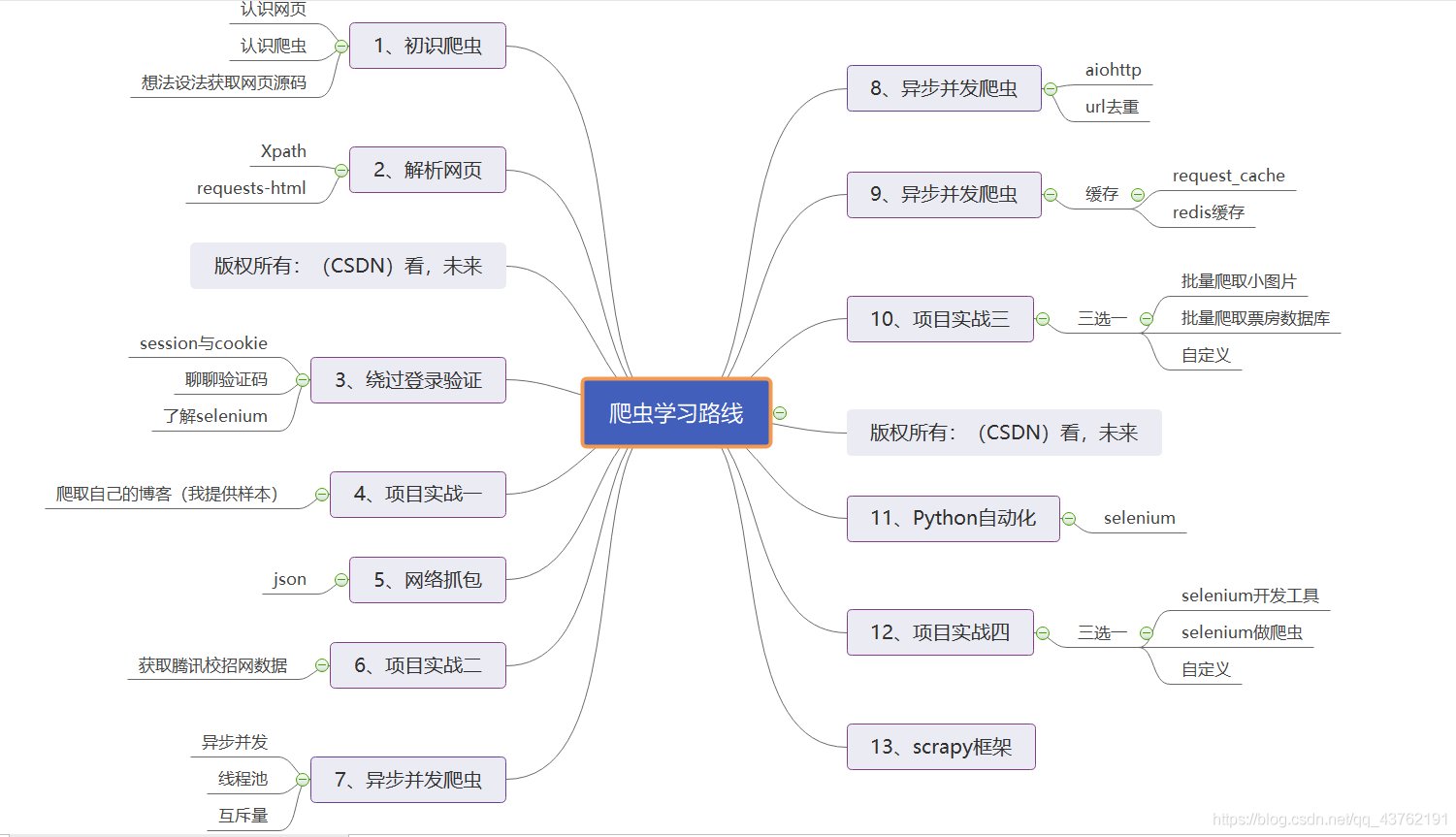
文章目錄
- 系列導讀
- 這個系列是什么?
- 本系列配套資源
- 已加入CSDN“蓄力計劃”,打造精品系列
- 系列適用人群
- 認識HTML源代碼
- 決議網頁
- 認識Xpath
- Xpath使用流程
- Xpath路徑提取
- Xpath基本語法節選
- Xpath函式封裝
- Xpath實操爬取小demo
- requests-html
- requests-html獲取網頁原始碼
- 抓取標簽
上圖已魔法反爬,哈哈哈,想爬就爬唄,不攔著,
系列導讀
這個系列是什么?
