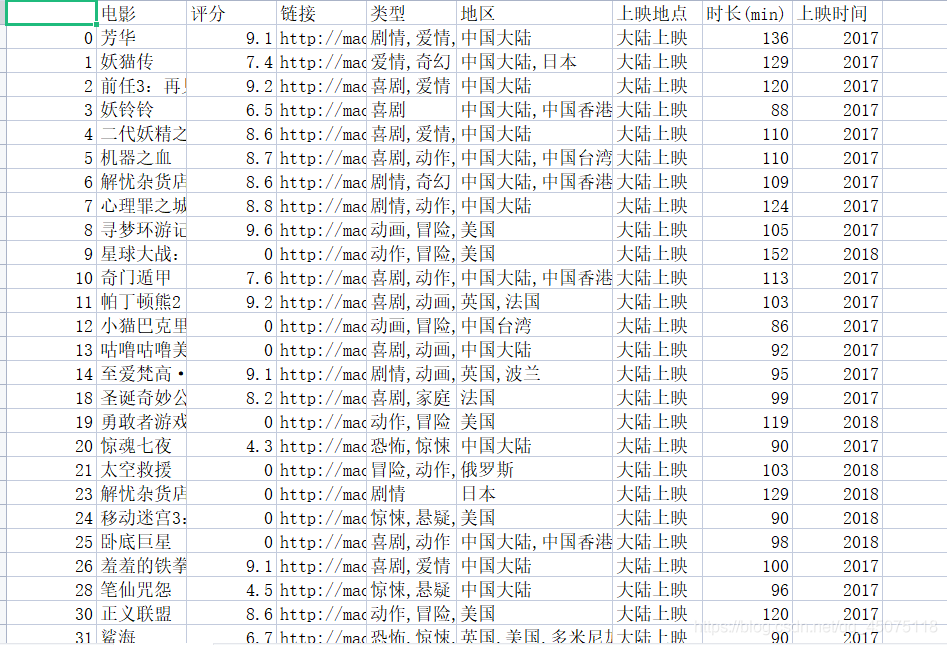
上周末接到一個單1200,客服抽了百分之十的提成,到手1000,兩個小時就完成了,心里美滋滋的,這樣的單其實平常不多,技術難度低但是價格高,我們俗稱“撿魚單”,想著賺錢了請女神吃飯,竟被無情拒絕!
貓眼電影資料可視化
- 效果展示
- 工具準備
- 專案思路決議
- 資料可視化需要用到的工具
- 效果圖展示
- 原始碼展示:
- 爬蟲:
- 可視化
- 小結
效果展示

工具準備
資料來源: 貓眼電影
開發環境:win10、python3.7
開發工具:pycharm、Chrome
專案思路決議
首先將貓眼電影的所以的電影資訊采集下來
這里以貓眼的top100榜為例
獲取到電影資訊:
- 電影名稱
- 電影評分
- 電影鏈接
- 電影型別
- 電影上映地點
- 地點
- 電影時長
- 電影時長
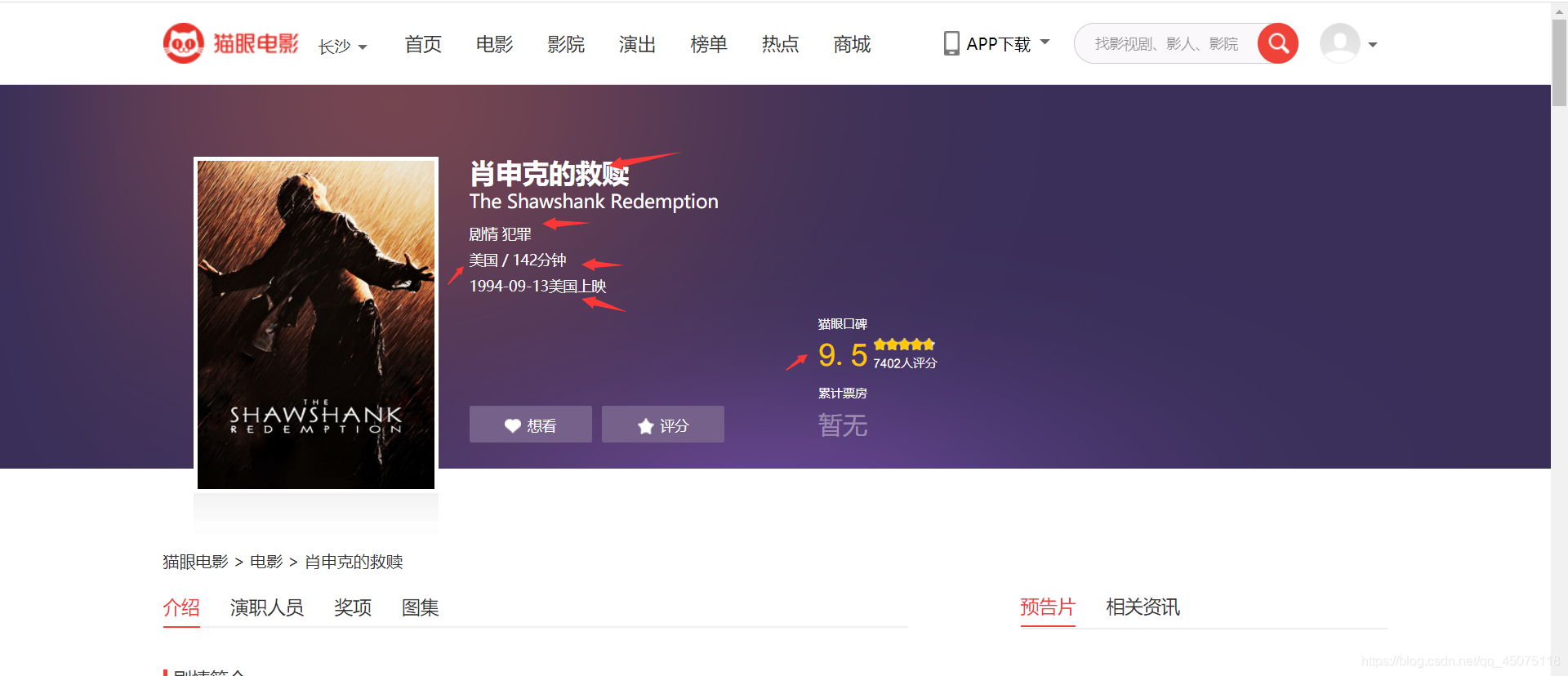
決議網頁資料資訊
決議首頁的跳轉鏈接
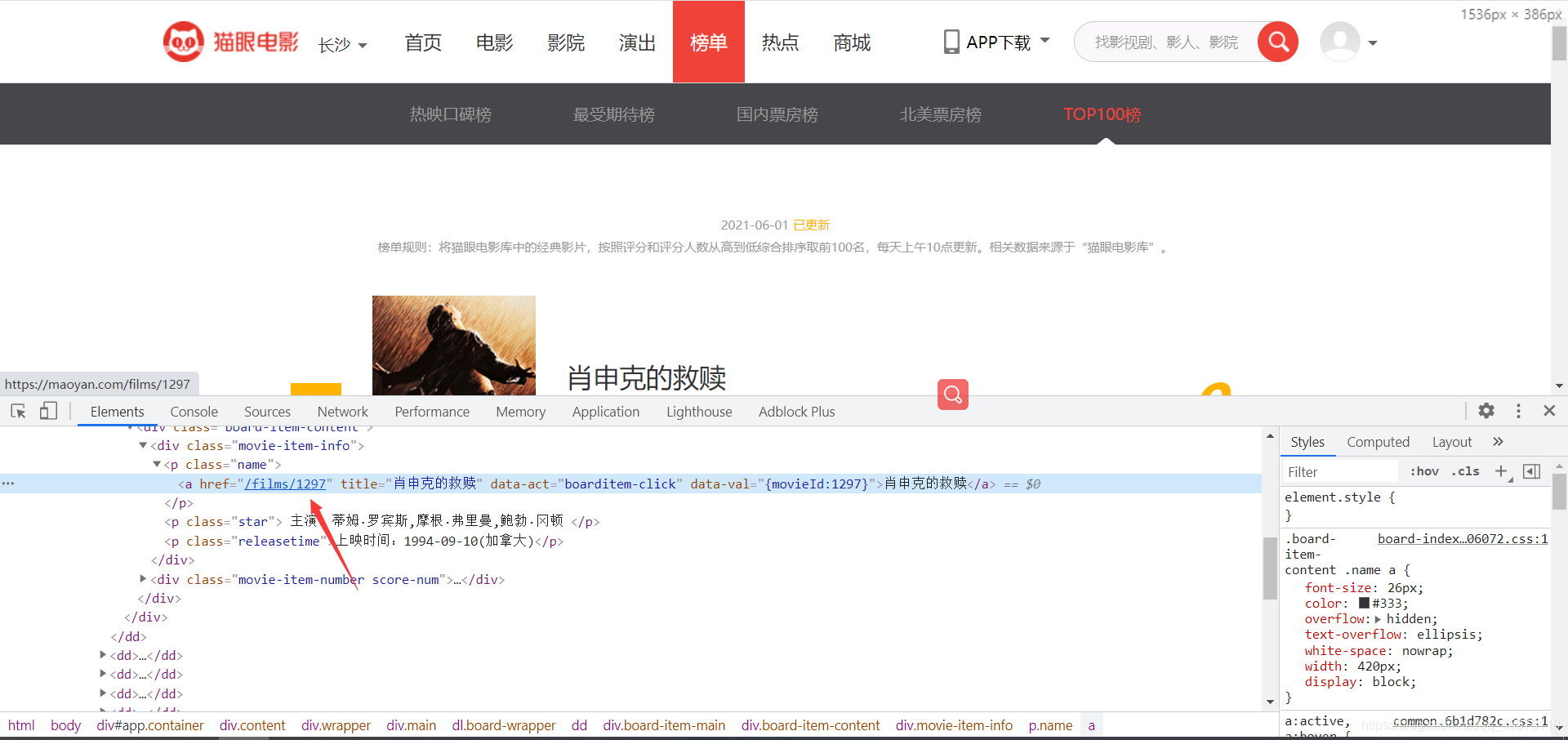
貓眼詳情頁面的評分是有加密的,所以我們直接重主頁提取評分資訊
在詳情頁面提取資料
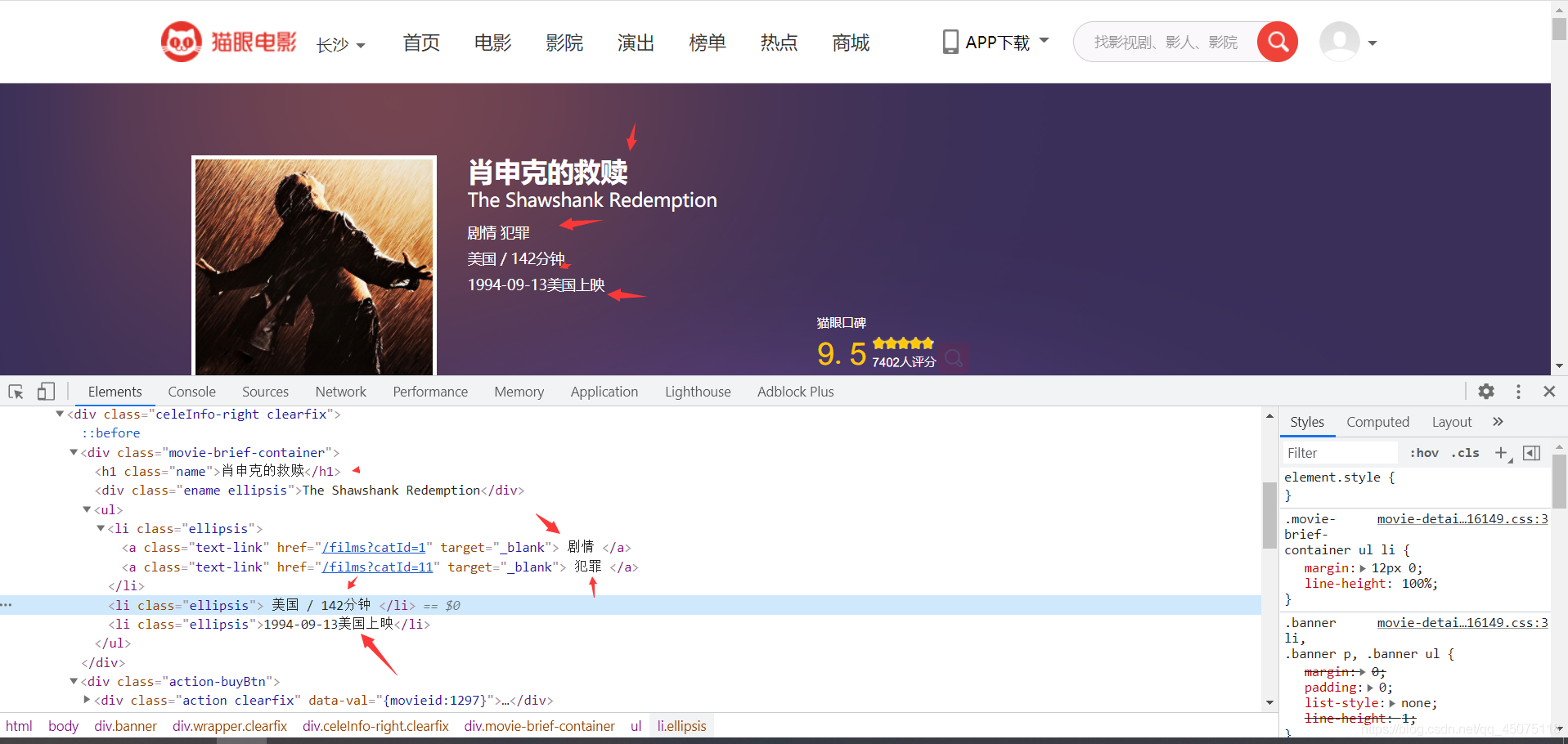
將資料保存在csv表格,方便之后做資料可視化
資料可視化需要用到的工具
import pandas as pd
import numpy as np
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# get_ipython().run_line_magic('matplotlib', 'inline')
效果圖展示

原始碼展示:
爬蟲:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021年06月05日
# @File : demo4.py
import requests
from fake_useragent import UserAgent
from lxml import etree
import time
# 隨機請求頭
ua = UserAgent()
# 構建請求 需要自己去網頁上面換一下 請求不到了就 去網頁重繪 把驗證碼弄了
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': '__mta=244176442.1622872454168.1622876903037.1622877097390.7; uuid_n_v=v1; uuid=6FFF6D30C5C211EB8D61CF53B1EFE83FE91D3C40EE5240DCBA0A422050B1E8C0; _csrf=bff9b813020b795594ff3b2ea3c1be6295b7453d19ecd72f8beb9700c679dfb4; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1622872443; _lxsdk_cuid=1770e9ed136c8-048c356e76a22b-7d677965-1fa400-1770e9ed136c8; _