大家好,我是辣條,
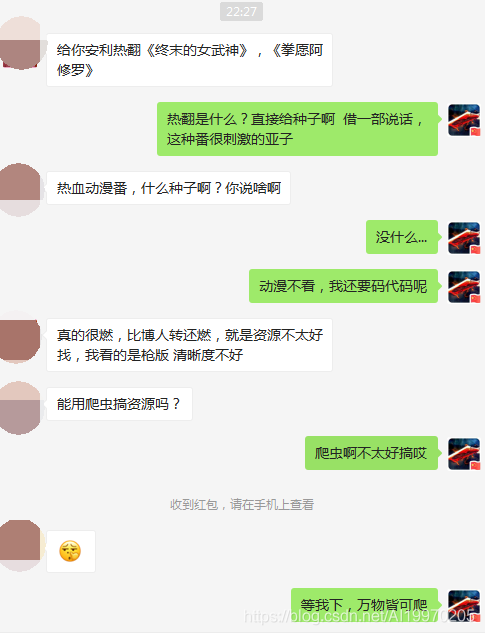
最近被室友安利熱血動漫番《終末的女武神》和《拳愿阿修羅》,太上頭了周末休息熬夜看完了,不過資源不太好找,辣條一怒爬取了資源,這下可以看個夠了,室友崇拜連連,想起了我的班花,快點開學啊,阿西吧...
Python爬蟲-vip動漫采集
效果展示
爬取目標
網站目標:櫻花動漫
工具使用
開發工具:pycharm
開發環境:python3.7, Windows10
使用工具包:requests,lxml, re,tqdm
重點學習內容
正則的使用 tqdm的使用 各種音頻資料的處理
專案思路決議
