今天簡單來講一下爬蟲決議庫bs4還有一點多執行緒
下面分步驟幾個小步驟來講
特此宣告 本人不足的地方還望指出
因為用到了幾個模塊所以要裝一下
這里決議庫用的是lxml所以要安裝一下
pip install lxml
pip isntall bs4
pip install requests
1.獲取回應
import requests
resposne = requests.get('https://www.baidu.com/')
print(resposne
)
如下圖所示
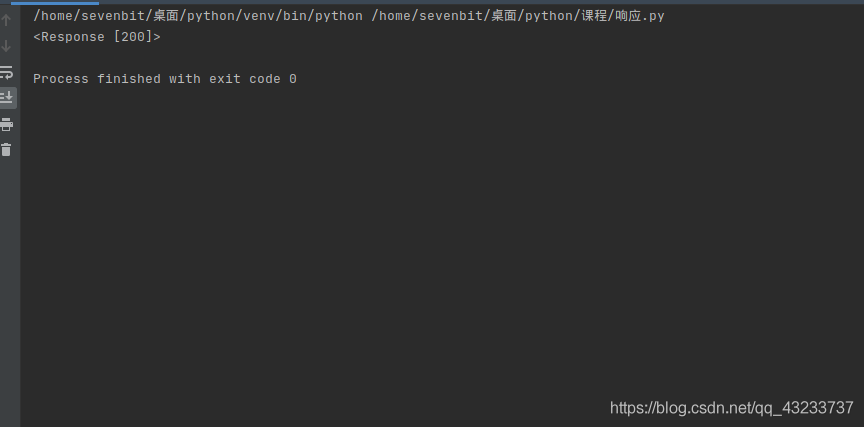
這里是向服務器發起回應
對百度發起來一個請求等待服務器回傳回應
結果是200表示請求成功
這里要了解一點http請求
比如常見的404就是表示頁面請求失敗
如果你請求程序失敗了多半被服務器發現這個是一個爬蟲而不是用戶
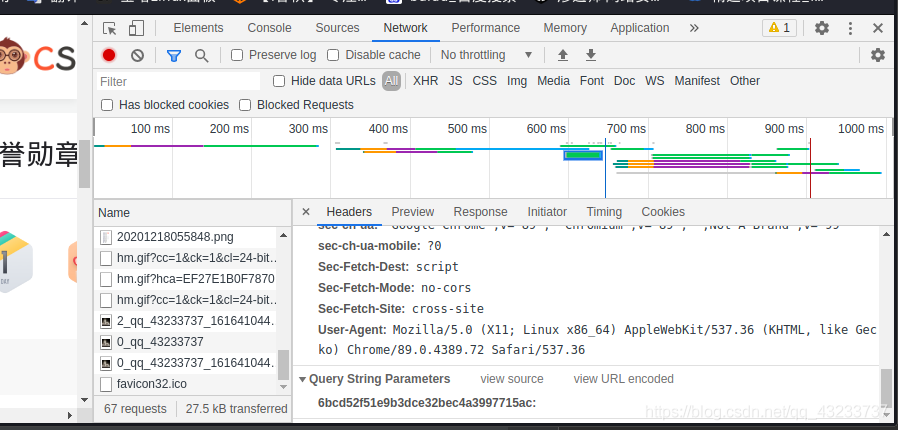
所以要加上請求頭就好了
f12重繪 netwwork 找到user就是請求頭加上就行了
2.決議網頁
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.13'
'0 Safari/537.36'
}
url = 'https://www.baidu.com/'
#定義請求頭
html = requests.get(url,headers=headers)
#所使用bs4決議決議
soup = BeautifulSoup(html.text,'lxml')
print(soup)
下圖是獲取的網頁資料
3,獲取資料
接下來我們來獲取網站資訊結合上述進行演練
我們要獲取這個網站的圖片地址
網站
我們來看一下怎么獲取呢?