lxsdk=6FFF6D30C5C211EB8D61CF53B1EFE83FE91D3C40EE5240DCBA0A422050B1E8C0; ci=59; recentCis=59; __mta=51142166.1622872443578.1622872443578.1622876719906.2; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1622877097; _lxsdk_s=179dafd56bf-06d-403-d81%7C%7C12',
'User-Agent': str(ua.random)
}
def RequestsTools(url):
'''
爬蟲請求工具函式
:param url: 請求地址
:return: HTML物件 用于xpath提取
'''
response = requests.get(url, headers=headers).content.decode('utf-8')
html = etree.HTML(response)
return html
def Index(page):
'''
首頁函式
:param page: 頁數
:return:
'''
url = 'https://maoyan.com/board/4?offset={}'.format(page)
html = RequestsTools(url)
# 詳情頁地址后綴
urls_text = html.xpath('//a[@class="image-link"]/@href')
# 評分
pingfen1 = html.xpath('//i[@class="integer"]/text()')
pingfen2 = html.xpath('//i[@class="fraction"]/text()')
for i, p1, p2 in zip(urls_text, pingfen1, pingfen2):
pingfen = p1 + p2
urs = 'https://maoyan.com' + i
# 反正請求太過于頻繁
time.sleep(2)
Details(urs, pingfen)
def Details(url, pingfen):
html = RequestsTools(url)
dianyan = html.xpath('//h1[@class="name"]/text()') # 電影名稱
leixing = html.xpath('//li[@class="ellipsis"]/a/text()') # 型別
diqu = html.xpath('/html/body/div[3]/div/div[2]/div[1]/ul/li[2]/text()') # 讀取總和
timedata = html.xpath('/html/body/div[3]/div/div[2]/div[1]/ul/li[3]/text()') # 時間
for d, l, b, t in zip(dianyan, leixing, diqu, timedata):
countyr = b.replace('\n', '').split('/')[0] # 地區
shichang = b.replace('\n', '').split('/')[1] # 時長
