< 參考答案在末尾>
-
下面關于pycharm描述錯誤的是()
- A . pycharm用于我們開發python程式的集成工具
- B. pycharm不可以打開已有的專案代碼
- C. 使用pycharm運行代碼需要設定python解釋器
- D. pycharm可以打開已有的專案代碼,運行前需要設定解釋器
決議:pycharm 可以創建新的專案,在創建的時候讓我們選擇解釋器,同樣也可以打開已有的專案,但是打開后需要我們再配置下解釋器,否則不能運行
-
下面python中變數命名不正確的是()
- A. Person
- B. Name10
- C. __name
- D.66name
決議:python中變數命名是由數字字符下滑線構成,但是不能以數字開頭
-
下面關于python中的注釋錯誤的是()
- A. #注釋
- B. ‘’‘注釋’‘’
- C. “”“注釋”“”
- // 注釋
-
下面關于python中的字串格式化錯誤的是()
- A. "{}".format(10)
- B. print("%d" % 10)
- C. f'{10}'
- D. print("%d",10,20)
D是普通的列印,其他是python3中不同的格式化方式
-
對于name = input("請輸入姓名:") 理解錯誤的是(A)
- name 是int型別
- input引數中的字串是提示字符
- input回傳的是字串
- input用于接收用戶從鍵盤的輸入資訊
input 回傳的都是字串型別,如果想轉其他型別使用對應的轉化方法
-
下面那些運算后回傳的不是bool值()
- A. 10 + 20
- B. 10>20
- C. 10==20
- D. 10<20 and 30 == 30
python 中比較運算子 邏輯運算子 回傳的都是bool型別
-
下面那一個不可以正確列印ok()
- A.
if 1:print('ok') - B.
if -1: print('ok') - C.
if 0: print('ok') - D.
if [1]:print('ok')
python中的非0數字可以表示True,容器型別的資料如果有資料也可以表示True
- A.
-
下面的代碼可以達到預期效果(錯誤)
# 根據用戶輸入,判斷年齡是屬于小孩(10歲以下),青年(10~20歲),還是中年,或者老年 age = int(input("請輸入年齡: ")) if age<=20: print("青年") if age<10: print("小孩") if age=>20 and age <=50: print("中年人") if age>50: priint("老年人")錯誤 不能完成,因為當年齡小于10歲的時候代碼不會執行
-
下面random【百度查詢】隨機1~10之間的浮點數正確的是()
- A.
random.random() - B.
random.randint(1,10) C. random.random()+1- D.
random.random()+random.randint(1,9)
random.randint 用于生成范圍整數,
random.random()用于生成0~1 直接的浮點數
如果想生成1~10直接的浮點數
可以先生成1~9的整數 然后再加上0~1 的浮點數,所以答案是D
- A.
-
請分析下面的代碼是否可以實作預期的目的?這塊程式的運行結果是什么? 如果不能實作請修改代碼實作目的要求
# 目的: 當x*y = 64的時候退出回圈
x = 1
while x<10:
y = 1
while y<10:
if x*y == 64:
continue
y+=1
x+=1
print(x,y) # 決議
#1. 不能實作
#2. 這個代碼會死回圈【在內回圈里面】,導致程式無休止運行,而不能列印任何內容
#3. 修改代碼,首先需要把coninue 改成break,內回圈break后僅僅跳出內回圈已經不能跳出外回圈,所以需要添加一個標志
x = 1
# 用于控制跳出外回圈的標志
flag = False
while x<10:
y = 1
while y<10:
if x*y == 64:
# 修改標志可以跳出外回圈了
flag = True
#continue,修改成break完成內回圈跳出
break
y+=1
# 檢查表示是否可以跳出外回圈
if flag:
break
x+=1
print(x,y)
11.分析修改下面的代碼不能達到預期結果的原因,如果不能把分析的原因說明,然后修改代碼【要求2種方式實作 一種是在現在代碼基礎上,一個是使用for in】
#要求: 現有一個串列 li = [1,2,3,4,6,7,8,10,12],洗掉串列中的偶數資料
li = [1,2,3,4,6,7,8,10,12]
index = 0
length = len(li)
while index < lg:
if li[index]%2==0:
del li[index]
index+=1
print(li)# 答案剖析
#1. 不能實作里面存在不少問題
#1.1 當洗掉元素的時候,我們的串列長度會減少 while 判斷標準是最初的長度,最后會越界錯誤,修正實時與li長度比較 while index<len(li)
#1.2 在上面的基礎上運行仍然會報越界錯誤, 洗掉元素后,我們的下標不應該再移動了
# 2. while 版本的修正
li = [1,2,3,4,6,7,8,10,12]
index = 0
# 因為要洗掉元素所以要實時與li的長度比較
while index < len(li):
if li[index]%2==0:
# 洗掉元素后,串列后面的元素會向前移動,所以index下標不應該再移動
del li[index]
continue
index+=1
print(li)
?
