目錄:
- 1. 寫入檔案的時候要encoding一下,
- 1. re
- 1. 正則的基礎知識
- 2. python的re模塊,
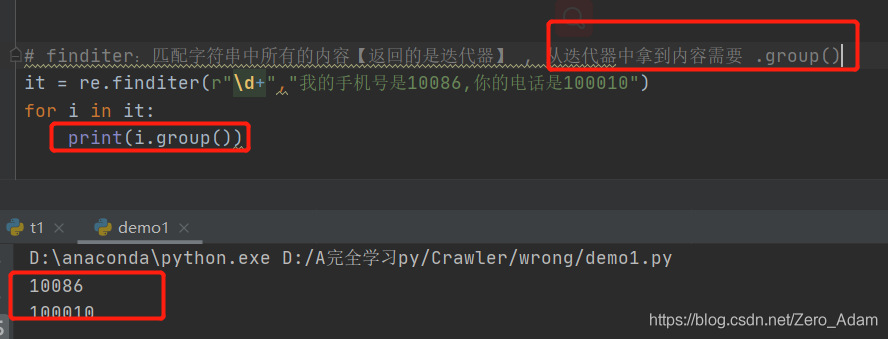
- 2. re.finditer ( r"\d+", "********") 最常用!!!!
- 3. 預加載正則運算式:
- 4. 從正則中取出資料來,
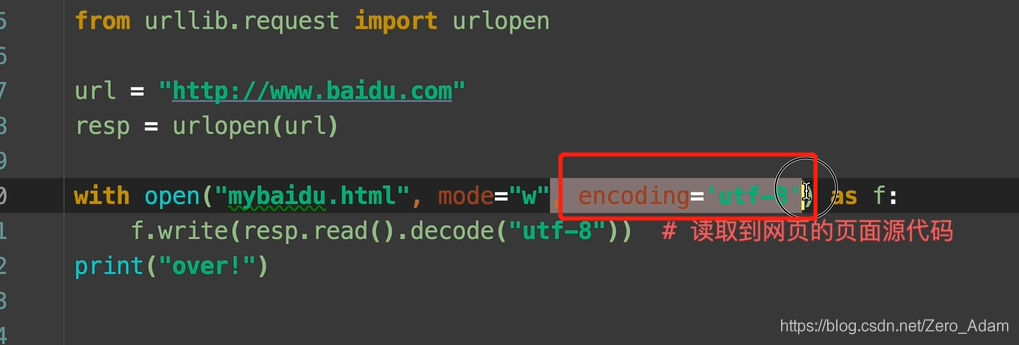
1. 寫入檔案的時候要encoding一下,
window默認的編碼是 gbk 編碼,

1. re
1. 正則的基礎知識
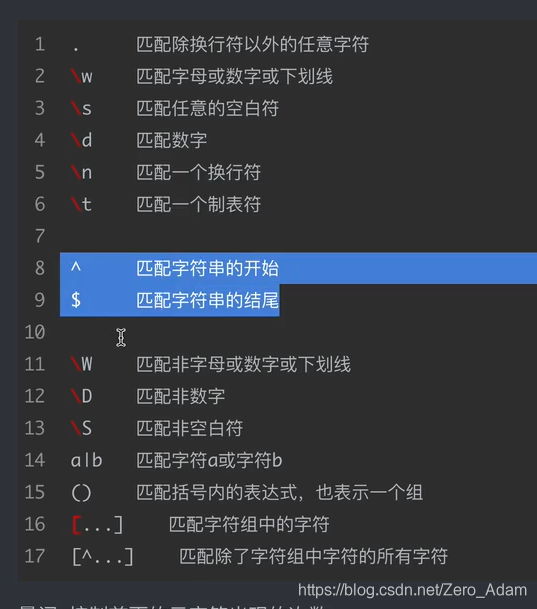
字符組,數字,字母: [a-zA-Z0-9]
[^***],除了這里面的都行,
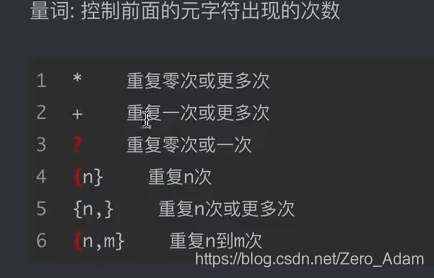
.*?非貪婪匹配
2. python的re模塊,

2. re.finditer ( r"\d+", “********”) 最常用!!!!
