相信有很多人在看小說的時候,都或多或少會看到點廣告吧,這樣子看感覺感覺非常的不盡興,用筆者的方法讓你越看越欲罷不能,從此迷戀上這種感覺哦
宣告
筆者所使用資料清洗方法是css選擇器,另外筆者建議如果可以的話爬蟲模塊可以使用requests_HTML,它在requests的基礎上進一步封裝,加入了資料清洗功能以及Ajax動態渲染功能,使用起來筆者感覺是要比requests模塊方便多了,
第一步----獲取各書籍鏈接
通過分析url發現排行榜變化的規律
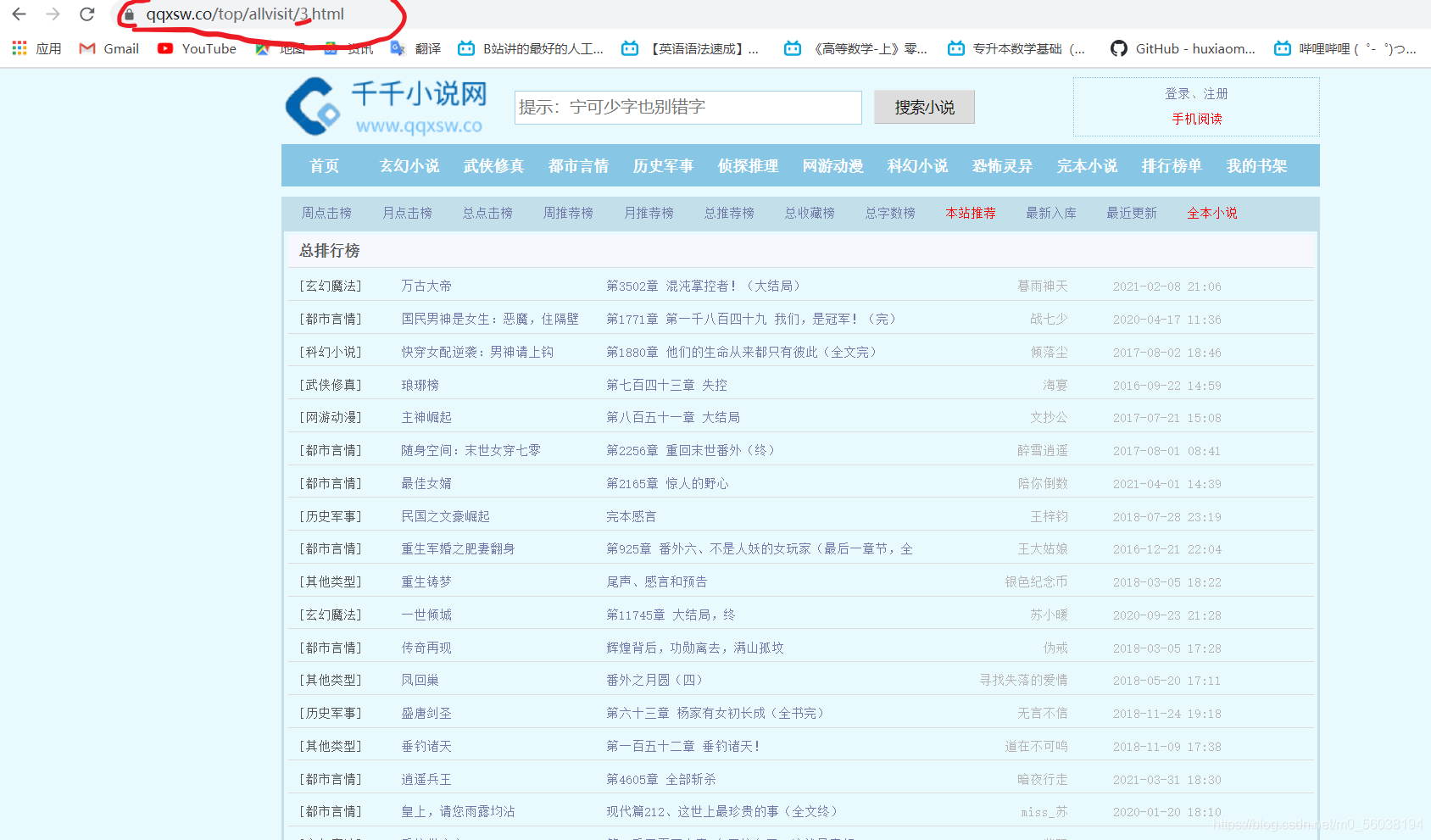
發現每向后翻一頁其url里的數字都會發生變化(圖片中用紅線標注的數字)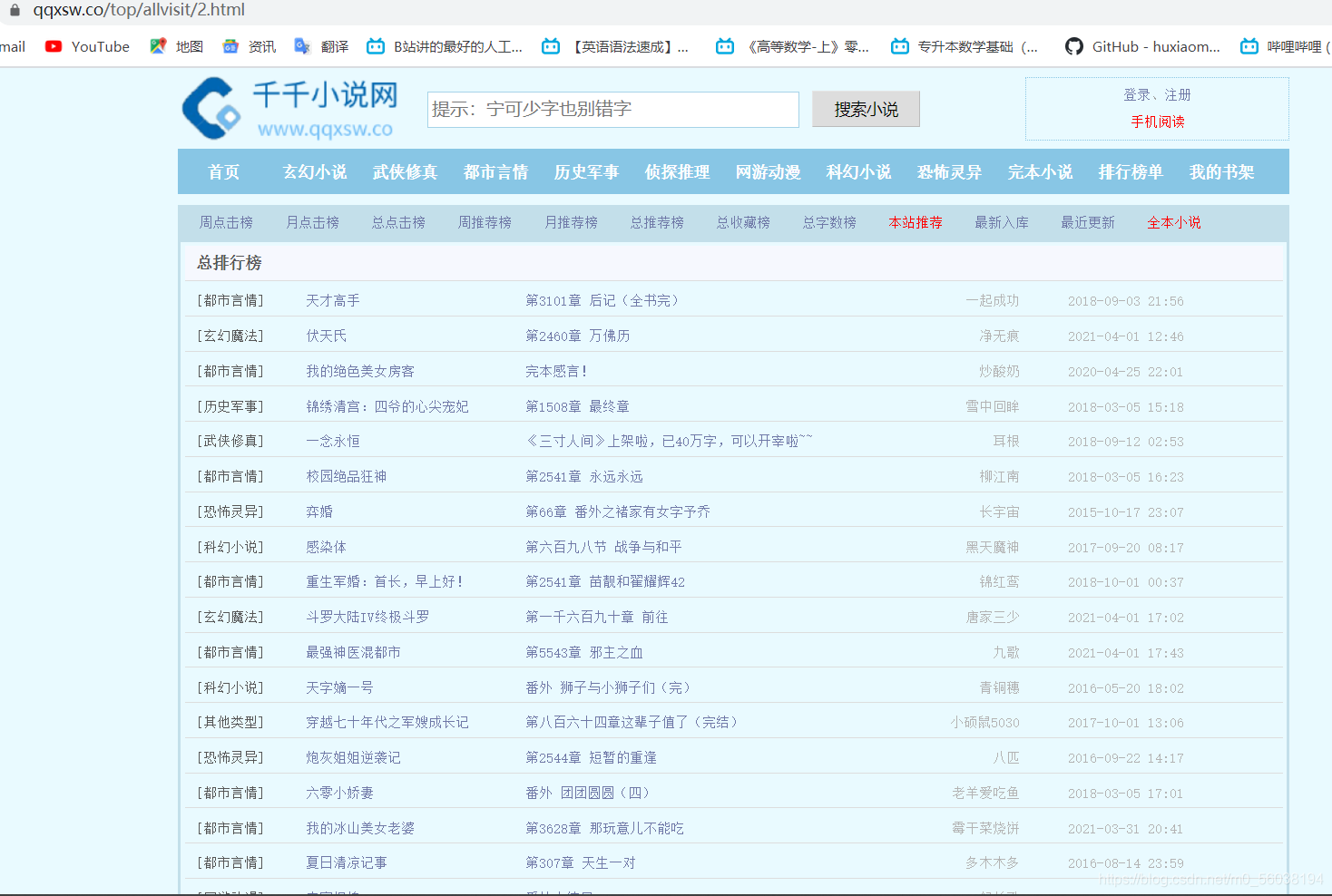
直接上代碼獲取其書籍鏈接:
def scrapyRootLink(url):
""" 獲取分類下的url """
try:
links = []
res = requests.get(url=url, headers=header)
res.encoding = 'gbk'
date = BeautifulSoup(res.text, 'lxml')
