作者:Eric Fu
鏈接:https://ericfu.me/g1-garbage-collector/
在過去很長一段時間內,HotSpot JVM 的首選垃圾收集器都是 ParNew + CMS 組合,直到 JDK7 中 Hotspot 團隊首次公布了 G1(Garbage-First),并在 JDK9 中用 G1 作為默認的垃圾收集器,我們團隊最近也將用了很多年的 CMS 換成了 G1 垃圾收集器,
本文主要從 G1 的論文 Garbage-First Garbage Collection 出發,結合其他較新的白皮書等,講解 G1 垃圾收集器的作業原理,
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.63.6386&rep=rep1&type=pdf
Motivation
關于為什么要重新設計一個 G1 垃圾收集器,論文中給出的理由相當簡單:現有的垃圾收集器無法滿足 軟實時(Soft Real-time) 特性:即讓 GC 停頓能大致控制在某個閾值以內,但是又不必像實時系統那樣非常嚴格,這也是很多業務系統都有的訴求,
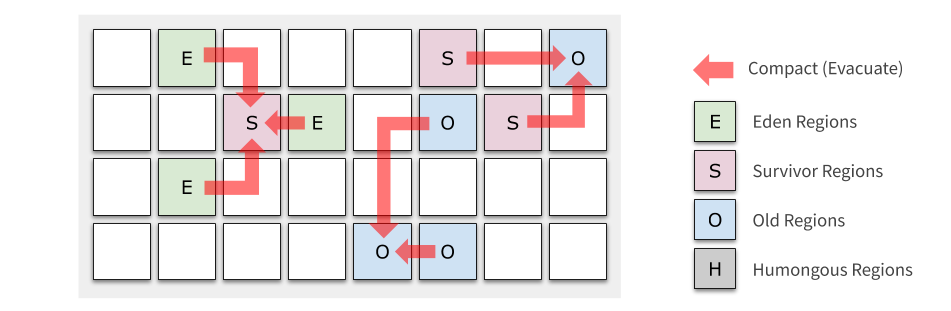
在過去的 JVM 設計中,如下圖所示,堆記憶體被分割成幾個區域 —— Eden、Survivor、Old 的大小都是預先劃分好的,對于總記憶體 64GB 的機器,可能 Old 區大小就有 32GB,即使用并行的方式收集一次仍然需要數秒,近十年,隨著記憶體越來越大,這一問題也變得更為嚴重,
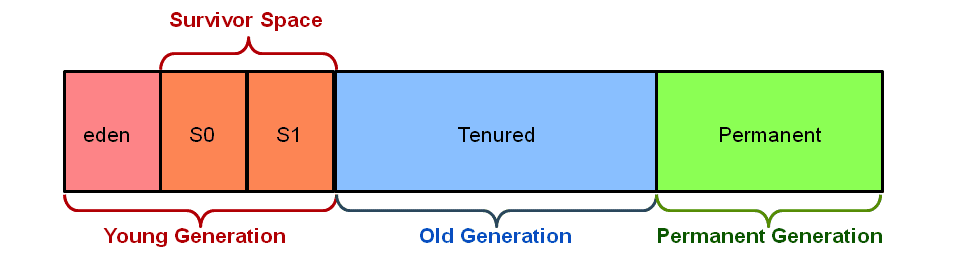
為了達到軟實時的目標,同時也是為了更好地應對大記憶體,G1 將中不再使用上述的記憶體布局,
基本資料結構
首先,我們介紹 G1 種最核心的兩個概念:Region 和 Remember Set,
Heap Regions
如下圖所示,G1 垃圾收集器將堆記憶體空間分成等分的 Regions,物理上不一定連續,邏輯上構成連續的堆地址空間,各個 Mutator 執行緒(即用戶應用的執行緒)擁有各自的 Thread-Local Allocation Buffer (TLAB),用于降低各個執行緒分配記憶體的沖突,
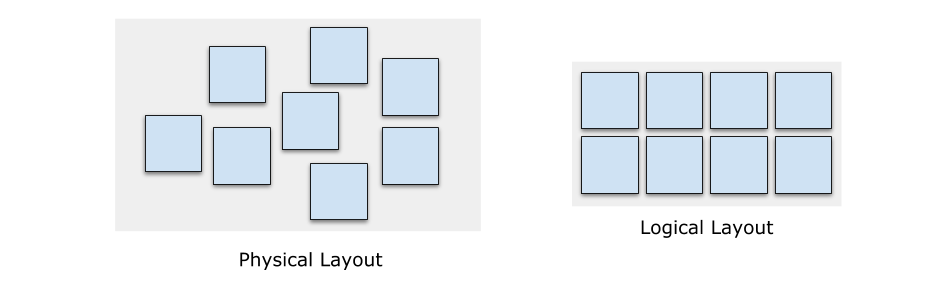
要特別注意的是,巨型物件(Humongous Object),即大小超過 3/4 的 Region 大小的物件會作特殊處理,分配到由一個或多個連續 Region 構成的區域,巨型物件會引起其他一些問題,不過這些已經超出了本文的范疇,總之記得盡量別用就好了,
默認配置下,在滿足 Region Size 是 2 的整數冪的前提下,G1 將總記憶體盡量劃分成大約 2048 個 Region,
Remember Set (RSet)
為什么要把堆空間分成 Region 呢?其主要目的是讓各個 Region 相對獨立,可以分別進行 GC,而不是一次性地把所有垃圾收集掉,我們知道現代 GC 演算法都是基于可達性標記,而這個程序必須遍歷所有 Live Objects 才能完成,那問題來了,如果為了收集一個 Region 的垃圾,卻完整的遍歷所有 Live Objects,這也太浪費了!
