追風趕月莫停留,平蕪盡處是春山,
文章目錄
- 追風趕月莫停留,平蕪盡處是春山,
- 一、網頁分析
- 二、介面分析
- url分析
- 回傳資料分析
- 三、撰寫代碼
- 獲取資料
- 保存資料
- 完整代碼
終于終于終于期末考試結束了,暑假集訓也結束了,終于有時間來更新我的博客了!!
今天咱們來聊一聊關于微博粉絲和關注者賬號的抓取,
依舊是使用新版微博,依舊是熟悉的女神迪麗熱巴😍,
咱們先看粉絲
一、網頁分析
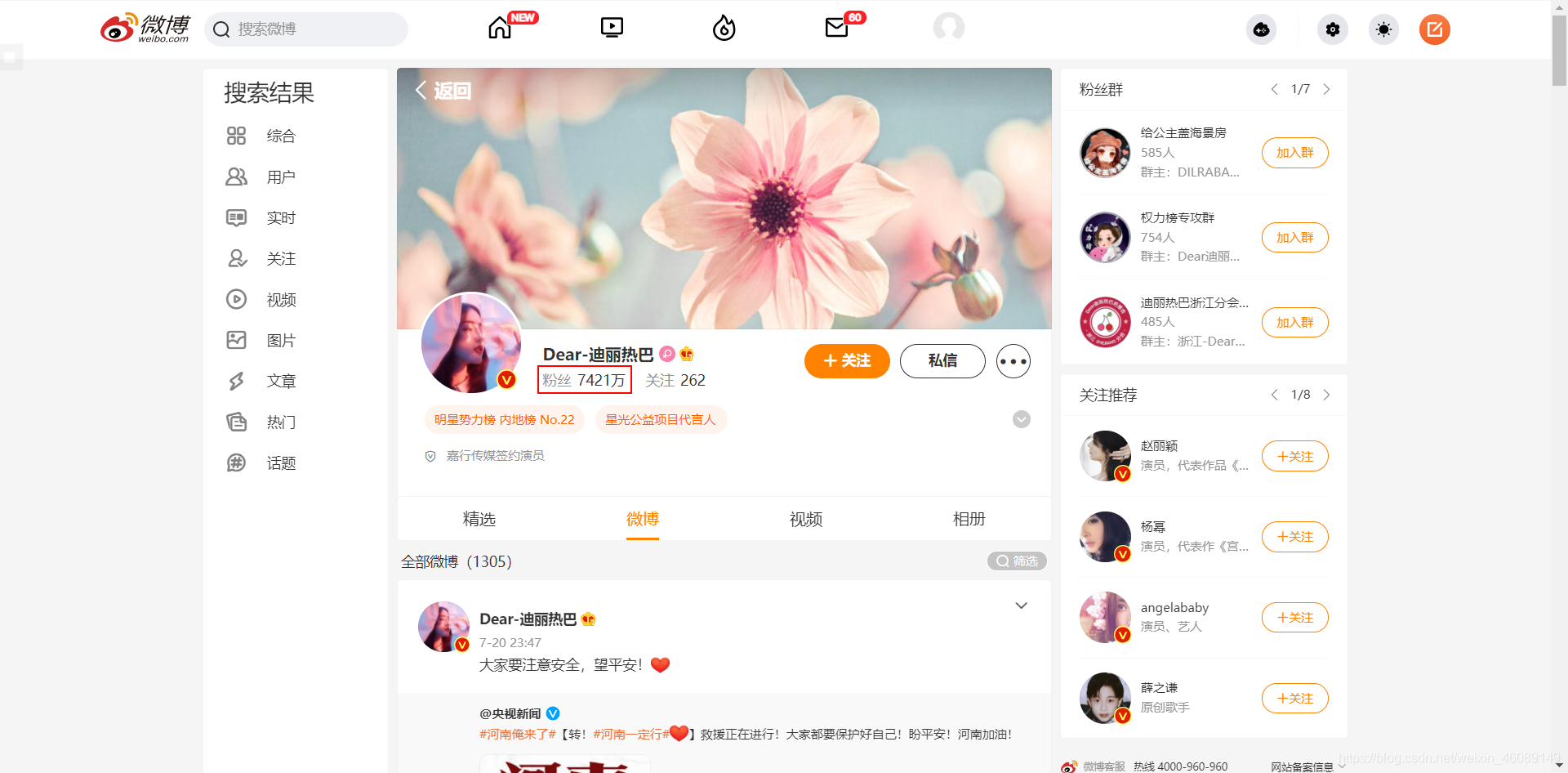
點擊熱巴的粉絲,然后F12開發者模式,然后重繪,依次點擊Network -> XHR -> friends?relate=fans... -> Preview, 你就會發現,熱巴的粉絲的賬戶資訊(uid,性別,個性簽名, 認證資訊,所在地區等等)
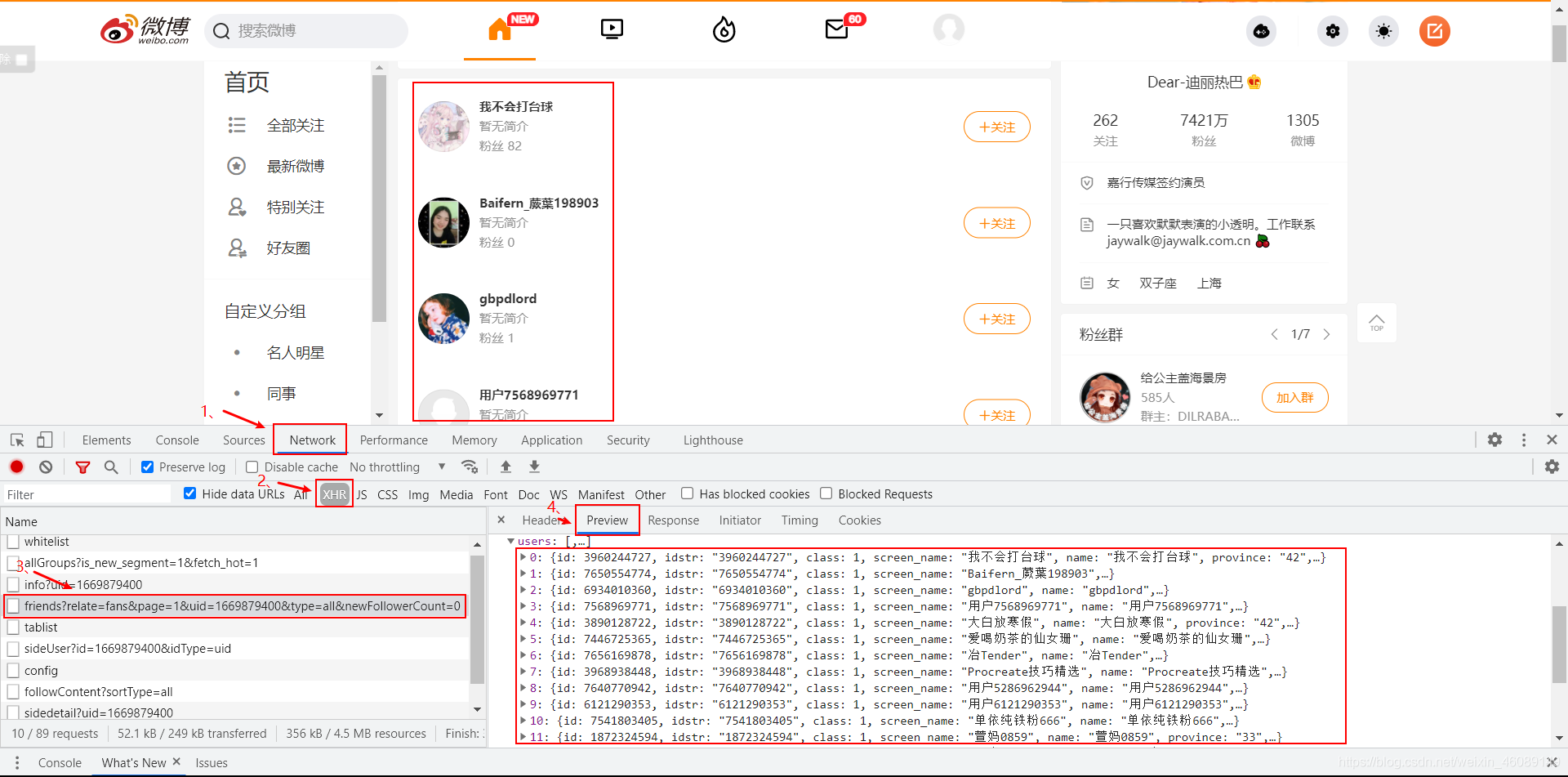
我給你們摘出來了請求但這個只是一頁的,想獲取所有的那就繼續往下看吧!
