requests的學習筆記
requests庫自動爬取HTML頁面,自動網路請求提交
此博客為中國大學MOOC北京理工大學《Python網路爬蟲與資訊提取》的學習筆記
requests庫的安裝
requests庫是Python的第三方庫,是目前公認的,爬取網頁最好的第三方庫,關于requests庫的更多資訊,可以在www.python-requests.org網站上獲得,
安裝方法:用管理員權限啟動command控制臺,輸入 pip install requests ,按下回車;
驗證方法:
啟動IDLE
import requests
r = requests.get("http://www.baidu.com")
r.status_code
運行顯示200即為成功
requests庫的方法
requests庫共7個主要方法

requests庫的request()方法
requests.request(method,url,**kwargs)
1.method:請求方式,對應get/put/post等7種(以上圖片上或http所對應的請求功能+options)
2. url: 擬獲取頁面的url鏈接
3. **kwargs:控制訪問引數,均為可選項(13個)
①params:字典或位元組序列,作為引數增加到url中(對url進行修改)
kv ={'key1':'value1','key2':'value2'}
r=requests.request("GET","http://python123.io/ws",params=kv)
print(r.url)
②data:字典,位元組序列或檔案物件,作為request的內容 向服務器提供或提交資源時使用
r=requests.request("POST","http://python123.io/ws",data=kv)
body="主體內容"
r=requests.request("POST","http://python123.io/ws",data=kv)
③json:JSON格式資料,作為request的內容 向服務器提供或提交資源時使用
