python面試題
對于機器學習演算法工程師而言,Python是不可或缺的語言,它的優美與簡潔令人無法自拔,那么你了解過Python編程面試題嗎?今天我們就來了解一下! 1、python 下多執行緒的限制以及多行程中傳遞引數的方式
1、 python多執行緒有個全域解釋器鎖(global interpreter lock),這個鎖的意思是任一時間只能有一個執行緒使用解釋器,跟單 cpu跑多個程式一個意思,大家都是輪著用的,這叫“并發”,不是“并行”,
多行程間共享資料,可以使用 multiprocessing.Value和multiprocessing.Array, 2、什么是lambda函式?它有什么好處?
2、 lambda 函式是一個可以接收任意多個引數(包括可選引數)并且回傳單個運算式值的函式,lambda 函式不能包含命令,它們所包含的運算式不能超過一個,不要試圖向lambda 函式中塞入太多的東西;如果你需要更復雜的東西,應該定義一個普通函式,然后想讓它多長就多長,
3、Python是如何進行型別轉換的? ①函式描述
② int(x [,base ]) 將x轉換為一個整數 ③long(x [,base ]) 將x轉換為一個長整數 ④float(x ) 將x轉換到一個浮點數 ⑤complex(real [,imag ]) 創建一個復數 ⑥str(x ) 將物件 x 轉換為字串 ⑦repr(x ) 將物件 x 轉換為運算式字串
⑧eval(str ) 用來計算在字串中的有效Python運算式,并回傳一個物件 ⑨tuple(s ) 將序列 s 轉換為一個元組 ⑩list(s ) 將序列 s 轉換為一個串列 ?chr(x ) 將一個整數轉換為一個字符 ?unichr(x ) 將一個整數轉換為Unicode字符 ?ord(x ) 將一個字符轉換為它的整數值 ?hex(x ) 將一個整數轉換為一個十六進制字串 ?oct(x ) 將一個整數轉換為一個八進制字串 4、python多執行緒與多行程的區別
在UNIX平臺上,當某個行程終結之后,該行程需要被其父行程呼叫wait,否則行程成為僵尸行程(Zombie),所以,有必要對每個Process物件呼叫join()方法 (實際上等同于wait)
,對于多執行緒來說,由于只有一個行程,所以不存在此必要性,
多行程應該避免共享資源,在多執行緒中,我們可以比較容易地共享資源,比如使用全域變數或者傳遞引數,在多行程情況下,由于每個行程有自己獨立的記憶體空間,以上方法并不合適,此時我們可以通過共享記憶體和Manager的方法來共享資源,
但這樣做提高了程式的復雜度,并因為同步的需要而降低了程式的效率, 5、Python
里面如何拷貝一個物件?
標準庫中的copy模塊提供了兩個方法來實作拷貝,一個方法是copy,它回傳和引數包含內容一樣的物件,使用deepcopy方法,物件中的屬性也被復制,
6、介紹一下except的用法和作用?
Python的except用來捕獲所有例外,因為Python里面的每次錯誤都會拋出一個例外,所以每個程式的錯誤都被當作一個運行時錯誤,
7 、Python中pass陳述句的作用是什么?
pass陳述句什么也不做,一般作為占位符或者創建占位程式,pass陳述句不會執行任何操作,
8、Python解釋器種類以及特點?
Python是一門解釋器語言,代碼想運行,必須通過解釋器執行,Python存在多種解釋器,分別基于不同語言開發,每個解釋器有不同的特點,但都能正常運行Python代碼,以下是常用的五種Python解釋器:
CPython:當從Python官方網站下載并安裝好Python2.7后,就直接獲得了一個官方版本的解釋器:Cpython,這個解釋器是用C語言開發的,所以叫CPython,在命名行下運行python,就是啟動CPython解釋器,CPython是使用最廣的Python解釋器, IPython:IPython是基于CPython之上的一個互動式解釋器,也就是說,IPython只是在互動方式上有所增強,但是執行Python代碼的功能和CPython是完全一樣的,好比很多國產瀏覽器雖然外觀不同,但內核其實是呼叫了IE,
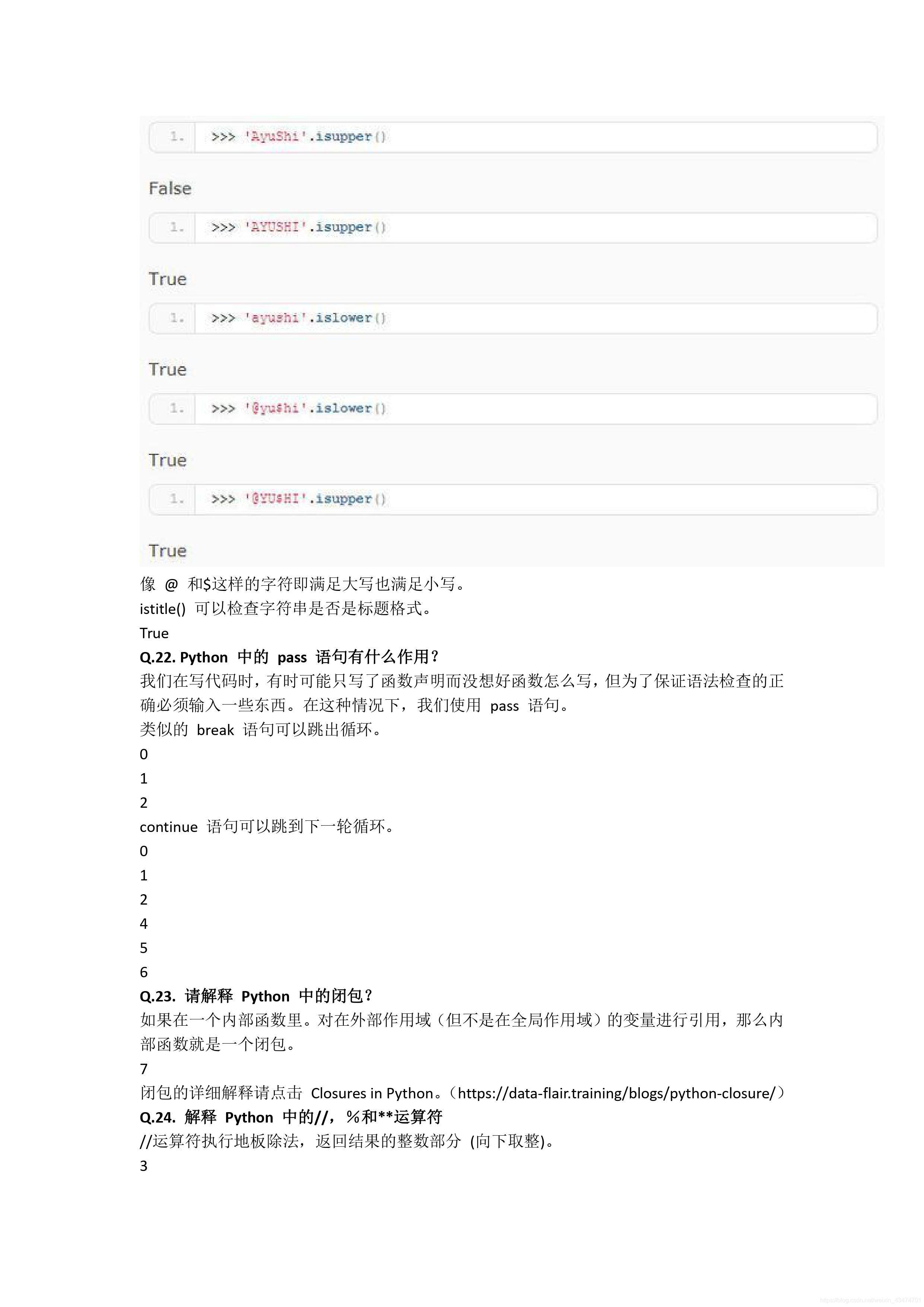
PyPy:PyPy是另一個Python解釋器,它的目標是執行速度,PyPy采用JIT技術,對Python代進行動態編譯,所以可以顯著提高Python代碼的執行速度,
Jython:Jython是運行在Java平臺上的Python解釋器,可以直接把Python代碼編譯成Java位元組碼執行,
IronPython:IronPython和Jython類似,只不過IronPython是運行在微軟.Net平臺上的Python解釋器,可以直接把Python代碼編譯成.Net的位元組碼,
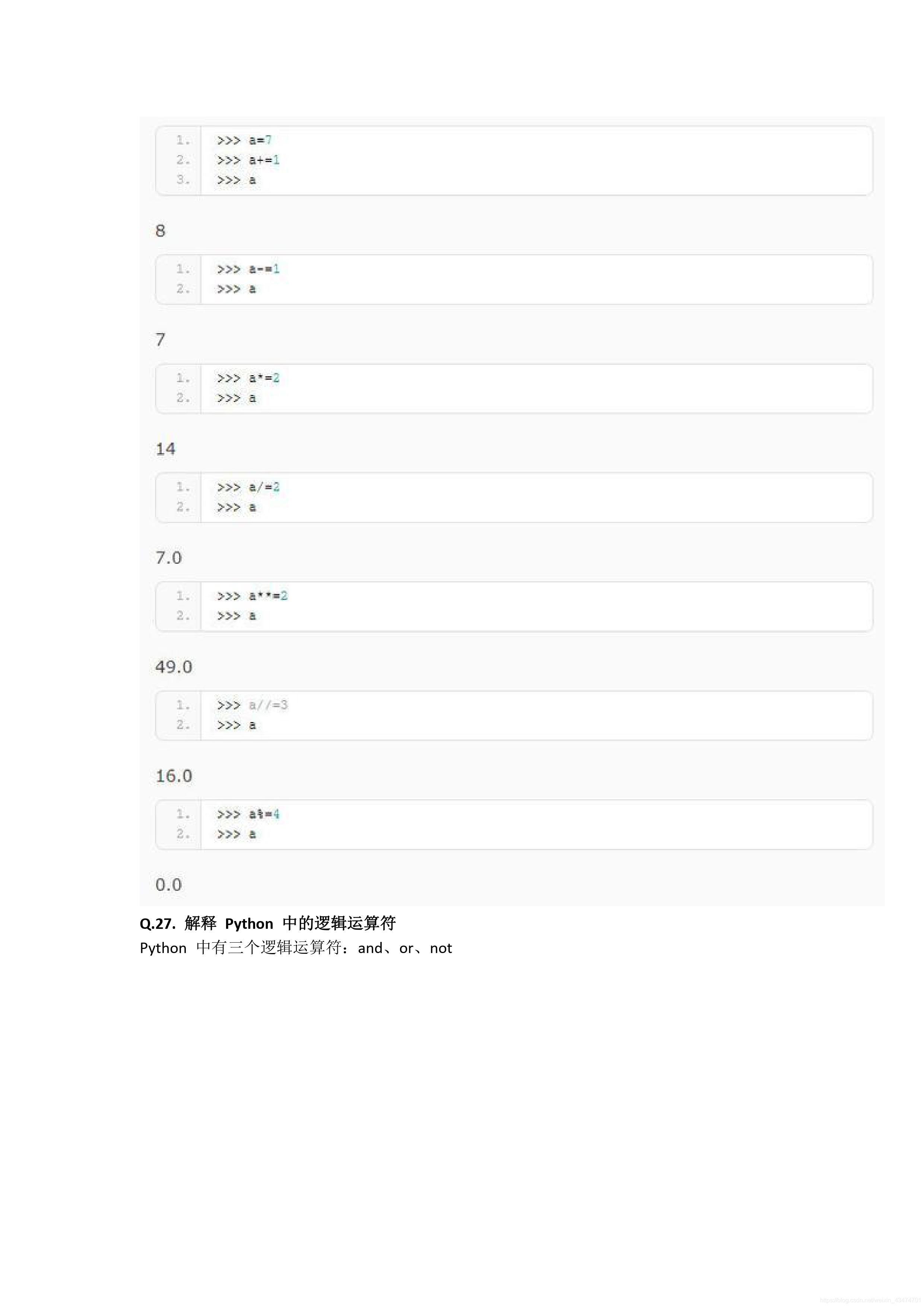
在Python的解釋器中,使用廣泛的是CPython,對于Python的編譯,除了可以采
用以上解釋器進行編譯外,技術高超的開發者還可以按照自己的需求自行撰寫Python解釋器來執行
Python代碼,十分的方便! 9、列舉布林值為
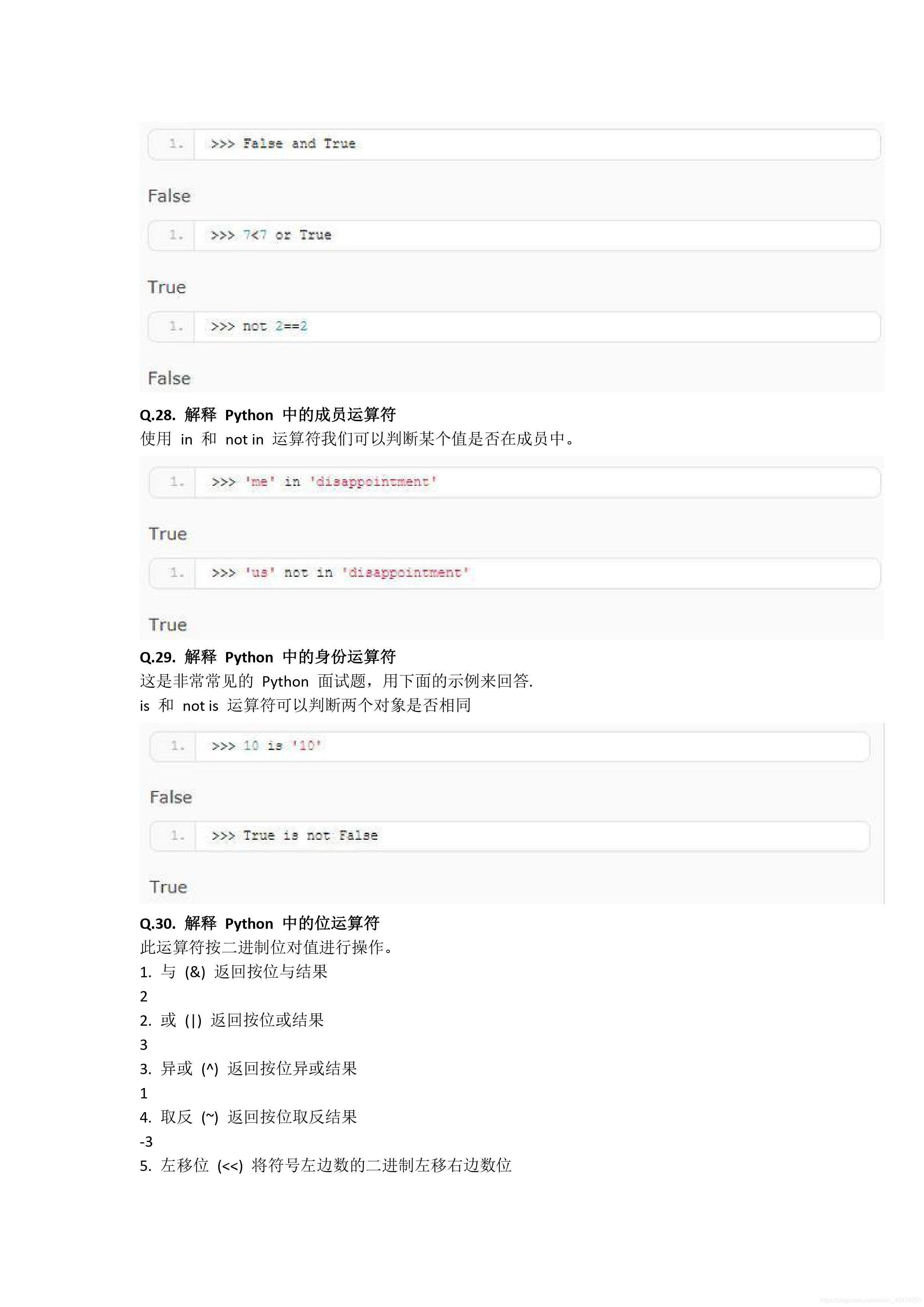
False的常見值?
0, [] , () , {} , '' , False , None 10、字串、串列、元組、字典每個常用的
5個方法?
字串:repleace,strip,split,reverse,upper,lower,join.....
串列:append,pop,,remove,sort,count,index.....
元組:index,count,__len__(),__dir__()
字典:get,keys,values,pop,popitems,clear,,items..... 11、lambda運算式格式以及應用場景?
運算式格式:lambda后面跟一個或多個引數,緊跟一個冒號,以后是一個運算式,冒號前是引數,冒號后是回傳值,例如:lambda x : 2x
應用場景:經
常與一些內置函式
相結合使用,
比如說
map(),filter(),sorted(),reduce()等
12、pass的作用?
①空陳述句do nothing;
②保證格式完整;
③保證語意完整, 13、arg
和 *kwarg作用?
萬能引數,解決了函式引數不固定的問題
*arg:會把位置引數轉化為tuple
**kwarg:會把關鍵字引數轉化為dict
14、is和==的區別?
