梯度下降及線性回歸詳解
- 一. 一元線性回歸
- 1 摘要
- 2 什么是回歸分析
- 3 如何擬合這條直線(方法)
- 4 最小二乘法
- 4.1 基本思想
- 4.2 推導程序
- 4.3 代碼
- 4.4 輸出結果
- 5 梯度下降演算法
- 5.1 目標/損失函式
- 5.2 梯度下降三兄弟(BGD,SGD, MBGD)
- 5.2.1 批量梯度下降法(Batch Gradient Descent)
- 5.2.2 隨機梯度下降法(Stochastic Gradient Descent)
- 5.2.3小批量梯度下降法(Mini-batch Gradient Descent)
- 5.3 梯度下降法的一般步驟
- 5.4 一元線性回歸函式推導程序
- 5 (例子)波士頓房價預測
- 5.1 代碼實作(Python)
- 5.2 輸出結果
- 二. 多元線性回歸
- 1 定義資料
- 3 定義函式
- 4 梯度下降
- 6 (例子)鳶尾花資料集
- 6.1 代碼實作(Python)
- 6.2 輸出結果
- 三.三種資料集
- 1 訓練集
- 2 驗證集
- 3 測驗集
- 4 三者區別
- 5 交叉驗證
- 四.回歸模型評價指標
一. 一元線性回歸
1 摘要
一元線性回歸可以說是資料分析中非常簡單的一個知識點,有一點點統計、分析、建模經驗的人都知道這個分析的含義,也會用各種工具來做這個分析,這里面想把這個分析背后的細節講講清楚,也就是后面的數學原理,
2 什么是回歸分析
回歸分析(Regression Analysis)是確定兩種或兩種以上變數間相互依賴的定量關系的一種統計分析方法,在回歸分析中,只包括一個自變數和一個因變數,且二者的關系可用一條直線近似表示,這種回歸分析稱為一元線性回歸分析,如果回歸分析中包括兩個或兩個以上自變數,且自變數和因變數之間是線性關系,則稱為多元線性回歸分析,我們先學習一元線性回歸分析,舉個例子來說吧:
比方說有一個公司,每月的廣告費用和銷售額,如下表所示:

如果我們把廣告費和銷售額畫在二維坐標內,就能夠得到一個散點圖,如果想探索廣告費和銷售額的關系,就可以利用一元線性回歸做出一條擬合直線
y
^
=
ω
x
+
b
\hat{y}=\omega x+b
y^?=ωx+b如圖:
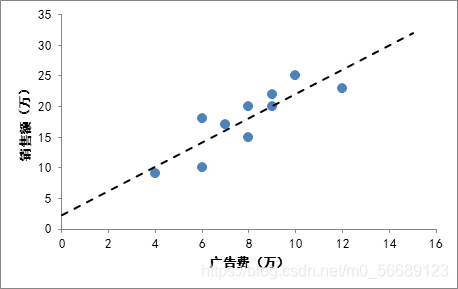 我們擬合出直線后可對廣告費和銷售額進行預測,這是一個應用
我們擬合出直線后可對廣告費和銷售額進行預測,這是一個應用
3 如何擬合這條直線(方法)
最常用的有最小二乘法和梯度下降演算法,下面我們分別講講最小二乘法和梯度下降演算法,主要講解梯度下降演算法
4 最小二乘法
4.1 基本思想
求出這樣一些未知引數使得樣本點和擬合線的總誤差(距離)最小最直觀的感受如下圖(圖參考自知乎某作者)
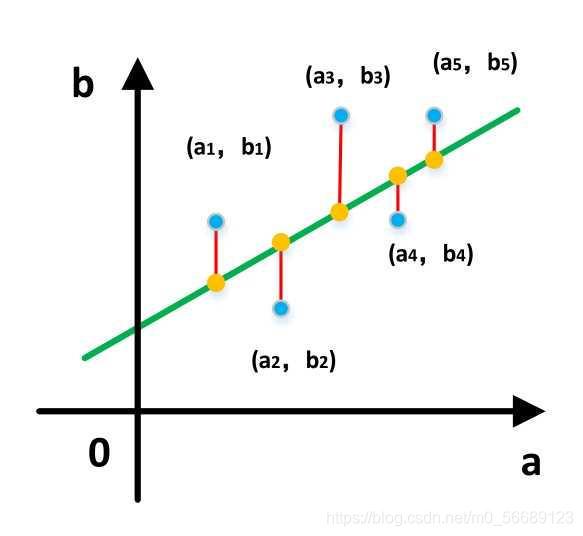
而這個誤差(距離)可以直接相減,但是直接相級訓有正有負,相互抵消了,所以就用差的平方
4.2 推導程序


4.3 代碼
import numpy as np
from matplotlib import pylab as pl
#Defining training data
x = np.array([1,3,2,1,3])
y = np.array([14,24,18,17,27])
# The regression equation takes the function
def fit(x,y):
if len(x) != len(y):
return
numerator = 0.0
denominator = 0.0
x_mean = np.mean(x)
