目錄
1、目標網站
2:技術選型
2.1 方案A
2.2 方案B
3、安裝環境
3.1 必要的環境
3.2 安裝 selenium
3.3 下載 chromedriver
4、代碼實作
4.1 代碼
4.2 一些點:
4.3 成果
5、未解決的問題
6、總結
在群里聊天的時候,突然聊起爬抖音的美女視頻,手機下載的視頻總是有水印,所以今天的目標就是爬抖音的無水印美女視頻,
1、目標網站
https://www.douyin.com/
搜索《 果果不一樣》,很漂亮的美女,愛了,愛了,
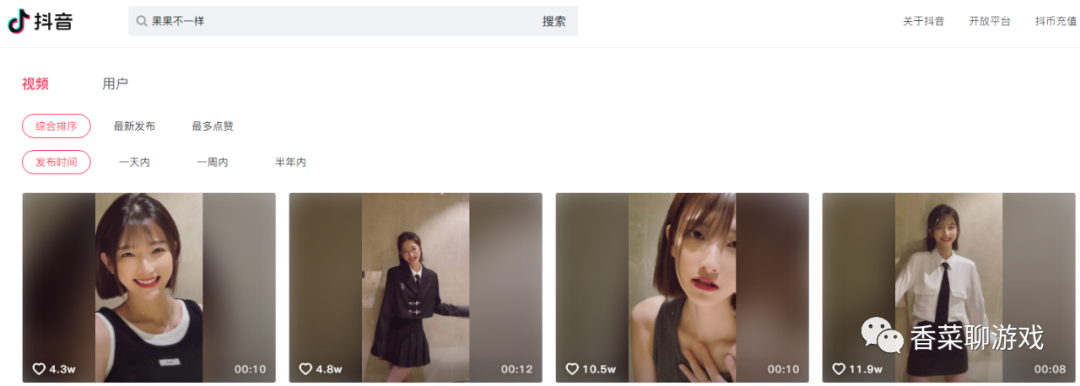
可以看到找到了目標的主頁
https://www.douyin.com/user/MS4wLjABAAAAvOU5GclmETa4jehXAEspnMfYJQZAbwcJzfUFhZk4cP8?extra_params=%7B%22search_id%22%3A%22202107292202370102121680920629F001%22%2C%22search_result_id%22%3A%2260142255276%22%2C%22search_keyword%22%3A%22%E6%9E%9C%E6%9E%9C%E4%B8%8D%E4%B8%80%E6%A0%B7%22%2C%22search_type%22%3A%22video%22%7D&enter_method=search_result&enter_from=search_result
看到一長串的url ,有點懵逼,但是仔細看一下,后面的引數似乎是告訴服務器怎么進入到主頁的,估計是服務器為了做統計日志用的,
直接去除后面的引數可以得到主頁地址:
https://www.douyin.com/user/MS4wLjABAAAAvOU5GclmETa4jehXAEspnMfYJQZAbwcJzfUFhZk4cP8
在瀏覽器中輸入地址驗證我們的猜想,沒毛病,正是我們想要的
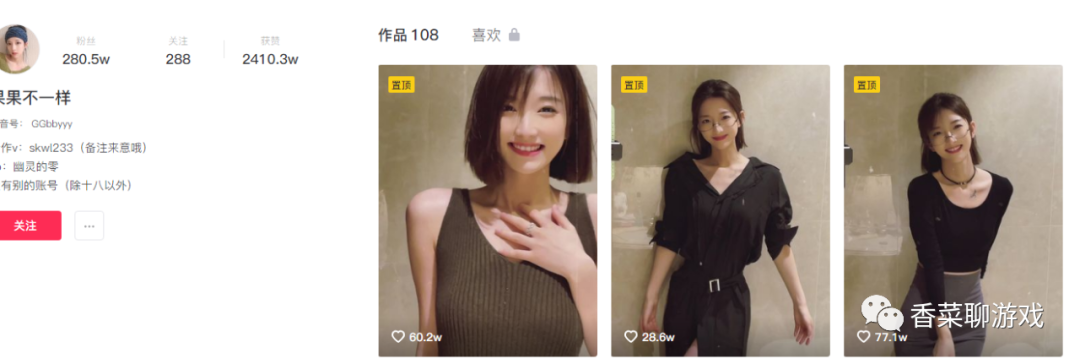
