????本系列Python演算法學習博文,基于《Python演算法詳解-張玲玲》一書,編譯環境為IDLE(Python 3.7 64-bit),
????博主系統計學方向,在學習Python演算法之前,已經掌握了Python編程基礎、Python資料挖掘與分析等知識,
文章目錄
- 一、演算法簡介
- 1.1、演算法含義
- 1.2、演算法的特征
- 1.3、演算法的表現形式
- 二、資料結構
- 2.1、串列的基本使用方法
- 2.2、元組的簡單使用方法
- 2.3、字典的基本使用方法
- 三、小結
一、演算法簡介
1.1、演算法含義
????演算法是程式的靈魂,只有掌握了演算法,才能輕松地駕馭程式開發,演算法能夠引導開發者在面對一個專案功能時用什么思路去實作,有了這個思路后,編程作業只需要遵循這個思路去實作即可,
????演算法是一系列解決問題的清晰指令,演算法代表著用系統的方法描述解決問題的策略機制,
1.2、演算法的特征
????演算法特征包括有:有窮性、確切性、輸入、輸出、可行性,
- 有窮性:保證執行有限步驟之后結束,
- 確切性:每一步都有確切的定義,
- 輸入:每個演算法有0個或者多個輸入,以用來刻畫運算物件的初始情況,0個輸入是指演算法本身舍棄了初始條件,
- 輸出:每一個演算法有一個或者多個輸出,顯示對輸入資料加工后的結果,沒有輸出的演算法是無意義的,
- 可行性:原則上演算法能夠精確地運行,進行有限次運算后即可完成一種運算,
1.3、演算法的表現形式
????演算法的表現形式有:流程圖、N-S圖、計算機語言,
- 流程圖
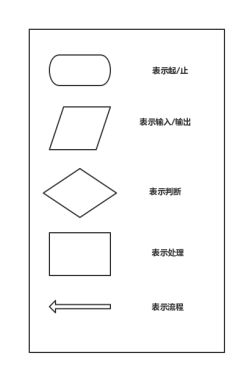
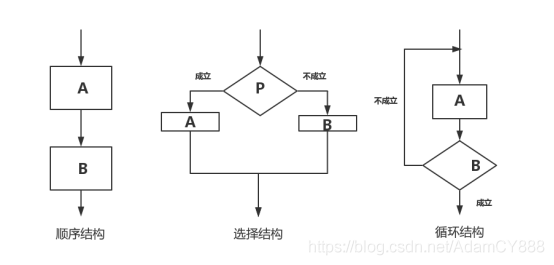
????流程圖包含有五種標識、三種結構,五種標識分別為:起/止、輸入/輸出、判斷、處理、流程,如圖1,三種結構為:順尋結構、選擇結構、回圈結構,如圖2,
- N-S圖
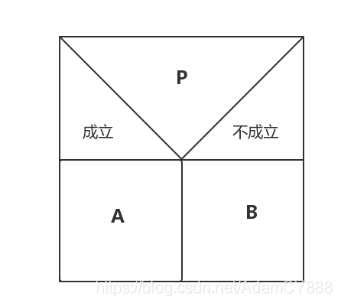
????N-S圖相對于傳統流程圖,省略了流程線,把整個程式寫在一個大框圖內,如圖3,
- 計算機語言
????例如
#專案:計算陣列元素與均值離差
list_1 = [1,3,8,11,32]
mean = sum(list_1)/len(list_1)
list_2 = list()
for i in list_1:
s = i - mean
list_2.append(s)
print(list_2)
#輸出結果:[-10.0, -8.0, -3.0, 0.0, 21.0]
????編程是讓計算機為解決某個問題而使用某種程式設計語言撰寫程式代碼,并最終得到結果的程序,作為一名統計方向的學習者,編程是一項增益技能,借助編程能有助于統計研究,
二、資料結構
????資料結構主要介紹:串列、元組、字典,
????資料結構的學習有利于在編程程序中存盤、轉換使用資料,資料結構屬于Python程式設計基礎知識,在本文中只做簡單介紹,
2.1、串列的基本使用方法
#串列的基本使用方法
list_1 = list() #定義一個名為list_1的空串列
print(list_1)
#輸出:[]
print(type(list_1))#查看list_1的變數型別
#輸出:<class 'list'>
list_2 = [] #定義一個空串列的另一種方法
print(list_2)
#輸出:[]
list_3 = list([100,200,300,400,500]) #定義一個包含元素的串列
print(list_3) #列印list_3的結果
#輸出:[1, 2, 3, 4, 5]
print(list_3[2])#列印list_3中的第三個元素
#輸出:300
'''
串列的索引
list_3[0]表示list_3串列中的第一個元素
list_3[1]表示list_3中的第二元素
依此類推,若超出范圍則會報錯
list_3[-1]表示list_3串列中的最后一個元素
依次類推,超出范圍則報錯
也由此可見,串列中的元素是一個有序的陣列
'''
print(list_3[1:4])#列印以list_3[1]開始的4-1=3個元素
#輸出:[200, 300, 400]
????此外還可以洗掉串列中重復的元素并保持順序不變、找到串列中最多的元素、使用串列推導式、命名切片等等,