所以,我們需要一個機制來讓各個 Region 能獨立地進行垃圾收集,這也就是 Remember Set 存在的意義,每個 Region 會有一個對應的 Remember Set,它記錄了哪些記憶體區域中存在對當前 Region 中物件的參考,(all locations that might contain pointers to (live) objects within the region)
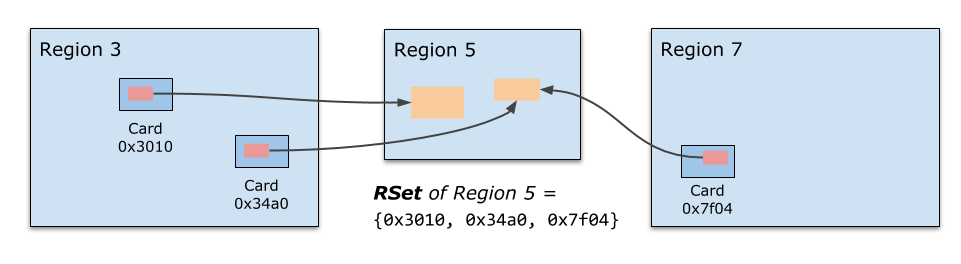
注意 Remember Set 不是直接記錄物件地址,而是記錄了那些物件所在的 Card 編號,所謂 Card 就是表示一小塊(512 bytes)的記憶體空間,這里面很可能存在不止一個物件,但是這已經足夠了:當我們需要確定當前 Region 有哪些物件存在外部參考時(這些物件是可達的,不能被回收),只要掃描一下這塊 Card 中的所有物件即可,這比掃描所有 live objects 要容易的多,
實作上,Remember Set 的實作就是一個 Card 的 Hash Set,并且為每個 GC 執行緒都有一個本地的 Hash Set,最后的 Remember Set 實際上是這些 Hash Set 的并集,當 Card 數量特別多的時候會退化到 Region 粒度,這時候就要掃描更多的區域來尋找參考,時間換空間,
Remember Set 的維護
維護上面所說的 Remember Set 勢必需要記錄物件的參考,通常的做法是在 set 一個參考的時候插入一段代碼,這稱為 Write Barrier,為了盡可能降低對 Mutator 執行緒的影響,Write Barrier 的代碼應當盡可能簡化,G1 的 Write Barrier 實際上只是一個“通知”:將當前 set 參考的事件放到 Remember Set Log 佇列中,交給后臺專門的 GC 執行緒處理,
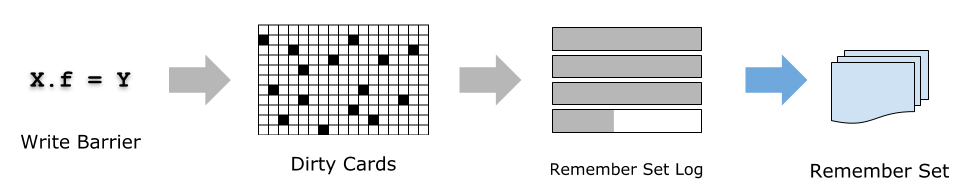
Write Barrier 具體實作如下,當發生 X.f = Y 時,假設 rX 為 X 物件的地址,rY 為 Y 物件的地址,則 Write 的同時還會執行以下邏輯:
t = (rX XOR rY) >> LogOfRegionSize // 對 X, Y 地址右移得到 Region 編號,并將二者做個 XOR
if (rY == NULL ? 0 : t) // 忽略兩種情況: X.f 被賦值為 NULL,或 X 和 Y 位于同一個 Region 內
rs_enqueue(rX) // 如果 Card(X) 還不是 dirty 的,將 X 的地址放進 Log,并把該 card 置為 dirty
這里 Dirty Bit 的作用是去除重復的 Cards,考慮到一個 Cards 內經常發生密集的參考賦值(比如物件初始化),去重一下能大幅減少冗余,
最后,后臺的 GC 執行緒則負責從 Remember Set Log 不斷取出這些參考賦值發生的 Cards,掃描上面所有的物件,然后更新相應 Region 的 Remember Set,在并發標記發生之前,G1 會確保 Remember Set Log 中的記錄都處理完,從而保證并發標記演算法一定能拿到最新的、正確的 Remember Set,
