1.研報概述
本文是研報復現系列的第一篇,文本復現了【方正證券】的研報【跟蹤聰明錢:從分鐘行情資料到選股因子】,
該研報嘗試從分鐘行情資料中挖掘出那些聰明人(即機構)所做的交易,稱為“聰明錢”,并量化這些聰明錢對后市看漲、看跌的情緒觀點,進而跟隨聰明錢進行選股,
2.研究環境
JointQuant
import datetime
import math
import matplotlib.pyplot as plt
from jqdata import *
import pandas as pd
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
3.研報復現
3.1 資料獲取
本文資料來源于聚寬JoinQuant,用到的介面名和功能如下表所示,具體引數請查閱聚寬的API檔案,
| 介面名 | 功能 |
|---|---|
| get_bars | 獲取行情資料 |
| get_price | 獲取獲取資料、是否停牌、漲跌停價 |
| get_trade_days | 獲取一段時間內的交易日串列 |
| get_extras | 查詢特定股票是否是ST股 |
| get_all_securities | 獲取股票資料,包括上市時間 |
| get_index_stocks | 獲取指數成分股 |
3.2 劃分聰明錢
聰明錢在交易程序中往往呈現“單筆訂單數量更大、訂單報價更為激進”
因此,某分鐘的交易的聰明度指標S定義為:S= ∣ R t ∣ \left| Rt \right| ∣Rt∣ / / / V t \sqrt{Vt} Vt ?,
Rt為第t分鐘的漲跌幅,Vt為第t分鐘的成交量,S的值越大,則說明此交易越聰明,
我們封裝一個獲取分鐘行情資料以及S值的函式,方便后面的研究使用,
def get_minute_data(
security,#股票代碼,可以是list或者字串
count,#獲取多少條資料
end_dt=datetime.datetime.now()
):
df = get_bars(
security,
count = count,
include_now=True,
unit = '1m',
fields = ['date','open','close','volume'],
df = True,
end_dt = end_dt
)
df['R'] = (df['close'] - df['open'])/df['open']#漲跌幅
df['S'] = abs(df['R'])/df['volume']**0.5*10000 #S值,乘10000為了方便畫圖
df['volume'] = df['volume']/10000#volume除以10000方便畫圖
return df
原研報利用成交量與計算出的S值來劃分聰明錢交易,
劃分演算法為:
step1:對于特定股票,特定時間段的分鐘級交易資料,計算得到每分鐘的S值,并將資料按照S值由大到小排序,
step2:求排序后的分鐘資料的交易量累加和,將交易量累加和占該該時間段總成交量前20%的分鐘交易視為由聰明錢進行的交易,
其中,閾值選取20%是因為在A股市場中機構交易者只貢獻了少量的交易量,原研報同時測驗了閾值選取其他數值時效果,其中20%是最優的.
我們以603198.XSHG在2021年4月8日下午14:00到14:30的分鐘資料為例,給出劃分聰明錢的程式并將結果可視化,
'''
功能:
尋找聰明錢的交易并可視化
演算法:
對于特定的股票,特定時間段的分鐘級交易資料,計算得到每分鐘的S值,并將資料按照S值由大到小排序,
求排序后的分鐘資料的交易量累加,將交易量累加和占比前20%的分鐘視為由聰明錢交易的時刻,
其中,閾值選取20%是因為在A股市場中機構交易者只貢獻了少量的交易量,原研報同時測驗了閾值選取其他數值時效果,其中20%是最優的,
資料:
以603198.XSHG在2021年4月8日下午14:00到14:30的分鐘資料為例,
'''
#獲取資料并且個每個分鐘編號
df = get_minute_data('603198.XSHG',30,end_dt='2021-04-08 14:30:00')
df['bar_no'] = [_ for _ in range(1,31)]#每根bar的序號,方便x軸的顯示
#繪圖
fig = plt.figure(figsize=(14,10))
#S值與成交量圖
ax = fig.add_subplot(211)
h1 = ax.bar(df.index,df['volume'],label='成交量',width=0.5)#成交量
ax2 = ax.twinx()
h2 = ax2.scatter(df.index, df['S'],label='S因子',marker='o',color='r')#S值
plt.legend([h1,h2], [h1.get_label(),h2.get_label()], loc='best')
ax.grid()#網格
ax.set_ylabel(u"成交量(萬)")