2:技術選型
2.1 方案A
首先我想直接根據鏈接地址去找到視頻的地址,然后直接下載,想法很直接,很暴力,
首先打開視頻詳情頁面,分析視頻的地址怎么來的,找到下面的請求,可以看到后面一堆引數,
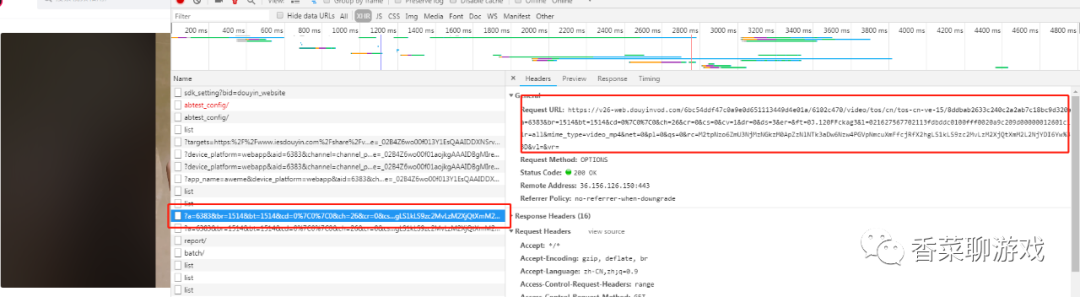
具體的引數如下面:
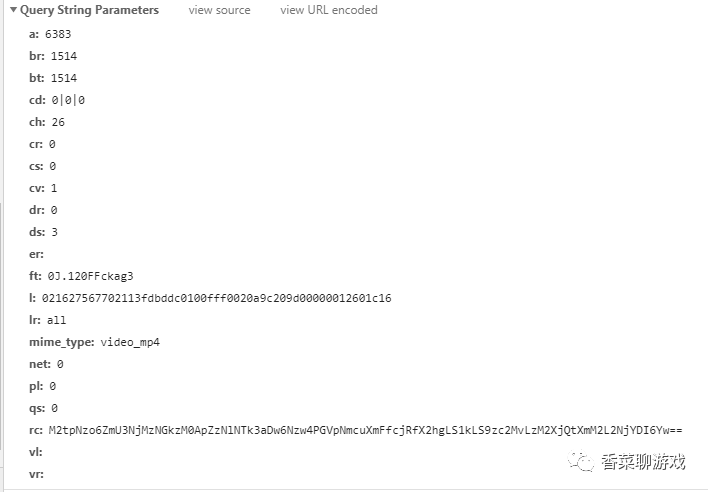
根據我僅有的爬蟲知識,我猜這是為了驗證用的,不知道什么演算法生成的,我也懶得去分析js,一坨亂七八糟的,而且還不知道是哪個,真雞兒難,同時畢竟也不是我的強項,我的目標是快速解決問題
我的分析中遇到的問題:
1、首先 視頻主頁需要動態的加載視頻,也就是下滑的時候會多加載一些視頻,這個可以解決,但是麻煩,
2、尋找視頻的url 不知道是哪個請求,一個一個點過去才最終發現上面的url,有點費勁,
3、視頻是異步加載的,需要先從主頁進到詳情頁,然后生成上面的url,上面這個url生成我似乎搞不定,即使能搞定也要花費很久的時間
綜合上面的問題,我掙扎了一段時間 還是放棄了上面的方案,事情果然沒有那么簡單,可能是我太菜,這也給我打開了另外一扇窗就是下面的方案B
2.2 方案B
我之前知道有種爬蟲技術是selenium ,但是沒用過,Selenium測驗直接運行在瀏覽器中,就像真正的用戶在操作一樣,所以我準備學習一下 selenium ,我的目標是爬取我喜歡的視頻,并不是精通這個技術,所以在網上一頓學習,發現還挺簡單的,建議測驗的同學可以學一下,很好的技術
剛開始學習的時候一臉懵逼,這玩意雜用,沒學過啊,有點害怕,想放棄,不過想想還有美女視頻,還是鼓起了勇氣去學習,最終的結果看來決定是正確的,
3、安裝環境
3.1 必要的環境
方案B 是使用selenium ,所以需要安裝配套的包python + selenium + chromedriver
3.2 安裝 selenium
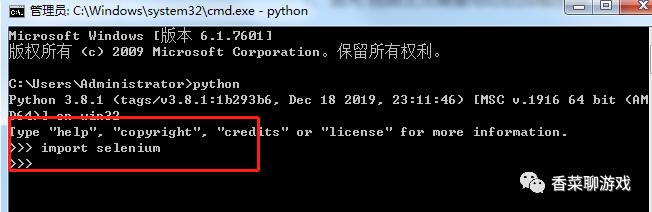
打開控制臺 (win +R ,輸入cmd 回車,進入控制臺),輸入下面的命令等待安裝完成
