常量池的分類
Class檔案常量池、運行時常量池、全域字串常量池、以及基本型別包裝類物件常量池,
Class檔案常量池
一個位元組碼檔案中除了包含類的版本資訊欄位方法等,還包括常量池,包含各種字面量和型別、域和方法的符號參考(符號參考就是類和方法的全限定名,欄位的名稱和描述符,方法的名稱和描述符)
字面量:
1、文本字串:就是我們在代碼中能夠看到的字串,例如:String a = “aa”,其中"aa"就是字面量
2、被final修飾的變數,
運行時常量池:
JVM在執行某個類的時候也就是加載類的時候,會經過加載、連接、初始化,在類加載進記憶體后JVM就會將Class常量池中的內容放到運行時常量池中,
JVM為每個加載的類都維護一個運行時常量池,運行時常量池中包含多種不同的常量,包括編譯器就已經明確的數值字面量,也包括到運行期決議后才能夠獲得方法或者欄位參考,此時不再是常量池匯總的符號地址了,這里換位真實地址,(class檔案常量池和運行時常量池的區別)
字串常量池
jdk1.7中,字串常量池由方法區轉義到了堆中
在堆中生成的字串物件實體,然后將該字串實體的參考存到String pool 中,存的是參考不是具體的實體,字串常量池里面的內容是在類加載的時候完成的,
決議階段是將符號參考轉化為直接參考,決議的程序會查詢字串常量池,找到后字串常量池指向堆中的物件實體,
注意點:
常量池中不會存在相同內容的常量
如果在拼接字串的前后出現了變數,就相當于在堆空間new String, 只要有一個變數,拼接結果就在堆中(常量池以外的堆),變數的拼接原理是StringBuilder
字串拼接不一定都用的是stringbuilder 如果拼接的兩邊都是字串常量或者常量參考(final)任然使用編譯器優化的方案

String
String的基本特性
String: 字串,使用一對“”引起來表示,//字面量的定義方式
? String s1 = “atguigu” ; //字面量的定義方式
? String s2 = new String(“hello”);

String實作了Serializable 表示實作了序列化,Comparable表示課比較大小了,
jdk1.8的時候用的是char[] value;
jdk1.9的時候用的是byte[] value;
? String的基本特性
String:代表不可變的字符序列,簡稱:不可變性
? 當對字串重新賦值時,需要重寫指定記憶體區域賦值,不能使用原有的value進行賦值
? 當對現有的字串進行連接操作時,也需要重寫指定記憶體區域賦值,不能使用原有的value進行賦值,
? 當呼叫String的replace()方法修改指定字符或字串時,也需要重新指定記憶體區域賦值,不能使用原有的value進行賦值,
? 通過字面量的方式(區別于new)給一個字串賦值,此時的字串值宣告在字串常量池中
public void test1(){
String s1 = "abc"; //字面量定義的方式,“abc”存盤在字串常量池中
String s2 = "abc";
System.out.println(s1==s2);
System.out.println(s1);
System.out.println(s2);
}
true
abc
abc
s1 ,s2 為區域變數都是存盤在堆疊上的,abc為字面量存盤在堆上的常量池中,"abc"只能在常量池中有一個,所以s1,s2指向同一個地址,
如果現在讓s2再加上def,那么是在原基礎上增加,還是重新開辟一塊空間呢?
