Python 爬蟲 120 例,已完成文章清單
- 10 行代碼集 2000 張美女圖,Python 爬蟲 120 例,再上征途
- 通過 Python 爬蟲,發現 60%女裝大佬游走在 cosplay 領域
本篇博客目標
爬取目標
- 貓咪圖片,http://p.ik123.com/zt/maomi/68_1.html
使用框架
- requests 庫 + re 模塊
重點學習內容
- requests 庫使用;
- re 模塊與正則運算式;
- 動態獲取頁碼,
頁面變化
- 隨機點擊頁碼,得到如下所示頁碼規律,
http://p.ik123.com/zt/maomi/68_1.html
http://p.ik123.com/zt/maomi/68_2.html
http://p.ik123.com/zt/maomi/68_3.html
http://p.ik123.com/zt/maomi/68_{頁碼}.html
詳情頁所在原始碼位置
通過開發者工具,可以便捷得到詳情頁地址所在 HTML 標簽,每頁合計 12 條資料,關鍵標簽分別如下圖所示,
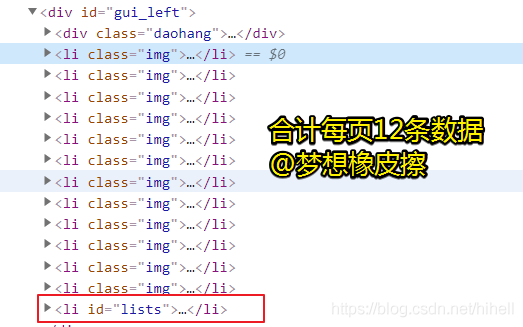
li class = "img"詳情頁所在標簽;li class = "lists"分頁所在標簽,
詳情頁圖片
點擊任意貓咪圖片,進入詳情頁,查看原始碼,很容易找到圖片標簽,
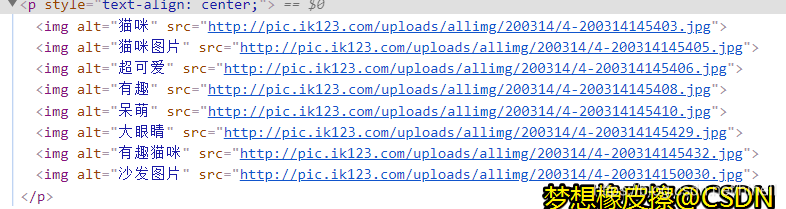
簡單分析已經完成,接下來對分析程序進行一下基本梳理,
整理需求如下
- 訪問串列起始頁,得到總頁數;
- 基于總頁數,生成待爬取串列;
- 依次爬取串列頁資料,獲取所有詳情頁資料;
- 爬取詳情頁中貓咪圖片;
- 保存圖片,
代碼實作時間
使用任意頁,換取總頁碼
該步驟只需要通過requests 抓取網頁原始碼,然后通過正則運算式匹配分頁部分標簽即可,
import requests
import re
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 獲取分頁
def get_pagesize(html):
# 撰寫簡單的正則運算式 <a href='68_(\d+).html'>末頁</a>
pagesize = re.search("<a href='68_(\d+).html'>末頁</a>", html)
if pagesize is not None:
return pagesize.group(1)
else:
return 0
# 獲取待抓取串列
def get_wait_list(url):
wait_urls = []
try:
res = requests.get(url=url, headers=HEADERS, timeout=5)
res.encoding = "gb2312"
html_text = res.text
pagesize = int(get_pagesize(html_text))
if pagesize > 0:
print(f"獲取到{pagesize}頁資料")
# 生成待抓取串列
for i in range(1, pagesize + 1):
wait_urls.append(f"http://p.ik123.com/zt/maomi/68_{i}.html")
return wait_urls
except Exception as e:
print("例外", e)
if __name__ == '__main__':
start_url = "http://p.ik123.com/zt/maomi/68_1.html"
wait_urls = get_wait_list(url=start_url)
print(wait_urls)
獲取所有詳情頁地址
本步驟只需要回圈上述代碼中 wait_urls 即可,
# 正則匹配詳情頁鏈接
def format_detail(html):