kv ={'key1':'value1'}
r=requests.request('POST','http://python123.io/ws',json=kv)
④headers:字典,HTTP定制頭
hd={'user-agent':'Chrome/10'}
r=requests.request('POST','http://python123.io/ws',headers=hd)
⑤cookies:字典或CookieJar,request中的cookie
⑥auth:元祖,支持HTTP認證功能
⑦files:字典型別,傳輸檔案
fs={'file':open('data.xis','rb')}
r=requests.request('POST','http://python123.io/ws',files=fs)
⑧timeout:設定超時時間,以秒為單位
r=requests.request(“GET”,‘http://www.baidu.com’,timeout=10)
⑨proxies:字典型別,設定訪問代理服務器,可以增加登錄認證(隱藏爬取地址)
pxs={'http':'http://user:pass@10.10.10.1:1234',
'https':'https://10.10.10.1:1234'}
r=requests.request("GET",'http://www.baidu.com',proxies=pxs)
⑩allow_redirects:True/False,默認為True,重定向開關
⑾.stream:True/False,默認為True,獲取內容立即下載開關
⑿.verify:True/False,默認為True,認證SSL證書開關
⒀.cert:本地SSL證書路徑
requests庫的get()方法
(實際以requests庫的方法來封裝)
r = requests.get(url)
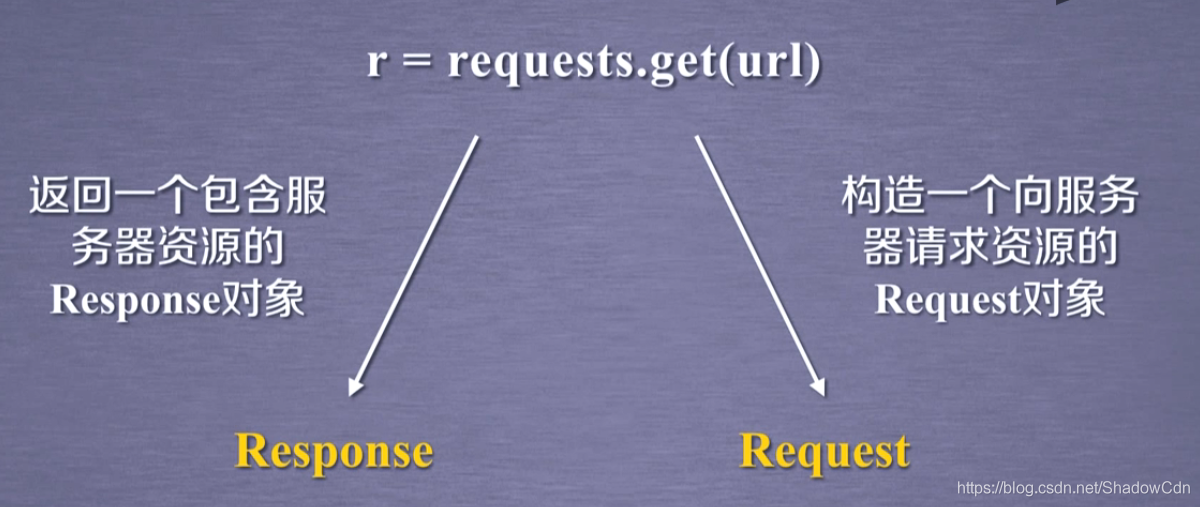
完整使用方法有三個引數
