資料爬取流程
指定url
發起請求
獲取回應資料
資料決議
持久化存盤
資料決議分類
正則
bs4
xpath
資料決議原理概述
決議的區域的文本內容都會在標簽之間或標簽對應的屬性中進行存盤
1、進行指定標簽的定位
2、標簽或者標簽對應的屬性中存盤的資料值進行提取(決議)
正則決議案例
正則決議案例需要用到正則運算式爬取圖片,如果對正則運算式不了解的,可以查看我之前的文章,Python正則運算式這次爬取糗事百科中的熱圖,糗事百科
我們打開開發者工具,可以看出來圖片在 < div class=“thumb” > 標簽中,src=后面就是圖片的地址,因此我們用到正則運算式去獲取網址:
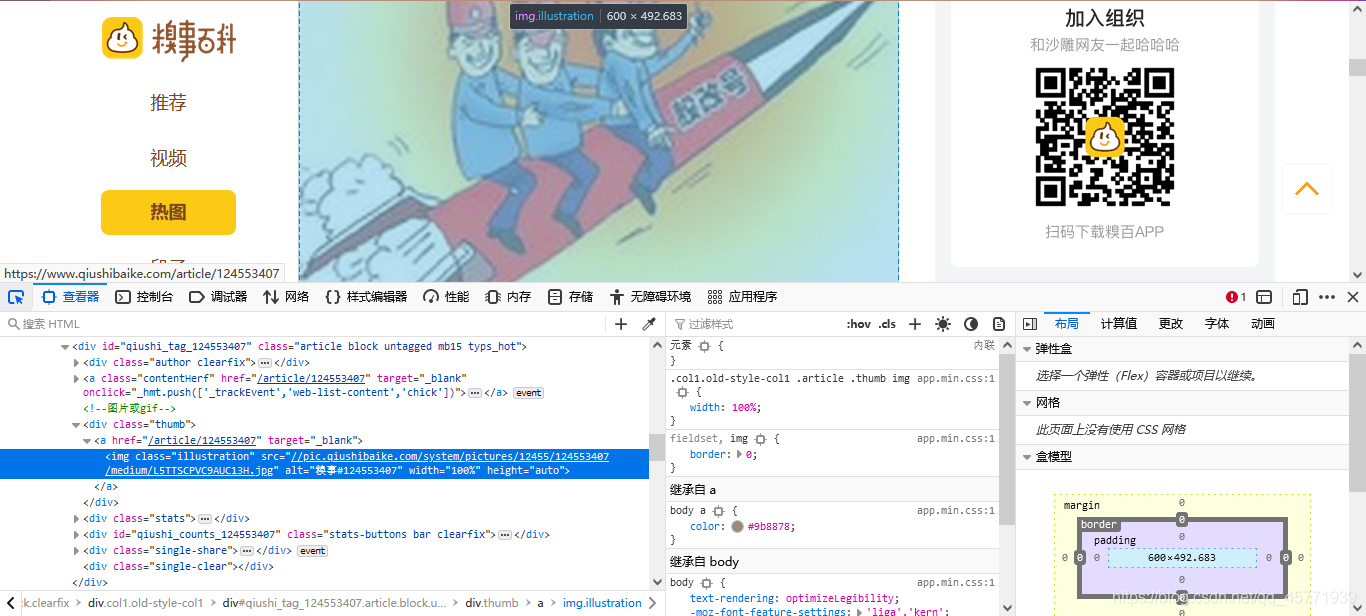
pattenr=r’< div class=“thumb”>.?<img src="(.?)" alt.*?’
