今天帶大家做點好玩的,把B站熱門視頻彈幕爬下來制作詞云圖!
康康大家都怎么說!

開始之前先給大家啰嗦幾句,可能有些兄弟不會安裝模塊,我大概講一下,
如何安裝模塊:
- win(鍵盤左下角ctrl 和 Alt 中間那個鍵) + R 輸入 cmd 輸入安裝命令: pip install 模塊名 回車
- pycharm里面安裝 terminal 輸入安裝命令: pip install 模塊名 回車
如果模塊安裝失敗了,可能是這些問題:
- 提示:pip 不是內部命令
你python環境變數可能沒有設定好 - 有安裝進度條顯示,但是安裝到一半出現報錯了
因為python安裝模塊都是在國外的網址進行下載安裝的, 國內請求國外 網速很慢,下載速度大概只有 幾KB
read time out 網路連接超時 你可以切換為國內的鏡像源 - 明明在cmd里面安裝好了,但是在pycharm 提示我沒有這個模塊
你pycharm里面python解釋器沒有設定,你在pycharm設定里面重新設定一下 - 可能安裝了多個python版本
安裝一個版本即可
Python做爬蟲到底可以做些什么呢?
常規: 爬取網上的資料 / 我可以批量下載圖片/文字/音頻 視頻…
12306搶票 / 京東商城電商網站搶購腳本 / 朋友圈刷票 / 一些問卷調查自動填寫… / 文章刷閱讀量 / 音頻 視頻 播放量
可以刷課 可以刷網課 自動 還能自動批量注冊賬號
模擬點擊 >>> 游戲輔助 >>> 修改游戲記憶體(單機) …
普通B站視頻可以爬 番劇是需要會員的
爬蟲都是通過開發者工具進行抓包分析 查詢資料來源 ( 靜態頁面 / 動態頁面 ajax異步加載)
1. 確定目標需求 (彈幕資料 那個視頻彈幕)
確定了
2. 找資料 (資料的來源分析)
簡簡單單 找到了
3. 對于資料來源的url地址 發送請求 (請求方式 / 請求頭)
請求方式: get / post
請求頭:
https://api.bilibili.com/x/v1/dm/list.so?oid=376200196
(通過開發者工具去看一下資料的具體來源,是否是來自有這個網站)
4. 獲取資料
文本資料 response.text 獲取網頁源代碼
json字典資料 response.json() 通常一般情況是 動態網頁 ajax異步加載 用的比較多
二進制資料 response.content 保存圖片 音頻 視頻 或者 特定格式檔案
5. 決議資料
正則運算式 .*? 解決一切 遇事不決 .*? 通配符 可以匹配任意字符
6. 保存資料
python除了做爬蟲資料采集,還可以做什么?
興趣學習 還是 通過python技術賺錢 (就業找作業 / 外包)
-
網站開發(就業/外包) >>> 我們課程是教授的全堆疊開發 薪資 13K-15K
比如: python開發網站: Youtobe / 豆瓣 / 知乎(以前版本) / Facebook / 美團 ;
我可以做到這樣么?
0基礎 初學者 從零開始學習,上線 通過 域名 服務器 資料互動,4個左右的時間 就可以獨立開發這個專案 類似知乎的網站;
如果你做去外包(團隊): python開發就業 大多數也是進入外包公司 一個 10-20K左右; -
爬蟲開發(腳本)(就業/外包) 可見即可爬
雖然爬蟲什么都可以爬,但是獲取用戶的個人隱私(資訊 電話 身份 販賣 )、國家資訊、商業機密(未公開資料,或侵犯著作權)、色情等違法資訊用來盈利,就基本上人無了!
很多兄弟問我,可以幫我淘寶用戶資料嗎? 我都是告訴他們,這個我還想多活幾年,這玩意涉及隱私,個人資訊,你可以自己學了悄悄爬,爬完記得刪了,用來實踐問題不大,但是別用來盈利!!!
之前有個兄弟爬取微博上面軍事武器航母圖片買給國外, 然后就進去了!所以奉勸大家,切記切記,別亂來! -
資料分析(就業/外包)
-
自動化(腳本)
-
游戲開發/輔助(腳本)
-
人工智能(研究生以上學歷 要求很高)