pip install selenium
安裝完成后,在控制臺輸入python 回車,進入python的命令列界面
然后輸入 import selenium 回車,如果不報錯則你已經安裝完成
3.3 下載 chromedriver
chromedriver 是chrome的驅動,英文大家應該看得懂的,
注意點:需要確認你chrome的版本下載對應的driver
確認版本步驟:
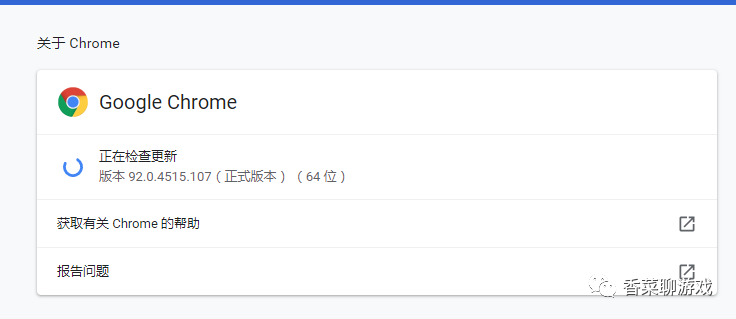
點擊三個點 -> 幫助 -> 關于 Google Chrome 打開下面的界面,可以看到我的版本是92
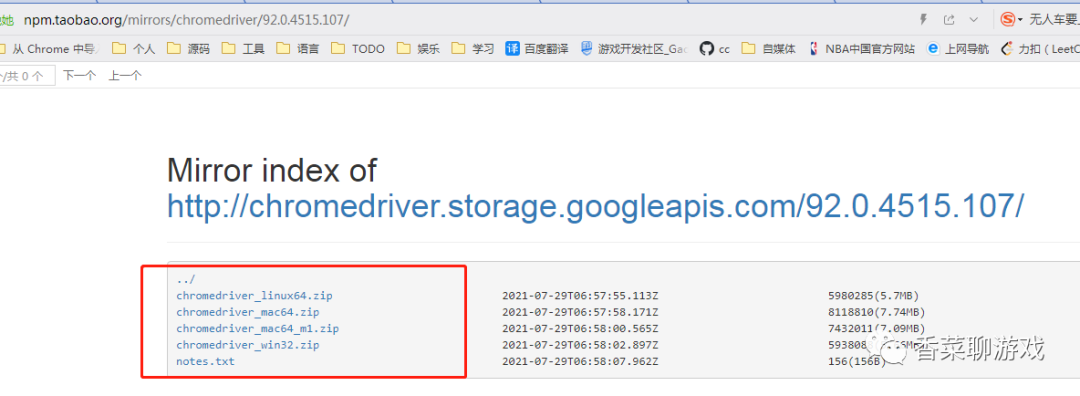
打開下面的網址,選擇 對應的版本下載,放到某個地方解壓即可,等待備用
下載地址:http://npm.taobao.org/mirrors/chromedriver/
4、代碼實作
環境裝好了,我們直接擼代碼,
經過一段時間對selenium的學習,我大概先擼了一個hello world 的程式練練手,最終明白這就是模擬用戶的操作的軟體,真的不錯,直接代碼擼起,
4.1 代碼
# coding:utf-8
import time
from collections import deque
import requests
from selenium import webdriver
# author :香菜
# 下載視頻
def downVideo(url, title):
r = requests.get(url)
filepath = 'video/' + title + '.mp4'
with open(filepath, 'wb') as fp:
fp.write(r.content)
print('%s已下載' % title)
# 主函式
if __name__ == '__main__':
