目錄
Numpy簡介
Numpy操作集合
1、不同維度資料的表示
1.1 一維資料的表示
1.2 二維資料的表示
1.3 三維資料的表示
2、 為什么要使用Numpy
2.1、Numpy的ndarray具有廣播功能
2.2 Numpy陣列的性能比Python原生資料型別高
3 ndarray的屬性和基本操作
3.1 ndarray的基本屬性
? 3.2 ndarray元素型別
3.3 創建ndarray的方式
3.4 ndarray物件的變換
3.5 ndarray物件的操作
4 、Numpy的函式與陣列運算
4.1 陣列與標量之間的運算
4.2 對陣列的元素進行運算
4.3 陣列之間的運算
4.4 統計函式
4.5 隨機函式
5 、Numpy資料的存取
5.1 csv資料檔案的存取
Pandas簡介
Pandas操作集合
1 、pandas資料結構之Series
1.1 創建Series
1.1.1 從ndarray創建Series
1.1.2 從字典或串列創建Series
1.1.3 從標量創建
1.2 對Series的操作
1.2.1 Series和ndarray相似的操作
1.2.2 向量化運算
1.2.3 類似字典的操作
1.2.4 時間序列操作
2、pandas資料結構之DataFrame
2.1 DataFrame的創建
2.1.1 從Series or dicts創建
2.1.2 從ndarrays或lists的字典創建
2.1.3 從結構化或成對的array/list創建
2.1.3 從字典的串列創建
2.2 變數選擇、添加和洗掉
3、 資料匯出
3.1 匯出到本地檔案
3.1.1 匯出為文本檔案
3.1.2 匯出為Excel檔案
3.1.3 匯出為Json檔案
3.1.4 匯出為hdf檔案
3.2 將資料存盤到資料庫
3.3 資料匯入
3.3.1 從本地檔案
4 、分組計算與匯總
5、資料融合
Pandas高級操作補充?
每文一語
Numpy簡介
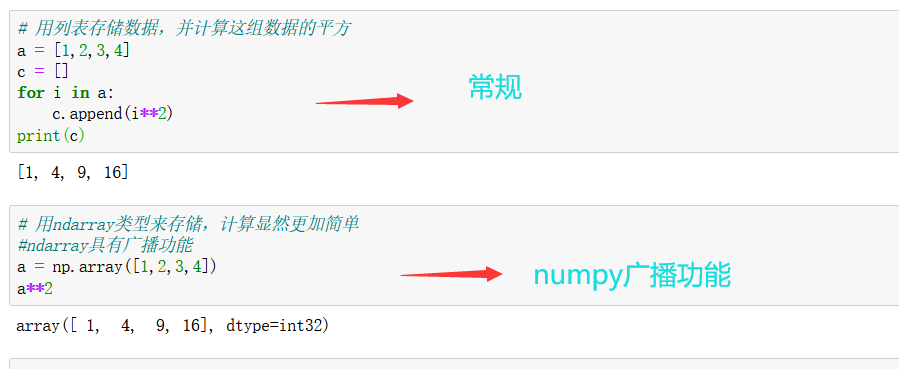
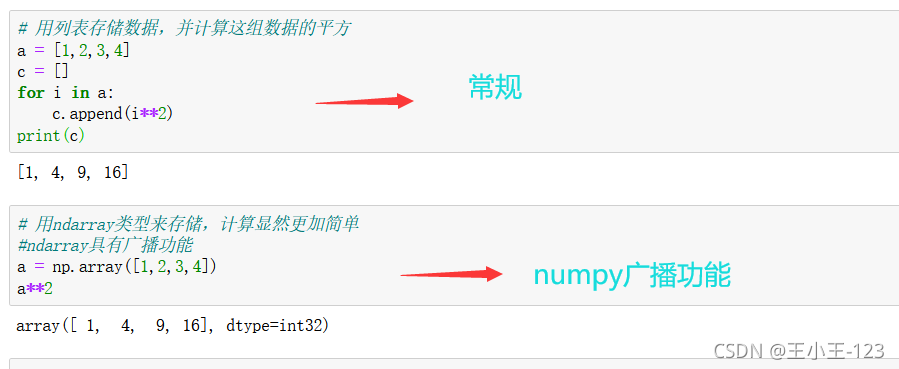
Numpy專門針對ndarray的操作和運算進行了設計,所以陣列的存盤效率和輸入輸出性能遠優于Python中的嵌套串列,陣列越大,Numpy的優勢就越明顯,Numpy系統是Python的一種開源的數值計算擴展,這種工具可用來存盤和處理大型矩陣,比Python自身的嵌套串列(nested list structure)結構要高效的多(該結構也可以用來表示矩陣(matrix)),據說NumPy將Python相當于變成一種免費的更強大的MATLAB系統,