y_mean = np.mean(y)
for i in range(len(x)):
numerator += (x[i]-x_mean)*(y[i]-y_mean)
denominator += np.square((x[i]-x_mean))
print('numerator:',numerator,'denominator:',denominator)
b0 = numerator/denominator
b1 = y_mean - b0*x_mean
return b0,b1
# Define prediction function
def predit(x,b0,b1):
return b0*x + b1
# Find the regression equation
b0,b1 = fit(x,y)
print('Line is:y = %2.0fx + %2.0f'%(b0,b1))
# prediction
x_test = np.array([0.5,1.5,2.5,3,4])
y_test = np.zeros((1,len(x_test)))
for i in range(len(x_test)):
y_test[0][i] = predit(x_test[i],b0,b1)
# Drawing figure
xx = np.linspace(0, 5)
yy = b0*xx + b1
pl.plot(xx,yy,'k-')
pl.scatter(x,y,cmap=pl.cm.Paired)
pl.scatter(x_test,y_test[0],cmap=pl.cm.Paired)
pl.show()
4.4 輸出結果

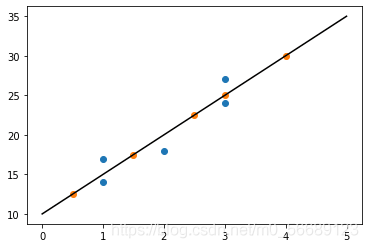
5 梯度下降演算法
學習梯度下降演算法大家可以看我的博客,梯度下降演算法
https://editor.csdn.net/md/?articleId=115729027
我們現在需要將梯度下降演算法應用進線性回歸中去,我們還需要學習下面內容
5.1 目標/損失函式
損失函式用來評價模型的預測值和真實值不一樣的程度,損失函式越好, 通常模型的性能越好,不同的模型用的損失函式一般也不一樣,在應用中,通常通過最小化損失函式求解和評估模型,
求解最佳引數,需要一個標準來對結果進行衡量,為此我們需要定量化一 個目標函式式,使得計算機可以在求解程序中不斷地優化,
針對任何模型求解問題,都是最終都是可以得到一組預測值 y ^ \hat{y} y^?,對比已有的真實值 y y y,資料行數為 n n n,可以將損失函式定義如下: L = 1 n ∑ i = 1 n ( y ^ i ? y i ) 2 L=\frac{1}{n}\sum_{i=1}^{n}(\hat{y}_i-y_i)^2 L=n1?i=1∑n?(y^?i??yi?)2
即預測值與真實值之間的平均的平方距離,統計中一般稱其為MAE(mean square error)均方誤差,把之前的函式式代入損失函式,并且將需要求解 的引數w和b看做是函式L的自變數,可得: L ( w , b ) = 1 n ∑ i = 1 n ( w x i + b ? y i ) 2 L(w,b)=\frac{1}{n}\sum_{i=1}^{n}(wx_i+b-y_i)^2 L(w,b)=n1?i=1∑n?(wxi?+b?yi?)2
現在的任務是求解最小化
L
L
L時
w
w
w和
b
b
b的值,
即核心目標優化式為:
(
w
?
,
b
?
)
=
arg
?
min
?
(
w
,
b
)
∑
i
=
1
n
(
w
x
i
+
b
?