ax.set_title(u"成交量與S因子值")
ax2.set_ylabel(u"S值(10e-4)")
ax.set_xlabel(u"時間序號")
plt.xticks(df.index.values, df['bar_no'])
#排序后的圖
ax = fig.add_subplot(212)
df = df.sort_values(by='S',ascending=False).reset_index(drop=True)#按S值排序
df['acc_volume_pct'] = df['volume'].cumsum()/df['volume'].sum()#計算累計成交量
df1 = df[df['acc_volume_pct']<=0.2]#累計成交量前20%
df2 = df[df['acc_volume_pct']>0.2]
ax.bar(df1.index,df1['volume'],color='r',width=0.5)#繪制累計成交量前20%的柱狀圖
h1 = ax.bar(df2.index,df2['volume'],label='成交量',width=0.5)#繪制余下的
ax2 = ax.twinx()
h2 = ax2.plot(df.index, df['acc_volume_pct'],label='累計成交量占比',marker='o',color='g')#累計成交量
plt.legend([h1,h2[0]], [h1.get_label(),h2[0].get_label()], loc='best')
ax.grid()
ax.set_ylabel(u"成交量(萬)")
ax.set_title(u"選擇聰明錢")
ax2.set_ylabel(u"累計成交量")
ax.set_xlabel(u"時間序號")
plt.xticks(df.index.values, df['bar_no'])
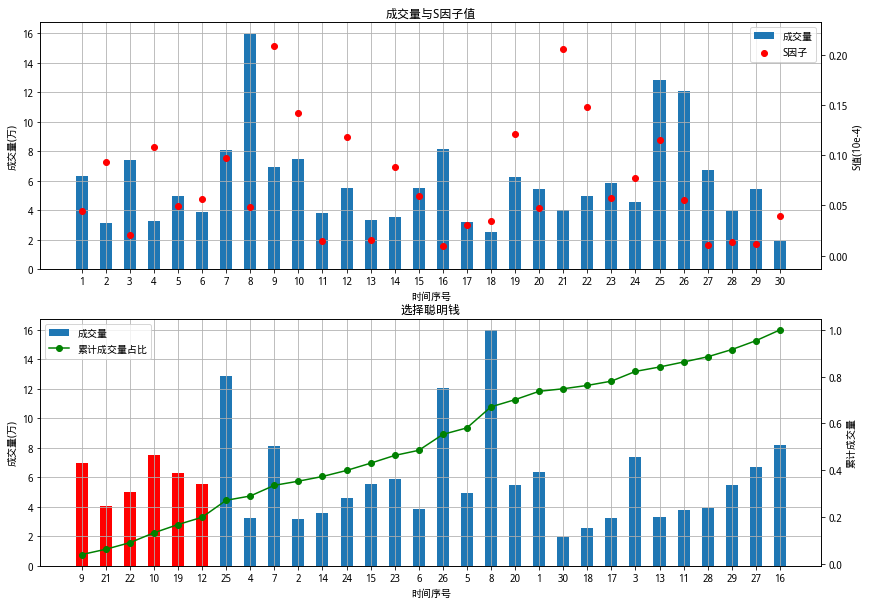
3.3 量化聰明錢對股票后市的情緒
我們劃分出了聰明錢的交易后,如何判斷聰明錢是對這只股票看多還是看空呢
對于特定股票、特定時段的分鐘行情資料,按照上述方法劃分出聰明錢的交易之后,我們可以構造聰明錢的情緒因子Q
Q = vwap_smart/vwap_all
vwap_smart和vwap_all分別是聰明錢的成交量加權平均價和該段時間內所有分鐘的成交量加權平均價
因子 Q 實際上反映了在該時間段中聰明錢參與交易的相對價位,之所以將其稱為聰明錢的情緒因子,是因為因子 Q 的值越大,表明聰明錢的交易越傾向于出現在價格較高處,這是逢高出貨的表現,反映了聰明錢的看空,消極情緒;因子Q的值越小,則表明聰明錢的交易多出現在價格較低處,這是逢低吸籌的表現,看多,積極情緒,
我們將情緒因子Q的計算封裝成一個函式
def calcQ(data_bar):
'''
功能:
計算Q值
引數:
DataFrame型別,特定股票一定時間段內的分鐘資料(close,volume和S)
回傳:
浮點數,即Q值
'''
data_bar = data_bar.sort_values(by='S',ascending=False).reset_index(drop=True)#按S值排序
data_bar['acc_volume_pct'] = data_bar['volume'].cumsum()/data_bar['volume'].sum()#計算累計成交量
smart_bar = data_bar[data_bar['acc_volume_pct']<=0.2]#聰明錢交易,累計成交量前20%
#vwmap:volume weighted average price,成交量加權平均價
vwap_smart = (smart_bar['close']*smart_bar['volume']).sum()/smart_bar['volume'].sum()
vwap_all = (data_bar['close']*data_bar['volume']).sum()/data_bar['volume'].sum()
return vwap_smart/vwap_all
3.4因子選股能力驗證
本小節對上一小節量化出的聰明錢情緒因子的選股能力進行驗證,
樣本空間:滬深300成分股,剔除 ST 股和上市未滿 60 日的新股,以及漲停、停牌、跌停(原研報為全部A股,但資料量過多,受硬體限制本文縮小了樣本范圍,做了簡化)
測驗時間:2013-04-30 到 2016-05-31
測驗方法:每個月末時,對于選股空間的所有股票,計算其之前10天的分鐘級交易資料的Q值,和該股票次月的收益率,這樣每個月可以得到兩組序列,分別為每只股票的Q值和次月的收益率,計算其RankIC秩相關系數,可視化測驗時間周期內所有月份的兩組序列的相關系數,統計顯著相關情況,
概念解釋:
RankIC秩相關系數為兩組序列中的元素在序列中的相對位置(即大小順序)的相關系數,
在因子模型中,因子與收益的相關系數大于0.03即認為是有效的因子,
為了實作對因子的驗證,我們封裝了兩個簡單的函式,分別用于
