這里寫目錄標題
- Python基操
- 字串
- 常見資料型別及操作
- 函式相關操作
- 裝飾器
- 檔案操作
- json序列化
- 小結
Python基操
- 對Python常用的基礎知識整理回顧
- 大部分操作使用代碼塊說明,IDE使用PyCharm
字串
- Python3中統一采用Unicode編碼,也封裝了字串類
strmystr = 'RoyKun' result = mystr.index('R') # 獲取字符索引,沒找到會崩潰 print(result) # 0 result = mystr.find('K') # 獲取字符索引,如果沒找到回傳-1 print(result) # 3 區分大小寫哦! result = mystr.count('u') # 字符出現的個數 print(result) # 1 result = len(mystr) # 回傳字串長度 print(result) # 6 result = mystr.replace('u','n') # 字符替換 print(result) # RoyKnn print(mystr) # RoyKun mystr = 'apple,pear,orange' result = mystr.split(',') # 分割資料 print(result) # ['apple', 'pear', 'orange'] 得到串列 mystr = 'aabccb' result = mystr.partition('b')# 以指定字串分割為3部分 print(result) # ('aa', 'b', 'ccb') 得到元祖,只會以第一個 , 分割 myurl = 'http://www.baidu.com' result = myurl.startswith('http') # 是否以指定資料開頭 print(result) # True myurl = 'http://www.baidu.com' result = myurl.endswith('xxx') # 是否以指定資料開頭 print(result) # False mystr = 'k' result = mystr.join('Roy') # 以指定字串拼接資料 print(result) # Rkoky mystr = mystr +'Roy' print(mystr ) # kRoy mystr = ' Roy ' result = mystr.strip(' ') # Roy 去除兩邊指定字符 # result = mystr.lstrip(' ') # result = mystr.rstrip(' ') print(result) - 注意有些是參考,直接操作;有些會回傳新的物件
常見資料型別及操作
-
串列
# 串列:以中括號表現形式的資料集合,可以放任意型別的資料 # 因此,串列本質是一個指標陣列 my_list = [1, 'app', True] print(type(my_list)) # <class 'list'> print(my_list[-2]) # app my_list.append('Roy') # 追加資料 my_list.insert(1, 'kun') # 指定位置插入資料 [1, 'kun', 'app', True, 'Roy'] mylist2 = ['watermelon', '草莓'] my_list.extend(mylist2) # 添加串列元素(擴展) print(my_list) # [1, 'app', True, 'watermelon', '草莓'] my_list.remove('草莓') # 洗掉指定元素 del my_list[0] # 根據下標洗掉元素 ['app', True, 'watermelon'] result = my_list.pop(1) # 洗掉資料并回傳資料值,如果不傳參 默認洗掉 -1 位置 # 即 list默認是個堆疊,后進先出 print(result) # 串列生成式 my_list = [value for value in range(1,6)] print(my_list) # [1, 2, 3, 4, 5] 包頭不包尾 my_list = [value+"Hello" for value in ['ab','abc']] print(my_list) my_list = [(x,y) for x in range(1,3) for y in range(2,4)] # range包頭不包尾 print(my_list) # [(1, 2), (1, 3), (2, 2), (2, 3)] 等價于兩層for回圈 -
元祖
