前言
暑假來臨,好多小伙伴都在找暑期實習吧?前幾天,朋友的弟弟,想在暑假期間找個實習作業鍛煉自己,可是面對網路上幾千條實習招聘資訊,簡直讓人頭大,隨后朋友向我發出了“請求幫助”的資訊,我了解了大致情況后,立馬用爬蟲爬取了實習網的的資訊,將資料結果發了過去,問題分分鐘解決,這請我吃一頓飯不過分吧?

這篇爬蟲實戰教程,不僅適合新手練習爬蟲,也適合需要找實習資訊的朋友!
希望在看了這篇文章后,能夠清晰的知道整個爬蟲流程,并且能夠獨立自主的完成,其次,能夠通過自己的爬蟲實戰,獲取自己想要的資訊,
好了,話不多說,咱們就開始吧!
內容主要分為兩個部分:
1、頁面分析
2、爬蟲步驟詳解
一、頁面分析
1、分析實習網
首先,我們應該要知道自己的爬蟲目標是個什么東西吧?俗話說,知己知彼,百戰不殆,我們已經知道自己要爬取的頁面是“實習網”,所以,咱們首先得去實習網看看,都有些什么資料,
實習網址: https://www.shixi.com/search/index
頁面如下:
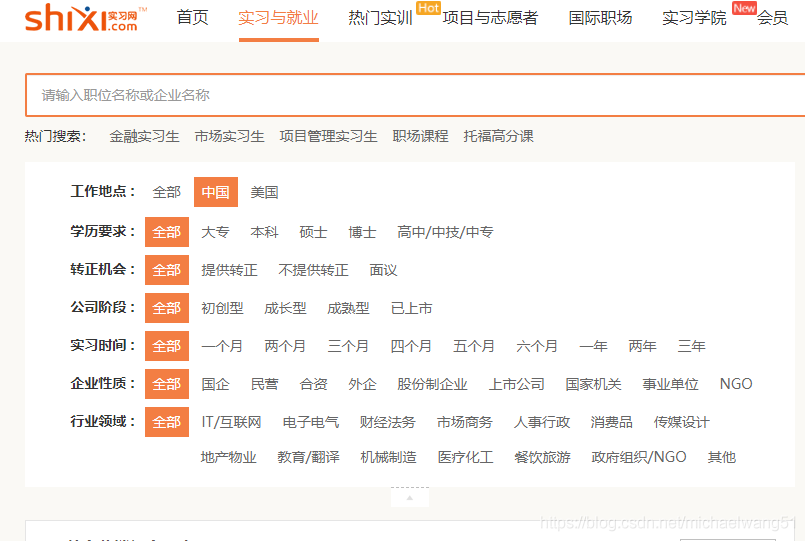
例如我們要找的崗位是“品牌運營”崗位的資料,因此直接在網頁的搜索框輸入品牌運營就行了,你會發現url發生了變化!

