
一、前言

在葉庭云混跡的一個學習氣氛挺好的交流群里,某一天一位鐵子求教一道題,引發了群友們的熱烈討論,一起來看看吧!
手機截圖下來圖片有點兒大~~,用 opencv resize 處理一下,然后用電腦 QQ 截圖,還有用馬賽克保護群友頭像隱私,
img1 = cv.imread(r"D:\test\pic\jietu_01.jpg")
img1 = cv.resize(img1, dsize=None, fx=0.5, fy=0.5)
img2 = cv.imread(r"D:\test\pic\jietu_02.jpg")
img2 = cv.resize(img2, dsize=None, fx=0.5, fy=0.5)
cv.imshow("img1", img1)
cv.imshow("img2", img2)
cv.waitKey(0)
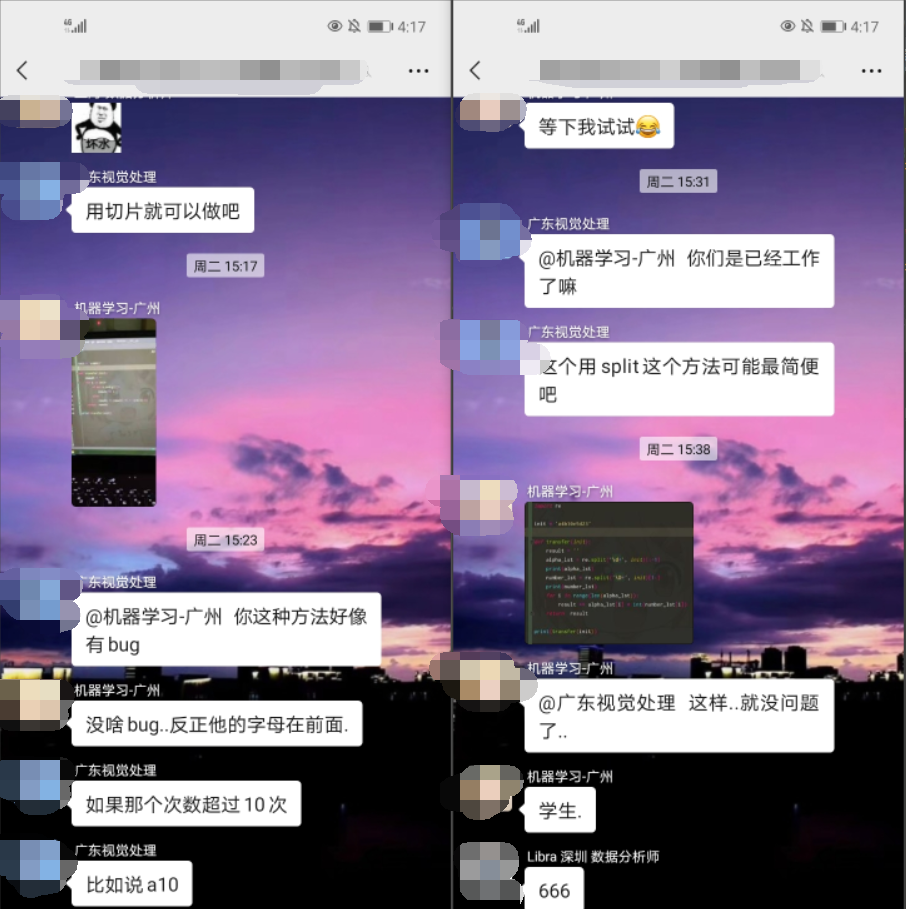