搜索你需要的動漫資料,根據自己需要的視頻不同決議視頻的方法也是不一樣的(會挑選兩種視頻進行決議)
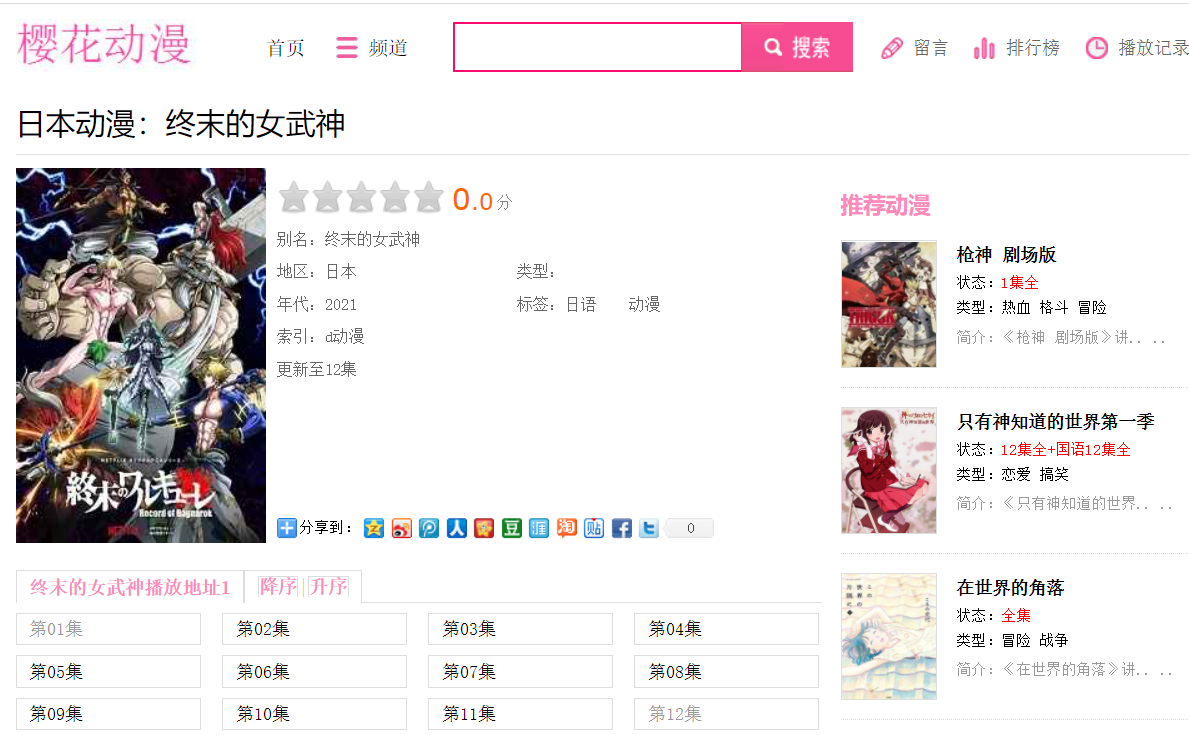
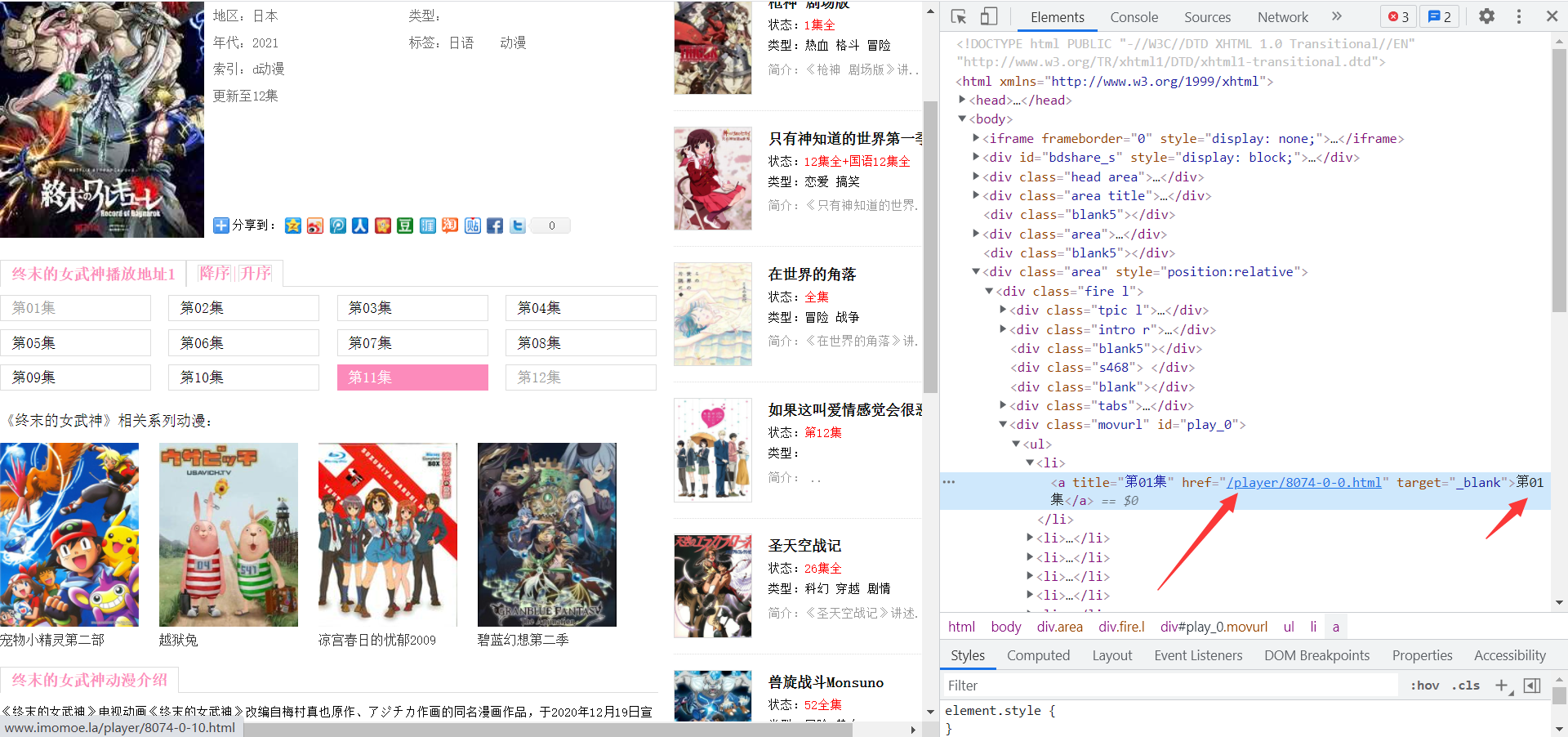
在當前頁面需要提取出對應的章節資訊,獲取到章節資訊的a標簽的跳轉內容,提取出每個章節的名字,提取章節的方法我使用的xpath的方法(各位大佬可自行嘗試其他的方法)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'Referer': 'http://www.imomoe.la/search.asp'
}
?
