本文基于JDK 1.8.0_211撰寫,基于java.util.Arrays.sort()方法淺談目前Java所用到的排序演算法,僅個人見解和筆記,若有問題歡迎指證,著重介紹其中的TimSort排序,其源于Python,并于JDK1.7引入Java以替代原有的歸并排序,
引入
Arrays.Sort方法所用的排序演算法主要涉及以下三種:雙軸快速排序(DualPivotQuicksort)、歸并排序(MergeSort)、TimSort,也同時包含了一些非基于比較的排序演算法:例如計數排序,其具體最終使用哪一種排序演算法通常根據型別以及輸入長度來動態抉擇,
- 輸入陣列型別為基礎型別時,采用雙軸快速排序,輔以計數排序;
public static void sort(int[] a) { DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0); }
- 輸入陣列型別為包裝型別時,采用歸并排序或TimSort(除非經過特殊的配置,否則默認采用TimSort)
public static void sort(Object[] a) { if (LegacyMergeSort.userRequested) legacyMergeSort(a); else ComparableTimSort.sort(a, 0, a.length, null, 0, 0); } public static <T> void sort(T[] a, Comparator<? super T> c) { if (c == null) { sort(a); } else { if (LegacyMergeSort.userRequested) legacyMergeSort(a, c); else TimSort.sort(a, 0, a.length, c, null, 0, 0); } } /** To be removed in a future release. */ private static <T> void legacyMergeSort(T[] a, Comparator<? super T> c) { T[] aux = a.clone(); if (c==null) mergeSort(aux, a, 0, a.length, 0); else mergeSort(aux, a, 0, a.length, 0, c); }
排序穩定性
假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i] = r[j],且 r[i] 在 r[j] 之前,而在排序后的序列中,r[i] 仍在 r[j] 之前,則稱這種排序演算法是穩定的;否則稱為不穩定的,
穩定性的含義:如果我們需要在二次排序后保持原有排序的意義,就需要使用到穩定性的演算法
例子:我們要對一組商品排序,商品存在兩個屬性:價格和銷量,當我們按照價格從高到低排序后,要再按照銷量對其排序,這時,如果要保證銷量相同的商品仍保持價格從高到低的順序,就必須使用穩定性演算法,
快速排序與雙軸快速排序
快速排序簡介
單軸快速排序 即為我們最常見的一種快速排序方式,我們選取一個基準值(pivot),將待排序陣列劃分為兩部分:大于pivot 和 小于pivot,再對這兩部分進行單軸快速排序... 但是這種方式對于輸入陣列中有很多重復元素時效率不太理想,
單軸三取樣切分快速排序 作為單軸快速排序的優化版本,其主要優化相同元素過多情況下的快排效率,同樣選取一個基準值,但將待排序陣列劃分三部分: 大于pivot、等于pivot、大于pivot,
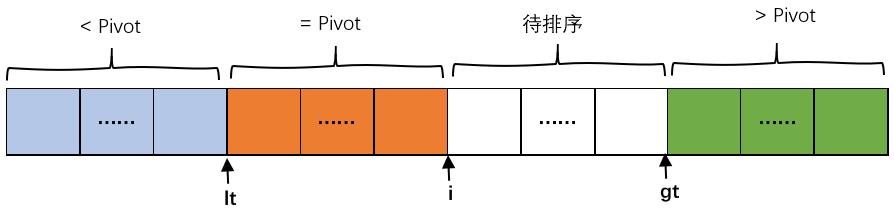
雙軸快速排序 選取兩個 基準值pivot1,pivot2,且保證pivot1<=pivot2,其具體實作與三取樣切分類似,不過時將待排序陣列劃分以下三部分:小于pivot,介于pivot1與pivot2之間,大于pivot2,

DualPivotQuicksort實作優化
Java在實作DualPivotQuickSort時,并未盲目使用雙軸快速排序,而是基于輸入長度選取排序演算法,
(1)針對int、long、float、double四種型別,跟據長度選取的排序演算法如下:
- 當待排序數目小于47,采用插入排序
- 當待排序數目小于286,采用雙軸快排
- 當待排序數目大于286,采用歸并排序
我們暫且將其稱之為一個標準的雙軸快排
static void sort(int[] a, int left, int right, int[] work, int workBase, int workLen) { // Use Quicksort on small arrays if (right - left < QUICKSORT_THRESHOLD) { sort(a, left, right, true); return; } // Use MergingSort doMerge(); } private static void sort(int[] a, int left, int right, boolean leftmost) { // Use insertion sort on tiny arrays if (length < INSERTION_SORT_THRESHOLD) { doInertionSort(); } doDualPivotQuickSort(); }