public void test2(){
String s1 = "abc";
String s2 = "abc";
s2+="def";
System.out.println(s2);
System.out.println(s1);
}
abcdef
abc
顯然是重新開啟了一塊空間,沒有在原基礎上進行操作
public void test3(){
String s1 = "abc";
String s2 = s1.replace('a','m');
System.out.println(s1);
System.out.println(s2);
}
在s1上將a變成了m,是否在原地址上進行操作還是重新開啟一塊空空間
它是重新開啟了一塊空間,沒有在原基礎上進行操作,所以s1和s2不一樣,
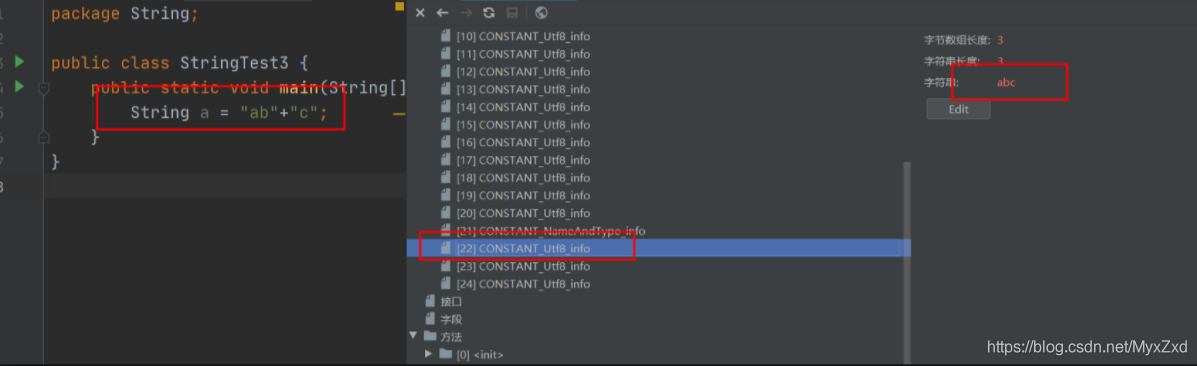
String a = “ab”+“c” 會給它在編譯器的時候就成為 String a =“abc”
字串常量池中是不會存盤相同內容的字串的
String的記憶體分配
? 在Java語言中有8種基本資料型別和一種比較特殊的型別String,這些 型別為了使它們在運行程序中速度更快、更節省記憶體,都提供了一種常量池的概念,
? 常量池就類似一.個Java系統級別提供的快取,8種基本資料型別的常量 池都是系統協調的,String類 型的常量池比較特殊,它的主要使用方法有兩種,
? 直接使用雙引號宣告出來的String物件會直接存盤在常量池中,
? 比如: String info = “abc” ;
? 如果不是用雙引號宣告的String物件,可以使用String提供的intern()方法,這個后面重點談
? Java 6 及以前,字串常量池存放在永久代,
? Java 7 中 Oracle 的工程師對字串的邏輯做了很大的改變,即將字串常量池的位置調整到了Java堆內,
? 所有的字串都保存在堆(Heap)中,和其他普通物件一樣,這樣可以讓你在進行調優應用時僅需要調整堆大小就可以了,
? 字串常量池概念原本使用得比較多,但是這個改動使得我們有足夠的理由讓我們重新考慮在Java 7中使用String. intern(),
Java8 元空間,字串常量在堆
StringTable為什么要調整
①永久代permSize默認比較小;
②永久代的垃圾回收頻率低;
String的基本操作

class Memory {
public static void main(String[] args) {//line 1
int i = 1;//line 2
Object obj = new Object();//line 3
Memory mem = new Memory();//line 4
mem.foo(obj);//line 5
}//line 9
private void foo(Object param) {//line 6
String str = param.toString();//line 7
System.out.println(str);
}//line 8
}
字串拼接操作
1.常量與常量的拼接結果在常量池,原理是編譯期優化
2.常量池中不會存在相同內容的常量,
3.只要其中有一個是變數,結果就在堆中,變數拼接的原理是StringBuilder