f = open('貓眼.csv', 'a')
f.write('{}, {}, {}, {}, {}, {}, {}\n'.format(d, pingfen, url, l, countyr, shichang, t))
print(d, pingfen, url, l, countyr, shichang, t )
for page in range(0, 11):
page *= 10
Index(page)
可視化
#!/usr/bin/env python
# coding: utf-8
# 加載資料分析常用庫
import pandas as pd
import numpy as np
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# get_ipython().run_line_magic('matplotlib', 'inline')
# In[3]:
path='./maoyan.csv'
df=pd.read_csv(path,sep=',',encoding='utf-8',index_col=False)
df.drop(df.columns[0],axis=1,inplace=True)
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)
df.head(10)
#查看資料的結構
df.info()
print(df.columns)
# In[11]:
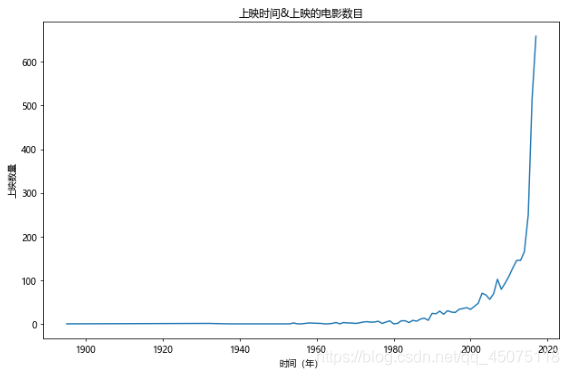
#年份&上映電影的數目 2018及以后的上映數目只是目前貓眼上公布的,具有不確定性,就先把2018及之后的剔除
fig,ax=plt.subplots(figsize=(9,6),dpi=70)
df[df[u'上映時間']<2018][u'上映時間'].value_counts().sort_index().plot(kind='line',ax=ax)
ax.set_xlabel(u'時間(年)')
ax.set_ylabel(u'上映數量')
ax.set_title(u'上映時間&上映的電影數目')
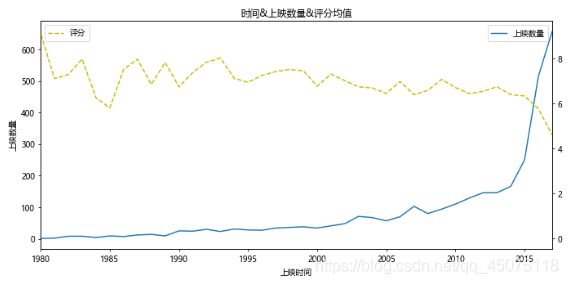
#基于上圖,再弄一個上映時間&上映數量&評分的關系圖
#但是由于1980年以前的資料量較少,評分不準確,將主要的分析區域集中在1980-2017
x=df[df[u'上映時間']<2018][u'上映時間'].value_counts().sort_index().index
y=df[df[u'上映時間']<2018][u'上映時間'].value_counts().sort_index().values
y2=df[df[u'上映時間']<2018].sort_values(by=u'上映時間').groupby(u'上映時間').mean()[u'評分'].values
fig,ax=plt.subplots(figsize=(10,5),dpi=70)
ax.plot(x,y,label=u'上映數量')
ax.set_xlim(1980,2017)
ax.set_xlabel(u'上映時間')