(2)針對short、char兩種型別,根據長度選取的排序演算法如下:
- 當待排序數目小于3200,采用標準雙軸快排;
- 當待排序數目大于3200,采用計數排序(CountingSort)
(3)針對byte型別,根據長度選取的排序演算法如下:
- 當待排序數目小于29,采用插入排序;
- 當待排序數目大于29,采用計數排序(CountingSort)
非基于比較排序演算法-計數排序
計數排序與傳統的基于比較的排序演算法不同,其不通過比較來排序,我們常見的非基于比較的排序演算法有三種:桶排序、計數排序(特殊桶排序)、基數排序,有興趣的可以逐個去了解,這里主要講解計數排序,
使用前提
使用計數排序待排序內容需要是一個有界的序列,且可用整數表示
引入
計數排序顧名思義即需要統計陣列中的元素個數,通過另外一個陣列的地址表示輸入元素的值,陣列的值表示元素個數,最后再將這個陣列反向輸出即可完成排序,見下方示例:
假設:一組范圍在 0~10 之間的數字,9, 3, 5, 4, 9, 1, 2, 7, 8,1,3, 6, 5, 3, 4, 0, 10, 9, 7, 9
第一步:建立一個陣列來統計每個元素出現的個數,因為是0~10,則建立如下陣列 Count:

第二步:遍歷輸入陣列,將獲取到的內容放置到Count 陣列對應的位置,使當前位置+1,例如當前為9:

以此類推,遍歷完整個輸入陣列,則得到一個完整狀態的Count:

這時候,Count中記錄了輸入陣列所有的元素出現的次數,將Count陣列按次數輸出即可得到最終排序輸出:
0, 1, 1, 2, 3, 3, 3, 4, 4, 5, 5, 6, 7, 7, 8, 9, 9, 9, 9, 10
計數排序的穩定性與最終實作
根據上面穩定性的定義,大家不難發現上面的實作程序不能保證基數排序的穩定性,而實際上計數排序是一個穩定的排序演算法,下面我們通過上面那個例子來引出計數排序的最終實作,
例子:輸入陣列 [ 0,9,5,4,5 ],范圍0 ~ 9
第一步:將Count陣列中所記錄的內容進行更改,由記錄當前元素的出現的次數 修正為 記錄當前索引出現的次數和當前索引之前所有元素次數的和,這樣在索引中存盤的值就是其真實的排序后排位數,例如9的值為5,則9的排序后的位置就是第5位:
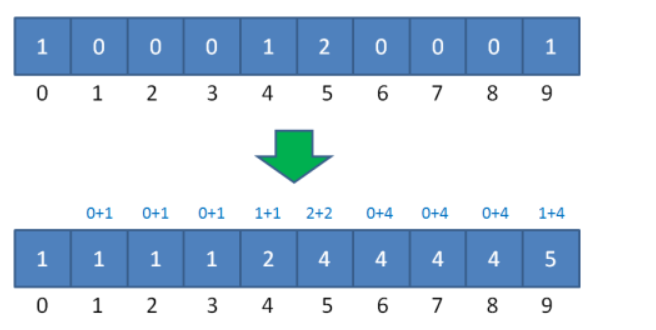
第二步:我們從后向前遍歷原序列,此時為5,則在最終排序序列的位置為4(索引為3)的地方放置5,并將Count序列的5索引處的值-1,
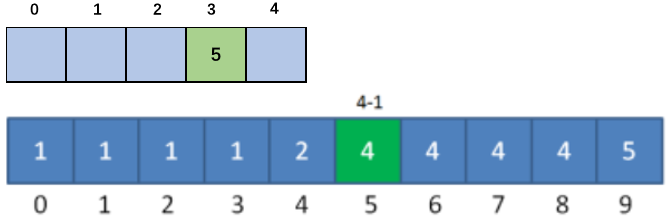
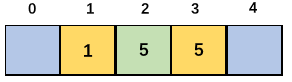
以此類推:到第二個5時,Count陣列中的值為3(索引為2),這樣就保證了插入排序的穩定性,
原始碼實作
/** The number of distinct byte values. */ private static final int NUM_BYTE_VALUES = 1 << 8; static void sort(byte[] a, int left, int right) { int[] count = new int[NUM_BYTE_VALUES]; // 建立count陣列 for (int i = left - 1; ++i <= right; count[a[i] - Byte.MIN_VALUE]++ ); // 從尾部開始遍歷 for (int i = NUM_BYTE_VALUES, k = right + 1; k > left; ) {
while (count[--i] == 0); byte value = https://www.cnblogs.com/rekent/p/(byte) (i + Byte.MIN_VALUE); int s = count[i]; do { a[--k] = value; } while (--s > 0); } }
TimSort
Timsort是工業級演算法,其混用插入排序與歸并排序,二分搜索等演算法,亮點是充分利用待排序資料可能部分有序的事實,并且依據待排序資料內容動態改變排序策略——選擇性進行歸并以及galloping,另外TimSort是一個穩定的演算法,其最好的執行情況要優于普通歸并排序,最壞情況與歸并排序相仿:

針對小資料優化
針對輸入長度較短的陣列排序,很多輕量級排序即可勝任,故TimSort在基于輸入陣列長度的條件下,做出如下優化:
當輸入序列的長度小于基準值時,將采用插入排序直接對輸入序列排序,基準值的選取:(1)Python:64(2)Java:32
此外上面提到的插入排序,Java的實作中,對這部分做了優化,嚴格來說這里使用的是二分插入排序,將插入排序與二分查找進行了結合,因為插入排序的索引左側均是有序序列:
- 傳統意義上需要單個依次向前比較,直到找到新插入元素放置的位置;
- 二分插入排序,則在此處采用二分查找來確認插入元素的放置位置,
TimSort簡要流程
TimSort is a hybrid sorting algorithm that uses insertion sort and merge sort.