is:判斷記憶體地址是否相等; ==:判斷數值是否相等,
15、簡述Python的深淺拷貝以及應用場景?
copy():淺copy,淺拷貝指僅僅拷貝資料集合的第一層資料 deepcopy():深copy,深拷貝指拷貝資料集合的所有層
16、Python垃圾回識訓制?
python采用的是參考計數機制為主,標記-清除和分代收集(隔代回收、分代回收)兩種機制為輔的策略 計數機制:
Python的GC模塊主要運用了參考計數來跟蹤和回收垃圾,在參考計數的基礎上,還可以通過“標記-清除”
解決容器物件可能產生的回圈參考的問題,通過分代回收以空間換取時間進一步提高垃圾回收的效率, 標記-清除:
標記-清除的出現打破了回圈參考,也就是它只關注那些可能會產生回圈參考的物件,
缺點:該機制所帶來的額外操作和需要回收的記憶體塊成正比,隔代回收:
原理:將系統中的所有記憶體塊根據其存活時間劃分為不同的集合,每一個集合就成
為一個“代”,
垃圾收集的頻率隨著“代”的存活時間的增大而減小,也就是說,活得越長的物件,就越不可能是垃圾,
就應該減少對它的垃圾收集頻率,那么如何來衡量這個存活時間:通常是利用幾次垃圾收集動作來衡量,
如果一個物件經過的垃圾收集次數越多,可以得出:該物件存活時間就越長, 17、python的可變型別和不可變型別?
不可變型別(數字、字串、元組、不可變集合);
可變型別(串列、字典、可變集合),
18、Python里面search()和match()的區別?
match()函式只檢測RE是不是在string的開始位置匹配,search()會掃描整個
string查找匹配, 也就是說match()
只有在0位置匹配成功的話才有回傳,如果不是開始位置匹配成功的話,
match()就回傳none
19、用Python匹配HTML tag的時候,<.>和<.?>有什么區別?
前者是貪婪匹配,會從頭到尾匹配 xyz,而后者是非貪婪匹配,只匹配到第一個 >,
20、Python里面如何生成亂數? import random;
random.random();
2021年最新Python面試題及答案
1、Python里面如何拷貝一個物件?(賦值,淺拷貝,深拷貝的區別)
答:賦值(=),就是創建了物件的一個新的參考,修改其中任意一個變數都會影響到另一個,
淺拷貝:創建一個新的物件,但它包含的是對原始物件中包含項的參考(如果用參考的方式修改其中一個物件,另外一個也會修改改變){1,完全切片方法;2,工廠函式,如list();3,copy模塊的copy()函式}
深拷貝:創建一個新的物件,并且遞回的復制它所包含的物件(修改其中一個,另外一個不會改變){copy模塊的()函式}
2、Python里面match()和search()的區別?
答:re模塊中match(pattern,string[,flags]),檢查string的開頭是否與pattern匹配,
re模塊中research(pattern,string[,flags]),在string搜索pattern的第一個匹配值,
print(‘super’, ‘superstition’).span())
(0, 5)print(‘super’, ‘insuperable’))
Noneprint(‘super’, ‘superstition’).span())
(0, 5)print(‘super’, ‘insuperable’).span())
(2, 7)
3、有沒有一個工具可以幫助查找python的bug和進行靜態的代碼分析?
答:PyChecker是一個python代碼的靜態分析工具,它可以幫助查找python代碼的bug, 會對代碼的復雜度和格式提出警告
Pylint是另外一個工具可以進行codingstandard檢查
4、簡要描述Python的垃圾回識訓制(garbage collection),
答案
這里能說的很多,你應該提到下面幾個主要的點:
Python在記憶體中存盤了每個物件的參考計數(reference count),如果計數值變成0,那么相應的物件就會小時,分配給該物件的記憶體就會釋放出來用作他用,
偶爾也會出現參考回圈(reference cycle),垃圾回收器會定時尋找這個回圈,并將其回收,舉個例子,假設有兩個物件o1和o2,而且符合 == o2和 == o1這兩個條件,如果o1和o2沒有其他代碼參考,那么它們就不應該繼續存在,但它們的參考計數都是1,
Python中使用了某些啟發式演算法(heuristics)來加速垃圾回收,例如,越晚創建的物件更有可能被回收,物件被創建之后,垃圾回收器會分配它們所屬的代(generation),每個物件都會被分配一個代,而被分配更年輕代的物件是優先被處理的,
5、什么是lambda函式?它有什么好處?
答:lambda 運算式,通常是在需要一個函式,但是又不想費神去命名一個函式的場合下使用,也就是指匿名函式
lambda函式:首要用途是指點短小的回呼函式
lambda [arguments]:expressiona=lambdax,y:x+y
a(3,11)
6、請寫出一段Python代碼實作洗掉一個list里面的重復元素
答:
1,使用set函式,set(list)
2,使用字典函式,a=[1,2,4,2,4,5,6,5,7,8,9,0]
b={}
b=(a)
c=list())
c
7、用Python匹配HTML tag的時候,<.>和<.?>有什么區別?
答:術語叫貪婪匹配( <.> )和非貪婪匹配(<.?> )
例如:
test
<.> :
test
<.?> :
8、如何在一個function里面設定一個全域的變數?
答:解決方法是在function的開始插入一個global宣告:
def f()
global x
9、編程用sort進行排序,然后從最后一個元素開始判斷
a=[1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
()
last=a[-1]
for i inrange(len(a)-2,-1,-1):
if last==a[i]:
del a[i]
else:last=a[i]
print(a)
10、下面的代碼在Python2中的輸出是什么?解釋你的答案
def div1(x,y):
print “%s/%s = %s” % (x, y, x/y)
def div2(x,y):
print "%s2)
div2(5,2)
div2(5.,2.)
另外,在Python3中上面的代碼的輸出有何不同(假設代碼中的print陳述句都轉化成了Python3中的語法結構)?