# chrome_options = Options()
# chrome_options.add_argument('--Headless')
# chrome_options.add_argument('--disable-gpu')
# chrome_options.add_argument(
# 'user-agent="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36"')
# 下載的驅動的地址
driver = webdriver.Chrome('E:\child\python\python\chromedriver.exe')
driver.get('https://www.douyin.com/user/MS4wLjABAAAAvOU5GclmETa4jehXAEspnMfYJQZAbwcJzfUFhZk4cP8')
# 選擇網頁元素
# 防止滑動完之后能渠道之前的視頻,做了一個已訪問集合
hasVisit = set()
urlList = driver.find_elements_by_xpath('//*[@id="root"]/div/div[2]/div/div[4]/div[1]/div[2]/ul/li/a/div/div[1]/img')
# 因為使用了selenium ,導致網頁識別到是爬蟲,總會出現驗證碼,我手動點一下,待解決
time.sleep(10)
i = 0
ph = driver.window_handles[0]
# 我選擇一個佇列,因為有下拉的動作
dq = deque(urlList)
while True:
urlEl = dq.pop()
if urlEl is None:
break
if urlEl in hasVisit:
continue
hasVisit.add(urlEl)
# 點擊主頁的視頻,進入子界面
urlEl.click()
# 取出新打開的句柄,切換當前頁面到詳情頁
detailHandle = driver.window_handles.pop()
driver.switch_to.window(detailHandle)
