python-爬蟲專案<實作增加博客訪問量>
- 一、整體思路
- 二、獲取偽裝的header,
- 三、爬取代理IP
- 四、獲取目標URL
- 五、模擬訪問,增加訪問量!
- 六、驗證環節
- 七、使用方法以及結語
一、整體思路
??如題,通過這個專案實作的目標是增加博客訪問量的功能,那我們如何實作這個目標呢?
??訪問量就是我們通過瀏覽器或者手機APP將對應的文章點開,這樣的一個步驟,那我們是不是可以通過python模擬我們的行為,達到增加訪問量的效果呢?說干就干!我們沖!
??想要模擬我們的行為,那我們需要準備什么呢?首先對應的文章URL總是需要的吧?然后為了模仿瀏覽器的行為,也是為了告訴服務器我們是正常用戶我們是不是需要對請求包的header進行封裝呢?最后為了表現出不是同一個人在訪問,我們是不是應該封裝一個代理IP呢?
??到這里,我們整理一下我們的需求!1、目標URL;2、偽裝header;3、代理IP;4、模仿行為訪問,既然需求明確了,那我們就準備開始吧,
??123我們都得做,那我們先完成3吧,
二、獲取偽裝的header,
??通過網上瀏覽資訊,我們找到了這樣一個網址https://www.cnblogs.com/0bug/p/8952656.html#_label1,如下圖:

??不需要爬取,咱直接復制粘貼即可!
??在代碼的目錄下創建"User-Agent.txt.txt"檔案,然后將下列內容粘貼進去即可:
Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19
Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30
Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1
Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0
Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0
Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36
Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19
Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3
Mozilla/5.0 (iPod; U; CPU like Mac OS X; en) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/3A101a Safari/419.3
三、爬取代理IP
??通過網上瀏覽資訊,我們找到了這樣一個網址https://www.kuaidaili.com/free/inha/,如下圖:
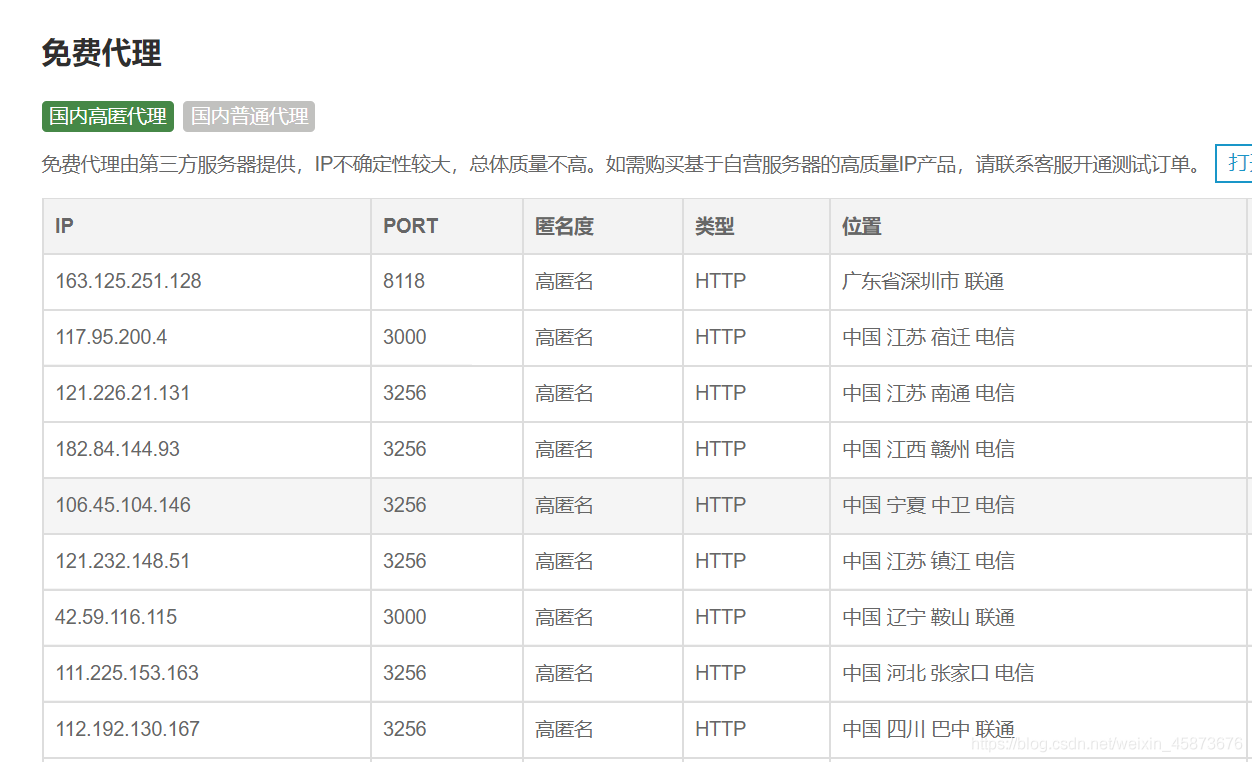
??直接爬取他的IP不就可以了嗎?說干就干!!