注意:我們要爬取的頁面就是這頁:https://www.shixi.com/search/index?key=品牌運營
在我們的爬取頁面中,我們需要觀察有哪些資料,并且一個頁面中有幾條資料,這個非常重要,關系到后面的代碼撰寫,以及可以幫你檢查,是否爬取到了頁面的所有資訊,
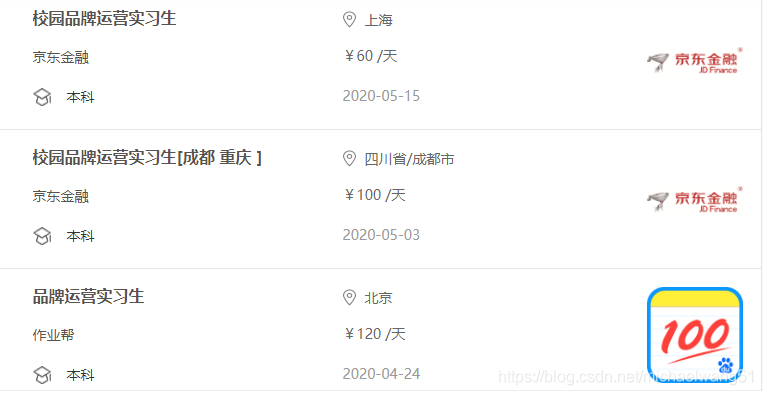
此時,我們要注意的是,我們所在的頁面是“一級頁面”,在瀏覽程序中,我們 點擊隨意一個崗位進入后呈現的是“二級頁面”,此時你也會發現url又發生了變化,
例如,我們點一個品牌運營實習,二級頁面就會自動跳轉成這樣,產生一個新的鏈接,如圖:
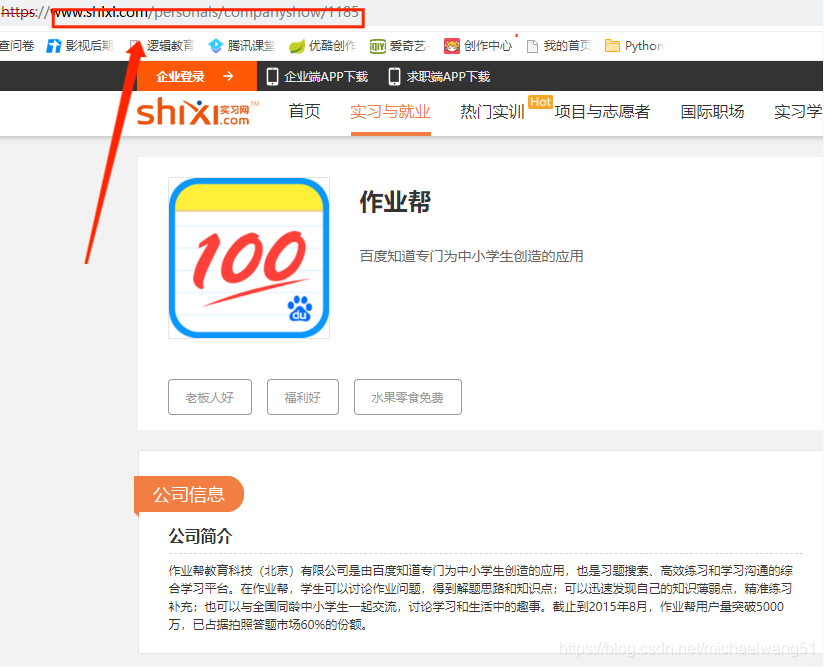
2、要爬取頁面上的那些資訊呢?
我們在分析程序中發現,有些資訊是在一級頁面中,有些是在二級頁面中,
在一級頁面中,我們可以獲取那些資訊呢?如圖所示:

總共有五條有效資料:職位、公司名、學歷、薪資、地址
在二級頁面中,我們來看看可以獲取什么有效資料,領域和規模,階段如果你覺得重要的話,也可以納入爬蟲范圍,但是我個人認為,這并不影響實習,畢竟不是找正式作業,影響不會很大,反而是招聘實習生的數量更為重要,這里并未顯示招聘人數,無法在圖片上呈現,后續可加上,

到這里,我們一共需要抓取7個資料,加上“人數”一共8個資料,這也就是我們爬蟲的最終目標資料,
3、爬取“靜態”網頁
這里分析下什么叫靜態網頁,什么叫動態網頁,靜態網頁,隨著html代碼的生成,頁面的內容和顯示效果就基本上不會發生變化了--除非你修改頁面代碼,而動態網頁則不然,頁面代碼雖然沒有變,但是顯示的內容卻是可以隨著時間、環境或者資料庫操作的結果而發生改變的,
它們的區別就在于:靜態網頁中的資料,是一勞永逸,也就是說一次性給你,動態網頁中的資料,是隨著頁面一步步加載出來,而逐步呈現的,也就是你用靜態網頁的爬蟲技術,無法獲取到其中所有的資料,
值得強調的是,不要將動態網頁和頁面內容是否有動感混為一談,這里說的動態網頁,與網頁上的各種影片、滾動字幕等視覺上的動態效果沒有直接關系,動態網頁也可以是純文字內容的,也可以是包含各種影片的內容,這些只是網頁具體內容的表現形式,無論網頁是否具有動態效果,只要是采用了動態網站技術生成的網頁都可以稱為動態網頁,
點擊 “滑鼠右鍵”,點擊 “查看網頁源代碼”,最終效果如圖(部分截圖):