# 元祖:以小括號形式表現的資料集合,可以存任意型別的資料 # 不能對元祖進行資料修改 my_tuple = (1, 2, 'Roy',[3,4]) print(my_tuple) # my_tuple[0] = 2 # 不能直接修改 # TypeError: 'tuple' object does not support item assignment my_tuple[3].append(5) print(my_tuple) # (1, 2, 'Roy', [3, 4, 5]) # 如果存盤的元素本身是可變的,那可以改變這個元素 # 如果只有一個元素需要添加逗號,不然會判斷為其他型別 my_tuple2 = (1,) print(type(my_tuple2)) # <class 'tuple'> my_tuple2 = (1) # <class 'int'> -
字典
# 字典:以大括號形式表現的資料集合,元素使用鍵值對表示 # 字典中的資料是無序的(輸出順序不定) my_dict = {'name':'Roy', 'age':18, 'hobby':'fuck'} print(my_dict) result = my_dict.pop('age') # 洗掉元素,必須指定key # 使用dict函式 dict2 = dict(a='a', b='b', t='t') # 一般傳入的是可迭代物件 print(dict2) dict(zip(['one', 'two', 'three'], [1, 2, 3])) dict([('one', 1), ('two', 2), ('three', 3)]) -
集合
# 集合set:以大括號表示的資料集合,無序,且不能重復 my_set = {1, 2, 'Roy'} print(type(my_set)) # <class 'set'> my_set.remove(1) # 洗掉指定元素,元素必須存在否則報錯 print(my_set) my_set.discard('Roy') # 不報錯 print(my_set) my_set2 = set() # 若沒有元素時 print(type(my_set2)) # <class 'set'> my_set2.add('666') print(my_set2) # 無序,也就是說不能根據下標進行操作 -
字典和集合都用大括號=={ }==
-
串列、元祖、集合都叫做資料容器,可以相互轉換
my_list = [1,2,2] my_tuple = (4,5) my_set = {'name', 'age'} # 串列轉集合 result = set(my_list) # 會對元素去重 # 元祖轉集合 result = set(my_tuple) # 串列轉元祖 result = tuple(my_list) # 集合轉元祖 result = tuple(my_set) # 集合轉串列 result = list(my_set) # 元祖轉串列 result = list(my_tuple) -
enumerate()函式用于將一個可遍歷的資料物件(如元組、串列、集合或字串)組合為一個索引序列 -
也是后面拆包的常用操作
for index, value in enumerate(['apple', 'banana']): print(index,value) # 在命令列執行要加空格 # 0 apple 加序號 # 1 banana -
針對字典可以使用
item()方法迭代# 針對字典 my_dict = {'name':'Roy', 'age':18, 'hobby':'fuck'} for key, value in my_dict.items(): # 這個就是key了,而不是序號! print(key,value) for keys in my_dict.keys(): # 當然,還有keys()方法 print(keys) -
字典、串列、字串是最常見的資料結構,且都是可迭代物件,后面會介紹迭代器
函式相關操作
-
函式傳參
# 不定長引數函式 def fun(a, b, *args, **kwargs):# a,b是必傳引數 print(a) print(b) print(args) print(kwargs) fun(1, 2, 3, 4, name = "hello", age = 20) # 1 # 2 # (3, 4) 元祖封裝 為什么不用串列呢? # {'name': 'hello', 'age': 20} 字典封裝 fun(1, 2, 3, 4, name = "hello", age = 20, 18) # SyntaxError: positional argument follows keyword argument 語法錯誤,引數位置不正確(這讓人家沒法歸類啊!) -
遞回函式