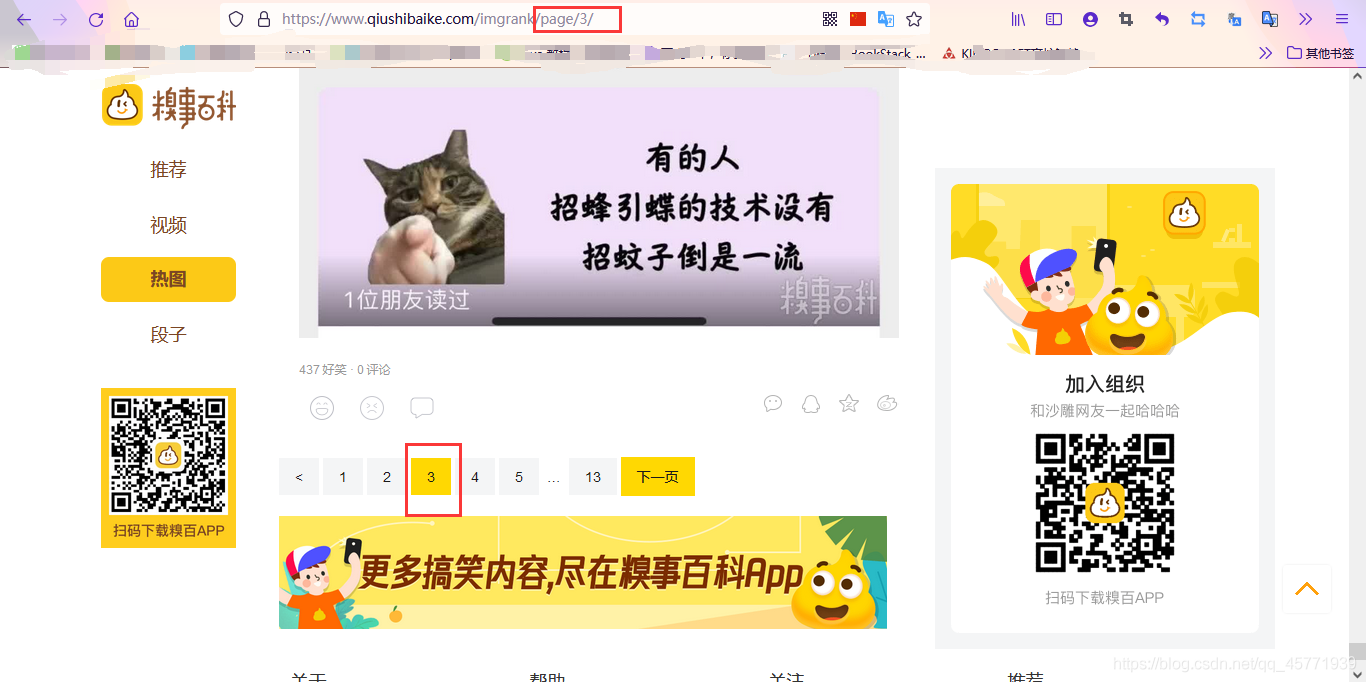
對于熱圖的第i頁,網址為:
https://www.qiushibaike.com/imgrank/page/ + i
因此我們就可以獲得每一頁的網址,從而可以爬取多頁的圖片
import requests
import re
import os
#獲得十頁的圖片
for i in range(1,11):
#每頁的網址后面只有頁數
url='https://www.qiushibaike.com/imgrank/page/'+str(i)
#UA偽裝
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0"
}
#創建圖片存盤的檔案夾
if not os.path.exists('./糗圖'):
os.mkdir('./糗圖')
#正則匹配
pattenr=r'<div class="thumb">.*?<img src="(.*?)" alt.*?'
