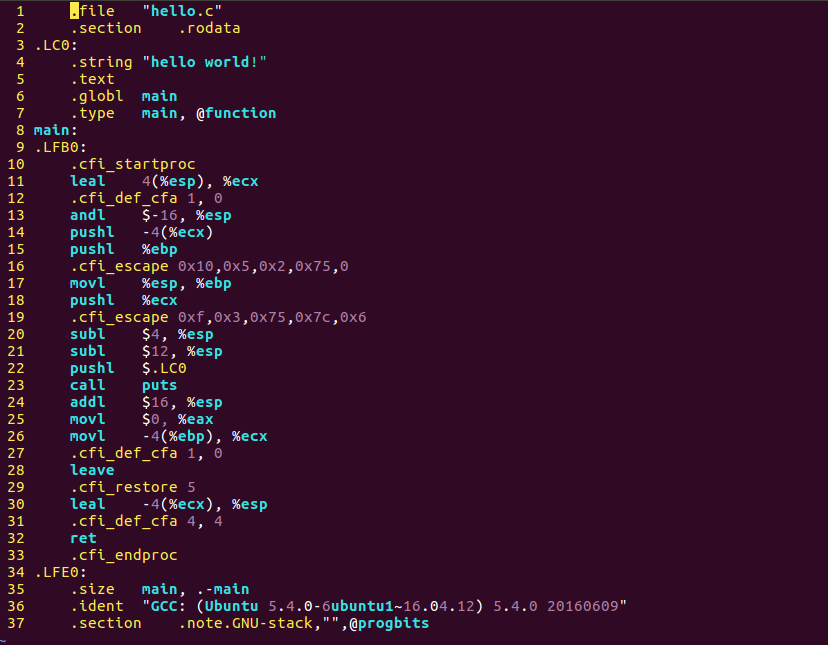
上面的匯編風格為AT&T的,我們可以加些引數將其轉換為Intel風格的,且去掉cfi宏,
$ gcc -S hello.i -o hello.s -masm=intel -fno-asynchronous-unwind-tables
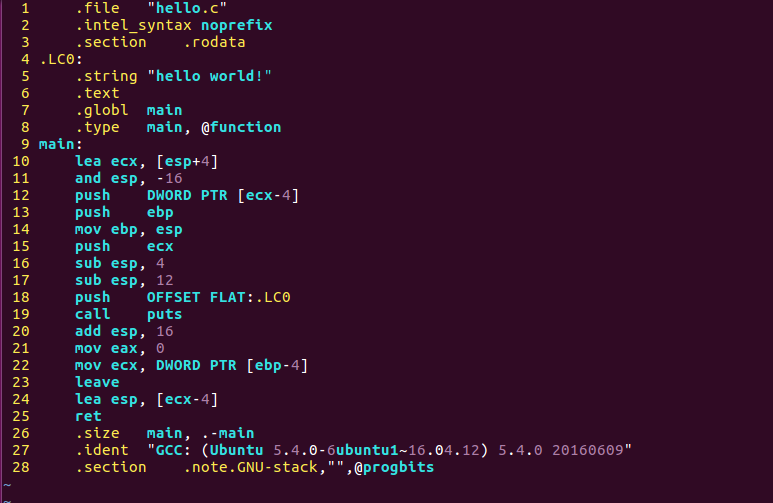
可以看到.string后面跟著字串"hello world!",值得注意的是,生成的匯編代碼中函式printf被替換成了puts,這是因為當printf只有一個單一引數時,與puts是十分類似的,于是GCC的優化策略就將其替換以提高性能,
下面我們對編譯程序進行詳細介紹
編譯器實作了從源程式到語意上等價的目標程式的映射,這個映射可以分為兩部分:分析部分和綜合部份,
分析(analysis)部分將源程式分解為多個組成要素,并在這些要素上加上語法結構,然后利用這個結構創建該源程式的一個中間表示,分析部分還會收集有關源程式的資訊,并把資訊存放在一個稱為符號表(symbol table)的資料結構中,符號表將和中間表示形式一起傳送給綜合部份,
綜合(synthesis)部分根據中間表示和符號表中的資訊來構造用戶期待的目標程式,
分析部分經常被稱為編譯器的前端(front end),它和目標機器無關;而綜合部份稱為后端(back end),與目標機器有關,前端和后端分離導致我們可以更好地開發編譯器,編譯器開發者便不用為每個CPU架構開發一整套編譯器,而是重新撰寫后端即可,也不用為每一種高級語言開發一整套編譯器,只需要更改前端即可,
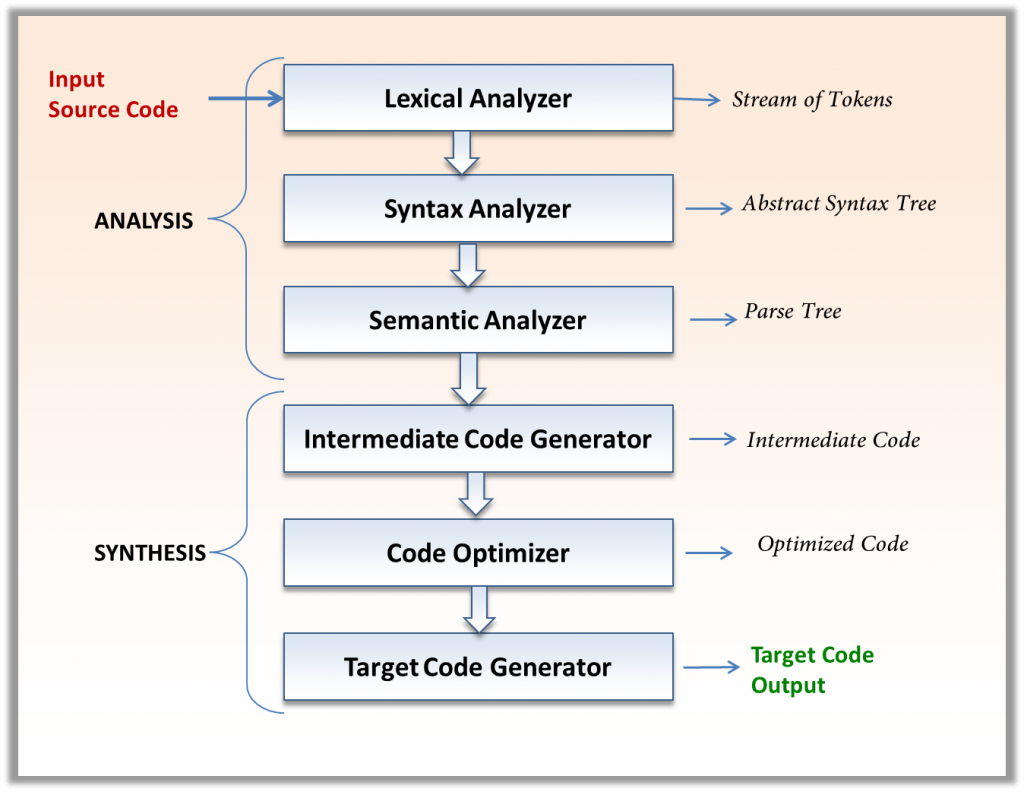
-
詞法分析(lexical analysis)
讀入組成源程式的字符流,并將它們組織成為有意義的詞素(lexeme)序列,對于每個詞素,詞法分析器產生詞法單元(token)作為輸出,
