B題——預測問題
- 資料預處理(可不讀)
- 資料的表格處理
- 畫出各原子坐標的 KDE 圖
- 題外話
- 資料的聚類處理——1
- 資料預處理與解題思路(如果想讀,一定要讀這部分)
- DBSCAN 演算法原理
- DBSCAN 簡單決議
- 聚類前資料結構說明
- DBSCAN 引數篩選
- 聚類結果
- 結果分析
- 資料的聚類處理——2
- 能量資料處理
- 標準化
- 繪制箱型圖
- 能量資料離散化
- 機器學習方法(不管用,可不讀)
- 多層感知器(不管用,可不讀)
- 卷積神經網路(重點)
- 資料預處理
- 將坐標資料視為“影像”
- 將能量資料標準化
- 搭建模型
- 訓練
- 訓練演算法
- 結果
- 缺點(參賽的朋友們建議仔細讀一下)
- 代碼
- 檔案組織
- 打開 .xyz 檔案(read_data.py)
- data_preprocess.py
- machine_learning.py
- deep_learning_method.py
- conv_network.py
- 題外話
- DBSCAN 演算法解釋網站
- TensorFlow BUG?
參賽賽題鏈接
謝絕提問
靜下心來,文章可能比較抽象,邊聽雨聲邊看有助于集中注意力哦~
這篇文章主要想解決預測問題,但也有考慮到接下來的 AU25 的最優結構預測問題,
為了能夠解決 AU25,文章也往定試圖性分析的方面靠,畢竟如果單靠機器學習的話,很難去跨越地解決(即便有遷移學習),因此,理想的解題思路應該是這樣的:
然而,美好的愿望終于失敗了,文章討論了一種基于聚類的定性分析方法,但效果不佳,如果大家感興趣,可以閱讀一下,
所以,這篇完整只完成了AU20能量預測模型的搭建作業,
最后,如果文章對大家有些許的幫助和啟發,希望不要吝嗇您的點贊,😊
白噪聲播放
資料預處理(可不讀)
下面的東西,都是為 機器學習、多層感知器 準備的,兩者都不管用,所以可以不看,但如果要取得一個好成績的話,可以看一下,寫進論文里,肯定可以作為加分項,并且,說不定能給大家帶啦一些啟示,
資料的表格處理
打開附件 1,讀取 .xyz 檔案,順序地讀取檔案中的坐標資料,將所有 .xyz 處理為具有如下表頭的表格:
| 第一個原子的 x 坐標 | 第一個原子的 y 坐標 | 第一個原子的 z 坐標 | 第二個原子的 x 坐標 | 第二個原子的 y 坐標 | 第二個原子的 z 坐標 | … | 第 20 個原子的 z 坐標 | 能量 |
|---|---|---|---|---|---|---|---|---|
| … | … | … | … | … | … | … | … | … |
回傳目錄
畫出各原子坐標的 KDE 圖
畫出 20個原子的 x、y、z 坐標的 KDE 圖,為什么要畫呢?
在上述處理檔案時,不知大家有沒有注意,我們不知不覺將原子“系結”在某一個位置了,換句話說,在附件沒有給定測量方法、測量順序、記錄順序的情況下,我們人工地給原子打上了標簽,
我們首先假定記錄是按照一定順序進行的,因此給原子人工打上標簽是合理的
之所以畫出 KDE,是因為若團簇真的是存在一些聯系,使得團簇的原子的位置,雖然存在一些差異,但總體上呈現出差不多的結構,若果真如此,則差異一般來說會滿足正態分布,因此,我們用 KDE 來判斷,是否真的是如此:
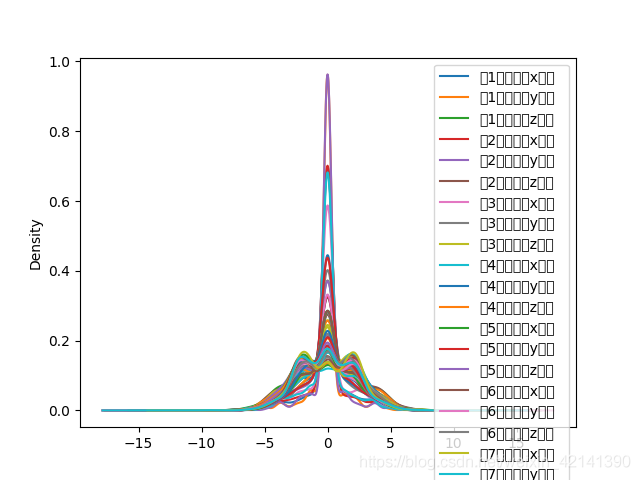 但看到,分布并不是正態的,特別是在下面的一些,幾乎呈現一個均勻分布,因此,不呈現正態可能是因為:
但看到,分布并不是正態的,特別是在下面的一些,幾乎呈現一個均勻分布,因此,不呈現正態可能是因為:
- 原子坐標的觀察、記錄順序是隨機的
- 總體的結構不是單一的
再結合題目給出的資料結構示意圖:
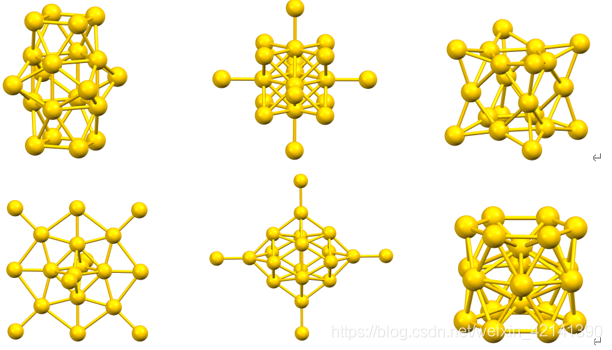 可見,au 團簇并非在總體上趨近于同一個結構,所以, 不能將資料按上述方式處理
可見,au 團簇并非在總體上趨近于同一個結構,所以, 不能將資料按上述方式處理
當然,這種可視化的方法雖然簡單粗暴,但如果要取得好成績,建議對每一列,都進行正態檢驗,
題外話
這個方法不但理論上行不通,而且在實際應用上也行不通,我之前按照這種處理方法,然后用了機器學習、多層感知器,效果均不佳,
但很可惜沒有保留代碼,否則那個誤差,就能讓大家嘆為觀止一番了,
回傳目錄
資料的聚類處理——1