The algorithm reorders the input array from left to right by finding consecutive (disjoint) sorted segments (called “runs” from hereon). If the run is too short, it is extended using insertion sort. The lengths of the generated runs are added to an array named runLen. Whenever a new run is added to runLen, a method named mergeCollapse merges runs until the last 3 elements in runLen satisfy the following two conditions (the “invariant”):
- runLen [n-2] > runLen [n-1] + runLen [n]
- runLen [n-1] > runLen [n]
Here n is the index of the last run in runLen. The intention is that checking this invariant on the top 3 runs in runLen in fact guarantees that all runs satisfy it. At the very end, all runs are merged, yielding a sorted version of the input array.
TimSort演算法通過找到連續的(不相交)排序的段(此后稱為“Run”),如果Run過短,則使用插入排序擴充,生成的Run的長度被稱添加到一個名為runLen陣列中,每當將新Run添加到runLen時,名為mergeCollapse的方法就會嘗試合并Run,直到runLen中的元素元素滿足兩個恒定的不等式,到最后,所有Run都將合并成一個Run,從而生成輸入陣列的排序版本,
基本概念 - Run
TimSort演算法中,將有序子序列(升序序列和嚴格降序序列)稱之為Run,例如如下將排序序列:1,2,3,4,5,4,3,6,8,10
則上面的序列所有的Run如下:1,2,3,4,5,5,3,2,2,6,8,10
TimSort中會區分其序列為升序還是降序,如果是降序會強行反轉Run,使其成為升序,則上述的序列經過反轉后即為:1,2,3,4,5,5,2,3,2,6,8,10
注意:Run必須是升序(可以相等)和嚴格降序(不能相等),嚴格降序的原因是保證TimSort穩定性,因為降序需要反轉,
基本概念 - MinRun
當兩個陣列歸并時,當這個陣列Run的數目等于或略小于2的乘方時,效率最高(基本數學概念參考:listsort.txt),
反過來說,我們需要得到一個Run的最小長度,使得其劃分的Run的數目達到上述標準準,即:選取32-64(16-32)這個范圍作為MinRun的范圍,使得原排序陣列可以被MinRun分割成N份,這個N等于或略小于2的乘方,
- 如果當前的Run長度小于MinRun:嘗試把后面的元素通過插入排序放入Run中,以盡量達到MinRun的長度(剩余長度滿足的情況下);
- 如果當前的Run長度大于MinRun:不處理,
通過上述的操作我們就識訓了一系列Run,將其放置到堆疊runLen中,并嘗試對其進行歸并:
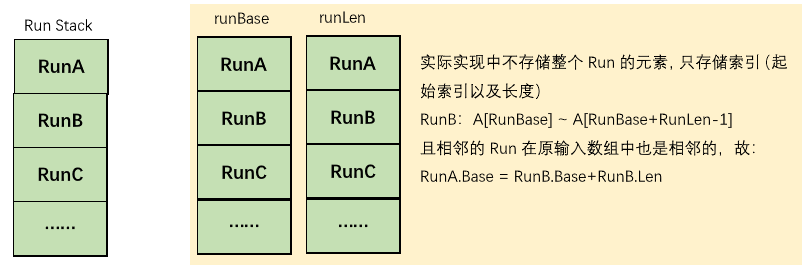