for lin in date.select('.s2 > :link'):
lin = str(lin)
link = re_link.findall(lin)
if link:
links.append(link)
if links:
print('書籍鏈接獲取成功')
return links
else:
print('scrapyRootLink有問題')
return []
except Exception:
print('獲取書籍鏈接函式錯誤')
return []
第二步----獲取章節鏈接
知道其規律之后就可點進去獲取書籍的url
點擊進入書籍界面,進入開發者模式,分析其結構具體看下圖:
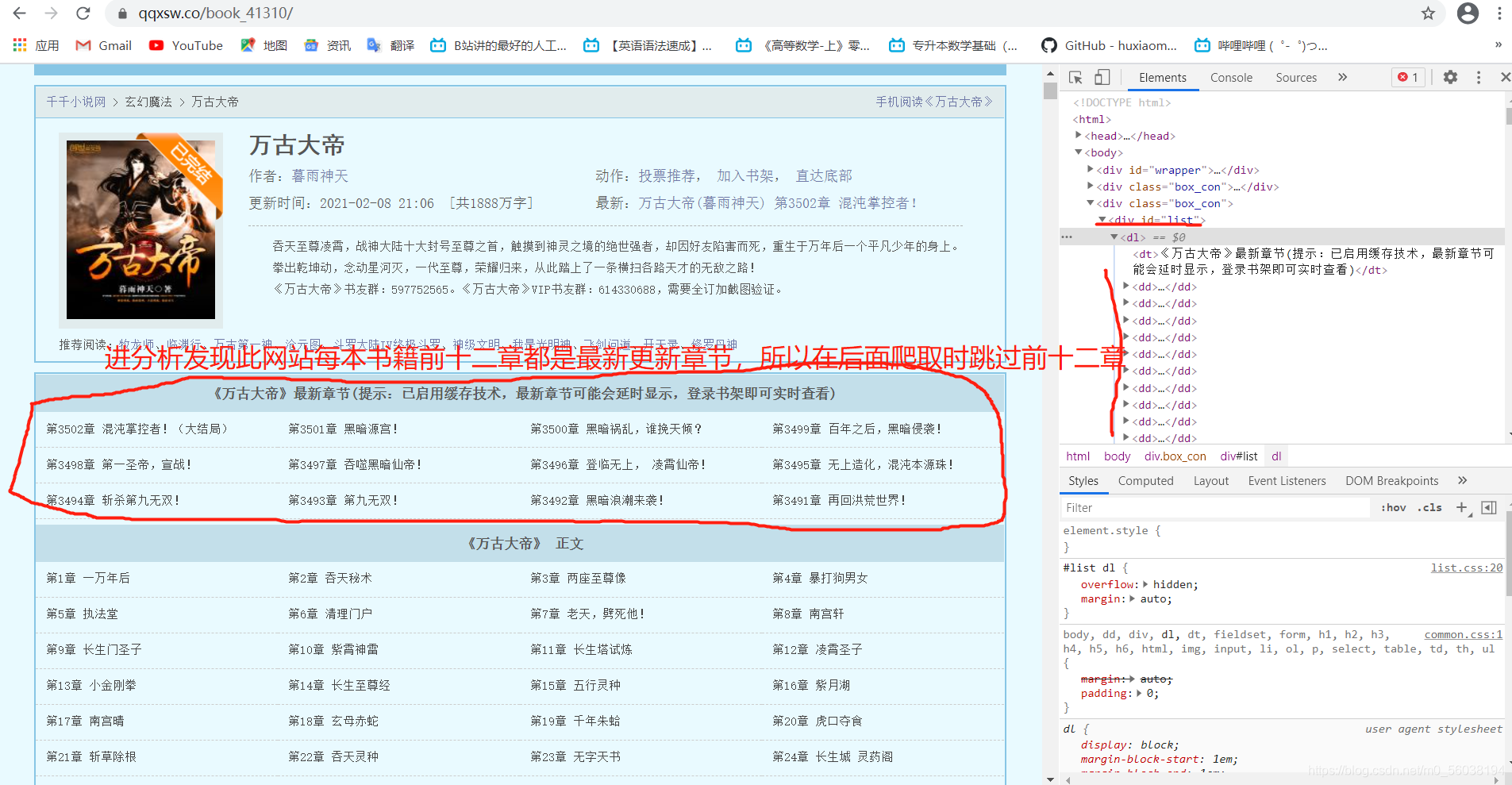
直接上代碼:
def scarpylink(self):
""" 爬取書籍每個章節的url """
try:
Link = self.rootLink[0]
data = []
res = requests.get(url=Link, headers=header)
res.encoding = 'gbk'
""" 決議內容 """