# #for in 版本1
li = [1,2,3,4,6,7,8,10,12]
tmp=[]
?
while True:
# 用于標志串列中沒有偶數元素了
flag = True
# 下面的洗掉會漏洗掉,所以多次回圈洗掉,保證所有的偶數都被洗掉
for num in li:
if num%2==0:
li.remove(num)
# 洗掉說明串列有偶數元素
flag = False
# 回圈結束后,flag沒有變化說明,里面全是奇數了,可以break 出來了
if flag:
break
#for in 版本2
li = [1,2,3,4,6,7,8,10,12]
# 臨時串列用于記錄要洗掉的元素
tmp=[]
# 回圈記錄要洗掉的元素
for num in li:
if num % 2==0:
tmp.append(num)
# 回圈洗掉要洗掉的元素
for num in tmp:
li.remove(num)
?
12.下面代碼可以正常運行()
dic = {"name":"mrsun",'age':20}
print(dic['money'])獲取不存在的鍵會發生例外, 可以使用 dic.get('money') 來獲取鍵,不存在則回傳None
- 對
- 錯
-
下面代碼運行后的輸出結果(D)
money = 100 age = 30 user = {"name":'mrsun','age':18,'money':0} def modify(user,age,money): user['age'] = age user['money'] = money age = 100 money = 1000000 modify(user,age,money) print(money,age,user)函式內部僅僅會修改字典user的值,字典是參考型別,所以可以修改其他不可以修改
- A. 100, 30, {'name': 'mrsun', 'age': 30, 'money': 0}
- B. 100000, 100, {'name': 'mrsun', 'age': 30, 'money': 0}
- C. 100000, 100, {'name': 'mrsun', 'age': 30, 'money': 100}
- D. 100,30, {'name': 'mrsun', 'age': 30, 'money': 100}
-
請按照下面的要求完成代碼撰寫
【難度有一些請同學們做好準備】假如現有一組爬蟲爬取的資料,每個元素包含了一個IP地址域埠號,[("192.168.1.109",6000),("192.168.1.109",None),("192.168.2.255",8000),("192.168.100.200",8080),("192.168.1.8600",6000),("192.168.1.199",8000),("192.168.1.500",6000),("192.168.1.50",80000),("192.168.1.50",'80000')],里面的部分資料有錯誤,
撰寫代碼中可以考慮使用串列推導式
提示:
-
ip地址192.168.1.205 由點號分割的4個整數范圍是0~255,埠是大于1~65535的數字
-
可以借助函式方法、靈活使用串列推導式、字串操作、邏輯運算 等
要求: 請同學們,串列推導式以外不要使用回圈
# 答案決議 #遍歷IP和埠滿足要求則是我們需要的 li = [("192.168.1.109",6000),("192.168.1.109",None),("192.168.2.255",8000),("192.168.100.200",8080),("192.168.1.8600",6000),("192.168.1.199",8000),("192.168.1.500",6000),("192.168.1.50",80000),("192.168.1.50",'80000')] # 檢查IP是否滿足標準 def ipok(ip): # 分割IP地址,獲取數字串列 ipli = ip.split('.') print(ipli) # 串列推導式,如果不符合對應欄位設定False tmp = [True if 0<int(num)<=255 else False for num in ipli ] # 