/** * A stack of pending runs yet to be merged. Run i starts at * address base[i] and extends for len[i] elements. It's always * true (so long as the indices are in bounds) that: * * runBase[i] + runLen[i] == runBase[i + 1] * * so we could cut the storage for this, but it's a minor amount, * and keeping all the info explicit simplifies the code. */ private int stackSize = 0; // Number of pending runs on stack private final int[] runBase; private final int[] runLen; /* * 初始化部分截取 * 分配runs-to-be-merged堆疊(不能擴大) */ int stackLen = (len < 120 ? 5 : len < 1542 ? 10 : len < 119151 ? 24 : 49); runBase = new int[stackLen]; runLen = new int[stackLen]; /** * Pushes the specified run onto the pending-run stack. * * @param runBase index of the first element in the run * @param runLen the number of elements in the run */ private void pushRun(int runBase, int runLen) { this.runBase[stackSize] = runBase; this.runLen[stackSize] = runLen; stackSize++; }
歸并原則 - 不等式
基于如下原因:
(1)堆疊runLen記憶體占用盡量減小,則其是線上具有固定大小,不考慮擴容(參考上述原始碼的注釋);
(2)讓歸并的兩個Run的數目都盡量接近,更接近普通歸并的模式,提高歸并效率,
TimSort在runLen上制定了兩個不等式以使runLen盡量貼近上面的條件:
- Run[n-1] > Run[n] + Run[n+1]
- Run[n] > Run[n+1]
當目前runLen滿足這兩個不等式時,則不進行歸并,否則進行歸并,因為TimSort時穩定的排序演算法,則僅允許歸并相鄰的兩個Run:
- 如果不滿足不等式一:歸并Run[n]與Run[n-1]、Run[n+1]中長度較短的Run
- 如果不滿足不等式二:歸并Run[n]與Run[n+1]
不變式的含義:
不變式一:從右至左讀取長度,則待處理的runLen的增長至少與斐波那契額增長的速度一樣快,則更使得兩個歸并的Run的大小更為接近;
不變式二:待處理的runLen按遞減順序排序,
通過以上兩個推論可以推測runLen中的Run數目永遠會收斂于一個確定的數,以此證明了只用極小的runLen堆疊就可以排序很長的輸入陣列,也正是因為如此在實作上不考慮擴容問題,如果需要詳細數學例證可以查看文后Reference,
實際代碼是線上,Java、Python、Android保證不等式的手段是檢查堆疊頂三個元素是否滿足,即上述不等式的n取堆疊頂第二個,如果不滿足則歸并,歸并完成后再繼續檢查堆疊頂三個直到滿足為止,