# 遞回函式:傳遞回歸,即在函式內部再次呼叫函式 def cal_num(num): # 計算階乘 if not isinstance(num, int): return 'error input' if num == 1: # 結束遞回的條件(遞回出口) return 1 else: return num * cal_num(num-1) cal_num(5) import sys result = sys.getrecursionlimit() # 獲取最大遞回次數 print(result) # 1000 sys.setrecursionlimit(1100) # 設定最大遞回次數 -
程式本質上就是:回圈、判斷、遞回
-
匿名函式
# 匿名函式:沒有名稱的函式 # 由于這個函式只在這里用一下,所以沒有必要單獨定義,可以簡化代碼 # func接收函式即可,需要傳遞函式作為引數時,直接寫lambda運算式即可 func = lambda x,y: x+y # 前面是引數;后面只能寫一句運算式,回傳計算結果 result = func(2,4) print(result) func1 = lambda num: True if num%2 == 0 else False # 判斷奇偶 T要大寫,放在前面! print(func1(5)) list2 = [{'name':'roy','age':22},{'name':'kun','age':20}] # 對字典串列進行排序 list2.sort(key=lambda item: item['age']) # key= reverse= 是關鍵字 # 默認False,升序! print(list2) # item代表串列中的每個字典,sort函式內部回圈獲取所有age值排序 -
語法就記一下吧:簡單運算、bool判斷、排序(傳遞關鍵字)
-
高階函式
# 高階函式 # 引數是函式或者回傳函式的函式 def test(new_func): new_func() # 呼叫 def inner(): print('內部函式') return inner def show(): print('我是個函式,但我在這做函式引數') func = test(show)
裝飾器
-
閉包:是高級函式
# 函式嵌套時,內部函式使用外部函式的引數或變數,最侄訓傳這個內部函式,叫做閉包 def exfunc(msg,num): def refunc(): print(msg*num) return refunc # 注意不帶括號 # 閉包的好處是可以根據引數得到新函式,從而適應不同需求 func = exfunc('roy',2) func() # royroy print(func) # <function exfunc.<locals>.refunc at 0x000002572A4AFE58> -
裝飾器:函式參考指向原函式,原函式名接收閉包,實作功能擴展
# 裝飾器本質上是一個函式,可以對原函式的功能進行擴展,不影響原函式的定義和呼叫 # 裝飾器的實作要用到閉包 # 通用裝飾器:可以修飾帶引數的和不帶引數的函式,有回傳值的和無回傳值的函式 def decorator(func): # 最外層,傳遞函式名 def inner(*args, **kwargs): # 內層,接收原函式引數 print('這是對被裝飾函式擴展的操作') # 擴展部分 return func(*args, **kwargs) # 需要設定原函式的引數,對于有回傳值的函式需要return;總之,加上是沒錯的! return inner # 上面是兩層裝飾器,如果裝飾器也帶引數呢?就需要三層 @decorator # 語法糖,相當于執行 sum = decorator(sum) 接收閉包,擴展了原函式 def sum(num1,num2): print(num1 + num2) sum(1,3) # 這是對被裝飾函式擴展的操作 @decorator def test(): print('Roy') test() # 這里函式不帶有引數 -
切片(取元素)