在Python2中,代碼的輸出是:
5/2 = 2
2 =
52結果是
注意你可以通過下面的import陳述句來覆寫Python2中的這一行為
from future import division
還要注意“雙斜杠”(//)運算子將會一直執行整除,忽略運算元的型別,這就是為什么/即使在Python2中結果也是
但是在Python3并沒有這一行為,兩個運算元都是整數時,也不執行整數運算,在Python3中,輸出如下:
5/2 =
2 =
5//2 = 2
/ =







Python基礎知識筆試
一、單選題(2.5分*20題)
-
下列哪個運算式在Python中是非法的? B
A. x = y = z = 1
B. x = (y = z + 1)
C. x, y = y, x
D. x += y
2. python my.py v1 v2 命令運行腳本,通過 from sys import argv如何獲得v2的引數值? C
A. argv[0]
B. argv[1]
C. argv[2]
D. argv[3]
3. 如何解釋下面的執行結果? B
print 1.2 - 1.0 == 0.2
False
A. Python的實作有錯誤
B. 浮點數無法精確表示
C. 布爾運算不能用于浮點數比較
D. Python將非0數視為False
4. 下列代碼執行結果是什么? D
x = 1
def change(a):
x+= 1
print x
change(x)
A. 1
B. 2
C. 3
D. 報錯
5. 下列哪種型別是Python的映射型別? D
A. str
B. list
C. tuple
D. dict
6. 下述字串格式化語法正確的是? D
A. ‘GNU’s Not %d %%’ % ‘UNIX’
B. ‘GNU’s Not %d %%’ % ‘UNIX’
C. ‘GNU’s Not %s %%’ % ‘UNIX’
D. ‘GNU’s Not %s %%’ % ‘UNIX’
7. 在Python 2.7中,下列哪種是Unicode編碼的書寫方式?C
A. a = ‘中文’
B. a = r‘中文’
C. a = u’中文’
D. a = b’中文’
8. 下列代碼的運行結果是? D
print ‘a’ < ‘b’ < ‘c’
A. a
B. b
C. c
D. True
E. False
9. 下列代碼運行結果是? C
a = ‘a’
print a > ‘b’ or ‘c’
A. a
B. b
C. c
D. True
E. False
10. 下列哪種不是Python元組的定義方式? A
A. (1)
B. (1, )
C. (1, 2)
D. (1, 2, (3, 4))
11. a與b定義如下,下列哪個是正確的? B
a = ‘123’
b = ‘123’
A. a != b
B. a is b
C. a == 123
D. a + b = 246
12. 下列對協程的理解錯誤的是? D
A. 一個執行緒可以運行多個協程
B. 協程的調度由所在程式自身控制
C. Linux中執行緒的調度由作業系統控制
D. Linux中協程的調度由作業系統控制
13. 下列哪種函式引數定義不合法? C
A. def myfunc(*args):
B. def myfunc(arg1=1):
C. def myfunc(*args, a=1):
D. def myfunc(a=1, args):
14. 下列代碼執行結果是? A
[ii for i in xrange(3)]
A. [1, 1, 4]
B. [0, 1, 4]
C. [1, 2, 3]
D. (1, 1, 4)
15. 一個段代碼定義如下,下列呼叫結果正確的是?A
def bar(multiple):
def foo(n):
return multiple ** n
return foo
A. bar(2)(3) == 8
B. bar(2)(3) == 6
C. bar(3)(2) == 8
D. bar(3)(2) == 6
16. 下面代碼運行結果? C
a = 1
try:
a += 1
except:
a += 1
else:
a += 1
finally:
a += 1
print a
A. 2
B. 3
C. 4
D. 5
17. 下面代碼運行后,a、b、c、d四個變數的值,描述錯誤的是? D
import copy
a = [1, 2, 3, 4, [‘a’, ‘b’]]
b = a
c = copy.copy(a)
d = copy.deepcopy(a)
a.append(5)
a[4].append(‘c’)
A. a == [1,2, 3, 4, [‘a’, ‘b’, ‘c’], 5]
B. b == [1,2, 3, 4, [‘a’, ‘b’, ‘c’], 5]
C. c == [1,2, 3, 4, [‘a’, ‘b’, ‘c’]]
D. d == [1,2, 3, 4, [‘a’, ‘b’, ‘c’]]
18. 有如下函式定義,執行結果正確的是? A
def dec(f):
n = 3
def wrapper(*args,**kw):
return f(*args,**kw) * n
return wrapper
@dec
def foo(n):
return n * 2
A. foo(2) == 12
B. foo(3) == 12
C. foo(2) == 6
D. foo(3) == 6
19. 有如下類定義,下列描述錯誤的是? D
class A(object):
pass
class B(A):
pass
b = B()
A. isinstance(b, A) == True
B. isinstance(b, object) == True
C. issubclass(B, A) == True
D. issubclass(b, B) == True
20. 下列代碼運行結果是? C
a = map(lambda x: x**3, [1, 2, 3])
list(a)
A. [1, 6, 9]
B. [1, 12, 27]
C. [1, 8, 27]
D. (1, 6, 9)
二、多選題(5分5題)
21. Python中函式是物件,描述正確的是? ABCD
A. 函式可以賦值給一個變數
B. 函式可以作為元素添加到集合物件中
C. 函式可以作為引數值傳遞給其它函式
D. 函式可以當做函式的回傳值
22. 若 a = range(100),以下哪些操作是合法的? ABCD
A. a[-3]
B. a[2:13]
C. a[::3]
D. a[2-3]
23. 若 a = (1, 2, 3),下列哪些操作是合法的? ABD
A. a[1:-1]
B. a3
C. a[2] = 4
D. list(a)
24. Python中單下劃線_foo與雙下劃線__foo與__foo__的成員,下列說法正確的是?ABC
A. _foo 不能直接用于’from module import ’
B. __foo決議器用_classname__foo來代替這個名字,以區別和其他類相同的命名
C. __foo__代表python里特殊方法專用的標識
D. __foo 可以直接用于’from module import ’
25. __new__和__init__的區別,說法正確的是? ABCD
A. new__是一個靜態方法,而__init__是一個實體方法
B. new__方法會回傳一個創建的實體,而__init__什么都不回傳
C. 只有在__new__回傳一個cls的實體時,后面的__init__才能被呼叫
D. 當創建一個新實體時呼叫__new,初始化一個實體時用__init
三、填空題(5分5題)
26. 在Python 2.7中,執行下列陳述句后,顯示結果是什么? 答:0 0.5
from future importdivision
print 1//2, 1/2
27. 在Python 2.7中,執行下列陳述句后的顯示結果是什么? 答:none 0
a = 1
b = 2 * a / 4
a = “none”
print a,b
28. 下列陳述句執行結果是什么? 答:[1, 2, 3, 1, 2, 3, 1, 2, 3]
a = [1, 2, 3]
print a3
29. 下列陳述句的執行結果是什么? 答:3
a = 1
for i in range(5):
if i == 2:
break
a += 1
else:
a += 1
print a
30. 下列代碼的運行結果是多少? 答:4
def bar(n):
m = n
while True:
m += 1
yield m
b = bar(3)
print b.next()
附錄:Python常見面試題精選
一、 基礎知識(7題)
題01:Python中的不可變資料型別和可變資料型別是什么意思?
難度: ★☆☆☆☆【參考答案】
不可變資料型別是指不允許變數的值發生變化,如果改變了變數的值,相當于是新建了一個物件,而對于相同的值的物件,在記憶體中則只有一個物件(一個地址),數值型、字串string和元組tuple都屬于不可變資料型別,
可變資料型別是指允許變數的值發生變化,即如果對變數執行append、+=等操作,只會改變變數的值,而不會新建一個物件,變數參考的物件的地址也不會變化,不過對于相同的值的不同物件,在記憶體中會存在不同的物件,即每個物件都有自己的地址,相當于記憶體中對于同值的物件保存了多份,這里不存在參考計數,是實實在在的物件,串列list和字典dict都屬于可變資料型別,
題02:請簡述Python中is和==的區別,
難度:★★☆☆☆ 【參考答案】
Python中的物件包含三個要素:id、type和value,is比較的是兩個物件的id,==比較的是兩個物件的value,
題03:請簡述function(args, **kwargs)中的 args, kwargs分別是什么意思?
難度:★★☆☆☆ 【參考答案】
*args和kwargs主要用于函式定義的引數,Python語言允許將不定數量的引數傳給一個函式,其中args表示一個非鍵值對的可變引數串列,kwargs則表示不定數量的鍵值對引數串列,注意:*args和kwargs可以同時在函式的定義中,但是args必須在**kwargs前面,
題04:請簡述面向物件中__new__和__init__的區別,
難度: ★★★☆☆【參考答案】
(1)__new__至少要有一個引數cls,代表當前類,此引數在實體化時由Python解釋器自動識別,
(2) __new__回傳生成的實體,可以回傳父類(通過super(當前類名, cls)的方式)__new__出來的實體,
或者直接是物件的__new__出來的實體,這在自己編程實作__new__時要特別注意,
(3) __init__有一個引數self,就是這個__new__回傳的實體,__init__在__new__的基礎上可以完成一
些其它初始化的動作,init__不需要回傳值,
(4) 如果__new__創建的是當前類的實體,會自動呼叫__init,通過回傳陳述句里面呼叫的__new__函
數的第一個引數是cls來保證是當前類實體,如果是其他類的類名,那么實際創建并回傳的就是其他類的實體,也就不會呼叫當前類或其他類的__init__函式,
題05:Python子類繼承自多個父類時,如多個父類有同名方法,子類將繼承自哪個方法?
難度:★☆☆☆☆
【參考答案】
Python語言中子類繼承父類的方法是按照繼承的父類的先后順序確定的,例如,子類A繼承自父類B、C,且B、C中具有同名方法Test(),那么A中的Test()方法實際上是繼承自B中的Test()方法,
題06:請簡述Python中如何避免死鎖?
難度:★☆☆☆☆
【參考答案】
死鎖是指不同執行緒獲取了不同的鎖,但是執行緒間又希望獲取對方的鎖,雙方都在等待對方釋放鎖,這種相互等待資源的情況就是死鎖,Python語言可以使用threading.Condition物件,基于條件事件通知的形式去協調執行緒的運行,即可避免死鎖,
題07:什么是排序演算法的穩定性?常見的排序演算法如冒泡排序、快速排序、歸并排序、堆排
序、Shell排序、二叉樹排序等的時間、空間復雜度和穩定性如何?
