文章目錄
- 1. 微服務
- 1.1 主流注冊中心對比
- 1.2 eureka 心跳檢測和自我保護機制
- 1.3 Ribbon 負載均衡策略
- 1.4 Hystrix 艙壁模式
- 1.5 Hystrix 作業模式
- 1.6 Fein
- 1.7 gateway
- 2. 并發編程
- 2.1 多執行緒
- 2.1.1 創建一個阻塞佇列
- 2.1.2 為什么wait() 方法要釋放鎖,
- 2.1.3 volatile 關鍵字的作用
- 2.1.4 synchronized
- 2.2 JUC
- 2.2.1 阻塞佇列
- 2.2.2 CopyOnWrite
- 2.2.3 鎖
- 2.2.4 AQS
- 2.2.5 CAS
- 2.2.5 ReentrantLock 互斥鎖
- 2.3 執行緒池
- 2.3.1 ThreadPoolExecutor
- 2.3.2 執行緒池拒絕策略
- 2.3.3 ScheduledThreadPoolExecutor
- 3. java 基礎
- 3.1 spring 啟動的流程(12步)
- 3.2 BeanFactory 創建流程
- 3.3 Bean 創建流程
- 3.4 Bean 生命周期(11步)
- 3.5 **Autowired 和Resource 注解的區別**
- 3.6 回圈依賴
- 3.7 事務的傳播行為(7中型別)
- 3.8 spring mvc 請求處理流程(10步)
- 3.9 過濾器攔截器
- 3.10 springboot 啟動流程(9步)
- 3.11. 說說 hashMap 的原理
- 3.12. synchronized 和 ReentrantLock 的區別
- 4. jvm
- 4.1 jvm 記憶體模型
- 4.2 jvm 堆
- 4.2.1 堆記憶體分布
- 4.2.2 物件分配程序
- 4.3 方法區
- 4.4 類加載的執行程序
- 4.5 雙親委派模型
- 4.6 判斷物件已死演算法
- 4.7 參考型別
- 4.8 垃圾回收演算法
- 4.8.1 分代收集理論
- 4.8.2 標記清除演算法
- 4.8.3 標記復制演算法
- 4.8.4 標記整理演算法
- 4.9 垃圾收集器
- 4.9.1 CMS 收集器
- 4.9.2 G1 收集器
- 4.9.3 ZGC 收集器
- 5. 設計模式
- 5.1 單例模式
- 5.2 工廠模式
- 5.3 構建者模式
- 5.4 代理模式
- 5.5 配接器模式
- 6. 資料結構和演算法
- 6.1 資料結構
- 6.1.1 線性表
- 6.1.1.1陣列
- 6.1.1.2鏈表
- 6.1.1.3 堆疊
- 6.1.1.4 佇列
- 6.1.2 散串列
- 6.1.3 樹
- 6.1.3.1 二叉樹
- 6.1.3.2 滿二叉樹
- 6.1.3.3 完全二叉樹
- 6.1.3.4 平衡二叉樹
- 6.1.3.5 二叉查找樹
- 6.1.3.6 紅黑樹
- 6.1.3.7 B 樹
- 6.1.3.8 B+ 樹
- 6.2 演算法
- 6.2.1 排序
- 6.2.1.1 冒泡
- 6.2.1.2 快排
- 6.2.1.3 堆排序
- 7. 訊息佇列
- 7.1 訊息佇列的使用場景
- 7.2 RocketMQ 的角色
- 7.3 RocketMQ 的執行流程
- 7.4 RocketMQ 訊息過濾
- 7.5 零拷貝
- 7.6 同步復制異步復制
- 7.7 刷盤機制
- 7.8 延時訊息
- 7.9 事務訊息
- 7.10 順序訊息
- 8. mysql
- 8.1 mysql 體系架構
- 8.2 mysql 運行機制
- 8.3 mysql 存盤引擎InnoDB
- 8.3.1 記憶體結構
- 8.4 mysql 索引
- 8.4.1 普通索引
- 8.4.2 唯一索引
- 8.4.3 主鍵索引
- 8.4.4 復合索引
- 8.4.5 聚集索引
- 8.4.6 索引原理
- 8.4.7 like 查詢
- 8.4.8 explain 有哪些欄位
- 8.4.9 慢查詢優化
- 8.5 mysql 鎖
- 8.5.1 鎖分類
- 8.5.2 悲觀鎖
- 8.5.3 樂觀鎖
- 8.5.4 死鎖
- 8.6 mysql 事務
- 8.6.1 事務特性
- 8.6.2 事務隔離級別
- 8.6.3 MVCC
- 8.7 mysql 分庫分表
- 8.7.1 主鍵策略
- 8.7.2 分片策略
- 8.8 mysql 主從同步
- 8.8.1 適用場景
- 8.8.2 主從同步作用
- 8.8.3 主從同步實作原理
- 9. redis
- 9.1 跳躍表
- 9.2 字典
- 9.3 壓縮串列
- 9.4 快速串列
- 9.5 快取過期和淘汰策略
- 9.5.1 過期洗掉策略
- 9.5.1.1 定時洗掉
- 9.5.1.2 惰性洗掉
- 9.5.1.3 主動洗掉(定期洗掉)
- 9.5.2 淘汰策略
- 9.5.2.1 LRU
- 9.5.2.2 隨機
- 9.5.2.3 volatile-ttl
- 9.6 快取穿透、快取雪崩、快取擊穿
- 9.6.1 快取穿透
- 9.6.2 快取雪崩
- 9.6.3 快取擊穿
- 9.7 單執行緒的Redis 為什么這么快
- 9.8 redis 分布式鎖實作
- 10. 中間件
- 10.1 zookeeper
- 10.1.1 zookeeper 資料結構
- 10.1.2 監聽器
- 10.1.3 zookeeper 應用場景
- 10.1.4 ZAB 協議
- 10.2 dubbo
- 11. 分布式
- 11.1 分布式下讀寫一致性
- 11.2 單調一致性
- 11.3 CAP 理論
- 11.4 BASE 理論
- 11.5 2PC 和 3PC
- 11.6 paxos 一致性演算法
- 11.7 Raft 一致性演算法
- 12. mybatis
- 12.1 mybatis 初始化
- 12.2 sql 執行程序
- 12.3 mybatis 插件
這是本人整理的數萬字的面試筆記,基本上涵蓋了 Java 領域的所有技術堆疊,本人也是憑借這份面試筆記斬獲了近 10 個 offer,面試成功率高達80%,當然這份筆記是我根據自身的經驗和技術堆疊整理的,自己覺得很重要的或者記不清的就會記錄記錄下來,面試被問到的時候也有回答的思路,現在共享給大家,希望對準備面試的小伙伴有幫助,
1. 微服務
1.1 主流注冊中心對比
zookeeper:zookeeper 作為注冊中心主要是因為它具有節點變更通知功能,只要客戶端監聽相關服務節點,服務節點有所變更就能及時的通知到監聽客戶端,非常方便,zookpeeper 是cp模式的,
eureka:是 netflix 開源的 基于RestFulAPI 風格開發的服務注冊和發現組件,現在不會再更新,
consul:是使用go 語言開發的支持多資料中心分布式高可用的服務發布和注冊的服務軟體,
nacos:是一個更易于構建云原生應用的動態服務發現、配置管理和服務管理平臺,
1.2 eureka 心跳檢測和自我保護機制
心跳檢測:eureka 每隔30 秒就會向注冊中心續約心跳一次,也就是報活,如果沒有續約,租約在90s 后到期,然后服務就會失效,每隔30s的續約操作,就是心跳檢測,
自我保護:eureka 服務端如果在15 分鐘內,超過 85% 的客戶端節點都沒有正常心跳,那么Eureka 就認為客戶端和注冊中心出現了網路故障,而微服務本身是可正常運行的,此時不應該移除這個微服務,所以引入了自我保護機制,在自我保護狀態下,不會移除任何服務,能接受新服務的注冊和查詢請求,但是不會和集群中其他節點同步,
1.3 Ribbon 負載均衡策略
1、輪尋策略
2、隨機策略
3、重試策略:一定時間內回圈重試,繼承隨機策略,
4、最小連接數策略:遍歷serverList,選出可用且連接數最小的server.
5、可用過濾策略:擴展了輪尋策略,會先通過默認的輪詢選取一個 server,再判斷 server 是否超時可用,
6、區域權衡策略:擴展了輪詢策略,除了過濾連接超時和連接數過多的server,還會過濾掉不符合要求的 zone 區域里面所有的節點,然后在剩下的節點中輪詢獲取,
1.4 Hystrix 艙壁模式
使用艙壁避免了單個作業負載(或服務)消耗掉所有資源,從而導致其他服務出現故障的場景,這種模式主要是通過防止由一個服務引起的級聯故障來增加系統的彈性,通過應用艙壁模式,可以保護有限的資源不被耗盡,為了避免問題服務請求過多導致正常服務?法訪問,Hystrix 不是采?增加執行緒數,?是單獨的為每?個控制?法創建?個執行緒池的?式,這種模式叫做“艙壁模式",
1.5 Hystrix 作業模式
1、當調?出現問題時,開啟?個時間窗(10s)
2、在這個時間窗內,統計調?次數是否達到最?請求數?
- 如果沒有達到,則重置統計資訊,回到第1步;
- 如果達到了,則統計失敗的請求數占所有請求數的百分?,是否達到閾值?
- 如果達到,則跳閘(不再請求對應服務)
- 如果沒有達到,則重置統計資訊,回到第1步
3、如果跳閘,則會開啟?個活動窗?(默認5s),每隔5s,Hystrix 會讓?個請求通過,到達那個問題服務,看是否調?成功,如果成功,重置斷路器回到第1步,如果失敗,回到第3步,
1.6 Fein
fegin 是NetFlix 開發的一個輕量級 RestFulf 的 HTTP 服務客戶端,用來進行遠程呼叫,
1.7 gateway
gateway 核心邏輯就是路由轉發加執行過濾器鏈,
客戶端向gateway 發送請求,然后在gateway handler Mapping 中找到與請求相匹配的路由,然后handler 通過制定了過濾器鏈來將請求發送到我們實際服務執行業務邏輯,然后回傳,在過濾器中可以進行引數加解密,引數校驗、權限校驗、日志輸出、協議轉換等等,
2. 并發編程
2.1 多執行緒
2.1.1 創建一個阻塞佇列
核心思想就是當佇列為空時,呼叫出佇列的方法,會進行wait() 等待,直到有資料入佇列時,呼叫notify() 方法,同樣的在佇列滿是,入佇列會阻塞,直到有出佇列才喚醒,
public class MyBlockingQueue {
private int[] data=new int[10];
private int putIndex;
private int getIndex;
private int size;
public synchronized void put(int val){
if(size==data.length){
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
put(val);
}else {
data[putIndex]=val;
putIndex++;
if(putIndex==data.length){
putIndex=0;
}
size++;
}
}
public synchronized int get(){
if(size==0){
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
return get();
}else {
int val = data[getIndex];
getIndex++;
if(getIndex==data.length){
getIndex=0;
}
size--;
return val;
}
}
}
2.1.2 為什么wait() 方法要釋放鎖,
因為當一個執行緒進入一個 synchronized 修飾的同步方法后,會鎖住當前物件,呼叫 wait() 方法進入阻塞狀態,如果不釋放當前物件的鎖的話,其他執行緒永遠獲取不到當前物件的鎖,也就沒有辦法喚醒當前執行緒了,這樣就形成了死鎖,所以在呼叫wait() 方法會釋放鎖,等待其他執行緒獲取當前物件鎖,呼叫notify() 喚醒此執行緒,然后此執行緒重新獲得鎖,執行剩下的操作,執行結束后,會再次的釋放鎖,
2.1.3 volatile 關鍵字的作用
1、保證64位寫入的原子性,
2、記憶體可見性
3、禁止指令重新排序,
2.1.4 synchronized
synchronized 實作原理是獲取不到鎖先自旋,自旋依然獲取不到鎖,再阻塞,
2.2 JUC
2.2.1 阻塞佇列
阻塞佇列有基于陣列實作的ArrayBlockQueue 和基于 鏈表實作的 LinkBlockQueue,以及還有優先級的 PriorityBlockQuere,按照元素的優先級出佇列,實作了Comparable 介面,以及延時佇列,根據延時時間大小出佇列的,實際上是未來時間減去當前時間放入,DelayQueue 中的元素,如果getDelay() 小于等于0,說明該元素到期,可以出佇列了,同步佇列沒有容量,先呼叫put(),執行緒就會阻塞,只要等另一個執行緒呼叫了task(),兩個執行緒才會喚醒,
2.2.2 CopyOnWrite
是指在寫的時候,不會直接操作源資料,而是先copy 一份資料進行修改,然后通過悲觀鎖或者樂觀鎖的方式寫回,這樣的好處是,讀不用加鎖,
CopyOnwriteArrayList 讀操作的時候不會加鎖,只有寫的時候才會加同步鎖,所以是執行緒安全的 ArrayList,
CopyOnwriteArraySet 就是用array 實作的一個執行緒安全的 Set .保證所有元素不重復,封裝的是CopyOnwriteArrayList ,利用CopyOnwriteArrayList 的addAllAbsent() 方法,
2.2.3 鎖
為了實作一把具有阻塞或喚醒功能的鎖,需要幾個核心要素:
-
需要一個state變數,標記該鎖的狀態,state變數至少有兩個值:0、1,對state變數的操作,使用CAS保證執行緒安全,
-
需要記錄當前是哪個執行緒持有鎖,
-
需要底層支持對一個執行緒進行阻塞或喚醒操作,
-
需要有一個佇列維護所有阻塞的執行緒,這個佇列也必須是執行緒安全的無鎖佇列,也需要使用CAS,
2.2.4 AQS
AbstractQueuedSynchronizer 的核心就是一個雙向鏈表形成的阻塞佇列以及CAS.
