1、常見的函式式介面
1、Function -T作為輸入,回傳的R作為輸出 、被稱為函式式介面
Function<String,String> function = (x) -> {System.out.print(x+": ");return "Function";}; System.out.println(function.apply("hello world"));
2、Predicate -T作為輸入,回傳的boolean值作為輸出 、被稱為斷言型介面
Predicate<String> pre = (x) ->{System.out.print(x);return false;}; System.out.println(": "+pre.test("hello World"));
3、Consumer - T作為輸入,執行某種動作但沒有回傳值 、被稱為消費型介面
Consumer<String> con = (x) -> {System.out.println(x);}; con.accept("hello world");
4、Supplier - 沒有任何輸入,回傳T 、被稱為供給型介面
Supplier<String> supp = () -> {return "Supplier";}; System.out.println(supp.get());
5、BinaryOperator -兩個T作為輸入,回傳一個T作為輸出,對于“reduce”操作很有用
BinaryOperator<String> bina = (x,y) ->{System.out.print(x+" "+y);return "BinaryOperator";}; System.out.println(" "+bina.apply("hello ","world"));
運行結果如下:
hello world:
Function hello World:
false hello world Supplier hello world BinaryOperator
6、關于函式式介面Comparator的疑惑
函式式介面代表的是只能由一個抽象方法,多個類方法或多個默認方法,但是查閱Comparator介面的原始碼,發現它有兩個抽象方法(compare和equals方法),但它又使用了@FunctionalInterface注解,這是為什么?
解答: 因為equals方法是Object的函式,每個類
都繼承于Object,由此可見函式是介面中可以定義或重寫Object中的函式,但是除此之外的函式只能定義一個,
代碼示例:
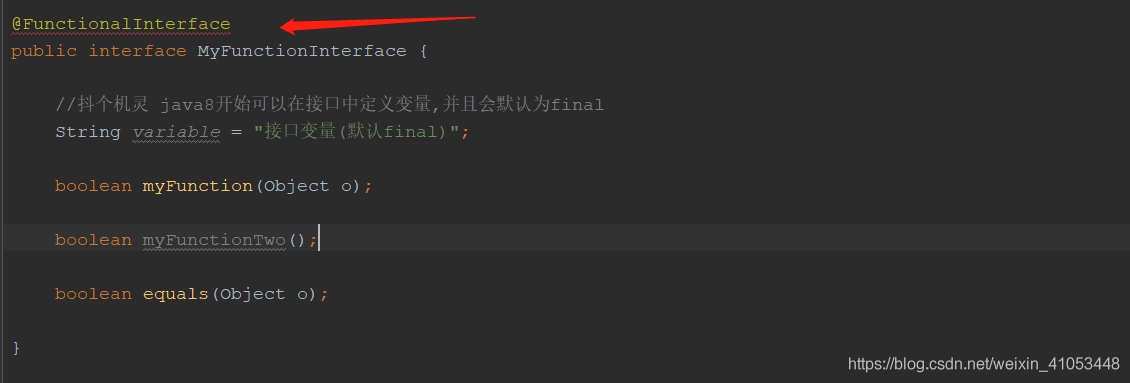
@FunctionalInterface
public interface MyFunctionInterface {
//抖個機靈 java8開始可以在介面中定義變數,并且會默認為final
String variable = "介面變數(默認final)";
boolean myFunction(Object o);
boolean equals(Object o);
}如果我們再定義一個函式呢?
可以看到當我們繼續定義一個函式的時候編譯器已經提示無法編譯了,由此可見我們的判斷是正確的,然后用實際例子再來實驗一下.
//關于函式是介面中存在繼承Object函式的驗證
@Test
public void test() {
MyFunctionInterface myFunctionInterface = (ss) -> {
System.out.println("自定義函式式介面:" + ss);
return true;
};
boolean objResult = myFunctionInterface.equals("測驗");
boolean myResult = myFunctionInterface.myFunction("測驗");
System.out.println("Object-equals方法:" + objResult);
System.out.println("---自定義函式式介面:" + myResult);
}
運行結果:
自定義函式式介面:測驗
Object-equals方法:false
---自定義函式式介面:true通過代碼可以看出,我們的函式式介面中有一個和Object的equals函式相同引數相同回傳值的函式,但是當我們同時呼叫函式式介面中的自定義函式和equals函式時,最終的回傳值是我們自定義函式的值,由此可見java8中只允許定義一個函式實際上是只允許定義一個非靜態、非默認以及非繼承Object的函式.