這里的資料處理,都是為后來的機器學習、神經網路方法搭建模型服務的,
資料預處理與解題思路(如果想讀,一定要讀這部分)
通過上述分析,資料的表格處理已經不能用,即給資料“貼標簽”的方法是不可能的了,因此,這了考慮將每一個原子,視為地位對等的一個點,然后,將 20 × 1000 = 20000 20\times 1000=20000 20×1000=20000 個點進行聚類,得到聚類結果(簇)后,再考慮將 au 簇下,某聚類簇下,原子的個數作為特征,
最后,得到的輸入資料的“表頭”大致如下:
| 屬于聚類簇 1 的原子數 | 屬于聚類簇 2 的原子數 | ? \cdots ? | 屬于聚類簇 n 的原子數 | |
|---|---|---|---|---|
| 0.xyz | 10 | 5 | ? \cdots ? | 2 |
| 1.xyz | 0 | 2 | ? \cdots ? | 0 |
| ? \cdots ? | ? \cdots ? | ? \cdots ? | ? \cdots ? | ? \cdots ? |
| 999.xyz | 1 | 1 | ? \cdots ? | 2 |
常見的聚類方法有 Kmeans、譜聚類等等,由于需要事前擇定聚類簇數,所以這里考慮采用一種自適應的聚類方法:DBSCAN,
但聚類的一個缺點也暴露出來了,就是會失去大量的資訊,使得輸入資料從定量分析,到定性分析,因此,對于預測資料(能量資料),我們也需要對其進行處理,從而將其轉換為 “定性” 的形式,
為什么要這樣將輸入資料,處理成定性分析的形式呢?大家可以回傳前面看一下
通過定性分析,構造定性預測模型,如何構造,就要看后文的機器學習、神經網路方法了,然后根據定性分析的結果,進一步進行定量預測,從而解決問題,這是我的思路,
但個思路最后還是失敗了,原因在于定性方法丟失了太多的資訊量,
但思路是無價的:如果成功的話,在考慮用定性分析后,得出的定性預測模型(該模型的輸出,是能量的定性,即低、中、高),然后,再根據那些標簽為高的團簇,他們的原子位置分布、分配情況,如有多少個原子在某聚類簇呀,得出哪一個聚類簇,與高能量的關系最大、那個聚類簇最小,
得到上述這些后,就可以針對性地進行定量分析,并且,還能夠據此,修正我們的定量預測模型,讓他用在 AU25 中,比如某個聚類簇與低能量有大關系,我們就可以考慮將多出的 5 個原子放置在 “低能量” 簇中,
可惜,最后由于資訊量丟失,無法構建定性預測模型,
回傳目錄
DBSCAN 演算法原理
其具體演算法如下:
DBSCAN(DB, distFunc, eps, minPts) {
C := 0 /* Cluster counter */
for each point P in database DB {
if label(P) ≠ undefined then continue /* Previously processed in inner loop */
Neighbors N := RangeQuery(DB, distFunc, P, eps) /* Find neighbors */
if |N| < minPts then { /* Density check */
label(P) := Noise /* Label as Noise */
continue
}
C := C + 1 /* next cluster label */
label(P) := C /* Label initial point */
SeedSet S := N \ {P} /* Neighbors to expand */
for each point Q in S { /* Process every seed point Q */
if label(Q) = Noise then label(Q) := C /* Change Noise to border point */
if label(Q) ≠ undefined then continue /* Previously processed (e.g., border point) */
label(Q) := C /* Label neighbor */
Neighbors N := RangeQuery(DB, distFunc, Q, eps) /* Find neighbors */
if |N| ≥ minPts then { /* Density check (if Q is a core point) */