y
i
)
2
(w^*,b^*)=\arg\min_{(w,b)}\sum_{i=1}^{n}(wx_i+b-y_i)^2
(w?,b?)=arg(w,b)min?i=1∑n?(wxi?+b?yi?)2
5.2 梯度下降三兄弟(BGD,SGD, MBGD)
我們在用梯度下降演算法解決線性回歸問題時需要采用資料集
現在有三種不同的采用方式,因此也產生了三種不同的梯度下降演算法
- 下面涉及到資料集名詞,可結合本篇內容三理解
5.2.1 批量梯度下降法(Batch Gradient Descent)
批量梯度下降法每次都使用訓練集中的所有樣本更新引數,它得到的是一 個全域最優解,但是每迭代一步,都要用到訓練集所有的資料,如果m很 大,那么迭代速度就會變得很慢, 優點:可以得出全域最優解, 缺點:樣本資料集大時,訓練速度慢
5.2.2 隨機梯度下降法(Stochastic Gradient Descent)
隨機梯度下降法每次更新都從樣本隨機選擇1組資料,因此隨機梯度下降比 批量梯度下降在計算量上會大大減少,SGD有一個缺點是,其噪音較BGD 要多,使得SGD并不是每次迭代都向著整體最優化方向,而且SGD因為每 次都是使用一個樣本進行迭代,因此最終求得的最優解往往不是全域最優 解,而只是區域最優解,但是大的整體的方向是向全域最優解的,最終的 結果往往是在全域最優解附近, 優點:訓練速度較快, 缺點:程序雜亂,準確度下降,
5.2.3小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法對包含n個樣本的資料集進行計算,綜合了上述兩種方 法,既保證了訓練速度快,又保證了準確度,
5.3 梯度下降法的一般步驟
假設函式:
y
=
f
(
x
1
,
x
2
,
x
3
.
.
.
.
x
n
)
y=f(x_1,x_2,x_3....x_n)
y=f(x1?,x2?,x3?....xn?) 只有一個極小點,
初始給定引數為
X
0
=
(
x
1
0
,
x
2
0
,
x
3
0....
x
n
0
)
X_0=(x_10,x_20,x_30....x_n0)
X0?=(x1?0,x2?0,x3?0....xn?0) ,
從這個點如何搜索才能找到 原函式的極小值點?
方法:
①首先設定一個較小的正數
α
,
ε
\alpha,\varepsilon
α,ε;
②求當前位置出處的各個偏導數:
f
′
(
x
m
0
)
=
?
y
?
x
m
(
x
m
0
)
,
m
=
1
,
2
,
.
.
.
,
n
f^{'}(x_{m0})=\frac{\partial y}{\partial x_m}(x_{m0}),m=1,2,...,n
f′(xm0?)=?xm??y?(xm0?),m=1,2,...,n
③修改當前函式的引數值,公式如下:
x
m
′
=
x
m
?
α
α
y
α
x
m
(
x
m
0
)
,
m
=
1
,
2
,
.
.
.
,
n
\ x^{'}_m=x_m-\alpha\frac{\alpha y}{\alpha x_m}(x_{m0}),m=1,2,...,n
xm′?=xm??ααxm?αy?(xm0?),m=1,2,...,n
④如果引數變化量小于 ,退出;否則回傳第2步,
5.4 一元線性回歸函式推導程序
設線性回歸函式:
y
^
=
ω
x
+
b
\hat{y}=\omega x+b
y^?=ωx+b
構造損失函式(loss):
L
(
w
,
b
)
=
1
2
n
∑
i
=
1
n
(
w
x
i
+
b
?
y
i
)
2
L(w,b)=\frac{1}{2n}\sum_{i=1}^{n}(wx_i+b-y_i)^2
L(w,b)=2n1?i=1∑n?(wxi?+b?yi?)2
思路:通過梯度下降法不斷更新 和 ,當損失函式的值特別小時,就得到
了我們最終的函式模型,
程序:
step1.求導:
α
α
w
L
(
w
,
b
)
=
1
n
∑
i
=
1
n
(
(
w
x
i
+
b
?
y
i
)
?
x
i
)
\frac{\alpha}{\alpha w}L(w,b)=\frac{1}{n}\sum_{i=1}^{n}((wx_i+b-y_i)\cdot x_i)
αwα?L(w,b)=n1?i=1∑n?((wxi?+b?yi?)?xi?)
α
α
b
L
(
w
,
b
)
=
1
n
∑
i
=
1
n
(
w
x
i
+
b
?
y
i
)
\frac{\alpha}{\alpha b}L(w,b)=\frac{1}{n}\sum_{i=1}^{n}(wx_i+b-y_i)
αbα?L(w,b)=n1?i=1∑n?(wxi?+b?yi?)
step2.更新
θ
0
\theta _0
θ0?和
θ
1
\theta _1
θ1? :
w
=
w
?
α
?
1
n
∑
i
=
1
n
(
(
w
x
i
+
b
?
y
i
)
?
x
i
)
w=w-\alpha \cdot \frac{1}{n} \sum_{i=1}^{n}((wx_i+b-y_i)\cdot x_i)
w=w?α?n1?i=1∑n?((wxi?+b?yi?)?xi?)
b
=
b
?