本系列會寫一些什么內容,在開頭那張思維導圖里面寫了個大概了,至于導圖里面沒有寫出來的,就作為一些探索的內容吧,
我之前有寫過一個Python爬蟲自學系列,反響也還可以,不過那個系列里面的不少鏈接是另一個付費專欄里面的內容了,相對要閱讀就有些困難,
這個系列是在原有知識點的基礎上,加入一些新的知識點,重新寫的一個系列,不出意外,這個系列將會是我在Python爬蟲領域的最后一個教學系列,
本系列配套資源
這個系列是會有配套視頻課的,將會發布在CSDN學院上,當然,如果還是喜歡看博文的朋友可以看我的這個系列,
已加入CSDN“蓄力計劃”,打造精品系列
由于參加了CSDN的“蓄力計劃”,諸多條條框框,總結一下就是為讀者服務,所以這個系列會寫的很認真,畢竟我想上榜啊,大家多多支持,
系列適用人群
有Python基本語法基礎的人,分支回圈、函式、類、模塊、例外處理等,
不喜歡枯燥乏味的填鴨式教育的朋友,
肯動手實操為最佳,
認識HTML源代碼
說到決議網頁,那么我們是不是要自己先了解一下這些個網頁呢?
來看一下這個網頁:
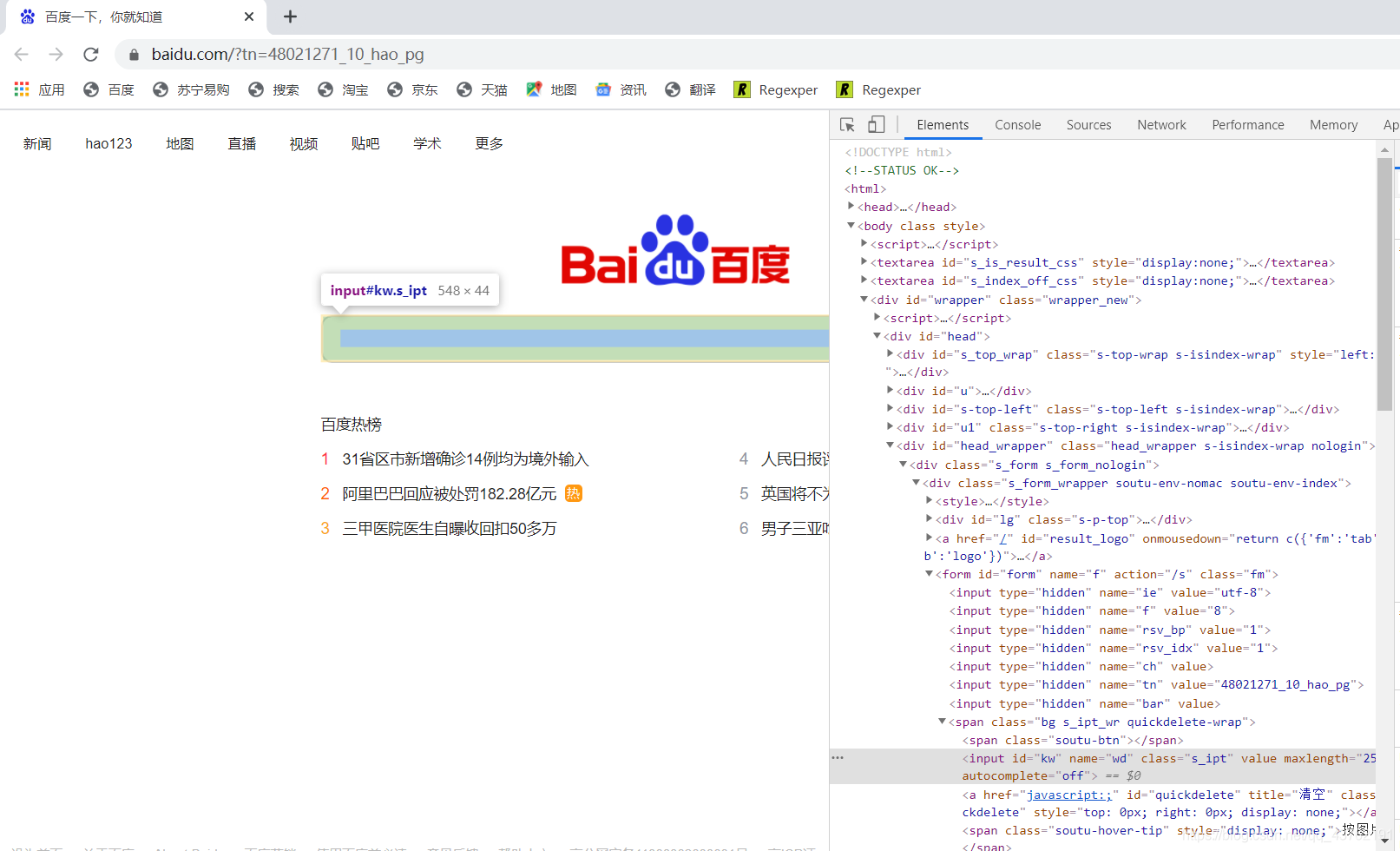
決議網頁
來,我們就拿這個網頁來研究一下它的構造,后面其他的網頁都是共通的,
首先可以看到在網頁的左側,輸入框有顏色,在網頁的右側,也有一段有顏色的代碼,這是怎么肥四呢?