實際上關于靜態函式和默認函式也是可以定義的
@FunctionalInterface
public interface MyFunctionInterface {
// java8開始可以在介面中定義變數,并且會默認為final
tring variable = "介面變數(默認final)";
boolean myFunction(Object o);
boolean equals(Object o);
static String get() {
return "靜態函式";
}
static void set() {
System.out.println("我也是靜態函式");
}
default void consume() {
System.out.println("我是默認函式");
}
default String sup() {
return "我也是默認函式";
}
}由此延申一下靜態函式和默認函式
靜態函式:可以直接通過介面名去呼叫
默認函式:繼承該介面的子類都可以呼叫該函式
2、方法參考
Ⅰ、方法參考的種類
有如下四種方法參考:
| 種類 | 舉例 |
| 1、Reference to a static method | ContainingClass::staticMethodName |
| 2、Reference to an instance method of a particular object | containingObject::instanceMethodName |
| 3、Reference to an instance method of an arbitrary object of a particular type | ContainingType::methodName |
| 4、Reference to a constructor | ClassName::new |
一、類名::靜態方法
在Integer中有個compare函式是靜態的
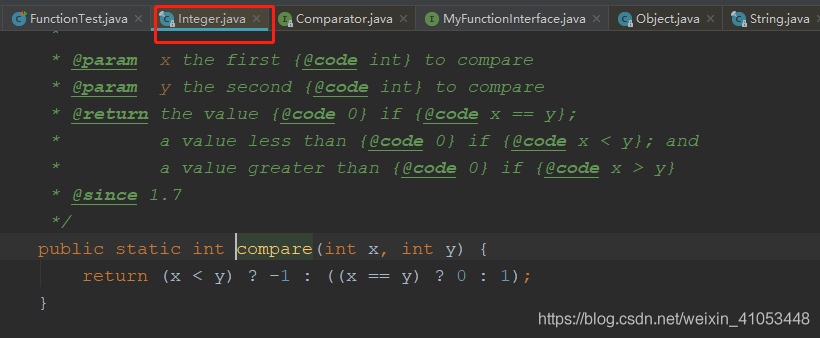
因此這里我們可以直接通過類名呼叫
@Test
public void staticFunction() {
Comparator<Integer> comparator = Integer::compare;
int result = comparator.compare(1, 2);
System.out.println(result);
}二、物件::實體方法
@Test
public void instanceFunction() {
Consumer<String> con = System.out::println;
con.accept("實體方法參考,實體為System.out");
}三、類名::實體方法
在Integer類中還有一個compareTo函式是非靜態函式,任意型別的方法參考相對比較復雜,這里我們遵循第四小節使用規則第二條去理解使用
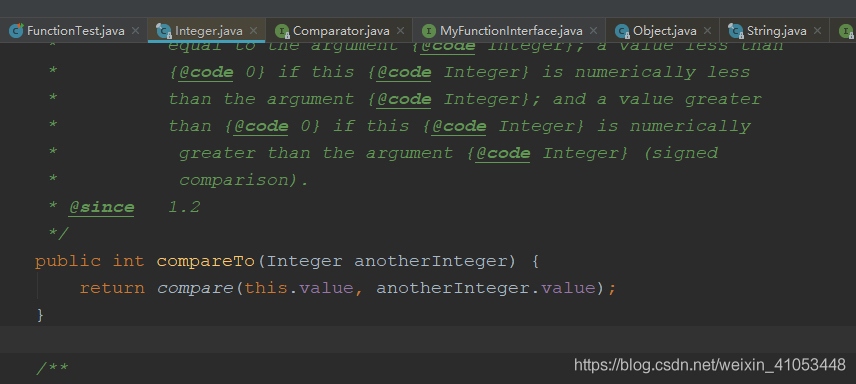
@Test
public void TypeInstanceFunction() {
Integer integer = new Integer(1);
System.out.println(integer.compareTo(2));
//若lambda引數串列中的第一個引數是實體方法的呼叫者,而第二個引數是實體方法的引數時,可以使用 ClassName :: method
Comparator<Integer> comparator = Integer::compareTo;
int result = comparator.compare(1, 2);
System.out.println(result);
}
運行結果:
-1
-1四、類名::new
在我們需要創建一個物件的時候可以使用構造器方法參考
public void ConstructFunction() {
Supplier<List<Integer>> sup = ArrayList::new;
List<Integer> list = sup.get();
}總結:
1、我們在使用方法參考的時候回傳值要和函式式介面回傳值一致
2、我們使用特定型別方法參考的時候(類名:普通函式),函式式介面的引數一定要是普通函式的呼叫方,如果函式式介面有兩個引數,那么第一個引數一定是普通函式呼叫方,第二個則為普通函式的引數
3、Stream Api
java8更新后,Stream流式操作為我們函式式編程提供了更大的可操作性以及強化了我們的代碼可讀性,尤其是并行流的實作不僅更好的提高了cup的利用率也針對java8之前的fork/join框架做了很好的封裝,當我們操作大量資料的時候減少了大量極其復雜的邏輯設計,下面看一下Stream都為我們提供了那些函式以及使用方式是怎么樣的,
java8中有兩個最為重要的改變,第一個是Lambda運算式,第二個就是Stream Api,Stream是java8中處理集合的關鍵抽象概念,它可以指定你希望對集合進行的操作,可以執行非常復雜的查詢、過濾和映射資料等操作,使用Stream API對集合資料進行操作,就類似于使用sql執行資料庫查詢,也可以使用Stream API來執行并行操作,簡而言之Stream API提供了一種高效且易于使用的資料處理方式,
一、什么是Stream(流)?
流是資料渠道,用于操作資料源(集合、陣列等)所生成的元素序列,集合講的是資料,流講的是計算,
注意:
1、Stream 自己不會存盤元素
2、Stream 不會改變源物件,相反,他們會回傳一個持有結果的新Stream,
3、Stream 操作是延遲執行的,這意味著它會等到需要結果的時候執行,
二、創建Stream
一個源,集合陣列等,獲取一個流
1、可以通過Collection系列提供的stream()或parallelStream()
2、通過Arrays中靜態方法stream()獲取陣列流
3、通過Stream的of()方法獲取流
4、通過Stream的iterate()方法創建無限流
@Test
public void test1() {
//1、通過Collection 獲取流stream() 或者parallelStream()
List<Integer> list = new ArrayList<>();
Stream<Integer> stream = list.stream();
//2、通過陣列Arrays的stream()獲取流