??原始碼如下:
import requests
from bs4 import BeautifulSoup
import codecs
from tqdm import tqdm
import random
import re
def main(url):
# 獲取代理header和ip
header = head()
ip = ipProxies()
# 爬取網頁
html = getURL(url,header,ip)
# 提取內容
result = getResult(html)
# 保存結果
saveResult(result)
def ipProxies():
f = codecs.open("IP.txt", "r+", encoding="utf-8")
ip = f.readlines()
f.close()
IP = {'http':random.choice(ip)[-2::-1][::-1]}
print("本次使用IP(proxies)為:",IP['http'])
return IP
def head():
f = codecs.open("User-Agent.txt","r+",encoding="utf-8")
head = f.readlines()
f.close()
header = {"User-Agent":random.choice(head)[-3::-1][::-1]}
print("本次使用header(User-Agent)為:", header["User-Agent"])
return header
def getURL(url,header,ip):
html = ""
try:
response = requests.get(url=url,headers=header,proxies=ip)
html = response.text
except:
print("url出錯啦!")
return html
def getResult(html):
# 決議網頁內容
bs = BeautifulSoup(html,"html.parser")
# 正則匹配IP地址
pantter = '(([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){3}([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])'
# 搜索檔案得到結果
result = bs.find_all(text= re.compile(pantter))
return result
def saveResult(result):
f = codecs.open("IP.txt",'w+',encoding="utf-8")
for ip in tqdm(result,desc="內容爬取中",ncols=70):
f.write(ip)
f.write("\n")
f.close()
if __name__ == '__main__':
url = "https://www.kuaidaili.com/free/inha/"
print("-------------------開始爬取------------------------")
# 調取主函式
main(url)
print("-------------------爬取完成------------------------")
print("^-^結果存在于同本代碼目錄下的'IP.txt'檔案中^-^")
??代碼我就不過多解釋,若此代碼第一次不能運行,應該是你的沒有“IP.txt”檔案,
??解決辦法:在和本代碼的目錄下創建"IP.txt"檔案,然后將你本機的IP寫在這個txt檔案中即可,
四、獲取目標URL
??這個可以參考這篇文章:prthon-爬蟲實作爬取某用戶csdn博客所有文章鏈接
??在這里當然我們也會給出我們在這的代碼,原始碼如下:干!
import requests
import random
from bs4 import BeautifulSoup
import codecs
from tqdm import tqdm
import sys
def main(url):
# 獲取代理header和ip
header = head()
ip = ipProxies()
# 爬取網頁
html = getURL(url,header,ip)
# 提取內容
result = getResult(html)
# 保存結果
saveResult(result)
# 獲取隨機IP
def ipProxies():
f = codecs.open("IP.txt", "r+", encoding="utf-8")
ip = f.readlines()
f.close()
IP = {'http':random.choice(ip)[-2::-1][::-1]}
print("本次使用IP(proxies)為:",IP['http'])
return IP
# 獲取隨機header頭
def head():
f = codecs.open("User-Agent.txt","r+",encoding="utf-8")
head = f.readlines()
f.close()
header = {"User-Agent":random.choice(head)[-3::-1][::-1]}
print("本次使用header(User-Agent)為:", header["User-Agent"])
return header
# 獲取頁面
def getURL(url,header,ip):
html = ""
try:
response = requests.get(url=url,headers=header,proxies=ip)
html = response.text
except:
print("目標URL有誤")
return html
# 獲取所需要的頁面(HTML)檔案
def getResult(html):
result = []
bs = BeautifulSoup(html,"html.parser")
for link in bs.find_all('a'):
getlink = link.get('href')
try:
if ("comments" not in getlink) and("/article/details/" in getlink) and ("blogdevteam" not in getlink):
if (getlink not in result):
result.append(getlink)
except TypeError as e:
print("這是警告,只是小例外,罩得住!還在爬取,別擔心!沖!!!!")
continue
return result
# 保存爬取結果URL
def saveResult(result):
f = codecs.open('url.txt','w+',encoding='utf-8')
for link in tqdm(result,desc="本頁面爬取中",ncols=70):
f.write(link)
f.write("\n")
f.close()
# 函式入口
if __name__ == '__main__':
# 獲取用戶所需爬取的頁面
url = str(input("請輸入需要爬取的URL:"))
# 判斷用戶輸入是否合法
if "blog.csdn.net" not in url:
print("請輸入合法的CSDN博客主頁鏈接")
sys.exit()
print("-------------------開始爬取------------------------")
# 調取主函式
main(url)
print("-------------------爬取完成------------------------")
print("^-^結果存在于同本代碼目錄下的'url.txt'檔案中^-^")
??到這里,我們的準備作業已經齊活啦!運行完本代碼以后,你的目前路徑有如下圖的5個檔案:
??如果沒有,那前邊肯定有問題,不用接著做了,
五、模擬訪問,增加訪問量!