右鍵檢查 看一下圖片地址在哪
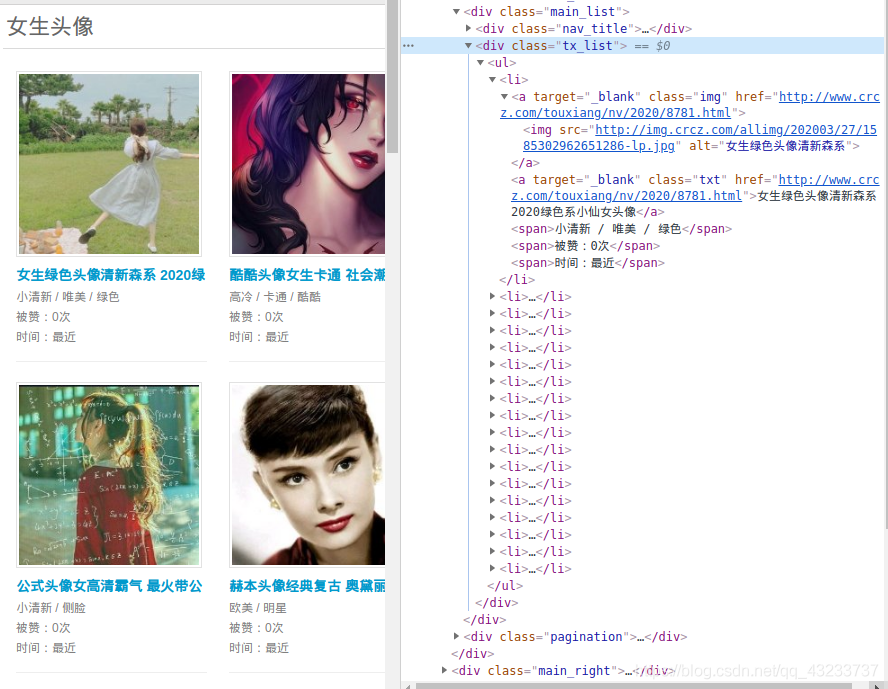
我們可以看到圖片在
標簽里
那就好辦了
我們獲取圖片名稱怎么辦呢?

那就好辦了
我們獲取圖片名稱怎么辦呢?
首頁地址
urls = 'http://www.crcz.com/touxiang/nv/list_'
# print(urls)
for x in range(1,3):
url = urls + str(x) + '.html' #拼接地址用于獲取分頁
# print(url)
# print(url)
html = requests.get(url,headers=headers)
html.encoding='utf-8'
soup = BeautifulSoup(html.text,'lxml')
#print(soup)
all_img = soup.select('.tx_list>ul>li')
# for all in all_img:
#圖片地址
# img = img_a.a.img.get('src')
# print(img)
# 圖片名稱
# # img_name = img_a.find('a', class_='txt').get_text()
# # print(img_name)
4.下載資料
圖片地址和圖片名稱的拿到了就好辦了
下載唄
# 新建一個檔案夾保存所有圖片
if not os.path.exists('./tu/'):
os.mkdir('./tu/')
imgpath = './tu/' + img_name +'.jpg'
with open(imgpath,'wb') as f:
f.write(img)
print(img_name,'下載完成!!!')