ax.set_ylabel(u'上映數量')
ax.set_title(u'時間&上映數量&評分均值')
ax2=ax.twinx()
ax2.plot(x,y2,c='y',ls='--',label=u'評分')
ax.legend(loc=1)
ax2.legend(loc=2)
# 解決中文亂碼,坐標軸顯示不出負值的問題
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# In[12]:
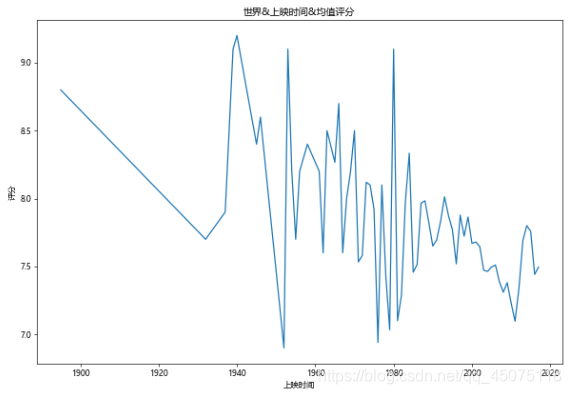
#世界&上映時間&均值評分
fig,ax=plt.subplots(figsize=(10,7),dpi=60)
df[df[u'評分']>0].groupby(u'上映時間').mean()[u'評分'].plot(kind='line',ax=ax)
ax.set_ylabel(u'評分')
ax.set_title(u'世界&上映時間&均值評分')
# In[13]:
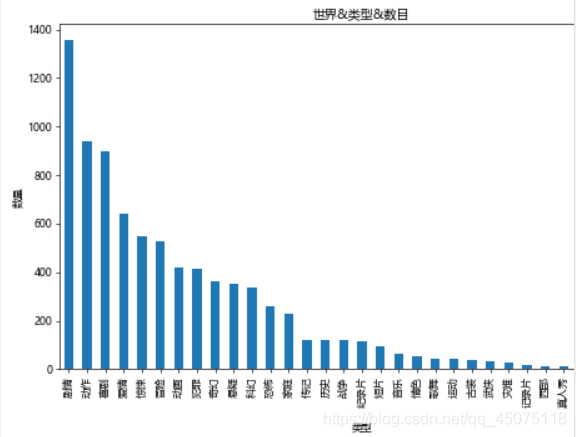
#世界各型別影片所占的數目
#對型別進行切割成最小單位,然后統計
types=[]
for tp in df[u'型別']:
ls=tp.split(',')
for x in ls:
types.append(x)
tp_df=pd.DataFrame({u'型別':types})
fig,ax=plt.subplots(figsize=(9,6),dpi=60)
tp_df[u'型別'].value_counts().plot(kind='bar',ax=ax)
ax.set_xlabel(u'型別')
ax.set_ylabel(u'數量')
ax.set_title(u'世界&型別&數目')
# In[14]:
#影片時長與評分的分布
#有個問題:其實有一些影片未進行評分,在這里要將這些給取締
x=df[df[u'評分']>0].sort_values(by=u'時長(min)')[u'時長(min)'].values
y=df[df[u'評分']>0].sort_values(by=u'時長(min)')[u'評分'].values
fig,ax=plt.subplots(figsize=(9,6),dpi=70)
ax.scatter(x,y,alpha=0.6,marker='o')
ax.set_xlabel(u'時長(min)')
ax.set_ylabel(u'數量')
ax.set_title(u'影片時長&評分分布圖')
#可以看出評分
i=0
c0=[]
c1=[]
c2=[]
c3=[]
c4=[]
c5=[]
c6=[]
c7=[]
for x in df[u'地區']:
if u'中國大陸' in x:
c0.append(df.iat[i, 0])
c1.append(df.iat[i, 1])
c2.append(df.iat[i, 2])
c3.append(df.iat[i, 3])
c4.append(df.iat[i, 4])
c5.append(df.iat[i, 5])
c6.append(df.iat[i, 6])
c7.append(df.iat[i, 7])