page_text=requests.get(url=url,headers=header).text
imag_list=re.findall(pattenr,page_text,re.S)
for src in imag_list:
src='https:'+src
#獲取圖片的二進制資料
imag_data=requests.get(src).content
#圖片的命名
imag_name=src.split('/')[-1]
imag_path=r'./糗圖/'+imag_name
with open(imag_path,'wb') as fp:
fp.write(imag_data)
print(imag_name,"下載成功")
print(imag_list)
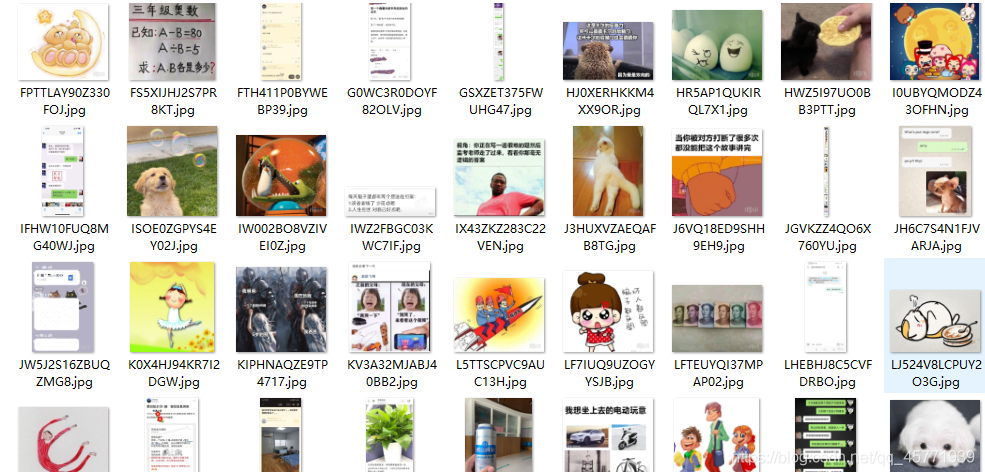
然后就獲得了爬取的圖片了
bs4
bs4進行資料決議
資料決議的原理:
1、標簽定位
2、提取標簽、標簽屬性中存盤的資料值
bs4資料決議的原理:
1.實體化一個BeautifulSoup物件,并且將頁面原始碼資料加載到該物件中
2.通過呼叫BeautifulSoup物件中相關的屬性或者方法進行標簽定位和資料提取
如何實體化BeautifulSoup物件:
from bs4 import BeautifulSoup
1.將本地的html檔案中的資料加載到該物件中
fp = open(’./test.html’,‘r’,encoding=‘utf-8’)
soup = BeautifulSoup(fp,‘lxml’)
2.將互聯網上獲取的頁面原始碼加載到該物件中
page_text = response.text
soup = BeatifulSoup(page_text,‘lxml’)
提供的用于資料決議的方法和屬性:
-soup.tagName:回傳的是檔案中第一次出現的tagName對應的標簽
soup.find():
find(‘tagName’):等同于soup.div
屬性定位:
soup.find(‘div’,class_/id/attr=’ ‘)
soup.find_all(‘tagName’):回傳符合要求的所有標簽(串列)
select:
select(‘某種選擇器(id,class,標簽…選擇器)’),回傳的是一個串列,
層級選擇器:
soup.select(’.tang > ul > li > a’):>表示的是一個層級
soup.select(’.tang > ul a’):空格表示的多個層級
獲取標簽之間的文本資料:
soup.a.text/string/get_text()
text/get_text():可以獲取某一個標簽中所有的文本內容
string:只可以獲取該標簽下面直系的文本內容
獲取標簽中屬性值:
soup.a[‘href’]
案例(爬取三國演義):
import requests
from bs4 import BeautifulSoup
#需求:爬取三國演義小說所有的章節標題和章節內容http://www.shicimingju.com/book/sanguoyanyi.html
if __name__ == "__main__":
#對首頁的頁面資料進行爬取
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0"
}
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=headers).content.decode('utf-8')
#在首頁中決議出章節的標題和詳情頁的url
#1.實體化BeautifulSoup物件,需要將頁面原始碼資料加載到該物件中
soup = BeautifulSoup(page_text,'lxml')
#決議章節標題和詳情頁的url
li_list = soup.select('.book-mulu > ul > li')
fp = open('./sanguo.txt','w',encoding='utf-8')
for li in li_list:
title = li.a.string
detail_url = 'http://www.shicimingju.com'+li.a['href']
#對詳情頁發起請求,決議出章節內容
detail_page_text = requests.get(url=detail_url,headers=headers).content.decode('utf-8')
#決議出詳情頁中相關的章節內容
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',class_='chapter_content')
#決議到了章節的內容
content = div_tag.text
fp.write(title+':'+content+'\n')
print(title,'爬取成功!!!')