難度:★★★☆☆
【參考答案】
假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序演算法是穩定的;否則稱為不穩定的,
常見排序演算法的時間、空間復雜度和穩定性如下表所示,
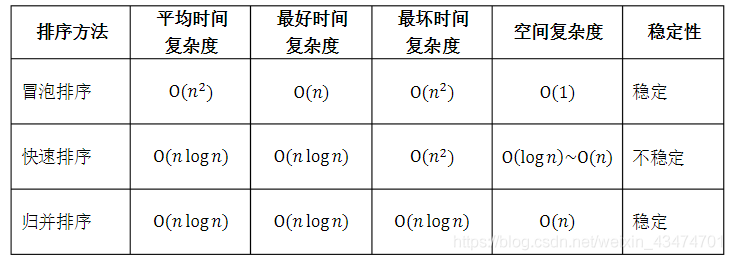
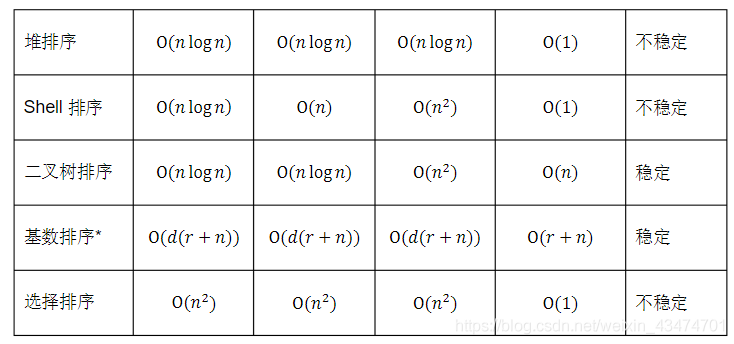
*基數排序的復雜度中,r表示關鍵字的基數,d表示長度,n表示關鍵字的個數,
二、 字串與數字(7題)
題08:字串內容去重并按字母順序排列,
難度:★☆☆☆☆
令 s = “hfkfdlsahfgdiuanvzx”,試對 s 去重并按字母順序排列輸出 “adfghiklnsuvxz”,
【參考答案】
s = "hfkfdlsahfgdiuanvzx"
s = list(set(s)) s.sort(reverse=False) print("".join(s))
題09:判斷兩個字串是否同構,
難度:★★☆☆☆
字串同構是指字串s中的所有字符都可以替換為t中的所有字符,在保留字符順序的同時,必須用另一個字符替換所有出現的字符,不能將s中的兩個字符映射到t中同一個字符,但字符可以映射到自身,試判定給定的字串s和t是否同構, 例如: s = “add” t = “apple” 輸出 False s = “paper” t = “title”
輸出
True 【參考答案】
print(len(set(s)) == len(set(t)) == len(set(zip(s, t))))
題10:使用Lambda運算式實作將IPv4的地址轉換為int型整數,
難度:★★★☆☆
例如:ip2int(“192.168.3.5”) 輸出:
3232236293
【參考答案】
ip2int = lambda x:sum([256**j*int(i) for j,i in enumerate(x.split('.')[::-1])])
題11:羅馬數字使用字母表示特定的數字,試撰寫函式romanToInt(),輸入羅馬數字字符
串,輸出對應的阿拉伯數字,
難度:★★★☆☆
【參考答案】
羅馬數字中字母與阿拉伯數字的對應關系如下:
M:1000,CM:900,D:500,CD:400,C:100,XC:90,L:50,XL: 40,X:10,IX:9,V:5,VI:4,I:1
def romanToInt(s):
table = {'M':1000, 'CM':900, 'D':500, 'CD':400, 'C':100, 'XC':90, 'L':50, 'XL': 40, 'X':10, 'IX':9, 'V':5, 'VI':4, 'I':1} result = 0
for i in range(len(s)):
if i > 0 and table[s[i]] > table[s[i-1]]: result += table[s[i]] result -= 2 * table[s[i-1]] else:
result += table[s[i]] return result
題12:判斷括號是否成對,
難度:★★★☆☆
給定一個只包含字符“(”“)”“{”“}”“[”和“]”的字串,試撰寫函式isParenthesesValid(),輸入該字串,確定輸入的字串是否有效,括號必須以正確的順序關閉,例如“()”和“()[]{}”都是有效的,但“(]”和“([]]”不是,
【參考答案】
def isParenthesesValid(s): pars = [None]
parmap = {')': '(', '}': '{', ']': '['} for c in s:
if c in parmap:
if parmap[c] != pars.pop(): return False else:
pars.append(c) return len(pars) == 1
題13:撰寫函式輸出count-and-say序列的第n項,
難度:★★★★☆
count-and-say序列是一個整數序列,其前五個元素如下: 1 11 21
1211 111221
1讀作“1”或11,11讀作“兩個1”或21,21讀作“一個2,然后一個1”或1211,即下一項是將上一項“讀出來”再寫成數字,
試撰寫函式CountAndSay(n),輸出count-and-say序列的第n項, 【參考答案】
def CountAndSay(n): ans = "1" n -= 1 while n > 0: res = "" pre = ans[0] count = 1
for i in range(1, len(ans)): if pre == ans[i]: count += 1 else:
res += str(count) + pre pre = ans[i] count = 1 res += str(count) + pre ans = res
n -= 1 return ans
題14:不使用sqrt
函式,試撰寫squareRoot()函式,輸入一個正數,輸出它的平方根的整
數部分
難度:★★★★☆ 【參考答案】
def squareRoot(x): result = 1.0
while abs(result * result - x) > 0.1: result = (result + x / result) / 2
return int(result)
三、 正則運算式(4題)
題15:請寫出匹配中國大陸手機號且結尾不是4和7的正則運算式,
難度:★☆☆☆☆ 【參考答案】
import re
tels = [“159********”, “14456781234”, “12345678987”, “11444777”] for tel in tels:
print(“Valid”) if (re.match(r"1\d{9}[0-3,5-6,8-9]", tel) != None) else print(“Invalid”)
題16:請寫出以下代碼的運行結果,
難度:★★☆☆☆
import re
str = '<div class="nam">中國</div>'
res = re.findall(r'<div class=".*">(.*?)</div>',str) print(res)
結果如下: 【參考答案】
['中國 ']
題17:請寫出以下代碼的運行結果,
難度:★★★☆☆
import re
match = re.compile('www\....?').match("www.baidu.com") if match:
print(match.group()) else:
print("NO MATCH")
【參考答案】
www.bai
題18:請寫出以下代碼的運行結果,
難度:★★☆☆☆
import re
example = "<div>test1</div><div>test2</div>" Result = re.compile("<div>.*").search(example)
print("Result = %s" % Result.group())
【參考答案】
Result =
四、 串列、字典、元組、陣列、矩陣(9題)
題19:使用遞推式將矩陣轉換為一維向量,
難度:★☆☆☆☆ 使用遞推式將 [[ 1, 2 ], [ 3, 4 ], [ 5, 6 ]]
轉換為
[1, 2, 3, 4, 5, 6], 【參考答案】
a = [[1, 2], [3, 4], [5, 6]] print([j for i in a for j in i])
題20:寫出以下代碼的運行結果,
難度:★★★★☆
def testFun():
temp = [lambda x : i*x for i in range(5)]
return temp
for everyLambda in testFun(): print (everyLambda(3))
結果如下: 【參考答案】
12 12 12 12 12
題21:撰寫Python程式,列印星號金字塔,
難度:★★★☆☆
撰寫盡量短的Python程式,實作列印星號金字塔,例如n=5時輸出以下金字塔圖形:
*
*** ***** ******* *********
參考代碼如下: 【參考答案】
n = 5
for i in range(1,n+1):
print(' '*(n-(i-1))+'*'*(2*i-1))
題22:獲取陣列的支配點,
難度:★★★☆☆
支配數是指陣列中某個元素出現的次數大于陣列元素總數的一半時就成為支配數,其所在下標稱為支配點,撰寫Python
函式FindPivot(li),輸入陣列,輸出其中的支配點和支配數,若陣列中不存在支配數,輸出None,
例如:[3,3,1,2,2,1,2,2,4,2,2,1,2,3,2,2,2,2,2,4,1,3,3]中共有23個元素,其中元素2出現了12次,其支配點和支配陣列合是(18, 2), 【參考答案】
def FindPivot(li): mid = len(li)/2 for l in li: count = 0 i = 0 mark = 0 while True: if l == li[i]: count += 1 temp = i i += 1
if count > mid: mark = temp
return (mark, li[mark]) if i > len(li) - 1: break
題23:將函式按照執行效率高低排序
難度:★★★☆☆
有如下三個函式,請將它們按照執行效率高低排序,
def S1(L_in):
l1 = sorted(L_in)
l2 = [i for i in l1 if i<0.5] return [i*i for i in l2]
def S2(L_in):
l1 = [i for i in L_in if i<0.5] l2 = sorted(l1)
return [i*i for i in l2]
def S3(L_in):
l1 = [i*i for i in L_in] l2 = sorted(l1)
return [i for i in l2 if i<(0.5*0.5)]
【參考答案】
使用cProfile庫即可測驗三個函式的執行效率:
import random import cProfile
L_in = [random.random() for i in range(1000000)]
cProfile.run('S1(L_in)') cProfile.run('S2(L_in)') cProfile.run('S3(L_in)')
從結果可知,執行效率從高到低依次是S2、S1、S3,
題24:螺旋式回傳矩陣的元素
難度:★★★★★
給定m×n個元素的矩陣(m行,n列),撰寫Python
函式spiralOrder(matrix),以螺旋順序回傳矩陣的所有元素,
例如,給定以下矩陣: [[ 1, 2, 3 ], [ 4, 5, 6 ], [ 7, 8, 9 ]]
應該回傳[1,2,3,6,9,8,7,4,5]
【參考答案】
def spiralOrder(matrix):
if len(matrix) == 0 or len(matrix[0]) == 0: return [] ans = []
left, up, down, right = 0, 0, len(matrix) - 1, len(matrix[0]) - 1 while left <= right and up <= down: for i in range(left, right + 1): ans += matrix[up][i], up += 1
for i in range(up, down + 1): ans += matrix[i][right], right -= 1
for i in reversed(range(left, right + 1)): ans += matrix[down][i], down -= 1
for i in reversed(range(up, down + 1)): ans += matrix[i][left], left += 1
return ans[:(len(matrix) * len(matrix[0]))]
題25:矩陣重整
難度:★★★★☆
對于一個給定的二維陣串列示的矩陣,以及兩個正整數r和c,分別表示所需重新整形矩陣的行數和列數,reshape函式生成一個新的矩陣,并且將原矩陣的所有元素以與原矩陣相同的行遍歷順序填充進去,將該矩陣重新整形為一個不同大小的矩陣但保留其原始資料,對于給定矩陣和引數的reshape操作是可以完成且合法的,則輸出新的矩陣;否則,輸出原始矩陣,請使用Python語言實作reshape函式, 例如:
輸入
r, c 輸出
說明
nums = [[1,2], [3,4]] r = 1,c =
4 [[1,2,3,4]]
行遍歷的是[1,2,3,4],新的重新形狀矩陣是1 * 4矩陣,使用前面的串列逐行填充,
nums = [[1,2], [3,4]]
r = 2,c =
4
[[1,2], [3,4]]
無法將2 * 2矩陣重新整形為2 * 4矩陣,所以輸出原始矩陣,
注意:給定矩陣的高度和寬度在[1,100]范圍內,給定的r和c都是正數,
【參考答案】
def matrixReshape(nums, r, c): """
if r * c != len(nums) * len(nums[0]): return nums m = len(nums) n = len(nums[0])
ans = [[0] * c for _ in range(r)] for i in range(r * c):
ans[i / c][i % c] = nums[i / n][i % n] return ans
題26:查找矩陣中第k個最小元素,
難度:★★★★☆
給定n×n矩陣,其中每行每列元素均按升序排列,試撰寫Python函式kthSmallest(matrix, k),找到矩陣中的第k個最小元素,
注意:查找的是排序順序中的第k個最小元素,而不是第k個不同元素, 例如: 矩陣= [[1,5,9], [10,11,13], [12,13,15]] k = 8,應回傳13,
【參考答案】
import heapq
def kthSmallest(matrix, k): visited = {(0, 0)}
heap = [(matrix[0][0], (0, 0))]