i=i+1
china_df=pd.DataFrame({u'電影':c0, u'評分':c1,u'鏈接':c2, u'型別':c3,u'地區':c4, u'上映地點':c5,u'時長(min)':c6,u'上映時間':c7})
# In[16]:
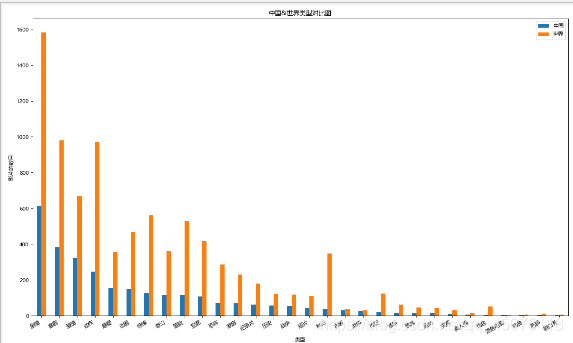
#中國&世界均值評分比較 時間范圍在1980-2017
x1 = df[df[u'評分']>0].groupby(u'上映時間').mean()[u'評分'].index
y1 = df[df[u'評分']>0].groupby(u'上映時間').mean()[u'評分'].values
x2 = china_df[china_df[u'評分']>0].groupby(u'上映時間').mean()[u'評分'].index
y2 = china_df[china_df[u'評分']>0].groupby(u'上映時間').mean()[u'評分'].values
fig,ax=plt.subplots(figsize=(12,9),dpi=60)
ax.plot(x1,y1,ls='-',c='DarkTurquoise',label=u'世界')
ax.plot(x2,y2,ls='--',c='Gold',label=u'中國')
ax.set_title(u'中國&世界均值評分')
ax.set_xlabel(u'時間')
ax.set_xlim(1980,2017)
ax.set_ylabel(u'評分')
ax.legend()
# In[17]:
#型別上映數目 中國&世界對比
#因為型別是混合的,為了方便統計 先寫一個函式用來對型別進行分割
# In[18]:
#寫分割的函式 傳入一個Sreies 型別物件 回傳一個型別分割的DataFrame
#這里傳入的是一個 型別的Series
def Cuttig_type(typeS):
types=[]
types1=[]
for x in typeS:
if len(x)<4:
# print x
types1.append(x)
ls=x.split(',')
for i in ls:
types.append(i)
types.extend(types1)
df=pd.DataFrame({u'型別':types})
return pd.DataFrame(df[u'型別'].value_counts().sort_values(ascending=False))
# In[19]:
#中國&世界影片型別比較
df1=Cuttig_type(china_df[u'型別'])
df2=Cuttig_type(df[u'型別'])
trans=pd.concat([df1,df2],axis=1)
trans.dropna(inplace=True)
trans.columns=[u'中國',u'世界']
fig,ax=plt.subplots(figsize=(15,9),dpi=80)
trans.plot(kind='bar',ax=ax)
fig.autofmt_xdate(rotation=30)
ax.set_title(u'中國&世界型別對比圖')
ax.set_xlabel(u'型別')