α
?
1
n
∑
i
=
1
n
(
w
x
i
+
b
?
y
i
)
b=b-\alpha \cdot \frac{1}{n} \sum_{i=1}^{n}(wx_i+b-y_i)
b=b?α?n1?i=1∑n?(wxi?+b?yi?)
5 (例子)波士頓房價預測
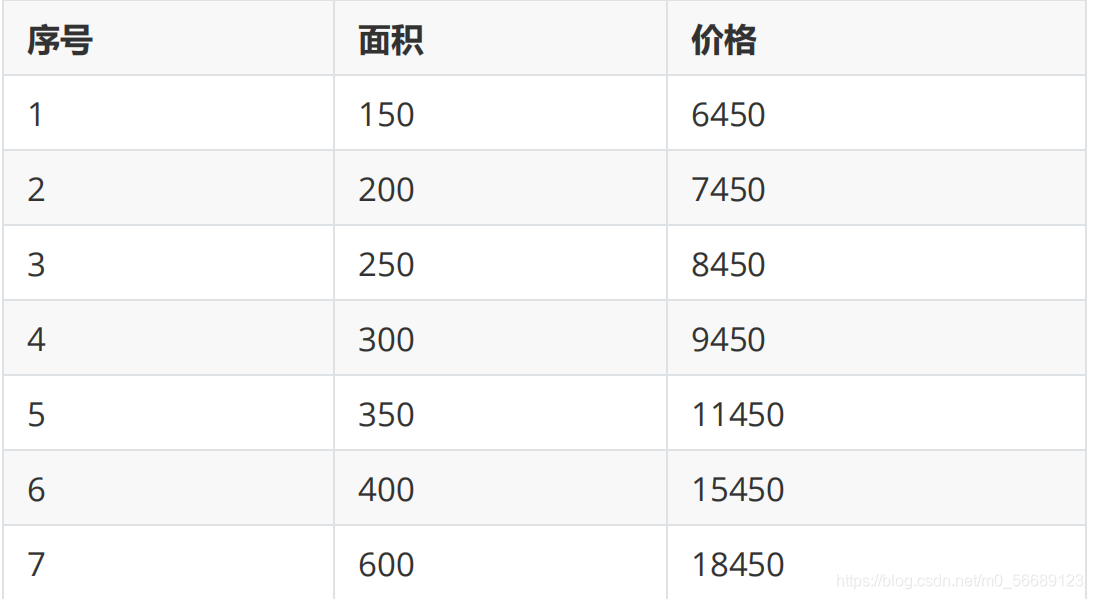
房屋價格與面積(資料在下面表格中):
使用梯度下降求解線性回歸(求
θ
0
\theta _0
θ0?,
θ
1
\theta_1
θ1? )
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_{\theta}(x)=\theta_0+\theta_1 x
hθ?(x)=θ0?+θ1?x
5.1 代碼實作(Python)
#房屋價格與面積
#序號:1 2 3 4 5 6 7
#面積:150 200 250 300 350 400 600
#價格:6450 7450 8450 9450 11450 15450 18450
import matplotlib.pyplot as plt
import matplotlib
from math import pow
import random
x0 = [150,200,250,300,350,400,600]
y0 = [6450,7450,8450,9450,11450,15450,18450]
#為了方便計算,將所有資料縮小 100 倍
x = [1.50,2.00,2.50,3.00,3.50,4.00,6.00]
y = [64.50,74.50,84.50,94.50,114.50,154.50,184.50]
#線性回歸函式為 y=theta0+theta1*x
#損失函式 J (θ)=(1/(2*m))*pow((theta0+theta1*x[i]-y[i]),2)
#引數定義
theta0 = 0.1#對 theata0 賦值
theta1 = 0.1#對 theata1 賦值
alpha = 0.1#學習率
m = len(x)
count0 = 0
theta0_list = []
theta1_list = []
#1.使用批量梯度下降法
for num in range(10000):
count0 += 1
diss = 0 #誤差
deriv0 = 0 #對 theata0 導數
deriv1 = 0 #對 theata1 導數
#求導
for i in range(m):
deriv0 += (theta0+theta1*x[i]-y[i])/m#對每一項測驗資料求導再求和取平均值
deriv1 += ((theta0+theta1*x[i]-y[i])/m)*x[i]
#更新 theta0 和 theta1
theta0 = theta0 - alpha*deriv0
theta1 = theta1 - alpha*deriv1
#求損失函式 J (θ)
for i in range(m):
diss = diss + (1/(2*m))*pow((theta0+theta1*x[i]-y[i]),2)
theta0_list.append(theta0*100)
theta1_list.append(theta1)
#如果誤差已經很小,則退出回圈
if diss <= 0.001:
break
theta0 = theta0*100#前面所有資料縮小了 100 倍,所以求出的 theta0 需要放大 100 倍,theta1 不用變
#2.使用隨機梯度下降法
theta2 = 0.1#對 theata2 賦值
theta3 = 0.1#對 theata3 賦值
count1 = 0
theta2_list = []
theta3_list = []
for num in range(10000):
count1 += 1