1.獲取特定日期滿足交易條件的股票(即在選股樣本中剔除ST股、漲停、跌停等)
2.獲取特定日期所在月的最后一日,用于獲取次月的行情資料
def get_stocks(date,index=None):
'''
功能:
根據日期,獲取該日滿足交易要求的股票相關資料,即剔除ST股、上市未滿60天、停牌、跌漲停股
引數:
date,日期
index,指數代碼,在特定指數的成分股中選股,預設時選股空間為全部A股
回傳:
DataFrame型別,索引為股票代碼,同時包含了價格資料,方便后續使用
'''
stocks = get_all_securities(
types=['stock'],
date=date
)#該日正在上市的股票
if index:#特定成分股
stock_codes = get_index_stocks(index,date=date)#成分股
stocks = stocks[stocks.index.isin(stock_codes)]
#上市日期大于60個自然日
#date = datetime.datetime.strptime(date,'%Y-%m-%d').date()
stocks['datedelta'] = date - stocks['start_date']
stocks = stocks[stocks['datedelta'] > datetime.timedelta(days=60)]
#是否是ST股
stocks['is_st'] = get_extras(
info='is_st',
security_list=list(stocks.index),
count=1,
end_date=date
).T
#漲停、跌停、停牌
stocks_info = get_price(
security = list(stocks.index),
fields=['close','high','low','high_limit','low_limit','paused'],
count=1,
end_date=date,
panel=False
).set_index('code').drop('time',axis=1)
stocks['price'] = stocks_info['close']#順便保存價格,方便后續運算
stocks['paused'] = stocks_info['paused'] == 1#是否停牌
stocks['high_stop'] = stocks_info['high'] >= stocks_info['high_limit']#漲停
stocks['low_stop'] = stocks_info['low'] <= stocks_info['low_limit']#跌停
stocks = stocks[~(stocks['is_st'] | stocks['paused'] | stocks['high_stop'] | stocks['low_stop'])]
return stocks
def last_day_of_month(any_day):
#獲取某個日期所在月份的最后一天,方便在計算次月收益時獲取次月的時間范圍
next_month = any_day.replace(day=28) + datetime.timedelta(days=4) # this will never fail
return next_month - datetime.timedelta(days=next_month.day)
萬事俱備,我們現在統計每個月份每只股票的Q值和次月收益率,并計算秩相關系數、可視化,
#獲取交易日序列
trade_days = get_trade_days(start_date='2013-04-30', end_date='2016-05-31')
#存盤結果
result={
'months':[],#月份序列
'stocks':[],#股票序列
'Q':[],#Q值序列
'return':[]#次月收益序列
}
days_count = len(trade_days)
for i,date in enumerate(trade_days):#遍歷交易日
if i == days_count-1:#如果是串列最后一個日期
#可交易的股票
stocks = get_stocks(trade_days[i],index='000300.XSHG')
stocks_list = list(stocks.index)
#每只股票下個月的價格
next_month_bar = get_bars(
stocks_list,
count = 1,
unit = '1M',
fields = ['open','close'],
df = True,
include_now=True,
end_dt = '2016-06-30'
)
'''
獲取分鐘資料,用來計算Q
這里一次性獲取所有股票的資料,來減少資料請求的次數,加速程式運行
'''
data = get_minute_data(
stocks_list,