ax.set_ylabel(u'影片的數目')
# In[20]:
#然后就是散點分布了,中國&世界&時長&評分分布
y = df[df[u'評分'] > 0].sort_values(by=u'時長(min)')[u'評分'].values
x = df[df[u'評分'] > 0].sort_values(by=u'時長(min)')[u'時長(min)'].values
y2 = china_df[china_df[u'評分'] > 0].sort_values(by=u'時長(min)')[u'評分'].values
x2 = china_df[china_df[u'評分'] > 0].sort_values(by=u'時長(min)')[u'時長(min)'].values
fig, ax = plt.subplots(figsize=(10,7), dpi=80)
ax.scatter(x, y, c='DeepSkyBlue', alpha=0.6, label=u'世界')
ax.scatter(x2, y2, c='Salmon', alpha=0.7, label=u'中國')
ax.set_title(u'中國&世界評分分布情況')
ax.set_xlabel(u'時長(min)')
ax.set_ylabel(u'評分')
ax.legend(loc=4)
# In[25]:
dfs=df[(df[u'上映時間']>1980)&(df[u'上映時間']<2019)]
# for x in range(0,len(dfs)):
# print(dfs.iat[x,0],dfs.iat[x,-1])
df666 = dfs['電影'][:15]
wl = ",".join(df666.values)
# 把分詞后的txt寫入文本檔案
# fenciTxt = open("fenciHou.txt","w+")
# fenciTxt.writelines(wl)
# fenciTxt.close()
# 設定詞云l
wc = WordCloud(background_color="white", #設定背景顏色
# mask=imread('shen.jpg'), #設定背景圖片
# max_words=2000, #設定最大顯示的字數
font_path="C:\\Windows\\Fonts\\simkai.ttf", # 設定為楷體 常規
#設定中文字體,使得詞云可以顯示(詞云默認字體是“DroidSansMono.ttf字體庫”,不支持中文)
max_font_size=60, #設定字體最大值
random_state=30, #設定有多少種隨機生成狀態,即有多少種配色方案
)
myword = wc.generate(wl) #生成詞云
wc.to_file('result.jpg')
# 展示詞云圖
plt.imshow(myword)
plt.axis("off")
plt.show()
# In[41]:
小結
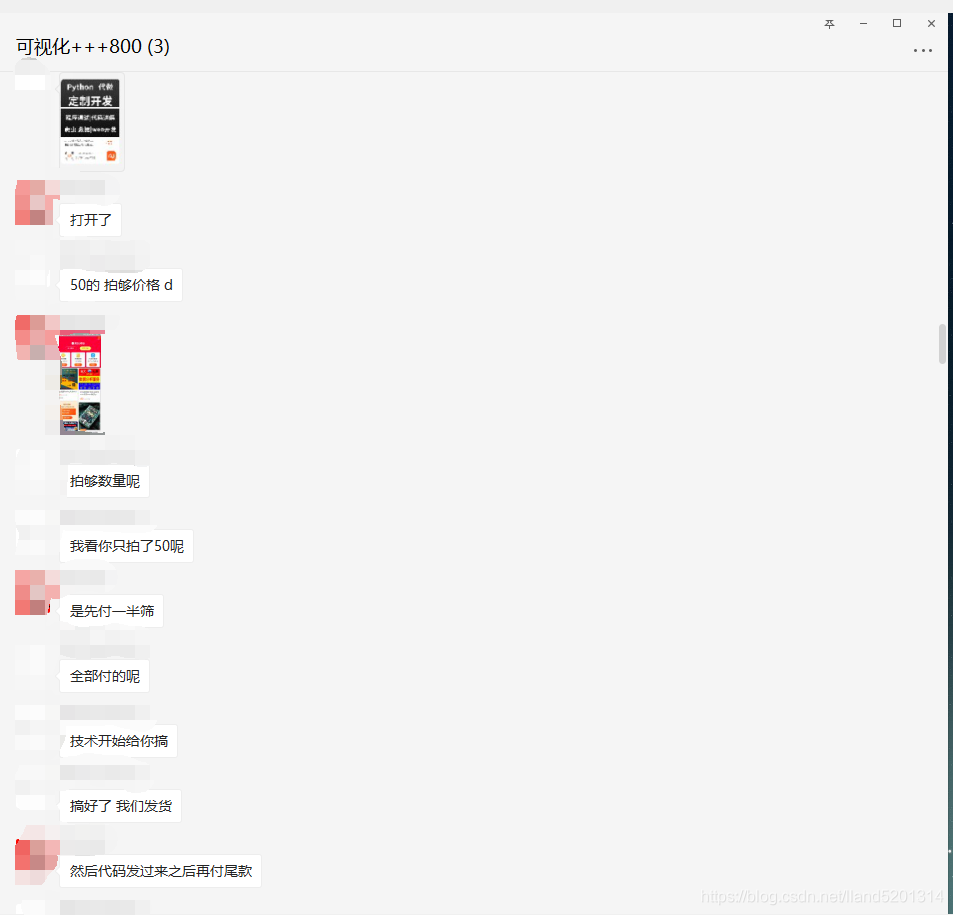
原始碼已經奉上了,就不對原始碼做決議了,如果對大家有用的話麻煩給個三連啦,十分感謝,最后給大家看一下我接單的程序,
PS : 接單拍單一定要走第三方平臺!!!