S := S ∪ N /* Add new neighbors to seed set */
}
}
}
}
回傳目錄
DBSCAN 簡單決議
可視化如下:
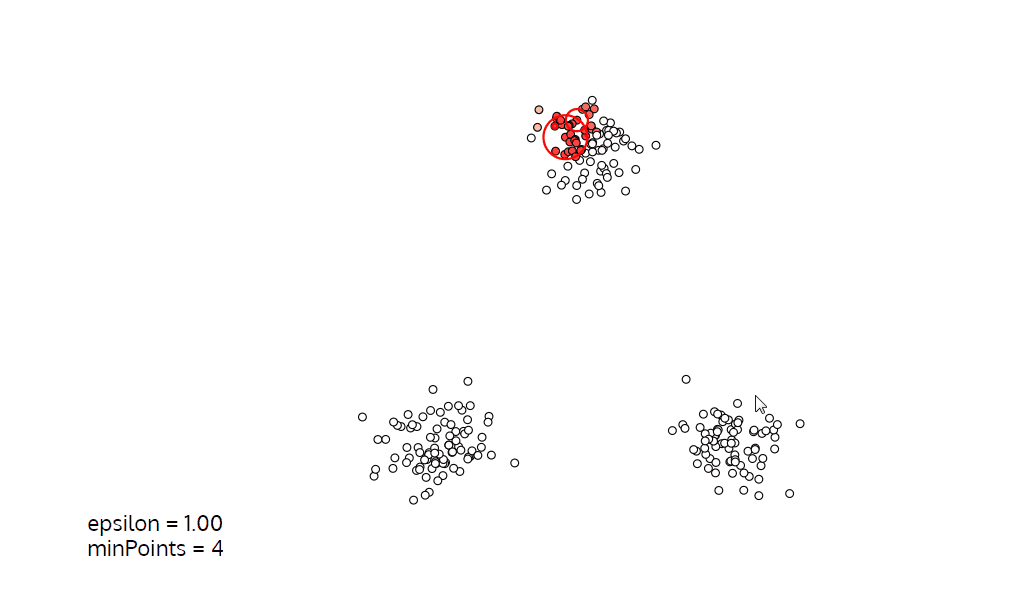 簡單來說,DBSCAN 就是根據一個隨機的初始點(或相對密集點),通過不斷地畫圈來實作聚類的方法,圈一般被稱為
?
\epsilon
? 域,其大小由
?
\epsilon
? 和域的最小點數決定,
簡單來說,DBSCAN 就是根據一個隨機的初始點(或相對密集點),通過不斷地畫圈來實作聚類的方法,圈一般被稱為
?
\epsilon
? 域,其大小由
?
\epsilon
? 和域的最小點數決定,
可以將 ? \epsilon ? 看成“圈” 的半徑,將域內最小點數作為“圈”是否成立的指標,
回傳目錄
聚類前資料結構說明
將
20
×
1000
=
20000
20\times 1000=20000
20×1000=20000 個點視為獨立的,從而構造一個
20000
×
3
20000\times3
20000×3 的表格,表格如下(附件一好像只有 999 個檔案…):
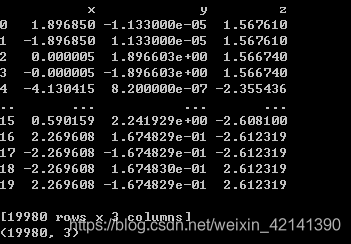
回傳目錄
DBSCAN 引數篩選
篩選可以通過網格尋優法,即大間隔的遍歷法,遍歷 e p s = [ 0.1 , 0.2 , . . . 1 ] , m i n _ s a m p l e s = [ 20 , 21 , ? ? , 30 ] eps=[0.1, 0.2, ... 1], min\_samples=[20,21,\cdots,30] eps=[0.1,0.2,...1],min_samples=[20,21,?,30]
根據聚類簇數,和剩余的,不能聚類的點的個數,篩選出比較好的引數,
最后再進行進一步地精選,遍歷: e p s = [ 0.5 , 0.51 , ? ? , 0.59 , 0.60 ] , m i n _ s a m p l e s = [ 25 , ? ? , 28 ] eps=[0.5,0.51,\cdots,0.59,0.60], min\_samples=[25,\cdots,28] eps=[0.5,0.51,?,0.59,0.60],min_samples=[25,?,28]
結果如下:
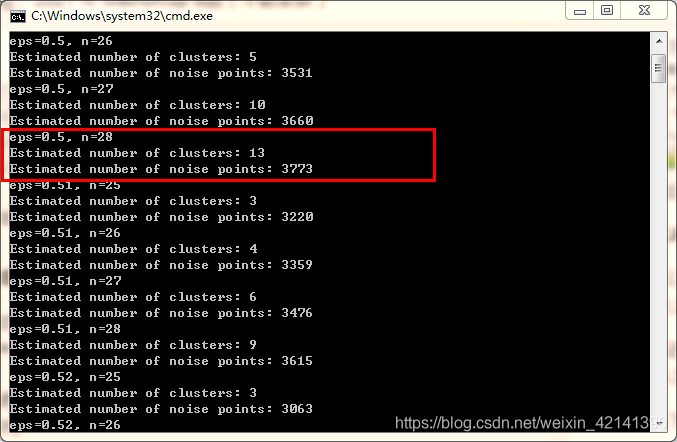
于是乎,可以考慮選擇
e
p
s
=
0.5
,
m
i
n
_
s
a
m
p
l
e
=
28
eps=0.5, min\_sample=28
eps=0.5,min_sample=28,
回傳目錄
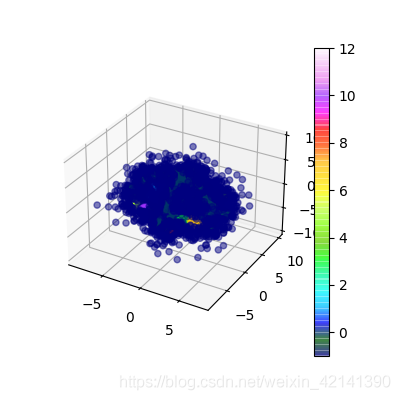
聚類結果
得到聚類簇編號,和相應的點的個數如下:
 其中 - 1 為噪聲點,
其中 - 1 為噪聲點,
畫出聚類結果圖如下:
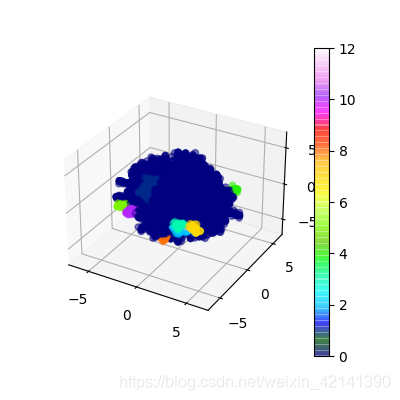
剔除掉噪聲:
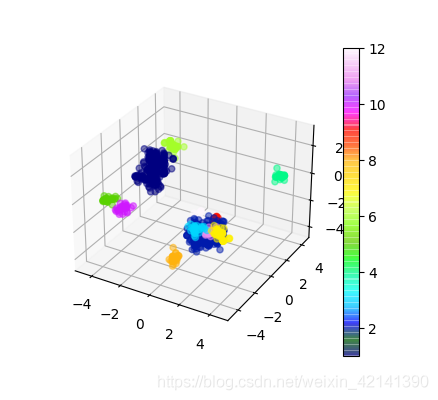
剔除掉噪聲 + 屬于編號 1 的點:
回傳目錄
結果分析
若修改引數 eps、min_samples 使得聚類簇數較少,興許(沒試過)可以得到比較均勻的結果,
但越是均勻,越是不能識別出“重要”的部位,不是嗎?
回傳目錄
資料的聚類處理——2
得到各點所屬的聚類簇后,就可以將每個 au 團簇,的每一個原子,按其所屬的聚類簇分配,從而將 au 團簇資料,轉換為具有如下表頭的表格:

其中每一列,代表屬于該聚類簇編號的原子的個數
回傳目錄
能量資料處理
標準化
繪制預處理前,能量資料的 KDE 如圖所示
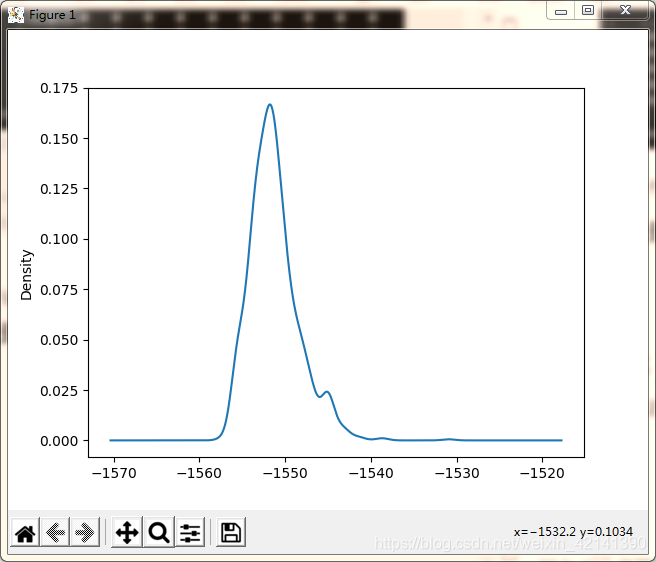
可以看到,資料主要集中在 -1550 處,為了方便機器學習模型的訓練,同時加強識別細微差異的能力,我們對能量進行標準化:
y
i
′
=
y
i
?
y
ˉ
s
\begin{aligned} y_i ^\prime= \frac{y_i-\bar{y}} {s } \end{aligned}
yi′?=syi??yˉ???
標準化后的資料 KDE 如下:
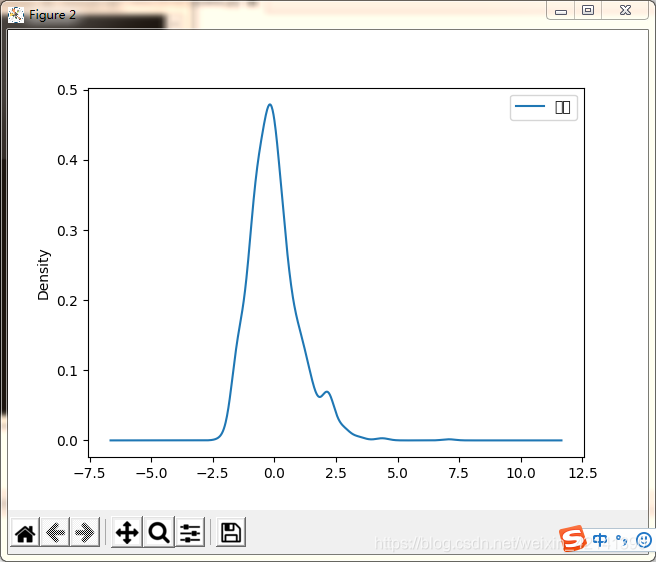