xpath決議
xpath決議原理:
1.實體化一個etree的物件,且需要將被決議的頁面原始碼資料加載到該物件中,
2.呼叫etree物件中的xpath方法結合著xpath運算式實作標簽的定位和內容的捕獲,
如何實體化一個etree物件:from lxml import etree
1.將本地的html檔案中的原始碼資料加載到etree物件中:
etree.parse(filePath)
2.可以將從互聯網上獲取的原始碼資料加載到該物件中
etree.HTML(‘page_text’)
xpath(‘xpath運算式’)
xpath運算式:
/:表示的是從根節點開始定位,表示的是一個層級,
//:表示的是多個層級,可以表示從任意位置開始定位,
屬性定位://div[@class=’ '] tag[@attrName=“attrValue”]
索引定位://div[@class=" "]/p[3] 索引是從1開始的,
取文本:
/text() 獲取的是標簽中直系的文本內容
//text() 標簽中非直系的文本內容(所有的文本內容)
取屬性:
/@attrName ==>img/src
xpath實體1——爬取58二手房
首先打開58二手房網站,58二手房,打開開發者工具,可以知道房源資訊在
 Gecko/20100101 Firefox/90.0"
}
url='https://bj.58.com/ershoufang/'
page_text=requests.get(url=url,headers=headers).text
#決議資料
tree=etree.HTML(page_text)
div_list=tree.xpath('//div[@class="property"]//div[@class="property-content-title"]/h3/text()')
print(div_list)
for div in div_list:
print(div)