判斷False與沒有在里面,如果再里面說明Ip有問題 return not False in tmp ? # 檢查埠是否滿足規則 def portok(port): # 埠不能為None 且是整數,范圍在0~65535直接 return port is not None and isinstance(port,int) and 0<port<65535 # 提取沒有問題的ip 與埠 hli = [item for item in li if ipok(item[0]) and portok(item[1])] print(hli) # ========================我是華麗的分割線=============================== # 終極合并版本 hli = [item for item in li if (not False in [True if 0<int(num)<=255 else False for num in item[0].split('.') ]) and (item[1] is not None and isinstance(item[1],int) and 0<item[1]<65535)] print(hli) -
16.下面關于函式錯誤錯誤的(A)
答案決議:
A . 定義函式的時候如果有默認預設引數值的時候,應該從引數的右邊向左,所以此選項錯誤
B. 函式的作用就是提高我們的代碼復用
C 的函式定義方式包含了 形參,預設引數,可變引數,關鍵詞引數 定義ok
D. Func(*arg)是函式引數解包,等價于 Func(1,2,3,4,5) 所以函式呼叫ok
def Fun(a = 100,b,c = 50): pass- 函式的作用就是提高代碼復用
def Func(a,b,c=None,*args,**kwargs):pass假如有一個arg = (1,2,3,4,5)元組, 按照Func定義方式去呼叫 Func(*arg)
17.關于下面代碼運行print的值是()
li = [1,2,3]
def Modify(li):
li.append(4)
print(li)
print(li)
Modify(li)
fn = Modify
print(fn)
fn(li)
print(li)
print(fn(li))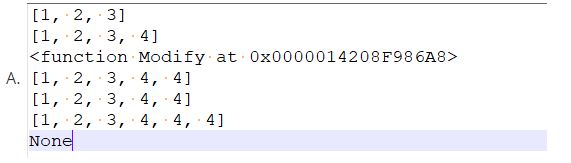

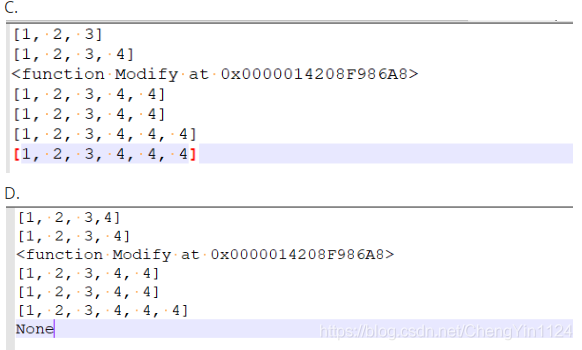
# 答案決議
li = [1,2,3]
# 函式定義
def Modify(li):
# 向li中追加元素4,li 是應用型別所以函式內部修改會影響外面的資料
li.append(4)
print(li)
# 沒有做任何修改所以原始資料[1,2,3]
print(li)
# 函式呼叫,函式內部列印修改后的li [1,2,3,4]
Modify(li)
# 函式也可以賦值給變數,那么這個變數也是函式
fn = Modify
# 列印函式,所以是:<function Modify at 0x0000014208F986A8> 這樣的格式
print(fn)
# 函式呼叫,再次增加一個元素4是:[1,2,3,4,4]
fn(li)
# 列印li 依舊是:[1,2,3,4,4]
print(li)
# 函式呼叫,函式內部追加4,列印:[1,2,3,4,4,4], print 列印函式的回傳值,因為函式沒有回傳值所以是None
print(fn(li))
18.下面代碼運行結果下面描述真正的()
f = open("1.txt",'w')
f.write("welcome to python!")
f.close()
f = open("1.txt",'w')
f.write("python is best language!")
f.close()
f = open("1.txt",'r')
# 第一次列印
print(f.read())
f.close()
f = open("1.txt",'w')
f.close()
f = open("1.txt",'r')
print(f.read())
f.close()- A. 第一次列印內容是 : welcome to python!python is best language!