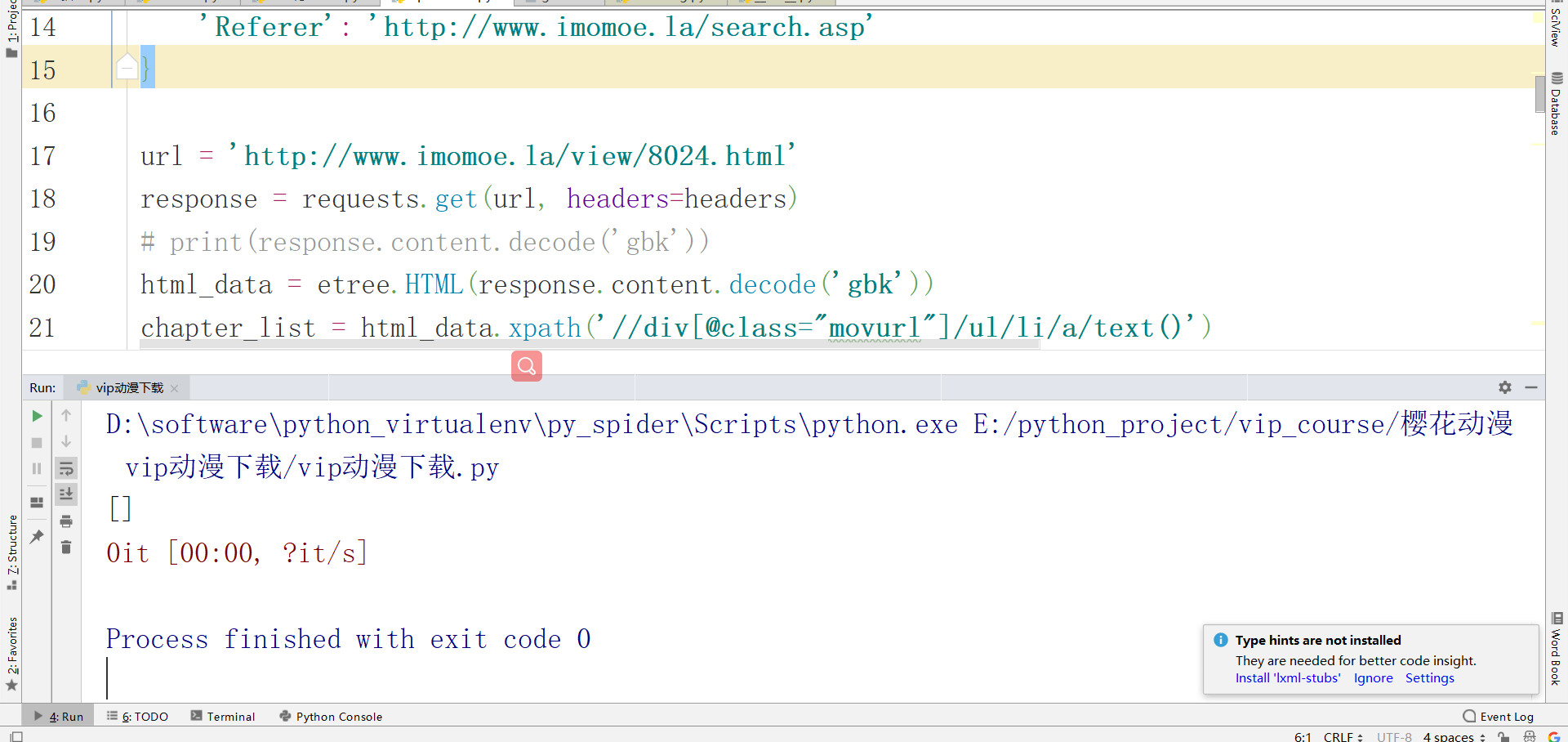
url = 'http://www.imomoe.la/view/8024.html'
response = requests.get(url, headers=headers)
# print(response.content.decode('gbk'))
html_data = etree.HTML(response.content.decode('gbk'))