2400,
end_dt=trade_days[i]
).reset_index(level=0). rename(columns={'level_0':'code'})
data_groups = data.groupby('code')#分鐘資料根據股票代碼分組
result['stocks']+=stocks_list
result['months']+=[trade_days[i].strftime('%Y-%m')]*stocks.shape[0]
#依次計算每一只股票的Q值
result['Q']+=[calcQ(data_bar) for name,data_bar in data_groups]
result['return']+=list((next_month_bar['close']-next_month_bar['open'])/next_month_bar['open'])
break
if trade_days[i+1].month != trade_days[i].month:#每月的最后一個交易日
stocks = get_stocks(trade_days[i],index='000300.XSHG')
stocks_list = list(stocks.index)
next_month_bar = get_bars(
stocks_list,
count = 1,
unit = '1M',
fields = ['open','close'],
df = True,
include_now = True,
end_dt = last_day_of_month(trade_days[i+1])
)
data = get_minute_data(
stocks_list,
2400,
end_dt=date
).reset_index(level=0).rename(columns={'level_0':'code'})
data_groups = data.groupby('code')
result['stocks']+=stocks_list
result['months']+=[date.strftime('%Y-%m')]*stocks.shape[0]
result['Q']+=[calcQ(data_bar) for name,data_bar in data_groups]
result['return']+=list((next_month_bar['close']-next_month_bar['open'])/next_month_bar['open'])
df = pd.DataFrame(result)
'''
因為該段程式需要運行的時間較長,所以將運行出的結果存盤到檔案中
之后的研究可以直接讀取檔案
'''
df.to_excel('result.xlsx')
result = pd.read_excel('result.xlsx').drop('stocks',axis=1)
result_group = result.groupby('months')
#存盤月份和每月兩個序列的秩相關系數
result_df = {
'month':[],
'RankIC':[]
}
for month,month_result in result_group:
result_df['month'].append(month)
result_df['RankIC'].append(month_result.corr(method='spearman')['Q']['return'])
#以0.03作為閾值來劃分顯著和不顯著相關
result_df = pd.DataFrame(result_df)
ic_plus = result_df[result_df['RankIC']>0.03]
ic_minus = result_df[result_df['RankIC']<-0.03]
ic_other = result_df[(result_df['RankIC']>=-0.03) &(result_df['RankIC']<=0.03)]
print('顯著為負: ',ic_minus.shape[0])
print('顯著為正: ',ic_plus.shape[0])
print('不顯著:',ic_other.shape[0])
#可視化
fig = plt.figure(figsize=(14,5))
ax1 = fig.add_subplot(111)
ax1.bar(ic_other.index, ic_other['RankIC'], align='center', width=0.5, color='pink')
ax1.bar(ic_plus.index, ic_plus['RankIC'], align='center', width=0.5, color='r')
ax1.bar(ic_minus.index, ic_minus['RankIC'], align='center', width=0.5, color='b')