2.2.5 CAS
CAS 名為:compare and swap,是比較記憶體中的值是否和預期值一致,如果一致就進行更新,這個程序是原子的,cas 有三個運算元,記憶體值,預期值和新值,只有當記憶體值和預期值相等時,才會將記憶體值更新為新值,否則什么都不做,底層是通過unsafe 類保證原子性的,unsafe類中都是native 方法,可以直接操作記憶體,
缺點:存在ABA 問題,解決方案就是加版本號,或者加時間戳,
2.2.5 ReentrantLock 互斥鎖
Condition 本身也是一個介面,其功能和wait/notify類似,Condition 也必須和Lock一起使用,因此,在Lock的介面中,有一個與Condition相關的介面,
await() 是獲取鎖執行緒阻塞方法,signal() 是喚醒執行緒的方法,
2.3 執行緒池
執行緒池是一個典型的生產者消費者模型,執行緒池的核心是使用阻塞佇列,我們常用的就是 ThreadPoolExecutor,
2.3.1 ThreadPoolExecutor
ThreadPoolExecutor 主要是 包含一個阻塞佇列和一組執行緒集合 Workers,每個執行緒是一個worker 物件,worker 繼承了AQS ,
ThreadPoolExecutor 包含7 個引數,
corePoolSize:在執行緒池中始終維護的執行緒個數,核心執行緒數
maxPoolSize:在corePooSize已滿、佇列也滿的情況下,擴充執行緒至此值,最大執行緒數
keepAliveTime/TimeUnit:maxPoolSize 中的空閑執行緒,銷毀所需要的時間,總執行緒數收碩訓corePoolSize,存活時間和單位
blockingQueue:執行緒池所用的佇列型別,阻塞佇列
threadFactory:執行緒創建工廠
RejectedExecutionHandler:corePoolSize已滿,佇列已滿,maxPoolSize 已滿,最后的拒絕策略,
提交程序的核心流程:
1、先判讀當前執行緒數是否小于 corePoolSize ,如果小于就新建執行緒執行
2、如果大于,就判斷阻塞佇列是否已經滿了,如果沒有滿,就加入阻塞佇列中,
3、如果滿了,就判斷當前執行緒數是否小于 maxPoolSize ,如果小于,就直接創建執行緒執行,如果大于就根據拒絕策略,拒絕任務,
執行緒池的關閉:
在呼叫shutdown() 或者shutdownNow() 之后,執行緒池并不會立即關閉,會等待所有任務執行完成之后,才會關閉執行緒池,
shutdown() 不會清空任務佇列,并且只會中斷空閑執行緒,
shutdownNow() 會清空任務佇列,并且中斷所有的執行緒,
2.3.2 執行緒池拒絕策略
執行緒池有四種拒絕策略
1、丟棄任務,并拋出例外
2、丟棄任務,單不拋出例外
3、丟棄佇列最前面的任務,然后重新提交當前任務,
4、執行緒池什么都不做,由當前執行緒自己處理,
2.3.3 ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor實作了按時間調度來執行任務,有延遲任務和周期性任務,底層實作一個延遲佇列來實作的,
3. java 基礎
3.1 spring 啟動的流程(12步)
1、prepareRefresh(),重繪前預處理,主要是設定啟動時間,以及初始化組態檔中的占位符,以及校驗配置資訊是否正確,
2、obtainFreshBeanFactory(),獲取 Beanfactory,
3、prepareBeanFactory(beanFactory),Beanfactory 的準備作業,對BeanFactory 的一些屬性進行配置,比如 context 的類加載器
4、postProcessBeanFactory(),BeanFactory 準備作業完成后,進行的后置處理作業,是一個鉤子函式,
5、invokeBeanFactoryPostProcessors(beanFactory),實體化并調?實作了BeanFactoryPostProcessor接?的Bean
6、registerBeanPostProcessors(beanFactory),注冊BeanPostProcessor(Bean的后置處理器),在創建Bean的前后執行
7、initMessageSource(),初始化 MessageSource 組件,并將資訊加入allpication.singletonObjects 中,
8、initApplicationEventMulticaster(),初始化事件派發器,并加入到singletonObjects 中
9、onRefresh(),子類重寫這個方法,在容器重繪時可以自定義邏輯,
10、registerListeners(),注冊應用監聽器, 就是 注冊 ApplicationListener 介面監聽器 bean
11、finishBeanFactoryInitialization(),初始化所有沒有設定延時加載的Bean
12、finishRefresh(),完成context 的重繪,發布事件,
3.2 BeanFactory 創建流程
1、判斷是否已經存在BeanFactory,如果存在,就銷毀Bean 和BeanFactory,
2、創建 BeanFactory
3、為當前BeanFactory 設定序列化id
4、將bean 物件加載到 BeanFactory 物件的 beanDefinitionMap 中,
5、回傳 BeanFactory
3.3 Bean 創建流程
1、初始化所有剩下的?懶加載的單例bean
2、初始化創建?懶加載?式的單例Bean實體(未設定屬性)
3、填充屬性
4、初始化?法調?(?如調?afterPropertiesSet?法、init-method?法)
5、調?BeanPostProcessor(后置處理器)對實體bean進?后置處
3.4 Bean 生命周期(11步)
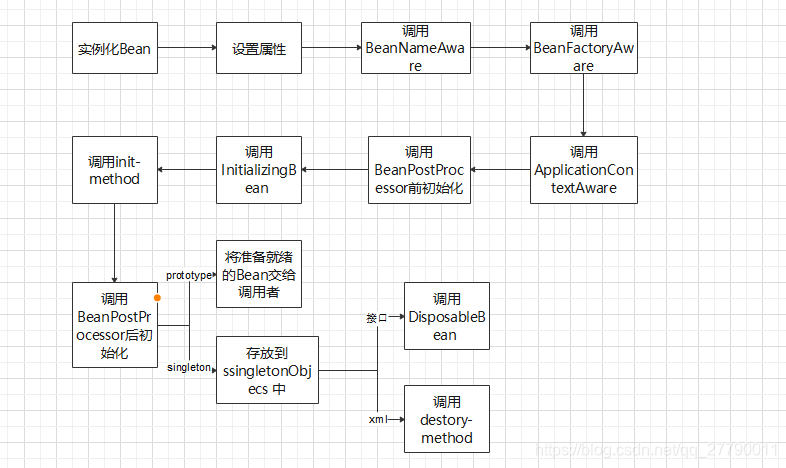
1、根據配置情況呼叫 Bean的構造方法或者工廠方法實體化Bean
2、利用依賴注入完成Bean的所以屬性值的配置注入
3、如果Bean 實作了BeanNameAware 介面,則spring 呼叫Bean的setBeanName() 傳入當前Bean的id
4、如果Bean實作了BeanFactoryAware 介面,呼叫setBeanFactory() 方法傳入當前工廠實體的參考
5、如果Bean 實作了ApplicationContextAware 介面,通過呼叫setApplicationContext 傳入當前applicationContext 實體的參考,
6、如果BeanPostProcessor 和Bean 關聯,則Spring 將呼叫改介面的預初始化方法,postProcessBeforeInitialization() 是前置處理的方法,Spring的AOP就是利用它實作的,
7、如果Bean 實作了InitializingBean 介面,需要實作afterPropertiesSet 方法
8、如果在組態檔中通過init-method 屬性指定了初始化方法,則的呼叫該方法,
9、如果BeanPostProcessor 和Bean 關聯,則Spring 將呼叫該介面的初始化方法postProcessAfterInitialization().此時Bean可以被應用系統使用,
10、如果在Bean標簽中指定了Bean的作用范圍的scope=“singleton” 則將改Bean 方法singletonObjects的快取池中
11、如果Bean 實作了DisposableBean 介面,則spring會呼叫destory() 方法 將Spring中的Bean銷毀,
3.5 Autowired 和Resource 注解的區別
1、autowired 是spring 提供的注解,@Resource是javaee 提供的注解,
2、Autowired 采用的是按型別注入,當一個類有多個Bean的時候需要配合@Qualifier 來指定唯一的Bean,而@Resource 默認安裝byName 自動注入,
3、@Resource 可以執行 name 和type .可以通過type 注入,也可以通過name 來注入,
3.6 回圈依賴
利用三級快取來解決回圈依賴的,
1、當創建物件A的Bean 的時候,會先將A物件Bean 放入三級快取,然后填充屬性;
2、發現依賴物件B ,但是物件B 還沒有創建,所以就創建物件B
3、物件B在創建程序中,發現依賴物件A,就先從一級快取中獲取,沒有獲取到就從二級快取中找,沒有找到就從三級快取中找,找到了還沒有創建完成的物件A .然后將物件A 進行一些處理移入二級快取中,
4、這樣物件B就可以繼續完成Bean 創建的其他步驟知道完全創建好,
5、B 物件的Bean 創建好之后,放入了一級快取SingLetonObject中,物件A可以繼續完成創建,最終創建好的A物件也會進入一級快取中,