這叫做標記,或者叫搜索,或者叫映射,愛怎么叫怎么叫,咱只需要知道左右兩個有顏色的地方是一一對應的,
那,要怎么根據頁面元素去搜索它對應的代碼塊兒呢,其實不難哈,
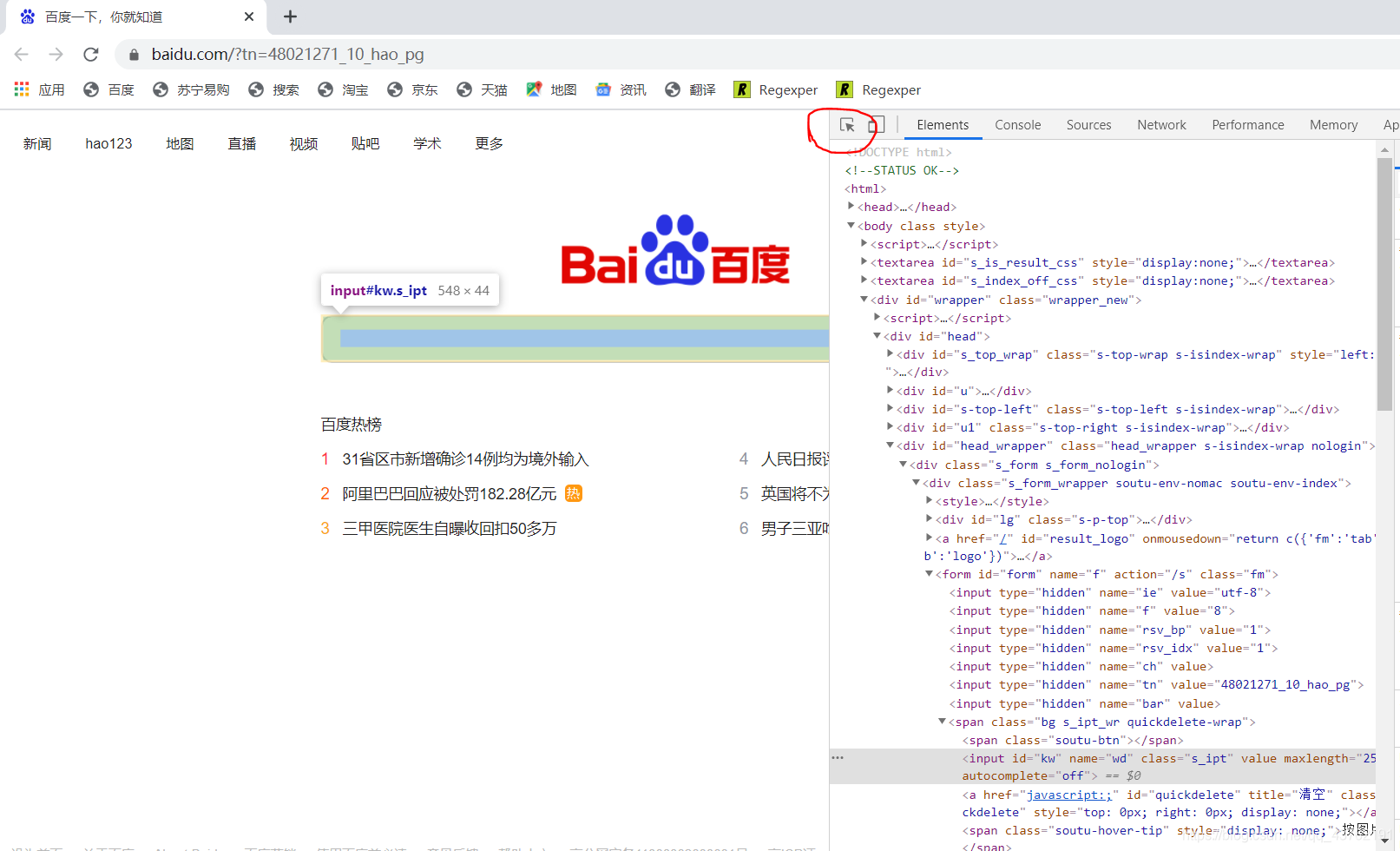
先點擊我圈出來的地方,再到網頁上點擊對應的元素即可,
我們再把目光聚焦在右側的代碼上,可以看到很多的三角形,稍微思索一下,就知道那些三角形是上下級的關系吧,
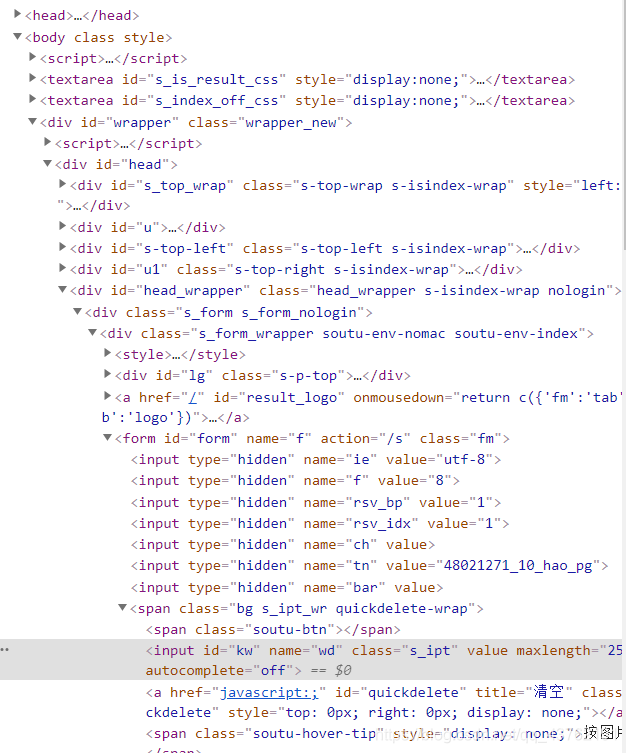
這些三角形是可以伸縮的,我們把每個三角形以及它包含的所有內容叫做:標簽,
(當然,有些沒有三角形的也叫標簽,比方說)

怎么看標簽呢,以"<“為標簽的起始,”>"為標簽的結尾,
這時候就會有同級標簽和上下級標簽的區分了,我習慣把它們之間的關系稱呼為:父標簽、子標簽、兄弟標簽以及祖標簽,
這些概念在后面講Xpath標簽提取的時候會很重要,都長點記性哈,
認識Xpath
XPath 是一種將 XML 檔案的層次結構描述為關系的方式,因為 HTML 是 由 XML 元素組成的,因此我們可以使用 XPath 從 HTML 檔案中定位和選擇元素,
要說從網頁原始碼中提取出資料來,那方法其實不少的,比方說某些人動不動就上來一個正則運算式啊,本系列主干中不提正則運算式,最多作為“番外篇”加入,怎么簡單怎么來嘛,
也有些人會用beautifulsoup,我初學的時候也是學這個庫的,后來發現有諸多的不便性,于是果斷放棄了,
其實也沒多少不便,就是學完Xpath之后怎么看soup怎么不順眼,
來看一下它們仨兒的性能對比哈:
| 抓取方法 | 性能 | 使用難度 | 安裝難度 |
|---|---|---|---|
| 正則 | 快 | 困難 | 內置模塊 |
| beautifulsoup | 慢 | 簡單 | 簡單(純Python) |
| lxml | 快 | 簡單 | 不難 |
可以看出beautiful為什么慢了吧,在pycharm下,沒有太多的安裝困難啦,
Xpath使用流程
看完Xpath的性能優勢之后,我們來看一下Xpath是如何決議一個網頁,并獲取到我們所需要的資料的,
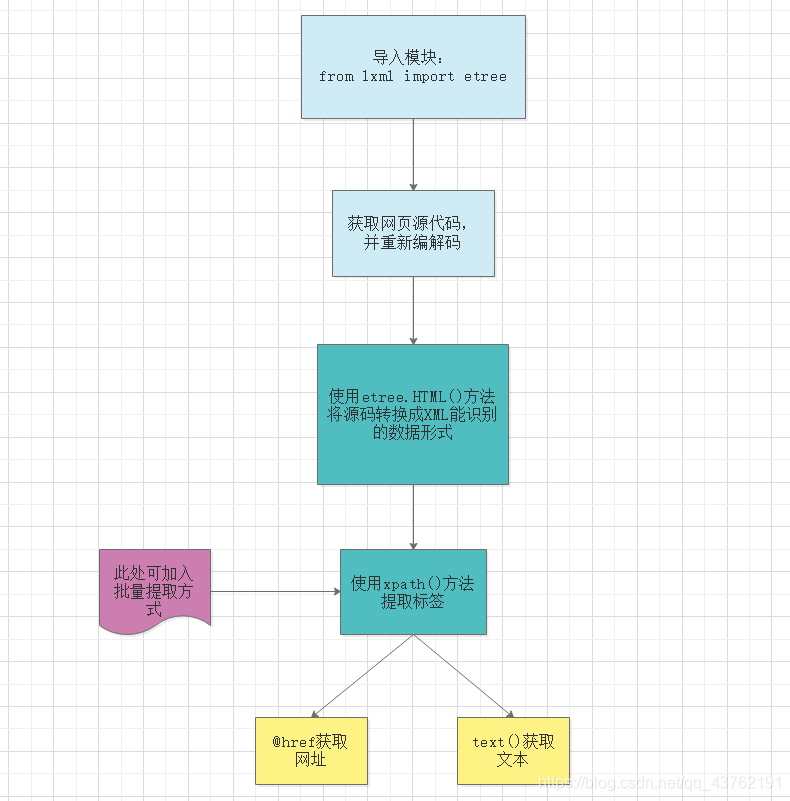
別急,我來解釋一下這張圖,
1、首先,匯入Xpath支持的模塊,位于lxml包里面的etree模塊,如果用pycharm時出現“報錯”,別管它,能運行的,歷史遺留原因,
2、其次,獲取網頁原始碼,這里需要使用content方法來對獲取到的網頁資料進行轉換,不能使用text,
3、接著,對轉換出的資料進行編解碼,不然會看到一堆的亂碼,
4、HTML方法,沒什么好說的,