chapter_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/text()')
chapter_url_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/@href')[0]url的資料需要自行拼接,根據新的url獲取詳情頁面的資料
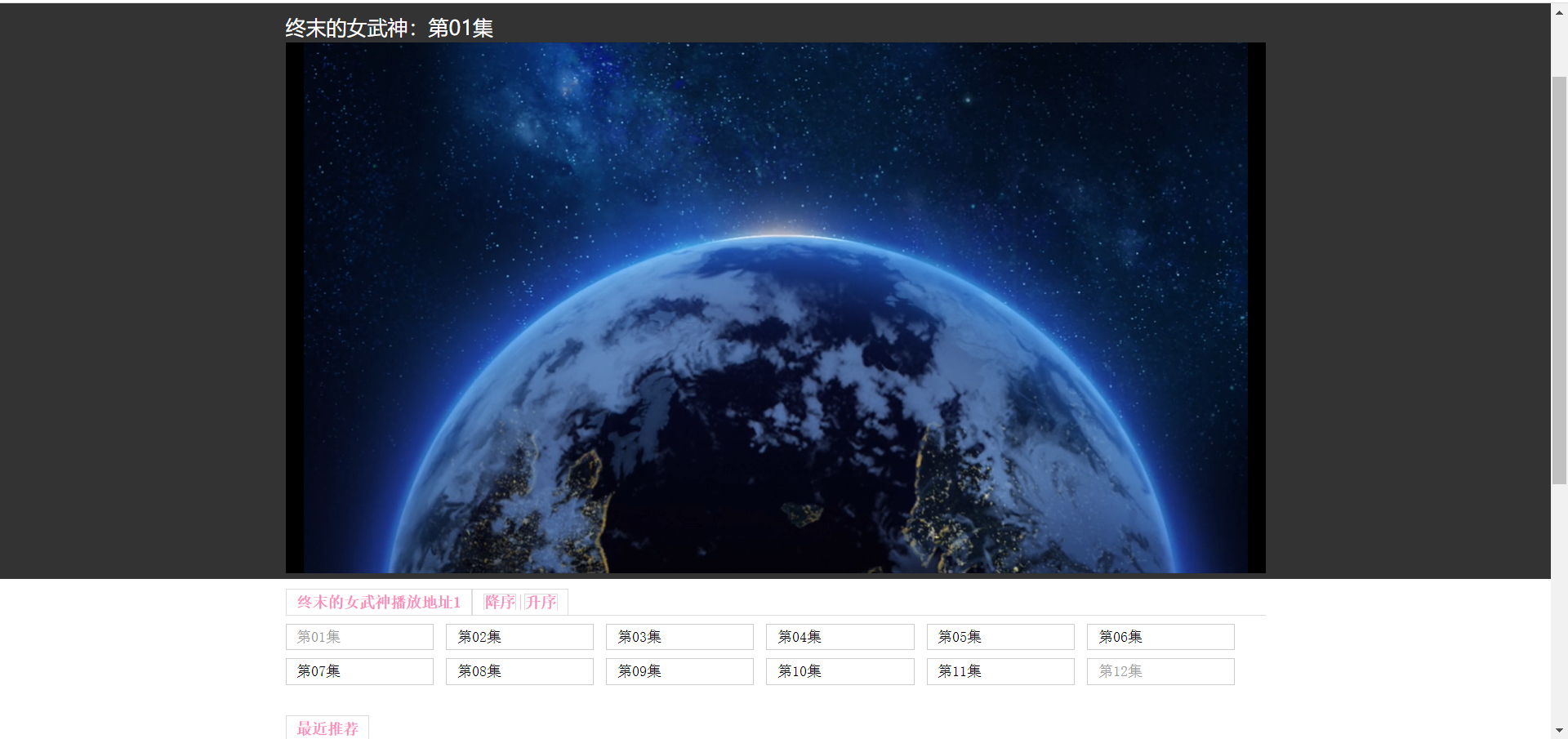
按照正常思路首先應該查看播放地址是否為靜態資料
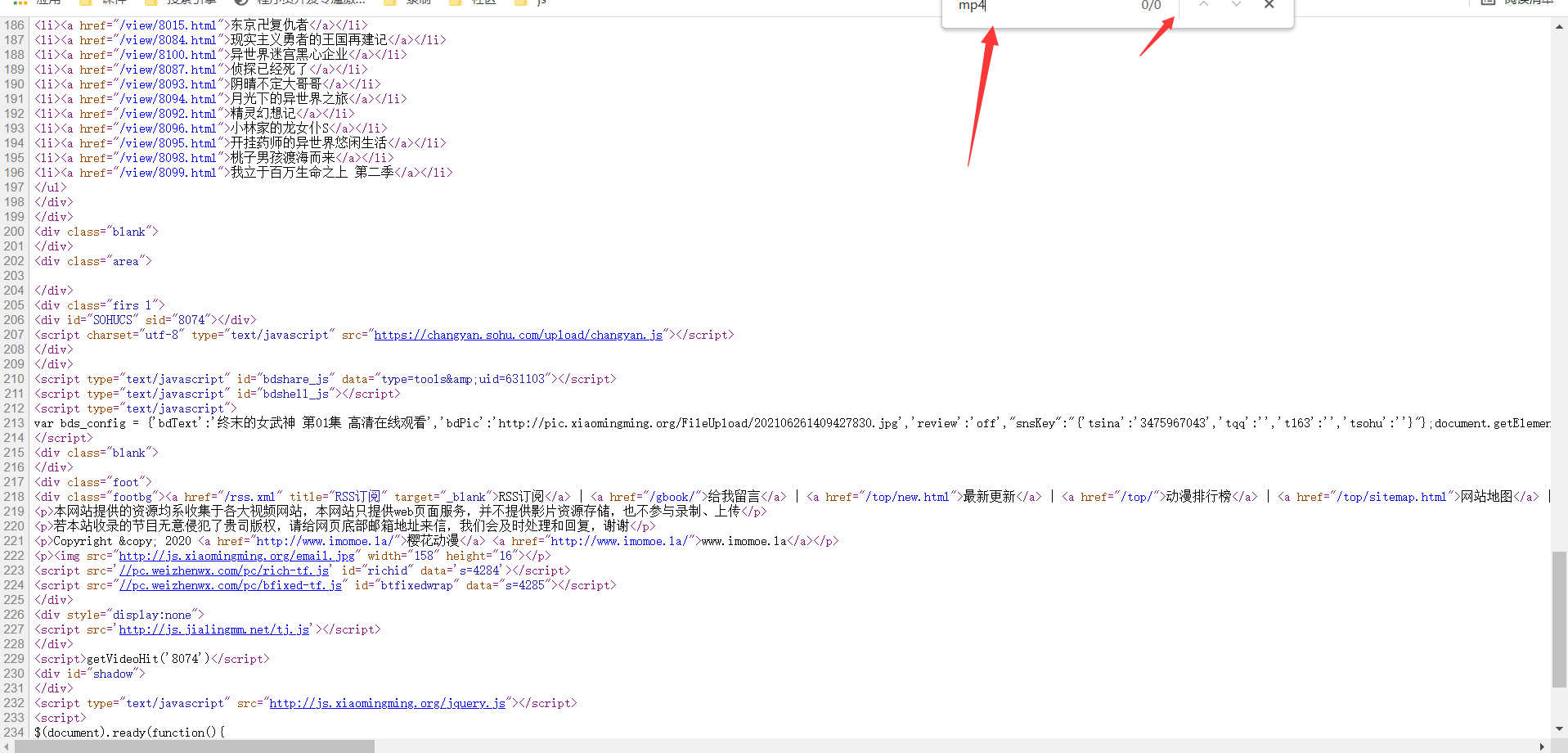
明顯看出資料并不是靜態資料,在區分是否為動態資料,通過抓包工具進行獲取,
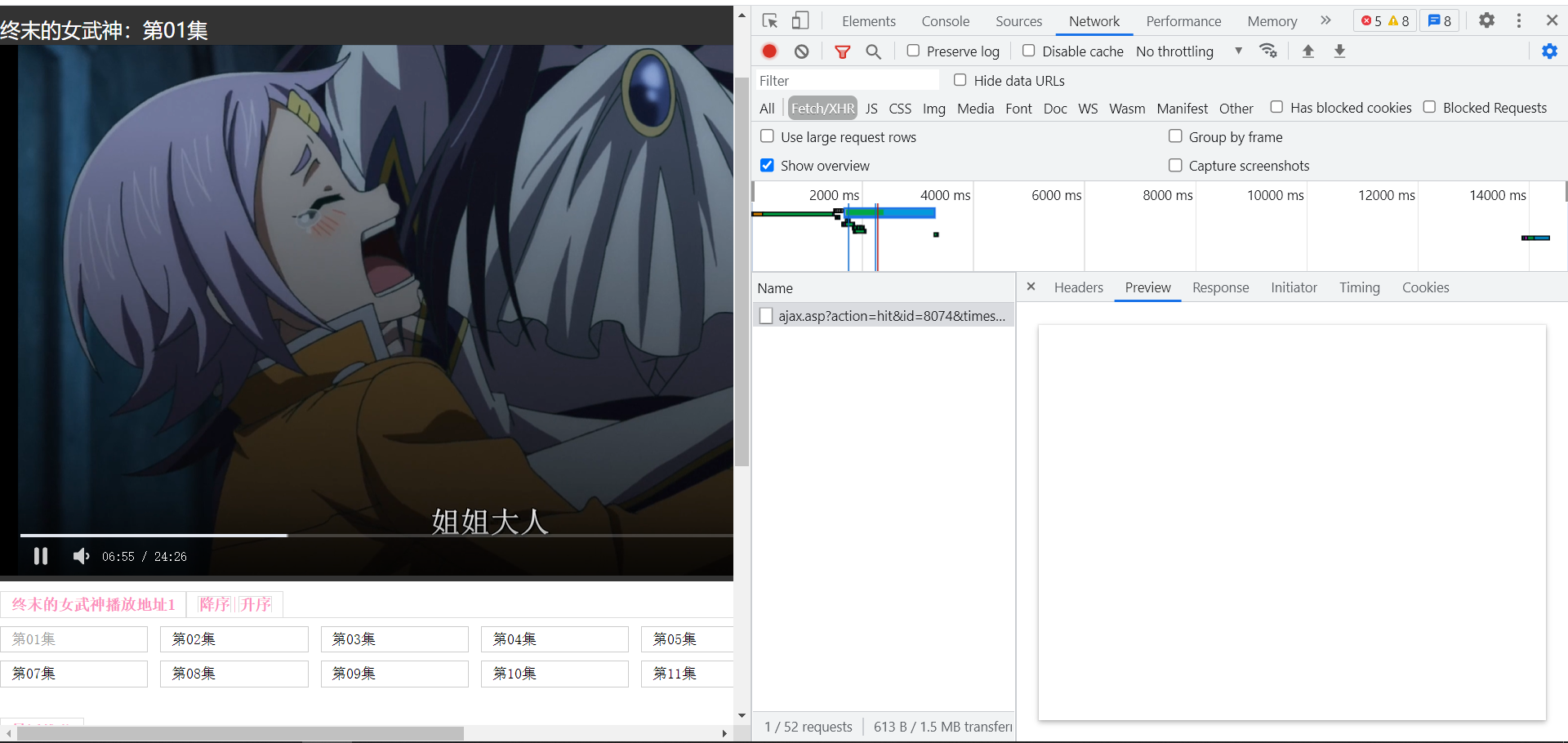
也并不是動態資料,媒體資料也不知道怎么形成的,

從頭在來從前端頁面在進行決議,找視頻頁面的事件,