diss = 0 #誤差
deriv2 = 0 #對 theata2 導數
deriv3 = 0 #對 theata3 導數
#求導
for i in range(m):
deriv2 += (theta2+theta3*x[i]-y[i])/m
deriv3 += ((theta2+theta3*x[i]-y[i])/m)*x[i]
#更新 theta0 和 theta1
for i in range(m):
theta2 = theta2 - alpha*((theta2+theta3*x[i]-y[i])/m)
theta3 = theta3 - alpha*((theta2+theta3*x[i]-y[i])/m)*x[i]
#求損失函式 J (θ)
rand_i = random.randrange(0,m)
diss = diss + (1/(2*m))*pow((theta2+theta3*x[rand_i]-y[rand_i]),2)
theta2_list.append(theta2*100)
theta3_list.append(theta3)
#如果誤差已經很小,則退出回圈
if diss <= 0.001:
break
theta2 = theta2*100
print("批量梯度下降最終得到theta0={},theta1={}".format(theta0,theta1))
print(" 得到的回歸函式是:y={}+{}*x".format(theta0,theta1))
print("隨機梯度下降最終得到theta0={},theta1={}".format(theta2,theta3))
print(" 得到的回歸函式是:y={}+{}*x".format(theta2,theta3))
#畫原始資料圖和函式圖
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
plt.plot(x0,y0,'bo',label='資料',color='black')
plt.plot(x0,[theta0+theta1*x for x in x0],label='批量梯度下降',color='red')
plt.plot(x0,[theta2+theta3*x for x in x0],label='隨機梯度下降',color='blue')
plt.xlabel('x(面積)')
plt.ylabel('y(價格)')
plt.legend()
plt.show()
plt.scatter(range(count0),theta0_list,s=1)
plt.scatter(range(count0),theta1_list,s=1)
plt.xlabel('上方為theta0,下方為theta1')
plt.show()
plt.scatter(range(count1),theta2_list,s=3)
plt.scatter(range(count1),theta3_list,s=3)
plt.xlabel('上方為theta0,下方為theta1')
plt.show()
5.2 輸出結果

線性回歸函式影像:
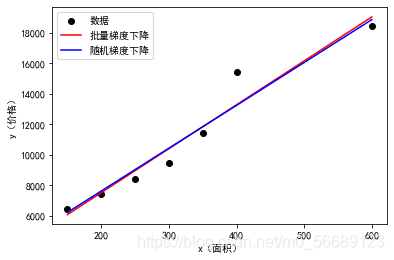
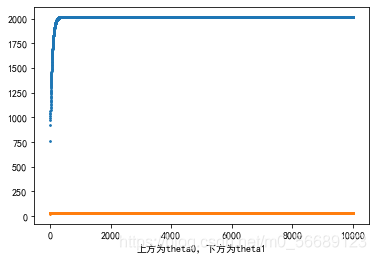
批量梯度下降時的theta0和theta1的變化:
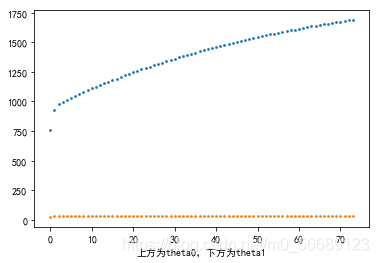
隨機梯度下降時的theta0和theta1的變化:
二. 多元線性回歸
1 定義資料
以下面一組資料作為例子:
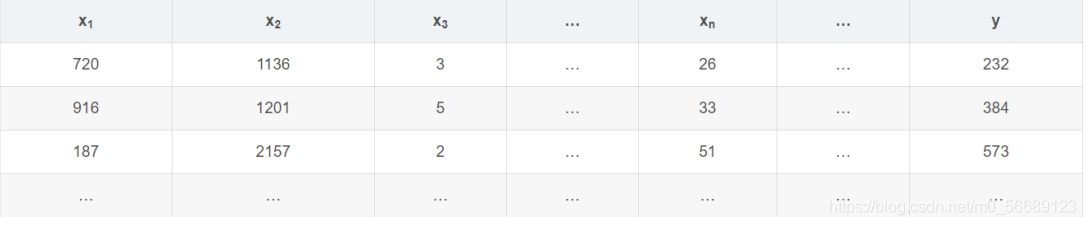
以上角標作為行索引,以下角標作為列索引
第二行可以寫成:
x
(
2
)
=
[
916
1201
5
.
