智能垃圾分類
2021.4.9,浙江省舉辦了第七屆工程訓練大賽,我們組參加的是垃圾分類的專案,我們組順利挺進決賽,但是我們看決賽規則并沒有標注多種垃圾分類,我們沒有完全的準備好應對多種垃圾分類,所以與國賽是無緣了!
影像識別
- 智能垃圾分類
- 前言
- (1)軟體安裝準備
- (2)垃圾分類的訓練模型
- (3)Qt界面設計
- 總結
前言
隨著人工智能的不斷發展,機器學習這門技術也越來越重要,很多人都開啟了學習機器學習,本文通過競賽就介紹了機器學習的基礎內容,和參加競賽需要的界面設計 我們預賽的規則如下,但是我對顯示垃圾名稱有點想不明白,分四種垃圾不就好了,還要把菜葉橘子皮分辨出來作甚?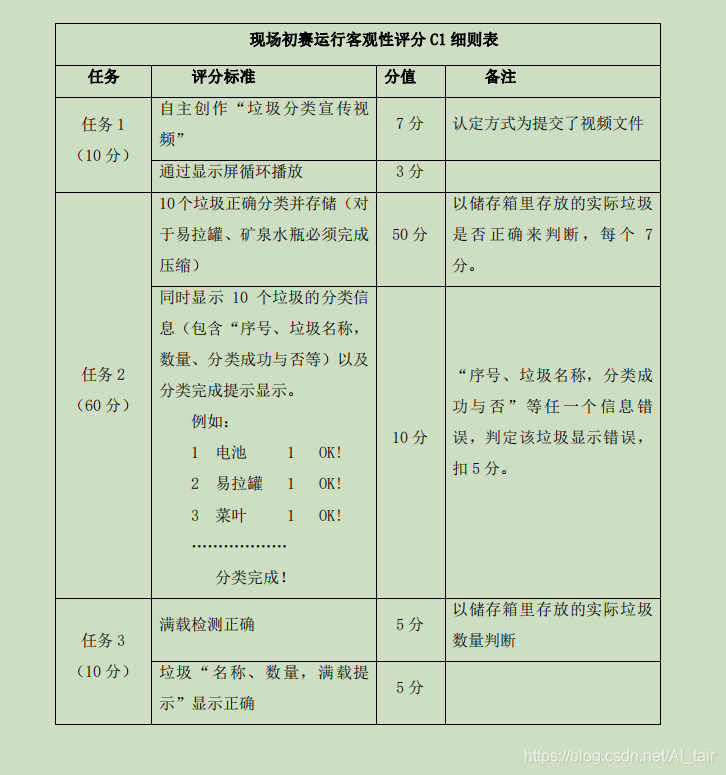
我先自我介紹一下,我是來自計算機科學與技術一名大二本科生,我和我的兩名隊友參加第七屆工程訓練大賽,我在隊伍中擔任得任務是進行影像處理,模型訓練和,stm322F4串口通訊與界面設計,所以我接下來主要講述我實作得代碼,講的不好,望諒解!
我們比賽的時候垃圾是類似這樣的!

(1)軟體安裝準備
軟體管家中都有這些軟體下載,大家不妨去微信公眾號關注一下,下載操作步驟是真的詳細!!
我安裝了Anaconda pycharm python3.6(版本不要太高) Qt界面設計軟體
通過python3.6進行tensflow的下載
其他的各種庫的下載就需要你先搭建好環境,然后再pycharm中如下的位置進行下載
格式: pip install numpy (以numpy為例)
我們用的筆記本電腦進行訓練,然后將模型訓練好放在微機win10中進行運行界面顯示(注意:訓練的機子一定要好!!!條件允許直接上臺式電腦)
(2)垃圾分類的訓練模型
首先,我展示我參加比賽的最終代碼的檔案如下
然后我們對于垃圾分類這件事本身來看,好像很好理解,就是區分垃圾,可是怎么實作的?可能一點方向都沒有,那么我們直接先從上面的檔案開始著手會快很多,
就好比我們是怎么進行分類物品,是不是一個反復學習的程序,但是最基礎是什么?是我們具備學習的能力,這就是程式模型的框架
第一個.py檔案中是訓練模型,框架是使用 keras 中的 resnet 模型,然后我們通過訓練,將這個模型訓練成具有針對性的模型,專門處理影像識別,