5、xpath方法,這里需要傳入引數為待提取標簽的Xpath路徑,關于這個路徑,一會兒會講,
6、批量提取,關于這個批量提取,一會兒也會講,
7、沒什么好說的了,
Xpath路徑提取
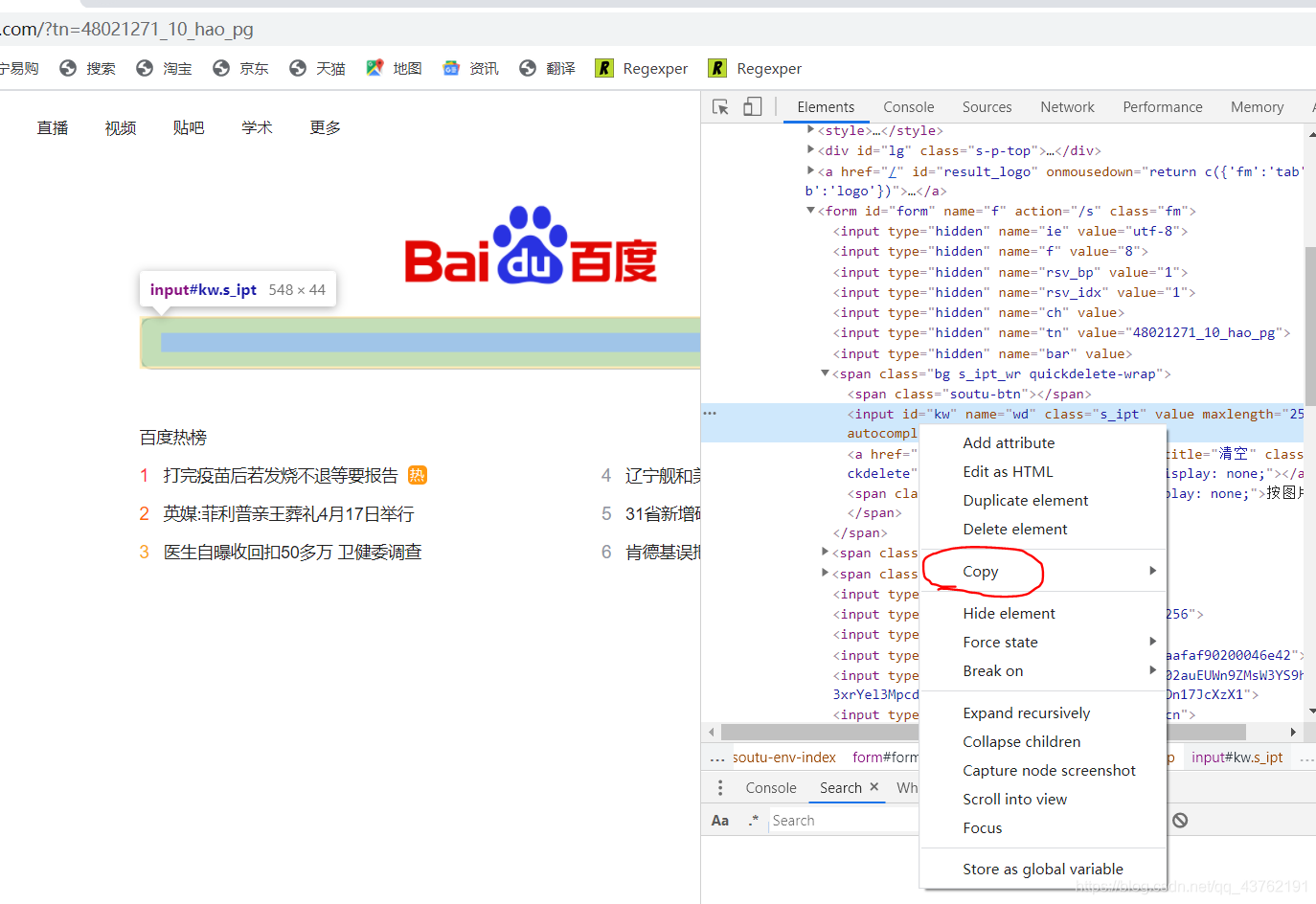
打開谷歌瀏覽器,在標簽上方,進行一次右擊,點擊那個“copy”,選擇里面的“Copy Xpath”,沒啥事兒的話就不要去“Copy Full Xpath”了,
這里我們統一使用谷歌瀏覽器,
這時候相對Xpath路徑我們就拿到了,
Xpath基本語法節選
Xpath的語法太多了,但是我們一般用不到那么多,沒必要死記硬背,我給你們挑一些常用的就好,
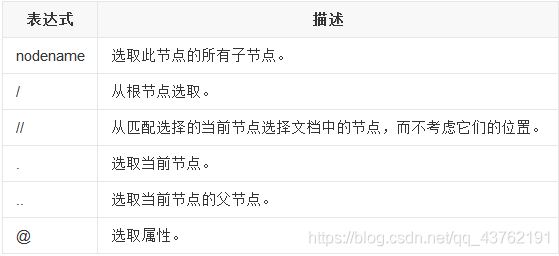
示例:


還有一個text()方法注意一下即可,沒必要搞那么多的花里胡哨的,
Xpath函式封裝
講到這里Xpath部分也差不多了,我們來封裝一下函式,并做一個小demo,
如果是要提取單個路徑下的標簽,采用以下方法即可:
def get_data(html_data,Xpath_path):
'''
這是一個從網頁源資料中抓取所需資料的函式
:param html_data:網頁源資料 (單條資料)
:param Xpath_path: Xpath尋址方法
:return: 存盤結果的串列
'''
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "") #洗掉資料中的注釋
tree = etree.HTML(data) #創建element物件
el_list = tree.xpath(Xpath_path)
return el_list
如果是要從多個Xpath中提取資料,可以采用以下方法:
def get_many_data(html_data,Xpath_path_list):
'''
通過多個Xpath對資料進行提取
:param html_data: 原始網頁資料
:param Xpath_paths: Xpath尋址串列
:return: 二維串列,一種尋址資料一個串列
'''
el_data = []
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "")
tree = etree.HTML(data)
for Xpath_path in Xpath_path_list:
el_list = tree.xpath(Xpath_path)
el_data.append(el_list)
el_list = [] #安全起見就自己清理了吧
return el_data
