大家好,歡迎來到二哥的爬蟲頻道,本次二哥準備爆更三天給大家帶來Scrapy教程,記得三連呦~
一、認識Scrapy
Scrapy是一個為了爬取網站資料,提供結構性資料而撰寫的應用框架,使用Scrapy時,我們使用少量的代碼就能實作快速的抓取,
Scrapy爬取流程
Scrapy的爬取流程圖如下所示:
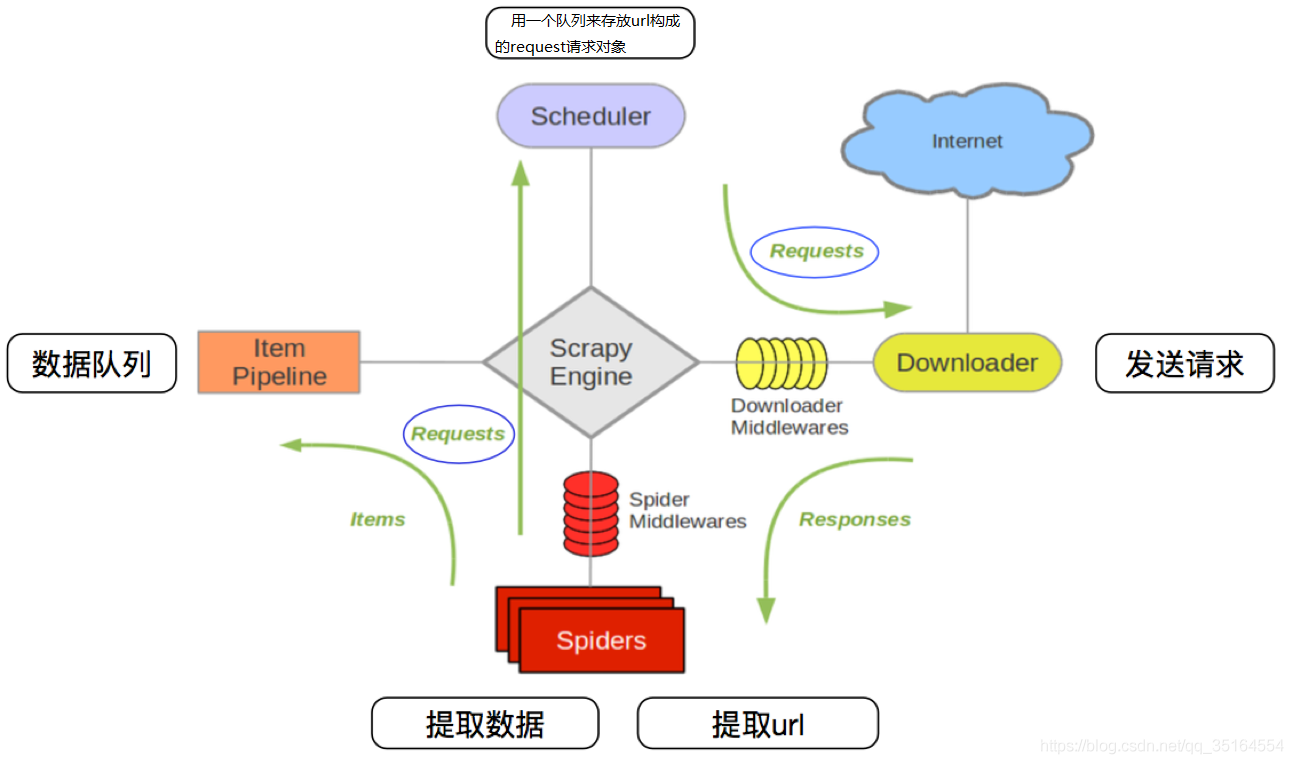
Scrapy的三個重要內置物件
- request請求物件
- response回應物件
- item資料物件
流程圖解釋
- 引擎(Scrapy Engine):負責資料和信號在整個系統中的傳遞(核心)
- 調度器(Scheduler):實作一個佇列,存放引擎發過來的requests請求物件
- 下載器(Downloader):發送引擎發過來的requests請求,下載網頁內容, 并將網頁內容回傳
- 爬蟲(Spider):處理引擎發過來的response,提取自己想要的資訊;提取url,并交給引擎
- 管道(Pipeline):處理引擎傳遞過來的資料,進行資料持久化(例:存盤資料到表格/資料庫中)
- 下載中間件(Downloader Middleware):可以自定義的下載擴展,比如設定User_Agent, Proxy
- 爬蟲中間件(Spider Middleware):可以自定義request請求和進行response過濾,類似下載中間件
Scrapy的作業流程如下
- 爬蟲——>URL(Requests)——> 爬取中間件——>引擎——>調度器
對應圖中(中間的綠色直線):Spiders將需要發送請求的Requests經過ScrapyEngine交給Scheduler
- 調度器——>Requests——>引擎——>下載中間件——>下載器
對應圖中(右上角的綠色線):Scheduler處理后經過ScrapyEngine,Downloader Middlewares交給Downloader
- 下載器——>Reponses——>下載中間件——>引擎——>爬蟲中間件——爬蟲
對應圖中(右下角的綠色線):Downloader向互聯網發送請求,接收Reponses后經過ScrapyEngine,Spider Middlewares交給Spiders
- 爬蟲——>Reponses——>引擎——>管道(保存資料)
Spiders處理回傳到的Reponses,提取資料將資料通過ScrapyEngine交給ItemPipeline進行資料保存
- 當新的URL請求出現時,重復執行1234的程序,知道沒有請求,
二、使用Scrapy
創建Scrapy專案
- 安裝模塊:pip install scrapy
- 創建Scrapy專案:scrapy startproject 檔案夾名稱
創建完成后會生成如下圖所示的檔案目錄:
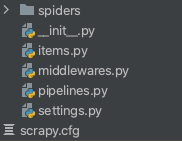
- scrapy.cfg:專案的組態檔