這個是訓練集,就是在dataset1檔案夾中放入圖片(我當時是分類成10種,每種420張圖片)來進行訓練,不過硬體條件允許的話,照片數量越多越好,
不過要特別注意放入圖片不要有中文路徑,并且每種檔案影像數量盡量相同
# 處理好的224*224檔案夾放在本程式同目錄下...
train_path_A = './dataset1/train/A/'
train_path_B = './dataset1/train/B/'
train_path_C = './dataset1/train/C/'
train_path_D = './dataset1/train/D/'
train_path_E = './dataset1/train/E/'
train_path_F = './dataset1/train/F/'
train_path_G = './dataset1/train/G/'
train_path_H = './dataset1/train/H/'
train_path_I = './dataset1/train/I/'
train_path_J = './dataset1/train/J/'
mglist_train_A = os.listdir(train_path_A) #匯入訓練串列
imglist_train_B = os.listdir(train_path_B)
imglist_train_C = os.listdir(train_path_C)
imglist_train_D = os.listdir(train_path_D)
imglist_train_E = os.listdir(train_path_E)
imglist_train_F = os.listdir(train_path_F)
imglist_train_G = os.listdir(train_path_G)
imglist_train_H = os.listdir(train_path_H)
imglist_train_I = os.listdir(train_path_I)
imglist_train_J = os.listdir(train_path_J)
這里定義兩個 numpy 物件,X_test輸入陣列 和 Y_test標簽陣列,np.empty為創建一個空的多維陣列,
3 是圖片的通道數(RGB三色)
因為一共有十種圖片,所以Y_train() 第二項設定為 10
X_train = np.empty((len(imglist_train_A) + len(imglist_train_B) + len(imglist_train_C) + len(imglist_train_D) + len(imglist_train_E)
+ len(imglist_train_F) + len(imglist_train_G) + len(imglist_train_H) + len(imglist_train_I) + len(imglist_train_J), 224, 224, 3))
Y_train = np.empty((len(imglist_train_A) + len(imglist_train_B) + len(imglist_train_C) + len(imglist_train_D) + len(imglist_train_E)
+ len(imglist_train_F) + len(imglist_train_G) + len(imglist_train_H) + len(imglist_train_I) + len(imglist_train_J), 10))
訓練好的模型保存在以下的模型上

#保存變數訓練檔案.h5
model.save('my_resnet_model_ABCD.h5')
model.save_weights('my_resnet_weights_model_ABCD.h5') #保存變數訓練檔案
#載入變數訓練檔案.h5
model = tf.keras.models.load_model('my_resnet_model_ABCD.h5')
model.load_weights('my_resnet_weights_model_ABCD.h5')
如果更換資料的訓練種類,這些引數需要對應更改 箭頭所指向的資料需要重點去看看,注釋上面都很詳細,就是batch_size最好是偶數
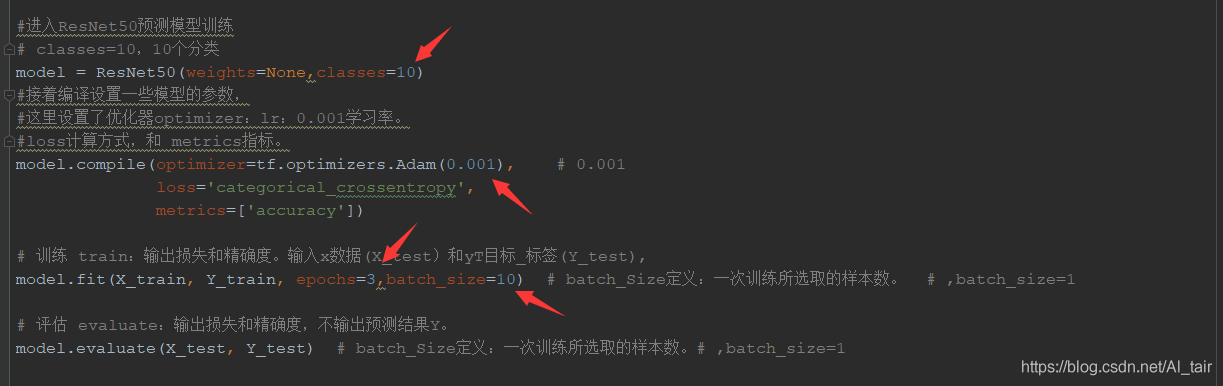
訓練模型有了,但是我們想讓它給予我們一個反饋準確值,這個時候就需要測驗集,訓練集和測驗集圖片的比例是10:3左右就可以
# 預測:predict(img)
for i in range(10):
img=X_test[i] #在資料集上取得一個樣本
print('某個測驗圖片X_test[i]的形態:', img.shape)
img=(np.expand_dims(img,0)) #表示在0位置添加一個維度資料[[[...],[...],[...],...,[...]]]
