很多爬蟲大佬都會建立自己的,IP 代理池,你想知道 IP 代理池是如何創建的嗎?
如果你恰巧有此需求,歡迎閱讀本文,
本案例為爬蟲 120 例專欄中的一例,顧使用 requests + lxml 進行實作,
從 89IP 網開始
代理 IP 目標網站之一為:https://www.89ip.cn/index_1.html,首先撰寫隨機回傳 User-Agent 的函式,也可以將該函式的回傳值設定為請求頭,即 headers 引數,
def get_headers():
uas = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)",
"Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)",
"Baiduspider-image+(+http://www.baidu.com/search/spider.htm)",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 YisouSpider/5.0 Safari/537.36",
"Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)",
"Mozilla/5.0 (compatible; Googlebot-Image/1.0; +http://www.google.com/bot.html)",
"Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)",
"Sogou News Spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0);",
"Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)",
"Sosospider+(+http://help.soso.com/webspider.htm)",
"Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)"
]
ua = random.choice(uas)
headers = {
"user-agent": ua,
"referer": "https://www.baidu.com"
}
return headers
上述代碼中的 uas 變數,使用的是各大搜索引擎的 UA,后續案例將會繼續擴展該串列欄位,爭取成為單獨的模塊,
串列隨機選擇一個值,使用 random.choice ,請提前匯入 random 模塊,
撰寫 requests 請求函式
提取公用的請求函式,便于后續擴展為多個代理站點采集資料,
def get_html(url):
headers = get_headers()
try:
res = requests.get(url, headers=headers, timeout=5)
return res.text
except Exception as e:
print("請求網址例外", e)
return None
上述代碼首先呼叫 get_headers 函式,獲取請求頭,之后通過 requests 發起基本請求,
撰寫 89IP 網決議代碼
下面的步驟分為兩步,首先撰寫針對 89IP 網的提取代碼,然后再對其進行公共函式提取,
提取部分代碼如下
def ip89():
url = "https://www.89ip.cn/index_1.html"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
# 待回傳的IP與埠串列
ret = []
html = etree.HTML(text)
ips = html.xpath(ip_xpath)
ports = html.xpath(port_xpath)
# 測驗,正式運行洗掉本部分代碼
print(ips,ports)
ip_port = zip(ips, ports)
for ip, port in ip_port:
item_dict = {
"ip": ip.strip(),
"port": port.strip()
}
ret.append(item_dict)
return ret
上述代碼首先獲取網頁回應,之后通過 lxml 進行序列化操作,即 etree.HTML(text),然后通過 xpath 語法進行資料提取,最后拼接成一個包含字典項的串列,進行回傳,
其中決議部分可以進行提取,所以上述代碼可以分割為兩個部分,
# 代理IP網站原始碼獲取部分
def ip89():
url = "https://www.89ip.cn/index_1.html"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
# HTML決議部分
def format_html(text, ip_xpath, port_xpath):
# 待回傳的IP與埠串列
ret = []
html = etree.HTML(text)
ips = html.xpath(ip_xpath)
ports = html.xpath(port_xpath)
# 測驗,正式運行洗掉本部分代碼
print(ips,ports)
ip_port = zip(ips, ports)
for ip, port in ip_port:
item_dict = {
"ip": ip.strip(), # 防止出現 \n \t 等空格類字符
"port": port.strip()
}
ret.append(item_dict)
return ret
測驗代碼,得到如下結果,
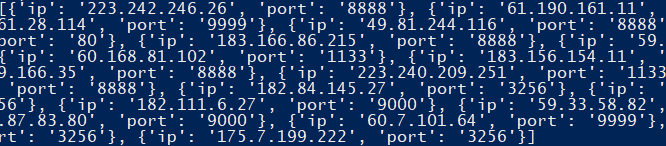
擴展其它代理 IP 地址
在 89IP 代理網代碼撰寫完畢之后,就可以進行其它站點的擴展實作了,各站點擴展如下:
def ip66():
url = "http://www.66ip.cn/1.html"
text = get_html(url)
ip_xpath = '//table/tr[position()>1]/td[1]/text()'
port_xpath = '//table/tr[position()>1]/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip3366():
url = "https://proxy.ip3366.net/free/?action=china&page=1"
text = get_html(url)
ip_xpath = '//td[@data-title="IP"]/text()'
port_xpath = '//td[@data-title="PORT"]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_huan():
