最近在學習python,然后看了我室友最近在看小說,就先看了幾篇文章,然后爬了本他正在看的小說練練手,然后就有了這篇爬取原神同人社的pljj的照片,第一次寫博客,大家多包涵包涵鴨!
1.首先匯入相關的模塊
import jsonpath
import requests
import os
import json
2.頁面分析
先打開米游社·原神
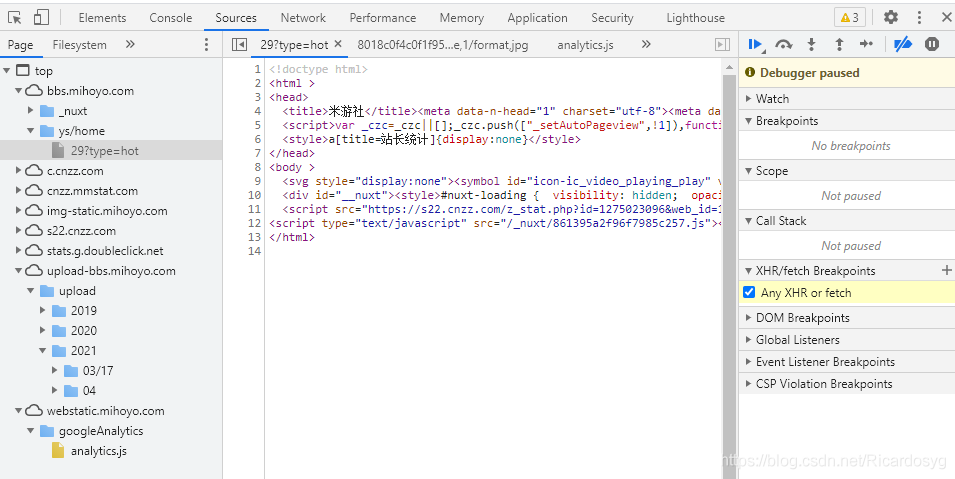
找到熱門部分,右擊檢查,network,ctrl+f8之后點擊多回藍色箭頭,找到下面介面,介面帶有getForumPostList,請求拿到資料,
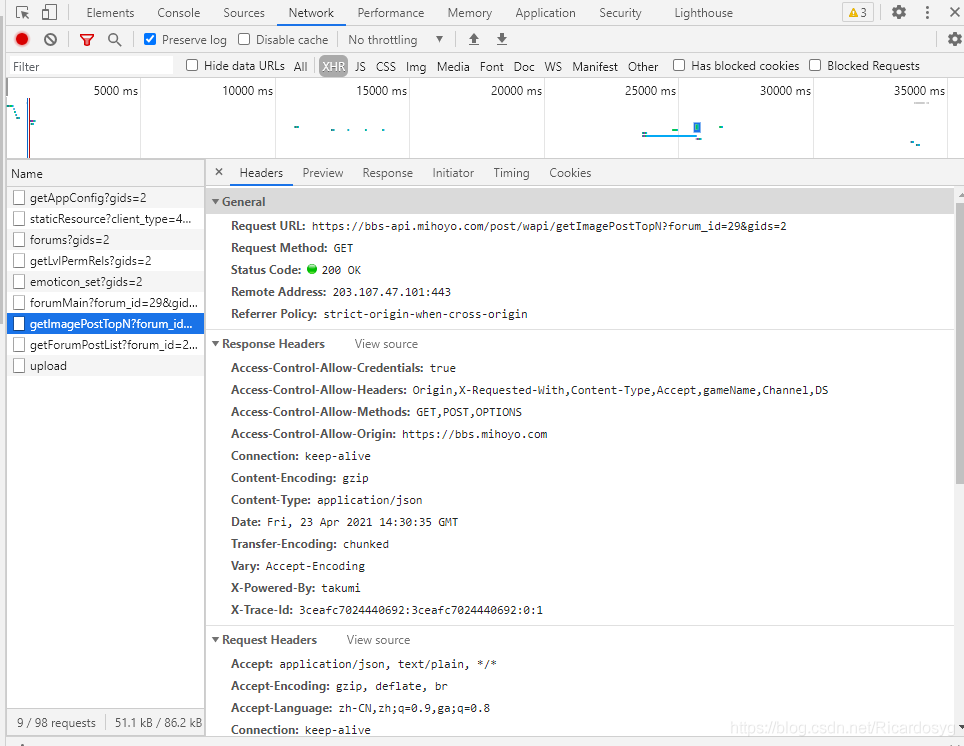
請求網站獲取資料
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
#構造請求頭,把爬蟲程式偽裝成正常的瀏覽器用戶
if not os.path.exists('./原神images'):
os.mkdir('./原神images/')
#創建保存圖片的檔案夾
url='https://bbs-api.mihoyo.com/post/wapi/getForumPostList?forum_id=29&gids=2&is_good=false&is_hot=true&page_size=20'
獲取網頁引數
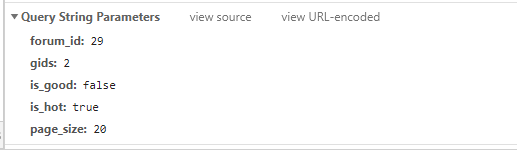
param = {
'forum_id': '29',
'gids': '2',
'last_id': image_id,
'page_size': '20'
}
last_id: 代表這個資料最后一張圖片相對于整個頁面圖片的位置編號
page_size: 代表這個資料總共有多少個圖片
3.決議資料
response = requests.get(url=url, headers=headers, params=param)
response.encoding = response.apparent_encoding
#使python編碼方式自動變化
print(response.status_code)
#輸出status_code,觀察網頁變化
response = response.text
json_data=json.loads(response, strict=False)
#把字串轉換成json資料
image_url= jsonpath.jsonpath(json_data, '$..images')
#使用jsonpath決議資料,獲取所有圖片的url,回傳的是一個串列
print(image_url)
因為requests的時候發現它是一個字典,可以使用Python中的鍵值索引方式獲取到想要的資料,但這里使用了jsonpath決議資料,能夠更快捷的獲取想要的資料
for i in image_url:
#遍歷拿到每一個URL
for img in i:
page_url=img
image_data = requests.get(page_url).content
#使用requests請求圖片URL,獲取圖片資料
使用requests請求每張圖片URL,獲取圖片資料
4.資料保存
with open(image_path, 'wb') as f:
f.write(image_data)
print(image_name, '下載完畢!!!')