3.7 事務的傳播行為(7中型別)
事務往往在service 層控制,如果在 service 層方法A呼叫另個 service 的方法 B ,A和B 本身都本身都添加了事務控制,那么在A呼叫B 的時候就需要進行事務的一些協商,這就是事務的傳播行為,
有如下7中型別:
A呼叫B,站在B的角度來定義傳播行為,
1、如果當前沒有事務,就新建事務;如果存在一個事物,就加入到當前事務中,這是最常見的一種型別,
2、支持當前事務,如果沒有事務,就以非事務執行,
3、支持當前事務,如果沒有事務,就拋出例外,
4、新建事務,如果當前存在事務,就將當前事務掛起,
5、以非事務運行,如果存在當前事務,就將當前事務掛起,
6、以非事務運行,如果存在當前事務,就拋出例外,
7、如果當前存在事務,就在嵌套事務內執行,如果當前沒有事務,就創建一個事物執行,
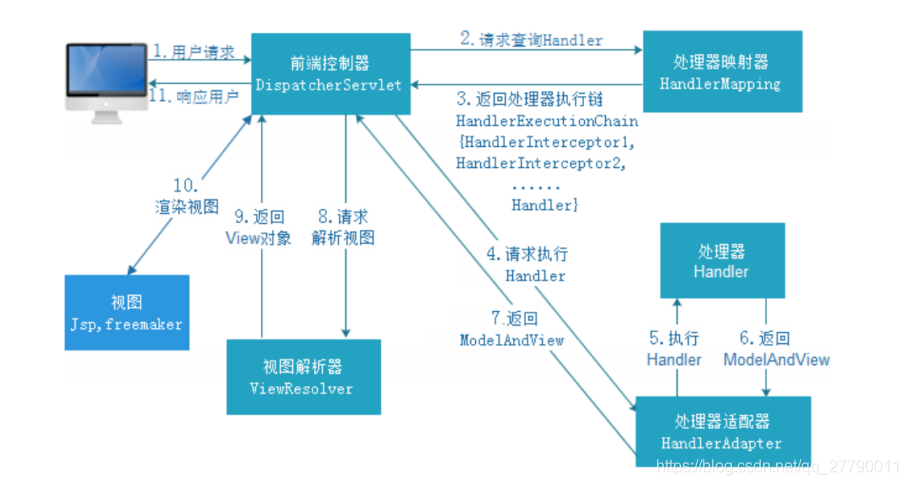
3.8 spring mvc 請求處理流程(10步)
1、DispatcherServlet 接收到客戶端發送的請求,
2、DispatcherServlet 收到請求呼叫HandlerMapping 處理器映射器,
3、HandleMapping 根據請求URL 找到對應的handler 以及處理器 攔截器,回傳給DispatcherServlet
4、DispatcherServlet 根據handler 呼叫HanderAdapter 處理器配接器,
5、HandlerAdapter 根據handler 執行處理器,也就是我們controller層寫的業務邏輯,并回傳一個ModeAndView
6、HandlerAdapter 回傳ModeAndView 給DispatcherServlet
7、DispatcherServlet 呼叫 ViewResolver 視圖決議器來 來決議ModeAndView
8、ViewResolve 決議ModeAndView 并回傳真正的view 給DispatcherServlet
9、DispatcherServlet 將得到的視圖進行渲染,填充到request域中
10、回傳給客戶端回應結果,
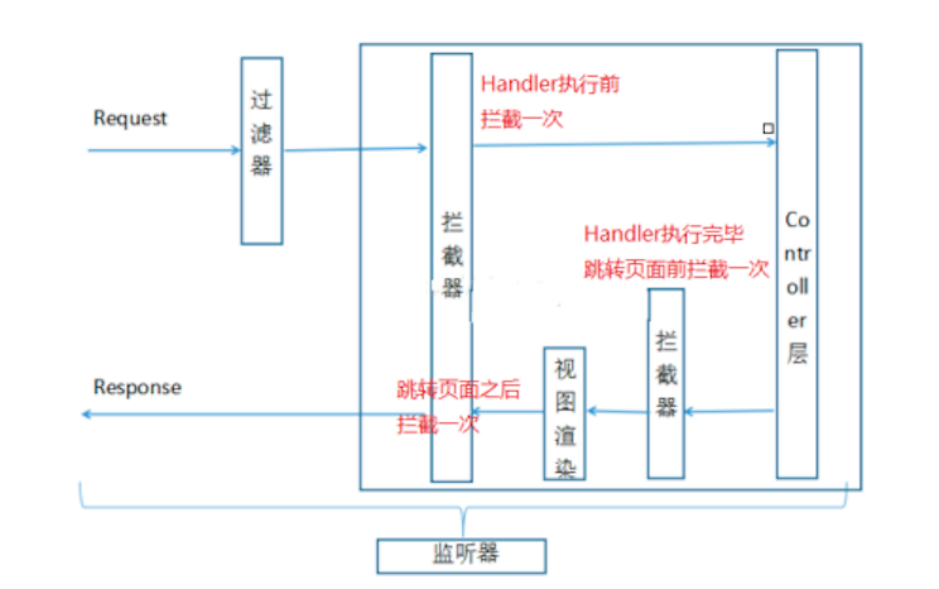
3.9 過濾器攔截器
-
過濾器(Filter):對Request請求起到過濾的作?,作?在Servlet之前,如果配置為/*可以對所有的資源訪問(servlet、js/css靜態資源等)進?過濾處理
-
攔截器(Interceptor):是SpringMVC、Struts 等表現層框架??的,不會攔截 jsp/html/css/image 的訪問等,只會攔截訪問的控制器?法(Handler),攔截器會作用三個地方:在 handler 執行之前執行一次,用來校驗引數合理性,handler 之后、視圖決議器之前執行一次,視圖決議之后執行一次,
3.10 springboot 啟動流程(9步)
1、加載并啟動監聽器
2、創建專案運行環境,并加載配置
3、創建 spring 容器,
4、運行spring 容器的前置處理,主要是容器重繪之前的準備作業,設定容器環境,并且將啟動類注入容器,為后面開啟自動化配置服務,
5、重繪是spring 容器,通過refresh() 方法對整個IOC 容器初始化,包含bean 資源點定位決議注冊等,
6、運行spring 容器后置處理器,擴展介面,如果有自定義需求,可以重寫該方法,
7、發布結束執行的事件,
8、執行自定義執行器,
9、回傳容器,
3.11. 說說 hashMap 的原理
在jdk 1.7 版本,hashmap 的資料結構是 陣列加鏈表
在jdk 1.8 版本,hashmap 的資料結構是陣列加鏈表叫紅黑樹,當陣列長度大于64 且鏈表長度大于8時,鏈表就會轉換成紅黑樹,
3.12. synchronized 和 ReentrantLock 的區別
1、synchronized 是 JVM 隱式實作的,而 ReentrantLock 是 Java 語言提供的 API;
2、ReentrantLock 可設定為公平鎖,而 synchronized 卻不行;
3、ReentrantLock 只能修飾代碼塊,而 synchronized 可以用于修飾方法、修飾代碼塊等;
4、ReentrantLock 需要手動加鎖和釋放鎖,如果忘記釋放鎖,則會造成資源被永久占用,而 synchronized 無需手動釋放鎖;
5、ReentrantLock 可以知道是否成功獲得了鎖,而 synchronized 卻不行,
4. jvm
4.1 jvm 記憶體模型
jvm 記憶體分為:程式計數器、虛擬機堆疊、本地方法堆疊、堆、方法區,
程式計數器:執行緒私有,是一塊較小的記憶體空間,它可以看做是當前執行緒所執行的位元組碼的行號指示器,
虛擬機堆疊:執行緒私有,用于存盤堆疊幀,每個方法在執行時都會創建一個堆疊幀(Stack Frame)**,**用于存盤區域變數表、運算元堆疊、動態鏈接、方法出口等資訊,每一個方法從呼叫直到執行完成的程序就對應著一個堆疊幀在虛擬機堆疊中從入堆疊到出堆疊的程序,
本地方法堆疊:執行緒私有,用于 虛擬機 Native 方法
堆:執行緒共享、保存物件實體,所有的物件實體都在堆上存盤,
方法區:執行緒共享,存盤被虛擬機加載的類資訊、常量、靜態變數等,
4.2 jvm 堆
4.2.1 堆記憶體分布
jvm 將堆記憶體分為 年輕代和年老代,年輕代和年老代的比例為1:2 ,年老代用來存盤存活時間比較長或者大物件,年輕代用來存盤錯過時間比較短的物件,年輕代中又分為Eden 區和兩個Survivor 區,比例為8:1:1,
4.2.2 物件分配程序
1、首先會將物件放入年輕代的 Eden 區,如果Eden 區能發下就放入,
2、如果 Eden 區放不下了,就會觸發 YangGC,會對Eden 區和使用的 Survivor 區進行垃圾回收,存活的物件保存到另一個空閑的Survivor 區,然后將新物件放入 Eden 區,
3、當Survivor 區有物件經歷 15 次 yangGC 后還存活,就遷移到年老代,15次是默認的,可以調整,
4、如果新增物件大小超過Eden 區 一半時,會直接加入年老區,如果年老區 能放下就放入,
5、如果年老區放不下,就會觸發OldGC,
6、如果OldGC 后,還是放不下物件,就會觸發FullGC
7、如果FullGC 還放不下,就會報OOM 例外,
4.3 方法區
方法區保存的內容:型別資訊、域資訊、方法資訊、運行時常量池,元空間用來存盤類的元資訊,存盤位置為本地記憶體,靜態變數和常量池存盤在堆中,
4.4 類加載的執行程序
類的生命周期:包含7個階段,有加載、驗證、準備、決議、初始化、使用和卸載,
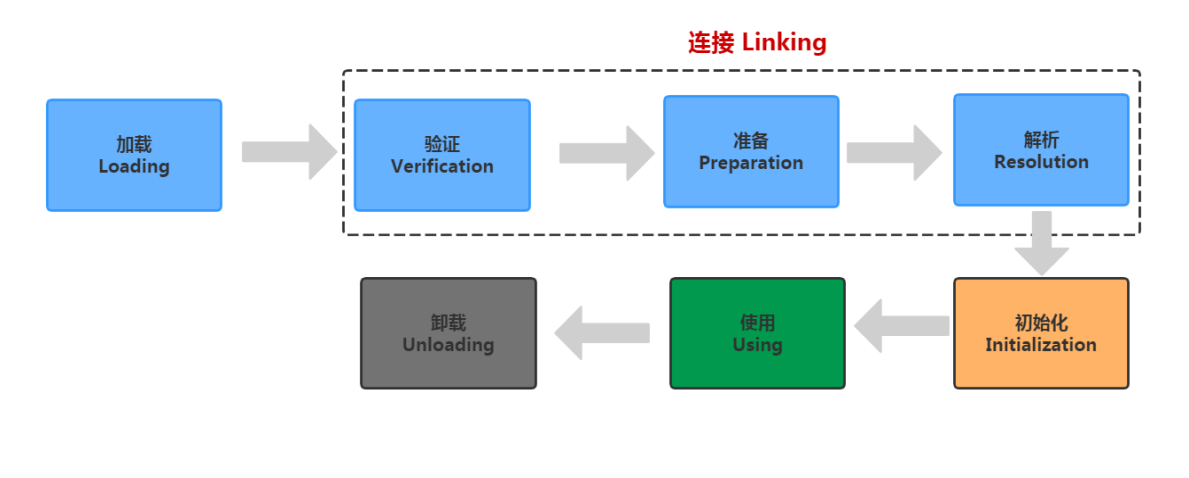
加載:分為預加載和運行時加載、預加載是在JVM啟動的時候就加載的class 檔案,加載的都是lib/rt.jar 下的 .class 檔案,運行時加載是指我們一般的class 檔案,只有在用到的時候會先去記憶體中查一下有沒有,沒有才會進行加載到記憶體中,主要獲取 .class 檔案的二進制流,類資訊、靜態變數、位元組碼、常量這些資訊會存入 方法區中,
連接分為驗證、準備和決議
驗證:保證 .class 檔案的位元組流中包含的資訊符合當前虛擬機的要求,并且不會危害虛擬機自身安全,
準備:為類的變數分配記憶體并設定其初始值,這里的初始值是 默認初始值,,比如"public static int value = 123",value在準備階段過后是0而不是123,給value賦值為123的動作將在初始化階段才進行;比如"public static final int value = 123;"就不一樣了,在準備階段,虛擬機就會給value賦值為123,
決議:是虛擬機將常量池內的符號參考替換為直接參考的程序,符號參考是一種定義,可以是任何字面上的含義,而直接參考就是直接指向目標的指標、相對偏移量,
初始化:類的初始化階段是類加載的最后一個程序,初始化階段就是執行類構造器方法的程序,為類變數進行初始化賦值,這里就是我們代碼中定義的值了,
4.5 雙親委派模型
如果一個類加載器收到類加載的請求,它首先不會自己嘗試加載這個類,而是把這個請求委派給自己的父類加載器完成,每個類加載器都是如此,只有當父類加載器在自己范圍內找不到指定類時,又會委派自己的子類進行加載,這就是雙親委派模型,這樣做的好處是:讓類加載盡量都交給父類加載,這樣就可以避免不同的子類都需要進行類加載,提升了效率,也更加安全,
4.6 判斷物件已死演算法
1、參考計數演算法,當該物件被應用了,計數器就+1,參考失效了,就-1,當計數器值為0 時表示沒有被使用,可以回收了,不能解決回圈參考的問題,
2、可達性分析演算法,從一系類的 GC root 的物件作為起點,向下搜索到物件的路勁,如果物件沒有和 GC root 物件不存在路勁,就會被標記需要清除,
GC root 物件有哪些?