ax1.set_ylabel(u"Rank IC")
ax1.set_title(u"因子 RankIC 的月度序列")
ax1.set_xlabel(u"時間" )
ax1.grid(axis='y')
plt.xticks(result_df.index, result_df['month'],ro
顯著為負: 22
顯著為正: 7
不顯著: 8
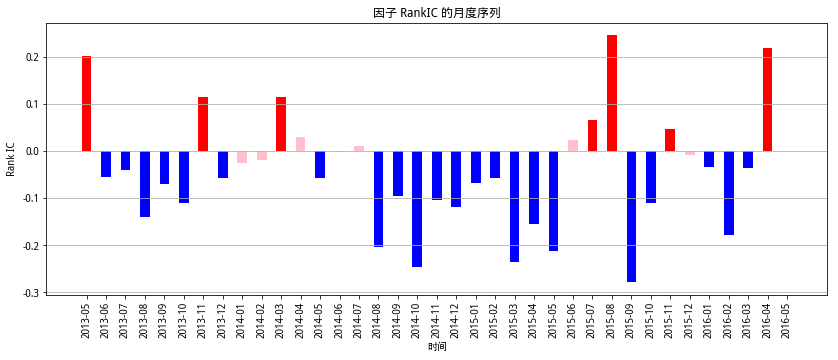
由結果來看,股票Q值與次月收益率在大部分時間顯著為負,這也許上文在定義Q時的分析一致,Q值越大,聰明錢對該只股票看跌,聰明錢在高位拋售該股,該股次月的收益率下降,
3.5 選股策略的構建與回測
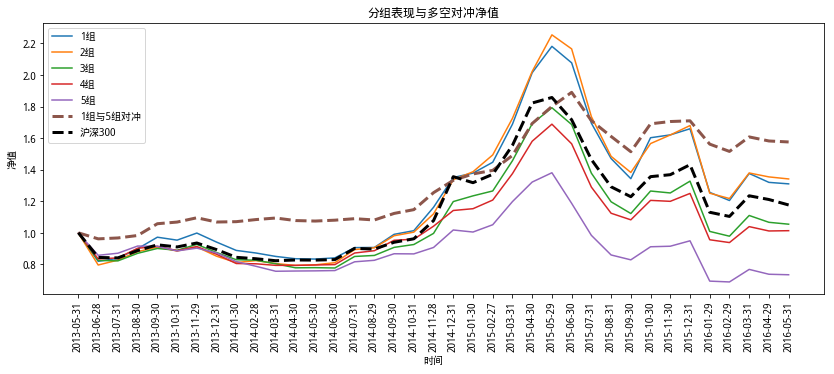
研究方法:每月月底將股票前10日分數資料的Q值排序、根據Q值由小到大等分為5類,每一類分別建倉,可視化每一類的收益情況,
研究結果:在策略運行的時間周期內,5類持倉的收益率具有單調性,即Q值小的組收益率大,這也可以由之前的分析解釋,因為Q值小意味著聰明錢在低價吸入,聰明錢具有看多的情緒,
策略構建:基于研究結果,可構建兩種策略,
一種是多空對沖策略,即做多第一組的股票,做空第五組的股票,進行對沖,該對沖策略在本文的回測中的收益率高于五組分別做多的收益,且最大回撤更低,在原研報的所有A股的樣本中,對沖策略的收益率位于第一組和第三組之間,且最大回撤更低,
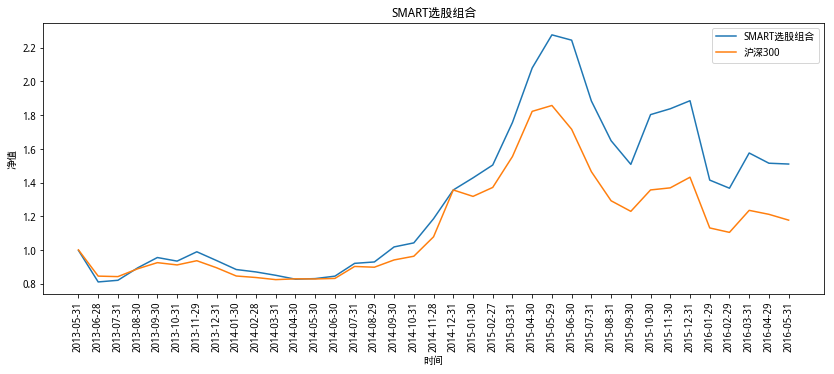
另一種是做多第一組的股票,但是要剔除前期漲幅過高的五分之一的樣本,原研報將這種選股組合稱為SMART組合,
回測規則:每月月底計算Q值、選股、調倉,等權重配置股票,即讓每只股票的(價格*持有數)占總資產的比例相同,初始資金100萬,交易費率0.003,選股空間、與上文相同,
為了方便回測,我們新建了一個倉位類,來對應每一組的賬戶,該類具有當前持有的股票串列、對應的價格、每只股票持有數量、現金、賬戶凈值這些屬性提供了更新價格、調整倉位的功能,并可以維護現金和賬戶凈值,
class Position():
'''
為了方便回測,我們新建了一個倉位類,來對應每一組的賬戶,
該類具有當前持有的股票串列、對應的價格、每只股票持有數量、現金、賬戶凈值這些屬性
提供了更新價格、調整倉位的功能,并可以維護現金和賬戶凈值
'''
def __init__(
self,
stocks=np.array([]),
price=np.array([]),
weight=np.array([]),
cash=0
):
self.stocks = stocks
self.price = price
self.weight = weight
self.cash = cash
if not self.stocks.size:
self.net_value = self.cash
else:
self.net_value = (self.weight*self.price).sum()+self.cash
def update_price(self,price):
#傳入一個價格序列,對應持有股票的最新價格
for i,p in enumerate(price):
if not np.isnan(p):
self.price[i] = p
self.net_value = (self.weight*self.price).sum()+self.cash
def change_position(self,new_stocks,price,commission):
#更新倉位,傳入篩選出的股票串列和對應的價格
for i,stock in enumerate(self.stocks):#原有股票不在新串列中,需要賣出
if stock not in new_stocks:
self.cash+=self.price[i]*self.weight[i]*(1-commission)
#計算每一只股票應持有的數量
new_weight = self.net_value*0.99/len(new_stocks)/price
new_weight = [int(_) for _ in new_weight]
for i,stock in enumerate(self.stocks):#原有股票在新串列中,需要調整數量
if stock in new_stocks:
weight_chg = new_weight[list(new_stocks).index(stock)] - self.weight[i]
self.cash -= self.price[i]*weight_chg\
+ abs(self.price[i]*weight_chg)*commission
for i,stock in enumerate(new_stocks):#新增股票,需要買入
if stock not in new_stocks:
self.cash -= price[i]*new_weight[i]*(1+commission)
self.stocks = new_stockps