.
.
33
]
x^{(2)}=\begin{bmatrix} 916 \\ 1201\\ 5\\ ...\\ 33 \end{bmatrix}
x(2)=???????91612015...33????????
位于第二行第一列位置的數寫成:
x
1
(
2
)
=
916
x^{(2)}_1=916
x1(2)?=916
以上下角標來區分位置,以便于后期運算,
3 定義函式
設定一個回歸方程:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
θ
3
x
3
+
?
?
?
+
θ
n
x
n
h_\theta (x)=\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_3+\cdot \cdot \cdot +\theta_nx_n
hθ?(x)=θ0?+θ1?x1?+θ2?x2?+θ3?x3?+???+θn?xn?
添加一個列向量
x
0
=
[
1
,
1
,
1
,
1
,
.
.
.
,
1
]
T
x_0=[1,1,1,1,...,1]^T
x0?=[1,1,1,1,...,1]T
這樣方程可以寫為:
h
θ
(
x
)
=
θ
0
x
0
+
θ
1
x
1
+
θ
2
x
2
+
θ
3
x
3
+
?
?
?
+
θ
n
x
n
h_\theta (x)=\theta_0 x_0+\theta_1x_1+\theta_2x_2+\theta_3x_3+\cdot \cdot \cdot +\theta_nx_n
hθ?(x)=θ0?x0?+θ1?x1?+θ2?x2?+θ3?x3?+???+θn?xn?
既不會影響到方程的結果,而且使 與 的數量一致以便于矩陣計算,
為了更方便表達,分別記為:
X
=
[
x
0
x
1
x
2
x
3
.
.
.
x
n
]
,
θ
=
[
θ
0
θ
1
θ
2
θ
3
.
.
.
θ
n
]
X=\begin{bmatrix} x_0 \\ x_1\\ x_2\\ x_3\\ ...\\ x_n \end{bmatrix},\theta =\begin{bmatrix} \theta_0 \\ \theta_1\\ \theta_2\\ \theta_3\\ ...\\ \theta_n \end{bmatrix}
X=?????????x0?x1?x2?x3?...xn???????????,θ=?????????θ0?θ1?θ2?θ3?...θn???????????
這樣方程就變為:
h
θ
(
x
)
=
[
θ
0
,
θ
1
,
θ
2
,
θ
3
,
.
.
.
,
θ
n
]
T
[
x
0
x
1
x
2
x
3
.
.
.
x
n
]
h_\theta(x)=[\theta_0,\theta_1,\theta_2,\theta_3,...,\theta_n]^T\begin{bmatrix} x_0 \\ x_1\\ x_2\\ x_3\\ ...\\ x_n \end{bmatrix}
hθ?(x)=[θ0?,θ1?,θ2?,θ3?,...,θn?]T?????????x0?x1?x2?x3?...xn???????????