# 針對字串,類似numpy的矩陣操作 str = 'RoyKun' result = str[0:5:1] # 起始下標:結束下標:步長 (不包含結束下標) print(result) # RoyKu result = str[-1:-4:-1] # nuK print(result)
檔案操作
-
主要用到
open函式和os包# 讀取鍵盤輸入,標準輸入讀入一行文本 str = input("請輸入:") print "你輸入的內容是: ", str -
這里均是在Linux環境中的操作
# 打開檔案使用open函式 fileObject = open('1.txt', 'r', encoding='UTF-8')# 在Windows上使用utf-8編碼格式 # 使用open函式相當于創建了一個file物件,包含常用方法: string = 'RoyKun' fileObject.write(string) # 寫入字串 string = fileObject.read(6) # 讀取檔案內容 引數count是要從已打開檔案中讀取的位元組計數 position = fileObject.tell() # 查找當前位置 fileObject.close() # 關閉物件 # 在python3中默認支持中文編碼(都是Unicode),也可以在代碼首行使用:-*- coding: UTF-8 -*- 指定編碼格式 # 使用'b'模式時,不需要指定編碼格式,同時讀取資料需要使用decode()解碼 -
其他方法
# 重繪檔案內部緩沖,直接把內部緩沖區的資料立刻寫入檔案, 而不是被動的等待輸出緩沖區寫入 file.flush() # 讀取整行,包括 "\n" 字符 file.readline([size]) # 讀取所有行并回傳串列,若給定sizeint>0,則是設定一次讀多少位元組,這是為了減輕讀取壓力 file.readlines([sizeint]) # 截取檔案,截取的位元組通過size指定,默認為當前檔案位置 file.truncate([size]) # 移動檔案讀取指標到指定位置 file.seek(offset[, whence]) -
對于打開檔案的模式總結如下圖:
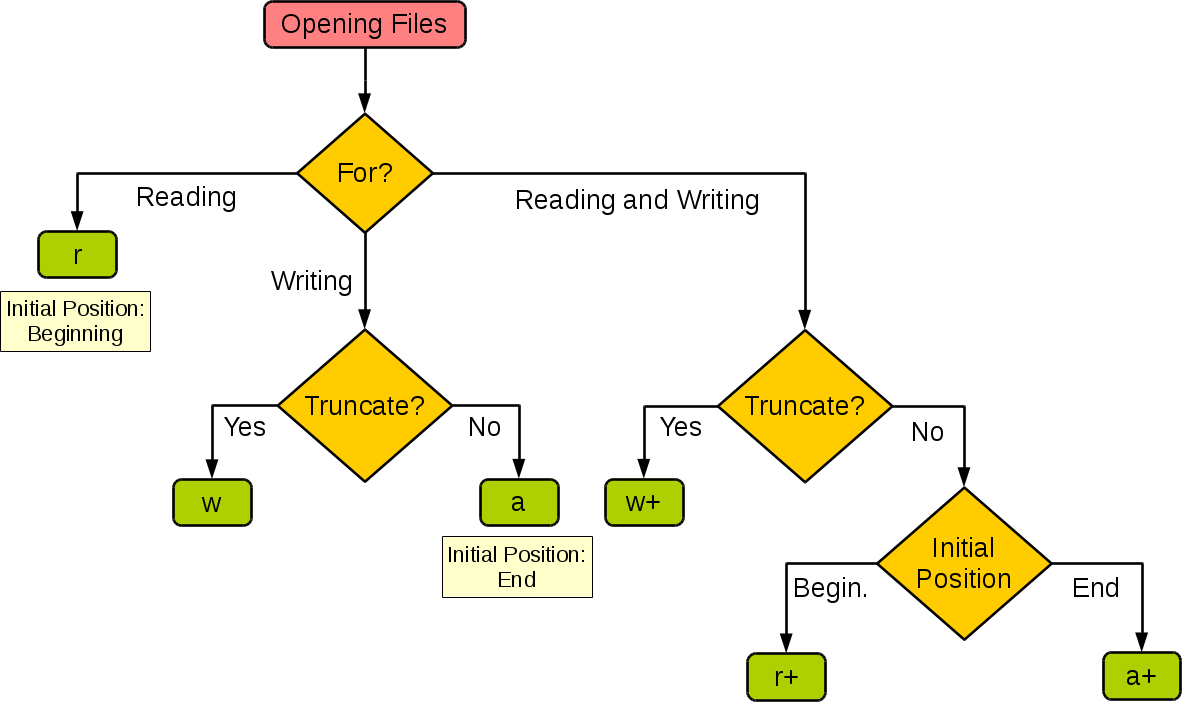
-
檔案物件還包含以下屬性:
屬性 描述 file.closed 回傳true如果檔案已被關閉,否則回傳false, file.mode 回傳被打開檔案的訪問模式, file.name 回傳檔案的名稱, file.softspace 如果用print輸出后,必須跟一個空格符,則回傳false,否則回傳true, -
os模塊提供了幫你執行檔案處理操作的方法,比如重命名和洗掉檔案
import os # 列出當前目錄下的檔案 os.listdir(os.getcwd()) # 重命名檔案test1.txt到test2.txt, os.rename( "test1.txt", "test2.txt" ) # 洗掉檔案 os.remove(file_name) # 創建一個新目錄 os.mkdir("newdir") # 將當前目錄改為"/home/newdir" os.chdir("/home/newdir") # 顯示當前的作業目錄 os.getcwd() # 洗掉目錄,它的所有內容應該先被清除 os.rmdir('dirname') -
小結:
open函式和os模塊最常用,很多使用也用到os定位路徑
json序列化
-
JSON (JavaScript Object Notation) 是一種輕量級的資料交換格式,它基于ECMAScript的一個子集
-
使用
json模塊對資料進行編解碼,主要包括json.dumps()轉換為json資料(字串 )json.loads()json資料轉換成python型別資料
-
Python 編碼為 JSON 后型別都為string:
import json data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ] data_json = json.dumps(data) print(type(data_json)) # <class 'str'> data_py = json.loads(data_json) print(type(data_py)) # <class 'list'>
小結
- 這里主要介紹了python資料結構、裝飾器及檔案操作
- 下一篇我們繼續python進階操作
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277339.html
標籤:python