/** * Examines the stack of runs waiting to be merged and merges adjacent runs * until the stack invariants are reestablished: * * 1. runLen[i - 3] > runLen[i - 2] + runLen[i - 1] * 2. runLen[i - 2] > runLen[i - 1] * * This method is called each time a new run is pushed onto the stack, * so the invariants are guaranteed to hold for i < stackSize upon * entry to the method. */ private void mergeCollapse() { while (stackSize > 1) { int n = stackSize - 2; if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) { if (runLen[n - 1] < runLen[n + 1]) n--; mergeAt(n); } else if (runLen[n] <= runLen[n + 1]) { mergeAt(n); } else { break; // Invariant is established } } }
歸并排序
歸并優化一:記憶體優化
由于需要保證TimSort的穩定性,則歸并排序不能采用原地排序,TimSort引入了臨時陣列來進行歸并,并將參與歸并的兩個Run中較小的那個放置到臨時陣列中,以節省記憶體占用,同時區分從小開始歸并和從大開始歸并,
歸并優化二:縮短歸并Run長度
兩個參與歸并的Run,由很多部分其實時不用參與歸并的(從Run的某個位置開始的前面或后面的元素均小于或大于另一個Run的全部元素,則這部分就可以不參與歸并),加之歸并兩個Run是在原輸入陣列中是相鄰,則我們考慮是否可以在去掉部分頭尾元素,以達到縮短歸并長度的目的:
(1)在RunA查找一個位置 I 可以正好放置RunB[0],則 I 之前的資料都不用參與歸并,在原地不需要變化;
(2)在RunB查找一個位置 J 可以正好放置RunA[Len-1],則 J 之后的資料都不用參與歸并,在原地不需要變化;
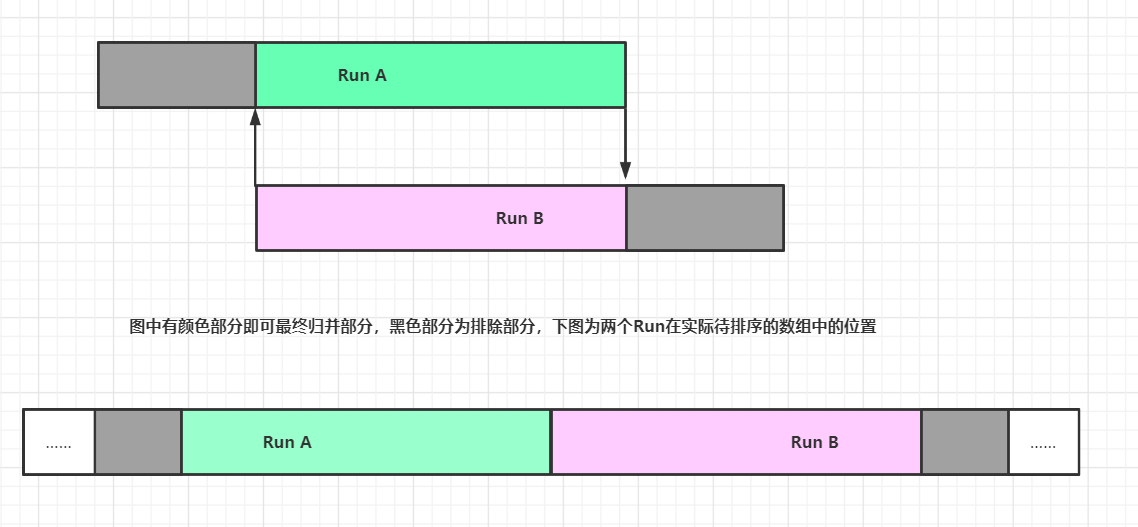
歸并排序優化三:GallopingMode
在歸并時有可能存在以下的極端情況:
RunA 的所有元素都小于RunB,如果這個情況下采用常規的歸并效率肯定不理想
于是TimSort引入了GallopingMode,用來解決上述的問題,即當歸并時,一個Run連續n的元素都小于另一個Run,則考慮是否有更多的元素都小于,則跳出正常歸并,進入GallopingMode,當不滿足Galloping條件時,再跳回到正常歸并(不滿足Galloping條件時強制使用Galloping效率低下),如果RunA的許多元素都小于RunB,那么有可能RunA會繼續擁有小于RunB的值(反之亦然),這個時候TimSort會跳出常規的歸并排序進入Galloping Mode,這里規定了一個閾值MIN_GALLOP,默認值為7,
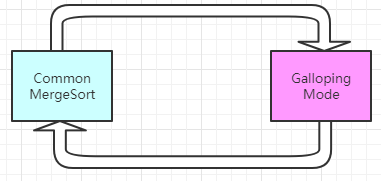
下面模擬一次Galloping,以mergeHi為例(從大開始歸并):
(1)例如此時RunA已經連續贏得7次歸并,而RunB的元素還沒有一次被選取,則已經達到閾值,進入GallopingMode:
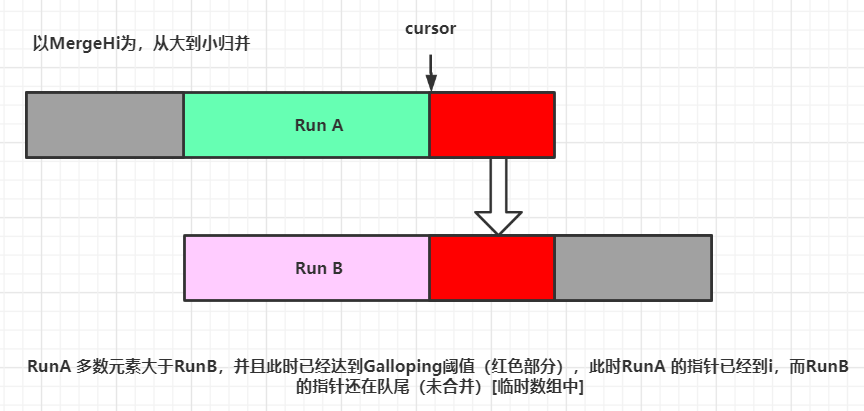
進入GallopingMode,說明此時已經有RunA已經小于RunB末尾的7個數字,TimSort猜測會有更多的RunA的數字小于RunB,則進行以下操作:
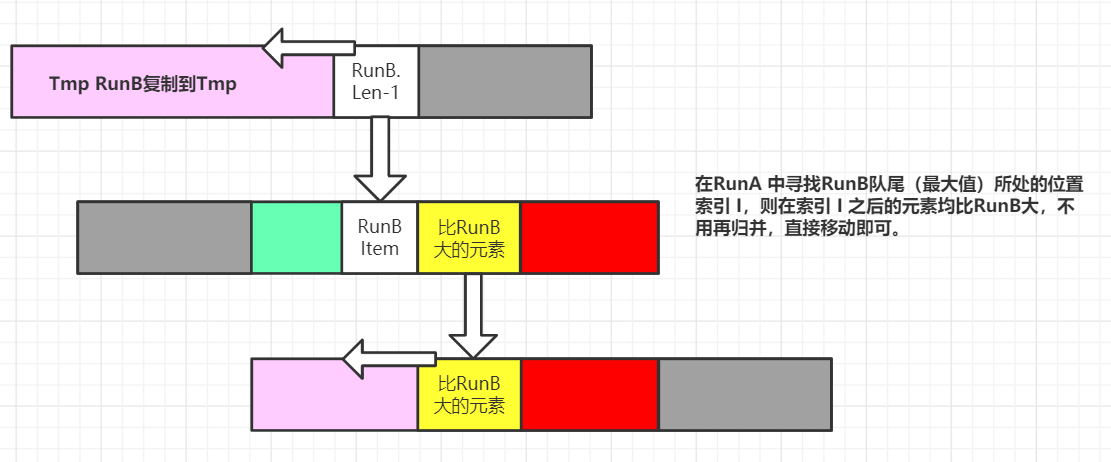
以上則完成了一次Galloping,在這一次Galloping中,我們一次性將所有大于RunB[len-1]的RunA元素一次性移動(包括RunB[len-1],放置到這次移動的RunA元素后),不需要再依次歸并,
這時涉及到一個概念即是否繼續執行Galloping,還是回到正常的歸并?