4.如果拼接的結果呼叫intern()方法,則主動將常量池中還沒有的字串物件放入池中,并回傳此物件地址,
@Test
public void test1(){
String s1 = "a" + "b" + "c";//編譯期優化:等同于"abc"
String s2 = "abc"; //"abc"一定是放在字串常量池中,將此地址賦給s2
/*
* 最終.java編譯成.class,再執行.class
* String s1 = "abc";
* String s2 = "abc"
*/
System.out.println(s1 == s2); //true
System.out.println(s1.equals(s2)); //true
}
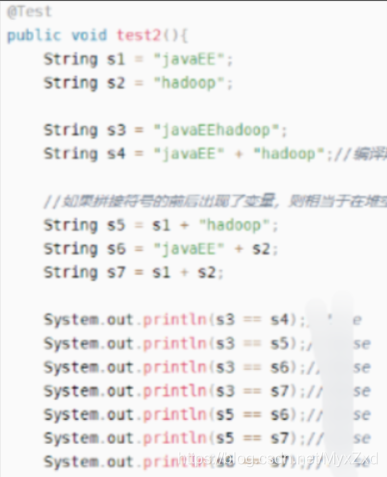
@Test
public void test2(){
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";//編譯期優化
//如果拼接符號的前后出現了變數,則相當于在堆空間中new String(),具體的內容為拼接的結果:javaEEhadoop
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4);//true
System.out.println(s3 == s5);//false
System.out.println(s3 == s6);//false
System.out.println(s3 == s7);//false
System.out.println(s5 == s6);//false
System.out.println(s5 == s7);//false
System.out.println(s6 == s7);//false
//intern():判斷字串常量池中是否存在javaEEhadoop值,如果存在,則回傳常量池中javaEEhadoop的地址;
//如果字串常量池中不存在javaEEhadoop,則在常量池中加載一份javaEEhadoop,并回傳次物件的地址,
String s8 = s6.intern();
System.out.println(s3 == s8);//true
}
字串拼接
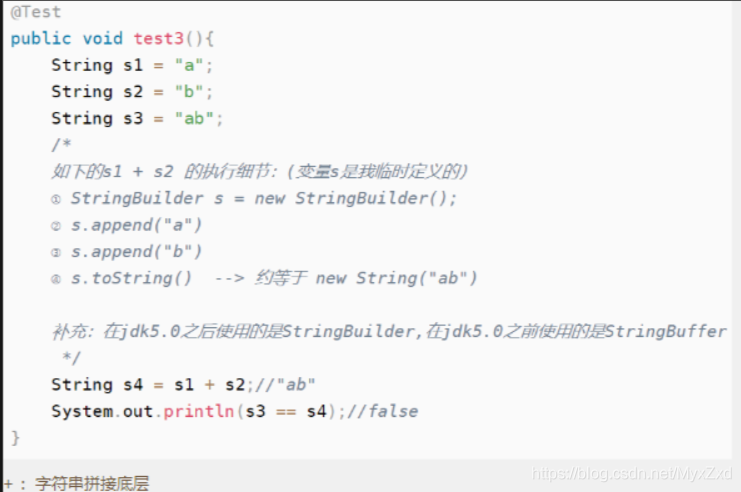
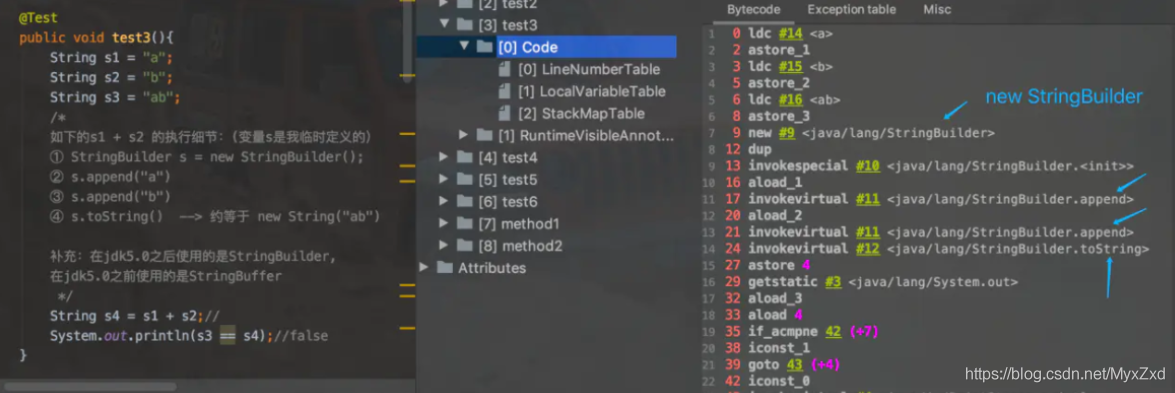
@Test
public void test3(){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
/*
如下的s1 + s2 的執行細節:(變數s是我臨時定義的)
① StringBuilder s = new StringBuilder();
② s.append("a")
③ s.append("b")
④ s.toString() --> 約等于 new String("ab")
補充:在jdk5.0之后使用的是StringBuilder,
在jdk5.0之前使用的是StringBuffer
*/
String s4 = s1 + s2;//
System.out.println(s3 == s4);//false
}
/*
1. 字串拼接操作不一定使用的是StringBuilder!