由回歸方程推匯出損失方程:
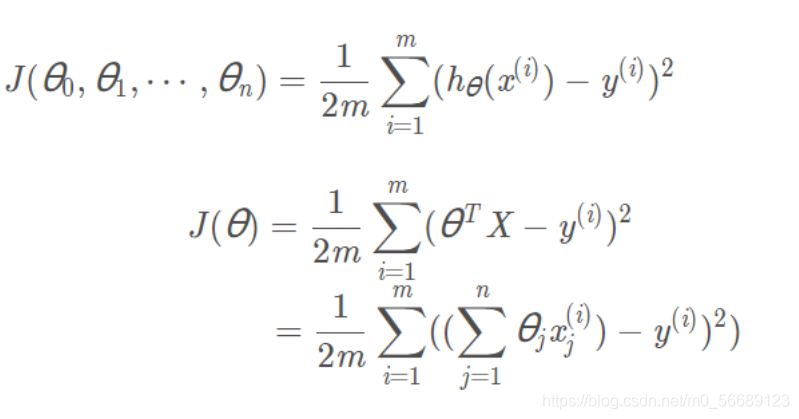
4 梯度下降

計算時要從
θ
0
\theta_0
θ0?一直計算到
θ
n
\theta_n
θn?后,再從頭由
θ
0
\theta_0
θ0?開始計算,以確保資料統一變
化,
在執行次數足夠多的迭代后,我們就能取得達到要求的
θ
j
\theta_j
θj?的值,
6 (例子)鳶尾花資料集
Iris 鳶尾花資料集內包含 3 類,分別為山鳶尾(Iris-setosa)、變色鳶尾
(Iris-versicolor)和維吉尼亞鳶尾(Iris-virginica),共 150 條記錄,
每類各 50 個資料,每條記錄都有 4 項特征:花萼長度、花萼寬度、花瓣長
度、花瓣寬度,可以通過這 4 個特征預測鳶尾花卉屬于哪一品種, 這是本
文章所使用的鳶尾花資料集: sl:花萼長度 ;sw:花萼寬度 ;pl:花瓣長
度 ;pw:花瓣寬度; type:類別:(Iris-setosa、Iris-versicolor、
Iris-virginica 三類)
鳶尾花資料集下載:
https://archive.ics.uci.edu/ml/machine-learning-databases/iris/

下載這個iris.data 即可
將其置于當前作業檔案夾即可
6.1 代碼實作(Python)
import numpy as np
import pandas as pd
import random
import time
def MGD_train(X, y, alpha=0.0001, maxIter=1000, theta_old=None):
'''
MGD訓練線性回歸
傳入:
X : 已知資料
y : 標簽
alpha : 學習率
maxIter : 總迭代次數
回傳:
theta : 權重引數
'''
# 初始化權重引數
theta = np.ones(shape=(X.shape[1],))
if not theta_old is None:
# 假裝是斷點續訓練
theta = theta_old.copy()
#axis=1 表示橫軸,方向從左到右;axis=0 表示縱軸,方向從上到下
for i in range(maxIter):
# 預測
y_pred = np.sum(X * theta, axis=1)
# 全部資料得到的梯度
gradient = np.average((y - y_pred).reshape(-1, 1) * X, axis=0)
# 更新學習率
theta += alpha * gradient
return theta
def SGD_train(X, y, alpha=0.0001, maxIter=1000, theta_old=None):
'''
SGD訓練線性回歸
傳入:
X : 已知資料
y : 標簽
alpha : 學習率
maxIter : 總迭代次數
回傳:
theta : 權重引數
'''
# 初始化權重引數
theta = np.ones(shape=(X.shape[1],))
if not theta_old is None:
# 假裝是斷點續訓練
theta = theta_old.copy()
# 資料數量
data_length = X.shape[0]
for i in range(maxIter):
# 隨機選擇一個資料
index = np.random.randint(0, data_length)
# 預測
y_pred = np.sum(X[index, :] * theta)
# 一條資料得到的梯度
gradient = (y[index] - y_pred) * X[index, :]
# 更新學習率
theta += alpha * gradient
return theta
def MBGD_train(X, y, alpha=0.0001, maxIter=1000, batch_size=10, theta_old=None):
'''
MBGD訓練線性回歸
傳入:
X : 已知資料
y : 標簽
alpha : 學習率
maxIter : 總迭代次數
batch_size : 沒一輪喂入的資料數
回傳:
theta : 權重引數
'''
# 初始化權重引數
theta = np.ones(shape=(X.shape[1],))
if not theta_old is None:
# 假裝是斷點續訓練
theta = theta_old.copy()
# 所有資料的集合
all_data = np.concatenate([X, y.reshape(-1, 1)], axis=1)
for i in range(maxIter):
# 從全部資料里選 batch_size 個 item
X_batch_size = np.array(random.choices(all_data, k=batch_size))
# 重新給 X, y 賦值
X_new = X_batch_size[:, :-1]
y_new = X_batch_size[:, -1]
# 將資料喂入,更新 theta
theta = MGD_train(X_new, y_new, alpha=0.0001, maxIter=1, theta_old=theta)
return theta
def GD_predict(X, theta):
'''
用于預測的函式
傳入:
X : 資料
theta : 權重
回傳:
y_pred: 預測向量
'''
y_pred = np.sum(theta * X, axis=1)