# 獲取視頻的標簽
video = driver.find_element_by_xpath('//*[@id="root"]/div/div[2]/div[1]/div[1]/div[1]/div[1]/div/div[1]/div[2]/video')
# 終于取到視頻的真實地址
videoUrl = video.get_attribute("src")
# 下載視頻
downVideo(videoUrl, str(i))
# 關閉當前頁面
driver.close()
i = i + 1
# 回到主頁
driver.switch_to.window(ph)
# 每下載三個視頻,將主頁往下滾動311 像素,這個不精確,待解決
if i % 3 == 0:
y = i // 3 * 311
sc = 'window.scrollBy(0,' + str(y) + ')'
driver.execute_script(sc)
# 將滑動之后的新的標簽加入到佇列待訪問
urlListNew = driver.find_elements_by_xpath(
'//*[@id="root"]/div/div[2]/div/div[4]/div[1]/div[2]/ul/li/a/div/div[1]/img')
for s in urlListNew:
if s not in hasVisit:
dq.append(s)
代碼中基本上都加了注釋,我先即使不會python的人也能看懂流程,
4.2 一些點:
1、?? 句柄:所謂的句柄可以理解為物件指標,或者物件的參考,總之就是代表一個物件就完了,不用考慮太多
2、?? 主頁的滾動:經過百度得到如下的代碼 window.scrollBy(0,100) 就是下拉到100像素的位置,我大概根據頁面的元素定位一個視頻的像素是311,所以在代碼里每三個滾動的距離是311像素,我沒有考慮間隔的問題,可以優化下,
3、?? 下滑滾動會導致下載相同的視頻,因為獲取到了相同元素,所以我增加了visitSet
4、?? 頁面的關閉:在開始的時候,我打開的子頁面沒有關閉,會打開非常多的網頁,導致電腦記憶體不足,程式崩了