至于要不要修修補補,就看個人喜好啦,
Xpath實操爬取小demo
我們來做一個小demo,獲取

這里的熱榜文本和網址,并一一配對吧,
首先,我們審查以下網頁:
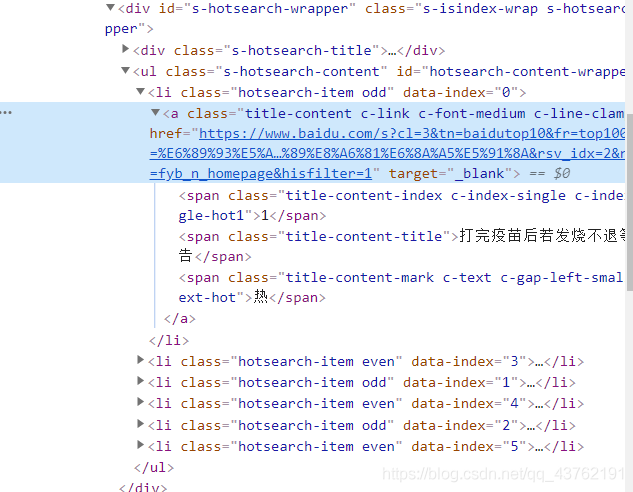
學的快的人看出兩個線索,有經驗的人看出三個線索:
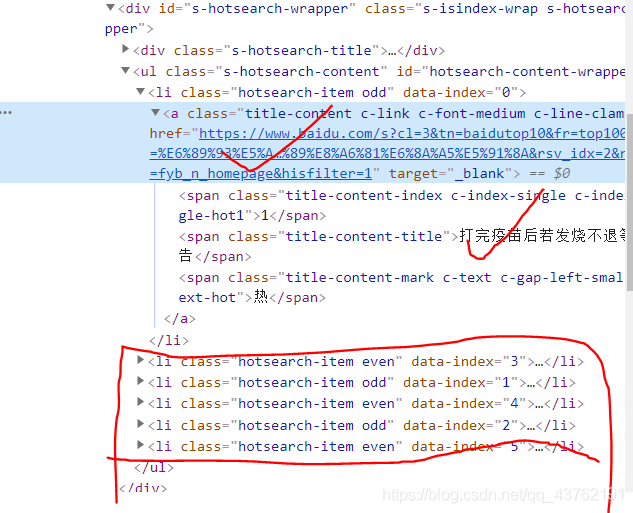
看到網址和文本是應該的,不過我們要一次性全部拿下,就需要查看其它的幾個標簽所在位置,然后,找到我們所需要的所有標簽的最小公共祖宗標簽,
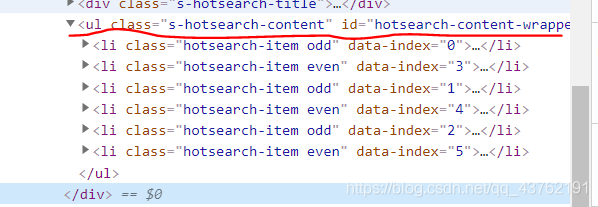
將標簽疊起來,我們很容易的發現它們都處在<ul>這個標簽下,
那就有辦法一次全部提取出來了,如果沒想明白的話建議翻到上面Xpath基本語法節選部分再想明白,
先對第一個標簽進行提取,發現文本路徑為://*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]
而網址路徑為://*[@id="hotsearch-content-wrapper"]/li[1]/a/@href
很顯然,li[1]代表的是第一個標簽,而下面五個標簽分別對應li[2]、li[3]、以此類推,此處可以優化為 //li
而對于 li標簽以下的部分,我們可以用簡單粗暴的 全部提取//的方式提取文本嗎?并不行,因為在li標簽下有多類文本,而我們只要一種,
所以我們的Xpath路徑這樣寫:
//*[@id="hotsearch-content-wrapper"]//li/a
./span[2]/text() | ./@href
或者這樣:
//*[@id="hotsearch-content-wrapper"]//li/a/span[2]/text() | //*[@id="hotsearch-content-wrapper"]//li/a/@href
一個是時間,一個是空間,自己選一個吧,
所以代碼也就很快出來了啊:
import requests #做爬蟲比較常用的一個包
import random
import time
from lxml import etree
url = 'https://www.baidu.com/?tn=48021271_10_hao_pg'
def get_html(url,header_list,sleep_time):
times = 3
try:
res = requests.get(url=url, headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"})