1、堆疊幀中區域變數表的reference 參考所參考的物件,
2、方法區中 static 靜態參考的物件,
3、方法區中final 常量參考的物件,
4、所有被同步鎖持有的物件,
5、java 虛擬機內部的參考,如基本資料型別的物件、例外物件、系統類加載器等
finalize() 方法
如果物件進行可達性分析,發現物件沒有和 GCroot 相連接的參考鏈,會被第一次標記,隨后進行一次篩選,判斷是否有必要執行 finalize() 方法,
如果沒有多載finalize() 方法,或者虛擬機已經執行過了該物件的 finalize() 方法,則判定為沒有必要,直接等待回收,如果判定有必要執行 finalize() 方法,就會放入F-Queue 佇列中,隨后由低優先級的執行緒執行 finalize() 方法,在方法中,可以將當前物件和GCroot 物件建立參考鏈,擺脫被回收的命運,否則執行完 finalize() 依舊會被回收,
4.7 參考型別
java虛擬機有4中參考型別:
強參考:進行垃圾回收時,垃圾回收器不會對強參考的物件進行回收,
軟參考:只要記憶體足夠,垃圾回收器就就不會回收,只要當記憶體不足時才會對軟參考的物件進行回收,
弱參考:在垃圾回收器執行垃圾回收時,不管記憶體夠不夠,都會對弱參考的物件進行回收,
虛參考: 它是最弱的一種參考關系,如果一個物件僅持有虛參考,在任何時候都可能被垃圾回收器回收,虛參考主要用來跟蹤物件被垃圾回收器回收的活動,
4.8 垃圾回收演算法
4.8.1 分代收集理論
基于兩個假說:
1、大部分物件都是朝生熄滅的
2、存活時間越久的物件越難以消亡,
4.8.2 標記清除演算法
演算法分為“標記”和“清除”兩個階段: 首先標記出所有需要回 收的物件, 在標記完成后,統一回收掉所有被標記的物件, 也可以反過來, 標記存活的物件, 統一回收所有未被標記的物件
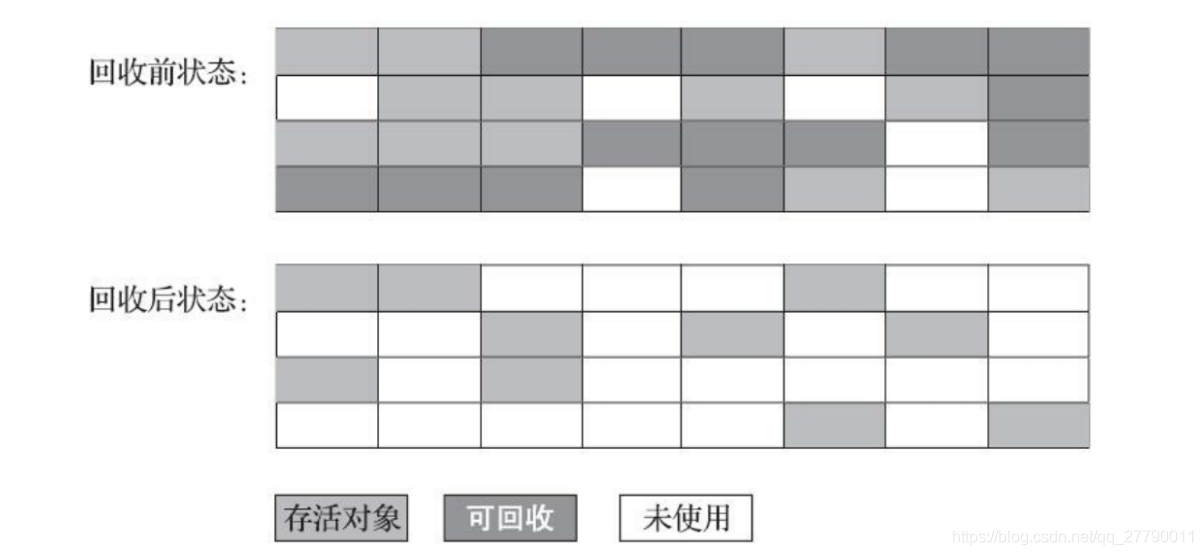
缺點:記憶體空間碎片化嚴重,
4.8.3 標記復制演算法
當這一塊的記憶體用完了, 就將還存活著 的物件復制到另外一塊上面, 然后再把已使用過的記憶體空間一次清理掉,
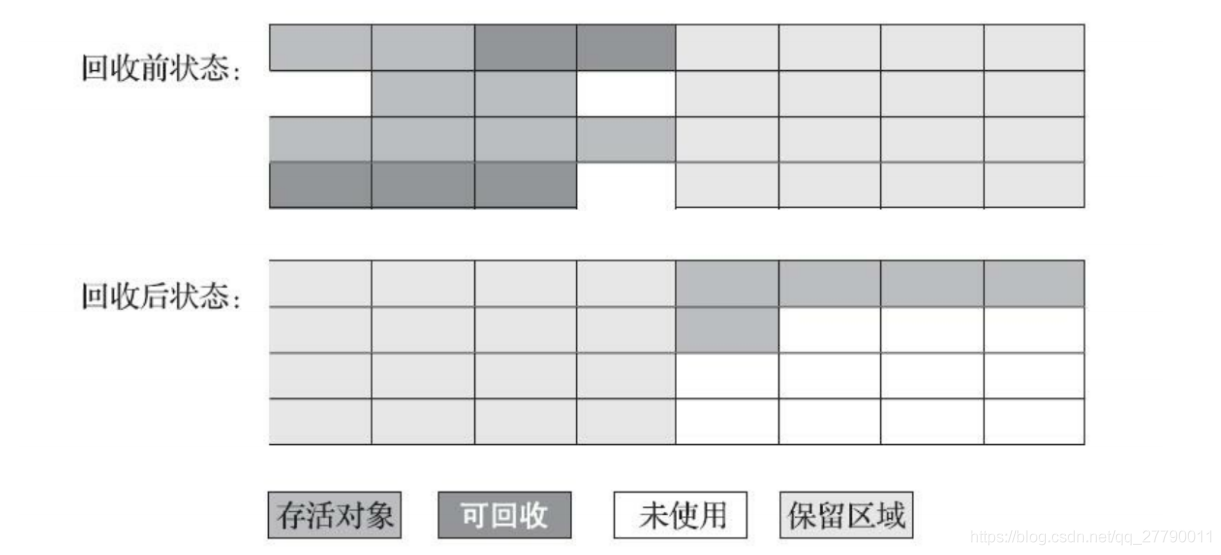
缺點:每次有一半的記憶體空閑,利用率不高,如果99%的物件都是存活的(老年代),那么老年代是無法使用這種演算法的,
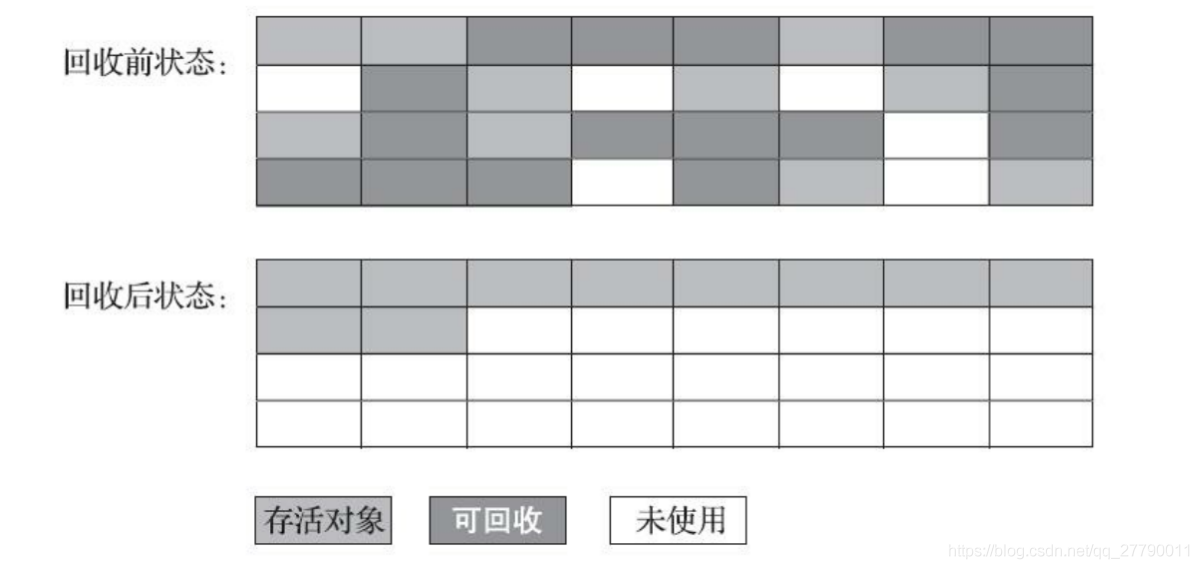
4.8.4 標記整理演算法
的“標記-整 理”(Mark-Compact) 演算法, 其中的標記程序仍然與“標記-清除”演算法一樣, 但后續步驟不是直接對可回收物件進行清理, 而是讓所有存活的物件都向記憶體空間一端移動, 然后直接清理掉邊界以外的記憶體 ,
4.9 垃圾收集器
4.9.1 CMS 收集器
CMS 收集器分為4個步驟:
1、初始標記: 這個階段會stop-the-world ,主要是來標記 GC roots 能夠直接關聯到的物件,標記之后恢復暫停的所有應用,操作速度是比較快的,
2、并發標記:這個階段是GC roots 直接關聯到的物件開始遍歷標記整個物件圖的程序,耗時較長,但不用暫停用戶執行緒,可以并發執行,
3、重新標記:為了修正并發標記階段用戶執行緒運行導致標記發生變動,從而進行重新標記,也會stop-the-world ,耗時比初始標記會長一點,
4、并發清理:清理哪些被標記為死亡的物件,并釋放記憶體空間,采用標記清除演算法,不用移動存活物件,可以并發執行,
4.9.2 G1 收集器
G1 收集器特點:
1、G1 把堆記憶體分為多個獨立的 region 區域,
2、G1 沿用了分代思想,保留了年輕代、年老代,但他們不再物理隔離,都通過Region 存盤,
3、G1 采用標記整理演算法,區域采用標記復制演算法,不會產生記憶體碎片化,
4、G1 能充分利用多CPU 、多核硬體環境,盡量縮短STW
程序:
初始標記:和CMS 初始標記階段一樣,標記 GC roots 能夠直接關聯到的物件,會STW
并發標記:和CMS 并發標記階段一樣,GC roots 直接關聯的物件整個物件樹進行標記,
最終標記:修正并發標記階段,因程式運行產生變化的那部分物件,
篩選回收:根據時間來進行價值最大化收集,
4.9.3 ZGC 收集器
ZGC 是java 11 版本中提供的高效垃圾回收演算法,有以下特點:
1、使用了著色指標技術,利用指標額外資訊位,在指標上對物件進行著色標記,
2、使用了讀屏障,使得進行垃圾回收大部分時間都不需要STW,因此大部分時間都是并發處理的,
3、基于Region ,沒有進行分代,也滅有固定Region 的大小,Region 是可以動態創建和銷毀的,對大物件可以更好的管理,
4、壓縮整理,在回收后會對 Region 物件進行移動合并,解決碎片化問題,
程序:
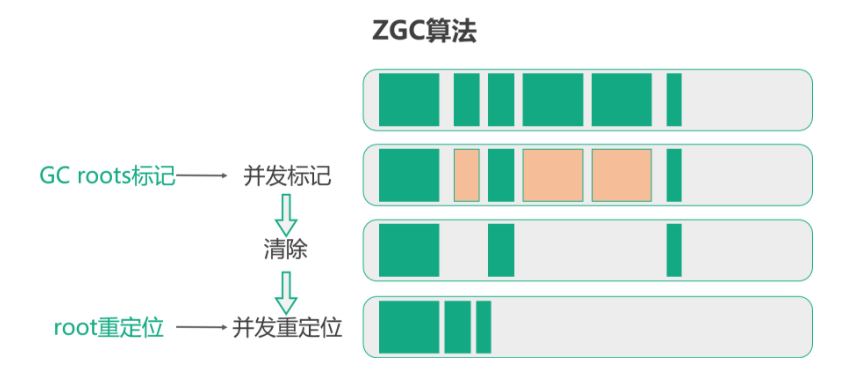
1、初始標記:在開始的時候會有短暫的 STW ,用戶標記 GC Roots,
2、并發標記:這個階段通過物件指標著色來標記,結合讀屏障解決單個物件的并發問題,在最后會有一個短暫的STW 來解決邊緣情況,
3、清理階段:這個階段會對不再使用的物件進行回收,
4、并發重定位:就是對存活的物件進行移動,來解決碎片化的問題,也是利用讀屏障和用戶執行緒并發處理的,
5. 設計模式
5.1 單例模式
保證一個類僅有一個實體,并提供一個訪問它的方法,包含一個靜態變數,一個私有的構造方法,一個 public 的靜態方法,
餓漢式、懶漢式、雙重校驗鎖,
public class SingLeton{
private volalite static SingLeton sing;
private SingLeton(){
}
public static SingLeton getSingLeton(){
if(sing==null){
synchronized(SingLeton.class){
if(sing==null){
sing=new SingLeton();
}
}
}
return sing;
}
}
靜態內部類,
public class SingLeton{
private static class SingLetonInner{
public static final SingLeton sing=new SingLeton();
}
private SingLeton(){}
public static SingLeton getInstance(){
return SingLetonInner.sing;
}
}
5.2 工廠模式
工廠模式就是通過工廠來創建想要的物件,而不是自己去創建物件,這樣降低了代碼間的耦合度,比如一個服飾工廠可以生產衣服,褲子,鞋子,襪子,帽子等等,我們想要用衣服,不用自己來造了,而是和工廠說你想要什么,那工廠就給你生產什么,這就是工廠模式,主要是將創建物件的實體交給工廠類來完成,并進行管理,
工廠分為簡單工廠模式、工廠方法模式和抽象工廠模式,
簡單工廠模式:是工廠模式最簡單的一種,實體有工廠直接創建,也就是上面的例子中,你想要衣服,那這個服飾工廠就給你做一件衣服給你,
工廠方法模式 :就是工廠本身不進行物體物件的創建,而是通過對應的下游工廠來創建然后在回傳,有點總工廠子工廠的意思,總工廠管理著所有的子工廠,每個子工廠只生產指定的商品,當通知總部想要什么東西時,總部就通知對應的子工廠生產,拿到產品后再回傳客戶,
抽象工廠:就是一個抽象工廠類,里面只是宣告可以實作哪些物件,但是具體的實作就交給具體的工廠完成,抽象工廠就好比包皮公司,它告訴你他可生產服飾,也就可以生產食品,那比如你想要衣服,它就給你一個服飾工廠的聯系方式,你通過這個服飾工廠來獲取到衣服,想要辣條,那他就給你推一個食品公司的聯系方式,讓這個食品公司給你做,
工廠方法模式和抽象工廠模式的區別:在于工廠方法模式主要是生產某一類商品,而抽象工廠,我不關心你怎么實作,只要你說你能做這個商品,我就可以為你代言,
5.3 構建者模式
將構建一個復雜的物件可以進行拆分成構建一個個簡單的物件,然后組裝成復雜的物件,就是構建者模式,比如mybatis 中為了構建Configuration 這個復雜物件,就先構建了Dadasource、MapperStment、等很多的物件組成,在決議SqlMapConfig組態檔的時候,就會先將各種組態檔封裝到對應的物件中,最后組裝成 Configuration 物件
5.4 代理模式
代理模式就是我們想要執行的方法通過代理物件來完成,就好比我們要搶票回家,我們不想自己盯著搶,所以就找代理幫我們搶從而達到目的,代理模式分為靜態代理和動態代理,
靜態代理:就是具體的代理類,在編譯階段就知道這個代理能做什么事情,就好比搶票的代理一樣,它只能做搶票這個代理,而不能代你搶錢哈哈,
動態代理:動態代理就不同了,它在編譯階段也沒有具體的實作,而是在程式運行期間根據JVM的反射機制動態生成的,比較出名的就JDK 動態代理 和cglib 動態代理,
JDK 動態代理:主要實作InvocationHandle 介面并實作其 invoke 方法,
Proxy.newProxyInstance(obj.getClass().getClassLoader(), obj.getClass().getInterfaces(),
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = null;
// 前置增強
....
