目錄
- 1. 統計分析
- 2. 資料型別
- 3.圖表
- 3.1 頻數分布表
- 3.2 直方圖
- 3.3 資料的位置
- 3.3.1 樣本平均數(Sample Mean)
- 3.3.2 中位數(Median)
- 3.3.3 眾數(Mode)
- 3.3.4 百分位數(Percentile)
- 4. 資料的離散度
- 4.1極差(Range)
- 4.2平均絕對偏差(Mean Absolute Deviation)
- 4.3方差(Variance)和標準差(Standard Deviation)
1. 統計分析
統計分析(Statistical)包括描述性統計(Descriptive Statistics) 和 推斷統計(Inferential Statistics) 兩大部分,面對收集來的資料,我們首先要對資料進行整理(Organization),如排序,統計頻數,繪制頻數分布表;也可以通過計算一些指標對資料進行總結(Summarization),這些指標包括平均數,中位數等;對已知資料進行整理,歸類、簡化或繪制圖示等呈現資料特征,是描述性分析的主要內容,
2. 資料型別
可將資料分為兩類:定性資料(Qualitative Data) 和 定量資料(Quantitative Data),
- 定性資料是對事物性質進行描述的資料,通常只具有有限個取值往往用于描述類別,如股票所屬行業即為定性資料,
- 定量資料是呈現事物數量特征的資料,是由不同數字組成的,數字的取值是可以比較大小的,比如各只股票的收益資料即是定量資料,我們可以比較哪一只股票的收益率高,也可以比較一只股票何時收益較高,
3.圖表
3.1 頻數分布表
了解頻數(Frequency) , 頻率(Relative Frequency) 及頻數分布表概念即可,
3.2 直方圖
直方圖是頻數分布表的圖形運算式,繪圖方式詳情點擊鏈接
Python–Matplotlib庫與資料可視化②–常見圖形的繪制(柱狀圖,直方圖,餅圖,箱線圖)
3.3 資料的位置
獲取一組資料,如萬科A(000002.SZ)
# 匯入相關模塊
import numpy as np
import tushare as ts
import pandas as pd
token = 'Your token' # 輸入你的介面密匙,獲取方式及相關權限見Tushare官網,
pro = ts.pro_api(token)
df = pro.daily(ts_code='000002.SZ') # daily為tushare的股票日線資料介面,
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index(['trade_date'], inplace=True) # 將日期列作為行索引
df = df.sort_index()
3.3.1 樣本平均數(Sample Mean)
平均數是常用的度量資料中心位置的指標,常用的平均數有兩種計算方式,分別是算術平均法和幾何平均法,
- 算術平均數(Arithmetic Mean):
x  ̄ = x 1 + x 2 + ? + x n n \displaystyle \overline{x}=\frac{x_1+x_2+\cdots +x_n}{n} x=nx1?+x2?+?+xn?? - 幾何平均數(Geometric mean):
x  ̄ = [ ∏ j = 1 k ( s j ) ] 1 k \displaystyle \overline{x}=\left[\prod_{j=1}^k (s_j)\right]^{\frac{1}{k}} x=[j=1∏k?(sj?)]k1?
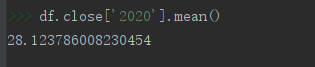
# 求2020年收盤價算術平均數
df.close['2020'].mean()
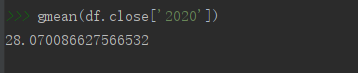
# 求幾何平均數
from scipy.stats.mstats import gmean
gmean(df.close['2020'])
算術平均數的應用范圍非常廣,幾乎是所有定量的資料都可以計算其算術平均,而幾何平均數經常用在收益率資料分析中,
3.3.2 中位數(Median)
中位數也是度量資料中心位置的指標之一,相比于平均數,中位數不易受到極端值的影響,因此當資料集中有多個極端值的時候,中位數會是一個更好的度量中心位置的方法,
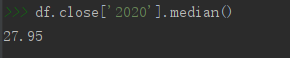
# 求2020年收盤價中位數
df.close['2020'].median()
3.3.3 眾數(Mode)
眾數是一組資料中出現次數最多的數值,也是比較常見的度量資料中心位置的指標,同中位數一樣,眾數不易受極端值影響,
# 求2020年收盤價眾數
df.close['2020'].mode()
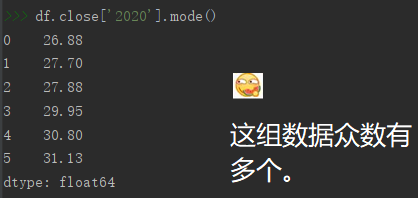
報錯啦哈哈哈,股價資料一般互不相同,很難有眾數,但是懂函式用法就行,咱也只是舉個例子,不糾結這個,繼續走起~
3.3.4 百分位數(Percentile)
第α百分位數即為使得至少(100-α)%的觀測值大于等于該數,至少α%的觀測值小于該數的一個數值,
第25百分位數,第50百分位數(即中位數),第75百分位數分別也被叫做第一四分位數(下四分位數),第二四分位數與第三四分位數(上四分位數),
在實踐中,可以使用百分位數來對業績進行排序,比如投資經理的業績經常以與同型別投資經理的業績相比所處的百分位數的形式來呈現,另外分析師也會根據某一分位數來定義一個以該分位數命名的組類,例如,在比較某股票的收益率的表現的時候,可以將收益率低于第10百分位數的股票作為收益率最低的股票,
#用quantile()函式求上下四分位數
[df.close['2020'].quantile(i) for i in [0.25, 0.75]]

