前言:
作者:神的孩子在歌唱
這是我聽老師講課做的筆記
大家好,我叫陳運智,大家可以叫我智
正則運算式
- 一. python正則運算式介紹
- 二. re模塊
- 2.1 match方法
- 2.2 匹配規則
- 2.2.1 匹配字符
- 2.2.2 分組匹配
- 2.2.3 限定匹配字符規則
- 2.2.4 轉義字符
- 三. re中的編譯函式
- 3.1 compile方法
- 3.2 search方法
- 3.3 finall方法
- 3.4 sub方法
- 3.5 split方法
- 四. 貪婪模式與非貪婪模式
一. python正則運算式介紹
-
正則運算式是一個特殊的字符序列,它能幫助你方便的檢查一個字串是否與某種模式匹配,
-
Python 自1.5版本起增加了re 模塊,它提供 Perl 風格的正則運算式模式,
-
re 模塊使 Python 語言擁有全部的正則運算式功能,
-
compile 函式根據一個模式字串和可選的標志引數生成一個正則運算式物件,該物件擁有一系列方法用于正則運算式匹配和替換,
-
re 模塊也提供了與這些方法功能完全一致的函式,這些函式使用一個模式字串做為它們的第一個引數,
二. re模塊
2.1 match方法
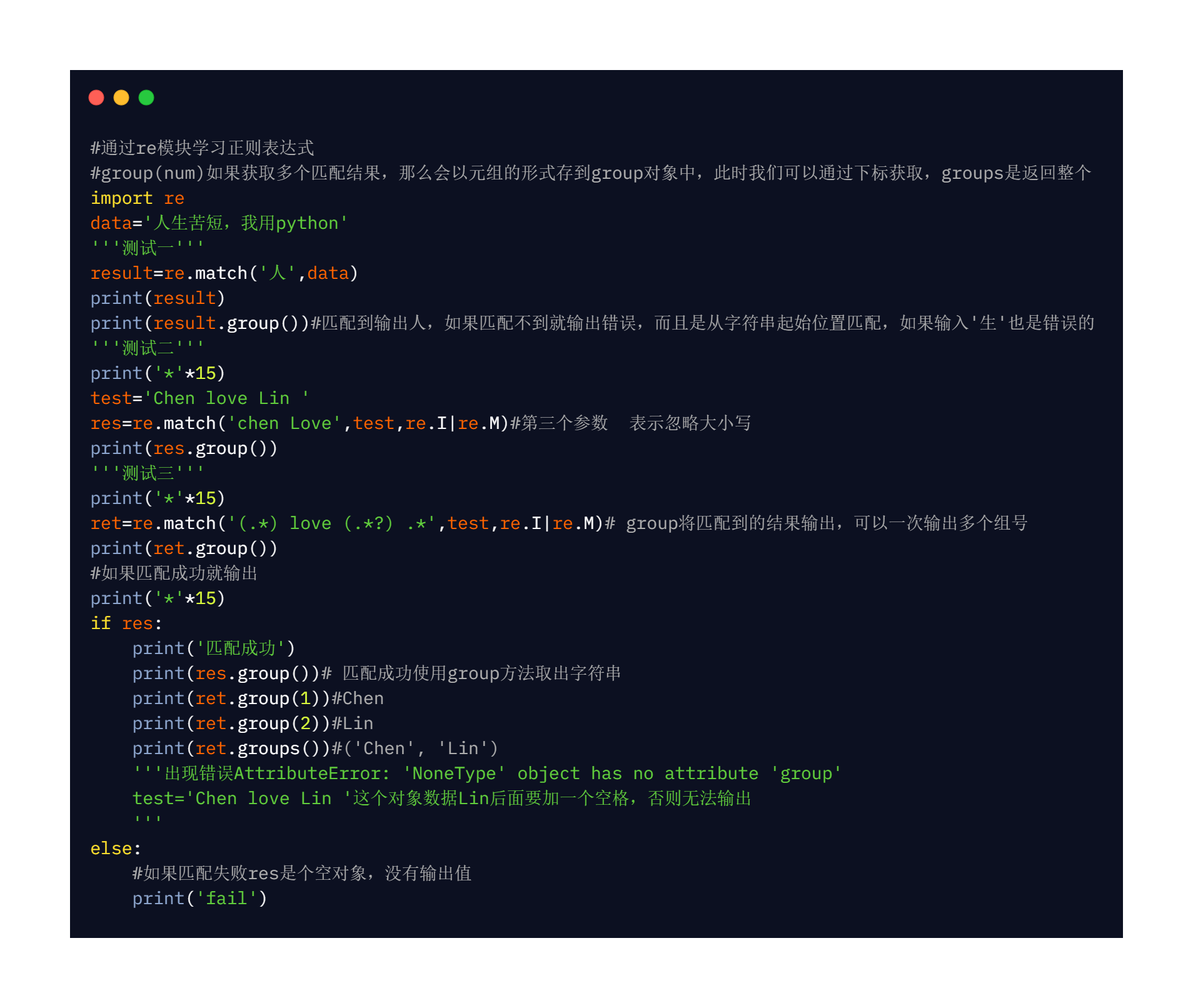
re.match 嘗試從字串的起始位置匹配一個規則,匹配成功就回傳match物件,否則回傳
None,可以使用group()獲取匹配成功的字串,
- 語法:
re.match(pattern, string, flags=0) - 引數說明:
| pattern | 匹配的正則運算式 |
|---|---|
| string | 要匹配的字串, |
| flags | 標志位,用于控制正則運算式的匹配方式,如:是否區分大小寫,多行匹配等等, |
- 我們可以使用
group(num)或groups()匹配物件函式來獲取匹配運算式,
| group(num=0) | 匹配的整個運算式的字串,group() 可以一次輸入多個組號,在這種情況下它將回傳一個包含那些組所對應值的元組, |
|---|---|
| groups() | 回傳一個包含所有小組字串的元組,從 1 到 所含的小組號, |
- 代碼演示
'''
修飾符 描述
re.I 使匹配對大小寫不敏感
re.L 做本地化識別(locale-aware)匹配
re.M 多行匹配,影響 ^ 和 $
re.S 使 . 匹配包括換行在內的所有字符
re.U 根據Unicode字符集決議字符,這個標志影響 \w, \W, \b, \B.
re.X 該標志通過給予你更靈活的格式以便你將正則運算式寫得更易于理解,
'''
輸出:
2.2 匹配規則
2.2.1 匹配字符
| 符號 | 匹配規則 |
|---|---|
| .(點) | 匹配任意1個字符除了換行符\n |