題目如下:
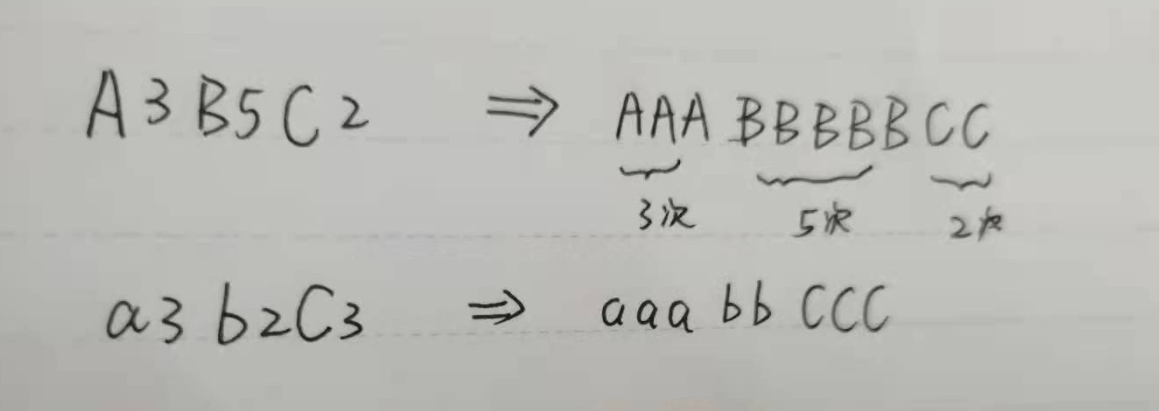
看起來還挺容易的,字母–后面跟數字的話這個字母就 num 個,沒有跟數字就一個,但實踐出真知嘛,寫代碼測驗才知道,
二、動手寫代碼
Python代碼三行搞定?
str1 = "A3B5C8"
ls1 = [i if i.isalpha() else str1[index_ - 1] * (int(i) - 1) for index_, i in enumerate(str1)]
print("".join(ls1))
結果如下:
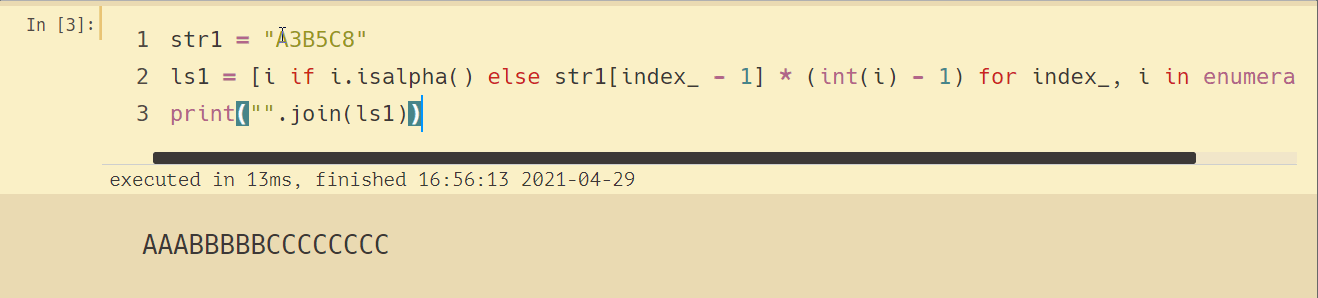
可事情好像沒有那么簡單,當后面跟的數字大于 10 的話,輸出結果就不對了,如下所示:
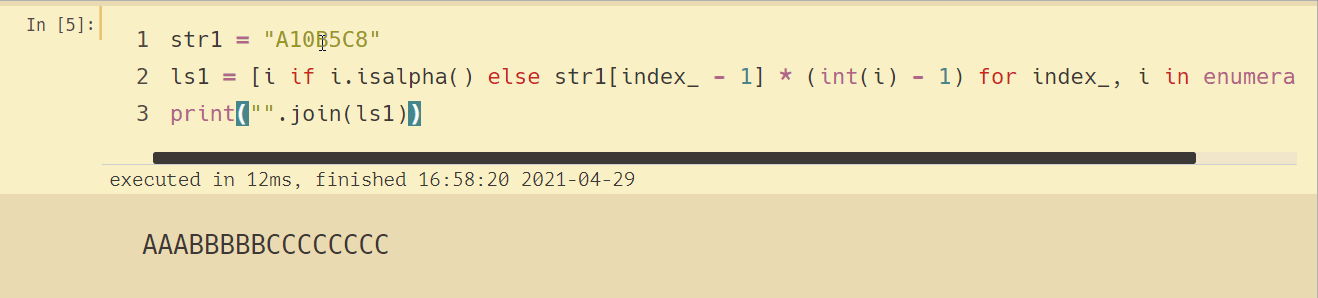
那這樣呢?