while heap:
val, (i, j) = heapq.heappop(heap) k -= 1 if k == 0: return val
if i + 1 < len(matrix) and (i + 1, j) not in visited:
heapq.heappush(heap, (matrix[i + 1][j], (i + 1, j))) visited.add((i + 1, j))
if j + 1 < len(matrix) and (i, j + 1) not in visited: heapq.heappush(heap, (matrix[i][j + 1], (i, j + 1))) visited.add((i, j + 1))
題27:試撰寫函式largestRectangleArea(),求一幅柱狀圖中包含的最大矩形的面積,
難度:★★★★★ 例如對于下圖:
輸入:[2,1,5,6,2,3] 輸出:10
【參考答案】
def largestRectangleArea(heights): stack=[] i=0 area=0
while i<len(heights):
if stack==[] or heights[i]>heights[stack[len(stack)-1]]: # 遞增直接入堆疊
stack.append(i) else: # 不遞增開始彈堆疊
curr=stack.pop() if stack == []: width = i else:
width = i-stack[len(stack)-1]-1 area=max(area,width*heights[curr]) i-=1 i+=1
while stack != []: curr = stack.pop() if stack == []: width = i else:
width = len(heights)-stack[len(stack)-1]-1 area = max(area,width*heights[curr]) return area
五、 設計模式(3
題)
題28:使用Python語言實作單例模式,
難度:★★★☆☆
【參考答案】
class Singleton(object):
def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kw) return cls._instance
題29:使用Python語言實作工廠模式,
難度:★★★★☆
撰寫適當的Python程式,完成以下功能: 1. 定義基類Person,含有獲取名字,性別的方法, 2. 定義Person類的兩個子類Male和Female,含有打招呼的方法, 3. 定義工廠類,含有getPerson方法,接受兩個輸入引數:名字和性別, 4. 用戶通過呼叫getPerson方法使用工廠類,
【參考答案】
class Person:
def __init__(self): self.name = None self.gender = None
def getName(self): return self.name
def getGender(self): return self.gender
class Male(Person):
def __init__(self, name): print("Hello Mr." + name)
class Female(Person):
def __init__(self, name): print("Hello Miss." + name)
class Factory:
def getPerson(self, name, gender): if(gender == 'M'): return Male(name) if(gender == 'F'): return Female(name)
if __name__ == '__main__': factory = Factory()
person = factory.getPerson("Huang", "M")
題30:使用Python語言實作觀察者模式,
難度:★★★★★
給定一個數字,現有的默認格式化顯示程式以十進制格式顯示此數字,請撰寫適當的Python程式,實作支持添加(注冊)更多的格式化程式(如添加一個十六進制格式化程式和一個二進制格式化程式),每次數值更新時,已注冊的程式就會收到通知,并顯示更新后的值,
【參考答案】
import itertools class Publisher: def __init__(self): self.observers = set()
def add(self, observer, *observers):
for observer in itertools.chain((observer, ), observers): self.observers.add(observer)
observer.update(self)
def remove(self, observer): try:
self.observers.discard(observer) except ValueError:
print('移除 {} 失敗!'.format(observer))
def notify(self):
[observer.update(self) for observer in self.observers]
class DefaultFormatter(Publisher): def __init__(self, name): Publisher.__init__(self) self.name = name self._data = 0
def __str__(self):
return "{}: '{}' 的值 = {}".format(type(self).__name__, self.name, self._data)
@property def data(self): return self._data
@data.setter
def data(self, new_value): try:
self._data = int(new_value) except ValueError as e: print('錯誤: {}'.format(e)) else:
self.notify()
class HexFormatter:
def update(self, publisher):
print("{}: '{}' 的十六進制值 = {}".format(type(self).__name__, publisher.name, hex(publisher.data)))
class BinaryFormatter:
def update(self, publisher):
print("{}: '{}' 的二進制值 = {}".format(type(self).__name__, publisher.name, bin(publisher.data)))
def main():
df = DefaultFormatter('test1') print(df)
hf = HexFormatter()
df.add(hf) df.data = 37 print(df)
bf = BinaryFormatter() df.add(bf) df.data = 23 print(df)
df.remove(hf) df.data = 56 print(df)
df.remove(hf) df.add(bf)
df.data = 'hello' print(df)
df.data = 7.2 print(df)
if __name__ == '__main__': main()
六、 樹、二叉樹、圖(5題)
題31:使用Python撰寫實作二叉樹前序遍歷的函式preorder(root, res=[]),
難度:★★☆☆☆ 【參考答案】
def preorder(root, res=[]): if not root: return
res.append(root.val) preorder(root.left,res) preorder(root.right,res) return res
題32:使用Python實作一個二分查找函式,
難度:★★★☆☆
【參考答案】
def binary_search(num_list, x): num_list = sorted(num_list) left, right = 0, len(num_list) - 1 while left <= right:
mid = (left + right) // 2 if num_list[mid] > x: right = mid - 1 elif num_list[mid] < x: left = mid + 1 else:
return '待查元素{0}在排序后串列中的下標為:
{1}'.format(x, mid) return '待查找元素%s不存在指定串列中' %x
題
33:撰寫Python函式maxDepth(),實作獲取二叉樹root最大深度,
難度:★★★★☆ 【參考答案】
def maxDepth(self, root): if root == None: return 0
return max(self.maxDepth(root.left),self.maxDepth(root.right))+1
題34:輸入兩棵二叉樹Root1、Root2,判斷Root2是否Root1的子結構(子樹),
難度:★★★★☆ 【參考答案】
class TreeNode:
def __init__(self, x): self.val = x self.left = None self.right = None
def istree(pRoot1, pRoot2): if not pRoot2: return True
if not pRoot1 and pRoot2: return False
if pRoot1.val != pRoot2.val: return False
elif pRoot1.val == pRoot2.val:
return istree(pRoot1.left, pRoot2.left) and istree(pRoot1.right, pRoot2.right)
def HasSubtree(pRoot1, pRoot2): if not pRoot1 or not pRoot2: return False
if pRoot1.val == pRoot2.val: return istree(pRoot1, pRoot2) else:
return HasSubtree(pRoot1.left, pRoot2) or HasSubtree(pRoot1.right, pRoot2)
題35:判斷陣列是否某棵二叉搜索樹后序遍歷的結果,
難度:★★★★☆
撰寫函式VerifySquenceOfBST(sequence),實作以下功能:輸入一個整數陣列,判斷該陣列是不是某二叉搜索樹的后序遍歷的結果,如果是則輸出True,否則輸出False,假設輸入陣列的任意兩個數字都互不相同, 【參考答案】
def VerifySquenceOfBST(sequence): if not sequence:
return False i= 0
for i in range(len(sequence)-1):
if sequence[i]>sequence[-1]: break
if i < len(sequence)-2:
for j in range(i+1,len(sequence)-1): if sequence[j]<sequence[-1]: return False left = True right = True if i>0:
left = VerifySquenceOfBST(sequence[:i]) elif i< len(sequence)-2:
right = VerifySquenceOfBST(sequence[i:-1]) return left and right
七、 檔案操作(3題)
題36:計算test.txt中的大寫字母數,
難度:★☆☆☆☆ 【參考答案】
import os os.chdir('D:\\')
with open('test.txt') as test: count = 0
for i in test.read(): if i.isupper(): count+=1
print(count)
題37:補全缺失的代碼,
難度:★★☆☆☆
def print_directory_contents(sPath): # 補充該函式的實作代碼
print_directory_contents()函式接受檔案夾路徑名稱作為輸入引數,回傳其中包含的所有子檔案夾和檔案的完整路徑,
【參考答案】
def print_directory_contents(sPath): import os
for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath,sChild) if os.path.isdir(sChildPath):
print_directory_contents(sChildPath) else:
print(sChildPath)
題38:設計記憶體中的檔案系統,
難度:★★★★☆
使用Python語言設計記憶體中的檔案系統,實作以下命令,
ls:給定字串格式的路徑,如果是檔案路徑,則回傳僅包含此檔案名稱的串列,如果是目錄路徑,則回傳此目錄中的檔案和目錄名稱串列,輸出結果(檔案和目錄名稱)應按字典順序排列,
mkdir:如果目錄路徑不存在,則應根據路徑創建新目錄,如果路徑中的中間目錄也不存在,則也應該創建它們,此函式具有void回傳型別, 注:
可以假設所有檔案或目錄路徑都是以/開頭并且不以/結尾的絕對路徑,除了路徑只是“/”, 可以假設所有操作都將傳遞有效引數,用戶不會嘗試檢索檔案內容或列出不存在的目錄或檔案, 可以假設所有目錄名稱和檔案名只包含小寫字母,并且同一目錄中不存在相同的名稱,
【參考答案】
class FileNode(object): def __init__(self, name): self.isFolder = True self.childs = {} self.name = name self.data = ""