??準備已經做好啦,成敗在此一舉!
??別擔心,既然文章已經出現在這里了,那肯定是成功了,
??廢話不多說,上碼:
import requests
import codecs
from tqdm import tqdm
import random
import time
def main():
# 獲取代理header和ip
header = head()
ip = ipProxies()
# 獲取目標URL,隨機訪問一篇博客
url = getURL()
# 訪問URL
return askURL(url,header,ip)
def ipProxies():
f = codecs.open("IP.txt", "r+", encoding="utf-8")
ip = f.readlines()
f.close()
IP = {'http':random.choice(ip)[-2::-1][::-1]}
print("本次使用IP(proxies)為:",IP['http'])
return IP
def head():
f = codecs.open("User-Agent.txt","r+",encoding="utf-8")
head = f.readlines()
f.close()
header = {"User-Agent":random.choice(head)[-3::-1][::-1]}
print("本次使用header(User-Agent)為:", header["User-Agent"])
return header
def getURL():
f = codecs.open("url.txt","r+",encoding="utf-8")
URL = f.readlines()
f.close()
url = random.choice(URL)[-2::-1][::-1]
print("本次使用訪問的鏈接為:", url)
return url
def askURL(url,header,ip):
try:
request = requests.get(url=url,headers=header,proxies=ip)
print(request)
time.sleep(5)
except:
print("本次訪問失敗!")
if __name__ == '__main__':
# 獲取模擬訪問的次數
num = int(input("請輸入模擬訪問次數:"))
for num in tqdm(range(num),desc="正在訪問",ncols=70):
print("這是第"+str(num+1)+"次訪問")
main()
??到這里本專案的目標我們已經實作了!接下里就是緊張刺激的驗證環節,
六、驗證環節
??最終運行結果如下:
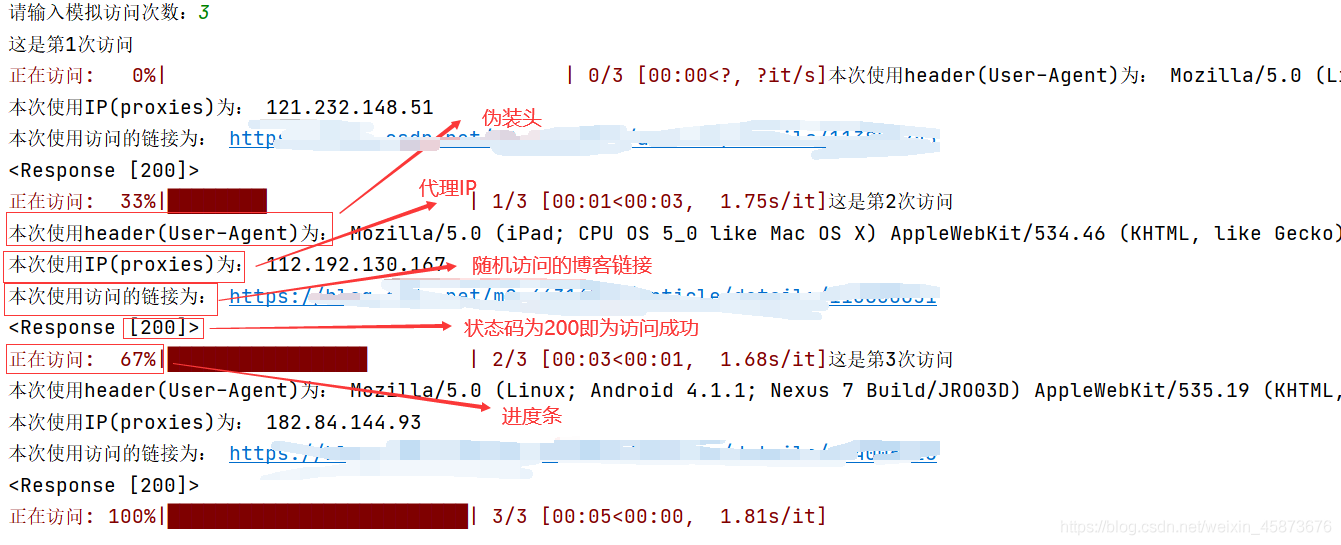
??由此,本專案功成!結束!
七、使用方法以及結語
??使用方法很簡單,把他們全部放在一個檔案夾里面就行,
??歡迎關注,點贊,與我交流一同學習python、Django、爬蟲、docker、路由交換、web安全等一切東西,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290276.html
標籤:python