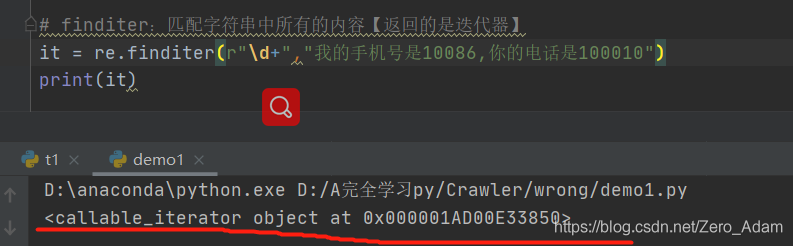
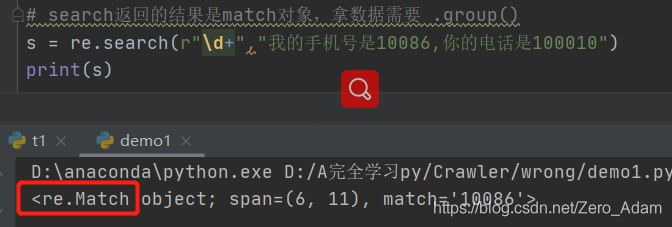
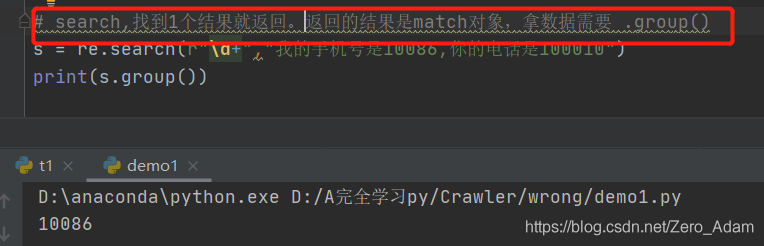
取東西:

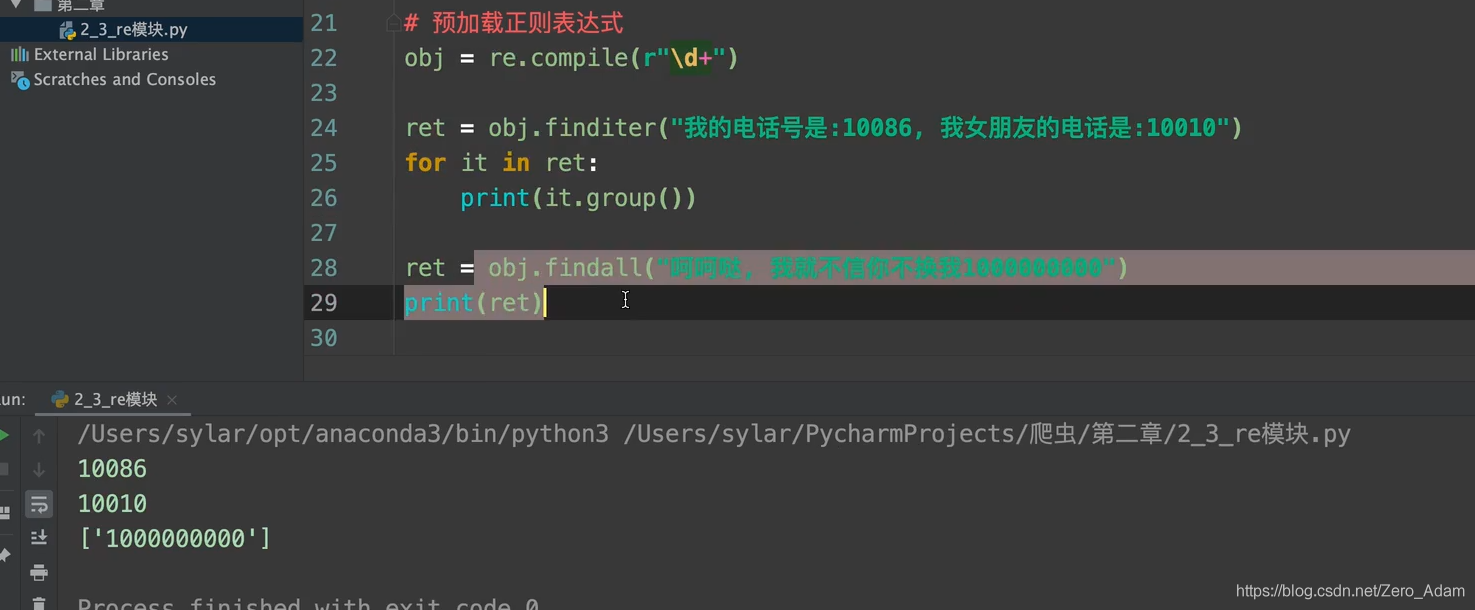
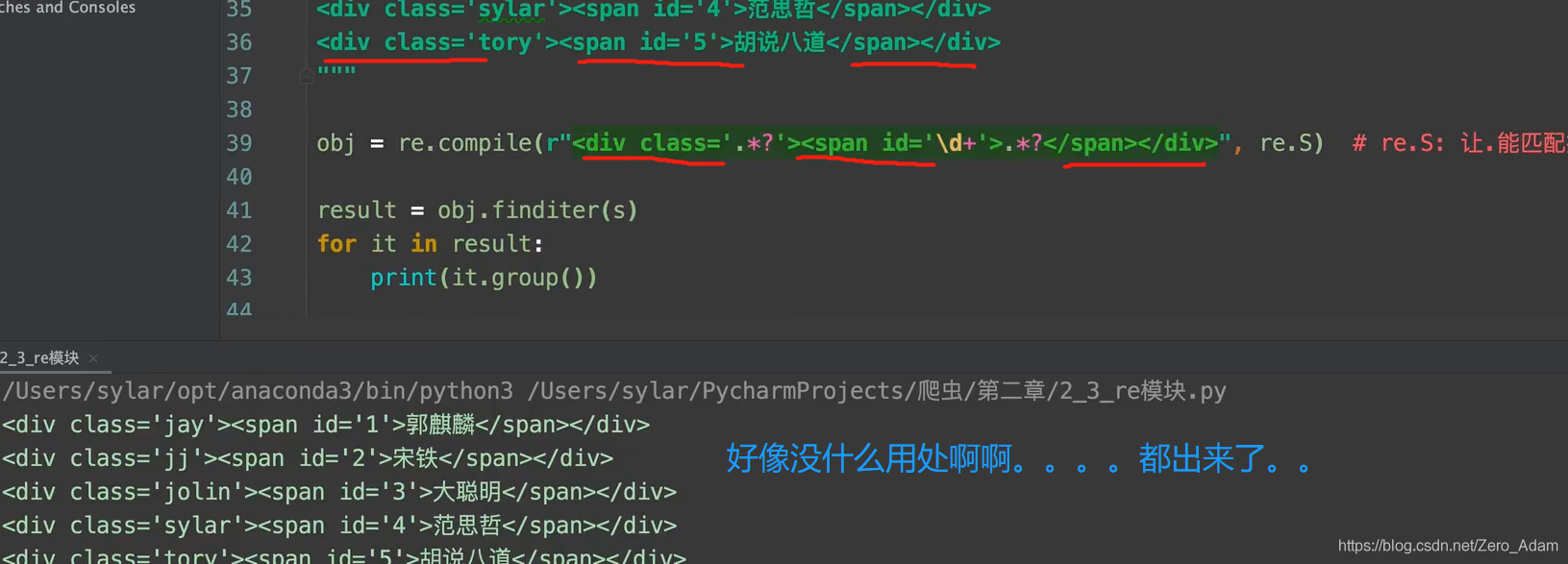
3. 預加載正則運算式:
正則很長的化,就很方便,,
4. 從正則中取出資料來,