繪制箱型圖
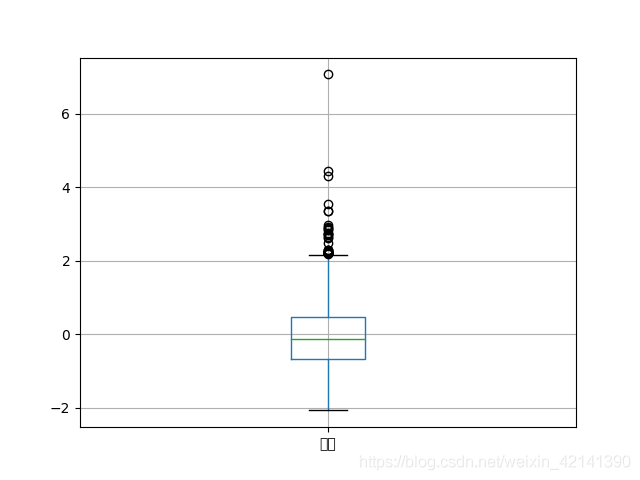
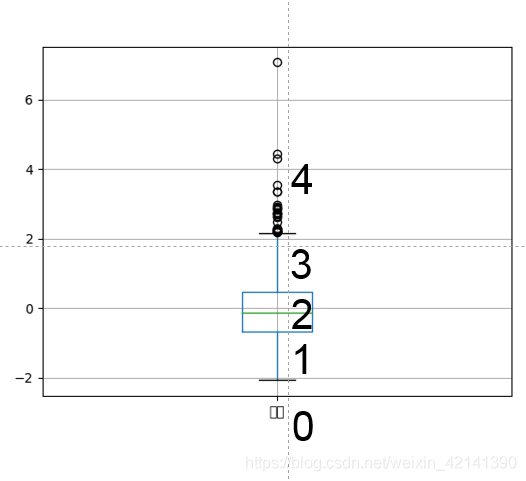
能量資料離散化
從箱型圖可以看到,資料有比較明顯的分層,另外,鑒于其他原因,本文將考慮對能量資料進行離散化,離散方法如下圖所示:
-
那么,到底為何要離散化呢:
- 從純理論上看,因為輸入已經是被弄成離散的、定性的,因此,若不將輸出也弄成離散的,定性的,那么接下來的預測模型就很難搭建,
- 從解題方面看,這部分定性分析,是為了之后的定量分析,同時解決 AU25 的最優結構預測問題著想,因此,沒有必要為定性分析提高難度,
離散結果如下所示,0 代表“能量較低”,4代表“能量較高”,同時進行 one-hot 編碼,最終資料如下:
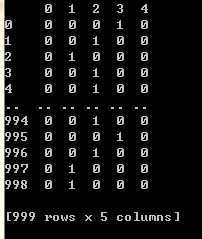
回傳目錄
機器學習方法(不管用,可不讀)
由于代碼的實作問題,所以在實作時,對于能量資料,不采用,one-hot 編碼法,而是僅根據箱型圖,進行離散化;one-hot 編碼法,主要用在深度學習上
分別從 kNN 、邏輯回歸、決策樹、支持向量機、隨機森林、Adaboost 、貝葉斯分類器中篩選出最佳的模型,和模型引數,
其中,AdaBoost 的基模型為邏輯回歸,
首先是篩選引數,可得上述模型的最佳引數(篩選方法為:網格尋優法+5折交叉驗證,篩選標準為 精確度,):
帶篩選的引數有:
| 模型 | 引數 |
|---|---|
| kNN | n_neighbors |
| SVC | C、核函式型別 |
| 決策樹 | α c c p \alpha_{ccp} αccp?, 最大樹深度 |
| 隨機森林 | 基模型(決策樹)的個數 |
| AdaBoost | 基模型的個數 |
引數網格就不給出來啦,大家看代碼哈,,
篩選的結果如下圖所示:
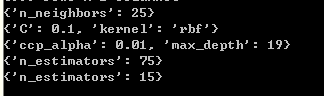
分別為:
- KNN
- 支持向量機(SVC)
- 決策樹(DTC)
- 隨機森林(RF)
- AdaBoost
然后,篩選模型,參與篩選的模型有:
| 邏輯回歸 | kNN | SVC | 決策樹 | 隨機森林 | AdaBoost | 樸素貝葉斯分類器 |
|---|
方法如下:
用各個模型的最佳引數,采用 5 折交叉驗證,計算各模型的精確度,并計算均值,如下所示:
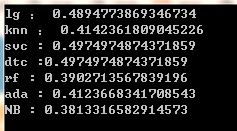
其中 (lg 為邏輯回歸、NB 為貝葉斯分類器)
可以看到,精確度都不高,故放棄機器學習模型!!!
回傳目錄
多層感知器(不管用,可不讀)
用了一個簡單的多層感知器模型,結果發現…,精確度為 0 ,
figures can’t lie, but liar figures!
 悟出了什么呢?
悟出了什么呢?
將坐標聚類,然后進行定性分析,效果不佳,原因在于:對輸入資料進行定性處理時,然大部分的資訊量喪失了,
到此,我們想要通過定性分析,來同時解決預測問題,同時便于我們解決 AU25 最優結構問題的思路,就此夭折,
回傳目錄
卷積神經網路(重點)
資料預處理
將坐標資料視為“影像”
從上述分析中,由于給原子“貼標簽”的方法不合理,而定性分析后考慮定量分析的方法失敗了,那么,如何保證各個原子“平等地位”的同時,又不會落入像聚類處理方法那樣,定性分析的窠臼呢?
這里最后考慮,將 au 團簇的所有原子坐標資料,當做“圖片”,然后用卷積神經網路的方法!
以團簇坐標檔案 0.xyz 為例,給出了 20 個原子的坐標,那么可以我們可以將 20 個原子坐標構造成一個 20 × 3 20\times 3 20×3 的矩陣,進行最大最小值標準化后,矩陣的每一個元素取值為 [ 0 , 1 ] [0,1] [0,1],
處理結果大約是這樣的:
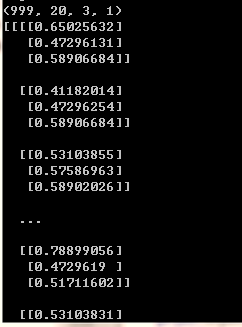
于是所有團簇檔案,從 0.xyz 到 999.xyz,構成一組維度為(999,20,3,1)的資料1?是不是和計算機視覺很像?在計算機視覺的時候,影像不是一般都是(num, width, height, color_channel)的嘛,且取值不也是 [ 0 , 1 ] [0,1] [0,1] 么?
于是順理成章,就可以用卷積神經網路,也即計算機視覺的方法來解決這個預測問題了!