Integer[] i = new Integer[10];
Stream<Integer> arrStream = Arrays.stream(i);
//3、通過Stream的of方法獲取流
Stream streamSelf = Stream.of(new ArrayList<>());
//創建無限流(迭代)
Stream<Integer> interateStream = Stream.iterate(0, (x) -> x++);
}三、中間操作
一個中間鏈操作,對資料源資料進行處理,多個中間操作可以連接起來形成一個流水線,除非流水線上出發終止操作,否則中間操作不會執行任何處理,而在終止操作時一次性全部處理,稱為 惰性求值
創建一個員工類
package java8;
import java.util.Objects;
public class Employee {
private String name;
private Integer age;
private Double salary;
private Status status;
public Employee(String name, int age, double salary, Status status) {
this.name = name;
this.age = age;
this.salary = salary;
this.status = status;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return Objects.equals(name, employee.name) &&
Objects.equals(age, employee.age) &&
Objects.equals(salary, employee.salary) &&
status == employee.status;
}
@Override
public int hashCode() {
return Objects.hash(name, age, salary, status);
}
public enum Status {
FREE,
BUSY,
BLOCK
}
public Status getStatus() {
return status;
}
public void setStatus(Status status) {
this.status = status;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
}//創建員工物件list
List<Employee> employeeList = Arrays.asList(
new Employee("Yudia", 18, 9999.99, Employee.Status.FREE),
new Employee("Williams", 28, 8888.88, Employee.Status.BUSY),
new Employee("Su", 38, 7777.77, Employee.Status.BLOCK),
new Employee("Mike", 48, 6666.66, Employee.Status.BUSY),
new Employee("John", 58, 5555.55, Employee.Status.FREE),
new Employee("White", 68, 4444.44, Employee.Status.BUSY),
new Employee("Black", 78, 3333.33, Employee.Status.FREE),
new Employee("Lucy", 88, 2222.22, Employee.Status.BUSY),
new Employee("Click", 98, 1111.11, Employee.Status.BLOCK)
);1、篩選與切片
filter-接受lambda,從流中排除某些元素
limit-截斷流,使元素不超過給定個數
skip(n)-跳過元素,回傳一個扔掉了前n個元素的流,若流中元素不足n個則回傳一個空流
distinct-篩選,通過流所產生元素的hashCode()和equals()去除重復元素
filter傳入一個斷言lambda運算式對流進行篩選
Filter、獲取工資大于5000的員工
@Test
public void test1() {
List<Employee> employees = employeeList.stream()
.filter(employee -> employee.getSalary() > 5000)
.collect(Collectors.toList());
System.out.println(employees);
}
運行結果
[Employee{name='Yudia', age=18, salary=9999.99, status=FREE},
Employee{name='Williams', age=28, salary=8888.88, status=BUSY},
Employee{name='Su', age=38, salary=7777.77, status=BLOCK},
Employee{name='Mike', age=48, salary=6666.66, status=BUSY},
Employee{name='John', age=58, salary=5555.55, status=FREE}]Distinct、獲取員工的作業狀態,可以看到所有員工的狀態重復的已經被去除
@Test
public void test2() {
List<Employee.Status> statuses = employeeList.stream()
.map(Employee::getStatus)
.distinct()
.collect(Collectors.toList());
System.out.println(statuses);
}
運行結果
[FREE, BUSY, BLOCK]Limit、獲取工資大于5000的三個員工
@Test
public void test3() {
List<Employee> employees = employeeList.stream()
.filter(employee -> employee.getSalary() > 5000)
.limit(3)
.collect(Collectors.toList());