| [abc ] | 匹配abc中的任意一個字符 |
| \d | 匹配一個數字,即0-9 |
| \D | 匹配非數字,即不是數字 |
| \s | 匹配空白,即空格,tab鍵 |
| \S | 匹配非空白,除空格,tab鍵之類的 |
| \w | 匹配單詞字符,即a-z、A-Z、0-9、_ |
| \W | 匹配非單詞字符 |
.點的使用,匹配除了換行符之外的任意一個字符字符,還可以.*輸出后面的字串
import re
data='python'
parrtern='..'#匹配規則,這里匹配兩個字符
res=re.match(parrtern,data)
print(res.group())#輸出:py
'''測驗二'''
names='運智在學習python','運氣','換人'
pattern='運.'#匹配規則:會匹配運開頭的
for item in names:
chen=re.match(pattern,item)
if chen:
print(chen.group())#輸出運智,運氣
輸出:

2. [] 中括號:匹配中括號中的任意一個字符,
str1='hello'
res=re.match('[he]',str1)
print(res.group())#輸出:h
2.2.2 分組匹配
| 符號 | 匹配規則 |
|---|---|
| | | 匹配左右任意一個運算式 |
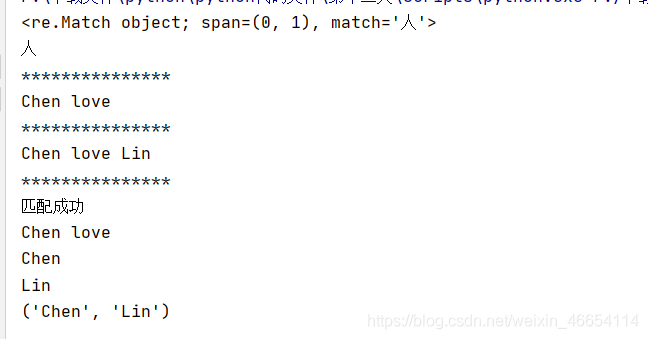
| (ab) | 將括號中字符作為一個分組 |
| \num | 參考分組num匹配到的字串 |
| (?P) | 分組起別名 |
| (?P=name) | 參考別名為name分組匹配到的字串 |
代碼按例:
2.2.3 限定匹配字符規則
原理:就是匹配數量
| 符號 | 匹配規則 |
|---|---|
| * | 匹配前一個字符出現0次或者無限次,即可有可無 |
| + | 匹配前一個字符出現1次或者無限次,即至少有1次 |
| ? | 匹配前一個字符出現1次或者0次,即要么有1次,要么沒有 |
| {m} | 匹配前一個字符出現m次 |
| {m,} | 匹配前一個字符至少出現m次 |
| {n,m} | 匹配前一個字符出現從n到m次 |
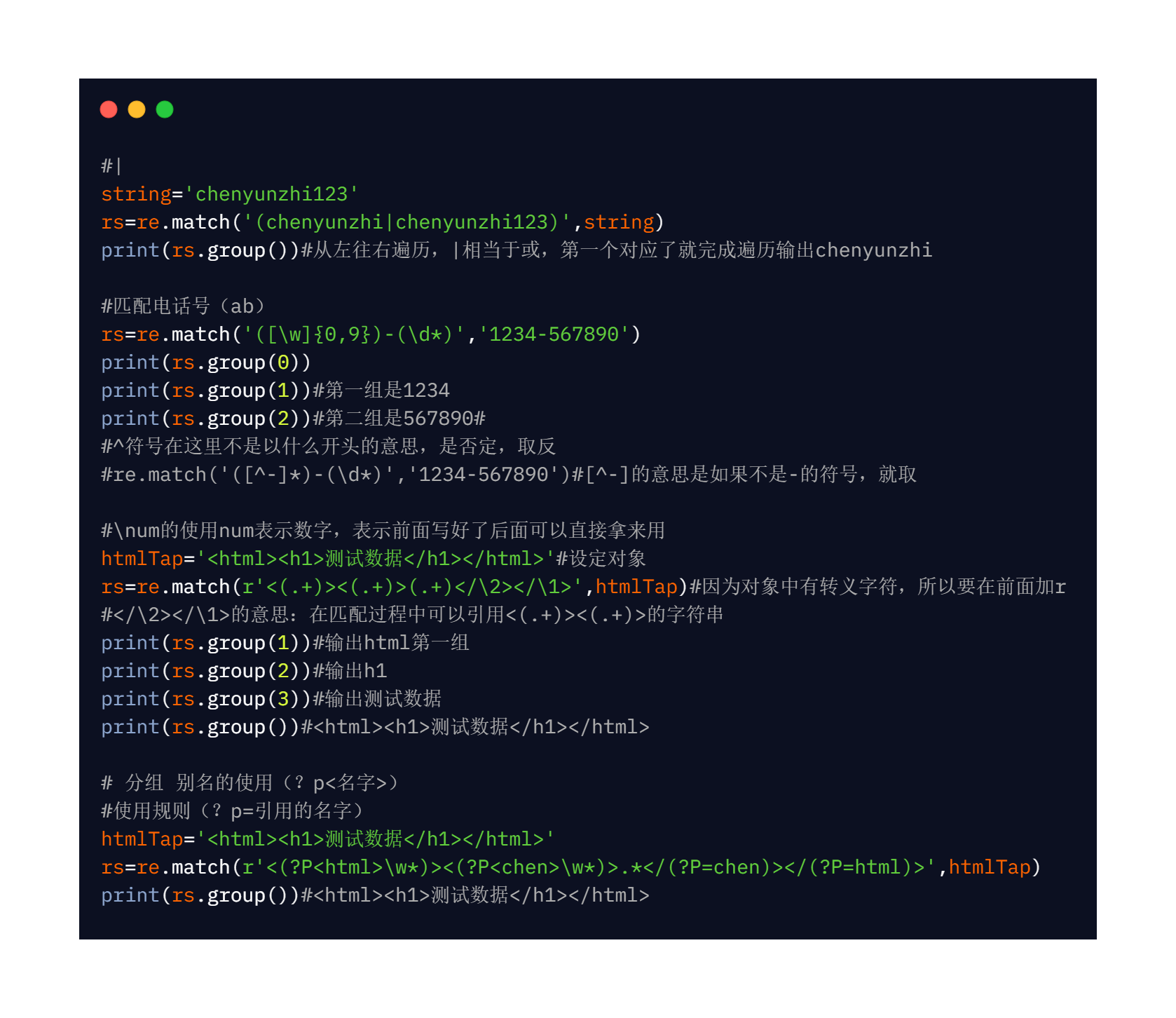
*匹配前一個字符出現0次或者無限次,即可有可無
代碼:
res=re.match('[A-Z]*','Cy')#匹配0次
print(res.group())#C
res=re.match('[A-Z][a-z]*','Che')#也可以寫成" [A-Za-z]* "
print(res.group())
# re.match('[a-zA-Z]+[\w]*','na99m_e')
#re.match('\d{4}','1234')#精確匹配