class FileSystem(object): def __init__(self):
self.root = FileNode("/")
def ls(self, path):
fd = self.lookup(path, False) if not fd: return [] if not fd.isFolder: return [fd.name] files = []
for file in fd.childs: files.append(file) files.sort() return files
def lookup(self, path, isAutoCreate): path = path.split("/") p = self.root for name in path: if not name: continue
if name not in p.childs: if isAutoCreate:
p.childs[name] = FileNode(name) else:
return None p = p.childs[name] return p
def mkdir(self, path):
self.lookup(path, True) # 測驗
obj = FileSystem() obj.mkdir("/test/path") obj.ls("/test")
八、 網路編程(4題)
題39:請至少說出三條TCP和UDP協議的區別,
難度:★★☆☆☆
【參考答案】
(1) TCP面向連接(如打電話要先撥號建立連接);UDP是無連接的,即發送資料之前不需要建立連
接,
(2) TCP提供可靠的服務,也就是說,通過TCP連接傳送的資料,無差錯,不丟失,不重復,且按序
到達;UDP盡最大努力交付,即不保證可靠交付,
(3) TCP面向位元組流,實際上是TCP把資料看成一連串無結構的位元組流;UDP是面向報文的,UDP沒
有擁塞控制,因此網路出現擁塞不會使源主機的發送速率降低(對實時應用很有用,如IP電話,實時視頻會議等),
(4) 每一條TCP連接只能是點到點的;UDP支持一對一,一對多,多對一和多對多的互動通信, (5) TCP首部開銷20位元組;UDP的首部開銷小,只有8個位元組,
(6) TCP的邏輯通信信道是全雙工的可靠信道,UDP則是不可靠信道,
題40:請簡述Cookie和Session的區別,
難度:★☆☆☆☆
【參考答案】
(1) Session在服務器端,Cookie在客戶端(瀏覽器),
(2) Session可以存放在檔案、資料庫或記憶體中,默認以檔案方式保存, (3) Session的運行依賴Session ID,而Session ID保存在Cookie中,因此,如果瀏覽器禁用了Cookie,
同時Session也會失效,
題41:請簡述向服務器端發送請求時的GET方式與POST方式的區別,
難度:★☆☆☆☆
【參考答案】
(1) 在瀏覽器回退時GET方式沒有變化,而POST會再次提交請求, (2) GET請求會被瀏覽器主動快取,而POST不會,除非手動設定, (3) GET請求只能進行URL編碼,而POST支持多種編碼方式,
(4) GET請求引數會被完整保留在瀏覽器歷史記錄里,而POST中的引數不會被保留, (5) 對引數的資料型別,GET只接受ASCII字符,而POST沒有限制,
(6) GET比POST更不安全,因為引數直接暴露在URL上,所以不能用來傳遞敏感資訊,
(7) GET引數通過URL傳遞且傳送的引數是有長度限制的,POST放在Request body中且長度沒有
限制,
(8) 對于GET方式的請求,瀏覽器會把http header和data一并發送出去,服務器回應200(回傳數
據);而對于POST,瀏覽器先發送header,服務器回應100 continue,瀏覽器再發送data,服務器回應200 ok(回傳資料),
題42:使用threading組件撰寫支持多執行緒的Socket服務端,
難度:★★★★☆
使用Python語言的threading組件撰寫支持多執行緒的Socket服務端,支持-x和-p引數,分別表示指定最大連接數和監聽埠,
【參考答案】
import socket
import threading,getopt,sys,string
opts, args = getopt.getopt(sys.argv[1:], "hp:l:",["help","port=","list="]) list=50 port=8001
for op, value in opts:
if op in ("-x","--maxconn"): list = int(value) elif op in ("-p","--port"): port = int(value)
def Config(client, address): try:
client.settimeout(500) buf = client.recv(2048) client.send(buf) except socket.timeout: print('time out') client.close()
def main():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.bind(('localhost', port)) sock.listen(list) while True:
client,address = sock.accept()
thread = threading.Thread(target=Config, args=(client, address)) thread.start()
if __name__ == '__main__': main()
九、 資料庫編程(6題)
題43:簡述資料庫的第一、第二、第三范式的內容,
難度:★★☆☆☆
【參考答案】
范式是“符合某一種級別的關系模式的集合,表示一個關系內部各屬性之間的聯系的合理化程度”,實際上就是一張資料表的表結構所符合的某種設計標準的級別,
1NF的定義為:符合1NF的關系中的每個屬性都不可再分,1NF是所有關系型資料庫的最基本要求, 2NF在1NF的基礎之上,消除了非主屬性對于碼的部分函式依賴,判斷步驟如下, 第一步:找出資料表中所有的碼,
第二步:根據第一步所得到的碼,找出所有的主屬性,
第三步:資料表中,除去所有的主屬性,剩下的就都是非主屬性了, 第四步:查看是否存在非主屬性對碼的部分函式依賴,
3NF在2NF的基礎之上,消除了非主屬性對于碼的傳遞函式依賴,
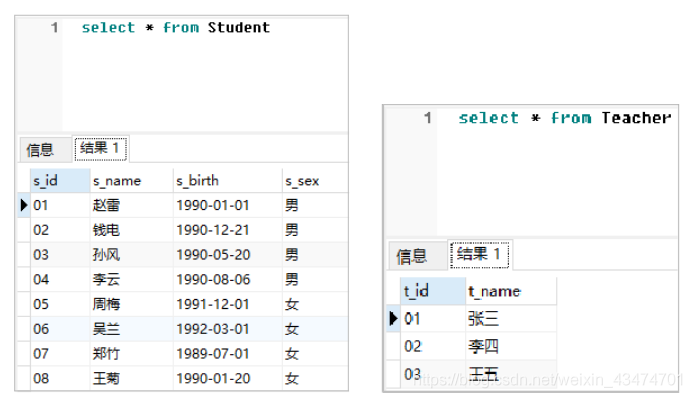
題44:根據以下資料表結構和資料,按照要求撰寫SQL陳述句,
難度:★★☆☆☆
資料庫中現有Course、Score、Student和Teacher四張資料表,其中資料分別如下所示,
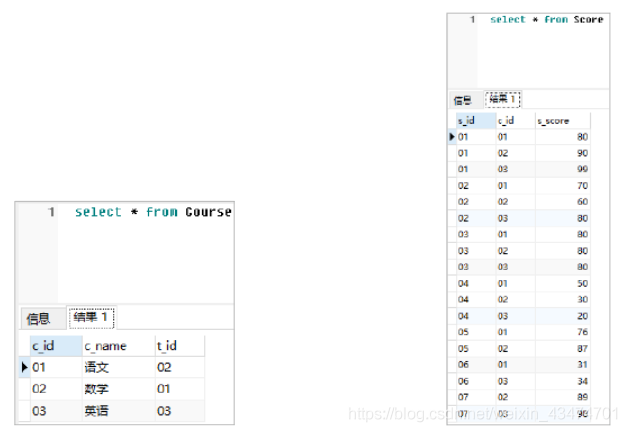
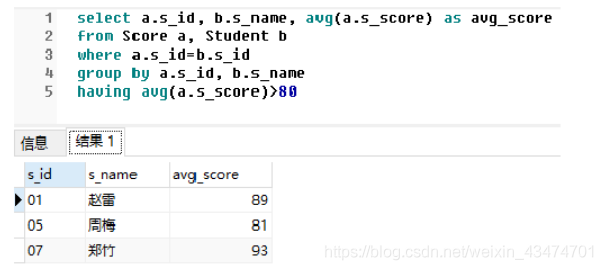
試撰寫SQL陳述句,查詢平均成績大于80的所有學生的學號、姓名和平均成績,
【參考答案(使用SQLServer)】
select a.s_id, b.s_name, avg(a.s_score) as avg_score from Score a, Student b where a.s_id=b.s_id group by a.s_id, b.s_name having avg(a.s_score)>80
查詢結果如下:
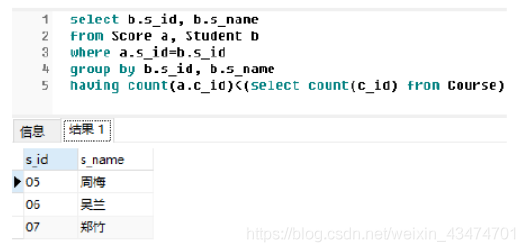
題45:按照44題所給條件,撰寫SQL陳述句查詢沒有學全所有課程的學生資訊,
難度:★★☆☆☆
【參考答案(使用SQLServer)】
select b.s_id, b.s_name from Score a, Student b where a.s_id=b.s_id
group by b.s_id, b.s_name
having count(a.c_id)<(select count(c_id) from Course)
查詢結果如下:
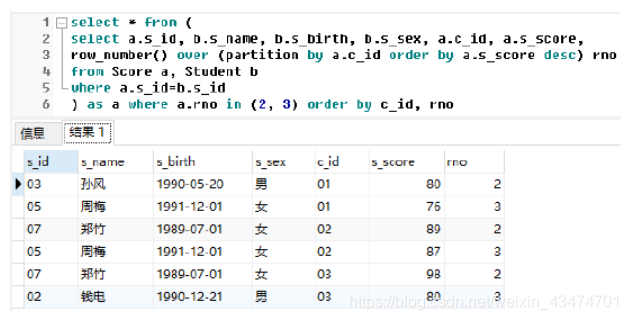
題46:按照44題所給條件,撰寫SQL陳述句查詢所有課程第2
名和第3名的學生資訊及該課
程成績,
難度:★★★★☆
【參考答案(使用SQLServer)】
select * from (
select a.s_id, b.s_name, b.s_birth, b.s_sex, a.c_id, a.s_score, row_number() over (partition by a.c_id order by a.s_score desc) rno from Score a, Student b where a.s_id=b.s_id
) as a where a.rno in (2, 3) order by c_id, rno
查詢結果如下:
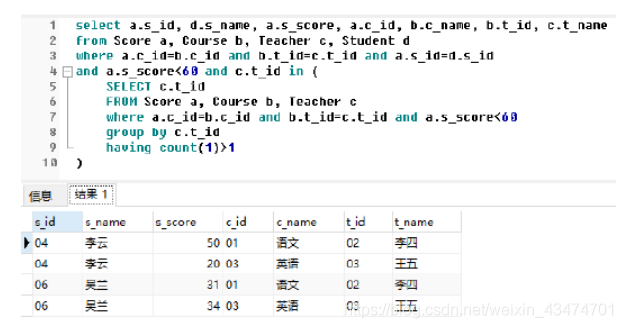
題47:按照44題所給條件,撰寫SQL陳述句查詢所教課程有2人及以上不及格的教師、課
程、學生資訊及該課程成績,
難度:★★★☆☆
【參考答案(使用SQLServer)】
select a.s_id, d.s_name, a.s_score, a.c_id, b.c_name, b.t_id, c.t_name from Score a, Course b, Teacher c, Student d
where a.c_id=b.c_id and b.t_id=c.t_id and a.s_id=d.s_id and a.s_score<60 and c.t_id in ( SELECT c.t_id
FROM Score a, Course b, Teacher c
where a.c_id=b.c_id and b.t_id=c.t_id and a.s_score<60 group by c.t_id having count(1)>1
)
查詢結果如下:
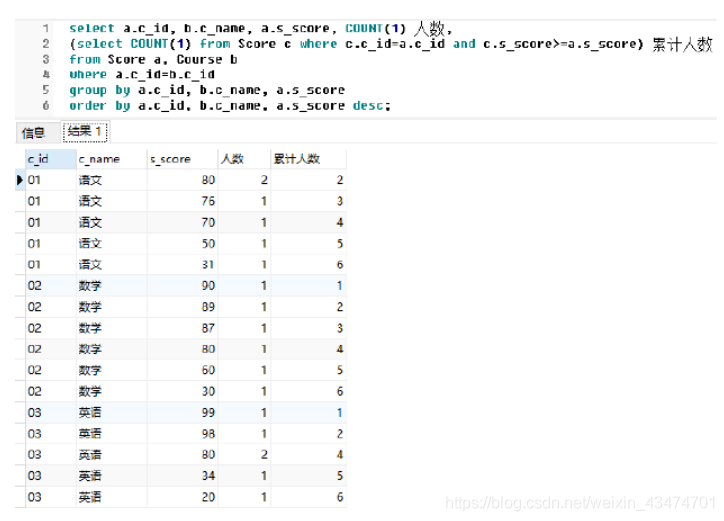
題48:按照44題所給條件,撰寫SQL陳述句生成每門課程的一分段表(課程ID、課程名
稱、分數、該課程該分數人數、該課程累計人數),
難度:★★★★☆
【參考答案(使用SQLServer)】
select a.c_id, b.c_name, a.s_score, COUNT(1) 人數,
(select COUNT(1) from Score c where c.c_id=a.c_id and c.s_score>=a.s_score) 累計人數 from Score a, Course b where a.c_id=b.c_id
group by a.c_id, b.c_name, a.s_score order by a.c_id, b.c_name, a.s_score desc;
查詢結果如下:
十、 圖形影像與可視化(2題)
題49:繪制一個二次函式的圖形,并同時畫出使用梯形法求積分時的各個梯形,
難度:★★★☆☆
【參考答案】
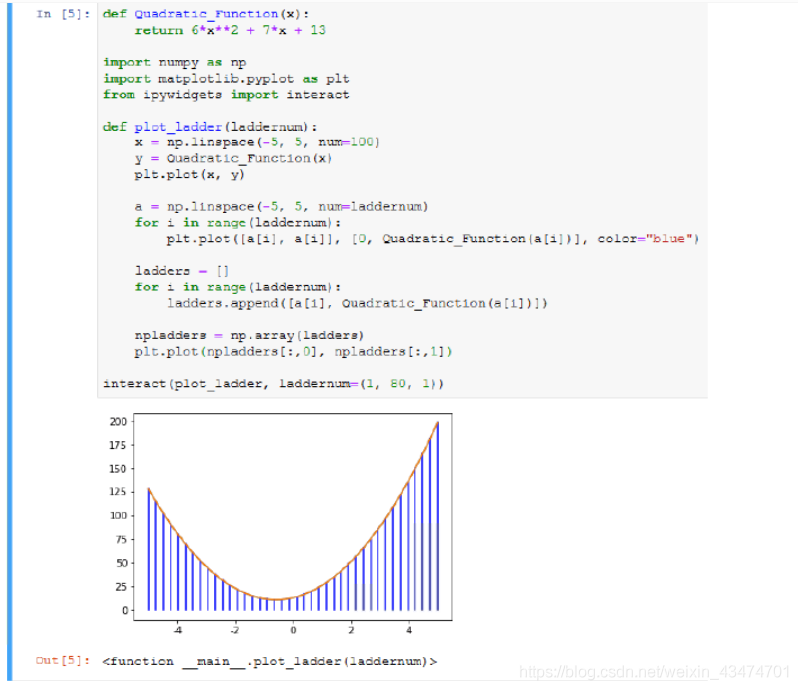
以𝑓(𝑥)=6𝑥2+7𝑥+13為例,代碼如下:
def Quadratic_Function(x):
return 6*x**2 + 7*x + 13
import numpy as np
import matplotlib.pyplot as plt from ipywidgets import interact
def plot_ladder(laddernum):
x = np.linspace(-5, 5, num=100) y = Quadratic_Function(x) plt.plot(x, y)
a = np.linspace(-5, 5, num=laddernum) for i in range(laddernum):
plt.plot([a[i], a[i]], [0, Quadratic_Function(a[i])], color="blue")
ladders = []
for i in range(laddernum):
ladders.append([a[i], Quadratic_Function(a[i])])
npladders = np.array(ladders)
plt.plot(npladders[:,0], npladders[:,1])
interact(plot_ladder, laddernum=(1, 80, 1))
運行結果如下(使用Jupyter Notebook):
題50:將給定資料可視化并給出分析結論
難度:★★★☆☆
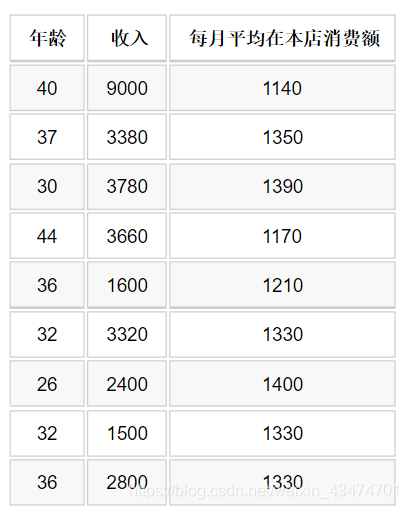
某門店部分顧客的年齡、月收入以及每月平均在本店消費情況如下表所示,

請據此使用Python語言繪制適當的圖形并分析得到結論, 【參考答案】
import matplotlib.pyplot as plt plt.figure(figsize=(10, 5)) # 年齡
age = [34, 40, 37, 30, 44, 36, 32, 26, 32, 36] # 收入
income = [7000, 9000, 3380, 3780, 3660, 1600, 3320, 2400, 1500, 2800] # 消費額
expense = [1230, 1140, 1350, 1390, 1170, 1210, 1330, 1400, 1330, 1330] # 年齡,收入 散點圖 ax1 = plt.subplot(121) ax1.scatter(age, income)
ax1.set_title('年齡,收入 散點圖', family='kaiti', size=16) # 年齡,消費額 散點圖 ax2 = plt.subplot(122) ax2.scatter(age, expense)
ax2.set_title('年齡,消費額 散點圖', family='kaiti', size=16) plt.show()
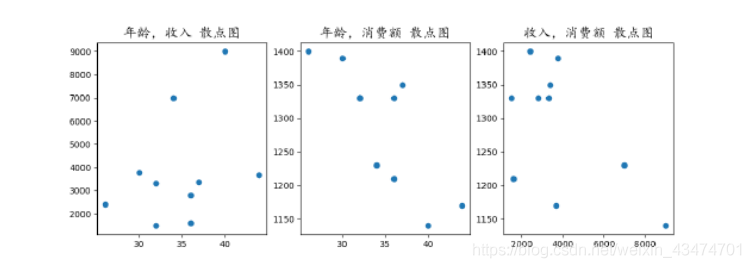
從圖中可以看到,顧客年齡與消費額幾近負相關,收入與消費額也幾乎負相關,而年齡與收入之間沒有特別明顯的關聯關系,
140.對Flask藍圖(Blueprint)的理解?