4. 資料的離散度
資料位置僅僅是一個點,若要全面地反映資料分布的特征,我們還需要其他指標,資料的離散度的變異性,主要衡量樣本資料對于中心位置的偏離程度,把資料的位置通離散度結合起來,就能夠很好地刻畫資料分布的特征,常用的離散度指標如下:
4.1極差(Range)
-
極
差
=
最
大
值
?
最
小
值
\displaystyle 極差 = 最大值 - 最小值
極差=最大值?最小值
極差計算簡單,能夠快速反映資料范圍,但是極差提供的資訊量相對比比較少,難以充分反映分布的情況,
# 求極差
df.close['2020'].max() - df.close['2020'].min()

4.2平均絕對偏差(Mean Absolute Deviation)
因為所有資料與均值的產值之和為0,所以一組資料的整體離散程度無法用其來衡量,再者我們關心的是偏離的大小,不是偏離的方向,因此平均絕對偏差能夠較好地反映一組資料的離散程度
- 平均絕對偏差計算公式:
M A D = 1 n ∑ i = 1 n ∣ x i ? x  ̄ ∣ \displaystyle MAD=\frac{1}{n}\sum_{i=1}^n\left|x_i-\overline{x}\right| MAD=n1?i=1∑n?∣xi??x∣
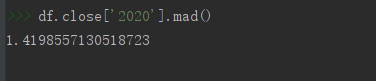
#求平均絕對偏差
df.close['2020'].mad()
4.3方差(Variance)和標準差(Standard Deviation)
除了對資料與均值的差取絕對值外,我們還可以對其進行平方運算,方差是根據資料與均值偏差平方和算出的用于衡量資料離散度的指標,計算公式如下:
σ
2
=
1
n
?
1
∑
i
=
1
n
(
x
i
?
x
 ̄
)
2
\displaystyle \sigma^2=\frac{1}{n-1}\sum_{i=1}^n(x_i-\overline{x})^2
σ2=n?11?i=1∑n?(xi??x)2
標準差是方差的平方根:
σ
=
1
n
?
1
∑
i
=
1
n
(
x
i
?
x
 ̄
)
2
\displaystyle \sigma=\sqrt{\frac{1}{n-1}\sum_{i=1}^n(x_i-\overline{x})^2}
σ=n?11?i=1∑n?(xi??x)2
?
這兩個指標是我們在實務中最常用的衡量資料離散度的指標:
# 求方差
df.close['2020'].var()

# 標準差
df.close['2020'].std()

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/279812.html
標籤:python
上一篇:爬取原神同人社的pljj照片