requests.get(url,params=None,**kwargs)
1.url: 擬獲取頁面的url鏈接
2.params:url中額外引數,字典或者位元組流格式,可選
3.**kwargs:控制訪問引數,均為可選項(13個)
Response物件包含服務器回傳的所有資訊,同時包含了想服務器請求的request資訊
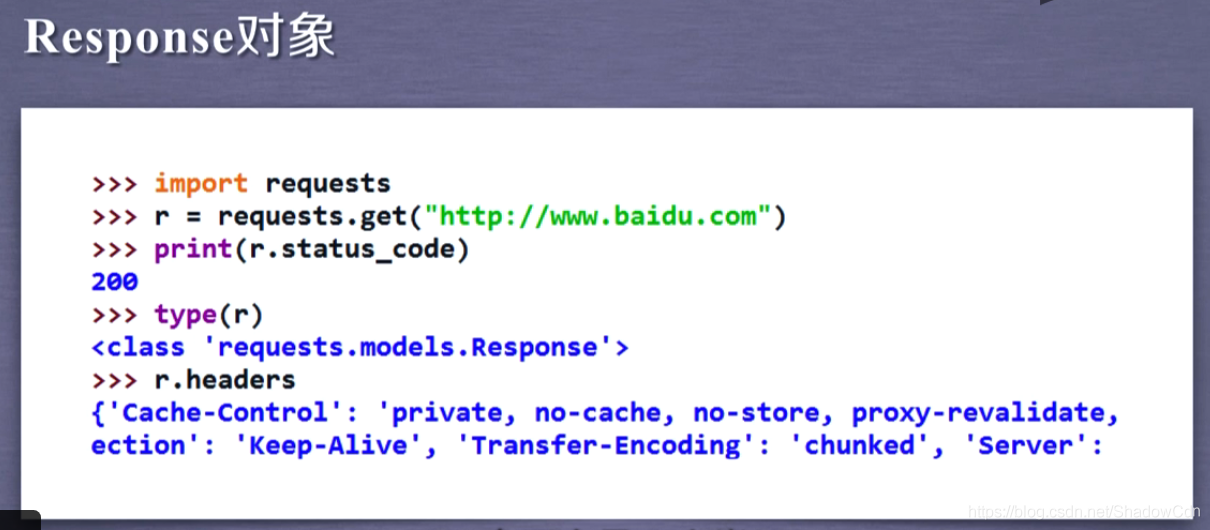
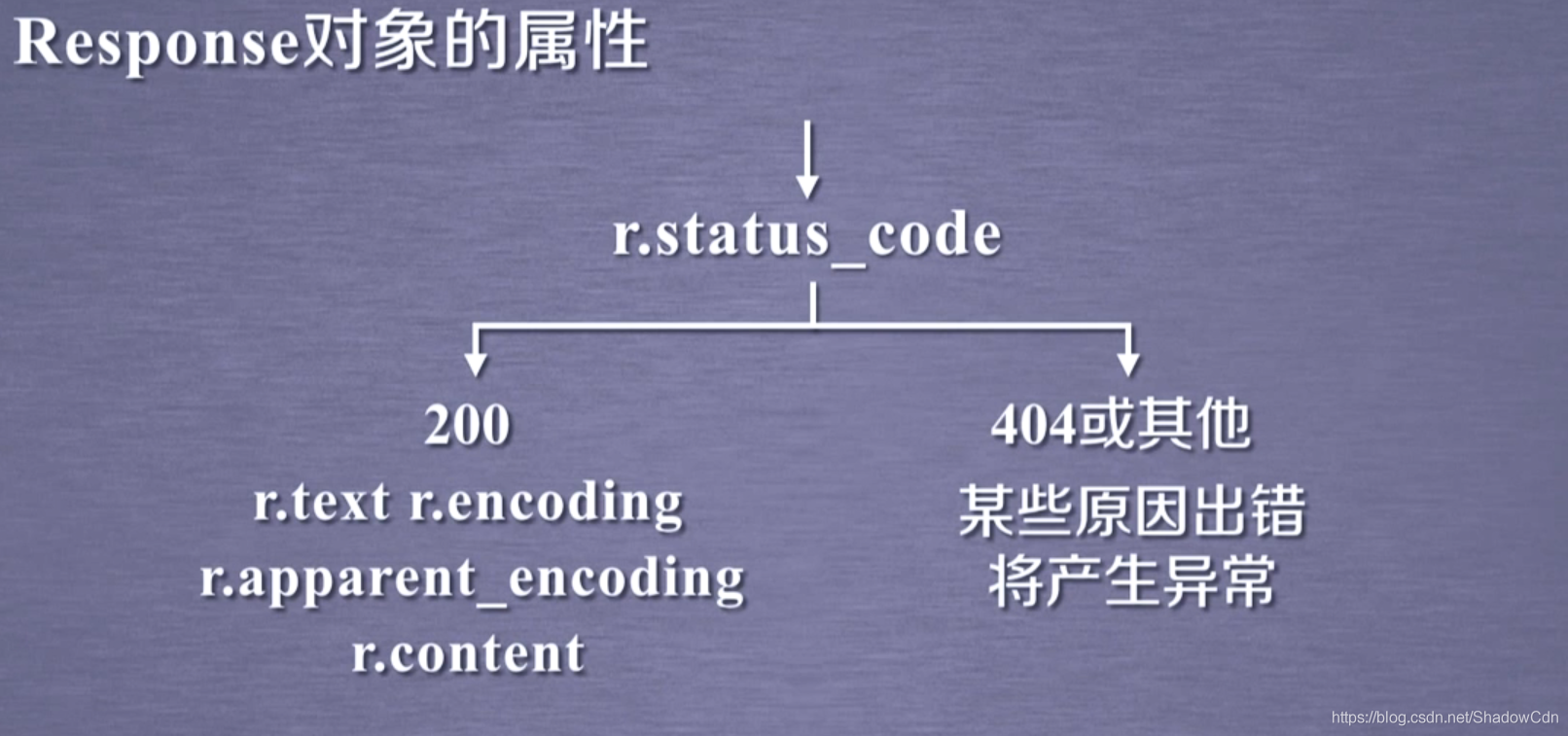
Response物件的屬性

這五個屬性為訪問網頁最必要的屬性,務必牢記!
使用get方法獲取網上資源的流程:
requests.head(url,**kwargs)
request.post(url,data=None,json=None,**kwargs)
data:字典、位元組序列或檔案,request的內容
json:JSON格式的資料,request的內容
requests.put(url,data=None,**kwargs)
requests.patch(url,data=None,**kwargs)
requests.delete(url,data=None,**kwargs)
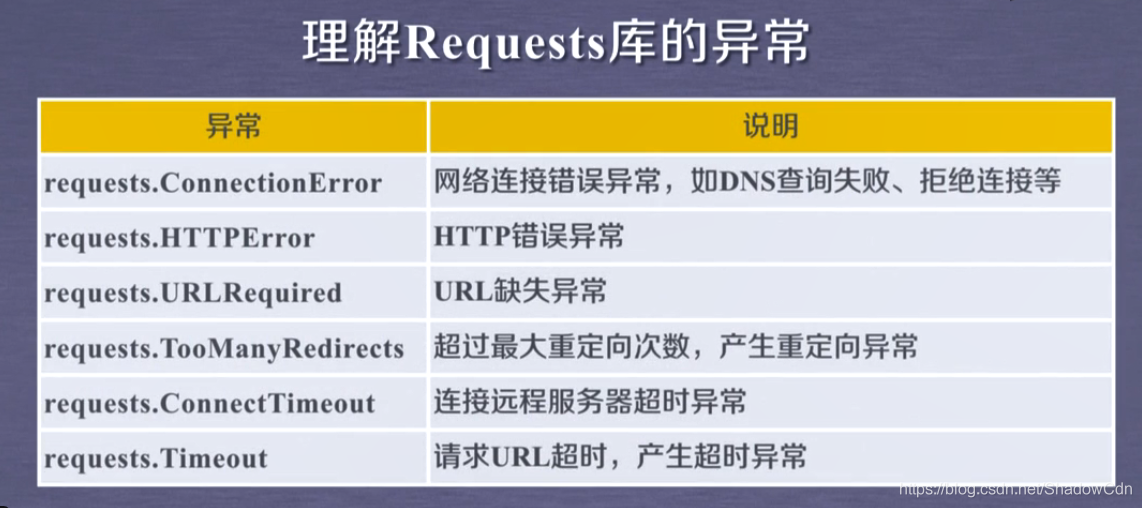
Requests庫的例外
爬取網頁的通用代碼框架
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()#如果狀態不是200,引發HTTPError的例外
r.encoding = r.apparent_encoding
return r.text
except:
return"產生例外"
if __name__=="__main__":
url = "http://www.baidu.com"
print(getHTMLText(url)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290888.html
標籤:python