藍圖的定義
藍圖 /Blueprint 是Flask應用程式組件化的方法,可以在一個應用內或跨越多個專案共用藍圖,使用藍圖可以極大簡化大型應用的開發難度,也為Flask擴展提供了一種在應用中注冊服務的集中式機制, 藍圖的應用場景:
把一個應用分解為一個藍圖的集合,這對大型應用是理想的,一個專案可以實體化一個應用物件,初始化幾個擴展,并注冊一集合的藍圖,
以URL前綴和/或子域名,在應用上注冊一個藍圖,URL前綴/子域名中的引數即成為這個藍圖下的所有視圖函式的共同的視圖引數(默認情況下) 在一個應用中用不同的URL規則多次注冊一個藍圖,
通過藍圖提供模板過濾器、靜態檔案、模板和其他功能,一個藍圖不一定要實作應用或視圖函式,
初始化一個Flask擴展時,在這些情況中注冊一個藍圖, 藍圖的缺點:
不能在應用創建后撤銷注冊一個藍圖而不銷毀整個應用物件, 使用藍圖的三個步驟 1.創建一個藍圖物件
blue = Blueprint(“blue”,name)
2.在這個藍圖物件上進行操作,例如注冊路由、指定靜態檔案夾、注冊模板過濾器…
@blue.route(’/’) def blue_index():
return “Welcome to my blueprint”
3.在應用物件上注冊這個藍圖物件
app.register_blueprint(blue,url_prefix="/blue")
141.Flask 和 Django 路由映射的區別?
在django中,路由是瀏覽器訪問服務器時,先訪問的專案中的url,再由專案中的url找到應用中url,這些url是放在一個串列里,遵從從前往后匹配的規則,在flask中,路由是通過裝飾器給每個視圖函式提供的,而且根據請求方式的不同可以一個url用于不同的作用,
Django
142.什么是wsgi,uwsgi,uWSGI?
WSGI:
web服務器網關介面,是一套協議,用于接收用戶請求并將請求進行初次封裝,然后將請求交給web框架,
實作wsgi協議的模塊:wsgiref,本質上就是撰寫一socket服務端,用于接收用戶請求(django)
werkzeug,本質上就是撰寫一個socket服務端,用于接收用戶請求(flask) uwsgi:
與WSGI一樣是一種通信協議,它是uWSGI服務器的獨占協議,用于定義傳輸資訊的型別, uWSGI:
是一個web服務器,實作了WSGI的協議,uWSGI協議,http協議
143.Django、Flask、Tornado的對比?
1、 Django走的大而全的方向,開發效率高,它的MTV框架,自帶的
ORM,admin后臺管理,自帶的sqlite資料庫和開發測驗用的服務器,給開發者提高了超高的開發效率, 重量級web框架,功能齊全,提供一站式解決的思路,能讓開發者不用在選擇上花費大量時間,
自帶ORM和模板引擎,支持jinja等非官方模板引擎,
自帶ORM使Django和關系型資料庫耦合度高,如果要使用非關系型資料庫,需要使用第三方庫 自帶資料庫管理app 成熟,穩定,開發效率高,相對于Flask,Django的整體封閉性比較好,適合做企業級網站的開發,python web框架的先驅,第三方庫豐富
2、 Flask 是輕量級的框架,自由,靈活,可擴展性強,核心基于Werkzeug WSGI工具 和jinja2 模板引擎
適用于做小網站以及web服務的API,開發大型網站無壓力,但架構需要自己設計
與關系型資料庫的結合不弱于Django,而與非關系型資料庫的結合遠遠優于Django
3、 Tornado走的是少而精的方向,性能優越,它最出名的異步非阻塞的設計方式
Tornado的兩大核心模塊:
iostraem:對非阻塞的socket進行簡單的封裝 ioloop: 對I/O 多路復用的封裝,它實作一個單例
144.CORS 和 CSRF的區別?
什么是CORS?
CORS是一個W3C標準,全稱是“跨域資源共享"(Cross-origin resoure sharing). 它允許瀏覽器向跨源服務器,發出XMLHttpRequest請求,從而客服了AJAX只能同源使用的限制, 什么是CSRF?
CSRF主流防御方式是在后端生成表單的時候生成一串隨機token,內置到表單里成為一個欄位,同時,將此串token置入session中,每次表單提交到后端時都會檢查這兩個值是否一致,以此來判斷此次表單提交是否是可信的,提交過一次之后,如果這個頁面沒有生成CSRF token,那么token將會被清空,如果有新的需求,那么token會被更新, 攻擊者可以偽造POST表單提交,但是他沒有后端生成的內置于表單的token,session中沒有token都無濟于事,
145.Session,Cookie,JWT的理解
為什么要使用會話管理
眾所周知,HTTP協議是一個無狀態的協議,也就是說每個請求都是一個獨立的請求,請求與請求之間并無關系,但在實際的應用場景,這種方式并不能滿足我們的需求,舉個大家都喜歡用的例子,把商品加入購物車,單獨考慮這個請求,服務端并不知道這個商品是誰的,應該加入誰的購物車?因此這個請求的背景關系環境實際上應該包含用戶的相關資訊,在每次用戶發出請求時把這一 小部分額外資訊,也做為請求的一部分,這樣服務端就可以根據背景關系中的資訊,針對具體的用戶進行操作,所以這幾種技術的出現都是對HTTP協議的一個補充,使得我們可以用HTTP協議+狀態管理構建一個的面向用戶的WEB應用,
Session 和Cookie的區別
這里我想先談談session與cookies,因為這兩個技術是做為開發最為常見的,那么session與cookies的區別是什么?個人認為session與cookies最核心區別在于額外資訊由誰來維護,利用cookies來實作會話管理時,用戶的相關資訊或者其他我們想要保持在每個請求中的資訊,都是放在cookies中,而
cookies是由客戶端來保存,每當客戶端發出新請求時,就會稍帶上cookies,服務端會根據其中的資訊進行操作, 當利用session來進行會話管理時,客戶端實際上只存了一個由服務端發送的session_id,而由這個session_id,可以在服務端還原出所需要的所有狀態資訊,從這里可以看出這部分資訊是由服務端來維護的,
除此以外,session與cookies都有一些自己的缺點: cookies的安全性不好,攻擊者可以通過獲取本地cookies進行欺騙或者利用cookies進行CSRF攻擊,使用cookies時,在多個域名下,會存在跨域問題, session 在一定的時間里,需要存放在服務端,因此當擁有大量用戶時,也會大幅度降低服務端的性能,當有多臺機器時,如何共享session也會是一個問題.(redis集群)也就是說,用戶第一個訪問的時候是服務器A,而第二個請求被轉發給了服務器B,那服務器B如何得知其狀態,實際上,session與cookies是有聯系的,比如我們可以把session_id存放在cookies中的, JWT是如何作業的
首先用戶發出登錄請求,服務端根據用戶的登錄請求進行匹配,如果匹配成功,將相關的資訊放入payload中,利用演算法,加上服務端的密鑰生成
token,這里需要注意的是secret_key很重要,如果這個泄露的話,客戶端就可以隨機篡改發送的額外資訊,它是資訊完整性的保證,生成token后服務端將其回傳給客戶端,客戶端可以在下次請求時,將token一起交給服務端,一般是說我們可以將其放在Authorization首部中,這樣也就可以避免跨域問題,
146.簡述Django請求生命周期
一般是用戶通過瀏覽器向我們的服務器發起一個請求(request),這個請求會去訪問視圖函式,如果不涉及到資料呼叫,那么這個時候視圖函式回傳一個模板也就是一個網頁給用戶) 視圖函式呼叫模型毛模型去資料庫查找資料,然后逐級回傳,視圖函式把回傳的資料填充到模板中空格中,最后回傳網頁給用戶, 1.wsgi ,請求封裝后交給web框架(Flask,Django)
2.中間件,對請求進行校驗或在請求物件中添加其他相關資料,例如:csrf,request.session
3.路由匹配 根據瀏覽器發送的不同url去匹配不同的視圖函式 4.視圖函式,在視圖函式中進行業務邏輯的處理,可能涉及到:orm,templates
5.中間件,對回應的資料進行處理 6.wsgi,將回應的內容發送給瀏覽器
147.用的restframework完成api發送時間時區
當前的問題是用django的rest framework模塊做一個get請求的發送時間以及時區資訊的api
class getCurrenttime(APIView): def get(self,request):
local_time = time.localtime()
time_zone =settings.TIME_ZONE
temp = {'localtime':local_time,'timezone':time_zone} return Response(temp)
148.nginx,tomcat,apach到都是什么?