5.成果展示
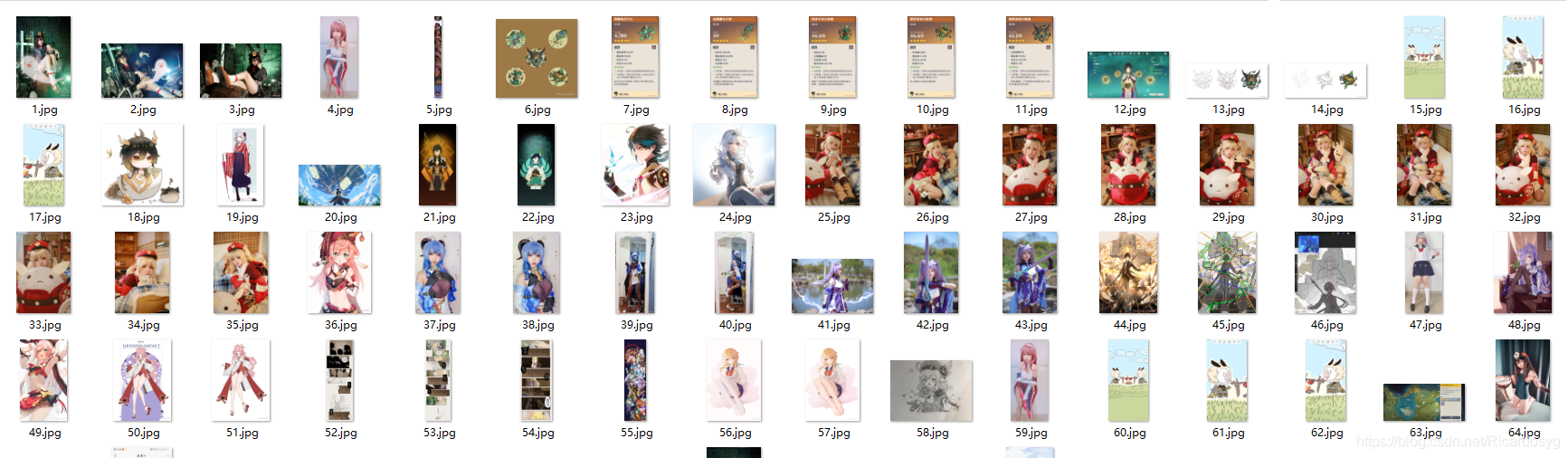
爬取成功啦!
6.完整代碼
import jsonpath
import requests
import os
import json
path='./原神images'
page = input('請輸入您想要爬取的頁數:')
page = int(page) + 1
n=0
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
#構造請求頭,把爬蟲程式偽裝成正常的瀏覽器用戶
if not os.path.exists('./原神images'):
os.mkdir('./原神images/')
#創建保存圖片的檔案夾
url='https://bbs-api.mihoyo.com/post/wapi/getForumPostList?forum_id=29&gids=2&is_good=false&is_hot=true&page_size=20'
# 資源包的url鏈接
image_id = 0
for m in range(1, page):
param = {
'forum_id': '29',
'gids': '2',
'last_id': image_id,
'page_size': '20'
}
response = requests.get(url=url, headers=headers, params=param)
response.encoding = response.apparent_encoding
#使python編碼方式自動變化
print(response.status_code)
#輸出status_code,觀察網頁變化
response = response.text
json_data=json.loads(response, strict=False)
#把字串轉換成json資料
image_url= jsonpath.jsonpath(json_data, '$..images')
#使用jsonpath決議資料,獲取所有圖片的url,回傳的是一個串列
print(image_url)
for i in image_url:
#遍歷拿到每一個URL
for img in i:
page_url=img
image_data = requests.get(page_url).content
#使用requests請求圖片URL,獲取圖片資料
image_name='{}'.format(n+1) + '.jpg'
image_path = path + '/' + image_name
with open(image_path, 'wb') as f:
f.write(image_data)
print(image_name, '下載完畢!!!')
n += 1
image_id += 20
7.經驗感想
今天是第一次寫一篇博客,之前一直聽說爬蟲一項很厲害的技術,正好這學期學了python,就想著什么時候能夠爬取一些東西,然后就去看了好幾篇大佬的博客,這些代碼有很多借鑒他們的地方,在這里想記錄一點自己再互聯網上留下的記憶,可能很多年過后,想起來自己還寫過這樣一篇博客,學習計算機我覺得真的要有很濃厚的興趣,就像現在在學Hadoop,flume,hbase,hive等等,能記錄下學習的程序,我覺得真的是一件很美好的事情,要是寫的還不錯記得點贊,關注,收藏,一鍵三連啦!阿里嘎多,米娜桑哇!
Author:RicardoZ
CSDN:https://blog.csdn.net/Ricardosyg
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/279811.html
標籤:python