如果拼接符號左右兩邊都是字串常量或常量參考,則仍然使用編譯期優化,即非StringBuilder的方式,
2. 針對于final修飾類、方法、基本資料型別、參考資料型別的量的結構時,能使用上final的時候建議使用上,
*/
@Test
public void test4(){
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);//true
}
//練習:
@Test
public void test5(){
String s1 = "javaEEhadoop";
String s2 = "javaEE";
String s3 = s2 + "hadoop";
System.out.println(s1 == s3);//false
final String s4 = "javaEE";//s4:常量
String s5 = s4 + "hadoop";
System.out.println(s1 == s5);//true
}
拼接操作與append的效率對比
append效率要比字串拼接高很多
/*
體會執行效率:通過StringBuilder的append()的方式添加字串的效率要遠高于使用String的字串拼接方式!
詳情:① StringBuilder的append()的方式:自始至終中只創建過一個StringBuilder的物件
使用String的字串拼接方式:創建過多個StringBuilder和String的物件
② 使用String的字串拼接方式:記憶體中由于創建了較多的StringBuilder和String的物件,記憶體占用更大;如果進行GC,需要花費額外的時間,
改進的空間:在實際開發中,如果基本確定要前前后后添加的字串長度不高于某個限定值highLevel的情況下,建議使用構造器實體化:
StringBuilder s = new StringBuilder(highLevel);//new char[highLevel]
*/
@Test
public void test6(){
long start = System.currentTimeMillis();
// method1(100000);//4014
method2(100000);//7
long end = System.currentTimeMillis();
System.out.println("花費的時間為:" + (end - start));
}
public void method1(int highLevel){
String src = "";
for(int i = 0;i < highLevel;i++){
src = src + "a";//每次回圈都會創建一個StringBuilder、String
}
// System.out.println(src);
}
public void method2(int highLevel){
//只需要創建一個StringBuilder
StringBuilder src = new StringBuilder();
for (int i = 0; i < highLevel; i++) {
src.append("a");
}
// System.out.println(src);
}
intern()的使用
如果不是用雙引號宣告的String物件,可以使用String提供的intern方法: intern方法會從字串常量池中查詢當前字串是否存在,若不存在就會將當前字串放入常量池中,
? 比如: String myInfo = new String(“I love u”).intern();
也就是說,如果在任意字串上呼叫String. intern方法,那么其回傳結果所指向的那個類實體,必須和直接以常量形式出現的字串實體完全相同,因此,下 列運算式的值必定是true: (“a” + “b” + “c”).intern()== “abc”;
通俗點講,Interned String就是確保字串在記憶體里只有一份拷貝,這樣可以節約記憶體空間,加快字串操作任務的執行速度,注意,這個值會被存放在字串內部池(String Intern Pool),
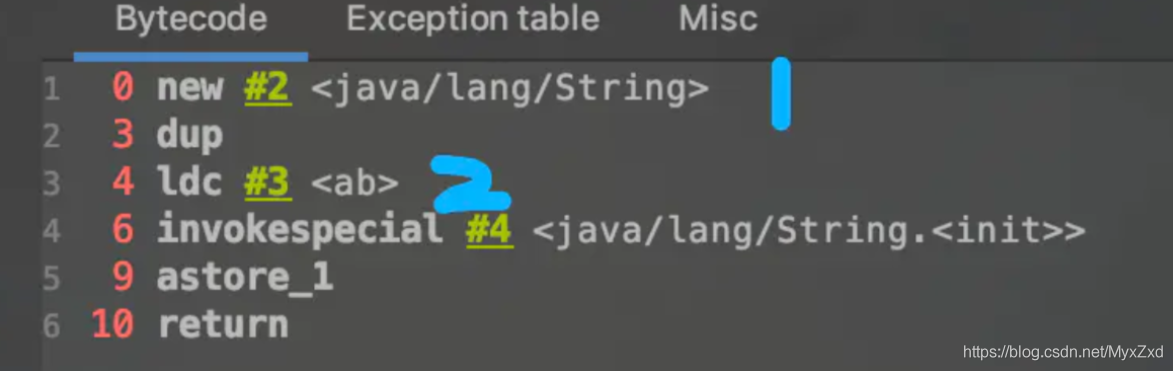
new String(“ab”)會創建幾個物件,new String(“a”)+new String(“b”)呢
public class StringNewTest {
public static void main(String[] args) {
// String str = new String("ab");
String str = new String("a") + new String("b");
}
}
new String(“ab”)會創建幾個物件?看位元組碼,就知道是兩個,
? 一個物件是:new關鍵字在堆空間創建的
? 另一個物件是:字串常量池中的物件"ab", 位元組碼指令:ldc
new String(“a”) + new String(“b”)呢?