System.out.println(employees);
}
運行結果
[Employee{name='Yudia', age=18, salary=9999.99, status=FREE},
Employee{name='Williams', age=28, salary=8888.88, status=BUSY},
Employee{name='Su', age=38, salary=7777.77, status=BLOCK}]Skip和limit相對的是 skip可以跳過幾個元素,如果流中的元素小于要跳過的數量則回傳一個空流
@Test
public void test4() {
List<Employee> employees = employeeList.stream()
.skip(8)
.collect(Collectors.toList());
System.out.println(employees);
}
運行結果
[Employee{name='Click', age=98, salary=1111.11, status=BLOCK}]可以看出我們跳過了流中的前八個元素
2、映射
map-接受lambda,將元素轉換成其他形式或提取資訊,接收一個函式作為引數,該函式會被應用到每個元素上,并將其映射成一個新的元素
flatMap-接受一個函式作為引數,將流中的每個值都當作一個流,最后將所有流匯總
通過map獲取所有員工的姓名
@Test public void test5() { List<String> list = employeeList.stream() .map(Employee::getName) .collect(Collectors.toList()); System.out.println(list); } 運行結果 [Yudia, Williams, Su, Mike, John, White, Black, Lucy, Click]
通過flatMap獲取所有員工姓名字母
@Test
public void test5() {
List<String> list = employeeList.stream()
.map(Employee::getName)
.collect(Collectors.toList());
System.out.println(list);
}
運行結果
[Yudia, Williams, Su, Mike, John, White, Black, Lucy, Click]3、排序
sorted()--自然排序
sorted(Compartor c)--定制排序
自然排序,排列員工年齡
@Test
public void test7() {
employeeList.stream()
.map(Employee::getAge)
.sorted()
.forEach(System.out::println);
}
結果
18
28
38
48
58
68
78
88
98定制排序,根據員工工資排序從小到大
@Test
public void test8() {
employeeList.stream()
.sorted((e1, e2) -> e1.getSalary().compareTo(e2.getSalary()))
.forEach(System.out::println);
}
運行結果:
Employee{name='Click', age=98, salary=1111.11, status=BLOCK}
Employee{name='Lucy', age=88, salary=2222.22, status=BUSY}
Employee{name='Black', age=78, salary=3333.33, status=FREE}
Employee{name='White', age=68, salary=4444.44, status=BUSY}
Employee{name='John', age=58, salary=5555.55, status=FREE}
Employee{name='Mike', age=48, salary=6666.66, status=BUSY}
Employee{name='Su', age=38, salary=7777.77, status=BLOCK}
Employee{name='Williams', age=28, salary=8888.88, status=BUSY}
Employee{name='Yudia', age=18, salary=9999.99, status=FREE}4、查找與匹配
allMatch-檢查是否匹配所有元素
anyMatch-檢查是否至少匹配一個元素
noneMatch-檢查是否沒有匹配所有元素
findFirst-回傳第一個元素
findAny-回傳當前流中任意元素
count-回傳流中元素總個數
max-回傳流中最大值
min-回傳流中最小值
檢查是否所有員工工資大于3000
@Test
public void test9() {
boolean result = employeeList.stream()
.allMatch(employee -> employee.getSalary() > 3000);
System.out.println(result);
}
運行結果:
false檢查所有員工中是否有35歲的員工
@Test
public void test10() {
boolean result = employeeList.stream()
.anyMatch(employee -> employee.getAge() == 35);
System.out.println(result);
}
運行結果:
false檢查所有員工中是否沒有叫Mike的
@Test
public void test11() {
boolean result = employeeList.stream()
.noneMatch(employee -> "Mike".equals(employee.getName()));
System.out.println(result);
}
運行結果:
false回傳年齡大于30的第一個員工
@Test
public void test12() {
Employee e = employeeList.stream()