if res.status_code >= 200 and res.status_code<300:
time.sleep(sleep_time)
return res
else:
return None
except Exception as e:
print(e)
if times>0:
print("機會次數:"+str(times))
get_html(url, header_list,sleep_time)
else:
print("無法爬取")
def get_data(html_data, Xpath_path):
'''
這是一個從網頁源資料中抓取所需資料的函式
:param html_data:網頁源資料 (單條資料)
:param Xpath_path: Xpath尋址方法
:return: 存盤結果的串列
'''
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "") # 洗掉資料中的注釋
tree = etree.HTML(data) # 創建element物件
el_list = tree.xpath(Xpath_path)
return el_list
res = get_html(url=url,header_list=header_list,sleep_time=2)
#print(res.content)
el_list = get_data(res,'//*[@id="hotsearch-content-wrapper"]//li/a')
for el in el_list:
e = el.xpath('./span[2]/text() | ./@href')
print(e)
得到結果:
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E6%89%93%E5%AE%8C%E7%96%AB%E8%8B%97%E5%90%8E%E8%8B%A5%E5%8F%91%E7%83%A7%E4%B8%8D%E9%80%80%E7%AD%89%E8%A6%81%E6%8A%A5%E5%91%8A&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '打完疫苗后若發燒不退等要報告']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E8%BE%BD%E5%AE%81%E8%88%B0%E5%92%8C%E7%BE%8E%E5%9B%BD%E9%A9%B1%E9%80%90%E8%88%B0%E8%BF%91%E8%B7%9D%E7%A6%BB%E7%A2%B0%E9%9D