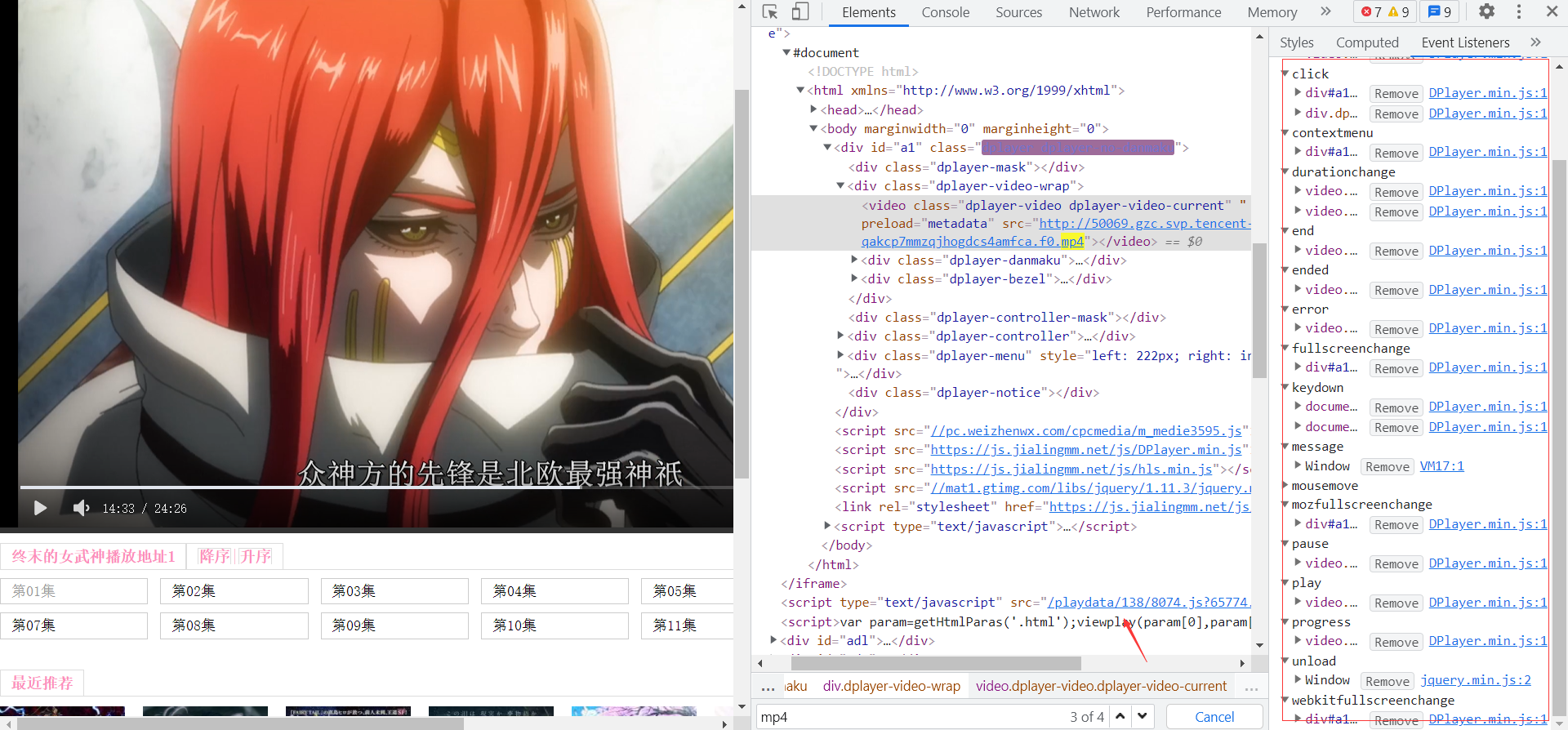
并沒有發現有效資料,但是在iframe下面的Script標簽有js跳轉地址 ,決議的資料網址和視頻的播放地址是一樣的域名, 點擊查看, 這不是就是我們找的視頻播放地址嘛 ,終于找到了,開始實作 在當前頁面通過xpath方式提取出script里的js跳轉地址, 拼接出新的視頻鏈接播放地址,發送請求,通過正則運算式提取出所有MP4播放地址,