# 實數域空間 -> 離散三值空間,則需要四舍五入
y_pred = (y_pred + 0.5).astype(int)
return y_pred
def calc_accuracy(y, y_pred):
'''
計算準確率
傳入:
y : 標簽
y_pred : 預測值
回傳:
accuracy : 準確率
'''
return np.average(y == y_pred)*100
# 讀取資料
iris_raw_data = pd.read_csv('iris.data', names =['sepal length', 'sepal width', 'petal length', 'petal width', 'class'])
# 將三種型別映射成整數
Iris_dir = {'Iris-setosa': 1, 'Iris-versicolor': 2, 'Iris-virginica': 3}
iris_raw_data['class'] = iris_raw_data['class'].apply(lambda x:Iris_dir[x])
# 訓練資料 X
iris_data = iris_raw_data.values[:, :-1]
# 標簽 y
y = iris_raw_data.values[:, -1]
# 用 MGD 訓練的引數
start = time.time()
theta_MGD = MGD_train(iris_data, y)
run_time = time.time() - start
y_pred_MGD = GD_predict(iris_data, theta_MGD)
print("MGD訓練1000輪得到的準確率{:.2f}% 運行時間是{:.2f}s".format(calc_accuracy(y, y_pred_MGD), run_time))
# 用 SGD 訓練的引數
start = time.time()
theta_SGD = SGD_train(iris_data, y)
run_time = time.time() - start
y_pred_SGD = GD_predict(iris_data, theta_SGD)
print("SGD訓練1000輪得到的準確率{:.2f}% 運行時間是{:.2f}s".format(calc_accuracy(y, y_pred_SGD), run_time))
# 用 MBGD 訓練的引數
start = time.time()
theta_MBGD = MBGD_train(iris_data, y)
run_time = time.time() - start
y_pred_MBGD = GD_predict(iris_data, theta_MBGD)
print("MBGD訓練1000輪得到的準確率{:.2f}% 運行時間是{:.2f}s".format(calc_accuracy(y, y_pred_MBGD), run_time))
6.2 輸出結果

三.三種資料集
1 訓練集
參與訓練,模型從訓練集中學習經驗,從而不斷減小訓練誤差,這個最容 易理解,一般沒什么疑惑,
2 驗證集
不參與訓練,用于在訓練程序中檢驗模型的狀態,收斂情況,驗證集通常 用于調整超引數,根據幾組模型驗證集上的表現決定哪組超引數擁有最好 的性能,
同時驗證集在訓練程序中還可以用來監控模型是否發生過擬合,一般來說 驗證集表現穩定后,若繼續訓練,訓練集表現還會繼續上升,但是驗證集 會出現不升反降的情況,這樣一般就發生了過擬合,所以驗證集也用來判 斷何時停止訓練,
3 測驗集
不參與訓練,用于在訓練結束后對模型進行測驗,評估其泛化能力,在之 前模型使用【驗證集】確定了【超引數】,使用【訓練集】調整了【可訓 練引數】,最后使用一個從沒有見過的資料集來判斷這個模型的好壞,
4 三者區別
為了方便理解,人們常常把這三種資料集類比成學生的課本、作業和期末考:
- 訓練集——課本,學生根據課本里的內容來掌握知識
- 驗證集——作業,通過作業可以知道不同學生實時的學習情況、進步的 速度快慢
- 測驗集——考試,考的題是平常都沒有見過,考察學生舉一反三的能力
傳統上,一般三者切分的比例是:6:2:2,驗證集并不是必須的
5 交叉驗證
假如我們教小朋友學加法:1個蘋果+1個蘋果=2個蘋果
當我們再測驗的時候,會問:1個香蕉+1個香蕉=幾個香蕉?
如果小朋友知道「2個香蕉」,并且換成其他東西也沒有問題,那么我們認 為小朋友學習會了「1+1=2」這個知識點,
如果小朋友只知道「1個蘋果+1個蘋果=2個蘋果」,但是換成其他東西就不 會了,那么我們就不能說小朋友學會了「1+1=2」這個知識點,
評估模型是否學會了「某項技能」時,也需要用新的資料來評估,而不是 用訓練集里的資料來評估,這種「訓練集」和「測驗集」完全不同的驗證 方法就是交叉驗證法
四.回歸模型評價指標


參考:
1.https://www.cnblogs.com/geo-will/p/10468253.html
2.https://blog.csdn.net/weixin_44613063/article/details/88659981
3.https://blog.csdn.net/HaoZiHuang/article/details/104819026
4.https://blog.csdn.net/qq_43673118/article/details/105490502
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277667.html
標籤:python