極端情況下,如果后臺的 GC 行程追不上 Mutator 行程寫入的速度,這時候 Mutator 執行緒會退化到自己處理更新,形成反壓機制,
Generational Garbage-First
G1 名字來自于 Garbage-First 這個理念,即,以收集到盡可能多的垃圾為第一目標,每次收集時 G1 會選出垃圾最多的幾個 Region,進行一次 Stop-the-world 的收集程序,
有趣的是,另一方面 G1 又是一個 Generational (分代)的垃圾收集器,它會從邏輯上將 Region 分成 Young、Old 等不同的 Generation,然后針對它們各自特點應用不同的策略,
G1 論文中提到它有一個 Pure Garbage-First 的模式,但在現在的資料中已經很難看到它的蹤影,我猜測實際使用中 Generational 模式要效果好的多,以下我們也會只討論 Generational 模式的作業方式,
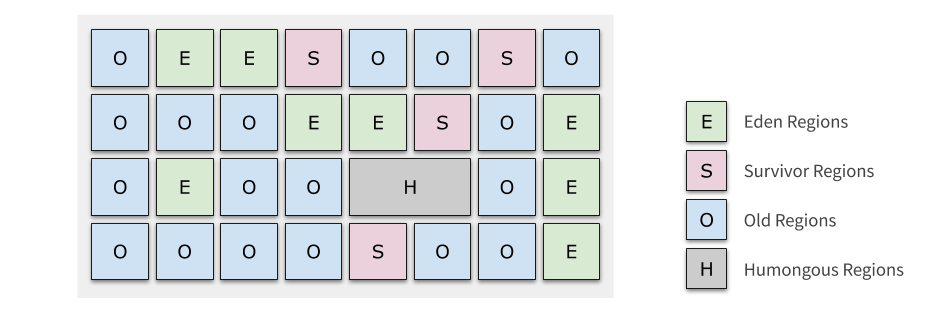
經典的記憶體布局中,各代的記憶體區域是完全分開的,而 G1 中的 Generation 只是 Region 的一個動態標志,下圖是一個標記了 Generation 的例子,各個 Region 的 Generation 是隨著 GC 的進行而不斷變化的,甚至各個代有多少 Region 這個比例也是隨時調整的,
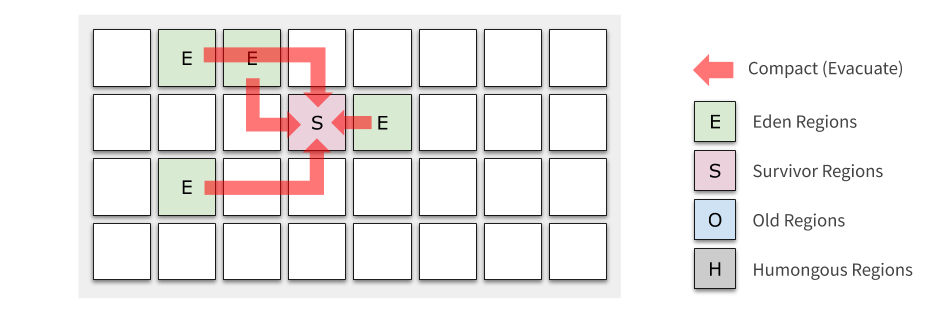
Evacuation
為了方便讀者理解 G1 收集的程序,我們先看下 Evacuation 的程序,之后再看如何做 Marking,
Generational 模式下 G1 的垃圾收集分為兩種:Young GC 和 Mixed GC,Young GC 只會涉及到 Young Regions,它將 Eden Region 中存活的物件移動到一個或多個新分配的 Survivor Region,之前的 Eden Region 就被歸還到 Free list,供以后的新物件分配使用,
當區域中物件的 Survive 次數超過閾值(TenuringThreshold)時,Survivor Regions 的物件被移動到 Old Regions;否則和 Eden 的物件一樣,繼續留在 Survivor Regions 里,
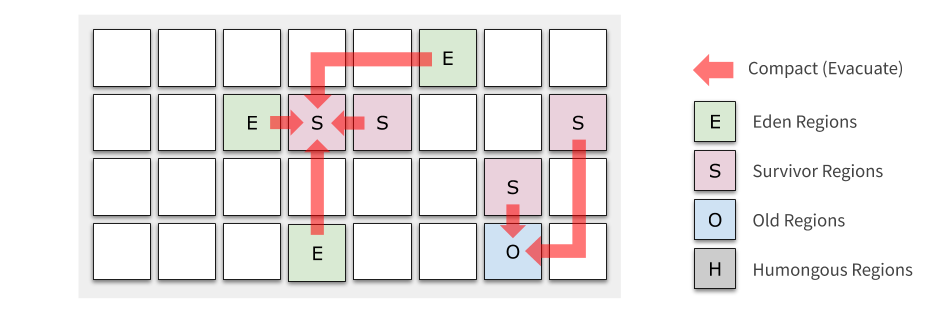
多次 Young GC 之后,Old Regions 慢慢累積,直到到達閾值(InitiatingHeapOccupancyPercent,簡稱 IHOP),我們不得不對 Old Regions 做收集,這個閾值在 G1 中是根據用戶設定的 GC 停頓時間動態調整的,也可以人為干預,
對 Old Regions 的收集會同時涉及若干個 Young 和 Old Regions,因此被稱為 Mixed GC,Mixed GC 很多地方都和 Young GC 類似,不同之處是:它還會選擇若干最有潛力的 Old Regions(收集垃圾的效率最高的 Regions),這些選出來要被 Evacuate 的 Region 稱為本次的 Collection Set (CSet),