二、介面分析
url分析
https://www.weibo.com/ajax/friendships/friends?relate=fans&page=1&uid=1669879400&type=all&newFollowerCount=0
很明顯,他有兩個引數:
- page
這個引數掌管著頁數,想要獲得多頁的資料那就必須改變它, - uid
這個引數掌管著你要獲取粉絲和關注的博主的id,也就是用戶id
如果你能掌管好這兩個引數,那資料不就是手到擒來嘛!
回傳資料分析
是get請求,回傳資料格式是json格式,編碼為utf-8
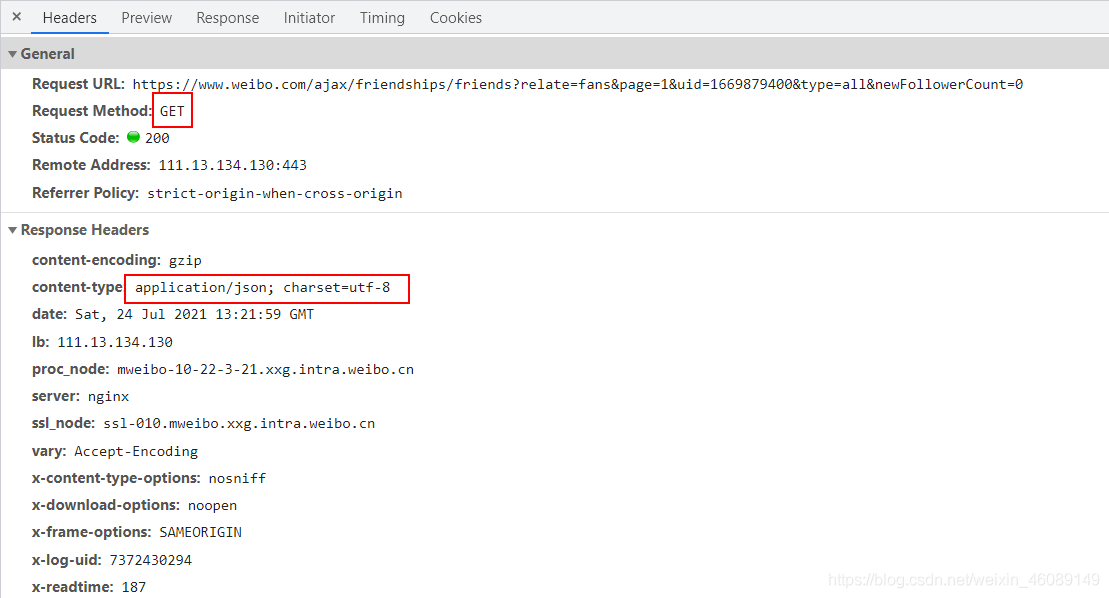
突然發現這幾次實戰請求方式都是GET請求,這可不行,下下期吧,我出一期POST請求的,也讓大家看看POST和GET有啥區別,