- B. 第二次列印內容是 : welcome to python!python is best language!
- C. 第一次列印內容是:welcome to python!
- D. 第二次列印內容是: 空字符
決議:
本題考查的內容是 打開檔案的w 模式
w模式,如果檔案不存在則創建檔案,如果檔案存在則清空檔案內容
第一次列印的內容應該是:python is best language!
第二次列印內容是:“” 也就是空字符
19.請同學實作一個可以遞回洗掉指定目錄下面的固定格式的檔案的程式()
示例: remove(myproject,'pyc') , 表示洗掉myproject目錄中的所有以pyc檔案結尾的檔案
# 答案決議,以洗掉txt檔案為例
import os
import sys
# remove 出指定目錄下面的指定后對檔案,支持嵌套目錄中的洗掉
def remove(rdir,suffix):
if not os.path.isdir(rdir):
print("目錄不存在,請核對!")
#1. 獲取當前目錄下面的所有檔案夾以及檔案
files = os.listdir(rdir)
# 記錄當前的路徑,也就是ridr路徑,需要拼接完整路徑
pwd = rdir
#2. 遍歷所有檔案,檢查是否是以suffix結尾的檔案,如果是執行洗掉
for tmp in files:
# 判斷當前的是檔案還是目錄
# 拼接完成路徑
obpath = os.path.join(pwd,tmp)
if os.path.isfile(obpath):
#3. 判斷檔案是否是以suffix 結尾的檔案
if obpath.endswith(suffix):
# 如果是則說明是我們要洗掉的檔案
os.remove(obpath)
else:
#4. 如果是目錄則遞回呼叫洗掉
print(obpath)
remove(obpath,suffix)
if __name__ == "__main__":
remove("mytest",".txt")20.對于下面代碼運行結果不正確的是()
class ObjSet(object):
gattr = "init"
def __init__(self, attr):
self.attr = attr
@classmethod
def setg(cls,gattr):
cls.gattr = gattr
def tryGattr(self,gattr):
self.gattr = gattr
obj = ObjSet(10)
# 第一次列印
print(obj.gattr,ObjSet.gattr)
obj.tryGattr("python")
# 第二次列印
print(obj.gattr,ObjSet.gattr)
obj.setg("golang")
# 第三次列印
print(obj.gattr,ObjSet.gattr)- A. 第一次列印結果 init init
- B. 第二次列印結果 python python
- C. 第二次列印結果 python init
- D. 第三次列印結果 python golang
# 答案決議
# 這里面主要弄清類方法與物件方法的區別與作用
# 類方法主要用于修改類屬性,物件方法主要用于修改物件屬性
class ObjSet(object):
# 類屬性
gattr = "init"
def __init__(self, attr):
# 物件屬性
self.attr = attr
@classmethod
def setg(cls,gattr):
# 通過類方法設定類屬性
cls.gattr = gattr
def tryGattr(self,gattr):
# 沒有gattr屬性所以默認使用了類屬性
print(self.gattr)
# 設定物件屬性
self.gattr = gattr
obj = ObjSet(10)
# 第一次列印,因為沒有物件屬性所以列印的都是 類屬性,所以都是 init init
print(obj.gattr,ObjSet.gattr)
# 設定了物件屬性
obj.tryGattr("python")
# 第二次列印,因為方法中設定了與類屬性同名的物件屬性,物件屬性變化,類屬性沒有變化,所以列印結果:python init
print(obj.gattr,ObjSet.gattr)
# 設定類屬性
obj.setg("golang")
# 第三次列印,類屬性更改,所以再第二次列印的基礎上變化: python golang
print(obj.gattr,ObjSet.gattr)