import re
def func(s):
return "".join([c * int(count) for c, count in re.findall("(\D+)(\d+)", s)])
func("a10b3c10")
結果如下:
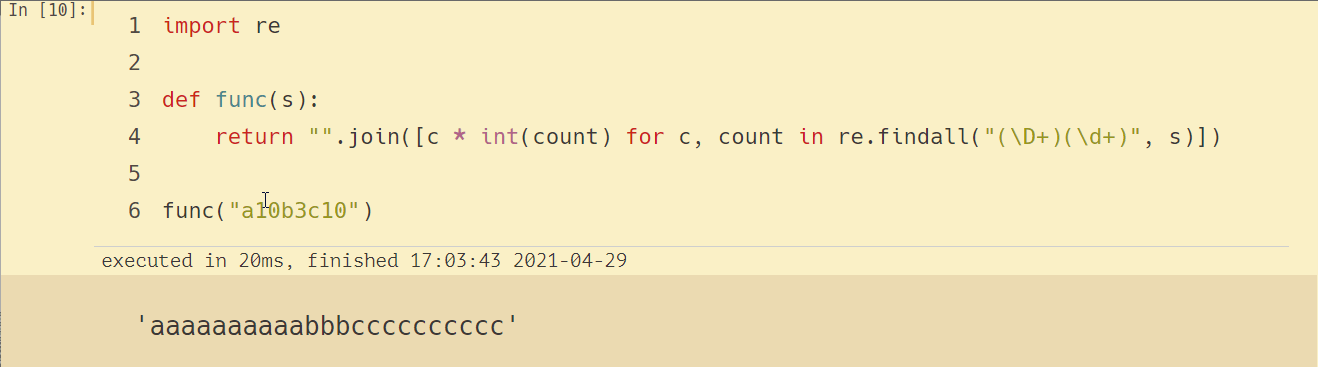
這下對了吧,后面跟的數字大于 10 的話,輸出結果也對了,可細心的群友又發現了問題,像 abc10 這樣輸出結果不對誒!如下所示:
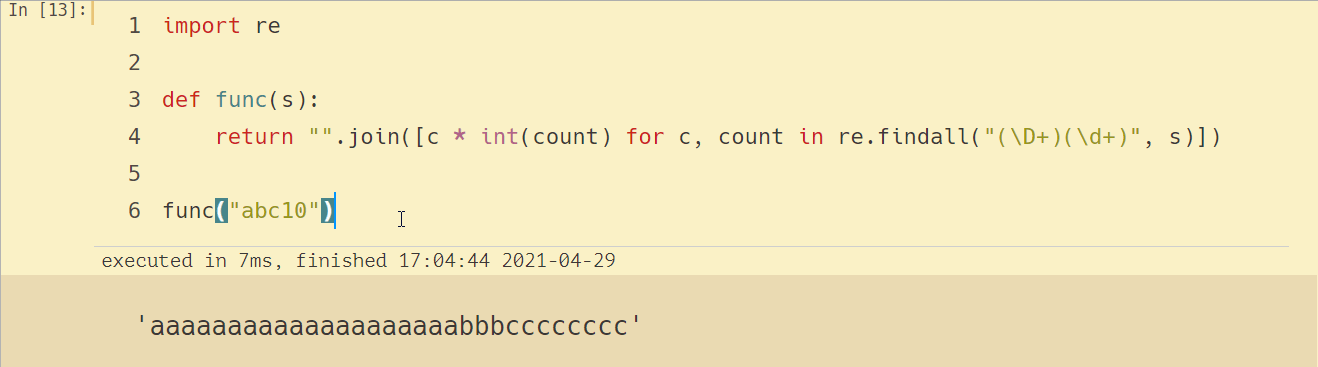
數字插入的位置有無,是否大于 10 都需要考慮到,不然輸出會有問題,可能不能寫得那么簡潔優雅了,簡單粗暴干掉它!