url = "https://ip.ihuan.me/?page=b97827cc"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/a/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_kuai():
url = "https://www.kuaidaili.com/free/inha/2/"
text = get_html(url)
ip_xpath = '//td[@data-title="IP"]/text()'
port_xpath = '//td[@data-title="PORT"]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_jiangxi():
url = "https://ip.jiangxianli.com/?page=1"
text = get_html(url)
ip_xpath = '//tbody/tr[position()!=7]/td[1]/text()'
port_xpath = '//tbody/tr[position()!=7]/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
def ip_kaixin():
url = "http://www.kxdaili.com/dailiip/1/1.html"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
print(ret)
可以看到,進行公共方法提取之后,各個站點之間的代碼都十分相似,上述內容都是只提取了一頁資料,擴展到其它頁面,在后文實作,在這之前,需要先處理一個特殊的站點:http://www.nimadaili.com/putong/1/,
該代理站點與上述站點存在差異,即 IP 與埠在一個 td 單元格中,如下圖所示: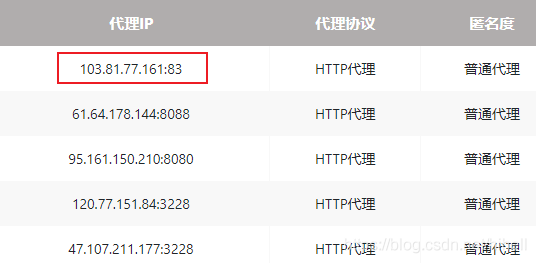
需要針對該網站提供一個特殊的決議函式,如下所示,在代碼中通過字串分割進行 IP 與埠號的提取,
def ip_nima():
url = "http://www.nimadaili.com/putong/1/"
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
ret = format_html_ext(text, ip_xpath)
print(ret)
# 擴展HTML決議函式
def format_html_ext(text, ip_xpath):
# 待回傳的IP與埠串列
ret = []
html = etree.HTML(text)
ips = html.xpath(ip_xpath)
print(ips)
for ip in ips:
item_dict = {
"ip": ip.split(":")[0],
"port": ip.split(":")[1]
}
ret.append(item_dict)
return ret
獲取到的 IP 進行驗證
獲取到的 IP 進行可用性驗證,并將可用 IP 存盤到檔案中,
檢測方式有兩種,代碼分別如下:
import telnetlib
# 代理檢測函式
def check_ip_port(ip_port):
for item in ip_port:
ip = item["ip"]
port = item["port"]
try:
tn = telnetlib.Telnet(ip, port=port,timeout=2)
except:
print('[-] ip:{}:{}'.format(ip,port))
else:
print('[+] ip:{}:{}'.format(ip,port))
with open('ipporxy.txt','a') as f:
f.write(ip+':'+port+'\n')
print("階段性檢測完畢")
def check_proxy(ip_port):
for item in ip_port:
ip = item["ip"]
port = item["port"]
url = 'https://api.ipify.org/?format=json'
proxies= {
"http":"http://{}:{}".format(ip,port),
"https":"https://{}:{}".format(ip,port),
}
try:
res = requests.get(url, proxies=proxies, timeout=3).json()
if 'ip' in res:
print(res['ip'])
except Exception as e:
print(e)
第一種是通過 telnetlib 模塊的 Telnet 方法實作,第二種通過請求固定地址實作,
擴大 IP 檢索量
上述所有的 IP 檢測都是針對一頁資料實作,接下來修改為多頁資料,依舊拿 89IP 舉例,
在該函式引數中新增加一個 pagesize 變數,然后使用回圈實作即可,
def ip89(pagesize):
url_format = "https://www.89ip.cn/index_{}.html"
for page in range(1,pagesize+1):
url = url_format.format(page)
text = get_html(url)
ip_xpath = '//tbody/tr/td[1]/text()'
port_xpath = '//tbody/tr/td[2]/text()'
ret = format_html(text, ip_xpath, port_xpath)
# 檢測代理是否可用
check_ip_port(ret)
# check_proxy(ret)
此時代碼運行得到如下結果:
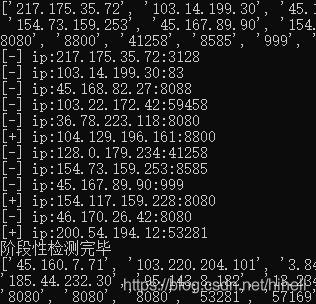
上述代碼,當 IP 可用時,已經對 IP 進行了存盤,
with open('ipporxy.txt','a') as f:
f.write(ip+':'+port+'\n')
評論時間
代碼下載地址:https://codechina.csdn.net/hihell/python120,可否給個 Star,
來都來了,不發個評論,點個贊嗎?
今天是持續寫作的第 192 / 200 天,
可以關注我,點贊我、評論我、收藏我啦,
更多精彩
- Python 爬蟲 100 例教程導航帖(已完結)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/290889.html
標籤:python