回歸正題~下一步就是撰寫代碼了,
三、撰寫代碼
知道了url規則,以及回傳資料的格式,那現在咱們的任務就是構造url然后請求資料
uid不是問題,那怎么知道他有多少頁呢
這個簡單:
第一頁
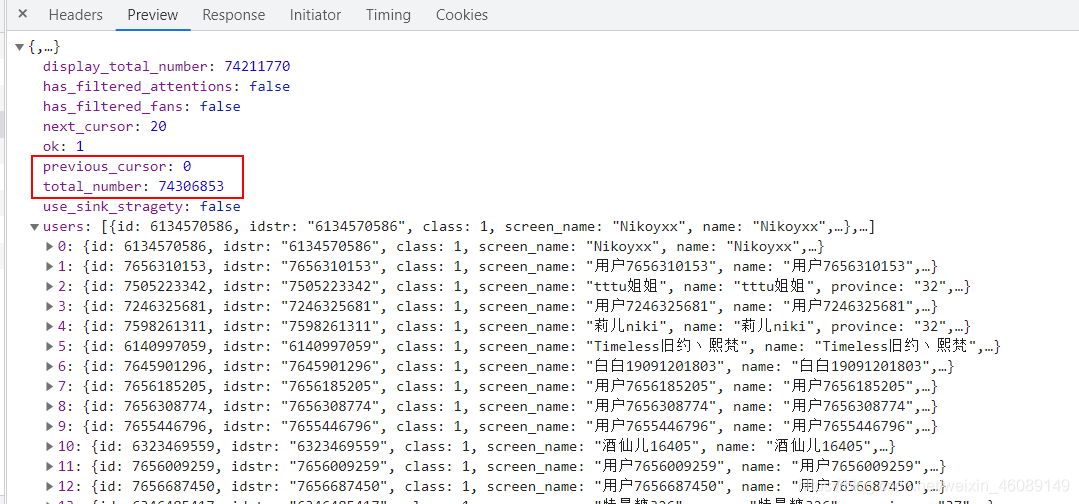
第二頁
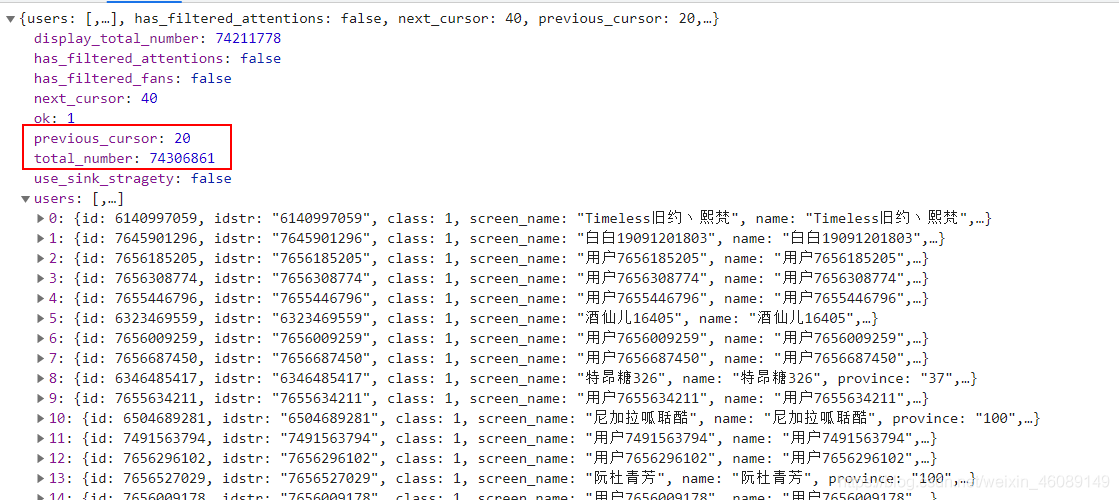
發現沒,previous_cursor的數量加了20,而咱們請求一頁資料回傳的用戶的數量正好是20個,totao_number對應的是該博主總粉絲數量,知道這兩點,那咱們不就好辦了,最大頁數不就得是total_number/20,不能整除就加一,最后也就是
?
t
o
t
a
l
_
n
u
m
b
e
r
20
?