Nginx(engine x)是一個高性能的HTTP和反向代理服務器,也是 一個IMAP/POP3/SMTP服務器,作業在OSI七層,負載的實作方式:輪詢,
IP_HASH,fair,session_sticky. Apache HTTP Server是一個模塊化的服務器,源于NCSAhttpd服務器 Tomcat 服務器是一個免費的開放源代碼的Web應用服務器,屬于輕量級應用服務器,是開發和除錯JSP程式的首選,
149.請給出你熟悉關系資料庫范式有哪些,有什么作用?
在進行資料庫的設計時,所遵循的一些規范,只要按照設計規范進行設計,就能設計出沒有資料冗余和資料維護例外的資料庫結構,
資料庫的設計的規范有很多,通常來說我們在設是資料庫時只要達到其中一些規范就可以了,這些規范又稱之為資料庫的三范式,一共有三條,也存在著其他范式,我們只要做到滿足前三個范式的要求,就能設陳出符合我們的資料庫了,我們也不能全部來按照范式的要求來做,還要考慮實際的業務使用情況,所以有時候也需要做一些違反范式的要求, 1.資料庫設計的第一范式(最基本),基本上所有資料庫的范式都是符合第一范式的,符合第一范式的表具有以下幾個特點:
資料庫表中的所有欄位都只具有單一屬性,單一屬性的列是由基本的資料型別(整型,浮點型,字符型等)所構成的設計出來的表都是簡單的二比表 2.資料庫設計的第二范式(是在第一范式的基礎上設計的),要求一個表中只具有一個業務主鍵,也就是說符合第二范式的表中不能存在非主鍵列對只對部分主鍵的依賴關系
3.資料庫設計的第三范式,指每一個非主屬性既不部分依賴與也不傳遞依賴于業務主鍵,也就是第二范式的基礎上消除了非主屬性對主鍵的傳遞依賴
150.簡述QQ登陸程序
qq登錄,在我們的專案中分為了三個介面,
第一個介面是請求qq服務器回傳一個qq登錄的界面;
第二個介面是通過掃碼或賬號登陸進行驗證,qq服務器回傳給瀏覽器一個code和state,利用這個code通過本地服務器去向qq服務器獲取
access_token覆回傳給本地服務器,憑借access_token再向qq服務器獲取用戶的openid(openid用戶的唯一標識)
第三個介面是判斷用戶是否是第一次qq登錄,如果不是的話直接登錄回傳的jwt-token給用戶,對沒有系結過本網站的用戶,對openid進行加密生成token進行系結
151.post 和 get的區別?
1.GET是從服務器上獲取資料,POST是向服務器傳送資料
2.在客戶端,GET方式在通過URL提交資料,資料在URL中可以看到,POST方式,資料放置在HTML——HEADER內提交
3.對于GET方式,服務器端用Request.QueryString獲取變數的值,對于POST方式,服務器端用Request.Form獲取提交的資料
152.專案中日志的作用
一、日志相關概念
1.日志是一種可以追蹤某些軟體運行時所發生事件的方法
2.軟體開發人員可以向他們的代碼中呼叫日志記錄相關的方法來表明發生了某些事情
3.一個事件可以用一個包含可選變數資料的訊息來描述
4.此外,事件也有重要性的概念,這個重要性也可以被成為嚴重性級別(level) 二、日志的作用
1.通過log的分析,可以方便用戶了解系統或軟體、應用的運行情況; 2.如果你的應用log足夠豐富,可以分析以往用戶的操作行為、型別喜好,地域分布或其他更多資訊;
3.如果一個應用的log同時也分了多個級別,那么可以很輕易地分析得到該應用的健康狀況,及時發現問題并快速定位、解決問題,補救損失,
4.簡單來講就是我們通過記錄和分析日志可以了解一個系統或軟體程式運行情況是否正常,也可以在應用程式出現故障時快速定位問題,不僅在開發中,在運維中日志也很重要,日志的作用也可以簡單,總結為以下幾點: 1.程式除錯
2.了解軟體程式運行情況,是否正常 3,軟體程式運行故障分析與問題定位
4,如果應用的日志資訊足夠詳細和豐富,還可以用來做用戶行為分析
153.django中間件的使用?
Django在中間件中預置了六個方法,這六個方法的區別在于不同的階段執行,對輸入或輸出進行干預,方法如下:
1.初始化:無需任何引數,服務器回應第一個請求的時候呼叫一次,用于確定是否啟用當前中間件
def init(): pass
2.處理請求前:在每個請求上呼叫,回傳None或HttpResponse物件,
def process_request(request): pass
3.處理視圖前:在每個請求上呼叫,回傳None或HttpResponse物件,
def process_view(request,view_func,view_args,view_kwargs): pass
4.處理模板回應前:在每個請求上呼叫,回傳實作了render方法的回應物件,
def process_template_response(request,response): pass
5.處理回應后:所有回應回傳瀏覽器之前被呼叫,在每個請求上呼叫,回傳HttpResponse物件, def process_response(request,response): pass
6.例外處理:當視圖拋出例外時呼叫,在每個請求上呼叫,回傳一個HttpResponse物件,
def process_exception(request,exception): pass
154.談一下你對uWSGI和nginx的理解?
1.uWSGI是一個Web服務器,它實作了WSGI協議、uwsgi、http等協議,Nginx中HttpUwsgiModule的作用是與uWSGI服務器進行交換,WSGI是一種Web服務器網關介面,它是一個Web服務器(如nginx,uWSGI等服務器)與web應用(如用Flask框架寫的程式)通信的一種規范, 要注意WSGI/uwsgi/uWSGI這三個概念的區分, WSGI是一種通信協議,
uwsgi是一種線路協議而不是通信協議,在此常用于在uWSGI服務器與其他網路服務器的資料通信,
uWSGI是實作了uwsgi和WSGI兩種協議的Web服務器, nginx 是一個開源的高性能的HTTP服務器和反向代理: 1.作為web服務器,它處理靜態檔案和索引檔案效果非常高
2.它的設計非常注重效率,最大支持5萬個并發連接,但只占用很少的記憶體空間
3.穩定性高,配置簡潔,
4.強大的反向代理和負載均衡功能,平衡集群中各個服務器的負載壓力應用
155.Python中三大框架各自的應用場景?
django:主要是用來搞快速開發的,他的亮點就是快速開發,節約成本,,如果要實作高并發的話,就要對django進行二次開發,比如把整個笨重的框架給拆掉自己寫socket實作http的通信,底層用純c,c++寫提升效率,ORM框架給干掉,自己撰寫封裝與資料庫互動的框架,ORM雖然面向物件來操作資料庫,但是它的效率很低,使用外鍵來聯系表與表之間的查詢; flask: 輕量級,主要是用來寫介面的一個框架,實作前后端分離,提考開發效率,Flask本身相當于一個內核,其他幾乎所有的功能都要用到擴展(郵件擴展Flask-Mail,用戶認證Flask-Login),都需要用第三方的擴展來實作,比如可以用Flask-extension加入ORM、檔案上傳、身份驗證等,Flask沒有默認使用的資料庫,你可以選擇MySQL,也可以用NoSQL,
其WSGI工具箱用Werkzeug(路由模塊),模板引擎則使用Jinja2,這兩個也是Flask框架的核心,
Tornado: Tornado是一種Web服務器軟體的開源版本,Tornado和現在的主流Web服務器框架(包括大多數Python的框架)有著明顯的區別:它是非阻塞式服務器,而且速度相當快,得利于其非阻塞的方式和對epoll的運用,Tornado每秒可以處理數以千計的連接因此Tornado是實時Web服務的一個理想框架
156.Django中哪里用到了執行緒?哪里用到了協程?哪里用到了行程?
1.Django中耗時的任務用一個行程或者執行緒來執行,比如發郵件,使用celery. 2.部署django專案是時候,組態檔中設定了行程和協程的相關配置,
157.有用過Django REST framework嗎?
Django REST framework是一個強大而靈活的Web API工具,使用RESTframework的理由有:
Web browsable API對開發者有極大的好處 包括OAuth1a和OAuth2的認證策略 支持ORM和非ORM資料資源的序列化
全程自定義開發–如果不想使用更加強大的功能,可僅僅使用常規的function-based views額外的檔案和強大的社區支持
158.對cookies與session的了解?他們能單獨用嗎?
Session采用的是在服務器端保持狀態的方案,而Cookie采用的是在客戶端保持狀態的方案,但是禁用Cookie就不能得到Session,因為Session是用Session ID來確定當前對話所對應的服務器Session,而Session ID是通過Cookie來傳遞的,禁用Cookie相當于SessionID,也就得不到Session,
爬蟲
159.試列出至少三種目前流行的大型資料庫 160.列舉您使用過的Python網路爬蟲所用到的網路資料包?
requests, urllib,urllib2, httplib2
161.爬取資料后使用哪個資料庫存盤資料的,為什么? 162.你用過的爬蟲框架或者模塊有哪些?優缺點?
Python自帶:urllib,urllib2 第三方:requests 框架: Scrapy
urllib 和urllib2模塊都做與請求URL相關的操作,但他們提供不同的功能, urllib2: urllib2.urlopen可以接受一個Request物件或者url,(在接受Request物件時,并以此可以來設定一個URL的headers),urllib.urlopen只接收一個url, urllib 有urlencode,urllib2沒有,因此總是urllib, urllib2常會一起使用的原因 scrapy是封裝起來的框架,他包含了下載器,決議器,日志及例外處理,基于多執行緒,twisted的方式處理,對于固定單個網站的爬取開發,有優勢,但是對于多網站爬取100個網站,并發及分布式處理不夠靈活,不便調整與擴展 requests是一個HTTP庫,它只是用來請求,它是一個強大的庫,下載,決議全部自己處理,靈活性高
Scrapy優點:異步,xpath,強大的統計和log系統,支持不同url,shell方便獨立除錯,寫middleware方便過濾,通過管道存入資料庫 163.寫爬蟲是用多行程好?還是多執行緒好? 164.常見的反爬蟲和應對方法?
165.決議網頁的決議器使用最多的是哪幾個? 166.需要登錄的網頁,如何解決同時限制ip,cookie,session 167.驗證碼的解決?
168.使用最多的資料庫,對他們的理解? 169.撰寫過哪些爬蟲中間件? 170.“極驗”滑動驗證碼如何破解?
171.爬蟲多久爬一次,爬下來的資料是怎么存盤? 172.cookie過期的處理問題?
173.動態加載又對及時性要求很高怎么處理? 174.HTTPS有什么優點和缺點?
175.HTTPS是如何實作安全傳輸資料的? 176.TTL,MSL,RTT各是什么?
177.談一談你對Selenium和PhantomJS了解
178.平常怎么使用代理的 ?
179.存放在資料庫(redis、mysql等), 180.怎么監控爬蟲的狀態?
181.描述下scrapy框架運行的機制? 182.談談你對Scrapy的理解?
183.怎么樣讓 scrapy 框架發送一個 post 請求(具體寫出來)
184.怎么監控爬蟲的狀態 ? 185.怎么判斷網站是否更新?
186.圖片、視頻爬取怎么繞過防盜連接
187.你爬出來的資料量大概有多大?大概多長時間爬一次?
188.用什么資料庫存爬下來的資料?部署是你做的嗎?怎么部署? 189.增量爬取
190.爬取下來的資料如何去重,說一下scrapy的具體的演算法依據,
191.Scrapy的優缺點?
192.怎么設定爬取深度?
193.scrapy和scrapy-redis有什么區別?為什么選擇redis資料庫?
194.分布式爬蟲主要解決什么問題?
195.什么是分布式存盤?
196.你所知道的分布式爬蟲方案有哪些?
197.scrapy-redis,有做過其他的分布式爬蟲嗎?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291210.html
標籤:python