PS : 接單拍單一定要走第三方平臺!!!
PS : 接單拍單一定要走第三方平臺!!!
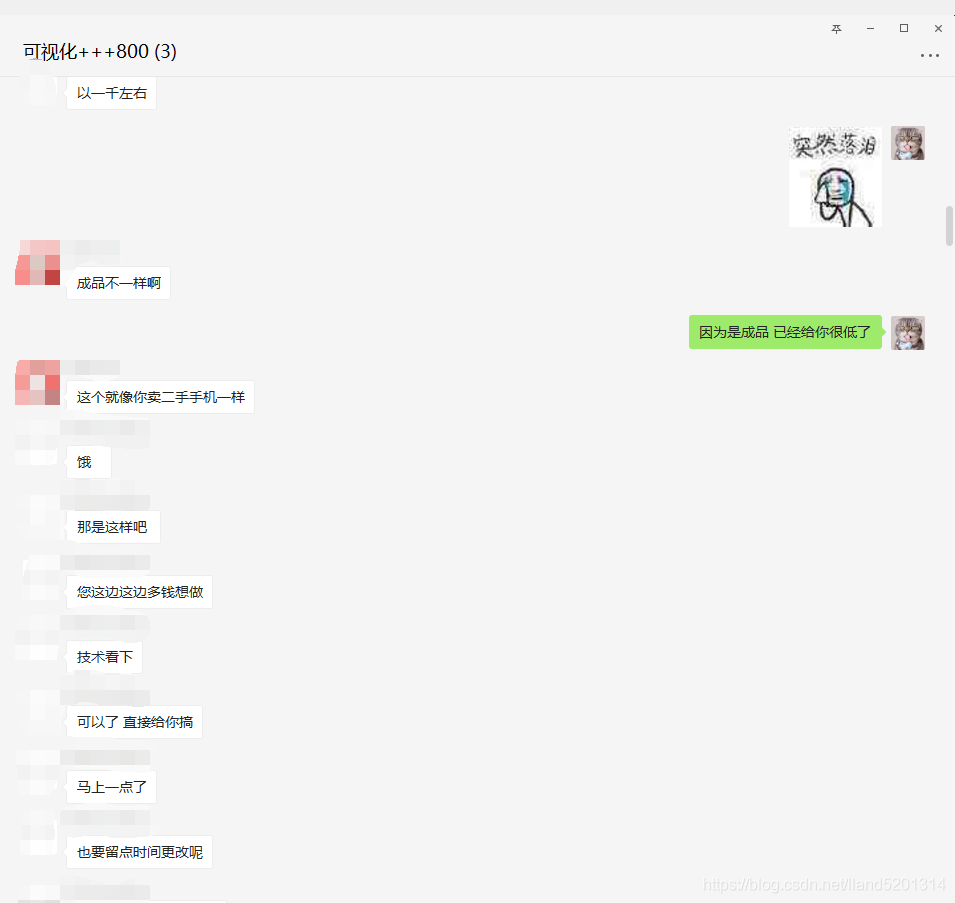
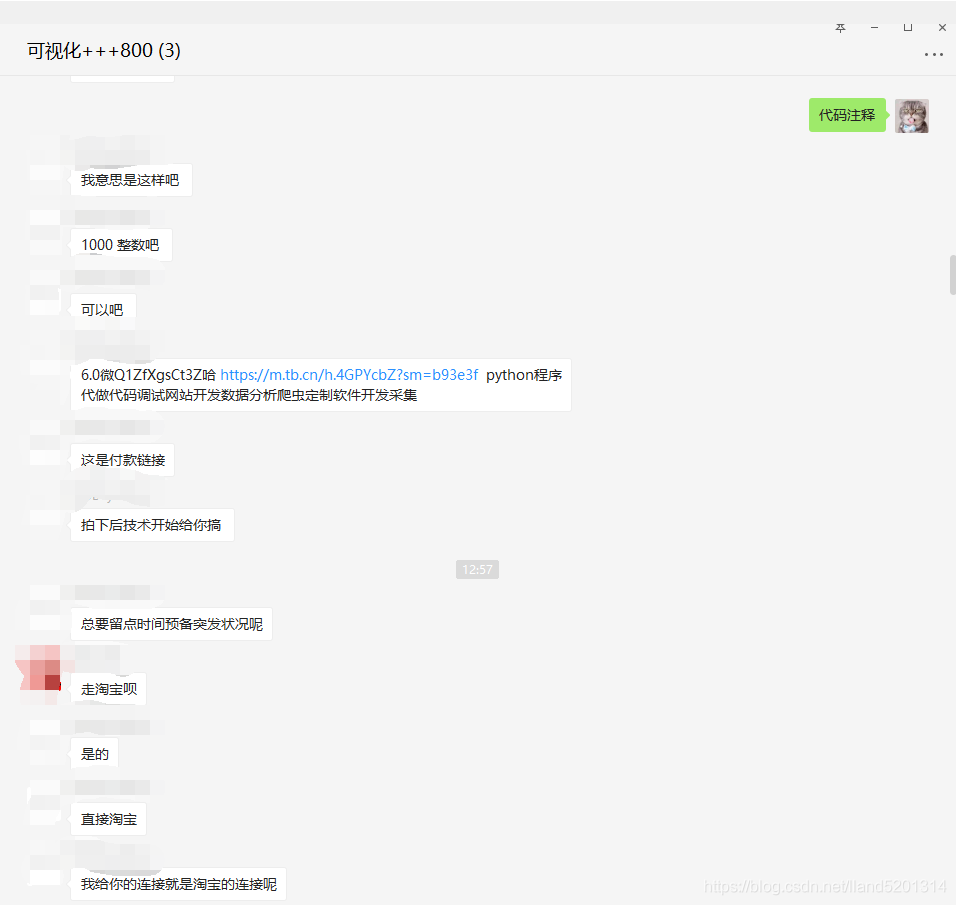
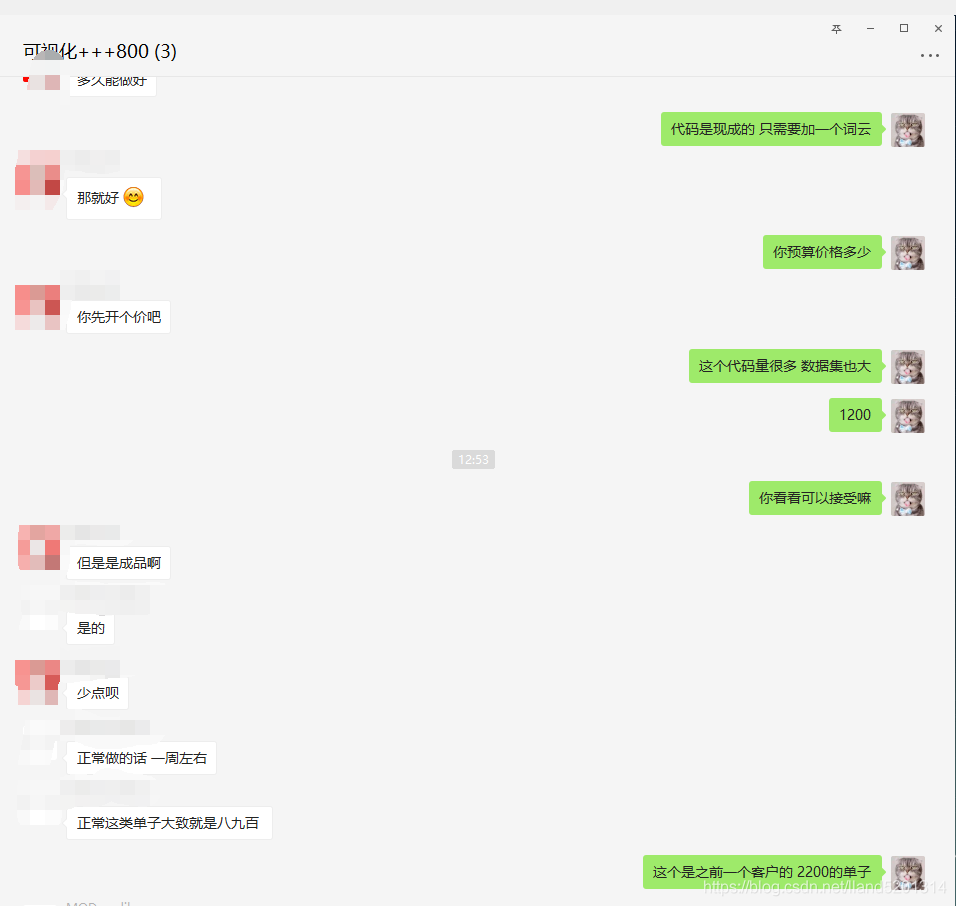
PS : 接單拍單一定要走第三方平臺!!!
PS : 接單拍單一定要走第三方平臺!!!
PS : 接單拍單一定要走第三方平臺!!!
如果大家有想法接單【有技術,小白別參和了】,或者想錘煉自己技術可在后臺私信我,備注自己會什么技術,想接哪一塊的單,我會拉大家進去,另外給小白整理了一些資料可自取,
①3000多本Python電子書有
②Python開發環境安裝教程有
③Python400集自學視頻有
④軟體開發常用詞匯有
⑤Python學習路線圖有
⑥專案原始碼案例分享有
如果你用得到的話可以直接拿走,在我的QQ技術交流群里(純技術交流和資源共享,廣告勿入)可以自助拿走,群號是949222410,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286325.html
標籤:python