21.下面的描述錯誤的是()
- A. 對于所有實體物件都有的屬性且屬性值都一樣的屬性可以設定為類屬性
- B. 對于所有物件都有的屬性,且每個物件的屬性值可能不同,可以設定為物件屬性
- C. 我們可以在物件(實體)方法中修改類屬性
- D. a, b 是同一個類的實體化的物件,a物件中修改了類屬性,在b物件中類屬性沒有發生變化
# 答案決議
A,B定義類屬性以及物件屬性的場景
C 類屬性主要是通過類方法修改,但是也可以在物件屬性中通過類名字加屬性訪問修改,但是不建議,假如某一天修改類名字的時候,方法中所有獲取或者修改類屬性的地方都要修改,不利于擴展,所以不推薦
D. 類屬性是所有的物件共享的屬性,所以a物件中更改后b物件中同樣看到的是更改后的值,所有D選項是錯誤的22.請修改下面的代碼使其運行正確
class Master1(object):
def __init__(self):
super().__init__()
self.a = 100
class Master2(object):
def __init__(self):
self.b = 200
class Sub(Master1,Master2):
def __init__(self):
pass
def show(self):
print(self.a,self.b)
sub = Sub()
sub.show()# 答案決議
# 這個題目考察super的作用以及多繼承的查找
# 1. 初次運行提示我們沒有a屬性,因為a屬性,是父類初始化中,初始化的,在Sub中并沒有呼叫super進行父類初始化,所以在super().__init__() 進行父類初始化
# 2. 此時再運行 提示沒有b屬性, 當我們查找b屬性的時候,發現sub中沒有,繼續向父類Master1中查找發現沒有,繼續Master2中查找依舊沒有,因為Master2的初始化沒有進行,Master1的初始化中添加super便于進行后續父類的初始化
class Master1(object):
def __init__(self):
self.a = 100
# 用于初始化Master2,獲取b屬性
super().__init__()
class Master2(object):
def __init__(self):
self.b = 200
class Sub(Master1,Master2):
def __init__(self):
# 用于初始化Master1,獲取a屬性
super().__init__()
def show(self):
print(self.a,self.b)
sub = Sub()
sub.show()23.下面的代碼是否可以運行,不能運行請指出其原因
# a.py
from b import age
name = "MrSun"
print(name,age)
# b.py
from a import name
age = 20
print(name,age)
# 運行其中任何一個檔案# 答案決議
# 不能運行,a模塊與b模塊出現了回圈導包
24.【此題有不小的難度4個星,請同學做好心理準備】
題目:現在有2個類,一個是博主類一個是粉絲類,要求博主可以發表博客,博主提供查看博客的內容,博主可以提供粉絲關注功能,博主提供粉絲取消關注的功能,當博主更新狀態的時候,粉絲可以得知博主的狀態更新了!提供博客的評論功能,便于當新博客更新后,粉絲評論
要求:
-
同學們百度關鍵詞
python 觀察者模式,查閱觀察者模式相關的資料 -
同學們請使用觀察者模式實作此案例
-
里面提供了2個類,其他的類需要同學自己抽取,方法也需要同學分析!
-
請同學們靈活使用基礎所學內容
-
把關注博主的粉絲資訊保存到檔案中fans.info,以及博主發表的博客內容,博客對應的評論內容保存到 blogs.info
-
fans.info 格式 : ['粉絲: 粉絲1', '粉絲: 粉絲2']
-
blogs.info 格式:
-
[{id:1,content:xxx,comments:[conment1,comment2]},xxx] # 可以考慮使用推導式提醒: 實際開發也是這樣的一個狀態,可能是邊查看資料邊寫代碼,提前感受下!
參考答案:
題目比較開放可以基本實作即可
參考答案放鏈接嘗試無法打開 文本分享+官方寫作口口交流裙:924403856
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/275483.html
標籤:python