%A2&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '遼寧艦和美國驅逐艦近距離碰面']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E5%93%88%E9%87%8C%E5%B0%86%E8%BF%94%E8%8B%B1%E5%8F%82%E5%8A%A0%E8%8F%B2%E5%88%A9%E6%99%AE%E4%BA%B2%E7%8E%8B%E8%91%AC%E7%A4%BC&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '哈里將返英參加菲利普親王葬禮']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E7%BE%8E%E9%BB%91%E4%BA%BA%E5%86%9B%E5%AE%98%E9%81%AD%E7%99%BD%E4%BA%BA%E8%AD%A6%E5%AF%9F%E5%96%B7%E8%BE%A3%E6%A4%92%E6%B0%B4&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '美黑人軍官遭白人警察噴辣椒水']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E5%8C%BB%E7%94%9F%E8%87%AA%E6%9B%9D%E6%94%B6%E5%9B%9E%E6%89%A350%E5%A4%9A%E4%B8%87+%E5%8D%AB%E5%81%A5%E5%A7%94%E8%B0%83%E6%9F%A5&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '醫生自曝識訓扣50多萬 衛健委調查']
['https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E8%82%AF%E5%BE%B7%E5%9F%BA%E8%AF%AF%E6%8A%8A%E6%B6%88%E6%AF%92%E6%B0%B4%E7%BB%99%E5%A5%B3%E5%AD%A9%E9%A5%AE%E7%94%A8&rsv_idx=2&rsv_dl=fyb_n_homepage&hisfilter=1', '肯德基誤把消毒水給女孩飲用']
注意看這個結果,排列的也是很有規律性的,
requests-html