\lceil \frac{total\_number}{20} \rceil
?20total_number??這個都懂吧,
uid = ['1669879400']
for id in uid:
# 先獲取總的粉絲數量
url = "https://www.weibo.com/ajax/friendships/friends?relate=fans&page={}&uid={}&type=all&newFollowerCount=0"
html = get_html(url.format(1, id))
response = json.loads(html)
total_number = response['total_number']
# 然后依次爬取每一頁的資料
for page in range(1, math.ceil(total_number/20) + 1):
html = get_html(url.format(page, id))
只要在uid這個串列里添加用戶id,這樣就可以實作多個用戶粉絲資料的抓取了,
對于每個url我們都要去用requests庫中的get方法去請求資料:
所以我們為了方便就把請求網頁的代碼寫成了函式get_html(url),傳入的引數是url回傳的是請求到的內容,
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Referer": "https://weibo.com"
}
cookies = {
"cookie": "你的cookie"
}
response = requests.get(url, headers=headers, cookies=cookies)
time.sleep(5) # 加上5s 的延時防止被反爬
return response.text
注意這里一定要把你的cookie替換掉,不然請求不到內容,
cookies獲取方式
獲取資料
將獲得的資料格式化為json格式的資料,然后提前他的粉絲的資訊
response = json.loads(html)
fans_list = response['users']
data = {} # 創建一個字典存放資料
for fan in fans_list:
data['uid'] = fan['id'] # 用戶id
data['screen_name'] = fan['screen_name'] # 用戶昵稱
data['description'] = fan['description'] # 個性簽名
data['gender'] = fan['gender'] # 性別
data['followers_count'] = fan['followers_count'] # 粉絲的粉絲數量
data['friends_count'] = fan['friends_count'] # 粉絲的關注數量
data['statuses_count'] = fan['statuses_count'] # 粉絲的博文數量
# 還有很多資訊可以得到,我這里就不再舉例子了
保存資料
封裝了一個函式:
def save_fans_data(data):
title = ['screen_name', 'description', 'followers_count', 'friends_count', 'statuses_count', 'gender', 'verified', 'verified_reason', 'birthday', 'created_at', 'sunshine_credit', 'company', 'school']
with open("fans_data.csv", "a", encoding="utf-8", newline="")as fi:
fi = csv.writer(fi)
fi.writerow([data[k] for k in title])
再來看關注
你可以先去自己看一下,是不是和爬取粉絲資料的方式一樣呀,自己嘗試著撰寫一下代碼吧~
完整代碼
# -*- coding:utf-8 -*-
# @time: 2021/7/24 21:52
# @Author: 韓國麥當勞
# @Environment: Python 3.7
import json
import requests
import csv
import time
import math
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Referer": "https://weibo.com"
}
cookies = {
"cookie": "你的cookie"
}
response = requests.get(url, headers=headers, cookies=cookies)
time.sleep(5) # 加上5s 的延時防止被反爬
return response.text
def save_fans_data(data):
title = ['uid', 'id', 'screen_name', 'description', 'followers_count', 'friends_count', 'statuses_count', 'gender']
with open("fans_data.csv", "a", encoding="utf-8", newline="")as fi:
fi = csv.writer(fi)