這就是,最終反饋給你的資料,如果你發現自己想要的資料都在這里面,那么就可以說是靜態頁面,如若不然,則考慮為“動態頁面”,
今天這里的案例是靜態網頁,
大家知道,在寫代碼之前要先知道,我們要用哪些方式,哪些庫,哪些模塊去幫你決議資料,常見用來決議資料的方法有:re正則運算式、xpath、beatifulsoup、pyquery等,
我們需要用到的是xpath決議法來分析定位資料,
二、爬蟲代碼講解
1、匯入相關庫
爬蟲的第一步是要考慮好,爬蟲程序中需要用到哪些庫,要知道python是一個依賴于眾多庫的語言,沒有庫的Python是不完整的,
import pandas as pd # 用于資料存盤
import requests # 用于請求網頁
import chardet # 用于修改編碼
import re # 用于提取資料
from lxml import etree # 決議資料的庫
import time # 可以粗糙模擬人為請求網頁的速度
import warnings # 忽略代碼運行時候的警告資訊
warnings.filterwarnings("ignore")2、請求一級頁面的網頁源代碼
url = 'https://www.shixi.com/search/index?key=品牌運營&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)這里我們要注意①②兩個地方,在①處,有兩個引數,一個是headers一個是verify,其中headers是一種反反扒的措施,讓瀏覽器認為爬蟲不是爬蟲,而是人在用瀏覽器去正常請求網頁,verify是忽略安全證書提示,有的網頁會被認為是一個不安全的網頁,會提示你,這個引數你記住就行,
在②處,我們已經獲取到了網頁的原始碼,但是由于網頁源代碼的編碼方式和你所在電腦的決議方式,有可能不一致,回傳的結果會導致亂碼,此時,你就需要修改編碼方式,chardet庫可以幫你自動檢測網頁原始碼的編碼,(一個很好用的檢測檔案編碼的三方庫chardet)
3、決議一級頁面網頁中的資訊
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 崗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 學歷
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪資
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]獲取二級頁面的鏈接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]此時,你可以看到,我直接采用xpath一個個去決議一級頁面中的資料分析,在代碼末尾,可以看到:我們獲取到了二級頁面的鏈接,為我們后面爬取二級頁面中的資訊,做準備,
4、決議二級頁面網頁中的資訊
要注意的是,二級頁面也是頁面,在爬取其中的資料時,也需要請求頁面,所以,①②③處的代碼,都是一模一樣的,
demand_list = []
area_list = []
scale_list = []
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 招聘人數
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司領域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司規模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)5、翻頁操作
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=1
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=2
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=3隨意復制幾個不同頁面的url,觀察它們的區別,這里可以看到,也就page引數后面的數字不同,是第幾頁,數字就是幾,
x = "https://www.shixi.com/search/index?key=資料分析&page="
url_list = [x + str(i) for i in range(1,20)] 由于我們爬取了20頁 的資料,這里就構造出了20個url,他們都存在url_list這個串列中,
6、完整代碼
我們現在來看看整個代碼吧,我就不再文字敘述了,直接在代碼中寫好了注釋,
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# 請求獲取一級頁面的源代碼
url = 'https://www.shixi.com/search/index?key=品牌運營&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# 獲取一級頁面中的資訊:一共有5個資訊,
# ①公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
#②崗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
#③地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# ④ 學歷
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# ⑤薪資
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# ⑥獲取二級頁面的內容
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# 獲取二級頁面中的資訊:
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
#① 需要幾人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# ②公司領域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# ③公司規模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
# ④ 將每個頁面獲取到的所有資料,存盤到DataFrame中,
data = pd.DataFrame({'公司名':company_list,'崗位名':job_list,'地址':address_list,"學歷":degree_list,
'薪資':salary_list,'崗位需求量':demand_list,'公司領域':area_list,'公司規模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=資料分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','崗位名','地址',"學歷",'薪資','崗位需求量','公司領域','公司規模'])
# 這里進行“翻頁”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# 保存資料
res.to_csv('aliang.csv',encoding='utf_8_sig')三、獲取源代碼
這樣一套下來,爬蟲的思路是不是瞬間清晰明了?眼睛:我會了!手:我還是不會,得多加練習啊,初學者不要急于求成,專案不在多,在精,踏踏實實吃透一個遠比看會十個更有效,
想要獲取源代碼的小火伴們,點贊+評論,看我主頁!或者直接si我~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/289299.html
標籤:python
上一篇:用python爬取豆瓣電影資訊,輸入類別和爬取頁數,想怎么爬就怎么爬,哎就是玩!
下一篇:[Python影像處理] 四十二.Python影像銳化及邊緣檢測萬字詳解(Roberts、Prewitt、Sobel、Laplacian、Canny、LOG)