5、?? 在python的當前目錄需要先創建video 檔案夾,要不然下載的時候會報錯
6、?? xpath:就是為了定位標簽位置,代碼中看的很復雜,不要害怕,那也不是我寫的,因為我也不會,下面的獲取方式
在頁面直接F12 打開除錯界面,然后選擇想要查看的元素,右鍵就會出現下面的選單,直接copy XPath,貼到代碼里就行了
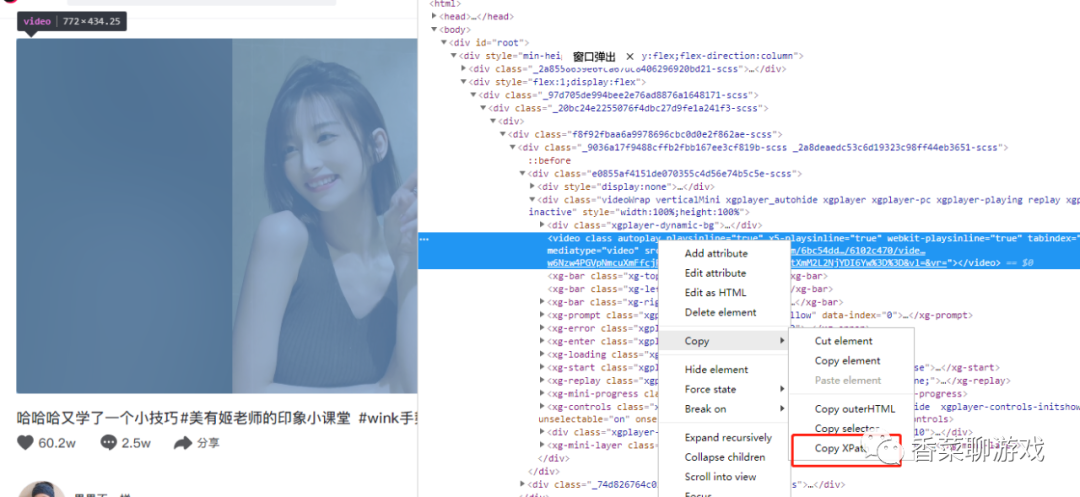
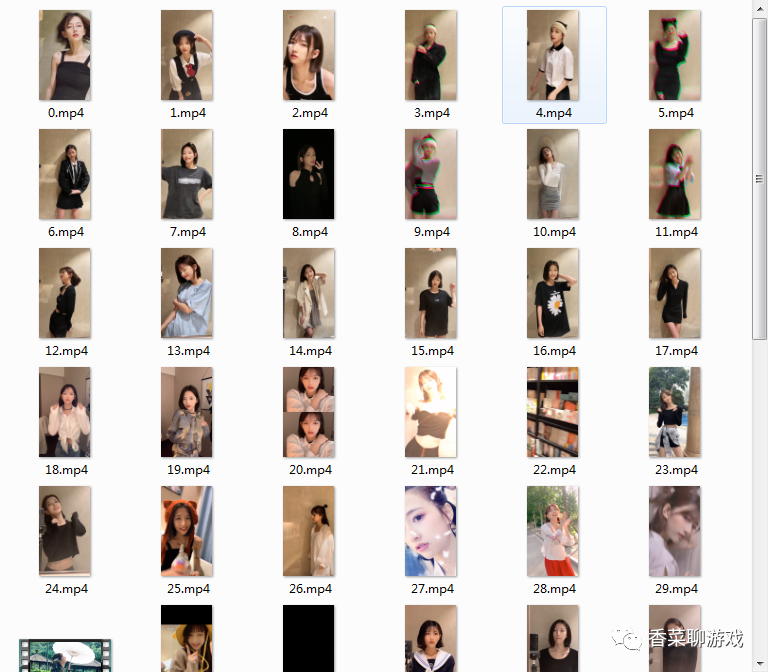
4.3 成果
下載了很多視頻,可以慢慢看了,技術改變生活啊
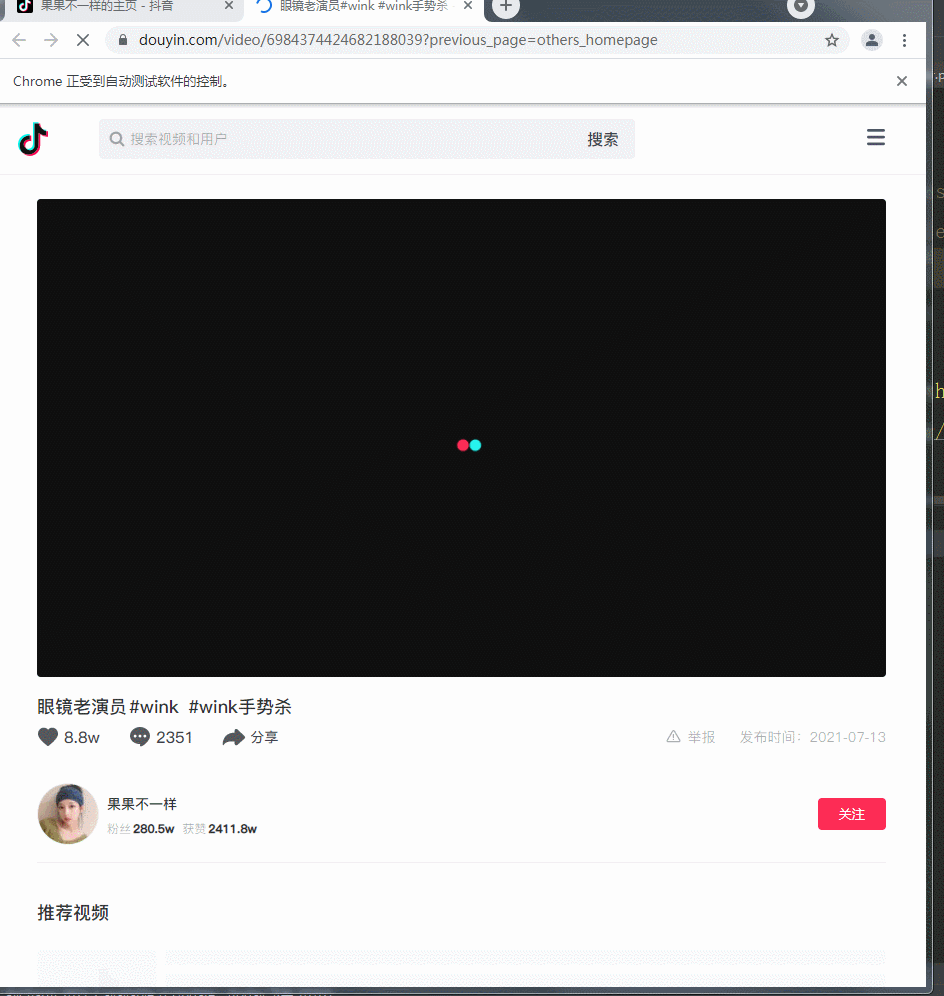
看下運行時的畫面:
在程式的控制下自動打開頁面并且下載對應的視頻
5、未解決的問題
?1、滾動問題,我沒有更精確的控制滾動,還有種方式就是直接在開始的時候一直滾到底,然后一次獲取所有元素下載,簡單暴力
?2、驗證碼問題,在開始的時候總是需要手動對齊圖形,所以我讓程式sleep 了10秒,這種防爬蟲的方式還沒研究不知道怎么破解,不過不影響爬取、待研究
?3、提供一個搜索的池子,直接從搜索主頁進行出發爬取多個小姐姐的視頻,不得了了,全世界的小姐姐都是你的了
6、總結
在這次爬取的程序中遇到了不少的問題,雖然最后都解決了,也總結一些經驗,
?1、遇到問題不要怕,先試試,萬一行吶
?2、不要放棄,想想其他的方式是不是能同樣解決問題,所以有了方案B
?3、解決問題優先,技術不會的可以以后補充,多寫代碼就會熟悉
?4、知識遷移很重要,平常多接觸,在你遇到新的東西能快速上手
這次爬蟲的代碼大概花費了2個多小時,主要是前期的探索花了不少的時間,這篇文章花了我接近2個小時,總共花費了兩個晚上的時間,唉,還是寫代碼簡單些,希望能動動小手幫我點個贊,支持一下,謝謝各位大佬,
常規福利

趕緊點贊!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291211.html
標籤:python