// 呼叫原有業務邏輯
result = method.invoke(obj,args);
//后置增強
...
return result;
}
})
cglib 動態代理:需要引入其依賴,使用方法和JDK動態代理差不多,實作MethodInterceptor 介面并實作 intercept 方法,
public Object getCglibProxy(Object obj) {
return Enhancer.create(obj.getClass(), new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
Object result = null;
//前置增強
...
result = method.invoke(obj,objects);
//后置增強
...
return result;
}
});
}
JDK 動態代理是java 語言自帶的功能,提供了穩定的支持,是通過攔截器和反射實作的,jdk 動態代理只能代理繼承介面的類,
cglib 動態代理是第三方提供的工具,基于ASM 實作的,性能比較高,cglib 動態代理無需通過介面實作,它是通過實作子類的方式來完成呼叫的,
5.5 配接器模式
6. 資料結構和演算法
6.1 資料結構
常見的資料結構如下:
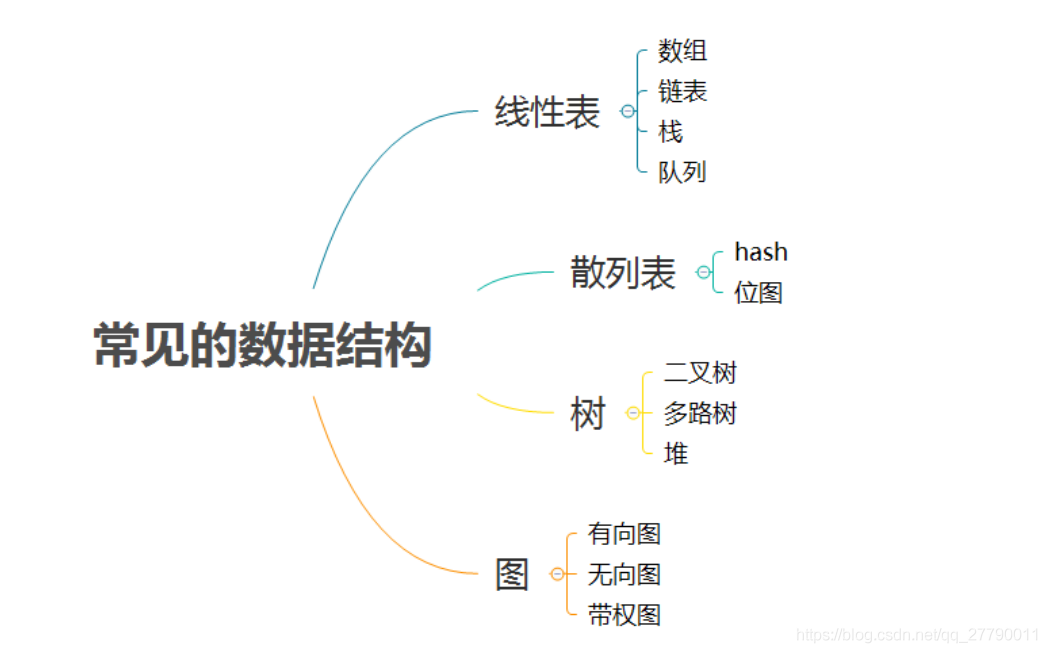
6.1.1 線性表
6.1.1.1陣列
有限個相同型別的變陣列成的集合,物理地址連續(連續的記憶體空間存盤),
洗掉和插入元素的時候,后續的元素需要進行位移,
擴容陣列的時候,需要先創建一個新資料,然后將原陣列的值填充到新陣列中,
優點:具有高效的隨機訪問能力,只需要給出下標,就可以常量時間找到對應元素,
缺點:插入和洗掉,會導致其他元素發生位移,影響效率,
6.1.1.2鏈表
鏈表是物理上不連續的節點組成,每個節點包含兩部分,存盤資料元素以及指向下個節點的指標,
常見的鏈表有:單鏈表,雙鏈表,回圈鏈表,
優點:插入,洗掉、更新的效率高,
缺點:查詢的效率低,不能隨機訪問,在查詢節點的時候,只能從頭結點開始一個個的往后找,
6.1.1.3 堆疊
堆疊是一種線性結構,堆疊中的元素只能先入后出,最早進入的元素為堆疊底,最后進入的元素叫堆疊頂,
堆疊可以用陣列實作也可以用鏈表實作,
6.1.1.4 佇列
佇列也是一種線性結構,只能先入先出,佇列的出口端叫做隊頭,佇列的入口端加做隊尾,
佇列可以用陣列實作也可以用鏈表實作,
6.1.2 散串列
散串列也是 hash 表,這種資料結構提供了key 和value 的映射關系,只要給出 key ,就可以高效的查詢出它所匹配的 value ,
6.1.3 樹
樹又分為二叉樹和多叉樹,

6.1.3.1 二叉樹
二叉樹每個節點最多只有兩個子節點,
6.1.3.2 滿二叉樹
一個二叉樹所有的非葉子節點都存在左右子節點,且所有的葉子節點都在同一層,就是滿二叉樹,
6.1.3.3 完全二叉樹
如果二叉樹的深度為k,k-1 層為滿二叉樹,第k 層,所有節點都連續集中在最左邊,則是一顆完全二叉樹,
6.1.3.4 平衡二叉樹
左子樹和右子樹的深度差的絕對值不超過1,并且左子樹和右子樹也為平衡二叉樹,
6.1.3.5 二叉查找樹
在二叉樹的基礎上,如果有左節點,左節點的的值都小于根節點,如果有右節點,右節點的值都大于根節點,二叉查找樹又叫二叉排序樹,
6.1.3.6 紅黑樹
一種自平衡的二叉查找樹,有以下特征:
1、每個節點不是紅色節點就是黑色節點,
2、根節點是黑色,
3、每個葉子節點都是黑色的空節點,
4、如果一個節點是紅色的,那么它的子節點必須為黑色,
5、每個節點到各個葉子節點的包含相同數量的黑節點,
6、新加入的節點為紅色,然后校驗是否滿足紅黑樹的規則,,如果不滿足則需要進行顏色翻轉、左旋、右旋等操作,
6.1.3.7 B 樹
B 樹為一種多叉樹,一顆 M 階的B 樹 特征如下:
1、樹的每個節點至多有M 個子節點,
2、根節點至少有兩個子節點,
3、除根節點外,其他非葉子節點至少有 m/2 個子節點,
4、所有葉子節點都在同一層,
6.1.3.8 B+ 樹
B+ 樹是B樹的變種,如下特征:
1、多路平衡樹
2、只有葉子節點保存資料
3、搜索時 也相當于二分查找
4、增加了相鄰葉子節點指標
6.2 演算法
常見的演算法如下:
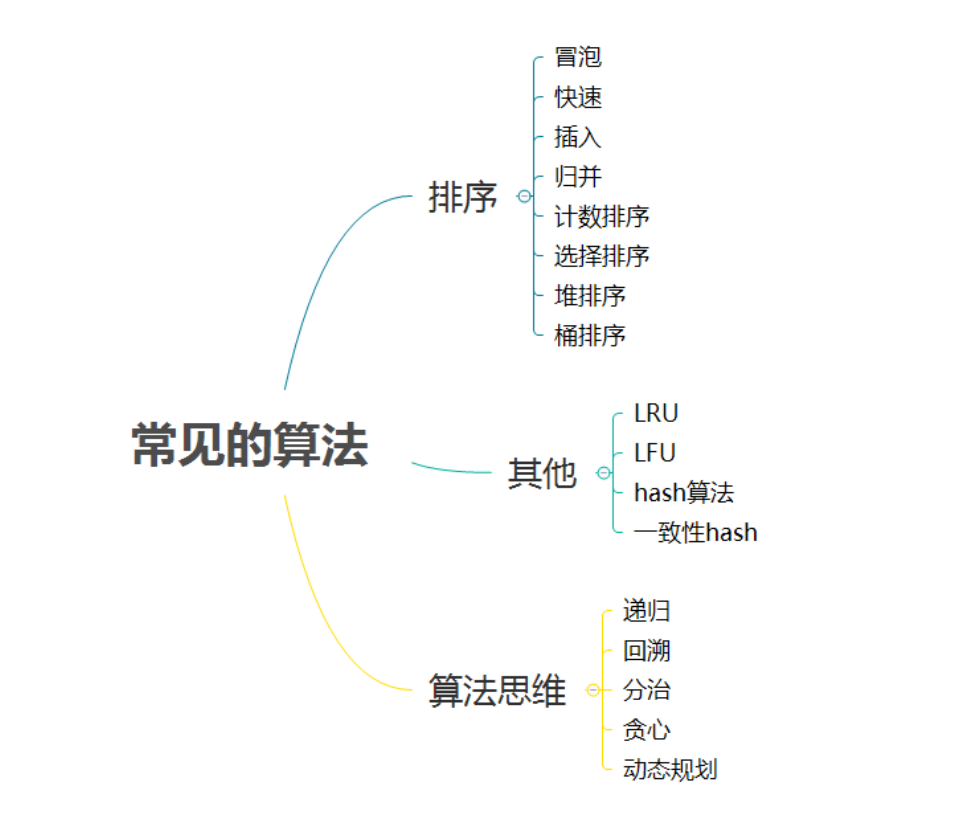
6.2.1 排序
6.2.1.1 冒泡
相鄰的兩個元素比較,左邊大于右邊則進行交換,時間復雜度O(n^2),是穩定排序
6.2.1.2 快排
快速排序也屬于交換排序,通過元素之間的比較和交換位置來達到排序的目的,每次選擇一個基準元素,將比基準元素大的元素放到右邊,比基準小的元素放到左邊,然后分別對左右進行快排,是不穩定的排序
6.2.1.3 堆排序
堆排序(Heapsort)是指利用堆這種資料結構所設計的一種排序演算法,是不穩定的排序,
7. 訊息佇列
主流的訊息佇列有RabbitMQ、kafka、RocketMQ,三者各有優劣,RocketMQ 支撐高并發高可用的,
7.1 訊息佇列的使用場景
比如 創建訂單減少庫存、以及秒殺場景就可以使用訊息佇列,訊息佇列的使用,主要有三大優點:降低耦合、流量削峰填谷、異步,在一些不需要同步處理的場景,可以先把請求保存到訊息佇列中,直接回傳結果給前端,提升回應速度,后續再進行訊息的處理,如我們感知專案中,對沒有介面日志都要進行日志入庫的操作,我們之前是回傳結果之前,將請求資訊寫入日志檔案,后臺執行緒定期執行入庫,這樣做將業務和日志入庫進行了強耦合,進行了磁盤io ,介面的整體回應效率受到影響,后面引入 RocketMQ,介面再回應之前,向RocketMQ 中發送一條請求的訊息后就回傳給前端了,然后單獨啟用一個日志入庫的服務消費RocketMQ 中的日志訊息,進行日志入庫,
7.2 RocketMQ 的角色
-
Producer:訊息的發送者;Producer與 NameServer 集群中的其中一個節點(隨機選擇)建立長連接,定期從 NameServer 獲取 Topic 路由資訊,并向提供Topic 服務的Master建立長連接,且定時向Master發送心跳,Producer完全無狀態,可集群部署,
-
Consumer:訊息接收者;Consumer與NameServer集群中的其中一個節點(隨機選擇)建立長連接,定期從NameServer獲取Topic路由資訊,并向提供Topic服務的Master、Slave建立長連接,且定時向Master、Slave發送心跳,Consumer既可以從Master訂閱訊息,也可以從Slave訂閱訊息,消費者在向Master拉取訊息時,Master服務器會根據拉取偏移量與最大偏移量的距離(判斷是否讀老訊息,產生讀I/O),以及從服務器是否可讀等因素建議下一次是從Master還 是Slave拉取,
-
Broker:暫存和傳輸訊息;Broker分為Master與Slave,一個Master可以對應多個Slave,Master與Slave 的對應關系通過指定相同的BrokerName,不
同的BrokerId來定義,BrokerId為0表示Master,非0表示Slave,Master也可以部署多個,每個Broker與NameServer集群中的所有節點建立長連接,定時注冊Topic資訊到所有NameServer, 注意:當前RocketMQ版本在部署架構上支持一Master多Slave,但只有BrokerId=1的從服務器才會參與訊息的讀負載,
-
NameServer:管理Broker;是一個幾乎無狀態節點,可集群部署,節點之間無任何資訊同步,
-
Topic:區分訊息的種類;一個發送者可以發送訊息給一個或者多個Topic;一個訊息的接收者可以訂閱一個或者多個Topic訊息
-
Message Queue:相當于是Topic的磁區;用于并行發送和接收訊息
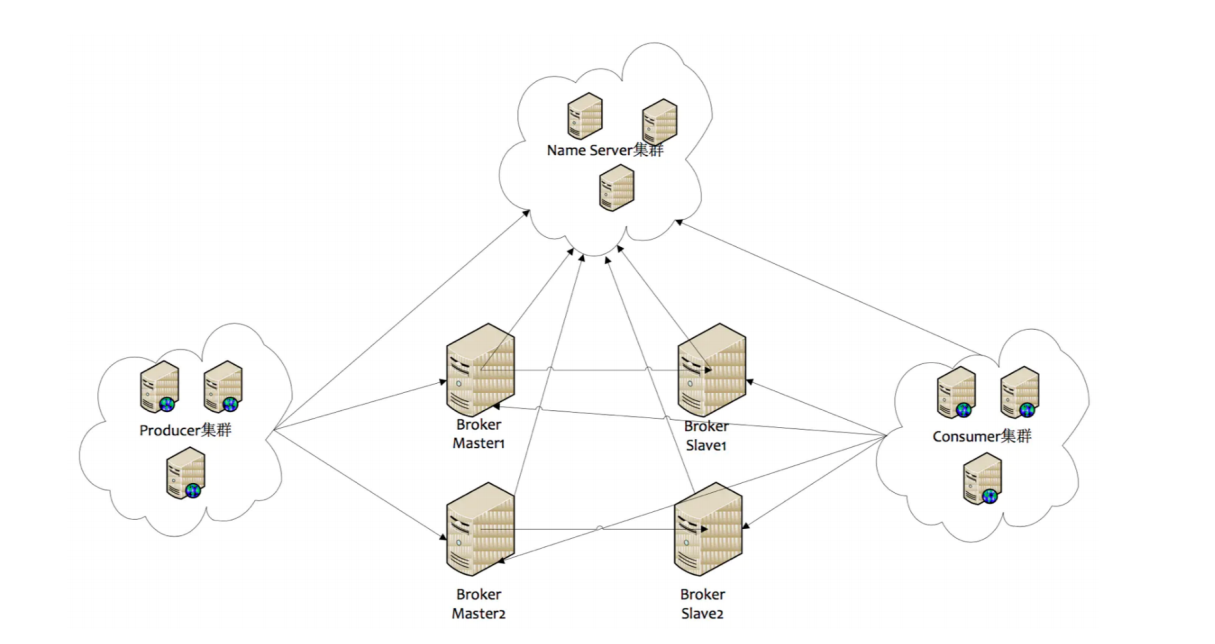
7.3 RocketMQ 的執行流程
1、啟動 NameServer,NameServer 起來后監聽埠,等待 Broker、Producer、Consumer 連上來,相當于一個路由控制中心,
2、Broker 啟動,跟所有的 NameServer 保持長連接,定時發送心跳包,心跳包中包含當前 Broker 資訊(IP+埠等)以及存盤所有 Topic 資訊,注冊成功后,NameServer 集群中就有 Topic 跟 Broker 的映射關系,