回傳目錄
將能量資料標準化
能量資料的標準化是必須的,因為量綱和輸入資料的差別太大了,這會影響卷積網路的效果,標準化的方法同上
回傳目錄
搭建模型
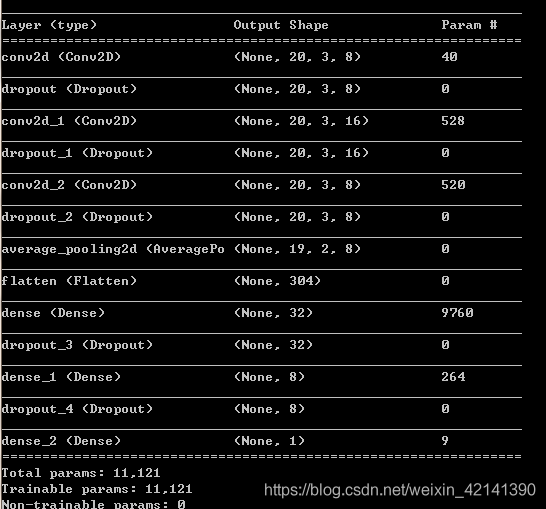
說人話就是:
| 層數 | 名稱 | 引數 |
|---|---|---|
| 1 | 卷積層 | 激活函式=relu ,步長=1,核尺寸=(2,2),深度8 |
| 2 | Dropout 層 | dropout 率=0.2 |
| 3 | 卷積層 | 激活函式=relu ,步長=1,核尺寸=(2,2),深度16 |
| 4 | Dropout 層 | dropout 率=0.2 |
| 5 | 卷積層 | 激活函式=relu ,步長=1,核尺寸=(2,2),深度8 |
| 6 | Dropout 層 | dropout 率=0.2 |
| 7 | 池化層 | 池化方法=平均法 ,步長=1,核尺寸=(2,2) |
| 8 | Flatten層 |
下面就接多層感知器了
| 層數 | 名稱 | 引數 |
|---|---|---|
| 9 | 隱藏層 | 激活函式=relu,神經節點個數=32 |
| 10 | Dropout 層 | dropout 率=0.2 |
| 11 | 隱藏層 | 激活函式=relu,神經節點個數=8 |
| 6 | Dropout 層 | dropout 率=0.2 |
| 11 | 輸出層 | 激活函式=linear,神經節點個數=1 |
回傳目錄
訓練
訓練演算法
損失函式:均方誤差
訓練演算法:Adam,引數:
| 學習率 | β 1 \beta_1 β1? | β 2 \beta_2 β2? | ? \epsilon ? |
|---|---|---|---|
| 0.001 | 0.9 | 0.999 | 0 |
結果
資料集拆分比例:7:3
評價指標:絕對平均誤差
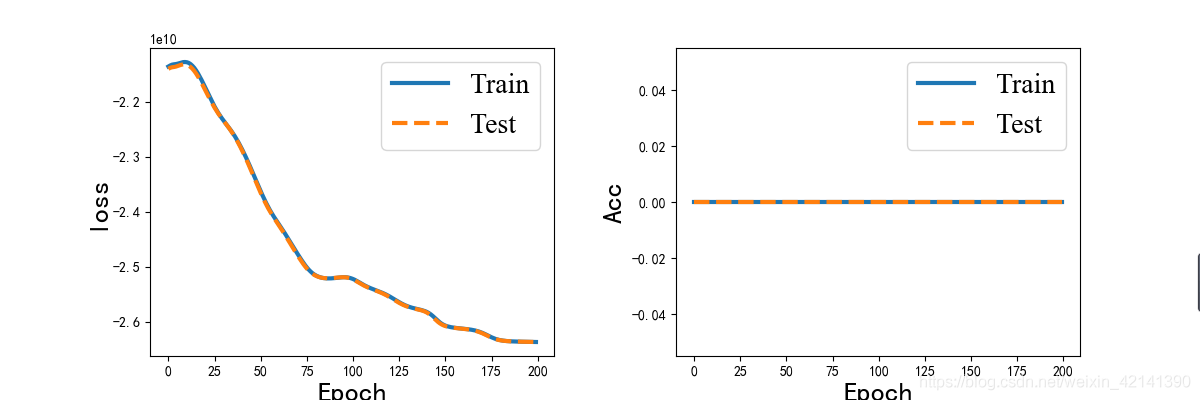
 這圖沒有改好,左邊 loss 是均方誤差;右邊是評價指標,Acc 是絕對平均誤差,
這圖沒有改好,左邊 loss 是均方誤差;右邊是評價指標,Acc 是絕對平均誤差,
可以看到,模型的效果,說好也不好,說差也不差(絕對平均誤差為:0.63),
缺點(參賽的朋友們建議仔細讀一下)
說到底,為什么結果會這么半溫不火呢?我感覺就是資料預處理方面,沒有做好,并且,如果這樣就結束了的話,對接下來的 Au25 的最優結構的尋找問題,等于是自斷了生路,
但這就是代價呀!定性分析的話,還能夠為接下來的 AU25 問題其些許作用,但走到這一步,接下來的 AU25 問題,只能求助于遷移學習了,
重申一次,若從 B 題總體的這個大局的角度來看,光解決預測問題肯定是不夠的,AU25 的預測模型、最優結構如何求解,肯定需要我們在構建 AU20 的預測模型時,需要慎重考慮,
然而,文章提供的卷積神經網路預測模型,不是一個“可持續發展”的好辦法,他沒有對資料進行本質處理,也沒有進行定性分析,在跨越性地將模型用于 AU25,甚至是單單基于這個模型,提出 AU25 的最優結構,都很難,
所以,文章這里列出了我定性分析時的一大推步驟,不是要誤導大家,是想分享一下我的思路,我想要通過定性分析,然后再定量分析,求解出 AU20 的預測模型,然后在定性分析的基礎上,修正預測模型,或不說修正,結合預測模型,跨越地解決 AU25 的最優結構問題,
希望大家能從該文章中得到啟發吧,
回傳目錄
最后這篇文章我寫了:

3 W字呀 😱,若文章有些許幫助,希望各位不吝點贊 👍,
代碼
本人的 Python 環境:3.8 以上,請保證如下庫的安裝:
numpy, pandas, sklearn, matplotlib, tensorflow, pickle, collections
若不知道怎么安裝 Python 第三方庫的,請打開 cmd(windows 下面的那個黑乎乎的視窗),然后輸入:
pip install 你要安裝的第三方庫
不要再問我一些簡單的編程問題啦,thanks
檔案組織
回傳目錄
打開 .xyz 檔案(read_data.py)
盡力了 VDM 我打不開…,所以只能用 Python 了,反正在之后的處理中,也需要將坐標、能量等資料讀取到 Python 中,才能進行處理,
新建一個檔案:read_data.py
# -*- coding: utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
def read_data_from_path(path):
with open(path,'r') as file_object:
contents = file_object.readlines()
num = len(contents)
cluster = []
cluster.append(float(contents[0].rstrip()))
cluster.append(float(contents[1].rstrip()))
for i in range(2,num):
str_space_limit = ' '.join(contents[i].split())
au = [float(i) for i in str_space_limit.split(' ')[1:]]
cluster += au
au_num = cluster[0]
energy = cluster[1]
cdn_vec = np.array(cluster[2:])
cdn_mat = cdn_vec.reshape((-1,3)) #Matrix
# au_num:是指原子的個數
# energy:指能量
# cdn_vec:指各個原子的坐標構成的向量(附件一中,每個向量的長度為60)
# cdn_mat:各個原子坐標構成的向量(shape=(20,3),列分別為 x,y,z)
return au_num, energy, cdn_vec, cdn_mat
def plot_cluster(coordination):
fig = plt.figure(figsize=(4,4))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs = coordination[:,0], ys=coordination[:,1], zs=coordination[:,2])
plt.show()
def plot_surface(coordination):
fig = plt.figure()
ax = plt.figure().add_subplot(projection='3d')
ax.plot_trisurf(coordination[:,0], coordination[:,1], coordination[:,2]\
, linewidth=0.2, antialiased=True)
plt.show()
若要讀取檔案,可用:(同一檔案)
if __name__ == '__main__':
path = r'..\題目\附件\Au20_OPT_1000\0.xyz'
au_num, energy, cdn_vec, cdn_mat = read_data_from_path(path)
print(f'原子個數為:{au_num}')
print(f'能量為:{energy}')
print(f'坐標向量:{cdn_vec}')
print(f'坐標矩陣:{cdn_mat}')
plot_cluster(cdn_mat)
plot_surface(cdn_mat)
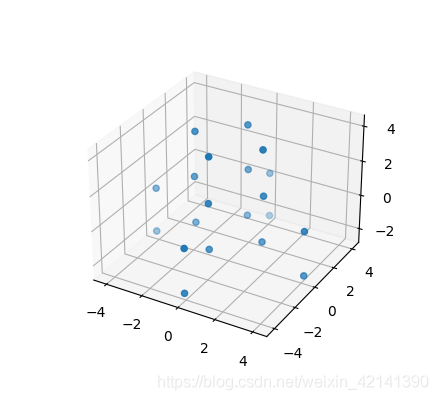
 呼叫檔案中的函式,即可讀取 .xyz 檔案
呼叫檔案中的函式,即可讀取 .xyz 檔案
回傳目錄
data_preprocess.py
主要進行資料預處理,對應文章的資料處理部分:
# -*- coding: utf-8 -*-
import os
import warnings
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.preprocessing import LabelBinarizer
from sklearn.cluster import DBSCAN
import pickle
import seaborn as sns
import matplotlib.pyplot as plt
from read_data import read_data_from_path
from read_data import plot_cluster
from read_data import plot_surface
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from collections import Counter
warnings.filterwarnings("ignore") #不顯示警告
path = '..\題目\附件\Au20_OPT_1000'
os.chdir(path)
au_num_arr = []
ener_arr = []
cdn_data = []
cdn_for_cluster = pd.DataFrame(columns=['x','y','z'])
for file in os.listdir():
au_num, energy, cdn_vec, cdn_mat = read_data_from_path(file)
au_num_arr.append(au_num)
ener_arr.append(energy)
cdn_data.append(cdn_vec)
cdn_mat = pd.DataFrame(data=cdn_mat, columns=['x','y','z'])
cdn_for_cluster = pd.concat([cdn_for_cluster, cdn_mat], axis=0)
cdn_data = np.array(cdn_data)
ener_arr = np.array(ener_arr).reshape((-1,1))
# print(cdn_data)
# print(f'各團簇的原子坐標資料矩陣的shape:{cdn_data.shape}')
# print(cdn_for_cluster)
# print(cdn_for_cluster.shape)
def data_table(cdn_data,ener_arr, ener_plot=False):
# construct dataframe using table data struture
columns = []
for i in range(20):
for j in ('x','y','z'):
columns.append(f'第{i+1}個原子的{j}坐標')
cdn = pd.DataFrame(data=cdn_data, columns=columns)
ener = pd.DataFrame(data=ener_arr,columns=['能量'])
data = pd.concat([cdn,ener],axis=1)
# print(data.describe())
if ener_plot == False:
data.iloc[:,:-1].plot.kde()
else:
data.iloc[:,-1].plot.kde()
plt.show()
# data.to_excel("data.xlsx", index=False)
return data
# data_table(cdn_data, ener_arr)
def select_params(cdn_for_cluster):
for eps in [i*0.01 for i in range(50,60)]:
for n in range(25,29):
db = DBSCAN(eps=eps, min_samples=n).fit(cdn_for_cluster)
labels = db.labels_
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print(f'eps={eps}, n={n}')
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
def clustering(cdn_for_cluster, eps, n):
db = DBSCAN(eps=eps, min_samples=n).fit(cdn_for_cluster)
labels = db.labels_
cdn_for_cluster['label'] = labels
# Number of clusters in labels, ignoring noise if present.
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print(f'eps={eps}, n={n}')
print('Estimated number of clusters: %d' % n_clusters_)
print('Estimated number of noise points: %d' % n_noise_)
c = Counter()
for cluster_num in labels:
c[cluster_num] += 1
# print(c)
return cdn_for_cluster, labels, db
def plot_result(cdn_for_cluster, labels, exclude=[]):
fig = plt.figure(figsize=(4,4))
ax = fig.add_subplot(111, projection='3d')
cdn_for_cluster['label'] = labels
cdn_for_cluster = cdn_for_cluster.loc[~cdn_for_cluster['label'].isin(exclude)]
im = ax.scatter(xs=cdn_for_cluster.iloc[:,0],
ys=cdn_for_cluster.iloc[:,1],
zs=cdn_for_cluster.iloc[:,2],
c=cdn_for_cluster.iloc[:,-1],
cmap=plt.get_cmap('gist_ncar'),
alpha=0.5)
plt.colorbar(im)
plt.show()
def data_clu_process(labels, file_num=999, moleclue_num=20):
num = len(set(labels))-1
columns = [i for i in range(-1,num)]
data_after = pd.DataFrame(columns=columns)
for i in range(file_num):
cnt = dict((k,0) for k in columns)
tmp = labels[i:i+20]
for cluster_num in tmp:
cnt[cluster_num] += 1
data_after = data_after.append(cnt, ignore_index=True)
return data_after
def standardlize(data, plot=True):
scaler = preprocessing.StandardScaler().fit(data)
print(scaler.mean_)
print(scaler.scale_)
data_standard = scaler.transform(data)
data_standard = pd.DataFrame(data=data_standard, columns=['能量'])
if plot:
data_standard.plot.kde()
plt.show()
return scaler, data_standard
def divide(data):
q1 = float(np.round(data.quantile(0.25).values, 2))
q3 = float(np.round(data.quantile(0.75).values, 2))
iqr = float(np.round(q3 - q1, 2))
med = float(np.round(data.median().values))
top_critical = med + 1.5*iqr
bottom_critical = med - 1.5*iqr
# print(bottom_critical, q1, q3, top_critical)
bins = [bottom_critical, q1, q3, top_critical]
data = np.digitize(data.iloc[:,0], bins=bins, right=True)
data_div = pd.DataFrame(data=data, columns=['能量'])
one_hot = LabelBinarizer()
data_one_hot = one_hot.fit_transform(data_div)
data_one_hot = pd.DataFrame(data=data_div, columns=one_hot.classes_)
return data_one_hot, data_div, one_hot
path = '..\..\..\代碼'
os.chdir(path)
if __name__ == '__main__':
# data_table(cdn_data, ener_arr) #繪制 KDE
# select_params(cdn_for_cluster)
eps = 0.5
n = 28
cdn_labels, labels, db = clustering(cdn_for_cluster, eps, n)
# plot_result(cdn_for_cluster, labels, exclude=[-1])
# plot_result(cdn_for_cluster, labels)
# plot_result(cdn_for_cluster, labels, exclude=[-1,0])
data_after_clu = data_clu_process(labels)
# print(data_after)
# data_table(cdn_data,ener_arr, ener_plot=True) #繪制 KDE(能量)
# 記得把 plot 改為 True,若要畫 KDE 的話
scaler, ener_standard = standardlize(ener_arr, plot=False)
# mean = ener_standard.mean()
# std = ener_standard.std()
# print(f'標準化后的均值,方差為:{mean},{std}')
# print(ener_standard.describe())
# ener_standard.boxplot()
# plt.show()
ener_one_hot, ener_div, one_hot = divide(ener_standard)
# print(ener_div)
pickle.dump(one_hot, open(r'.\model_and_data\one_hot.pkl','wb'))
pickle.dump(ener_one_hot, open(r'.\model_and_data\ener_one_hot.pkl','wb'))
pickle.dump(ener_div, open(r'.\model_and_data\ener_div.pkl','wb'))
pickle.dump(ener_arr, open(r'.\model_and_data\ener_arr.pkl','wb'))
pickle.dump(scaler, open(r'.\model_and_data\scaler.pkl', 'wb'))
pickle.dump(db, open(r'.\model_and_data\dbscan.pkl', 'wb'))
pickle.dump(cdn_labels, open(r'.\model_and_data\cdn_labels.pkl', 'wb'))
pickle.dump(data_after_clu, open(r'.\model_and_data\data_after_clu.pkl', 'wb'))
pickle.dump(db, open(r'.\model_and_data\dbscan.pkl', 'wb'))
回傳目錄
machine_learning.py
這部分代碼對應文章的機器學習部分,
# -*- coding: utf-8 -*-
import os
import warnings
import numpy as np
from sklearn import preprocessing
import pickle
# 用于機器學習的第三方庫匯入
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import MultinomialNB
from read_data import read_data_from_path
from read_data import plot_cluster
from read_data import plot_surface
warnings.filterwarnings("ignore") #不顯示警告
def select_knn(X,Y):
""""篩選kNN演算法的最合適引數k"""
grid = {'n_neighbors':[3,5,7,9,11,13,15,17,19,21,23,25,27]}
grid_search = GridSearchCV(KNeighborsClassifier(),\
param_grid=grid,
cv=5,
scoring='accuracy')
grid_search.fit(X,Y)
print(grid_search.best_params_)
return grid_search.best_params_
def select_svc(X,Y):
grid = {'C':[0.1,0.25,0.5,0.75,1,1.25,1.5,1.75],\
'kernel':['linear','rbf','poly']}
