'harvitronix/five-video-classification-methods'視頻分類-Code總結
- 環境要求
- 準備作業
- 提取視頻幀
- CNN提取視頻幀特征
- LSTM
- 驗證模型
- 擴展
Code: https://github.com/harvitronix/five-video-classification-methods.
環境要求
requirements:
Keras>=2.0.2
numpy>=1.12.1
pandas>=0.19.2
tqdm>=4.11.2
matplotlib>=2.0.0
Pillow>=2.1.0
h5py>=2.7.0
專案檔案目錄概覽:
準備作業
1)下載UCF101資料集壓縮包并減壓至data檔案夾,
2)在data檔案夾創建train、test 、sequences、checkpoints四個檔案,
提取視頻幀
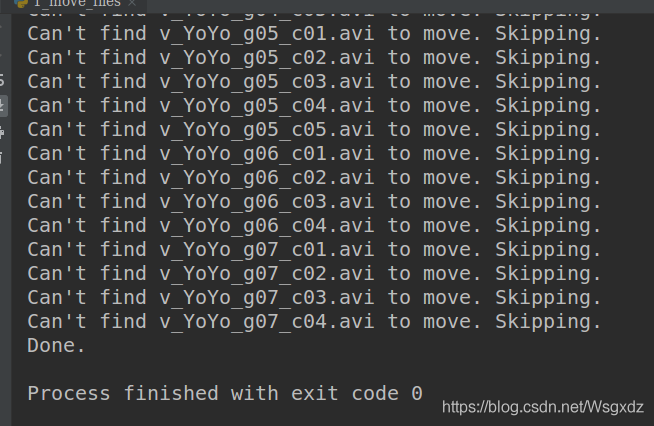
1、UCF101資料集是由101類視頻組成的,首先通過運行1_move_files.py將101類視頻按照ucfTrainTestlist檔案夾下的資料標簽將101視頻分別移至train、test檔案夾,
Lable:

這里有個坑!!
1_move_files.py 第58行:
if not os.path.exists(filename):
print("Can't find %s to move. Skipping." % (filename))
continue
# Move it.
dest = os.path.join(group, classname, filename)
print("Moving %s to %s" % (filename, dest))
os.rename(filename, dest)
print("Done.")
未將UCF101資料集讀取!
修改后的代碼:
filename_input = os.path.join('UCF-101', classname, filename)
if not os.path.exists(filename_input):
print("Can't find %s to move. Skipping." % (filename))
continue
# Move it.
dest = os.path.join(group, classname, filename)
print("Moving %s to %s" % (filename, dest))
os.rename(filename_input, dest)
print("Done.")
2、現在通過運行2_extract_files.py提取train、test檔案夾中視頻的視頻幀,并生成一個CSV檔案 ,該CSV檔案為之后特征提取及網路訓練時資料讀取提供幫助:
def get_data():
"""Load our data from file."""
with open(os.path.join('data', 'data_file.csv'), 'r') as fin:
reader = csv.reader(fin)
data = list(reader)
return data
CNN提取視頻幀特征
通過運行extract_features.py提取視頻幀特征,
seq_length = 40
class_limit = 101
seq_length:每個視頻段考慮的視頻幀數目
class_limit:限制分類數
舉個例子:一個視頻段input_list有240幀,seq_length = 40,首先判斷input_list是否大于seq_length即 assert len(input_list) >= seq_length,然后將input_list與seq_length做地板除即: skip = len(input_list) // size,本例中skip = 6,即每隔6幀從input_list中取一幀以串列的形式保存到output即:output = [input_list[i] for i in range(0, len(input_list), skip)],最終取得40幀,
def rescale_list(input_list, size):
assert len(input_list) >= size
skip = len(input_list) // size
output = [input_list[i] for i in range(0, len(input_list), skip)]
return output[:size]
在Imagenet上預訓練好的InceptionV3卷積網路提取這40幀特征作為該視頻段的特征,并將特征保存在sequences檔案夾,numpy會自動在末尾添加 .npy,
path = os.path.join('data', 'sequences', video[2] + '-' + str(seq_length) + \
'-features')
LSTM
將提取到的序列特征送入LSTM網路進行訓練,通過運行 train.py生成 .hdf5檔案,并將模型保存到checkpoints檔案夾,并且會在logs檔案夾生成一個 .log 訓練日志檔案,用來可視化訓練程序中acc與loss的變化,
獲取由CNN提取的序列特征:
def get_extracted_sequence(self, data_type, sample):
"""Get the saved extracted features."""