 注意:該網站多次訪問需要驗證
注意:該網站多次訪問需要驗證
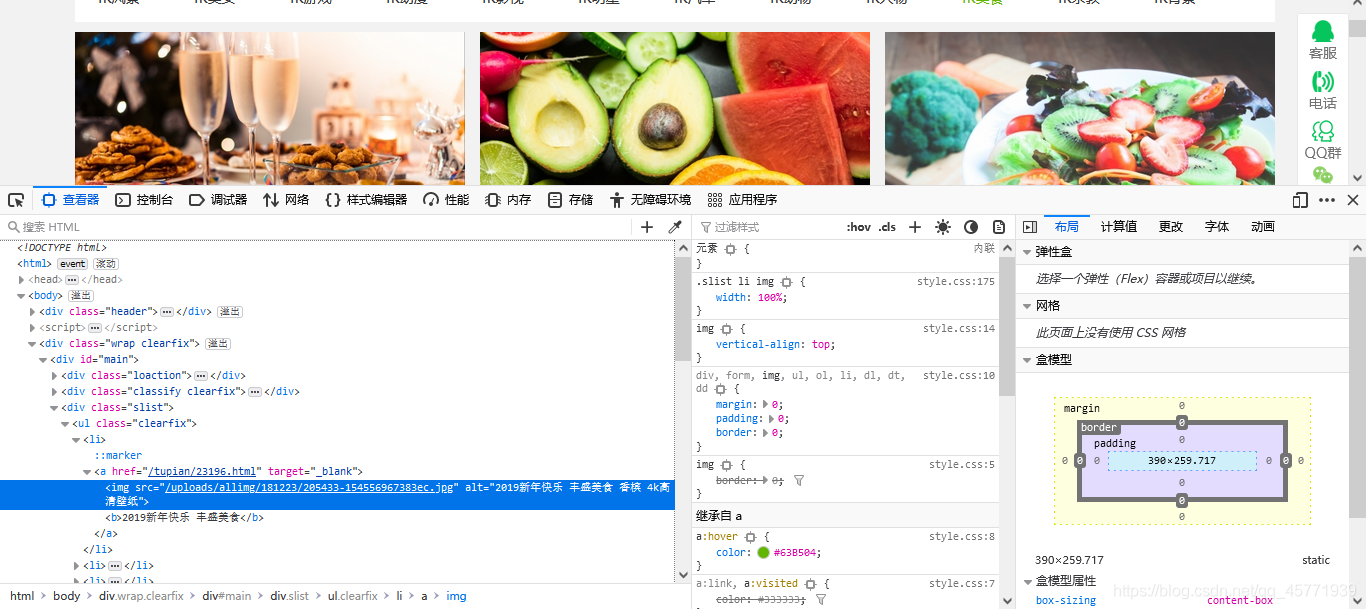
xpath實體2——4K圖片爬取
首先廢話少說,上網站:https://pic.netbian.com/4kmeishi/index.html
打開開發者工具可以知道圖片在每個li標簽中,可以從li標簽中的a標簽獲得圖片的名稱和鏈接,從而爬取圖片,
import requests
from lxml import etree
import os
#UA偽裝
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0"
}
#創建存盤路徑
if not os.path.exists(r"./美食圖片"):
os.mkdir(r"./美食圖片")
url='https://pic.netbian.com/4kmeishi/index.html'
response=requests.get(url=url,headers=headers)
response.encoding='gbk'
page_text=response.text
#決議資料
tree=etree.HTML(page_text)
li_list=tree.xpath('//div[@class="slist"]/ul/li')
for li in li_list:
#獲得圖片的名稱
alt=li.xpath('.//a//@alt')[0]
#獲得圖片的url
src=li.xpath("./a/img/@src")[0]
img_name=alt+'.jpg'
img_src='https://pic.netbian.com/'+src
img_data=requests.get(url=img_src,headers=headers).content
img_path=r'美食圖片'+img_name
#存盤圖片