requests-html和其他決議HTML庫最大的不同點在于HTML決議庫一般都是專用的,所以我們需要用另一個HTTP庫先把網頁下載下來,然后傳給那些HTML決議庫,而requests-html自帶了這個功能,所以在爬取網頁等方面非常方便,
有了上面的鋪墊,下面這些應該是輕車熟路了,我就不多說,直接上實操,
requests-html獲取網頁原始碼
from requests_html import HTMLSession
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改變標準輸出的默認編碼
session = HTMLSession()
r = session.get('https://www.baidu.com/?tn=48021271_10_hao_pg',headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"})
# 查看頁面內容
print(r.html.html)
print(r.html.links) # 獲取所有鏈接
print(r.html.text) # 獲取所有文本
print(r.html.absolute_links) # 獲取全部絕對鏈接
print(r.html.raw_html) # 回傳二進制
抓取標簽
這里抓取標簽依舊是Xpath,不過就是把程序簡化了,其實用我們上面封裝好的函式也不比這個麻煩,
這里只講Xpath,這需要另一個函式xpath的支持,它有4個引數如下:
- selector,要用的XPATH路徑;
- clean,布林值,如果為真會忽略HTML中style和script標簽造成的影響(原文是sanitize,大概這么理解);
- first,布林值,如果為真會回傳第一個元素,否則會回傳滿足條件的元素串列;
- _encoding,編碼格式,
print(r.html.xpath("//div[@id='menu']", first=True).text)
print(r.html.xpath("//div[@id='menu']/a"))
print(r.html.xpath("//div[@class='content']/span/text()"))
如果僅僅是獲取這些東西的話,我建議直接使用lxml,因為這個模塊的底層也是封裝了lxml、requests、beautifulsoup等模塊包的,
今天先到這里啦,下一篇見啦,
(不要問我為什么不講requests-html對JavaScript的支持,問就是目前沒必要,后面有更簡單的方法)

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/275488.html
標籤:python
上一篇:有趣python小程式系列之一