渣男,你為什么有這么多小姐姐的照片?因為我Python爬蟲學的好啊??!
- 前言
- 程式說明
- 爬蟲程式
- 觀察網頁結構
- 頁面決議
- 創建圖片保存路徑
- 圖片下載
- 爬取結果展示
- 完整程式
- 最后
前言
大家心心念的三次元來了,又又到了無中生友的環節了,自從上次出了突破次元壁障,Python爬蟲獲取二次元女友后,很多朋友都在評論說想要一期三次元小姐姐的爬蟲教程,這個問題就來了,雖然三次元小姐姐的圖片網站有很多,但是本著學習交流的目的,要找一個尺度合適的就太難了,但是我沒有放棄,經過了夜以繼日的長時間不懈努力,終于為大家找到了一個適合學習研究爬蟲技術的治愈系圖庫分享網站,這從每篇圖冊的名字就可以看出來,例如《你依舊是你》、《你的美好適逢其時》、《時光都走慢了》等等就可以看出來了,如果你還是不相信,我只能將網頁展示一下了,
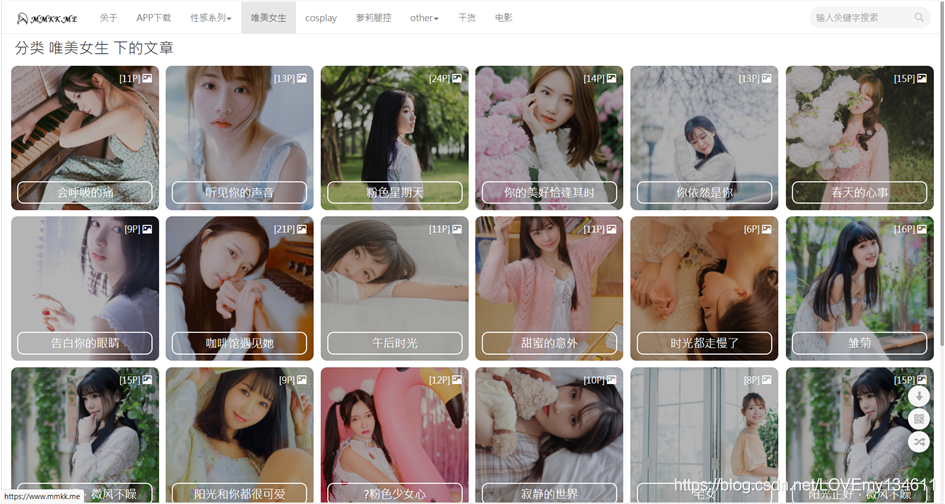
怎么樣,沒騙人吧?都是治愈系的小姐姐,
程式說明
通過爬取小姐姐圖庫分享網站——mmkk.me,獲取高清小姐姐照片,使用庫包括:requests 和 BeautifulSoup,
爬蟲程式
有很多小伙伴可能會想都是爬圖片,那和突破次元壁障,Python爬蟲獲取二次元女友中介紹的方法有什么區別呢,直接換下網址,決議不同的元素不就可以了?如果真的只是這樣,那我直接給出網站不就可以了(雖然可能很多小伙伴的真實目的就只需要這個),但如果你也是這么想的,那你就想的太簡單了,
觀察網頁結構
在網頁結構這里我們就能看到第一個區別,就是此網站的加載方式,是頁面滾動動態加載資料,也就是說下拉滾動潭訓滑鼠滾輪滾動到頁面底部時才會動態即時加載下一頁新內容,這就需要我們認真觀察網路選項卡中頁面動態加載時的變化了,
經過觀察,可以看到每次加載新的圖冊時,都會顯示有數字標記的頁面請求,點擊查看詳情,可以看到新的頁面請求,如下圖所示:
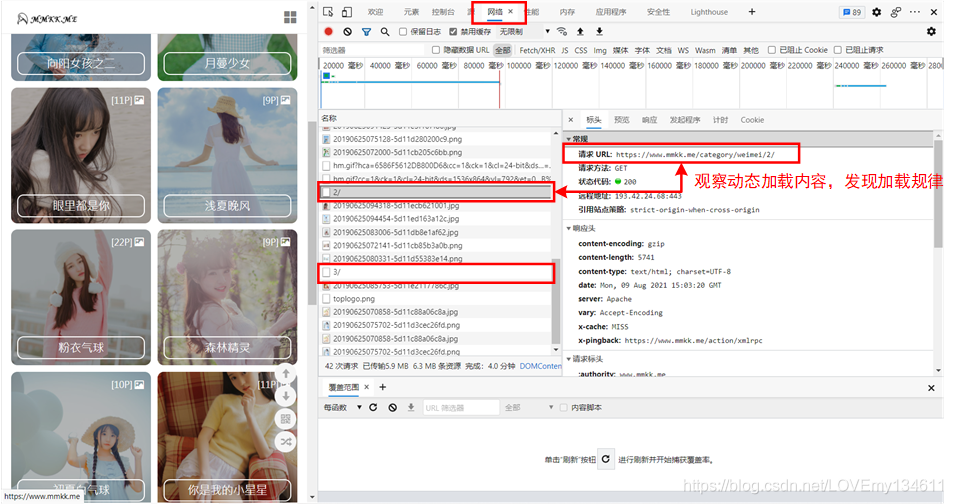
因此如果想要獲取前10頁的圖冊,可以采用如下方式構造請求頁:
url_pattern = "https://www.mmkk.me/category/weimei/{}/"
for i in range(1,11):
url = url_pattern.format(i)
頁面決議
第二個區別就是,此網站中的資料是直接鑲嵌在頁面元素中的,也就是說可以直接通過使用 BeautifulSoup 決議獲取,
首先需要獲取圖冊的地址,使用瀏覽器“開發者工具”,定位圖冊鏈接:
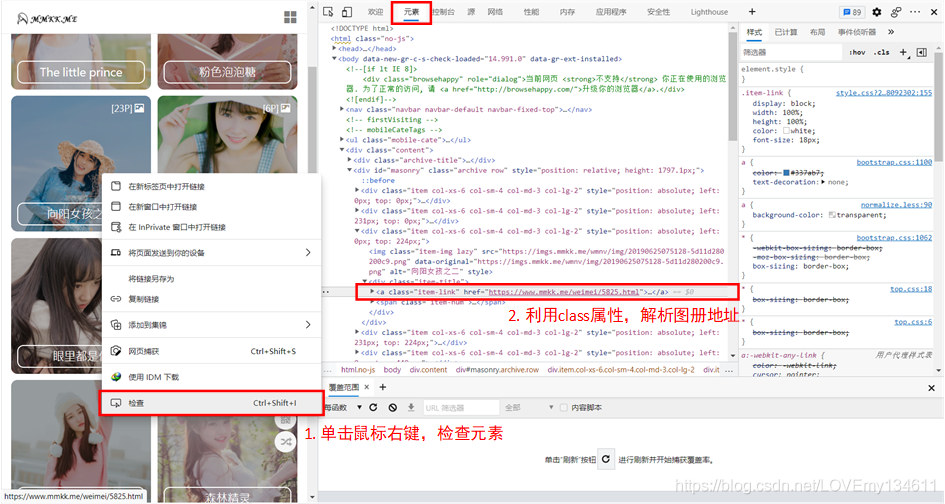
因此,例如要獲取第一頁中所有圖冊地址,可以使用如下方式:
url = url_pattern.format(1)
response = requests.get(url=url, headers=headers)
# 解碼
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all('a',attrs={"class":"item-link"})
# 列印查看獲取的圖冊鏈接
for j in results:
print(j.attrs['href'])
# 為了對每個圖冊分別存盤,獲取每個圖冊的標題資訊
path_name=j.get_text().strip()