我們判斷這一次移動的元素個數是否還滿足閾值(黃色),如果滿足則繼續,在RunA中尋找RunB[len-2]的位置,否則回到正常的歸并,
Java版本實作中每次進入和退出Galloping會變更這個進入GallopingMode的閾值,應該是某種獎懲機制,這里不做說明,
TimSort 的實作缺陷
在Java8中TimSort的實作是有缺陷的,在極端復雜情況下可能會觸發例外,其主要原因是如果只檢查堆疊頂三個Run的不等式關系,沒辦法辦證這個不等式在整個runLen堆疊上成立,參考以下示例: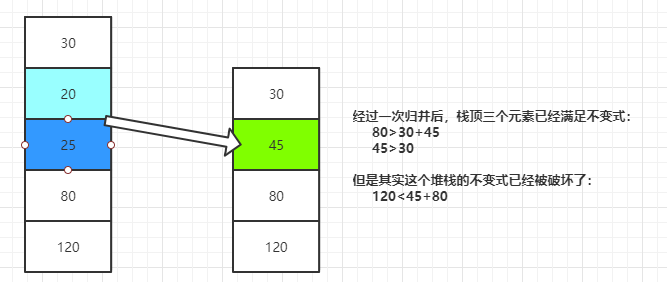
不等式被破壞的代價,即為Run的歸并時機被破壞,導致在某些極端情況下,會導致堆疊中的Run超過我們通過不等式推出來的那個收斂值導致溢位:ArrayOutOfBoundsException,這個Bug在后續版本已經修復:
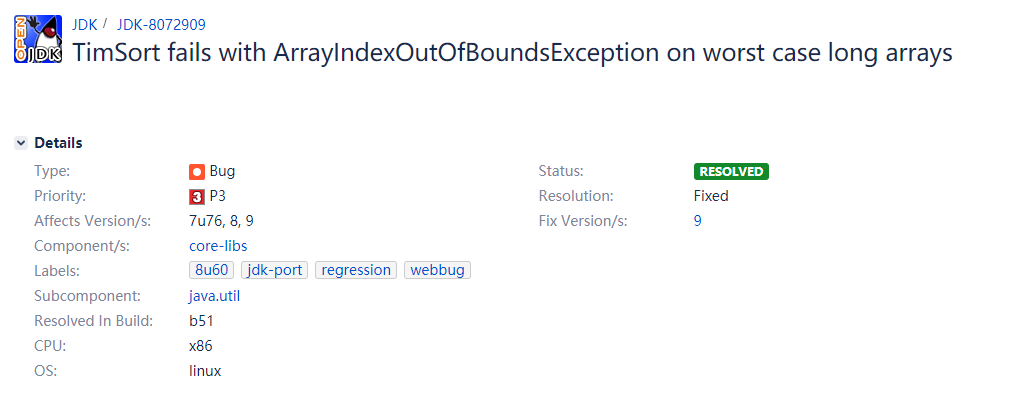
提供的修復方案即為檢查堆疊頂四個Run而非三個:
private void newMergeCollapse() { while (stackSize > 1) { int n = stackSize - 2; if ( (n >= 1 && runLen[n-1] <= runLen[n] + runLen[n+1]) || (n >= 2 && runLen[n-2] <= runLen[n] + runLen[n-1])) { if (runLen[n - 1] < runLen[n + 1]) n--; } else if (runLen[n] > runLen[n + 1]) { break; // Invariant is established } mergeAt(n); } }
有興趣手動Debug這個問題的讀者可以參考如下Git操作:https://github.com/Rekent/java-timsort-bug
部分原始碼注釋
入口方法:
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c, T[] work, int workBase, int workLen) { assert c != null && a != null && lo >= 0 && lo <= hi && hi <= a.length; int nRemaining = hi - lo; if (nRemaining < 2) { return; // Arrays of size 0 and 1 are always sorted } // 如果小于32位,則不采用TimSort,而是采用二分插入排序對整個陣列直接排序 if (nRemaining < MIN_MERGE) { // 獲取第一個序列(Run) int initRunLen = countRunAndMakeAscending(a, lo, hi, c); // 二分插入排序(從第一個Run后開始向前排序,第一個Run已經是增序了,不用再排) binarySort(a, lo, hi, lo + initRunLen, c); return; } MyTimSort<T> ts = new MyTimSort<>(a, c, work, workBase, workLen); // 根據當前排序陣列長度生成最小的Run長度 int minRun = minRunLength(nRemaining); do { // 識別下一個Run序列,回傳這個Run的長度 int runLen = countRunAndMakeAscending(a, lo, hi, c); // 如果當前的Run序列長度小于MinRun長度,則嘗試擴展到MinRun的長度(從后面選取元素進行二分拆入排序) if (runLen < minRun) { // 如果剩余長度小于當前的MinRun,則補全為剩余的長度 int force = nRemaining <= minRun ? nRemaining : minRun; binarySort(a, lo, lo + force, lo + runLen, c); runLen = force; } // 記錄當前Run的起始Index以及Run長度 ts.pushRun(lo, runLen); // 嘗試合并 ts.mergeCollapse(); // 開始下一輪的Run尋找 lo += runLen; nRemaining -= runLen; } while (nRemaining != 0); // 所有的Run都已經尋找完畢,必須合并所有Run assert lo == hi; ts.mergeForceCollapse(); assert ts.stackSize == 1; }
歸并方法(優化縮短歸并長度):