-
語法分析(syntax analysis)
使用由詞法分析器生成的各個詞法單元token來創建樹形的中間表示,該中間表示給出了詞法分析產生的詞法單元流的語法結構,一個常用的表示是語法樹(syntax tree),樹中的每個內部節點表示一個運算,而該結點的子節點表示該運算的分量,
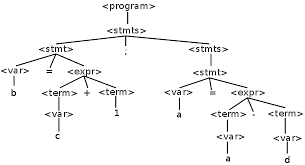
-
語意分析(semantic analysis)
語法分析僅僅是完成了對運算式語法層面的分析,但是它并不了解這個陳述句是否真正有意義,比如C語言里面兩個指標作乘法運算是沒有意義的,但這個陳述句在語法上是合法的,編譯器所能分析的語意是靜態語意(Static Sematic),即編譯期間可以確定的語意,與之對應的動態語意(Dynamic Sematic)就是只有在運行期才能確定的語意,比如將零作為除數是一個運行期語意錯誤,
語意分析使用語法樹和符號表中的資訊來檢查源程式是否和語言定義的語意一致,它同時也收集型別資訊,并把這些資訊存放在語法樹或符號表中,以便在隨后的中間代碼生成程序中使用,語意分析的一個重要部分是型別檢查(type checking),編譯器檢查每個運算子是否具有匹配的運算分量,
-
中間代碼生成
根據語意分析的輸出,生成類機器語言的中間表示,比如三地址碼和P-代碼,三地址碼類似于匯編語言的指令組成(但還不是匯編語言),每個指令具有三個運算分量,每個運算分量都像一個暫存器,這種中間代碼一般跟目標機器和運行時環境無關,
比如
a = b + c * (4 + 2)的源代碼最后生成的中間代碼模樣大概為:t0 = 2 + 4 t1 = id3 * t0 t2 = id2 + t1 id1 = t3 -
中間代碼優化
改進中間代碼,生成更好的目標代碼,比如上面的中間代碼可以優化為:
t1 = id3 * 6 id1 = id2 + t1中間代碼使得編譯器可以被分為前端和后端,編譯器前端負責產生機器無關的中間代碼,編譯器后端將中間代碼轉換為目標代碼,這樣對于一些可以跨平臺的編譯器而言,可以針對不同的平臺使用同一個前端和針對不同機器平臺的后端,
-
目標代碼生成
這個程序非常依賴于目標機器,因為不同的機器有著不同的字長、暫存器等,如果目標語言是x86匯編語言,那么上面的中間代碼產生的目標代碼可能為:
mov edx, DWORD PTR [ebp - 8] ;[ebp-8]里面為c的值 mov eax, edx ;eax = c add eax, eax ;eax = 2c add eax, edx ;eax = 3c add eax, eax ;eax = 6c mov edx, eax ;edx = 6c mov eax, DWORD PTR [ebp - 12] ;[ebp - 12]里面為b的值 add eax, edx ;eax = b + 6c
匯編
匯編程序就是將匯編語言轉換為機器語言,由于匯編指令是機器指令的助記符,每一個匯編陳述句幾乎都對應一潭訓器指令,所以匯編器的匯編程序相對于編譯器來講比較簡單,沒有復雜的語法,也沒有語意,也不需要做指令優化,只是根據匯編指令和機器指令的對照表一一翻譯就可以,
$ gcc -c hello.s -o hello.o
或者
$ as hello.s -o hello.o
此時的目標檔案hello.o是一個可重定位目標檔案(Relocatable File),如果使用文本編輯器查看hello.o會看到一堆亂碼,我們需要采用反匯編技術查看hello.o檔案內容
$ objdump -sd hello.o -M intel
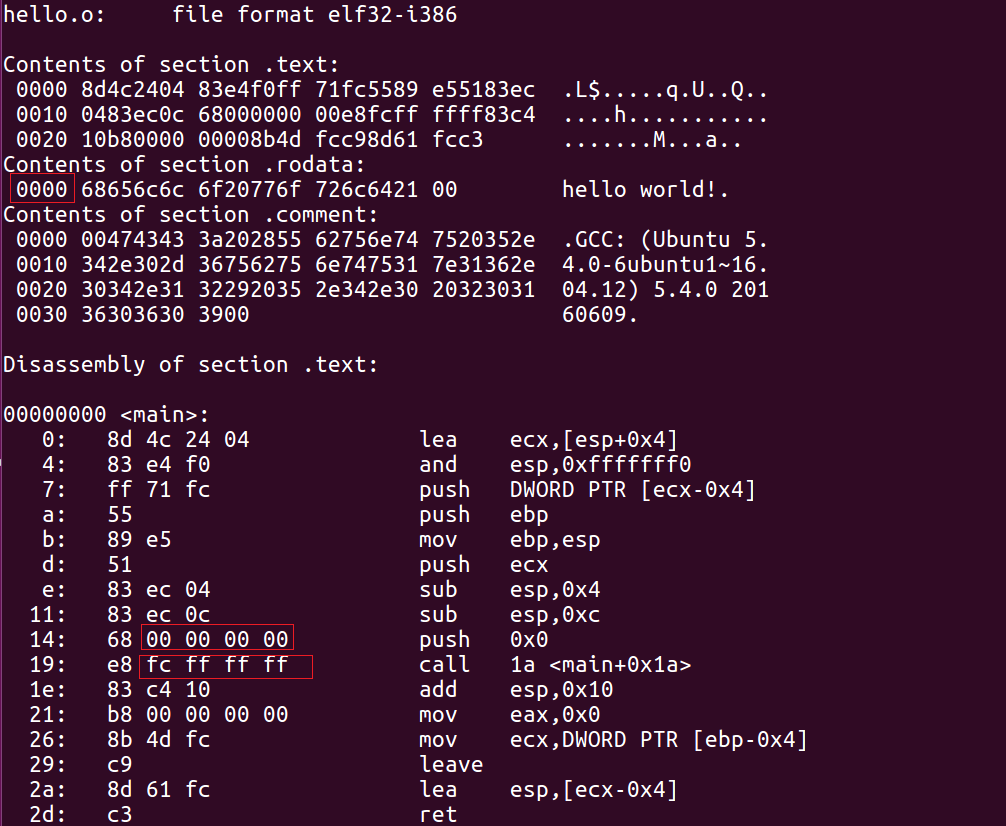