列印查看獲取的圖冊鏈接:
https://www.mmkk.me/weimei/5537.html
https://www.mmkk.me/weimei/5438.html
https://www.mmkk.me/weimei/5991.html
https://www.mmkk.me/weimei/6278.html
https://www.mmkk.me/weimei/5827.html
獲取圖冊地址后,就可以請求圖冊頁面,然后在圖冊中決議獲取每張圖片的地址(方法與決議圖冊地址類似):
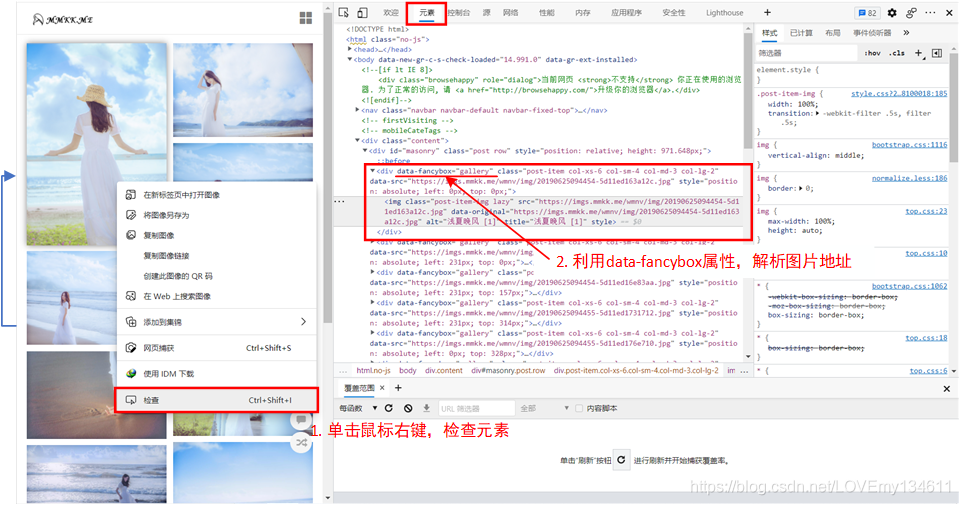
例如要獲取第一個圖冊中所有的圖片地址:
url_imgs = results[0].attrs['href']
response_imgs = requests.get(url=url_imgs, headers=headers)
# 解碼
response_imgs.encoding = 'utf-8'
response_imgs.raise_for_status()
soup_imgs = BeautifulSoup(response_imgs.text, 'html.parser')
results_imgs = soup_imgs.find_all('div',attrs={"data-fancybox":"gallery"})
# 列印查看獲取的圖片地址
for k in range(len(results_imgs)):
print(results_imgs[k].attrs['data-src'])
列印查看獲取的圖片地址鏈接:
https://imgs.mmkk.me/wmnv/img/20190625081910-5d11d8fe5422b.png
https://imgs.mmkk.me/wmnv/img/20190625081910-5d11d8feae474.png
https://imgs.mmkk.me/wmnv/img/20190625081911-5d11d8ff282b1.png
...
創建圖片保存路徑
根據在頁面決議中獲取到圖冊名,創建保存路徑:
if not os.path.exists(path_name):
os.makedirs(path_name, exist_ok=True)
圖片下載
首先利用獲取的圖冊名以及圖片順序,構建保存的圖片名:
file_name = path_name +'_'+str(k+1)+'.png'
file_name = os.path.join(path_name, name_webp)
然后將獲取的圖片內容寫入檔案中:
# 以第一張圖片為例
r = requests.get(results_imgs[0].attrs['data-src'], headers=headers)
if r.status_code == 200:
with open(file_name, 'wb') as f:
f.write(r.content)
爬取結果展示
接下來看下爬取程式結果:

完整程式
import time
import requests
from bs4 import BeautifulSoup
import os