self.weight = new_weight
self.price = price
self.net_value = (self.weight*self.price).sum()+self.cash
多空對沖策略回測
capital_base = 1000000 #初始資金
commission = 0.003 #交易費率
#五組倉位
position_dict = {
1:Position(cash=capital_base),
2:Position(cash=capital_base),
3:Position(cash=capital_base),
4:Position(cash=capital_base),
5:Position(cash=capital_base)
}
#凈值統計
net_value_dict = {
'month':[],#時間
1:[],#每一組每個月月末的凈值序列
2:[],
3:[],
4:[],
5:[]
}
trade_days = get_trade_days(start_date='2013-04-30', end_date='2016-05-31')
days_count = len(trade_days)
for i,date in enumerate(trade_days):#遍歷交易日
if i == days_count-1 or trade_days[i+1].month != trade_days[i].month:
#print(trade_days[i])
#可交易股票
stocks = get_stocks(trade_days[i],index='000300.XSHG')
stocks_list = list(stocks.index)
#股票的前10天的分鐘資料,并根據股票分組
data = get_minute_data(
stocks_list,
2400,
end_dt=trade_days[i]
).reset_index(level=0).rename(columns={'level_0':'code'})
data_groups = data.groupby('code')
#計算每一只股票的Q值
stocks['Q'] = [calcQ(data_bar) for name,data_bar in data_groups]
#Q值排序
stocks = stocks.sort_values(by='Q').reset_index()
lens = stocks.shape[0]
#根據Q值的大小等分為5組
s_1 = stocks[stocks['Q'].isin(stocks['Q'][:int(0.2*lens)])].reset_index()
s_2 = stocks[stocks['Q'].isin(stocks['Q'][int(0.2*lens):int(0.4*lens)])].reset_index()
s_3 = stocks[stocks['Q'].isin(stocks['Q'][int(0.4*lens):int(0.6*lens)])].reset_index()
s_4 = stocks[stocks['Q'].isin(stocks['Q'][int(0.6*lens):int(0.8*lens)])].reset_index()
s_5 = stocks[stocks['Q'].isin(stocks['Q'][int(0.8*lens):])].reset_index()
#如果有持倉資料
if position_dict[1].stocks.size:
#更新持倉價格
for cls in range(1,6):
position_dict[cls].update_price(
price=get_price(
security = list(position_dict[cls].stocks),
count = 1,
end_date = trade_days[i],
panel = False
)['close']
)
#調倉
position_dict[1].change_position(new_stocks=s_1['index'],price = s_1['price'],commission=commission)
position_dict[2].change_position(new_stocks=s_2['index'],price = s_2['price'],commission=commission)
position_dict[3].change_position(new_stocks=s_3['index'],price = s_3['price'],commission=commission)
position_dict[4].change_position(new_stocks=s_4['index'],price = s_4['price'],commission=commission)