.sorted((e1, e2) -> e1.getAge().compareTo(e2.getAge()))//先對員工按年齡順序排列
.filter(employee -> employee.getAge() > 30)
.findFirst()
.get();
System.out.println(e);
}
運行結果:
Employee{name='Su', age=38, salary=7777.77, status=BLOCK}回傳任意一個員工、這里我們使用并行流同時取查找
@Test
public void test13() {
Employee employee = employeeList.parallelStream()
.findAny().get();
System.out.println(employee);
}
運行結果:
Employee{name='White', age=68, salary=4444.44, status=BUSY}回傳所有員工個數
@Test
public void test14() {
long count = employeeList.stream()
.count();
System.out.println(count);
}
運行結果:
9回傳所有員工中最高的工資
@Test
public void test15() {
double salary = employeeList.stream()
.max((e1, e2) -> e1.getSalary().compareTo(e2.getSalary()))
.get()
.getSalary();
System.out.println(salary);
}
運行結果:
9999.99回傳所有員工中最小的年齡
@Test
public void test16() {
int age = employeeList.stream()
.min((e1, e2) -> e1.getAge().compareTo(e2.getAge()))
.get()
.getAge();
System.out.println(age);
}
運行結果:
18四、終止操作
一個終止操作,執行中間鏈操作,并產生結果
1、規約和收集
規約:reduce(T identity,BinaryOperate)/reduce(BinaryOperate),可以將流中的元素反復結合起來得到一個值
獲取所有員工工資總和
@Test
public void test17() {
Double d = employeeList.stream()
.map(Employee::getSalary)
.reduce(Double::sum)
.get();
System.out.println(d);
}
運行結果:
49999.95000000001有起始值的規約函式可以防止空指標例外
@Test
public void test18() {
Double d = employeeList.stream()
.map(Employee::getSalary)
.reduce(0.00, Double::sum);
System.out.println(d);
}
運行結果:
49999.95000000001收集:collect-將流轉換為其他形式,接受一個Collector介面的實作,用于給Stream中元素做匯總的方法
Collector 介面中的方法實作決定了如何對流執行收集操作,如收集到List、Set、Map,并且Collectors實用類提供了很多靜態方法,可以方便地創建常見收集器實體
將員工的姓名放到ArrayList和HashSet中
@Test
public void test20() {
List<String> list = employeeList.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(ArrayList::new));
Set<String> set = employeeList.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));
System.out.println("ArrayList:" + list);
System.out.println("HashSet:" + set);
}
運行結果:
ArrayList:[Yudia, Williams, Su, Mike, John, White, Black, Lucy, Click]
HashSet:[Su, Mike, Williams, White, John, Click, Black, Lucy, Yudia]收集員工總數
@Test
public void test21() {
long count = employeeList.stream()
.collect(Collectors.counting());
System.out.println(count);
}
運行結果:
9 獲取員工年齡平均值
@Test
public void test22() {
double d = employeeList.stream()
.collect(Collectors.averagingInt(Employee::getAge));
System.out.println(d);
}
運行結果:
58.0獲取工資最大值
public void test23() {
double salary = employeeList.stream()
.collect(Collectors.maxBy((e1, e2) -> e1.getSalary().compareTo(e2.getSalary())))
.get()
.getSalary();
System.out.println(salary);
}
運行結果:
9999.99獲取工資最小值
@Test
public void test24() {
double salary = employeeList.stream()
.collect(Collectors.minBy((e1, e2) -> e1.getSalary().compareTo(e2.getSalary())))
.get()
.getSalary();
System.out.println(salary);
}
運行結果:
9999.99通過collector函式獲取工資最大值、最小值、總和、平均值
@Test
public void test27() {
//獲取最大工資