# tf.keras 模型輸入形態要增加一個維度(1,28,28)
print('某個測驗圖片資料形態:',img.shape)
predictions=model.predict(img)
#看下第0項圖片樣本的預測結果是什么
print('模型預測結果predictions[i]:',predictions)
#第0項圖片預測最大的概率項是哪一項,就是說最可能是哪種衣服
print('模型預測最大的概率項:',np.argmax(predictions))
#再查詢第0項圖片真正的標簽是什么樣的
print('查詢第i項圖片真正的標簽是:',Y_test[i])
#顯示一個圖片:
plt.figure()
plt.imshow(X_test[i])
plt.colorbar()
plt.grid(False)
plt.show()
(3)Qt界面設計
我當時做界面設計的時候,就是盡量跟著顯示屏大小去布置內容的,所以內容比較緊湊,背景是綠色是不難想的,和這個主題有關,
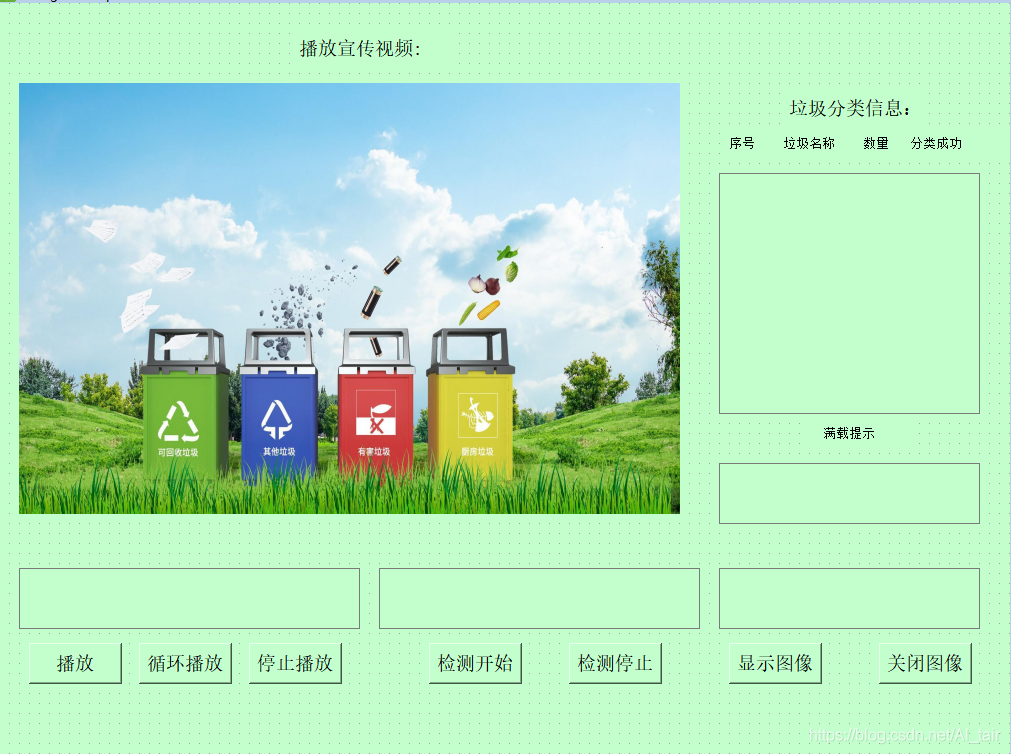
如何在textedit上顯示文字,如何觸發按鈕?