ndarray中的所有元素的型別都是相同的,而Python串列中的元素型別是任意的,所以ndarray在存盤元素時記憶體可以連續,而python原生lis就t只能通過尋址方式找到下一個元素,這雖然也導致了在通用性能方面Numpy的ndarray不及Python原生list,但在科學計算中,Numpy的ndarray就可以省掉很多回圈陳述句,代碼使用方面比Python原生list簡單的多,
總的來說,在科學計算和大資料的處理上面,numpy的優勢遠遠超過了原生態的Python內置方法,正所謂“工欲善其事必先利其器”,任何一門工程學科的發現和精進,都離不開各種軟體的升級和迭代,
Numpy操作集合
1、不同維度資料的表示
1.1 一維資料的表示
# 串列
[1,2,'a',4]在Python中,最為常見的資料型別就是串列,串列是一維的資料,同時也是我們處理資料的常見集裝箱,

在anaconda里面的jupyter notebook里面,我們直接使用pip安裝這一個庫,一般的anaconda會自帶numpy這一個第三方庫,
在使用numpy的時候,首先要引入這一個第三方庫,使用:import numpy as np即可,便于為我們后面的方法屬性呼叫,
在構造最為基本的numpy資料時,我們使用numpy的array()方法,里面就是一個串列形式的,可以是多維陣列,最終構造成:ndarray型別
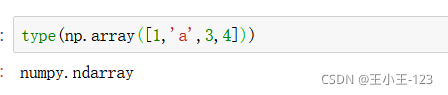

# 集合
set([1,'a',3,4]) #集合的元素唯一且無序# 元組
tuple([1,'a',3,4])#元組的元素不可變對于Python里面的常見的幾種資料型別:字串、元組、串列、字典、集合,重點需要注意的是字串和元組是不可修改的,但是可以通過索引來組合和切斷這些元素,例如:
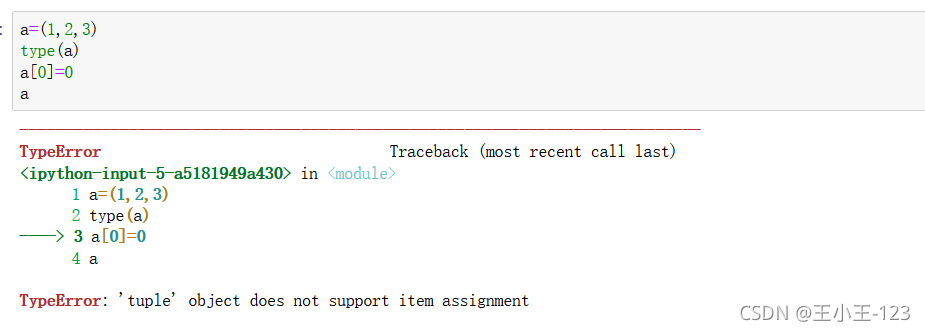
我們發現,元組是不可以修改的,但是我們的串列卻可以
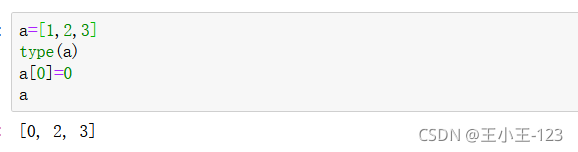
那么就會有小伙伴疑問了,那么不可修改,怎么辦!我們可以通過下面的方法:
直接在同一個元組上更新是不可行的,但是可以通過拷貝現有的元組片段構造一個新的元組的方式解決,
通過分片的方法讓元組拆分成兩部分,然后再使用連接運算子(+)合并成一個新元組,最后將原來的變數名(temp)指向連接好的新元組,在這里就要注意了,逗號是必須的,小括號也是必須的!
temp = ('小雞','小狗','小豬')
temp = temp[:2] + ('小猴子',) + temp[2:]
print(temp)
('小雞', '小狗', '小猴子', '小豬')洗掉元組中的元素:對于元組是不可變的原則來說,單獨洗掉一個元素是不可能的,當然你可以利用切片的方式更新元組,間接的洗掉一個元素,
temp = ('小雞','小狗','小豬')
temp = temp[:1] + temp[2:]
print(temp)
('小雞', '小豬')在日常中很少用del去洗掉整個元組,因為Python的回識訓制會在這個元組不再被使用的時候自動洗掉,如果整個洗掉那么就會報錯!!!
1.2 二維資料的表示