position_dict[5].change_position(new_stocks=s_5['index'],price = s_5['price'],commission=commission)
#添加該月的結果
net_value_dict['month'].append(trade_days[i])
for cls in range(1,6):
net_value_dict[cls].append(position_dict[cls].net_value)
continue
#可視化
net_value_df = pd.DataFrame(net_value_dict)
net_value_df.to_excel('net_value_df.xlsx')
net_value_df = pd.DataFrame(net_value_dict)
plt.figure(figsize=(14,6))
net_value_df[1] = (net_value_df[1]/1000000)
net_value_df[2] = (net_value_df[2]/1000000)
net_value_df[3] = (net_value_df[3]/1000000)
net_value_df[4] = (net_value_df[4]/1000000)
net_value_df[5] = (net_value_df[5]/1000000)
net_value_df['1與5對沖'] = net_value_df[1] - net_value_df[5]+1
index=get_bars(
'000300.XSHG',
count = 37,
unit = '1M',
fields = ['close'],
df = True,
include_now=True,
end_dt = '2016-05-31'
)['close']
index = index/index[0]
fig = plt.figure(figsize=(14,5))
ax = fig.add_subplot(111)
ax.plot(net_value_df['month'].index,net_value_df[1],label='1組')
ax.plot(net_value_df['month'].index,net_value_df[2],label='2組')
ax.plot(net_value_df['month'].index,net_value_df[3],label='3組')
ax.plot(net_value_df['month'].index,net_value_df[4],label='4組')
ax.plot(net_value_df['month'].index,net_value_df[5],label='5組')
ax.plot(net_value_df['month'].index,net_value_df['1與5對沖'],label='1組與5組對沖',linestyle='--',linewidth=3)
ax.plot(net_value_df['month'].index,index,linestyle='--',label='滬深300',color='black',linewidth=3)
ax.set_xlabel(u"時間")
ax.set_ylabel(u"凈值")
ax.set_title(u"分組表現與多空對沖凈值")
plt.xticks(net_value_df['month'].index,net_value_df['month'],rotation=90)
plt.legend()
SMART選股策略
capital_base = 1000000
position_dict_2 = {
1:Position(cash=capital_base)
}
net_value_dict_2 = {
'month':[],
1:[]
}
trade_days = get_trade_days(start_date='2013-04-30', end_date='2016-05-31')
days_count = len(trade_days)
commission = 0.003
for i in range(days_count):
if i == days_count-1 or trade_days[i+1].month != trade_days[i].month:
stocks = get_stocks(trade_days[i],index='000300.XSHG')
stocks_list = list(stocks.index)
data = get_minute_data(
stocks_list,
2400,
end_dt=trade_days[i]
).reset_index(level=0).rename(columns={'level_0':'code'})
data_groups = data.groupby('code')
stocks['Q'] = [calcQ(data_bar) for name,data_bar in data_groups]