3、收發訊息前,先創建 Topic,創建 Topic 時需要指定該 Topic 要存盤在哪些 Broker上,也可以在發送訊息時自動創建 Topic,
4、Producer 發送訊息,啟動時先跟 NameServer 集群中的其中一臺建立長連接,并從 NameServer 中獲取當前發送的 Topic 存在哪些 Broker上,輪詢從佇列串列中選擇一個佇列,然后與佇列所在的 Broker 建立長連接從而向 Broker 發訊息,
5、Consumer 跟 Producer 類似,跟其中一臺 NameServer 建立長連接,獲取當前訂閱 Topic 存在哪些 Broker 上,然后直接跟 Broker 建立連接通道,開始消費訊息
7.4 RocketMQ 訊息過濾
RocketMQ 的訊息過濾主要是在 consumer 端訂閱訊息時再做訊息過濾的,主要基于 Tag 進行過濾,consumer 在訂閱訊息時,除了指定 topic 還可以指定 tag ,根據 tag 來過濾訊息,
7.5 零拷貝
所謂的零拷貝就是資料在專案的虛擬記憶體和服務器的物理記憶體之間沒有發生資料拷貝,正常的資料和磁盤的互動流程是,資料首先在專案的虛擬記憶體中,然后拷貝到物理記憶體,最后拷貝到磁盤上,讀取的話先從磁盤到物理記憶體,再到專案的虛擬記憶體,使用零拷貝技術可以減少拷貝的次數,記憶體中不發生資料拷貝,提升資料傳輸效率,
7.6 同步復制異步復制
如果一個broker 組中存在master 和slave .訊息需要從 master 同步到 slave.有同步復制和異步復制兩種方式,
同步復制:是等 master 和 slave 都寫入成功后才回傳客戶端寫成功狀態,
異步復制:只等 master 寫入成功就回傳,
Master 角色的broker 支持讀和寫,slave 角色的broker 僅支持讀,consumer 可以連接master 或者slave 進行訊息的讀取,
7.7 刷盤機制
RocketMQ 的所有訊息都是持久化的,訊息會先寫入物理記憶體,然后刷盤保存到磁盤上,刷盤有同步刷盤和異步刷盤
同步刷盤:同步刷盤等待訊息保存到了磁盤后才回傳,
異步刷盤:訊息保存到了物理記憶體就回傳了,
7.8 延時訊息
延時訊息是指訊息發送到 broker 后,不會立即被消費,而是等待特定的時間投遞給真正的topic .一共有18個等級,可以通過messageDelayLevel 配置,最久延時2小時,
7.9 事務訊息
RocketMQ 采用的是兩階段提交的方式實作事務訊息,
流程如下:
1、發送方向RocketMQ發送“待確認”訊息,
2、RocketMQ將收到的“待確認”訊息持久化成功后,向發送方回復訊息已經發送成功,此時第一階段訊息發送完成,
3、發送方開始執行本地事件邏輯,
4、發送方根據本地事件執行結果向 RocketMQ 發送二次確認(Commit或是Rollback)訊息,RocketMQ收到Commit狀態則將第一階段訊息標記為可投遞,訂閱方將能夠收到該訊息;收到 Rollback 狀態則洗掉第一階段的訊息,訂閱方接收不到該訊息,
7.10 順序訊息
實作順序訊息的話,只需要生產者只往一個佇列中發送訊息,并且發送模式調整為同步發送,這樣就可以保證消費中從這個佇列中消費的訊息都是有序的,
8. mysql
8.1 mysql 體系架構
mysql server 架構分為:網路連接層、服務層、存盤引擎層、和系統檔案層,
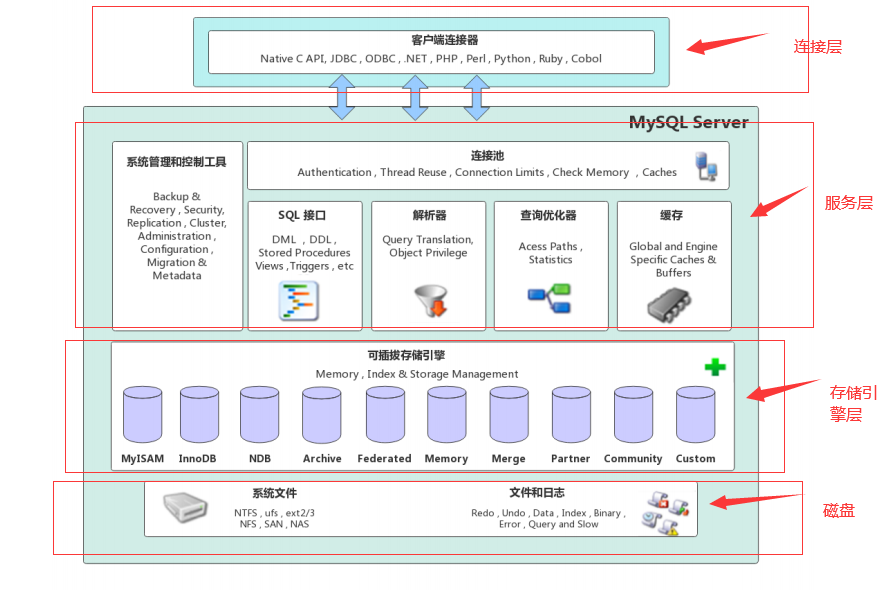
網路連接層:客戶端連接器提供與 mysql 服務端連接的支持,java、c、typhon 通過各自的 api 與 mysql 進行連接,
服務層:系統管理和控制工具、連接池、SQL 介面、決議器、查詢優化器、快取,
8.2 mysql 運行機制
1、建立連接,mysql 客戶端和服務端通信方式為半雙工,也就是某一時刻,只能接受資料或者發送資料,
2、查詢快取,先在快取中查詢是否有完全一致的 sql ,如果存在就直接將結果回傳,
3、決議器決議,決議器將 sql 進行語法決議,檢測語法是否正確,
4、查詢優化器根據決議樹生成最優的執行計劃,
5、查詢存盤引擎執行計劃回傳結果,
8.3 mysql 存盤引擎InnoDB
InnoDB 支持事務、有行鎖,支持多種索引,主要分為記憶體結構和磁盤結構兩大部分,
8.3.1 記憶體結構
記憶體結構包含:buffer pool 、change buffer、log buffer、Adaptive Hash index 四部分,
1、buffer pool(緩沖池),以page 為基本單位,在InnoDB 訪問表和索引時會在 Page 頁中快取,從而下次查詢的時候從 緩沖池中查找,從而減少 磁盤的IO ,提升效率,
2、change buffer(寫快取),主要在進行增刪改的操作是,如果 buffer pool 中沒有對應的 Page 資料,并不會立刻從磁盤頁中加載資料到快取池,而是先在 change buffer 中記錄下來,等下次資料讀取時,再將資料合并到buffer pool 中,減少IO ,提升效率,
3、Adaptive Hash Index (自適應哈希索引),用戶優化對快取池的查詢,
4、Log buffer(日志緩沖區),用來保存要寫入磁盤的 undo/redo 資料 ,
8.4 mysql 索引
mysql 索引可以提升查詢效率,有如下索引型別
從應用層次劃分:普通索引、唯一索引、主鍵索引、復合索引
從資料存盤和索引鍵值邏輯關系劃分:聚集索引(聚簇索引)、非聚集索引(非聚簇索引)
8.4.1 普通索引
最普通的索引型別,基于普通欄位簡歷的索引,沒有任何限制,
8.4.2 唯一索引
和普通所以的區別,索引欄位的值必須唯一,但是可以為空值,
8.4.3 主鍵索引
它是一種特殊的索引,不允許有空值,且欄位值必須唯一,一張表只能有一個主鍵,也只能有一個主鍵索引,
8.4.4 復合索引
復合索引是對表的多個欄位創建的聯合索引,
如果表已經建立了(col1,col2),就沒有必要再單獨建立(col1);如果現在有(col1)索引,如果查詢需要col1和col2條件,可以建立(col1,col2)復合索引,對于查詢有一定提高,
8.4.5 聚集索引
B+樹葉子節點存放的索引值和行記錄就屬性聚集索引,如果葉子節點只存盤了索引值和主鍵 那就是非聚集索引,
簡單說不需要回表查詢的就是聚集索引,需要回表查詢的就是非聚集索引,主鍵索引就是聚集索引,
8.4.6 索引原理
Mysql 索引采用的是B+ 樹的資料結構,
1、非葉子節點不存盤資料,值存盤索引值,
2、葉子節點包含在同一層,包含所有的索引值和資料,
3、相鄰的葉子節點通過指標連接,提高區間訪問性能,
8.4.7 like 查詢
MySQL 在使用 Like 模糊查詢時,索引是可以被使用的,只有把%字符寫在后面才會使用到索引,
8.4.8 explain 有哪些欄位
1、select_type 表示查詢型別,常用值有SIMPLE
2、type 表示存盤引擎查詢資料時采用的方式,ALL 全表查詢、index 基于索引的全表掃描、range 范圍查詢、ref 索引查詢,
3、possible_keys 表示查詢時能夠使用到的索引,
4、key:表示查詢時真正使用到的索引,顯示的是索引名稱,
8.4.9 慢查詢優化
先分析慢查詢的原因:
1、全表掃描
2、全索引掃描
3、索引過濾性不好
4、頻繁的回表查查詢
如果沒有使用索引就創建所以,如果索引效率不高,就優化索引,最好使用覆寫索引,避免回表查詢,
8.5 mysql 鎖
8.5.1 鎖分類
在 MySQL中鎖有很多不同的分類
-
從操作的粒度可分為表級鎖、行級鎖和頁級鎖,
- 表級鎖:每次操作鎖住整張表,鎖定粒度大,發生鎖沖突的概率最高,并發度最低,應用在MyISAM、InnoDB、BDB 等存盤引擎中,
- 行級鎖:每次操作鎖住一行資料,鎖定粒度最小,發生鎖沖突的概率最低,并發度最高,應用在InnoDB 存盤引擎中,
- 頁級鎖:每次鎖定相鄰的一組記錄,鎖定粒度界于表鎖和行鎖之間,開銷和加鎖時間界于表鎖和行鎖之間,并發度一般,應用在BDB 存盤引擎中,
-
從操作的型別可分為讀鎖和寫鎖
- 讀鎖(S鎖):共享鎖,針對同一份資料,多個讀操作可以同時進行而不會互相影響,
- 寫鎖(X鎖):排他鎖,當前寫操作沒有完成前,它會阻斷其他寫鎖和讀鎖,
-
從操作的性能可分為樂觀鎖和悲觀鎖,
- 樂觀鎖:一般的實作方式是對記錄資料版本進行比對,在資料更新提交的時候才會進行沖突檢測,如果發現沖突了,則提示錯誤資訊,