? 物件1:new StringBuilder()
? 物件2: new String(“a”)
? 物件3: 常量池中的"a"
? 物件4: new String(“b”)
? 物件5: 常量池中的"b"
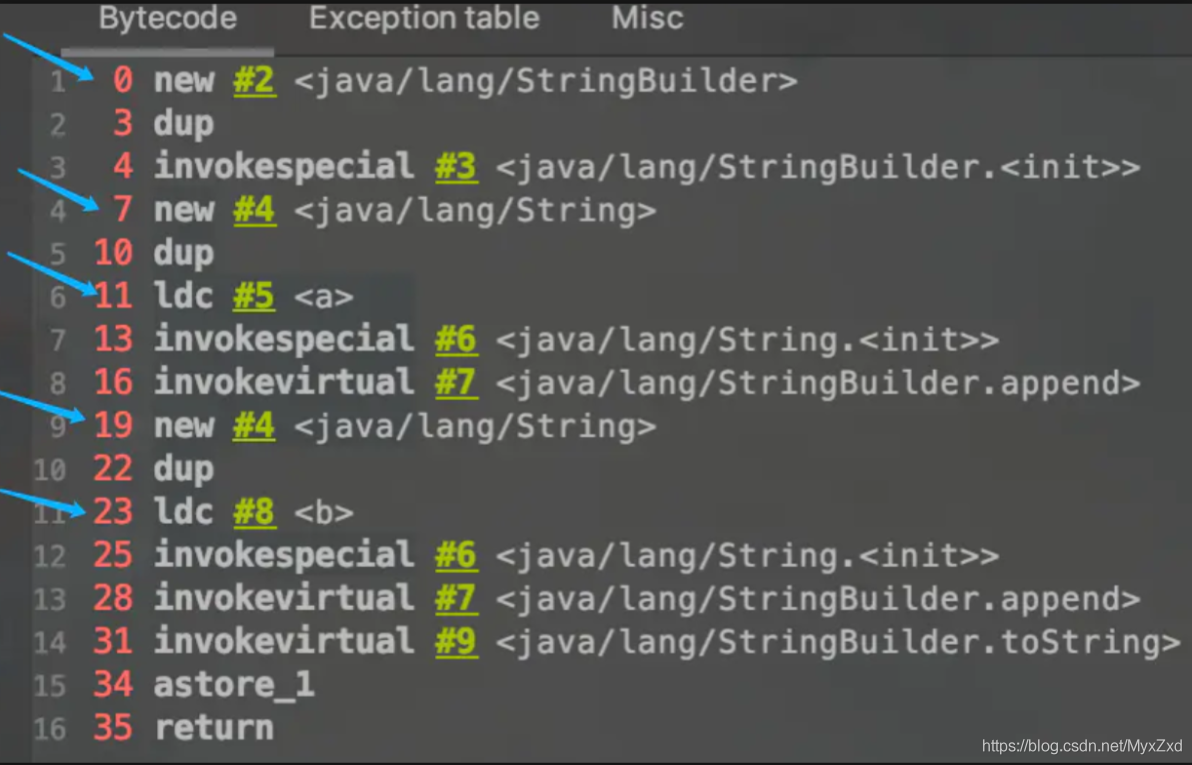
? 深入剖析: StringBuilder的toString():
? 物件6 :new String(“ab”)
? 強調一下,toString()的呼叫,在字串常量池中,沒有生成"ab"
關于String.intern()的面試題
/**
* 如何保證變數s指向的是字串常量池中的資料呢?
* 有兩種方式:
* 方式一: String s = "shkstart";//字面量定義的方式
* 方式二: 呼叫intern()
* String s = new String("shkstart").intern();
* String s = new StringBuilder("shkstart").toString().intern();
*
*/
public class StringIntern {
public static void main(String[] args) {
String s = new String("1");
String s1 = s.intern();//呼叫此方法之前,字串常量池中已經存在了"1"
String s2 = "1";
//s 指向堆空間"1"的記憶體地址
//s1 指向字串常量池中"1"的記憶體地址
//s2 指向字串常量池已存在的"1"的記憶體地址 所以 s1==s2
System.out.println(s == s2);//jdk6:false jdk7/8:false
System.out.println(s1 == s2);//jdk6: true jdk7/8:true
System.out.println(System.identityHashCode(s));//491044090
System.out.println(System.identityHashCode(s1));//644117698
System.out.println(System.identityHashCode(s2));//644117698
//s3變數記錄的地址為:new String("11")
String s3 = new String("1") + new String("1");
//執行完上一行代碼以后,字串常量池中,是否存在"11"呢?答案:不存在!!