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下載成功')


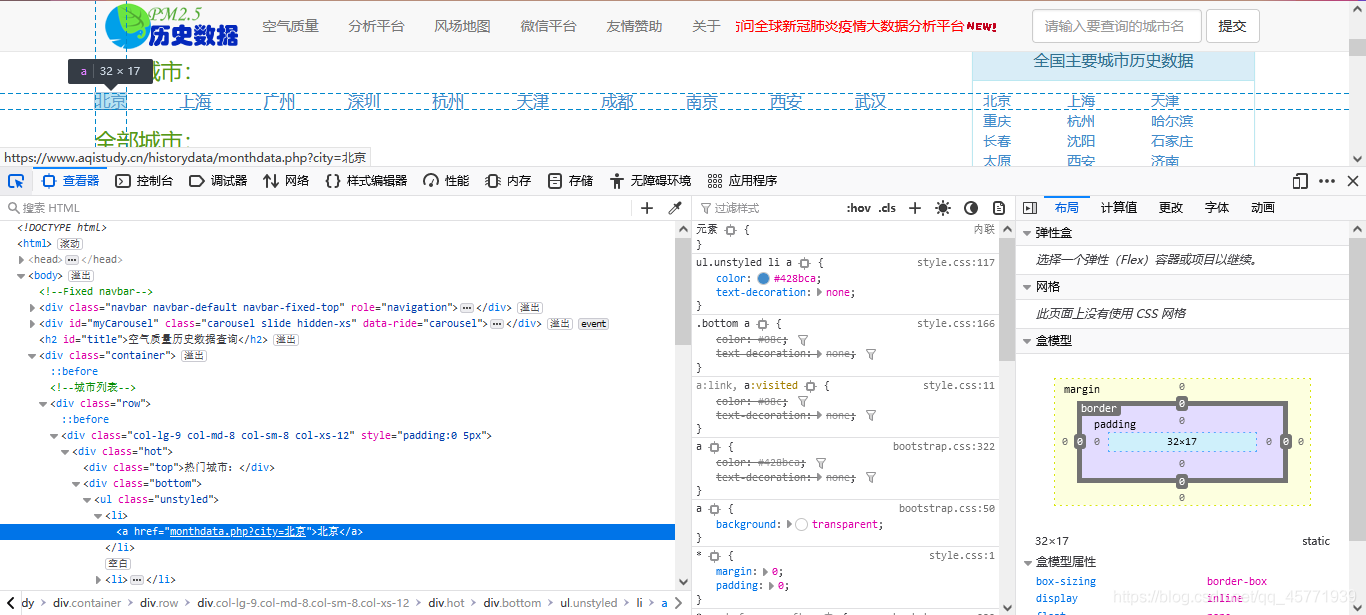
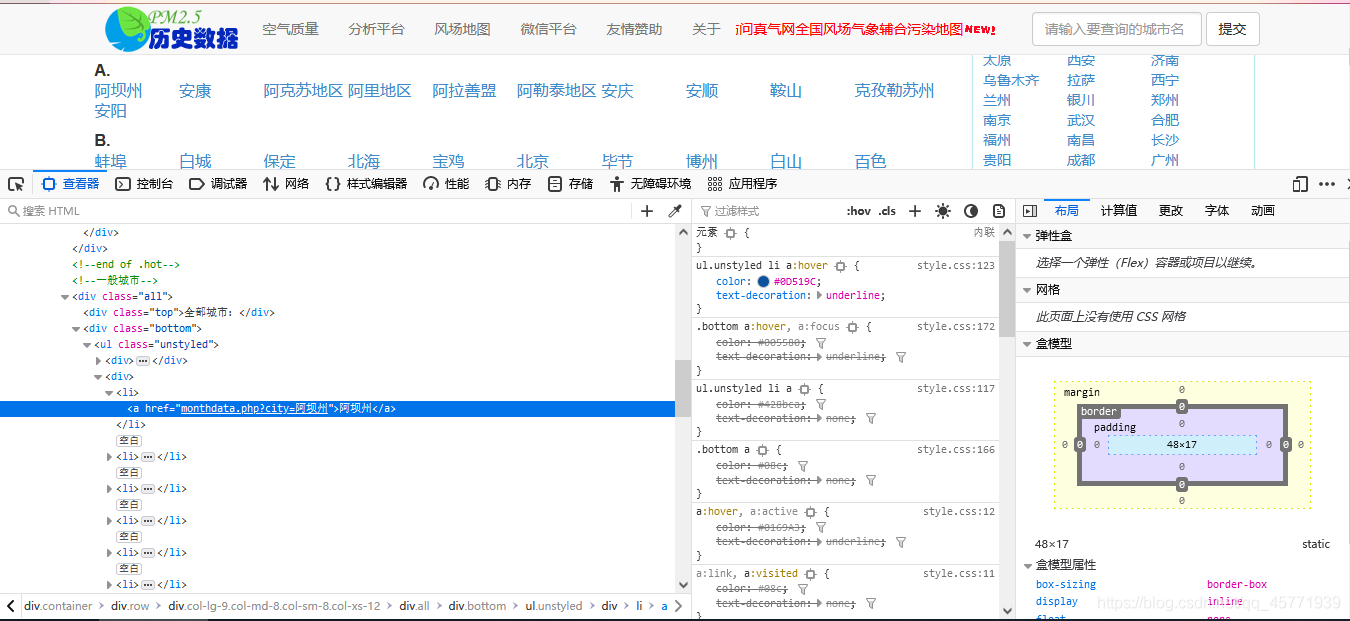
xpath實體3——爬取中國城市名稱
網站:https://www.aqistudy.cn/historydata/,老規矩,打開開發者工具,可以知道熱門城市在div:hot的 li 標簽中,而全部城市在div:all的 li 標簽中,這樣就很容易決議資料了,
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0"
}
url='https://www.aqistudy.cn/historydata/'
page_text=requests.get(url=url,headers=headers).text
tree=etree.HTML(page_text)
hotcity_list=tree.xpath('//div[@class="hot"]//div[@class="bottom"]//li')
print("熱門城市:")
for hotcity in hotcity_list:
hot_name=hotcity.xpath('./a/text()')
print(hot_name[0])
all_list=tree.xpath('//div[@class="all"]//div[@class="bottom"]//li')
print('全部城市:')
for all in all_list:
all_name=all.xpath('./a/text()')
print(all_name[0])

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290273.html
標籤:python