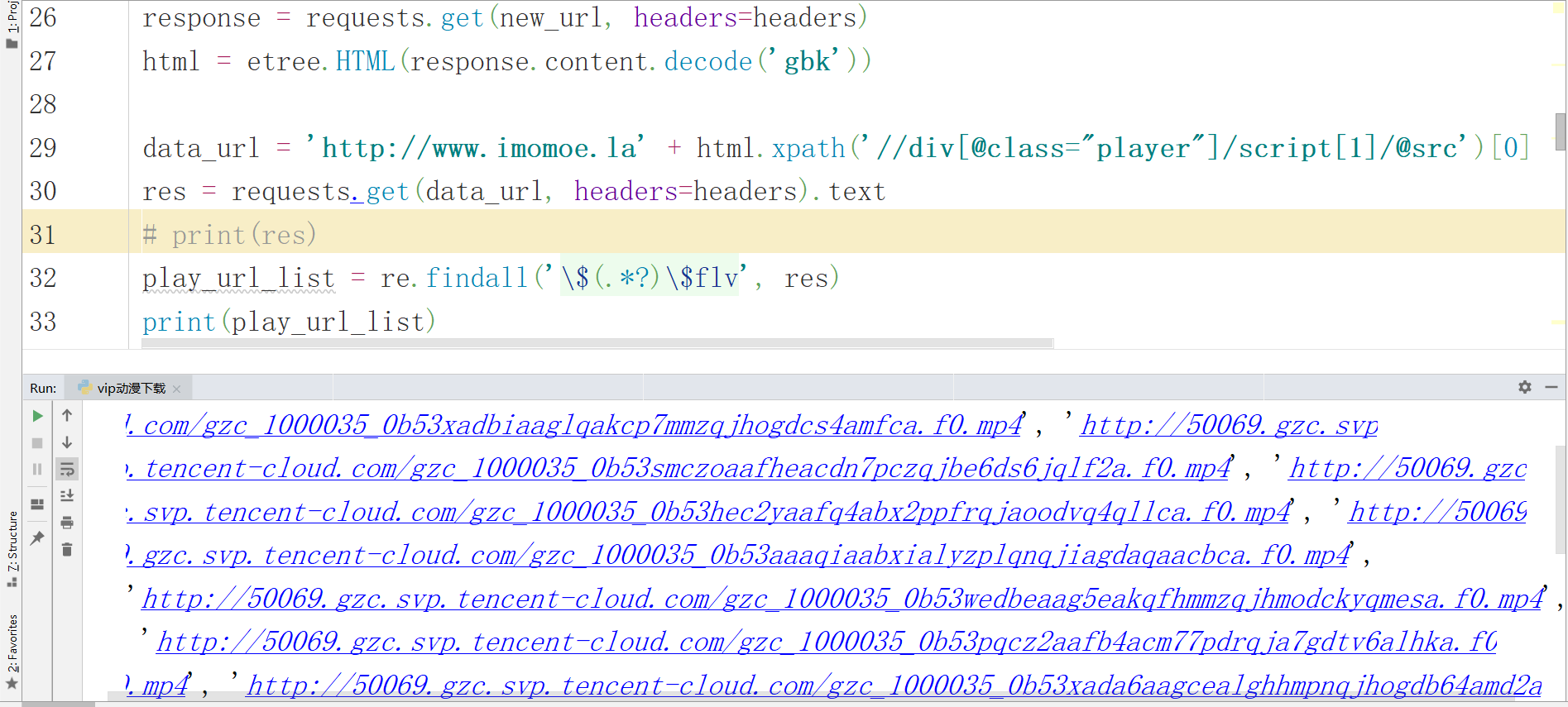
new_url = 'http://www.imomoe.la' + chapter_url_list
response = requests.get(new_url, headers=headers)
html = etree.HTML(response.content.decode('gbk'))
?