# 多次模擬得到正則運算式 <a class=preview href="(.*?)"
# 注意單引號與雙引號嵌套
detail_urls = re.findall('<a class=preview href="(.*?)"', html)
return detail_urls
# 獲取所有詳情頁鏈接資料
def get_detail_list(url):
try:
res = requests.get(url=url, headers=HEADERS, timeout=5)
res.encoding = "gb2312"
html_text = res.text
return format_detail(html_text)
except Exception as e:
print("獲取詳情頁例外", e)
if __name__ == '__main__':
start_url = "http://p.ik123.com/zt/maomi/68_1.html"
wait_urls = get_wait_list(url=start_url)
detail_list = []
for url in wait_urls:
print(f"正在抓取{url}")
detail_list.extend(get_detail_list(url))
print(f"獲取到{len(detail_list)}條詳情頁")
等待 20 秒所有,即可得到下述內容,
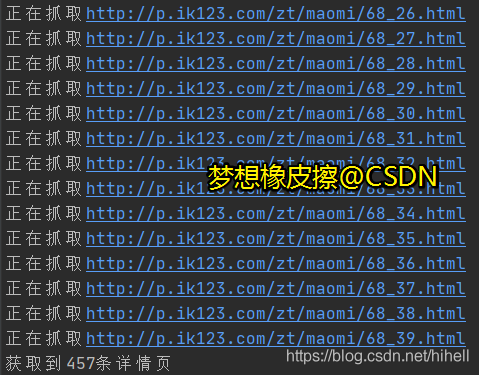
爬取內頁貓咪資料
下面就是本爬蟲的最后一步了,進入詳情頁獲取內頁圖片,
本步驟也可以拆分成兩步,先獲取貓咪的圖片地址,最后在進行消耗資源的圖片抓取,
本案例只展示到抓取到的貓咪圖地址,最后爬取圖片交給你來完成啦,
最終的完整代碼如下,關鍵代碼,已經備注注釋,
import requests
import re
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 獲取分頁
def get_pagesize(html):
# 撰寫簡單的正則運算式 <a href='68_(\d+).html'>末頁</a>
pagesize = re.search("<a href='68_(\d+).html'>末頁</a>", html)
if pagesize is not None:
return pagesize.group(1)
else:
return 0
# 獲取待抓取串列
def get_wait_list(url):
wait_urls = []
try:
res = requests.get(url=url, headers=HEADERS, timeout=5)
res.encoding = "gb2312"
html_text = res.text
pagesize = int(get_pagesize(html_text))
if pagesize > 0:
print(f"獲取到{pagesize}頁資料")
# 生成待抓取串列
for i in range(1, pagesize + 1):
wait_urls.append(f"http://p.ik123.com/zt/maomi/68_{i}.html")
return wait_urls
except Exception as e:
print("獲取分頁例外", e)
# 正則匹配詳情頁鏈接
def format_detail(html):
# 多次模擬得到正則運算式 <a class=preview href="(.*?)"
# 注意單引號與雙引號嵌套
detail_urls = re.findall('<a class=preview href="(.*?)"', html)
return detail_urls
# 獲取所有詳情頁鏈接資料
def get_detail_list(url):
try:
res = requests.get(url=url, headers=HEADERS, timeout=5)
res.encoding = "gb2312"
html_text = res.text
return format_detail(html_text)
except Exception as e:
print("獲取詳情頁例外", e)
def format_mao_img(html):
# 匹配貓咪圖正則運算式 <img alt=".*?" src=".*?" />
mao_img_urls = re.findall('<img alt=".*?" src="(.*?)" />', html)
return mao_img_urls
# 獲取貓咪圖片地址
def get_mao_img(detail_url):
try:
res = requests.get(url=detail_url, headers=HEADERS, timeout=5)
res.encoding = "gb2312"
html_text = res.text
return format_mao_img(html_text)
except Exception as e:
print("獲取貓咪圖片例外", e)
if __name__ == '__main__':
start_url = "http://p.ik123.com/zt/maomi/68_1.html"
wait_urls = get_wait_list(url=start_url)
detail_list = []
for url in wait_urls:
print(f"正在抓取{url}")
detail_list.extend(get_detail_list(url))
print(f"獲取到{len(detail_list)}條詳情頁")
mao_imgs = []
for index, mao_detail in enumerate(detail_list):
if len(mao_detail) > 0:
print(f"正抓取第{index}頁資料")
mao_imgs.extend(get_mao_img(mao_detail))
# 以下代碼測驗用
if len(mao_imgs) > 100:
break
print(f"獲取到{len(mao_imgs)}條貓咪圖")
print(mao_imgs[:5])
完整代碼下載地址:https://codechina.csdn.net/hihell/python120
抽獎時間(目前累計送出 4 份)
上一篇博客中獎者 mimigege2 抓緊聯系擦姐吧,

只要評論數過 50
隨機抽取一名幸運讀者
獎勵 39.9 元爬蟲 100 例專欄 1 折購買券一份,只需 3.99 元
今天是持續寫作的第 162 / 200 天,可以點贊、評論、收藏啦,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286320.html
標籤:python