import random
url_pattern = "https://www.mmkk.me/category/weimei/{}/"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62',
'Connection': 'keep-alive'
}
# 爬取前5頁
for i in range(1, 6):
time.sleep(10)
url = url_pattern.format(i)
response = requests.get(url=url, headers=headers)
# 解碼
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 相冊鏈接
results = soup.find_all('a',attrs={"class":"item-link"})
# 回圈所有相冊鏈接
for j in results:
time.sleep(random.randint(8,13))
url_imgs = j.attrs['href']
# 相冊名
path_name = j.get_text().strip()
# 創建圖片保存路徑
if not os.path.exists(path_name):
os.makedirs(path_name, exist_ok=True)
response_imgs = requests.get(url=url_imgs, headers=headers)
# 解碼
response_imgs.encoding = 'utf-8'
response_imgs.raise_for_status()
soup_imgs = BeautifulSoup(response_imgs.text, 'html.parser')
# 圖片鏈接
results_imgs = soup_imgs.find_all('div',attrs={"data-fancybox":"gallery"})
# 回圈所有圖片鏈接
for k in range(len(results_imgs)):
img = results_imgs[k].attrs['data-src']
file_name = path_name + '_' + str(k+1) + '.png'
file_name = os.path.join(path_name, file_name)
if not os.path.exists(file_name):
time.sleep(random.randint(3,8))
r = requests.get(img, headers=headers)
if r.status_code == 200:
with open(file_name, 'wb') as f:
f.write(r.content)
最后
當然網站中也包含其他分類的圖冊,但是我并沒有點開,畢竟大家都喜歡治愈唯美系的小姐姐,如果有小伙伴對其他分類感興趣,也可以自行修改程式.
為了給大家謀取更多福利,博主都被罵成渣男了,求求各位給個三連,不過分吧?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/294229.html
標籤:python