fi.writerow([data[k] for k in title])
def save_followers_data(data):
title = ['uid', 'id', 'screen_name', 'description', 'followers_count', 'friends_count', 'statuses_count', 'gender']
with open("followers_data.csv", "a", encoding="utf-8", newline="")as fi:
fi = csv.writer(fi)
fi.writerow([data[k] for k in title])
def get_fans_data(id):
# 先獲取總的粉絲數量
url = "https://www.weibo.com/ajax/friendships/friends?relate=fans&page={}&uid={}&type=all&newFollowerCount=0"
html = get_html(url.format(1, id))
response = json.loads(html)
total_number = response['total_number']
# 然后依次爬取每一頁的資料
for page in range(1, math.ceil(total_number/20) + 1):
html = get_html(url.format(page, id))
response = json.loads(html)
fans_list = response['users']
data = {} # 創建一個字典存放資料
for fan in fans_list:
data['uid'] = id
data['id'] = fan['id'] # 用戶id
data['screen_name'] = fan['screen_name'] # 用戶昵稱
data['description'] = fan['description'] # 個性簽名
data['gender'] = fan['gender'] # 性別
data['followers_count'] = fan['followers_count'] # 粉絲的粉絲數量
data['friends_count'] = fan['friends_count'] # 粉絲的關注數量
data['statuses_count'] = fan['statuses_count'] # 粉絲的博文數量
# 還有很多資訊可以得到,我這里就不再舉例子了
save_fans_data(data)
def get_followers_data(id):
# 先獲取總的關注的數量
url = "https://www.weibo.com/ajax/friendships/friends?page={}&uid={}"
html = get_html(url.format(1, id))
response = json.loads(html)
total_number = response['total_number']
# 然后依次爬取每一頁的資料
for page in range(1, math.ceil(total_number / 20) + 1):
html = get_html(url.format(page, id))
response = json.loads(html)
fans_list = response['users']
data = {} # 創建一個字典存放資料
for fan in fans_list:
data['uid'] = id
data['id'] = fan['id'] # 用戶id
data['screen_name'] = fan['screen_name'] # 用戶昵稱
data['description'] = fan['description'] # 個性簽名
data['gender'] = fan['gender'] # 性別
data['followers_count'] = fan['followers_count'] # 關注的粉絲數量
data['friends_count'] = fan['friends_count'] # 關注的關注數量
data['statuses_count'] = fan['statuses_count'] # 關注的博文數量
# 還有很多資訊可以得到,我這里就不再舉例子了
save_followers_data(data)
if __name__ == '__main__':
uid = ['1669879400'] # 如果想獲取多個人的粉絲關注資訊,就在后面依次加上uid
for id in uid:
get_fans_data(id)
get_followers_data(id)
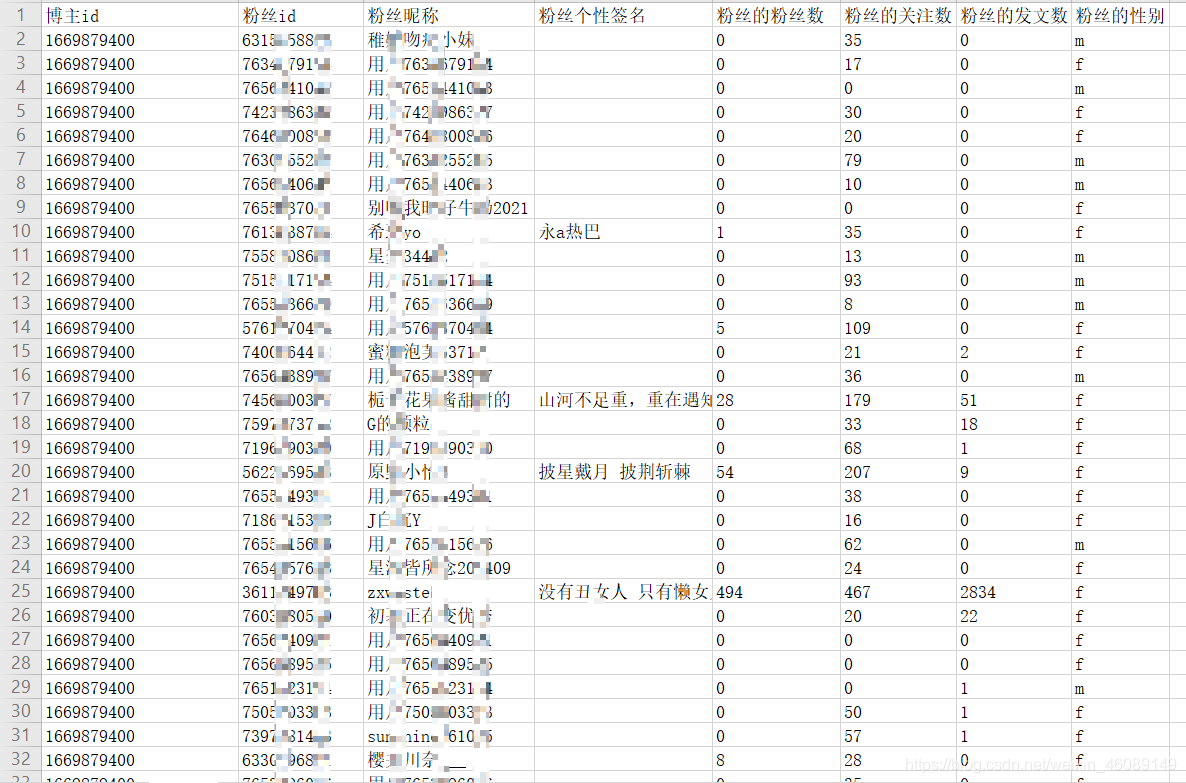
獲得的部分資料截圖(以前是我不好,從今以后獲得的資料只要是涉及到隱私的全部打碼處理),
下期預告:
百度指數對于一個關鍵詞的搜索指數和咨詢指數的抓取,提前劇透一下:js加密資料喲~
歡迎一鍵三連哦!
還想看哪個網站的爬蟲?歡迎留言,說不定下次要分析的就是你想要看的!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290272.html
標籤:python
上一篇:Python學習第一周總結