stocks = stocks.sort_values(by='Q').reset_index()
lens = stocks.shape[0]
s_1 = stocks[stocks['Q'].isin(stocks['Q'][:int(0.2*lens)])].reset_index(drop=True)
month_bar = get_bars(
list(s_1['index']),
count = 1,
unit = '1M',
fields = ['open','close'],
df = True,
include_now=True,
end_dt = trade_days[i]
).reset_index(drop=True)
#剔除漲幅過高的20%的股票
s_1['ratio'] = (month_bar['close'] - month_bar['open'])/month_bar['open']
s_1 = s_1.sort_values(by='ratio').reset_index(drop=True)
lens = s_1.shape[0]
s_1 = s_1[s_1['ratio'].isin(s_1['ratio'][:int(0.8*lens)])]
if position_dict_2[1].stocks.size:
position_dict_2[1].update_price(
price=get_price(
security = list(position_dict_2[1].stocks),
count = 1,
end_date = trade_days[i],
panel = False
)['close']
)
position_dict_2[1].change_position(new_stocks=s_1['index'],price = s_1['price'],commission=commission)
net_value_dict_2['month'].append(trade_days[i])
net_value_dict_2[1].append(position_dict_2[1].net_value)
#可視化
net_value_df_2 = pd.DataFrame(net_value_dict_2)
net_value_df_2[1] = (net_value_df_2[1]/1000000)
index=get_bars(
'000300.XSHG',
count = 37,
unit = '1M',
fields = ['close'],
df = True,
include_now=True,
end_dt = '2016-05-31'
)['close']
index = index/index[0]
fig=plt.figure(figsize=(14,5))
ax = fig.add_subplot(111)
ax.plot(net_value_df_2['month'].index,net_value_df_2[1],label='SMART選股組合')
ax.plot(net_value_df_2['month'].index,index,label='滬深300')
ax.set_xlabel(u"時間")
ax.set_ylabel(u"凈值")
ax.set_title(u"SMART選股組合")
plt.xticks(net_value_df_2['month'].index,net_value_df['month'],rotation=90)
plt.legend()
4.總結
本文基本復現了【方正證券-跟蹤聰明錢:從分鐘行情資料到選股因子】的研究內容,同時得到了與原研報相近的結果,
本文的不足:
1.因為軟硬體條件的限制,壓縮了原研報的樣本空間,
2.缺少原研報中因子風險特性的研究,
5.本文作者
蔡金航 哈爾濱工業大學威海校區 計算機科學與技術學院
舒意茗 哈爾濱工業大學威海校區 汽車工程學院
寫在最后
我們是國內普通高校的在校學生,同時也是量化投資的初學者,我們的學校不是清北復交,也沒有金融工程實驗室,同時地處三線小城,因此我們在校期間較難獲得量化實習機會,但我們期待與業界進行溝通、交流,
蔡金航同學是我們其中的一員,其在尋找暑期量化實習時,收到了幾家私募和券商金工組的筆試邀請,筆試內容皆為在給定時間內復現出一篇金工研報,蔡同學受到啟發,發覺復現金工研報是我們學習量化策略、鍛煉程式設計能力同時也是與業界交流的很好的途徑,
在蔡同學的建議下,我們開啟研報復現系列的創作,記錄我們的學習程序,并將我們的創作內容分享出來,與讀者們一起交流、學習、進步,
我們的水平有限,創作的內容難免會有錯誤或不嚴謹的內容,我們歡迎讀者的批評指正,
如果您對我們的內容感興趣,請聯系我們:cai_jinhang@foxmail.com
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/275484.html
標籤:python