輸出:
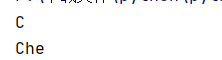
2. 代碼按例匹配郵箱
regexMail=re.match('[a-zA-Z0-9]{6,11}@qq.com','chenyunzhi@qq.com')
if regexMail:
print('匹配成功{}'.format(regexMail.group()))
pass
輸出:
2.2.4 轉義字符
| 符號 | 匹配規則 |
|---|---|
| ^ | 匹配字串開頭 |
| $ | 匹配字串結尾 |
import re
# 在正則前加r,表示原生字串,python字串不轉義 或者直接\\\\a,
print(re.match(r'c:\\a.txt','c:\\a.txt').group())#c:\a.txt
dt='python is chen'
result=re.match('^p.*',dt)#開頭是對的就輸出
chen=re.match('^p\w{5}',dt)
End=re.match('\w{5,12}@[\w]{1,9}.\w{3}$','chenyunzhi@qq.com')
if result:
print(result.group())#python is chen
print(chen.group())#python
print(End.group())#chenyunzhi@qq.com
輸出:
三. re中的編譯函式
3.1 compile方法
compile可以把一個字串編譯成位元組碼- 優點:在使用正則運算式進行match的操作時,python會將字串轉為正則運算式物件,
- 而如果使用
compile只需要一次轉換,以后再使用模式物件的話 無需轉換
import re
rs=re.compile('\w.*')
res=rs.match('chenyunzhi')
print(res.group())#輸出:chenyunzhi
3.2 search方法
search:在全文中匹配一次,匹配到就回傳- 語法:
re.search(pattern, string, flags=0)
| 引數 | 描述 |
|---|---|
| pattern | 匹配的正則運算式 |
| string | 要匹配的字串, |
| flags | 標志位,用于控制正則運算式的匹配方式,如:是否區分大小寫,多行匹配等等, |
- 代碼
'''
print(re.search('python','人生苦短,我用python').group())
#輸出:python
3.3 finall方法
finall():查詢字串中某個正則運算式全部的非重復出現的情況 回傳是一個符合正則運算式的結果串列- 語法:
findall(string[, pos[, endpos]])
| 引數 | 描述 |
|---|---|