# 在各個write_ui...的界面textEdit...中寫入str
self.ms.text_print1.connect(self.write_ui1)
self.ms.text_print2.connect(self.write_ui2)
self.ms.text_print3.connect(self.write_ui3)
self.ms.text_print4.connect(self.write_ui4)
self.ms.text_print5.connect(self.write_ui5)
# 初始化執行緒引數
self.ui.pushButton.clicked.connect(self.handlePlay) # 播放
self.ui.pushButton_2.clicked.connect(self.handleCircle) # 回圈播放
self.ui.pushButton_7.clicked.connect(self.handleStopPlay) # 停止播放
self.ui.pushButton_3.clicked.connect(self.handleStart) # 檢測開始
self.ui.pushButton_4.clicked.connect(self.handleStop2) # 檢測停止
self.ui.pushButton_5.clicked.connect(self.handleShow) # 顯示影像
self.ui.pushButton_6.clicked.connect(self.handleQuit) # 關閉影像
# 在各個textEdit...控制元件上寫入字符
def write_ui1(self, str1):
self.ui.textEdit.append(str1 + '\n') # 在textEdit寫入str
def write_ui2(self, str2):
self.ui.textEdit_2.append(str2 + '\n') # 在textEdit_2寫入str
def write_ui3(self, str3):
self.ui.textEdit_3.append(str3 + '\n') # 在textEdit_3寫入str
def write_ui4(self, str4):
self.ui.textEdit_4.append(str4 + '\n') # 在textEdit_4寫入str
def write_ui5(self, str5):
self.ui.textEdit_5.append(str5 + '\n') # 在textEdit_5寫入str
那么回圈播放和停止播放又是怎么實作的呢?我是通過觸發按鈕來進行回圈播放和關閉標志位來進行停止播放,代碼如下
# 回圈播放
def handleCircle(self):
global ThreadFlag1 # 全域變數
ThreadFlag1 = 0
for i in range(20):
j = 0
cap = cv2.VideoCapture('./refuse classification video.mp4')
while (cap.isOpened()): # cap.grab()下一幀是否為空
info = ''
info += f'\t-- 垃圾回收宣傳片回圈播放 --\n'
self.ms.text_print1.emit(info) # 在textEdit寫入str1
ret, frame = cap.read()
cv2.imshow('refuse classification video.mp4', frame)
j += 1
if (j == 835): # 防止視頻最后的空幀報錯
break
# 停止宣傳片
if (ThreadFlag1 == 1):
self.ms.text_print1.emit(f'\t-- 垃圾回收宣傳片停止播放 --\n')
break
k = cv2.waitKey(20)
# 關閉視窗
cap.release()
cv2.destroyAllWindows() # 洗掉視頻視窗
# 停止播放
def handleStopPlay(self):
global ThreadFlag1 # 全域變數
if(ThreadFlag1==0&cap.isOpened()):
ThreadFlag1 = 1
當時在比賽前幾周的時候,我就想開關攝像頭去看垃圾桶內的環境,因為我們的垃圾筒的上半部分是黑箱,不好直接觀看
# 顯示影像
def handleShow(self):
global ThreadFlag3 # 全域變數
ThreadFlag3 = 0