/** * 合并i以及i+1兩個Run. Run i 一定是倒數第二個或者倒數第三個Run * * @param i 合并堆疊的索引 */ private void mergeAt(int i) { // i 一定是倒數第二個或者倒數第三個,換句話說,i一定是stackSize-2或者stackSize-3 assert stackSize >= 2; assert i >= 0; assert i == stackSize - 2 || i == stackSize - 3; int base1 = runBase[i]; int len1 = runLen[i]; int base2 = runBase[i + 1]; int len2 = runLen[i + 1]; assert len1 > 0 && len2 > 0; assert base1 + len1 == base2; // 將i的長度更新len1+len2,即合并后的長度,如果是倒數第三個Run,則將倒數第一個長度合并到倒數第二個Run中(倒數第二個和倒數第三個Run合并了) // [RUN1,RUN2,RUN3] -> [RUN1+RUN2,RUN3] ; [RUN1,RUN2] -> [RUN1+RUN2] runLen[i] = len1 + len2; if (i == stackSize - 3) { runBase[i + 1] = runBase[i + 2]; runLen[i + 1] = runLen[i + 2]; } stackSize--; // 縮短歸并長度:在Run1中尋找Run2的起始節點位置(Run2的首個元素應該放置Run1中的位置),可以忽略run1中先前的元素(因為其已經有序) int k = gallopRight(a[base2], a, base1, len1, 0, c); assert k >= 0; // !!! Run1 這個位置之前的可以省略不再排序,因為Run2所有元素都大于這個位置 base1 += k; len1 -= k; // 如果剩余排序長度為0,則已經有序,不用再排序(Run1全體大于Run2) if (len1 == 0) { return; } // 縮短歸并長度:在Run2中尋找Run1的最后一個元素應該放置的位置,!!! Run2的這個位置后面可以省略不再排序,因為后面所有元素都大于Run1 len2 = gallopLeft(a[base1 + len1 - 1], a, base2, len2, len2 - 1, c); assert len2 >= 0; // 如果剩余排序長度為0,則已經有序,不用再排序(Run2全體大于Run1) if (len2 == 0) { return; } // 并歸兩側,選取較短的一方作為臨時陣列長度 // mergeLo:將len1 放入臨時陣列,mergeHi:將len2 放入臨時陣列 if (len1 <= len2) { mergeLo(base1, len1, base2, len2); } else { mergeHi(base1, len1, base2, len2); } }
歸并與Gollaping:
/** * 類似于mergeLo,除了這個方法應該只在len1 >= len2;如果len1 <= len2,則應該呼叫mergeLo, * (兩個方法都可以在len1 == len2時呼叫,) * * @param base1 Run1的隊首元素 * @param len1 Run1的長度 * @param base2 Run2的隊首元素(???must be aBase + aLen) * @param len2 Run2的長度 */ private void mergeHi(int base1, int len1, int base2, int len2) { assert len1 > 0 && len2 > 0 && base1 + len1 == base2; T[] a = this.a; // For performance T[] tmp = ensureCapacity(len2); int tmpBase = this.tmpBase; System.arraycopy(a, base2, tmp, tmpBase, len2); int cursor1 = base1 + len1 - 1; int cursor2 = tmpBase + len2 - 1; int dest = base2 + len2 - 1; // Move last element of first run and deal with degenerate cases a[dest--] = a[cursor1--]; if (--len1 == 0) { System.arraycopy(tmp, tmpBase, a, dest - (len2 - 1), len2); return; } // 簡化操作,如果Run2要合并的元素只有一個,這個元素不比Run1的最大值大,也不比當前Run1索引的最小值大(base1的位置是大于Run2隊首元素的位置),故Run2這個元素應該放置到Run1第一個 if (len2 == 1) { dest -= len1; // dest = dest - len1 (因前序dest已經-1,故是Run1隊尾坐標),dest:Run1應該開始合并的起始位置:[....{1},6,16,0,27] cursor1 -= len1; // cursor1 = cursor1 - len1 (因前序cursor1已經-1,故是Run1倒數第二坐標),cursor1:dest的前序位置:[...{X},1,6,16,0,27] System.arraycopy(a, cursor1 + 1, a, dest + 1, len1); // [...