filename = sample[2]
path = os.path.join(self.sequence_path, filename + '-' + str(self.seq_length) + \'-' + data_type + '.npy')
if os.path.isfile(path):
return np.load(path)
else:
return None
LSTM網路模型:
def lstm(self):
model = Sequential()
model.add(LSTM(2048, return_sequences=False,
input_shape=self.input_shape,
dropout=0.5))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(self.nb_classes, activation='softmax'))
return model
用來可視化訓練程序的plot_trainlog.py:
import csv
import matplotlib.pyplot as plt
def main(training_log):
with open(training_log) as fin:
reader = csv.reader(fin)
next(reader, None) # skip the header
accuracies = []
Val_acc = []
cnn_benchmark = [] # this is ridiculous
for epoch,acc,loss,val_acc,val_loss in reader:
accuracies.append(float(acc))
Val_acc.append(float(val_acc))
cnn_benchmark.append(0.65) # ridiculous
plt.plot(accuracies)
plt.plot(Val_acc)
plt.plot(cnn_benchmark)
plt.show()
if __name__ == '__main__':
training_log = 'data/logs/lstm-training-1617251893.3342032.log'
main(training_log)
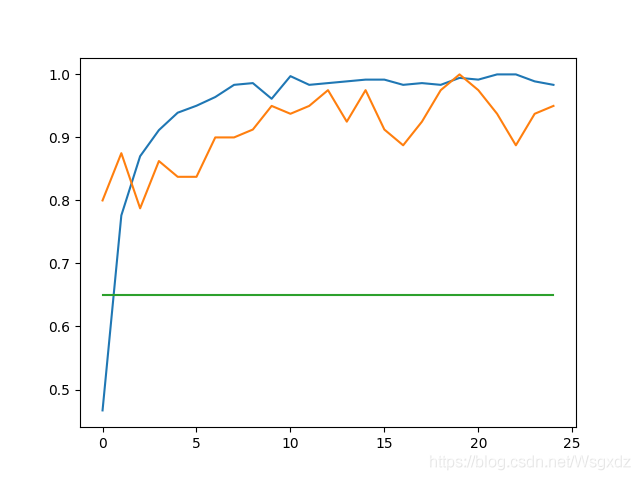
綠線:cnn_benchmark
橘黃線:Val_acc
藍線:accuracies
驗證模型
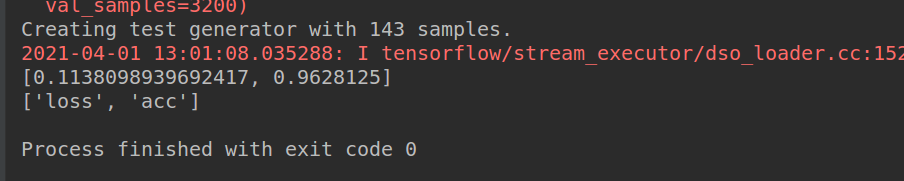
通過運行validate_rnn.py將保存在checkpoints檔案夾的模型加載進來驗證模型準確度,結果如圖:
擴展
若要將一段視頻進行分段處理,十幀作為一個序列,首先送入CNN提取基礎特征,后送入LSTM提取時間-空間特征,會遇到什么問題?能否完成視頻分段任務?是否過擬合?模型魯棒性如何?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/271570.html
標籤:python
上一篇:Spring5總述(四)—— IOC操作Bean管理(FactoryBean,Bean的作用域,Bean的生命周期,Xml的自動裝配)
下一篇:爬蟲入門bs4之多執行緒