self.ms.text_print3.emit(f' -- 攝像頭打開,請投放垃圾! --\n')
while 1:
# get a frame
ret, frame = cap.read()
# show a frame
cv2.imshow("capture", frame)
if ThreadFlag3 == 1:
# 關閉視窗
cv2.destroyAllWindows() # 洗掉視頻視窗
self.ms.text_print3.emit(f' -- 攝像頭已經關閉,開始識別! --\n')
break
cv2.waitKey(1)
# 關閉影像
def handleQuit(self):
global ThreadFlag3 # 全域變數
if ThreadFlag3 == 0:
ThreadFlag3 = 1
然后我們通過接受串口的發送去完成什么時候開始影像識別?什么時候開始向下位機傳輸資訊,轉動舵機和垃圾筒
# 接收串口資料
def handleRecv(self):
global final
global no
global ThreadFlag2 # 全域變數
ThreadFlag2 = 0
ser.flushInput() # 先清除一下緩沖區
ser.flushInput()
def download():
while 1:
self.ms.text_print2.emit(f'\t-- 接收到串口資料 --\n')
mcu = ser.read(1) ## 讀取1個資料
mcu = ser.read(1) ## 讀取1個資料
mcu = ser.read(1) ## 讀取1個資料
mcu = ser.read(1) ## 讀取1個資料
mcu = ser.read(1) ## 讀取1個資料
print("接收到第一個資料:", mcu)
self.ms.text_print2.emit(f"\t-- 接收到資料:" + str(mcu))
if mcu == b'5': # 若收到下位機發送的資料/字符,
self.ms.text_print2.emit(f'\t-- 開始拍照 --')
mcu = '' # 清空資料
mcu = '' # 清空資料
mcu = '' # 清空資料
frameone,frame = cap.read() # 讀取攝像頭
# cv2.imshow("capture", frame) # 顯示照片
cv2.waitKey(1) # 等0.1秒
cv2.imwrite("D:\\project_garbage\\picture\\0.jpg", frame) # 保存圖片,自己新建個picture檔案夾
self.ms.text_print2.emit(f'\t-- 保存照片 --')
self.predict() # 進入預測函式
最后我們開始預測實作影像識別,
在我做這個界面設計的時候遇到了很多的問題,我在這里講述一下
第一個問題就是如圖的0 或者 1 的區別
0 指的是電腦顯示屏本身沒有攝像頭,而是通過外設攝像頭來進行拍照
1 指的是比如筆記本電腦,本身就有攝像頭,可以自身攝像頭和外設攝像頭相互切換
在微機除錯始中終沒有發現這個問題,耽擱了我一會時間

第二個問題是影像匯入的路徑非常值得注意 / \的區別
匯入圖片,讀出圖片
cv2.imwrite("D:\\project_garbage\\picture\\0.jpg", frame) # 保存圖片,自己新建個picture檔案夾
img_path = "D:/project_garbage/picture/0.jpg"
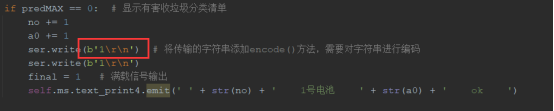
第三個問題就是如圖后串口傳輸資料的時候接受不到,這個問題種類很多,可以多通過百度解決,我們是python 與單片機32 下位機進行串口通訊, 末尾上加 \r\n很關鍵
總結
值得回憶的備賽視頻
第七屆工程訓練大賽最終雖無緣國賽,但是我們組員在實驗室一起奮斗的場景歷歷在目,我覺得這段記憶是非常珍貴,我們有一起努力過!奮斗過!我覺得就值得了,競賽之外的友誼是非常難得的!
首先分享一下在比賽前一個晚上,護著我們的寶貝垃圾桶進實驗樓(兩位隊友)

接下來我來分享一下我們寧波杭州灣之旅行的照片

寧波工程學院的鳥巢型書吧,我是真的喜歡!

這是比賽前,風特別大的時候,隊友在進行拍照,我在重新訓練模型,獻上我的垃圾桶,充滿神秘感!!
 最后留下一張參賽證,這就是回憶!!!
最后留下一張參賽證,這就是回憶!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277336.html
標籤:python