res = str(res.text)
soup = BeautifulSoup(res, 'lxml')
# 獲取書名
bookname = soup.select_one('#info > h1').text
# 獲取章節鏈接
ran = 1
for htmls in soup.select('#list > dl > dd > a'):
if ran > 12:
htmls = str(htmls)
links = re_link.findall(htmls)
data.append(Link + ''.join(links))
else:
ran += 1
if data:
print('章節鏈接獲取成功')
return {'bookname': bookname,
'links': data}
else:
return []
except Exception:
print('出錯')
return []
第三步
進入其章節頁面分析其結構,具體情況如下:
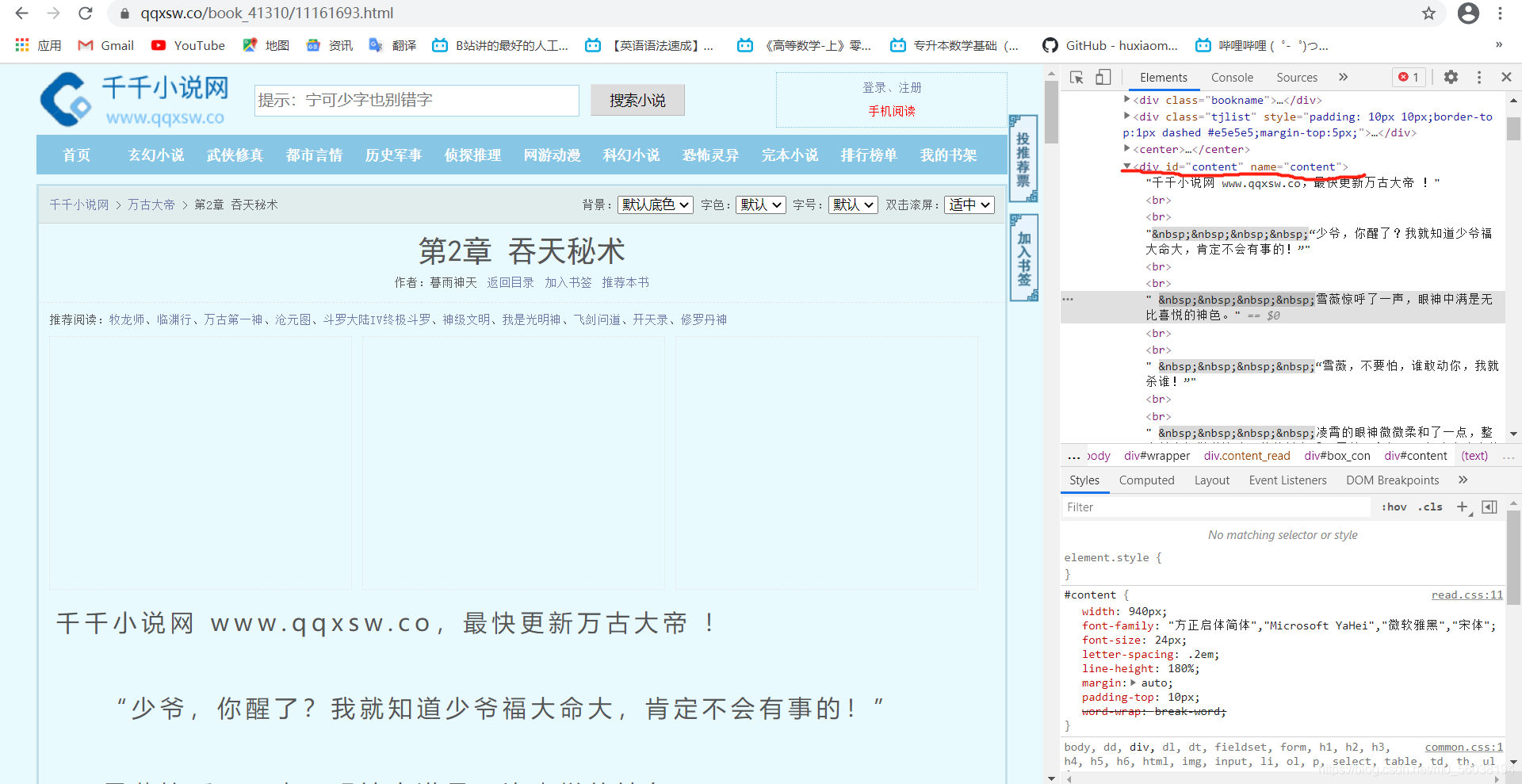
發現其章節內容都在一個div下面,這就好辦了,不過里面還有一些特殊字符包括小說的url鏈接,這里可以用replace()進行字串替換,由于只是做示范,所以筆者這里并沒有進行url的替換,只替換了特殊字符
不說了,直接上代碼:
def scarpytext(self, url):
""" 爬取書籍每個章節的內容 """
try:
texts = []
page = requests.get(url=url, headers=header)
page.encoding = 'gbk'
soup = BeautifulSoup(page.text, 'lxml')
selctname = soup.select_one('.bookname > h1').text
print('章節標題獲取成功')
for text_list in soup.select('#content'):
for tex in text_list: # 需要獲取詳細文本
tex = str(tex)
tex = tex.replace('<br/>', '').replace('\xa0\xa0\xa0\xa0', '')
texts.append(tex)
if texts:
print('章節文本獲取成功!')