Mixed GC 的重要性不言而喻:Old Regions 的垃圾就是在這個階段被收集掉的,也正是因為這樣,Mixed GC 是作業量最為繁重的一個環節,如果不加以控制,就會像 CMS 一樣發生長時間的 Full GC 停頓,這時候 Region 的設計就發揮出優越性了:只要把每次的 Collection Set 規模控制在一定范圍,就能把每次收集的停頓時間軟性地控制在 MaxGCPauseMillis 以內,起初這個控制可能不太精準,隨著 JVM 的運行估算會越來越準確,
那來不及收集的那些 Region 呢?多來幾次就可以了,所以你在 GC 日志中會看到 continue mixed GCs 的字樣,代表分批進行的各次收集,這個程序會多次重復,直到垃圾的百分比降到 G1HeapWastePercent 以內,或者到達 G1MixedGCCountTarget 上限,
對于 Young Regions,我們對它有以下特殊優化:
- Evacuation 的時候,Young Regions 一定會被放到待收集的 Regions 集合(Collection Set)中,原因很簡單,絕大多數物件壽命都很短,在 Young Regions 做收集往往絕大部分都是垃圾,
- 由于 Young Regions 一定會被收集,我們獲得了一個可觀的收益:Remember Set 的維護作業不需要考慮 Young 內的參考修改(換句話說 RSet 只關心 old-to-young 和 old-to-old 的參考),當 Young Region 上發生 Evacuation 時我們再去掃描并構建出它的 RSet 即可,
Concurrent Marking
在 Evacuation 之前,我們要通過并發標記來確定哪些物件是垃圾、哪些還活著,G1 中的 Concurrent Marking 是以 Region 為單位的,為了保證結果的正確性,這里用到了 Snapshot-at-the-beginning(SATB)演算法,
SATB 演算法顧名思義是對 Marking 開始時的一個(邏輯上的)Snapshot 進行標記,為什么要用 Snapshot 呢?下面就是一個直接標記導致問題的例子:物件 X 由于沒有被標記到而被標記為垃圾,導致 B 參考失效,

SATB 演算法為了解決這一問題,在修改參考 X.f = B 之前插入了一個 Write Barrier,記錄下被覆寫之前的參考地址,這些地址最終也會被 Marking 執行緒處理,從而確保了所有在 Marking 開始時的參考一定會被標記到,這個 Write Barrier 偽代碼如下:
t = the previous referenced address // 記錄原本的參考地址
if (t has been marked && t != NULL) // 如果地址 t 還沒來的及標記,且 t 不為 NULL
satb_enqueue(t) // 放到 SATB 的待處理佇列中,之后會去掃描這個參考
通過以上措施,SATB 確保 Marking 開始時存活的物件一定會被標記到,