grid_search = GridSearchCV(SVC(),param_grid=grid,cv=5,
scoring='accuracy')
grid_search.fit(X,Y)
print(grid_search.best_params_)
return grid_search.best_params_
def select_dtc(X,Y):
grid = {'max_depth':[19,24,29,34,39,44,49,54,59,64,69,74,79],\
'ccp_alpha':[0,0.00025,0.0005,0.001,0.00125,0.0015,0.002,0.005,0.01,0.05,0.1]}
grid_search = GridSearchCV(DecisionTreeClassifier(),\
param_grid=grid, cv=5, \
scoring='accuracy')
grid_search.fit(X,Y)
print(grid_search.best_params_)
return grid_search.best_params_
def select_rf(X,Y):
grid = {'n_estimators':[15,25,35,45,50,65,75,85,95]}
grid_search = GridSearchCV(RandomForestClassifier(max_samples=0.67,\
max_features=0.33, max_depth=5), \
param_grid=grid, cv=5,\
scoring='accuracy')
grid_search.fit(X,Y)
print(grid_search.best_params_)
return grid_search.best_params_
def select_ada(X,Y):
grid = {'n_estimators':[15,25,35,45,50,65,75,85,95]}
grid_search = GridSearchCV(AdaBoostClassifier( \
base_estimator=LogisticRegression()),\
param_grid=grid,
cv=5,
scoring='r2')
grid_search.fit(X,Y)
print(grid_search.best_params_)
return grid_search.best_params_
def select_model(X,Y):
knn_param = select_knn(X,Y)
svc_param = select_svc(X,Y)
dtc_param = select_dtc(X,Y)
rf_param = select_rf(X,Y)
ada_param = select_ada(X,Y)
return knn_param, svc_param, dtc_param, rf_param, ada_param
def cv_score(X, Y, \
knn_param={'n_neighbors':25}, \
svc_param={'C': 0.1, 'kernel': 'rbf'},\
dtc_param={'ccp_alpha':0.01, 'max_depth':19}, \
rf_param={'n_estimators':75},\
ada_param={'n_estimators':15}):
"""根據上述最優引數,構建模型"""
lg = LogisticRegression()
knn = KNeighborsClassifier(n_neighbors=knn_param['n_neighbors'])
svc = SVC(C=svc_param['C'], kernel=svc_param['kernel'])
dtc = DecisionTreeClassifier(max_depth=dtc_param['max_depth'],
ccp_alpha=dtc_param['ccp_alpha'])
rf = RandomForestClassifier(n_estimators=rf_param['n_estimators'],\
max_samples=0.67,\
max_features=0.33, max_depth=5)
ada = AdaBoostClassifier(base_estimator=lg,\
n_estimators=ada_param['n_estimators'])
NB = MultinomialNB(alpha=1)
"""用5折交叉驗證,計算所有模型的 r2,并計算其均值"""
S_lg_i = cross_val_score(lg, X, Y, \
scoring='accuracy',cv=5)
S_knn_i = cross_val_score(knn, X, Y, \
scoring='accuracy',cv=5)
S_svc_i = cross_val_score(svc, X, Y, \
scoring='accuracy',cv=5)
S_dtc_i = cross_val_score(dtc, X, Y, \
scoring='accuracy',cv=5)
S_rf_i = cross_val_score(rf, X, Y, \
scoring='accuracy',cv=5)
S_ada_i = cross_val_score(ada, X, Y, \
scoring='accuracy',cv=5)
S_NB_i = cross_val_score(NB, X, Y,\
scoring='accuracy',cv=5)
print(f'lg : {np.mean(S_lg_i)}')
print(f'knn : {np.mean(S_knn_i)}')
print(f'svc : {np.mean(S_svc_i)}')
print(f'dtc :{np.mean(S_dtc_i)}')
print(f'rf : {np.mean(S_rf_i)}')
print(f'ada : {np.mean(S_ada_i)}')
print(f'NB : {np.mean(S_NB_i)}')
return S_lg_i, S_knn_i, S_svc_i, S_dtc_i, S_rf_i, S_ada_i, S_NB_i
if __name__ == '__main__':
data_after_clu = pickle.load(open(r'.\model_and_data\data_after_clu.pkl','rb'))
ener_div = pickle.load(open(r'.\model_and_data\ener_div.pkl','rb'))
# print(data_after_clu)
# print(ener_div)
# knn_param, svc_param, dtc_param, rf_param, ada_param = select_model(data_after_clu,
# ener_div)
S_lg_i, S_knn_i, S_svc_i, S_dtc_i, \
S_rf_i, S_ada_i, S_NB_i= cv_score(data_after_clu,ener_div)
回傳目錄
deep_learning_method.py
這部分代碼對應文章的多層感知器部分,
# -*- coding: utf-8 -*-
import pickle
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.model_selection import train_test_split
import tensorflow_addons as tfa
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore") #不顯示警告
font1 = {'family' : 'Times New Roman',
'weight' : 'normal',
'size' : 20,
}
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def plot_train_test(history):
plt.figure(figsize=(12,4))
plt.subplots_adjust(left=0.125, bottom=None, right=0.9, top=None,
wspace=0.3, hspace=None)
plt.subplot(1,2,1)
plt.plot(history.history['loss'],linewidth=3,label='Train')
plt.plot(history.history['val_loss'],linewidth=3,linestyle='dashed',label='Test')
plt.xlabel('Epoch',fontsize=20)
plt.ylabel('loss',fontsize=20)
plt.legend(prop=font1)
plt.subplot(1,2,2)
plt.plot(history.history['categorical_accuracy'],linewidth=3,label='Train')
plt.plot(history.history['val_categorical_accuracy'],linewidth=3,linestyle='dashed',label='Test')
plt.xlabel('Epoch',fontsize=20)
plt.ylabel('Acc',fontsize=20)
plt.legend(prop=font1)
plt.show()
if __name__ == '__main__':
data_after_clu = pickle.load(open('./model_and_data/data_after_clu.pkl','rb'))
ener_div = pickle.load(open(r'.\model_and_data\ener_div.pkl','rb'))
ener_one_hot = pickle.load(open(r'.\model_and_data\ener_one_hot.pkl','rb'))
data_after_clu = data_after_clu.to_numpy(dtype=np.int32)
ener_div = ener_div.to_numpy(dtype=np.int32)
ener_one_hot = ener_one_hot.to_numpy(dtype=np.int32)
X_train, X_test, y_train, y_test = train_test_split(
data_after_clu,\
ener_one_hot,\
test_size=0.3,\
random_state=0)
rows, cols = data_after_clu.shape
# print(y_train.shape)
# print(y_test.shape)
model = keras.Sequential()
model.add(layers.Input(shape=(cols,)))