- 悲觀鎖:在對一條資料修改的時候,為了避免同時被其他人修改,在修改資料之前先鎖定,再修改的控制方式,共享鎖和排他鎖是悲觀鎖的不同實作,但都屬于悲觀鎖范疇,
8.5.2 悲觀鎖
悲觀鎖(Pessimistic Locking),是指在資料處理程序,將資料處于鎖定狀態,一般使用資料庫的鎖機制實作,從廣義上來講,前面提到的行鎖、表鎖、讀鎖、寫鎖、共享鎖、排他鎖等,這些都屬于悲觀鎖范疇,
表鎖:表級讀鎖會阻塞寫操作,但是不會阻塞讀操作,而寫鎖則會把讀和寫操作都阻塞,
共享鎖:是行鎖-讀鎖,事務使用了共享鎖(讀鎖),只能讀取,不能修改,修改操作被阻塞,
排它鎖:是行鎖-寫鎖,事務使用了排他鎖(寫鎖),當前事務可以讀取和修改,其他事務不能修改,也不能獲取記錄
8.5.3 樂觀鎖
樂觀鎖是相對于悲觀鎖而言的,它不是資料庫提供的功能,需要開發者自己去實作,在資料庫操作時,想法很樂觀,認為這次的操作不會導致沖突,因此在資料庫操作時并不做任何的特殊處理,即不加鎖,而是在進行事務提交時再去判斷是否有沖突了,
樂觀鎖實作的關鍵點:沖突的檢測,
悲觀鎖和樂觀鎖都可以解決事務寫寫并發,在應用中可以根據并發處理能力選擇區分,比如對并發率要求高的選擇樂觀鎖;對于并發率要求低的可以選擇悲觀鎖,
實作方式:添加版本和時間戳
8.5.4 死鎖
死鎖產生的四個必要條件:
互斥條件:一個資源同一時刻只能被一個行程占用,
不可剝奪:一個資源除非被占用的行程主動釋放,否則不能被剝奪
請求保持:一個進行請求資源時,沒有獲取到則保持請求,直到獲取資源
回圈等待:行程a 等待行程b 持有的資源,行程b 等待行程a 持有的資源
破壞其中一個條件就可以避免死鎖,
8.6 mysql 事務
8.6.1 事務特性
mysql 事務有4個特性,即所謂的 ACID:原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)和持久性(Durability),
原子性:事務是一個原子操作單元,對資料的修改,要么全都執行,要么全都不執行,
一致性:是指事務在開始前和事務結束后,資料庫的完整性限制沒有被破壞,
隔離性:是指一個事務的執行,不會被其他事務干擾,一個事務的內部操作及使用的資料對其他的并發事務是隔離的,
持久性:指事務一旦提交,它對資料庫中的資料修改時永久性的,后續操作不會對其有任何影響,不會丟失,
8.6.2 事務隔離級別
資料庫系統提供了以下 4 種事務隔離級別
-
讀未提交:解決了回滾覆寫型別的更新丟失,但可能發生臟讀現象(一個事務讀取到了另一個事務修改但未提交的資料),也就是可能讀取到其他會話中未提交事務修改的數據,
-
已提交讀:只能讀取到其他會話中已經提交的資料,解決了臟讀,但可能發生不可重復讀現象(一個事務中多次讀取同一行記錄不一致,后面讀取的跟前面讀取的不一致),也就是可能在一個事務中兩次查詢結果不一致,
-
可重復度:解決了不可重復讀,它確保同一事務的多個實體在并發讀取資料時,會看到同樣的資料行,不過理論上會出現幻讀(一個事務中多次按相同條件查詢,結果不一致,后續查詢的結果和面前查詢結果不同,多了或少了幾行記錄),簡單的說幻讀指的的當用戶讀取某一范圍的資料行時,另一個事務又在該范圍插入了新行,當用戶在讀取該范圍的資料時會發現有新的幻影行,
-
可串行化:所有的增刪改查串行執行,它通過強制事務排序,解決相互沖突,從而解決幻度的問題,這個級別可能導致大量的超時現象的和鎖競爭,效率低下
8.6.3 MVCC
多版本控制,支持讀讀、讀寫、寫讀并行,但為了保證一致性,寫寫是無法并行的,
在事務1開始寫操作的時候會copy一個記錄的副本,其他事務讀操作會讀取這個記錄副本,因此不會影響其他事務對此記錄的讀取,實作寫和讀并行,
8.7 mysql 分庫分表
使用分庫分表時,主要有垂直拆分和水平拆分兩種拆分模式,都屬于物理空間的拆分,
垂直拆分:由于表數量多導致的單個庫大,將表拆分到多個庫中,
水平拆分:由于表記錄多導致的單個庫大,將表記錄拆分到多個表中,
8.7.1 主鍵策略
1、uuid
2、雪花片演算法,ID 按照時間有序生成,其核心思想是:使用41bit作為毫秒數,10bit作為機器的ID(5個bit是資料中心,5個bit的機器ID),12bit作為毫秒內的流水號,最后還有一個符號位,永遠是0
3、redis 生成id.利用 redis 的原子操作 INCR 來實作,
8.7.2 分片策略
1、范圍分片
2、hash 取模分片
3、一致性hash 分片
8.8 mysql 主從同步
8.8.1 適用場景
MySQL 主從模式是指資料可以從一個 MySQL 資料庫服務器主節點復制到一個或多個從節點,MySQL 默認采用異步復制方式,這樣從節點不用一直訪問主服務器來更新自己的資料,從節點可以復制主資料庫中的所有資料庫,或者特定的資料庫,或者特定的表,
8.8.2 主從同步作用
1、實時災備,用于故障切換
2、讀寫分離,提供查詢服務
3、資料備份,避免影響業務(高可用)
8.8.3 主從同步實作原理
主要分為三個步驟
1、主庫將資料庫的變更記錄到Binlog 日志檔案中
2、從庫讀取主庫的 Binlog 日志檔案資訊寫入到從庫的 Ready log 日志中,
3、從庫讀取 Ready Log 日志資訊在從庫中 Replay ,更新從庫資訊
異步復制:master 不會等待slave 節點回傳,直接提交事務,會導致資料不一致,
半同步復制:master 會等待slave 節點的ack 訊息后才會進行事務提交,
9. redis
9.1 跳躍表
跳躍表是有序集合的底層實作,就是將有序集合的部分節點進行分層,每一層都是有序集合,并且層次越高,節點數量就越少,最底層的包含所有節點資料,典型的空間換時間,
9.2 字典
字典是 redis 用來存盤鍵值對的一種資料結構,
hash 函式: 把redis 的key(字串、整型、浮點型)統一轉換成統一長度的整數,
hash 沖突:采用單鏈表解決,
字典擴容:新申請的容量為原來的一倍,將老的資料遷移到新字典中需要rehash,比較緩慢,
9.3 壓縮串列
由一系列特殊編碼的連續記憶體塊組成的順序型資料結構,沒有壓縮串列包頭部、entry資料和尾部,頭部資訊包含壓縮串列的位元組長度、壓縮串列尾部元素的偏移量、壓縮串列元素個數;尾部為一個位元組,為結束標志,
entry 資料包含:前一個元素的位元組長度、當前元素的編碼、以及當前元素的資料內容,
9.4 快速串列
quicklist 是串列的底層實作,quicklist 是一個雙向鏈表,同時每個節點是一個壓縮串列,這樣quicklist 的每個節點都可以存盤多個元素,
9.5 快取過期和淘汰策略
9.5.1 過期洗掉策略
redis 淘汰策略有三種,定時洗掉、惰性洗掉和主動洗掉,
Redis 目前采用惰性洗掉和主動洗掉,
9.5.1.1 定時洗掉
在設定鍵的過期時間時,創建一個定時器,讓定時器在該鍵過期時,執行對鍵的洗掉操作,(需要創建定時器,消耗cpu)
9.5.1.2 惰性洗掉
在訪問 key 的時候發現它失效了,就洗掉這個key
9.5.1.3 主動洗掉(定期洗掉)
每隔一段時間,我們就對一些key 進行檢查,洗掉過期的 key
9.5.2 淘汰策略
9.5.2.1 LRU
LRU (Least recently used )最近最少使用,基于鏈表實作,每次新資料插入到鏈表頭部,如果鏈表中的節點有被用到,就將該節點移到鏈表頭部,這樣鏈表尾部的元素就是最近最少使用的了,洗掉的 時候從尾部開始洗掉,
volatile-lru:從已經設定過期的資料集中挑選最近最少使用的進行資料淘汰,
allkeys-lru:從所有資料集中挑選最近最少使用的資料進行淘汰,
9.5.2.2 隨機
從資料集中任意選擇一個資料淘汰
9.5.2.3 volatile-ttl
從已經設定過期時間的資料集中挑選將要過期的資料進行淘汰,從過期時間表中隨機挑選幾個鍵值對,取出其中ttl 最小的鍵值對進行淘汰,
9.6 快取穿透、快取雪崩、快取擊穿
9.6.1 快取穿透
快取穿透是指在高并發下查詢 key 不存在資料,會穿透快取查詢資料庫,導致資料庫壓力過大而宕機,
解決方案:
一:設定一個短暫的隨機延時,避免同一時刻所有的請求都穿過快取增大資料的壓力,這樣先從資料庫查詢的資料查詢出后,添加到快取中,其他的請求就不會從資料庫中請求了,
二:設定布隆過濾器,在快取之前再加一個層布隆過濾器,在查詢的時候先去布隆過濾器中查詢key 是否存在,如果不存在就直接回傳,如果存在再查詢快取和DB.