等等方向還有很多,我就不一 一述說了,那些方向對于一般人來說作用不大,
我們開始正題吧
爬蟲部分:
發送請求 第三方模塊 需要pip install requests
import requests
import re # 內置模塊
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=376200196'
請求頭的作用就是偽裝
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36'
}
模擬瀏覽器對服務器發送請求, 服務器接收到請求之后,確定你沒問題 然后會給你回傳 response回應體資料
函式傳參
response = requests.get(url=url, headers=headers)
<> 物件 物件意味著你可以呼叫里面的方法或者屬性
200 狀態碼 請求成功
獲取資料 文本資料
自動識別編碼
response.encoding = response.apparent_encoding
html_data = re.findall('<d p=".*?">(.*?)</d>', response.text)
content_str = ‘\n’.join(html_data)
- 要串列轉成字串 ‘’.join()
- for 遍歷
- 保存資料 保存字串
for content in html_data:
# mode 保存方式 w 寫入會覆寫 a 追加寫入
with open('彈幕1.txt', mode='a', encoding='utf-8') as f:
f.write(content)
f.write('\n')
# print(content_str)
爬取結果
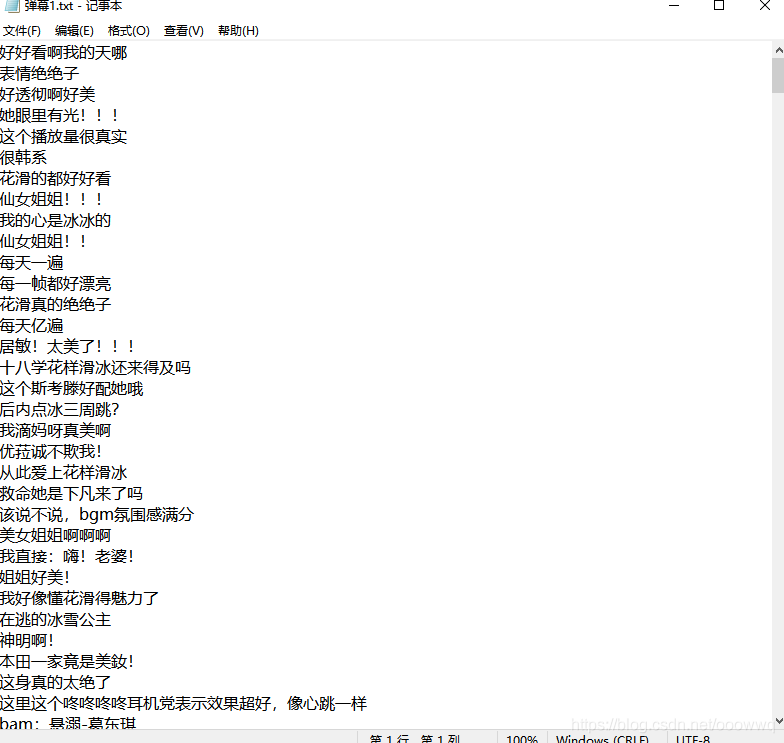
然后我們再來實作制作詞云圖部分
首先要安裝這兩個模塊
import jieba
import wordcloud
一個相對路徑 一個絕對路徑,保存好的txt文本名字要注意看一下,不對的話,記得改一下保持一致,
f = open('彈幕.txt', mode='r', encoding='utf-8')
text = f.read()
txt_list = jieba.lcut(text)
# print(txt_list)
串列整合成一個字串
string = ' '.join(txt_list)
print(string)
print('---'*50)
print(str(txt_list))
詞云圖設定
wc = wordcloud.WordCloud(
width=1000, # 圖片的寬
height=700, # 圖片的高
background_color='white', # 圖片背景顏色
font_path='msyh.ttc', # 詞云字體
# mask=py, # 所使用的詞云圖片
scale=15,
# stopwords={words}, # 停用詞
# contour_width=5,
# contour_color='red' # 輪廓顏色
)
給詞云輸入文字
wc.generate(string)
詞云圖保存圖片地址
wc.to_file('output1.png')
詞云圖的程序中有點慢,大家不要心急

這是最后的結果

沒有加停用詞,所以一些無用的詞比較多
stopwords={'了', '啊'}
把這個部分的代碼加入要屏蔽的詞就OK了!比如我現在把 了 跟 啊 這兩個字屏蔽了,
我們再來看下

不知名網友:666666 牛批 老哥我要學!!!

想學的話,這個是有教程的,和代碼我已經打包了,直接在這個群可以找管理員免費領取 點我加群領取
小編創作不易,復制文章請帶上原文鏈接!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/291212.html
標籤:python