str2 = "a10b10c"
ls = []
for i in range(len(str2)):
num = ""
if str2[i].isalpha(): # 是字母
# 查找后面跟的數字 拼出來
for j in range(i + 1, len(str2)):
if str2[j].isdigit():
num += str2[j]
# print(num)
# 開始又是字母了 break
else:
break
# 字母重復 然后添加進串列 沒有重復 直接添加
if num:
ls.append(str2[i] * int(num))
else:
ls.append(str2[i])
# 輸出
print("".join(ls))
結果如下:
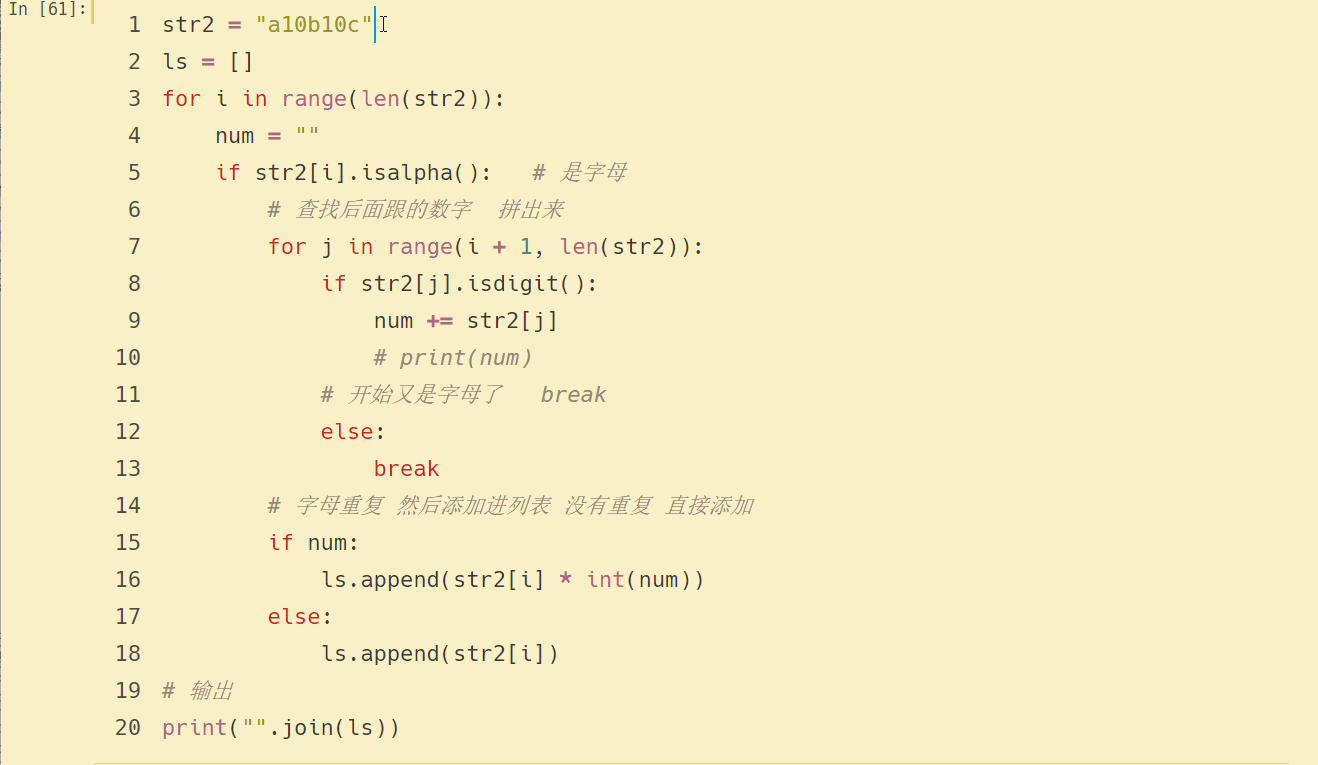
終于搞定啦~~
代碼如下:
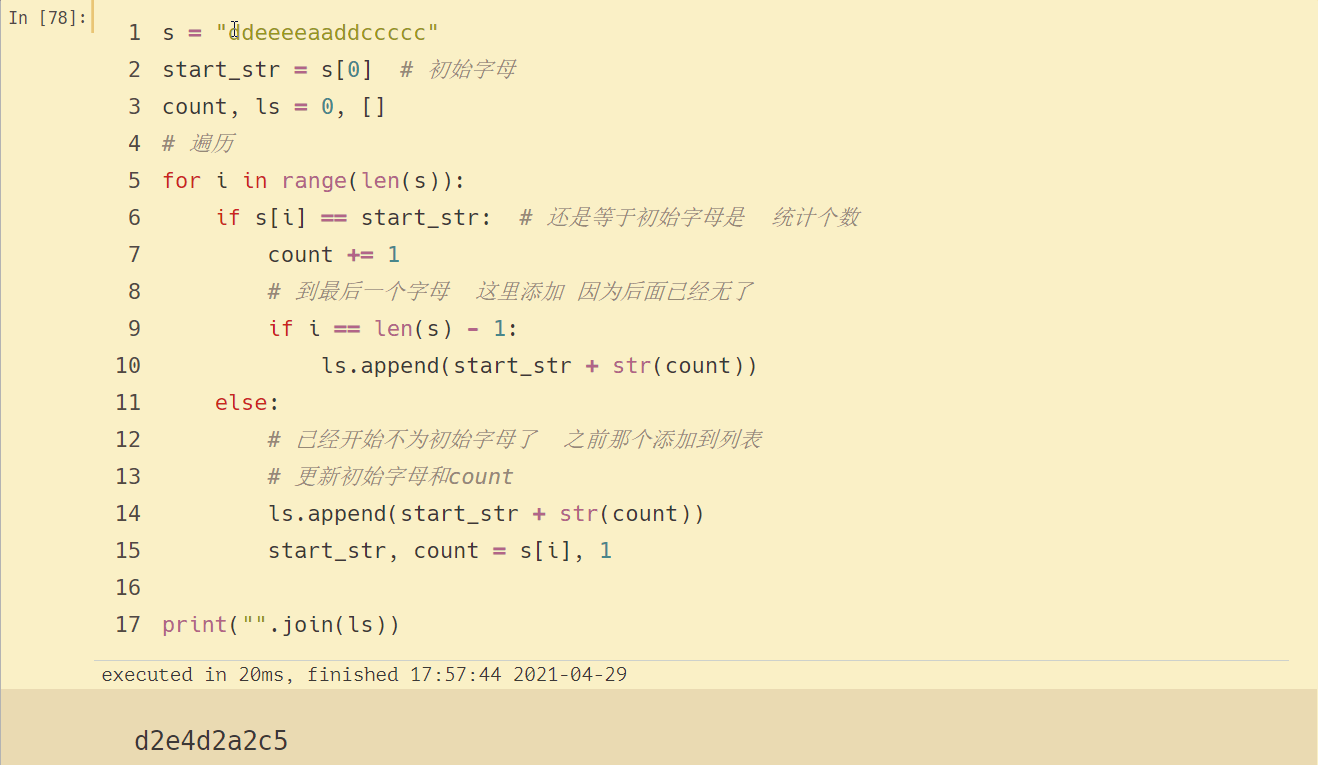
s = "ddeeeeaaddccccc" # 2 4 2 2 5
start_str = s[0] # 初始字母
count, ls = 0, []
# 遍歷
for i in range(len(s)):
if s[i] == start_str: # 還是等于初始字母是 統計個數
count += 1
# 到最后一個字母 這里添加 因為后面已經無了
if i == len(s) - 1:
ls.append(start_str + str(count))
else:
# 已經開始不為初始字母了 之前那個添加到串列
# 更新初始字母和count
ls.append(start_str + str(count))
start_str, count = s[i], 1
print("".join(ls))
結果如下:
總結:學編程,很多題目可能并不像看起來那樣簡單,實踐出真知,動手才能發現問題,多思考才能解決問題,切忌眼高手低!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286319.html
標籤:python