布隆過濾器的原理是一組hash函式,當一個元素被加入集合中時,通過k個 hash 函式將這個元素映射成一個資料中的k個點,把他們置為1,檢索是,我們只要看看這些點是不是1就知道集合中存不存在這個元素了,只要有一個點為0,則被檢測的元素一定不存在集合中,
9.6.2 快取雪崩
大量快取集中在某一時間段內失效,這樣在失效的時候,大量請求達到資料庫,造成資料庫崩潰,
解決方案:
1、key 的失效期分散開,不同的key 設定不同的有效期,
2、設定二級快取
3、搭建集群,單節點故障后,由從節點補上,
9.6.3 快取擊穿
主要針對熱點資料,當key 在某一時間點過期的時候,正好有大量的并發請求訪問這個key,從而請求都達到資料庫,加大的資料庫壓力,
解決方案:
1、針對熱點 key.不設定超時時間,定期的充資料庫同步到redis 中,
2、用分布式鎖控制訪問的執行緒,使用redis 的setnx互斥鎖進行判斷,只有獲取鎖的執行緒才能訪問資料庫,其他的執行緒進行等待,
9.7 單執行緒的Redis 為什么這么快
1、正常情況下都是記憶體操作,不會和磁盤交換,從而訪問速度更快,
2、單執行緒沒有鎖,沒有多執行緒的切換和調度,不會死鎖,沒有性能損耗,
3、采用I/O 多路復用模型,非阻塞io ,效率更高
4、資料結構簡單,壓縮處理,
9.8 redis 分布式鎖實作
加鎖:使用setnx 加鎖,如果執行成功,然后設定過期時間,
解鎖:洗掉加鎖的key
10. 中間件
10.1 zookeeper
10.1.1 zookeeper 資料結構
zookeeper 將所有的資料存盤在記憶體中,資料模型是一個Znode tree,用斜杠分割路徑,每個znode 上還保留自己的資料內容,同時保留一系列的屬性資訊,
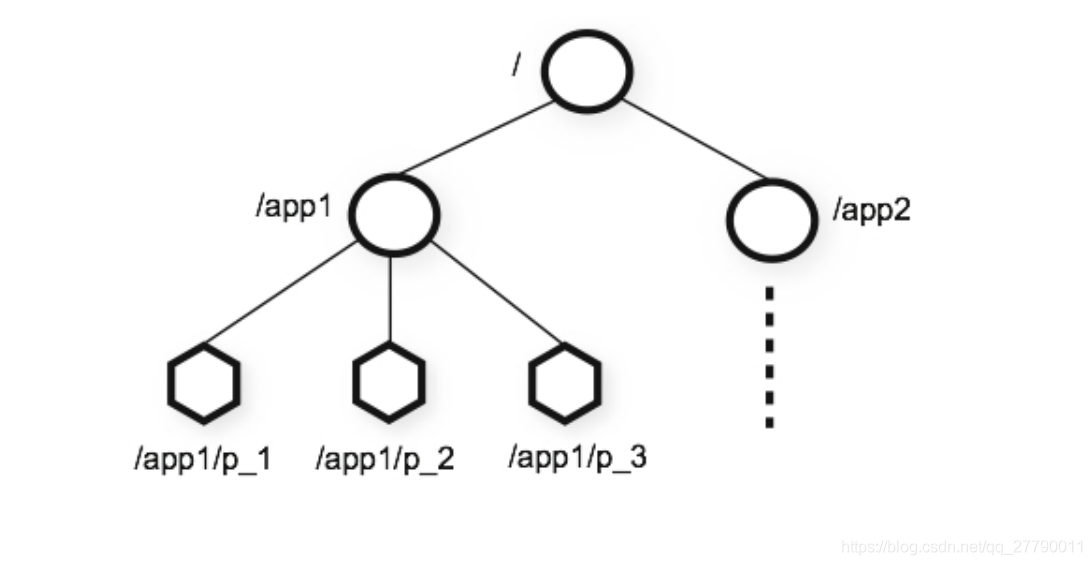
可以根據需求創建如下四種型別的節點:
持久節點:在節點創建后,會一直存在服務器上,直到洗掉操作主動洗掉,
持久順序節點:和持久節點一樣,創建后就一直存在,并且多了一個特性,在創建節點的時候,會加上一個數字后綴,來表示順序,
臨時節點:它的生命周期和客戶端會話系結在一起,客戶端會話結束,節點就會被洗掉掉,如持續節點不同的是,臨時節點不能創建子節點,
臨時順序節點:有順序的臨時節點,相對于臨時節點而言,在創建的時候,會加一個數字后綴,表示順序,
10.1.2 監聽器
Watcher(事件監聽器)是zookeeper 中一個重要的特性,zookeeper 允許用戶在指定的節點上注冊一些watcher,并在一些特定的事件觸發的時候,zookeeper 服務端會將事件通知到感興趣的客戶端,
10.1.3 zookeeper 應用場景
1、資料發布訂閱
2、集群管理
3、分布式鎖,利用zookeeper 可以實作分布式鎖的排它鎖和共享鎖,
排他鎖:利用zk 的強一致性,以及臨時節點的特性,首先定義一二鎖節點,然后多執行緒在鎖節點下創建一個臨時節點,哪個節點創建成功了,就說明該執行緒獲取到了分布式鎖,沒有獲取到鎖的執行緒,就注冊一個所節點的子節點監聽事件,以便監聽到鎖節點的變化情況,如果一個執行緒執行完成或者執行例外,都會關閉連接,表示釋放了鎖,這樣其他節點就可以通過監聽事前來重新獲取鎖了,
共享鎖:一樣的是利用zk 節點的強一致性,不過創建的是順序的臨時節點,分別表示讀鎖和寫鎖,對于讀請求,如果沒有比自己小的節點或者所有比自己小的節點都是讀請求,那么表明自己已經成功的獲取到了共享鎖,開始執行讀取邏輯,對于寫請求,如果自己不是序號最小的節點,就需要等待,
4、分布式佇列
10.1.4 ZAB 協議
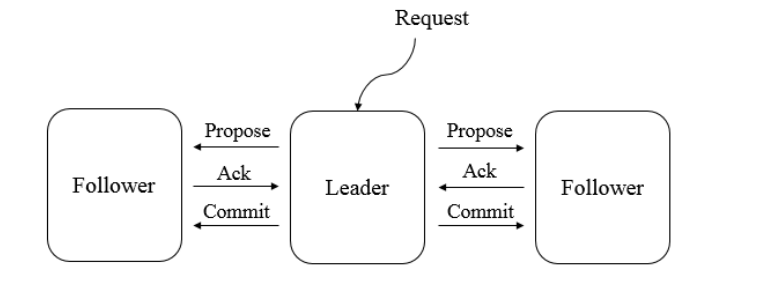
在 zookeeper 中主要是利用原子廣播協議來保證資料一致性的,
ZAB 協議的核心是定義了對于那些會改變 Zookeeper 服務器資料狀態的事務請求的處理方式
即:所有事務請求必須由一個全域唯一的服務器來協調處理,這樣的服務器被稱為Leader服務器,余下的服務器則稱為Follower服務器,Leader服務器負責將一個客戶端事務請求轉化成一個事務Proposal(提議),并將該Proposa1分發給集群中所有的Follower服務器,之后Leader服務器需要等待所有Follower服務器的反饋,一旦超過半數的Follower服務器進行了正確的反饋后,那么Leader就會再次向所有的Follower服務器分發Commit訊息,要求其將前一個Proposal進行提交,
10.2 dubbo
在集群負載均衡時,dubbo 提供了多種均衡策略,包含隨機、輪詢、最小活躍呼叫數、一致性hash, 默認為隨機呼叫,
11. 分布式
11.1 分布式下讀寫一致性
用戶讀取自己結果的一致性,保證用戶永遠能夠第一時間看到自己更新的內容,
如:我們發朋友圈,別人能不能第一時間看到沒關系,但是需要我們自己第一時間就能看到,這個應該怎么實作?
解決方案:
1、我們設定一個更新時間視窗,在剛剛更新的這段時間內,我們默認都從主庫讀取,過了這個視窗后,挑選最近有從主庫更新的從庫讀取,
2、我們直接記錄用戶操作的時間戳,在請求的時候,直接把這個時間戳帶上,凡是最后更新時間小于這個時間戳的分庫就不予以回應,
11.2 單調一致性
本次讀取到的資料不能比上次讀取到的資料舊,
解決方案:
根據用戶id 計算hash 值,映射到對應的服務器上,這樣同一個用戶不管怎樣重繪,都會被映射到同一臺機器,保證不會出現資料變舊的情況,
11.3 CAP 理論
一個分布式系統不能同時滿足一致性、可用性、磁區容錯性這三個基本需求,只能滿足其中兩個,
11.4 BASE 理論
BASE 由三個單詞組成,基本可用(Basically Available)、軟狀態(Soft state)、最終一致性(Eventually consistent),核心是想是:即使無法做到強一致性,但是每個應用都可以根據自己的特點,采用適當的方式來使得系統達到最終一致性,
11.5 2PC 和 3PC
兩階段提交協議:分為準備階段和提交階段,在準備階段,事務管理器會給每個參入者發送prepare 訊息,每個引數者在自己本地執行事務,并寫入undo/redo 日志(undo 是修改前的日志,用于事務回滾,redo是修改后的日志,用來資料提交),這個時候事務還沒有提交,在提交階段,如果事務管理器收到了參入者執行失敗或者超時的訊息時,會發送回滾的訊息給所有參入者進行回滾,如果都成功了,就發送提交的訊息給所有參入者進行資料提交操作,
三階段提交協議:是將2PC 的提交階段一分為二,precommit 階段發送預提交請求,各個參入者向協調者反饋執行結果,docommit 階段執行事務提交,
11.6 paxos 一致性演算法
paxos 演算法核心就是提案,
1、proposer 選擇一個提案為N ,向半數以上的Acceptor 發送編號為N 的 prepare 請求,
2、如果 Acceptor 收到一個編號為N的 prepare請求,并且N為當前Acceptor 所回應的請求中編號最大的,它就接收這個提案,并且不再接收比這個編號更小的提案了,
3、如果proposer 收到了半數以上Acceptor 對其發出的編號為N 的prepare請求回應,就會給半數以上的 Acceptor 發送提案的accept 請求,
4、如果acceptor 收到一個編號為N的accept 請求,如果當前acceptor 沒有對編號大于N 的prepare 請求做出回應,它就接收該提案,
11.7 Raft 一致性演算法
Raft 一致性演算法分為兩個階段:首先是選舉階段,然后通過選舉出來的領匯入帶領進行正常操作,
選舉的程序:
1、集群中所有的節點開始的時候都是 follower 跟隨者,當發現沒有領導者的時候,
2、部分的跟隨者會變成候選者,候選者會向跟隨者發起投票請求,如果當前候選者獲得了超過半數的選票,就自動變成了領導者,
3、如果集群中存在領導者,其他的候選者也會變成跟隨者,所有的跟隨者都會從領導者中進行資料同步,保證資料一致性,
12. mybatis
12.1 mybatis 初始化
1、通過jdk 檔案流加載器讀取xml組態檔,
2、通過XmlConfigBuilder 來決議組態檔,并封裝到configuration 物件中,
3、創建SqlSessionFactory 物件,并傳遞configuration
4、通過SqlSessionFactory.openSqlSession() 來創建sqlSession 物件并回傳,
12.2 sql 執行程序
1、通過呼叫Sqlsession 物件的query()或者update() 方法,
2、通過statmentid 從configuration 中獲取到對應的mapperstatement
3、將configuration 和mapperstatement 物件傳遞給Executor 執行器來執行sql 操作,
4、Executor 執行器用來處理快取,以及動態sql 的生成,并將sql 傳遞給statementhandle
5、statementHandle 將呼叫parameterHandle 進行引數的決議
6、statementHandle 執行sql 得到結果,
7、statementHandle 通過ResultSetHandle 將回傳的結果進行物件映射,最侄訓傳結果,
12.3 mybatis 插件
mybatis 作為應用廣泛的優秀的ORM開源框架,具有強大的擴展性,在mybatis 中的 Executor、StatementHandle、ParameterHandle、ResultSet 這四大組件提供了簡易的拓展支持,mybatis 支持插件對上面這四大物件進行攔截,從而實作前置增強和后置增強,
自定義插件只需要實作mybatis 的interceptor 介面,并通過注冊來宣告攔截的類和方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/275462.html
標籤:java
上一篇:Java執行緒池七個引數詳解:核心執行緒數、最大執行緒數、空閑執行緒存活時間、時間單位、作業佇列、執行緒工廠、拒絕策略
下一篇:Java進階知識——注解