double max = employeeList.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary))
.getMax();
//獲取最小工資
double min = employeeList.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary))
.getMin();
//獲取工資總和
double sum = employeeList.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary))
.getSum();
//獲取工資平均值
double avg = employeeList.stream()
.collect(Collectors.summarizingDouble(Employee::getSalary))
.getAverage();
System.out.println("最大工資:" + max);
System.out.println("最小工資:" + min);
System.out.println("工資總和:" + sum);
System.out.println("平均工資:" + avg);
}
運行結果:
最大工資:9999.99
最小工資:1111.11
工資總和:49999.95
平均工資:5555.549999999999按照員工狀態分組
@Test
public void test25() {
Map<Employee.Status, List<Employee>> map = employeeList.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
System.out.println(map);
}
運行結果:
{BUSY=[
Employee{name='Williams', age=28, salary=8888.88, status=BUSY},
Employee{name='Mike', age=48, salary=6666.66, status=BUSY},
Employee{name='White', age=68, salary=4444.44, status=BUSY},
Employee{name='Lucy', age=88, salary=2222.22, status=BUSY}],
BLOCK=[
Employee{name='Su', age=38, salary=7777.77, status=BLOCK},
Employee{name='Click', age=98, salary=1111.11, status=BLOCK}],
FREE=[
Employee{name='Yudia', age=18, salary=9999.99, status=FREE},
Employee{name='John', age=58, salary=5555.55, status=FREE},
Employee{name='Black', age=78, salary=3333.33, status=FREE}]} 按照員工狀態分組后按照年齡段分組
@Test
public void test26() {
Map<Employee.Status, Map<String, List<Employee>>> map = employeeList.stream()
.collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy((e) -> {
if (10 <= e.getAge() && e.getAge() < 30) {
return "新手";
} else if (30 <= e.getAge() && e.getAge() < 50) {
return "高級";
} else {
return "專家";
}
})));
System.out.println(map);
}
運行結果:
{
FREE = {
新手 = [Employee {name = 'Yudia', age = 18, salary = 9999.99, status = FREE}],
專家 = [Employee {name = 'John', age = 58, salary = 5555.55, status = FREE},
Employee {name = 'Black', age = 78, salary = 3333.33, status = FREE
}]
}, BUSY = {
新手 = [Employee {name = 'Williams', age = 28, salary = 8888.88, status = BUSY}],
專家 = [Employee {name = 'White', age = 68, salary = 4444.44, status = BUSY},
Employee {name = 'Lucy', age = 88, salary = 2222.22, status = BUSY}],
高級 = [Employee {name = 'Mike', age = 48, salary = 6666.66, status = BUSY}]
}, BLOCK = {
專家 = [Employee {name = 'Click', age = 98, salary = 1111.11, status = BLOCK}],
高級 = [Employee {name = 'Su', age = 38, salary = 7777.77, status = BLOCK}]
}
}4、Optional類
Optional類(java.util.Optional)是一個容器類,代表一個值存在或者不存在,原來用null標識一個之不存在,現在Optional可以更好的表達這個概念,并且可以避免空指標例外
常用方法:
Optional.of(T t):創建一個Optional實體
Optional.empty():創建一個空的Optional實體
Optional.ofNullable(T t):若t不為null,創建Optional實體,否則創建空實體
isPresent():判斷是否包含值
orElse(T t):如果呼叫物件包含值,回傳該值,否則回傳t
orElseGet(Suppile s):如果呼叫物件包含值,回傳該值,否則回傳s獲取的值