- items.py:專案的目標檔案
- pipelines.py:專案的管道檔案
- settings.py:專案的設定檔案
- spiders:存盤爬蟲代碼
創建爬蟲
創建好了專案之后,我們還需要創建爬蟲讓我們能夠在里面撰寫爬蟲代碼,步驟如下,
- cd到創建的檔案夾下
- 執行:scrapy genspider +<爬蟲名字> + <爬取的域名>
舉例:
cd Sp_1
scrapy genspider Cars_data 12365auto.com
執行完成后會在spiders檔案夾下出現爬蟲檔案,檔案內的格式如下:
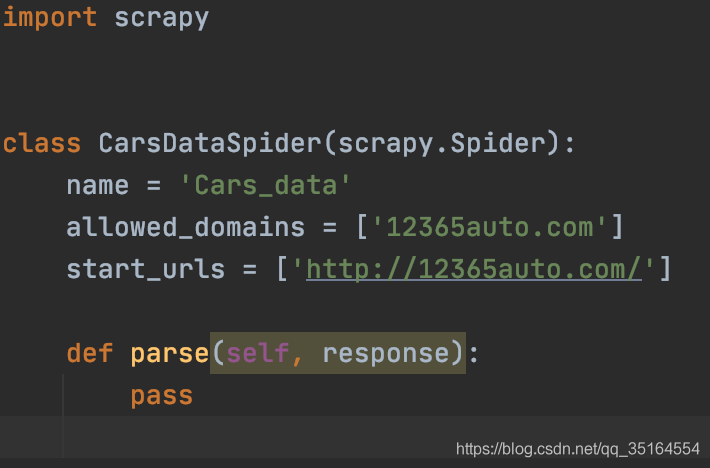
撰寫爬蟲
至此我們的準備作業就做好了,接下來就可以開始完善爬蟲了,
完善代碼(這里舉一個最簡單的小例子)
import scrapy
class CarsDataSpider(scrapy.Spider):
name = 'Cars_data'
allowed_domains = ['12365auto.com']
start_urls = ['http://12365auto.com/']
# 決議資料
def parse(self, response):
name_car = response.xpath(".//div[@class='in_cxsx_b'][1]/div[@class='in_wxc'][1]/dl[1]/dt/a/text()")
item = {}
item['name'] = name_car.extract()
yield item
在進行parse的時候,我們可以直接使用scrapy中的response物件進行Xpath,
需要注意的是response.xpath方法的回傳結果是一個類似list的型別,其中包含的是selector物件,操作和串列一樣,但是獲取結果的時候有一些額外的方法,
extract():回傳一個包含有字串的串列
extract_first():回傳串列中的第一個字串,串列為空沒有回傳None
代碼最后需要使用yield函式讓整個函式變成一個生成器
此時我們可以嘗試進行資料爬取了,在Terminal運行如下命令:
scrapy crawl name
注意:name是你創建爬蟲的名字,也就是爬蟲檔案中name=""中的內容
看到沒有報錯的長串輸出就證明運行成功了,
保存資料
保存資料的時候我們主要會使用pipeline來進行,
- 開啟pipeline
找到類似如下的代碼取消注釋(初始位置在65行左右):
ITEM_PIPELINES = {
'Sp_1.pipelines.Sp1Pipeline': 300,
}
- 運行
最終在terminal中運行如下腳本即可保存檔案為Json
scrapy crawl dmoz -o items.json
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290275.html
標籤:python