5.完整代碼
from bs4 import BeautifulSoup
import requests
import os
#請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.13'
'0 Safari/537.36'
}
urls = 'http://www.crcz.com/touxiang/nv/list_'
# 新建一個檔案夾保存所有圖片
if not os.path.exists('./tu'):
#如果沒有當前檔案夾則創建一個
os.mkdir('./tu/')
#定義下載函式
def get_url(page):
for x in range(1,page+1):
url = urls + str(x) + '.html'# 拼接url
html = requests.get(url, headers=headers)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text, 'lxml')
div_img = soup.select('.tx_list>ul>li')
for img_a in div_img:
# 圖片名稱
# img_name = img_a.find('a', class_='txt').get_text()
# print(img_name)
# 圖片
img = img_a.a.img.get('src')
# print(img)
# 圖片二進制
img_data = requests.get(url=img, headers=headers).content
# print(img_data)
# 圖片名稱
img_name = img_a.find('a', class_='txt').get_text()
# print(img_name)
# 圖片存盤路徑
imgpath = './tu/' + img_name + '.jpg'
with open(imgpath, 'wb') as f:
f.write(img_data)
print(img_name, '下載成功')
if __name__ == '__main__':
page = int(input('請輸入需要爬取的頁數:'))
get_url(page)
總結我們了解基本的流程了相信這一步步小節的拆分能幫助大家1好了解爬蟲整個流程
這里上面的是單執行緒如果我們爬去資料過多就會導致下載過慢
這就要涉及行程問題
單執行緒就是同好比如說一群人在排隊
必須要排對一個一個來等他結束
所謂多執行緒就是需要多個玩成的任務
幾個人就可以玩成不必等待
單執行緒時間
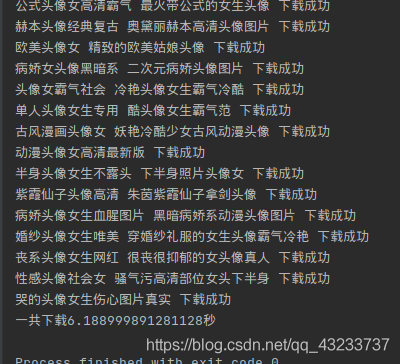
多執行緒時間
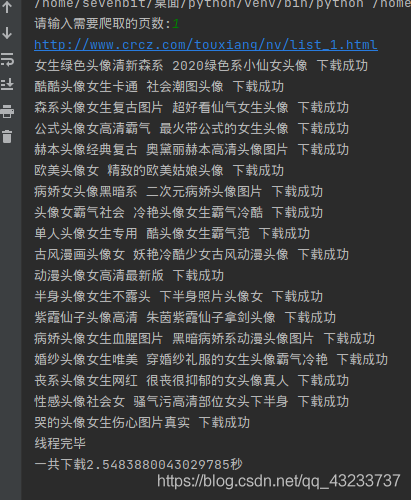
多執行緒代碼
import requests
import threading
import time
import queue
import os
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.13'
'0 Safari/537.36'
}
#queeue執行緒
url_queue = queue.Queue()
#首頁
urls = 'http://www.crcz.com/touxiang/nv/list_'
#定義下載函式
def get_url(page):
for x in range(1,page+1):
url = urls + str(x) + '.html'# 拼接url
print(url)
# print(url)
url_queue.put(url)
# print(url_queue.queue)
#定定義爬取函式
def spider(url_queue):
# 新建一個檔案夾保存所有圖片
if not os.path.exists('./tu1'):
os.mkdir('./tu1')
url = url_queue.get()# 從佇列中取出最前面的url
html = requests.get(url=url,headers=headers)
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text,'lxml')# 對原始碼進行決議
div_img = soup.select('.tx_list>ul>li')
for img_a in div_img:
img = img_a.a.img.get('src')
# 圖片二進制
img_data = requests.get(url=img, headers=headers).content
# 圖片名稱
img_name = img_a.find('a', class_='txt').get_text()
# 圖片存盤路徑
imgpath = './tu1/' + img_name + '.jpg'
with open(imgpath, 'wb') as f:
f.write(img_data)
print(img_name, '下載成功')
if not url_queue.empty():
spider(url_queue)
def main():
queue_list = []
t = threading.Thread(target=spider, args=(url_queue,))
t.start()
queue_list.append(t)
for t in queue_list:
t.join()
print('執行緒完畢')
if __name__ == '__main__':
page = int(input('請輸入需要爬取的頁數:'))
get_url(page)
# start_time = time.time()
ted = time.time()
main()
end = time.time()
print(f'一共下載{end - ted}秒')
# print("test3用時:%f" % (time.time() - start_time))
多執行緒首先定義一個任務串列
來供行程來使用
然后呼叫任務行程添加1到對列去執行
等待進來行程執行完畢
這里如果網路不好的行程就會2堵塞導致網站請求過慢所以使用代碼之前要保證1網路通暢
不然就是同步了比同步還慢
感謝大家點個贊在走吧
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/271571.html
標籤:python
上一篇:UCF101視頻分類之CNN-LSTM-Code總結
下一篇:用Python實作定時任務