//在字串常量池中生成"11",如何理解:jdk6:創建了一個新的物件"11",也就有新的地址,
// jdk7:此時常量中并沒有創建"11",而是創建一個指向堆空間中new String("11")的地址
s3.intern();
//s4變數記錄的地址:使用的是上一行代碼代碼執行時,在常量池中生成的"11"的地址
String s4 = "11";
System.out.println(s3 == s4);//jdk6:false jdk7/8:true
}
}
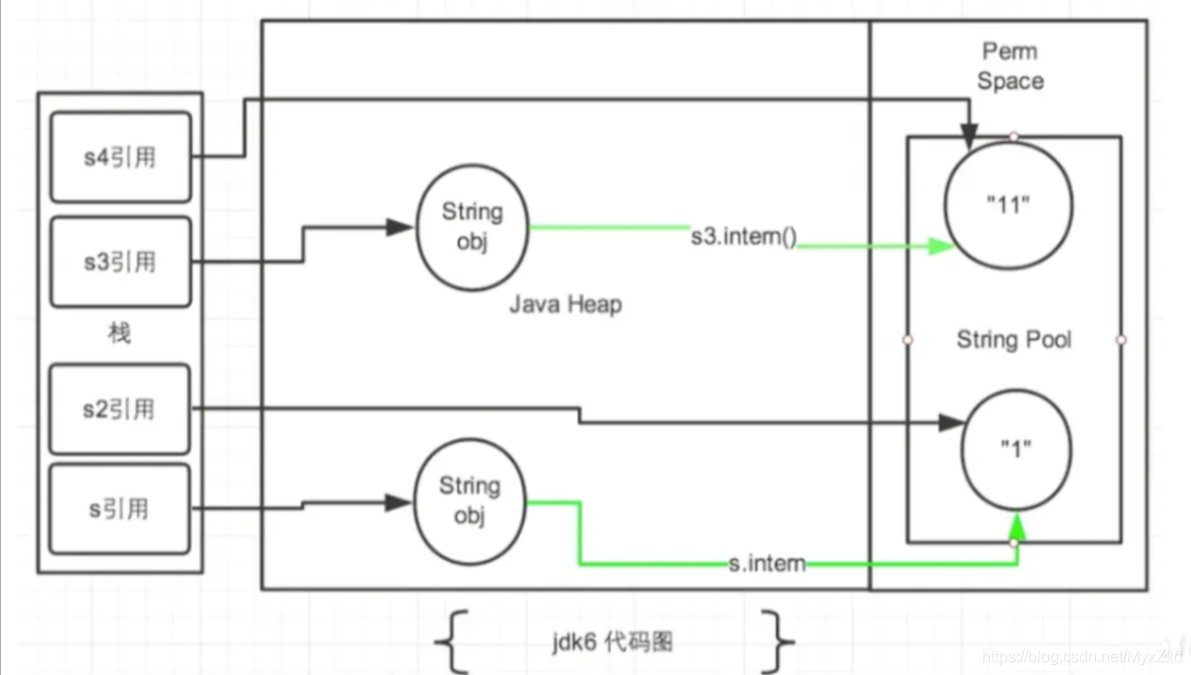
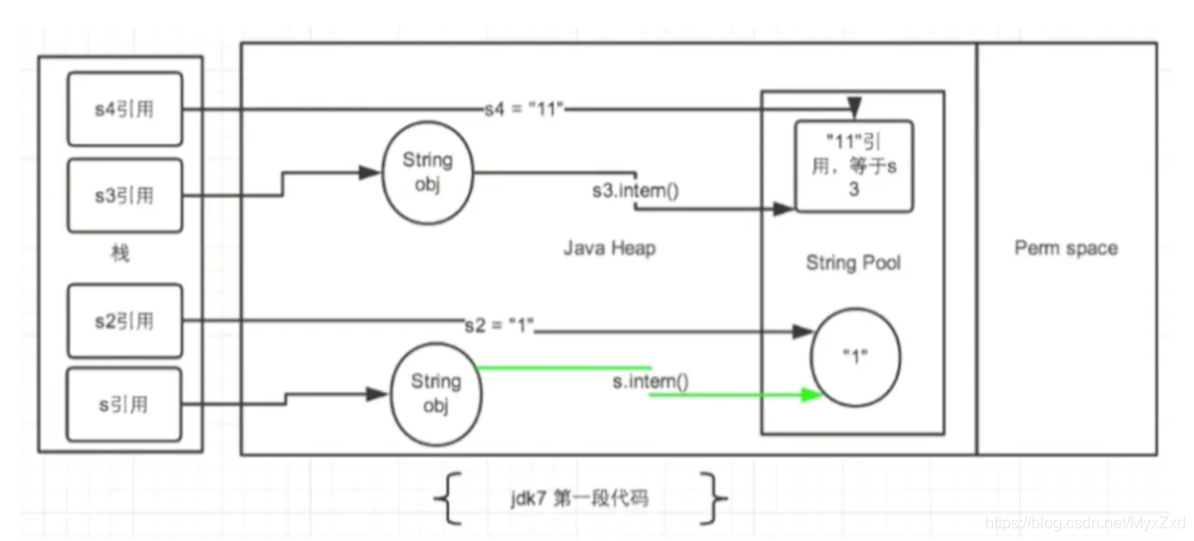
拓展
public class StringIntern1 {
public static void main(String[] args) {
//StringIntern.java中練習的拓展:
String s3 = new String("1") + new String("1");//new String("11")
//執行完上一行代碼以后,字串常量池中,是否存在"11"呢?答案:不存在!!
String s4 = "11";//在字串常量池中生成物件"11"
String s5 = s3.intern();
System.out.println(s3 == s4);//false
System.out.println(s5 == s4);//true
}
}