map(Function f):如果有對值對其處理,并回傳處理后的Optional,否則回傳Optional.empty()
flatMap(Function mapper):與map類似,要求回傳值必須是Optional
舉一個例子,我們獲取一個員工物件如果為空則重新創建一個新的物件
@Test
public void test28() {
Employee employee = (Employee) Optional.ofNullable(null).orElse(new Employee());
System.out.println("為空時:" + employee);
Employee employee1 = Optional.ofNullable(new Employee("Click", 98, 1111.11, Employee.Status.BLOCK)).orElse(new Employee());
System.out.println("不為空時:" + employee1);
}
運行結果:
為空時:Employee{name='null', age=null, salary=null, status=null}
不為空時:Employee{name='Click', age=98, salary=1111.11, status=BLOCK}5、并行流、串行流
并行流:并行流就是把一個內容分成多個資料塊,并用不同的執行緒分別處理每個資料塊的流
java8中將并行進行了優化,我們可以很容易的對資料進行并行操作,StreamAPI可以宣告性地同構parallel()與sequential()在并行流與順序流之間進行切換
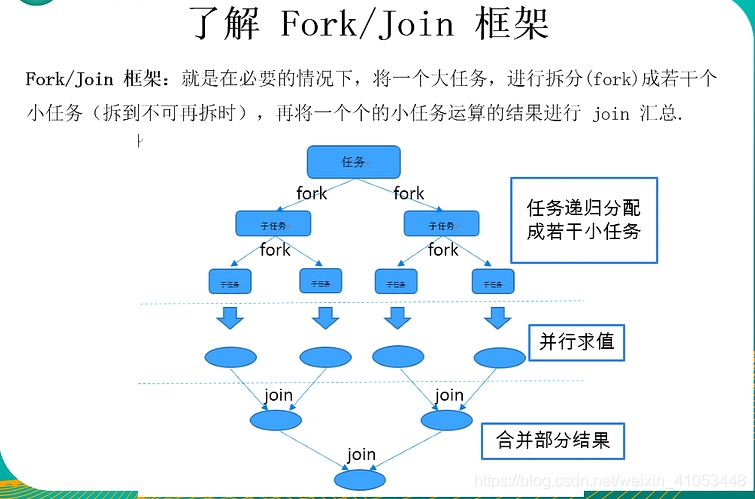

我們通過一個例子計算1~100000000000L的和
java8之前需要繼承RecursiveTask類來實作fork/join框架
package forkJoin;
import java.util.concurrent.RecursiveTask;
public class ForkJoinCalculate extends RecursiveTask<Long> {
private long start;
private long end;
private static final long THRESHODE = 1000000;
public ForkJoinCalculate(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if (length <= THRESHODE) {
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
} else {
long middle = (start + end) / 2;
ForkJoinCalculate left = new ForkJoinCalculate(start, middle);
left.fork();//拆分子任務 同時壓入執行緒佇列
ForkJoinCalculate right = new ForkJoinCalculate(middle + 1, end);
right.fork();
return left.join() + right.join();
}
}
}//java7 forkJoin
@Test
public void test1() {
//fork join 框架需要forkJoinPool的支持
Instant start = Instant.now();
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinCalculate(0, 100000000000L);
long sum = pool.invoke(task);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("java7 forkJoin耗時:" + Duration.between(start, end).toMillis());}
運行結果:
932356074711512064
java7 forkJoin耗時:38610java7 fork/join框架cup利用率
//普通for回圈
@Test
public void test2() {
Instant start = Instant.now();
long sum = 0L;
for (long i = 0; i <= 100000000000L; i++) {
sum += i;
}
System.out.println(sum);
Instant end = Instant.now();
System.out.println("普通for耗時:" + Duration.between(start, end).toMillis());
}
運行結果:
932356074711512064
普通for耗時:46514普通for回圈cup利用率
//java8 并行流
@Test
public void test3() {
Instant start = Instant.now();
long sum = LongStream.rangeClosed(0, 100000000000L)
.parallel()//切換并行流
.reduce(0, Long::sum);
System.out.println(sum);
Instant end = Instant.now();
System.out.println("并行流耗時:" + Duration.between(start, end).toMillis());
}
運行結果:
932356074711512064
并行流耗時:27743Java8并行流cup利用率
總結:相比單執行緒for回圈,java8并行流以及java8之前的fork/join框架都是用多執行緒拆分任務的方式更好的利用了cup的執行提高的程式運行效率,但是從實際運行結果來看java8并行流的效率明顯會更勝一籌并且相比之前的fork/join框架做了很好的封裝,不需要我們再去創建ForkJoinPool,并且也不需要我們設計復雜的遞回演算法去實作,所以java8并行流的出現會成為我們操作大量資料時的首選,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291018.html
標籤:java