Windows10+YOLOv5訓練自己的資料集
- 一、環境和配置
- 1.1 安裝anaconda
- 1.2 在anaconda中安裝pytorch虛擬環境
- 1.3 安裝CUDA和cudnn
- 1.4 安裝pytorch GPU版
- 二 原始碼測驗
- 2.1 下載原始碼
- 2.2 安裝依賴項
- 2.3 測驗
- 2.3.1 下載權重檔案
- 2.3.2 測驗
- 三、訓練自己的資料集
- 3.1 資料集制作
- 3.2 修改組態檔
- 3.2.1 修改資料集方面的yaml檔案
- 3.2.2 修改網路引數方面的yaml檔案
- 3.2.3 修改train.py中的一些引數
- 3.3 訓練
- 3.3.1 在預訓練模型的基礎上訓練
- 3.3.2 從頭開始訓練
- 3.3.3 訓練結果
一、環境和配置
系統:window10
CUDA:10.1
CUDNN:7.4
python:3.7
opencv-python>=4.1.2
pytorch>=1.7.0
本文介紹使用anaconda搭建環境,
1.1 安裝anaconda
anaconda的安裝教程之前已經寫過一篇文章,還沒安裝的請自行參考安裝,這里不再贅述,參考鏈接:anaconda安裝教程
1.2 在anaconda中安裝pytorch虛擬環境
這一步不是必須的,但是建議建立虛擬環境安裝pytorch,免得中途出錯把別的環境也破壞了,到時候就得不償失了,
在anaconda中安裝虛擬環境的教程之前也已經寫過了,這里就不寫了,自行參考鏈接:anaconda中創建虛擬環境
1.3 安裝CUDA和cudnn
若要使用GPU訓練,則需要安裝CUDA和cudnn,具體的安裝方法可以參考我的另一篇文章:CUDA和cudnn的安裝
1.4 安裝pytorch GPU版
yolov5最新版本需要pytorch1.7(以前要求是1.6)版本以上,因此我們安裝pytorch1.7版本,
第一步:打開命令提示符:

第二步:激活torch環境(我裝的虛擬環境取名為torch),輸入命令:
activate torch

第三步:安裝pytorch,由于先安裝好了CUDA10.1,因此在環境中輸入:
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
然后就是等待pytorch的安裝完成,可能需要一定的時間,
如果你想裝其他版本,可以先進入pytorch官網,然后選擇相應的版本,下面有相應的安裝命令,復制下來,在torch環境下輸入該命令即可,
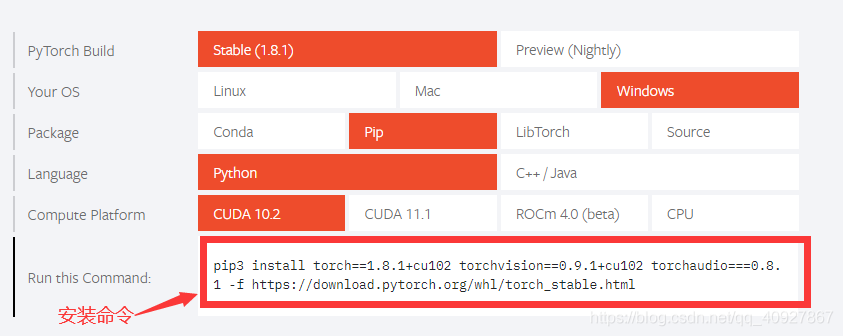
第四步:安裝好之后,可能需要將numpy進行升級,輸入命令:
pip install --upgrade numpy
第五步:測驗torch是否安裝成功
先打開python編譯環境,輸入:
python
然后輸入下面的命令查看torch的版本:
import torch as t
t.__version__
若輸出為下面的結果,則說明pytorch安裝成功:

另外也可以輸入另一個命令:
import torch as t
t.cuda.is_available
若輸出的結果為“True”,則說明安裝成功

補充:匯入pytorch使用的命令是“torch”,而非“pytorch”,若在匯入torch的時候出現錯誤:“OSError:[WinError 126]找不到指定的模塊,”這里根據提示在路徑中去找這個模塊,會發現這個“asmjit.dll”是存在于該路徑下的,并沒有丟失,
解決辦法:根據出錯的提示,上面有一個網址,把它復制下來,用任意一個瀏覽器打開,下載這個應用程式,然后雙擊安裝,安裝完畢后重啟一下電腦,就會發現可以正確的匯入torch模塊了 ,