標記的程序和 CMS 中是類似的,可以看作一個優化版的 DFS:記當前已經標記到的 offset 為 cur,隨著標記的進行 cur 不斷向后推進,每當訪問到地址 < cur 的物件,就對它做深度掃描,遞回標記所有應用;反之,對于地址 > cur 的物件,只標記不掃描,等到 cur 推進到那邊的時候再去做掃描,
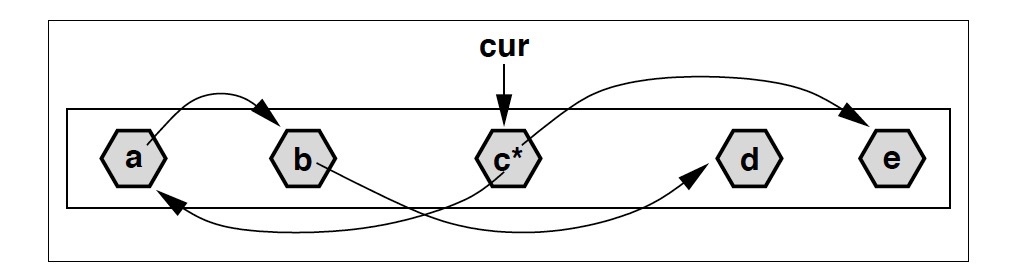
上圖中,假設當前 cur 指向物件 c,c有兩個參考:a 和 e,其中 a 的地址小于 cur,因而做了掃描;而 e 則僅僅是標記,掃描 a 的程序中又發現了物件 b,b 同樣被標記并繼續掃描,但是 b 參考的 d 在 cur 之后,所以 d 僅僅是被標記,不再繼續掃描,
最后一個問題是:如何處理 Concurrent Marking 中新產生的物件?因為 SATB 演算法只保證能標記到開始時 snapshot 的物件,對于新出現的那些 物件,我們可以簡單地認為它們全都是存活的,畢竟數量不是很多,
最后,關注公眾號Java技術堆疊,在后臺回復:JVM46,可以獲取一份 46 頁的 JVM 調優教程,
參考資料:
- Detlefs, David, et al Garbage-First Garbage Collection. Proceedings of the 4th international symposium on Memory management. ACM, 2004.
- Printezis, Tony, and David Detlefs. A Generational Mostly-Concurrent Garbage Collector. Vol. 36. No. 1. ACM, 2000.
- https://www.oracle.com/technetwork/java/javase/tech/memorymanagement-whitepaper-1-150020.pdf
- https://www.redhat.com/en/blog/part-1-introduction-g1-garbage-collector1
- https://www.redhat.com/en/blog/collecting-and-reading-g1-garbage-collector-logs-part-2
- https://www.slideshare.net/MonicaBeckwith/con5497
- https://blog.csdn.net/coderlius/article/details/79272773
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2021最新版)
2.終于靠開源專案弄到 IntelliJ IDEA 激活碼了,真香!
3.阿里 Mock 工具正式開源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式發布,全新顛覆性版本!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288489.html
標籤:Java