總結String的intern()的使用
? jdk1.6 中,將這個字串物件嘗試放入串池,
? 如果字串常量池中有,則并不會放入,回傳已有的串池中的物件的地址,
? 如果沒有,會把此物件復制一份,放入串池,并回傳串池中的物件地址,
? Jdk1.7起,將這個字串物件嘗試放入串池
? 如果字串常量池中有,則并不會放入,回傳已有的串池中的物件的地址,
? 如果沒有,則會把物件的參考地址復制一份,放入串池,并回傳串池中的參考地址,
練習
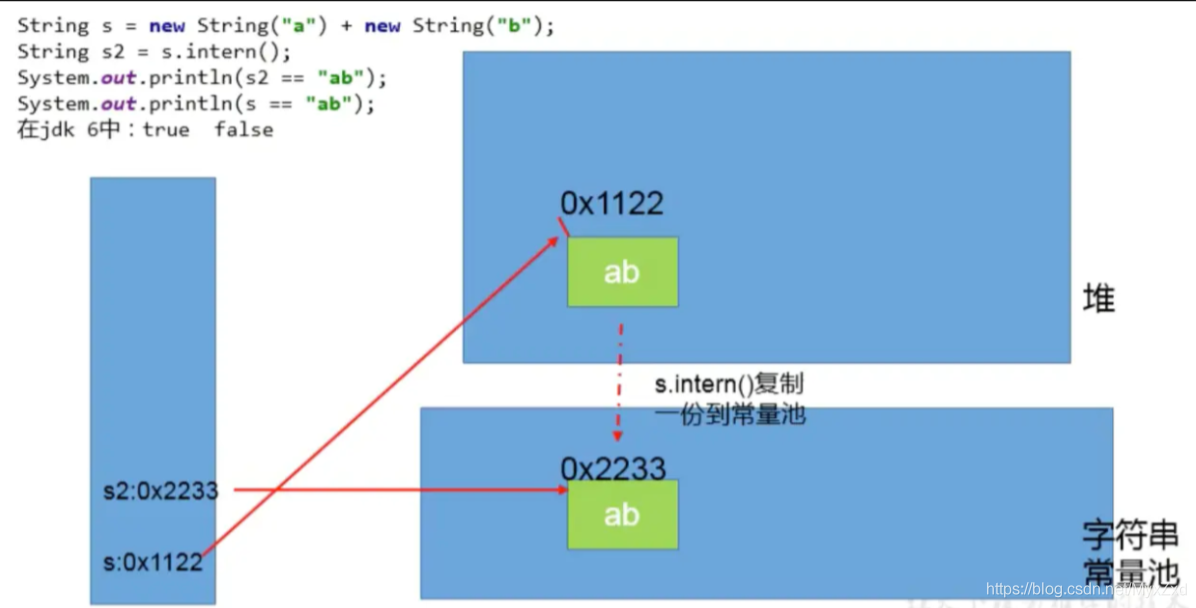
練習1
public class StringExer1 {
public static void main(String[] args) {
//String x = "ab";
String s = new String("a") + new String("b");//new String("ab")
//在上一行代碼執行完以后,字串常量池中并沒有"ab"
String s2 = s.intern();//jdk6中:在串池中創建一個字串"ab"
//jdk8中:串池中沒有創建字串"ab",而是創建一個參考,指向new String("ab"),將此參考回傳
System.out.println(s2 == "ab");//jdk6:true jdk8:true
System.out.println(s == "ab");//jdk6:false jdk8:true
}
}
jdk6
jdk7/8