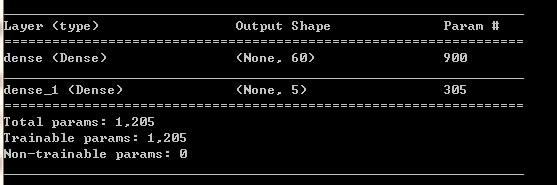
model.add(layers.Dense(60, activation='sigmoid'))
model.add(layers.Dense(5, activation='sigmoid'))
loss_fn = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
model.compile(
optimizer='adam', # Optimizer
# Loss function to minimize
loss= loss_fn,
# List of metrics to monitor
metrics =['categorical_accuracy']
)
filepath = r'./model_and_data/ann_model.h5'
checkpoint = ModelCheckpoint(filepath=filepath,monitor='val_acc',
verbose=1,save_best_only=True,mode='max')
callback_list=[checkpoint]
history = model.fit(
X_train,
y_train,
batch_size=200,
epochs=200,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(X_test, y_test),
callbacks=callback_list,
)
plot_train_test(history)
model.summary()
conv_network.py
這部分對應文章的卷積神經網路
import pickle
import numpy as np
import pandas as pd
import os
from read_data import read_data_from_path
import tensorflow as tf
from tensorflow.keras import layers
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.callbacks import ModelCheckpoint
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
font1 = {'family' : 'Times New Roman',
'weight' : 'normal',
'size' : 20,
}
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def build_cnn_model(rate=0.2, initializer='glorot_uniform'):
model = tf.keras.Sequential()
model.add(layers.Conv2D(8, 2, activation='relu', padding='same',
input_shape=input_shape[1:],
kernel_initializer=initializer))
model.add(layers.Dropout(rate=rate))
model.add(layers.Conv2D(16, 2, activation='relu', padding='same',
input_shape=input_shape[1:],
kernel_initializer=initializer))
model.add(layers.Dropout(rate=rate))
model.add(layers.Conv2D(8, 2, activation='relu', padding='same',
input_shape=input_shape[1:],
kernel_initializer=initializer))
model.add(layers.Dropout(rate=rate))
model.add(layers.AveragePooling2D(pool_size=(2,2), strides=(1,1),
padding='valid'))
model.add(layers.Flatten())
model.add(layers.Dense(units=32, activation='relu',
kernel_initializer=initializer))
model.add(layers.Dropout(rate=rate))
model.add(layers.Dense(units=8, activation='relu',
kernel_initializer=initializer))
model.add(layers.Dropout(rate=rate))
model.add(layers.Dense(units=1, activation='linear'))
loss_fn = tf.keras.losses.MeanSquaredError()
optimizer = tf.keras.optimizers.Adam(
learning_rate=0.001, beta_1=0.9, beta_2=0.999,
epsilon=1e-07,
amsgrad=False,
name='Adam',
)
model.compile(
optimizer=optimizer, # Optimizer
# Loss function to minimize
loss= loss_fn,
# List of metrics to monitor
metrics =['mae']
)
model.summary()
return model
def plot_train_test(model, epochs=200, batch_size=200):
filepath = r'./model_and_data/cnn_model.h5'
checkpoint = ModelCheckpoint(filepath=filepath,monitor='val_mae',
verbose=1,save_best_only=True,mode='min')
callback_list=[checkpoint]
history = model.fit(
X_train,
y_train,
batch_size=batch_size,
epochs=epochs,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
validation_data=(X_test, y_test),
callbacks=callback_list,
)
plt.figure(figsize=(12,4))
plt.subplots_adjust(left=0.125, bottom=None, right=0.9, top=None,
wspace=0.3, hspace=None)
plt.subplot(1,2,1)
plt.plot(history.history['loss'],linewidth=3,label='Train')
plt.plot(history.history['val_loss'],linewidth=3,linestyle='dashed',label='Test')
plt.xlabel('Epoch',fontsize=20)
plt.ylabel('loss',fontsize=20)
plt.legend(prop=font1)
plt.subplot(1,2,2)
plt.plot(history.history['mae'],linewidth=3,label='Train')
plt.plot(history.history['val_mae'],linewidth=3,linestyle='dashed',label='Test')
plt.xlabel('Epoch',fontsize=20)
plt.ylabel('Acc',fontsize=20)
plt.legend(prop=font1)
plt.show()
if __name__ == "__main__":
cdn_data = pickle.load(open('./model_and_data/cdn_labels.pkl','rb'))
ener_arr = pickle.load(open('./model_and_data/ener_arr.pkl', 'rb'))
ener_arr = np.array(ener_arr).reshape((-1,1))
cdn_data = cdn_data.iloc[:,:-1].to_numpy()
min_max_scaler = MinMaxScaler()
cdn_scale = min_max_scaler.fit_transform(cdn_data)
cdn_scale = cdn_scale.reshape(999,20,3,1)
standard_scaler = pickle.load(open('./model_and_data/scaler.pkl','rb'))
ener_scale = standard_scaler.transform(ener_arr)
input_shape = cdn_scale.shape
print(input_shape)
print(cdn_scale)
pickle.dump(min_max_scaler, open(r'./model_and_data/min_max_scaler.pkl','wb'))
X_train, X_test, y_train, y_test = train_test_split(
cdn_scale,\
ener_scale,\
test_size=0.3,\
random_state=0)
model = build_cnn_model()
plot_train_test(model)
回傳目錄
題外話
DBSCAN 演算法解釋網站
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
TensorFlow BUG?
我本來用 one-hot 編碼法,對(類別化后的)能量進行編碼,再用神經網路模型的,然后用類別交叉熵,作為損失函式;用 categorical_accuracy 作為評價指標,來評價模型效果:
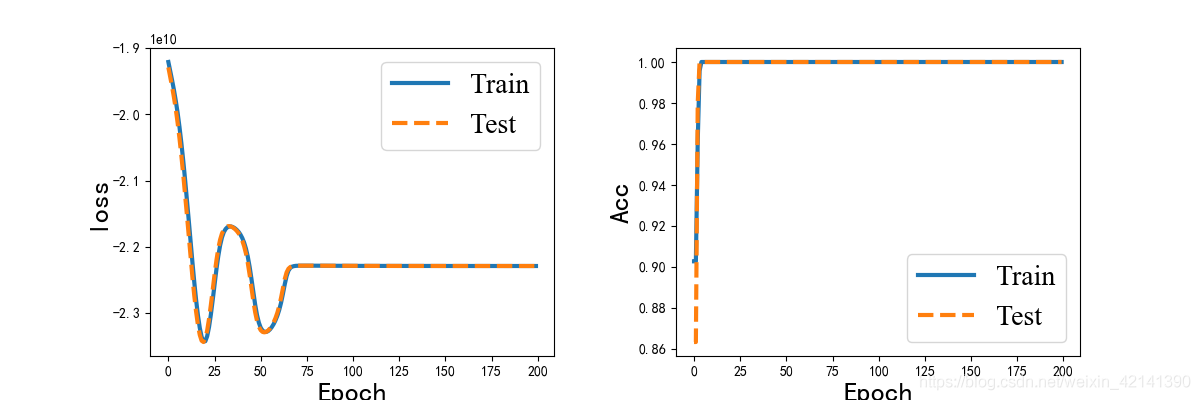
發現精確度居然達到 100% ,然而,在實際用的時候,(就用在訓練集上!!),卻發現精確度是 0%,當真苦笑不得,,
如果需要代碼源檔案的,可以關注一下我,回復競賽, 如果自動回復通過的話,就會馬上將網盤鏈接發給你們啦,否則就得手動發了,手動發很慢,大家多擔待,
回傳目錄
其中 (999,20,3,1) 中的1是指一個通道(channel),何謂通道?如 RGB 就是 3 通道, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277340.html
標籤:python
上一篇:Python基礎筆記
下一篇:5W+H解讀Python