由于還未進行鏈接,目標檔案的符號的虛擬地址無法確定,于是我們看到字串“hello world!”的地址為0x0000,傳給puts函式的引數(即hello world字串的地址)也為00000000,而call puts機器語言中的0xfffffffc(小端)為-4,表示相對PC尋址,puts函式的地址為0x1e - 4 = 0x1a,我們可以看到0xfffffffc和之前的0x00000000一樣,存放的并不是puts函式的地址,只是一個臨時的假地址,因為在編譯的時候,編譯器并不知道puts函式的地址,分配地址的事情交給聯結器來做,
鏈接
鏈接可以分為靜態鏈接和動態鏈接兩種,GCC默認使用動態鏈接,添加編譯選項"-static"即可指定使用靜態鏈接,,這一階段將目標檔案及其依賴庫進行鏈接,生成可執行檔案,功能主要包括
-
地址和空間分配(Address and Storage Allocation)
-
符號系結(Symbol Binding)
-
重定位(Relocation)
將每一個符號的定義與一個記憶體地址進行關聯,然后修改這些符號的參考,使其指向這個記憶體地址,
$ gcc hello.o -o hello -static
使用objdump反匯編查看hello檔案內容
$ objdump -d hello
(使用書中的這個命令一下子顯示出太多內容,于是我自己使用了objdump -d hello | grep '<main>'查看了main的地址,然后最后用objdump -d hello | grep '80488'查看了main函式的反匯編代碼,可以看到此時的push和call中的地址都已經修正到了正確的位置,
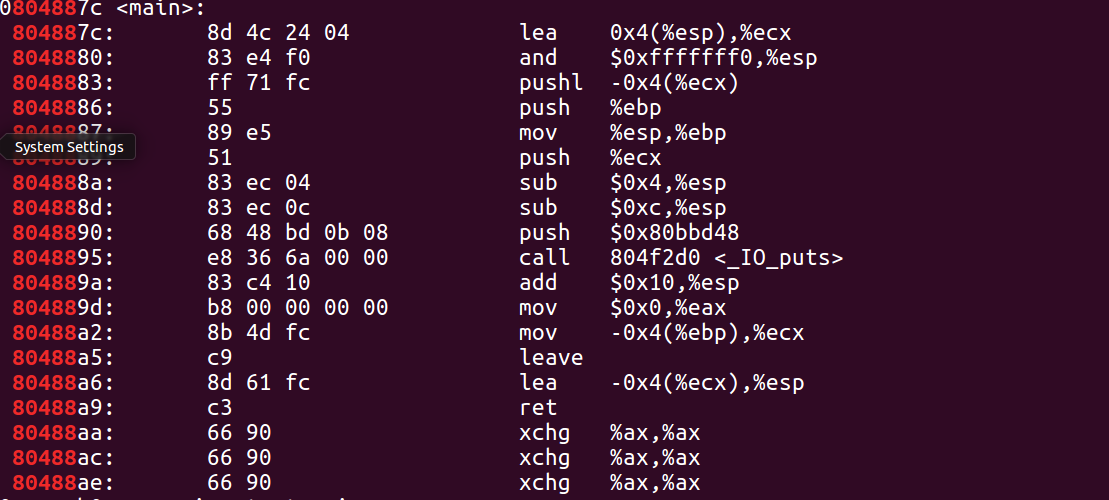
此時程式也就可以被加載到記憶體中正常執行了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/265537.html
標籤:C