2.2、元組的簡單使用方法
????Python編程中,可以將元組看作一種特殊的串列,其與串列不同的是元組內的元素不能發生變化,不能添加和洗掉元素 ,
#元組的簡單使用方法
tup_1 = tuple() #定義一個名為tup_1的空元組
tup_2 = ('baidu','中國','123','---') #定義一個元組
tup_3 = (1.1,2,3,4.3,5)#注意與tup_2定義的元素不同
'''
tup_1也可以定義為:tup_1 = ()
tup_2中的元素為字串
tup_3中的元素為整數、浮點型
'''
print("這是空元組:",tup_1)
print('這是包括字串的元組:',tup_2)
print("這是包含數字型元素的元組:",tup_3)
print(type(tup_1)) #查看變數型別
'''
輸出:
這是空元組: ()
這是包括字串的元組: ('baidu', '中國', '123', '---')
這是包含數字型元素的元組: (1.1, 2, 3, 4.3, 5)
<class 'tuple'>
'''
print(tup_2[1])#查看tup_2中的第2個元素,序號從0開始
print(tup_3[1:4])#切片,同串列原理一致
'''
輸出:
中國
(2, 3, 4.3)
'''
tup_4 = tup_2 + tup_3 #元組拼接為一個新的元組
print(tup_4)
#輸出:('baidu', '中國', '123', '---', 1.1, 2, 3, 4.3, 5)
del tup_4 #洗掉元組tup_4,其后無法再將tup_4列印出來
????此外還可以使用內置方法操作元組、將序列分解為單獨的變數、實作優先級佇列等,
2.3、字典的基本使用方法
????字典是一種比較特別的資料型別,字典中的每個成員以"鍵:值"對的形式成對出現,字典以大括號{}包圍,并以“鍵:值”對的方式宣告存在的資料集合,字典與串列相比,最大的不同在于字典是無序的,其成員(元素)的位置是象征性的,在字典中通過鍵來訪問成員,而不能通過位置來訪問,也不能通過值來訪問,這就好比我們設定QQ號,QQ號和密碼是一一對應的,不同用戶的QQ號不能相同,但密碼可以相同,并且我們可以通過賬號找回密碼,
#字典的基本使用方法
dic_1 = dict() #定義空串列方式1
dic_2 = {} #定義空字典方式2
print(dic_1,dic_2)
#輸出:{} {}
print(type(dic_1)) #查看dic_1的型別
#輸出:<class 'dict'>
dic_3 = {'蘋果':'apple','張三':'78分','博主':'帥哥'}#定義一個包含鍵值對的字典
print(dic_3['蘋果'])#查找‘蘋果’這個鍵對應的值
#輸出:apple
dic_3['abcd'] = 'ABCD'#在字典dic_3中添加{"abcd":"ABCD"}鍵值對
print(dic_3)
#輸出:{'蘋果': 'apple', '張三': '78分', '博主': '帥哥', 'abcd': 'ABCD'}
dic_3['張三'] = '100' #鍵‘張三’原本已經存在字典中,重新賦值100,修改鍵值
print(dic_3)
#輸出:{'蘋果': 'apple', '張三': '100', '博主': '帥哥', 'abcd': 'ABCD'}
del dic_3['博主']#洗掉字典中{“博主”:“帥哥”}這一對鍵值對
print(dic_3)
#輸出:{'蘋果': 'apple', '張三': '100', 'abcd': 'ABCD'}
????此外還可以用字典映射多個值、使用OrderedDict創建有序字典、獲取字典中最大值最小值、獲取兩個字典中相同的鍵值對、使用itemgetter()對字典排序、使用字典推導式等,
三、小結
????最后,本文簡單介紹了演算法的含義以及資料結構的三種型別,并用代碼進行演示,演算法是一系列解決問題的清晰指示,資料結構的作用是保存專案中的資料資訊,Python 內置了許多資料結構,需要對每一種資料結構一一學習,這對后續學習十分重要,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277338.html
標籤:python
下一篇:Python基礎筆記