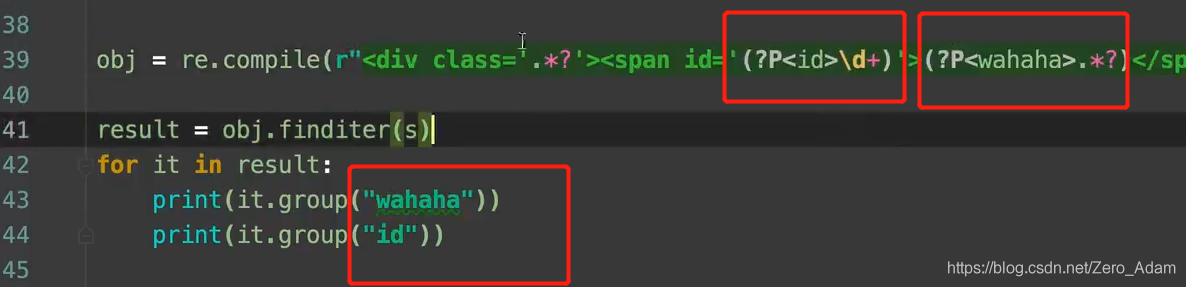
- 我想把里面的名字什么的拿出來,
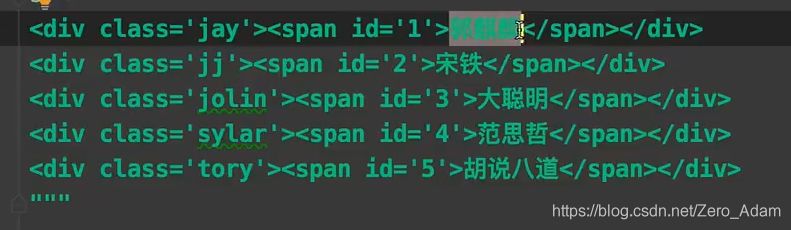
(?P<name>正則 ) 可以單獨從正則匹配的內容中進一步提取內容
(?P<name>.*?),然后那的時候,it.group('name'),就拿到了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286311.html
標籤:python