data_url = 'http://www.imomoe.la' + html.xpath('//div[@class="player"]/script[1]/@src')[0]
res = requests.get(data_url, headers=headers).text
# print(res)
play_url_list = re.findall('\$(.*?)\$flv', res)
print(play_url_list)保存對視頻資料發送請求,保存資料到mp4 ,通過tqdm工具能查看對應下載的速度以及下載的進度
for chapter, play_url in tqdm(zip(chapter_list, play_url_list)):
result = requests.get(play_url, headers=headers).content
f = open('終末的女武神/' + chapter + '.mp4', "wb")
f.write(result)
?到這大功告成 但是當我把網址修改成斗破蒼穹這個動漫時,卻回傳的資料為空

這個視頻的加載資料的規則是不一樣的加載的資料為m3u8的格式, 其他的音頻的資料加載可能也不一樣, 處理m3u8的資料稍稍的有丟丟復雜,它的m3u8的檔案內部有嵌套了m3u8鏈接地址, 需要轉換對應的資料介面,進行鏈接地址拼接, 取出ts檔案進行下載,拼接成視頻,
m3u8_url_list = re.findall('\$(.*?)\$bdhd', res)
for m3u8_url, chapter in zip(m3u8_url_list, chapter_list):
data = requests.get(m3u8_url, headers=headers)
# print(data.text)
new_m3u8_url = 'https://cdn.605-zy.com/' + re.findall('/(.*?m3u8)', data.text)[0]
# print(new_m3u8_url)
ts_data = requests.get(new_m3u8_url, headers=headers)
ts_url_list = re.findall('/(.*?ts)', ts_data.text)
print("正在下載:", chapter)
for ts_url in tqdm(ts_url_list):
result = requests.get('https://cdn.605-zy.com/' + ts_url).content
f = open('斗破蒼穹/' + chapter + '.mp4', "ab")
f.write(result)專案思路總結
-
獲取到想要動漫的地址
-
提取詳情頁面的名字已經跳轉地址
-
獲取頁面的靜態js檔案
-
決議視頻播放地址或者m3u8檔案
-
保存對應資料
簡易原始碼分享
import requests
from lxml import etree
import re
from tqdm import tqdm
?
?
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'Referer': 'http://www.imomoe.la/search.asp'
}
?
url = 'http://www.imomoe.la/view/8024.html'
response = requests.get(url, headers=headers)
# print(response.content.decode('gbk'))
html_data = etree.HTML(response.content.decode('gbk'))
chapter_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/text()')
chapter_url_list = html_data.xpath('//div[@class="movurl"]/ul/li/a/@href')[0]
# print(chapter_list)
# print(chapter_url_list)
new_url = 'http://www.imomoe.la' + chapter_url_list
response = requests.get(new_url, headers=headers)
html = etree.HTML(response.content.decode('gbk'))
?
data_url = 'http://www.imomoe.la' + html.xpath('//div[@class="player"]/script[1]/@src')[0]
res = requests.get(data_url, headers=headers).text
# print(res)
play_url_list = re.findall('\$(.*?)\$flv', res)
print(play_url_list)
?
for chapter, play_url in tqdm(zip(chapter_list, play_url_list)):
result = requests.get(play_url, headers=headers).content
f = open('終末的女武神/' + chapter + '.mp4', "wb")
f.write(result) 
發現不會的或者學習Python的,可以直接評論留言或者私我【非常感謝你的點贊、收藏、關注、評論,一鍵四連支持】

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/292963.html
標籤:python