{1,6,16},0,27] -> [...1,{1,6,16},27],將Run要排序部分后移一位 a[dest] = tmp[cursor2]; // [....1,1,6,16,27] -> [...0,1,6,16,27],將tmp中的唯一元素放置到隊首 return; } Comparator<? super T> c = this.c; // Use local variable for performance int minGallop = this.minGallop; // " " " " " outer: while (true) { // 開始正常歸并,并記錄Run1、Run2 贏得選擇的次數,如果大于minGallop則跳出進入GallopingMode int count1 = 0; // Number of times in a row that first run won int count2 = 0; // Number of times in a row that second run won /* * Do the straightforward thing until (if ever) one run * appears to win consistently. */ do { assert len1 > 0 && len2 > 1; if (c.compare(tmp[cursor2], a[cursor1]) < 0) { a[dest--] = a[cursor1--]; count1++; count2 = 0; if (--len1 == 0) { break outer; } } else { a[dest--] = tmp[cursor2--]; count2++; count1 = 0; if (--len2 == 1) { break outer; } } } while ((count1 | count2) < minGallop); /* * 一方已經連續合并超過minGallop次,則進入GallopingMode */ do { assert len1 > 0 && len2 > 1; count1 = len1 - gallopRight(tmp[cursor2], a, base1, len1, len1 - 1, c); if (count1 != 0) { dest -= count1; cursor1 -= count1; len1 -= count1; System.arraycopy(a, cursor1 + 1, a, dest + 1, count1); if (len1 == 0) { break outer; } } a[dest--] = tmp[cursor2--]; if (--len2 == 1) { break outer; } count2 = len2 - gallopLeft(a[cursor1], tmp, tmpBase, len2, len2 - 1, c); if (count2 != 0) { dest -= count2; cursor2 -= count2; len2 -= count2; System.arraycopy(tmp, cursor2 + 1, a, dest + 1, count2); if (len2 <= 1) { break outer; } } a[dest--] = a[cursor1--]; if (--len1 == 0) { break outer; } // 完成一次Galloping后對閾值做修改,并判斷是否需要繼續Galloping minGallop--; } while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP); if (minGallop < 0) { minGallop = 0; } minGallop += 2; // Penalize for leaving gallop mode } // End of "outer" loop this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field if (len2 == 1) { assert len1 > 0; dest -= len1; cursor1 -= len1; System.arraycopy(a, cursor1 + 1, a, dest + 1, len1); a[dest] = tmp[cursor2]; // Move first elt of run2 to front of merge } else if (len2 == 0) { throw new IllegalArgumentException("Comparison method violates its general contract!"); } else { assert len1 == 0; assert len2 > 0; System.arraycopy(tmp, tmpBase, a, dest - (len2 - 1), len2); } }
Reference
http://www.envisage-project.eu/proving-android-java-and-python-sorting-algorithm-is-broken-and-how-to-fix-it/
https://svn.python.org/projects/python/trunk/Objects/listsort.txt
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/265548.html
標籤:Java