二 原始碼測驗
2.1 下載原始碼
在GitHub上下載原始碼:YOLOv5原始碼下載地址
2.2 安裝依賴項
下載原始碼并解壓后,原始碼根目錄下有一個requirements.txt,這里面就是需要安裝的各種依賴項了,安裝方法是,從根目錄打開命令提示符:在檔案夾上方的框里輸入“cmd”,然后按回車:
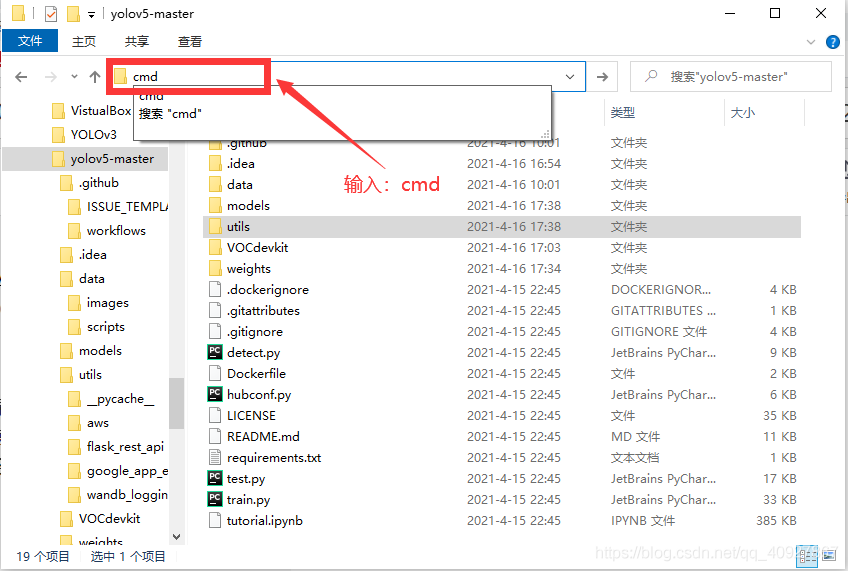
之后就會跳出來一個命令提示符框,并且是在該根目錄下:

輸入命令:
pip install -r requirements.txt
然后等待安裝完成就行了,
2.3 測驗
2.3.1 下載權重檔案
作者在GitHub中給出了他們訓練出來的權重檔案:權重檔案下載地址
并給出了各種權重檔案的檢測效果,我們可以隨意下載,
將下載的權重檔案放在./weight檔案夾下,
2.3.2 測驗
還是在原始碼的根目錄下打開命令提示符,然后激活torch環境

圖片測驗:
輸入命令:
python detect.py --source ./data/images/ --weights ./weights/yolov5s.pt --conf 0.4
運行之后輸出:
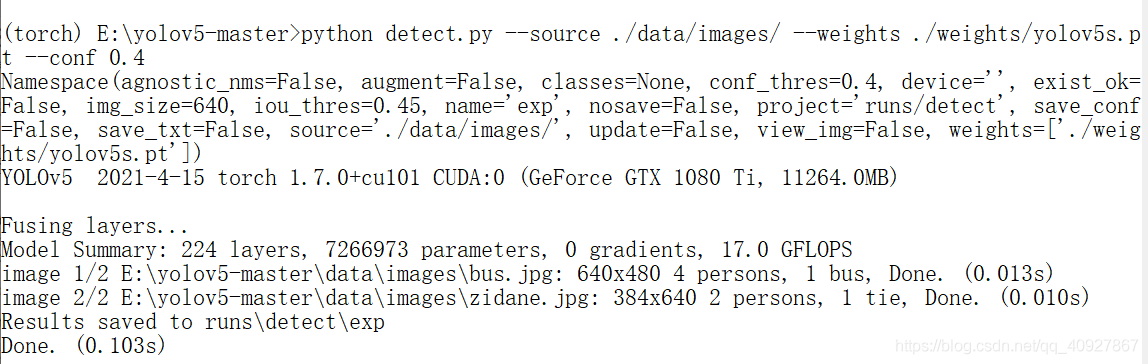
這時候根目錄檔案夾中,多了一個runs檔案夾,這里面就是測驗的結果:
打開runs檔案夾,一路打開里面所有的檔案夾,里面有兩張檢測后的圖片:
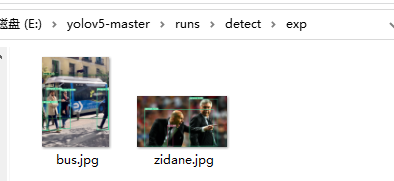
打開其中一個看一下:

視頻測驗
輸入命令:
python detect.py --source 0 --weights ./weights/yolov5s.pt --conf 0.4
三、訓練自己的資料集
3.1 資料集制作
資料集制作的前半部分可以參考我的另一篇文章VOC資料集制作
這里我就接著VOC資料集制作這篇文章來講接下來對資料集的操作,
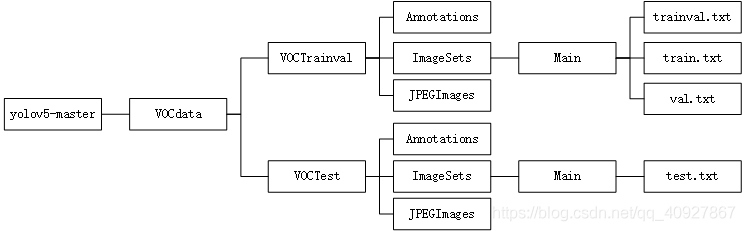
第一步:將制作好的資料集放到yolov5-master根目錄下,我的資料集檔案夾結構為:
第二步:將資料集轉換到yolo資料集格式,在VOCdata中新建一個voc_label.py檔案,輸入如下代碼:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('TrainVal', 'train'), ('TrainVal', 'val'), ('Test', 'test')] # 根據自己檔案夾的路徑結構進行修改
classes = ['類別1', '類別2', '類別3', '類別4'] #修改為自己的類別
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)):
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
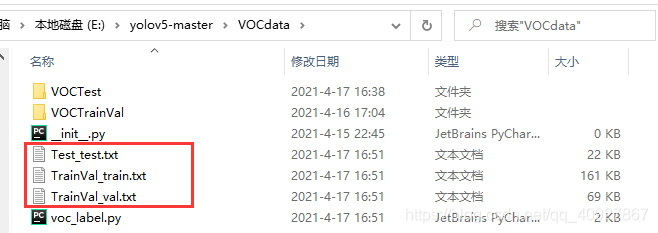
轉換后可以看到VOCData/…/labels下生成了每個圖的txt檔案:
另外,在VOCdata檔案夾下還生成如下三個包含資料集的txt檔案,訓練代碼就是通過txt中的路徑去讀取圖片
3.2 修改組態檔
3.2.1 修改資料集方面的yaml檔案
在準備完資料后,v5創新性的省略了.data和.names檔案的配置,而是將二者合二為一到yaml中,在data檔案夾下創建myvoc.yaml檔案,輸入以下資訊
# 上面那三個檔案的位置
train: ./VOCdata/TrainVal_train.txt
val: ./VOCdata/TrainVal_val.txt
test: ./VOCdata/Test_test.txt
# number of classes
nc: 4 # 修改為自己的類別數量
# class names
names: ["類別1", "類別2", "類別3", "類別4"] # 自己來的類別名稱
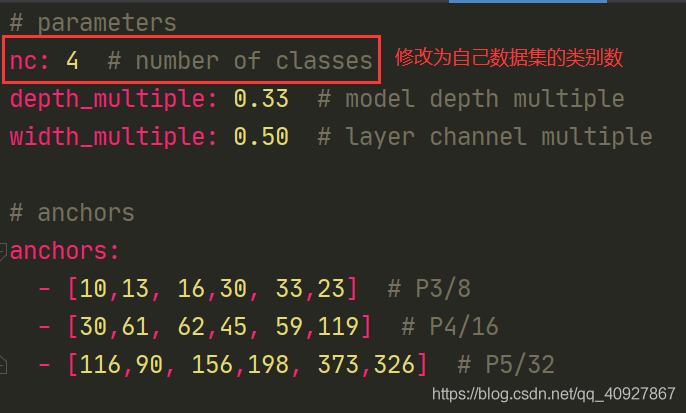
3.2.2 修改網路引數方面的yaml檔案
這個相當于以前版本的.cfg檔案,在models/yolov5s.yaml【當然,你想用哪個模型就去修改對應的yaml檔案】,就修改一下類別數量:
3.2.3 修改train.py中的一些引數
在train.py中修改一下訓練引數,也可以直接在訓練陳述句中重寫,修改的話只是修改默認值,
parser.add_argument('--epochs', type=int, default=200) # 根據需要自行調節訓練的epoch
parser.add_argument('--batch-size', type=int, default=16) # 根據自己的顯卡調節,顯卡不好的話,就調小點
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='*.cfg path') # 根據需要,自行選擇模型
parser.add_argument('--data', type=str, default='data/myvoc.yaml', help='*.data path') # data設定為前兩步中我們新建的myvoc.yaml
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes') # 可調可不調
3.3 訓練
3.3.1 在預訓練模型的基礎上訓練
在yolov5-master目錄中打開命令提示符,再激活torch環境,然后輸入下列命令:
python train.py --img 640 --batch 4 --epoch 300 --data ./data/myvoc.yaml --cfg ./models/yolov5s.yaml --weights weights/yolov5s.pt --workers 0
引數解釋:
–img:輸入圖片尺寸
–batch:batch_size大小
–epoch:訓練周期
–data:上面修改過的資料集方面的資訊檔案
–cfg:模型的組態檔,自行選擇模型,當然這里選的是哪個模型,就要在3.2.2中修改相應的組態檔中的類別數
–weights:預訓練模型,之前下載好的,這里選擇的預訓練模型需要跟–cfg中相同
–workers:暫時還沒搞明白是什么
當然這些引數可以直接在train.py檔案中直接修改默認值,然后直接運行train.py檔案,
3.3.2 從頭開始訓練
將train.py中的第458行–weights的默認引數刪掉

在上面命令的基礎上,去掉–weight,在yolov5-master目錄中打開命令提示符,再激活torch環境,然后輸入下列命令:
python train.py --img 640 --batch 4 --epoch 300 --data ./data/myvoc.yaml --cfg ./models/yolov5s.yaml --workers 0
當然如果其他引數也修改為適合自己訓練的引數了,也可以直接運行train.py檔案,
3.3.3 訓練結果
待更新!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277337.html
標籤:python
上一篇:智能垃圾分類