| string | 待匹配的字串, |
| pos | 可選引數,指定字串的起始位置,默認為 0, |
| endpos | 可選引數,指定字串的結束位置,默認為字串的長度, |
3.代碼
print(re.findall('p','python的開頭是p'))#輸出:['p', 'p']
小結:search找到就回傳,finall全部找到才回傳
3.4 sub方法
sub:將匹配到的資料進行替換,實作目標的搜索和查找- 語法:
sub(pattern, repl, string, count=0, flags=0)
| 引數 | 描述 |
|---|---|
| pattern | 正則中的模式字串, |
| repl | 替換的字串,也可為一個函式, |
| string | 要被查找替換的原始字串, |
| count | 模式匹配后替換的最大次數,默認 0 表示替換所有的匹配, |
| flags | 標志位,用于控制正則運算式的匹配方式 |
- 代碼

輸出:

3.5 split方法
- split:實作分割字串,以串列形式回傳
- 語法:
split(pattern, string, maxsplit=0, flags=0)
| 引數 | 描述 |
|---|---|
| pattern | 匹配的正則運算式 |
| string | 要匹配的字串, |
| maxsplit | 分隔次數,maxsplit=1 分隔一次,默認為 0,不限制次數, |
| flags | 標志位,用于控制正則運算式的匹配方式 |
print(re.split(',','chen,yun,zhi'))#輸出:['chen', 'yun', 'zhi']
四. 貪婪模式與非貪婪模式
默認條件下為貪婪模式
- 貪婪:在滿足條件情況下盡可能匹配到資料
- 非貪婪:滿足條件就可以,在
"*","?","+","{m,n}"后面加上?,就能將貪婪變成非貪婪.
代碼
#貪婪模式
pattern=re.compile('a.*b')
result=pattern.search('abcabcd')
print(result.group())#abcab
#非貪婪
pattern=re.compile('a.*?b')
result=pattern.search('abcabcd')
print(result.group())#ab
輸出:
abcab
ab
上面可以看出,貪婪模式要匹配到最后一個b才停止,然而非貪婪模式匹配到第一個b就停止了
本人博客:https://blog.csdn.net/weixin_46654114
轉載說明:跟我說明,務必注明來源,附帶本人博客連接,
請給我點個贊鼓勵我吧

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286324.html
標籤:python