前篇:
傳送門
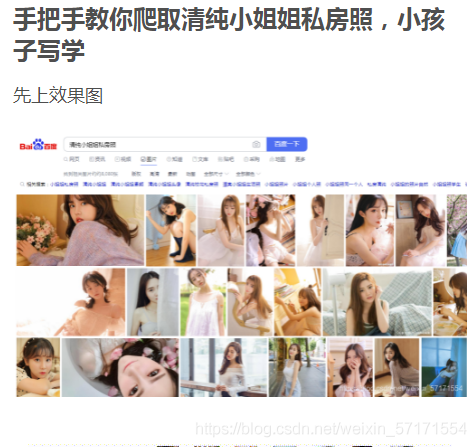
因為寫了前一篇爬蟲博客,看來挺火的,哈哈,第一篇閱讀量破萬的的博客,還是的慶幸的,
因為火熱程度比較高,直接就進入了python熱榜第一了,

來來來,這一篇除了炫耀下成績以外,還來一些干貨,
有挺多小伙伴在后臺問我,甚至加我問的問題就是:為什么我的程式報錯了?誒,奇怪的是,他們報錯都是同一個問題,


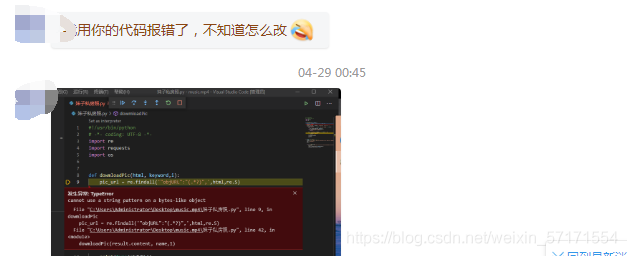
好家伙,起碼有幾十個小伙子問過這個問題,具體問題是:
TypeError: cannot use a string pattern on a bytes-like object
哎呀,這是為什么呢?是不是博主夾帶了干貨沒放出來呢?實屬冤枉 啊,大概率是我用的是py2,你用的是py3
python2和python3之間切換,難免會碰到一些問題,python3中Unicode字串是默認格式(就是str型別),ASCII編碼的字串(就是bytes型別,bytes型別是包含位元組值,其實不算是字串,python3還有bytearray位元組陣列型別)要在前面加運算子b或B;python2中則是相反的,ASCII編碼字串是默認,Unicode字串要在前面加運算子u或U
那怎么解決呢?轉換一下不就行了嗎,
import chardet #需要匯入這個模塊,檢測編碼格式
encode_type = chardet.detect(html)
html = html.decode(encode_type['encoding']) #進行相應解碼,賦給原識別符號(變數)
完整代碼如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import chardet
import re
import requests
import os
def dowmloadPic(html, keyword,i):
encode_type = chardet.detect(html)
html = html.decode(encode_type['encoding']) #進行相應解碼,賦給原識別符號(變數)
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
abc=i*60
print('找到關鍵詞:' + keyword + '的圖片,現在開始下載圖片...')
for each in pic_url:
print('正在下載第' + str(abc) + '張圖片,圖片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【錯誤】當前圖片無法下載')
continue
dir = r'D:\image\i' + keyword + '_' + str(abc) + '.jpg'
if not os.path.exists('D:\image'):
os.makedirs('D:\image')
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
abc += 1
if __name__ == '__main__':
#word = input("Input key word: ")
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'}
name = "清純妹子私房照"
num = 0
x =1
for i in range(int(x)):
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='+name+'+&pn='+str(i*30)
print(url)
result = requests.get(url,headers=headers)
dowmloadPic(result.content, name,1)
print("下載完成")
更多干貨內容,請移步到公眾號:詩一樣的代碼

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/282123.html
標籤:python