return {'name': selctname,
'text': texts}
except Exception:
print('文本函式出錯')
return []
以下是全部代碼:
# -*- encoding='utf-8' -*-
import requests
import random
import time
import re
from bs4 import BeautifulSoup
import os
# 首頁域名
Host = "https://www.qqxsw.co/"
user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
header = {'User-Agent': random.choice(user_agent)}
re_link = re.compile(r'<a href="(.*?)"')
class Bug_pa(object):
def __init__(self, RootLink):
""" 初始化 """
self.rootLink = RootLink
def scarpylink(self):
""" 爬取書籍每個章節的url """
try:
Link = self.rootLink[0]
data = []
res = requests.get(url=Link, headers=header)
res.encoding = 'gbk'
""" 決議內容 """
res = str(res.text)
soup = BeautifulSoup(res, 'lxml')
# 獲取書名
bookname = soup.select_one('#info > h1').text
# 獲取章節鏈接
ran = 1
for htmls in soup.select('#list > dl > dd > a'):
if ran > 12:
htmls = str(htmls)
links = re_link.findall(htmls)
data.append(Link + ''.join(links))
else:
ran += 1
if data:
print('章節鏈接獲取成功')
return {'bookname': bookname,
'links': data}
else:
return []
except Exception:
print('出錯')
return []
def scarpytext(self, url):
""" 爬取書籍每個章節的內容 """
try:
texts = []
page = requests.get(url=url, headers=header)
page.encoding = 'gbk'
soup = BeautifulSoup(page.text, 'lxml')
selctname = soup.select_one('.bookname > h1').text
print('章節標題獲取成功')
for text_list in soup.select('#content'):
for tex in text_list: # 需要獲取詳細文本
tex = str(tex)
tex = tex.replace('<br/>', '').replace('\xa0\xa0\xa0\xa0', '')
texts.append(tex)
if texts:
print('章節文本獲取成功!')
return {'name': selctname,
'text': texts}
except Exception:
print('文本函式出錯')
return []
def save(self, bookname, name, booktext):
""" 保存小說 """
try:
# exists: 判斷括號中的檔案路徑是否存在
# 如果檔案夾不存在, 就以書名創建一個檔案夾
print(bookname)
print(name)
if not os.path.exists(r'G:\book\-'+str(bookname)):
os.mkdir(r'G:\book\-'+str(bookname))
# with open(r'G:\book\book' + str(bookname) + str(name) + '.txt', 'a') as fp:
with open(r'G:\book\-' + str(bookname) + '\-' + str(name) + '.txt', 'a') as fp:
fp.write(name + '\n')
for txt in booktext:
fp.write(txt + '\n')
print('保存成功')
except Exception:
print('保存函式出錯了')
return []
def rand_time(self):
""" 啟動隨機延時 """
i = random.uniform(0, 30)
time.sleep(i)
def main(self):
""" 主函式 """
try:
# 爬取書的章節鏈接
linkinfo = self.scarpylink()
i = 1
for link in linkinfo['links']:
txt = self.scarpytext(link)
if txt:
if self.save(linkinfo['bookname'], str(i) + '-' + txt['name'], txt['text'] ):
print('儲存ok', txt['name'])
else:
print('儲存失敗', txt['name'])
i += 1
except Exception:
print('主函式有問題')
def scrapyRootLink(url):
""" 獲取分類下的url """
try:
links = []
res = requests.get(url=url, headers=header)
res.encoding = 'gbk'
date = BeautifulSoup(res.text, 'lxml')
for lin in date.select('.s2 > :link'):
lin = str(lin)
link = re_link.findall(lin)
if link:
links.append(link)
if links:
print('書籍鏈接獲取成功')
return links
else:
print('scrapyRootLink有問題')
return []
except Exception as e:
print(e)
return []
if __name__ == '__main__':
rootlinks = []
for i in range(1, 2):
rlink = 'https://www.qqxsw.co/top/allvisit/%s.html' %(i)
rootlinks.append(rlink)
for rootlink in rootlinks:
for alink in scrapyRootLink(rootlink):
shu = Bug_pa(alink)
shu.main()
shu.rand_time() # 每爬取一頁執行緒隨機睡眠0-30秒
希望以上內容可以幫助到更多的想要學習的人,第一次當博主希望筆者自己可以堅持下去,一起加油吧
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/271573.html
標籤:python
上一篇:用Python實作定時任務