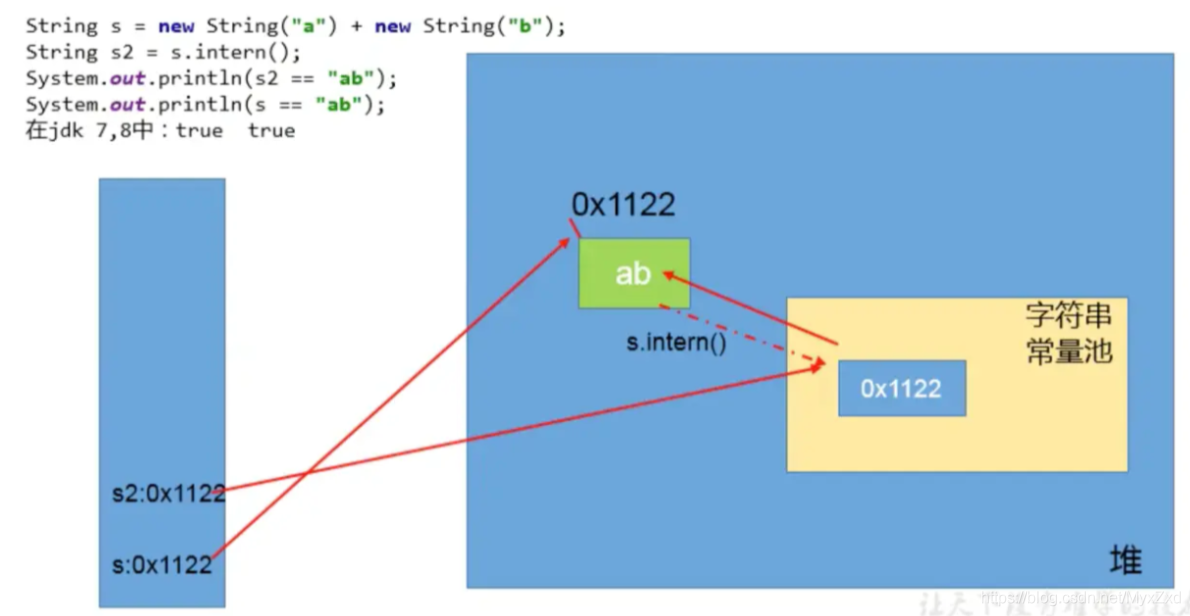
練習2
public class StringExer2 {
public static void main(String[] args) {
String s1 = new String("ab");//執行完以后,會在字串常量池中會生成"ab"
// String s1 = new String("a") + new String("b");執行完以后,不會在字串常量池中會生成"ab"
s1.intern();
String s2 = "ab";
System.out.println(s1 == s2); //false
}
}
總結
1、String的記憶體結構
String a = "a"
會直接字串常量池中有一個a
String a = new String("abc")
這個會在堆中進行創建,并且會在字串常量池中有一個abc
String a = new String("a")+ new String("b");
會生成一個StringBuilder進行字串的拼接,然后進行append方法,最后生成String(“ab”)在堆中
如果在jdk.1.6呼叫 intern方法,那么它的值會存盤在字串常量池匯總
如果1.7之后會有一個連接的地址指向堆中相應的地址
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291019.html
標籤:java
上一篇:java8特性匯總