最簡單的方法就是使用串列進行二維陣列的創建,那么如果我們不使用這種方法,我們應該如何去做呢?

答案是:numpy的array()
我們也可以將一個numpy裝換為dataframe型別,也就是我們的二維資料表
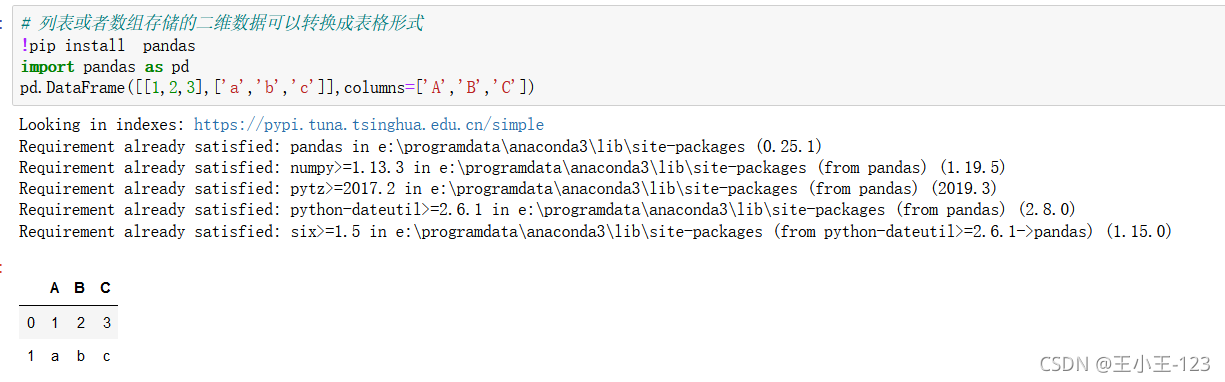
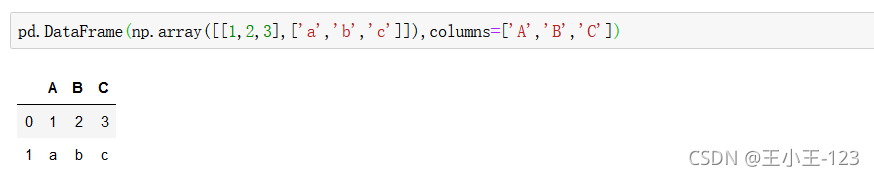
我們使用Python里面的最強大的pandas庫,進行處理,構造一個二維陣列,使用pandas里面的column方法,對陣列的標簽進行自定義,
1.3 三維資料的表示
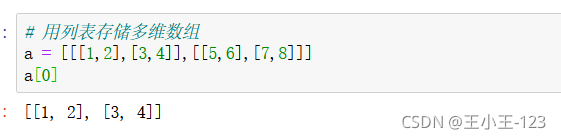
如何去理解這個維度呢?首先我們知道任何一個陣列都是需要一個[]進行包裹的,其實最為簡單的判斷方法就是看[]的個數,從左到右,數一下,三個,那么就是三維陣列,簡單粗暴但是言簡意賅,
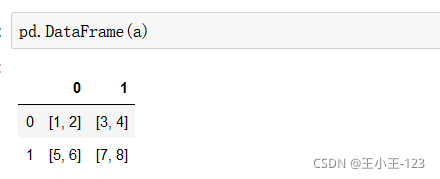
其實從資料表里面我們可以看出,如果需要組成這樣二維單獨的資料表,那么就是二維資料,在單元的資料表中,仍然存在陣列的嵌套,那么就是維度的+1
2、 為什么要使用Numpy
2.1、Numpy的ndarray具有廣播功能
查看版本
np.array?
可以查看官方的解釋,同時我們也可以使用np.info(np.array)對方法進行查看和學習
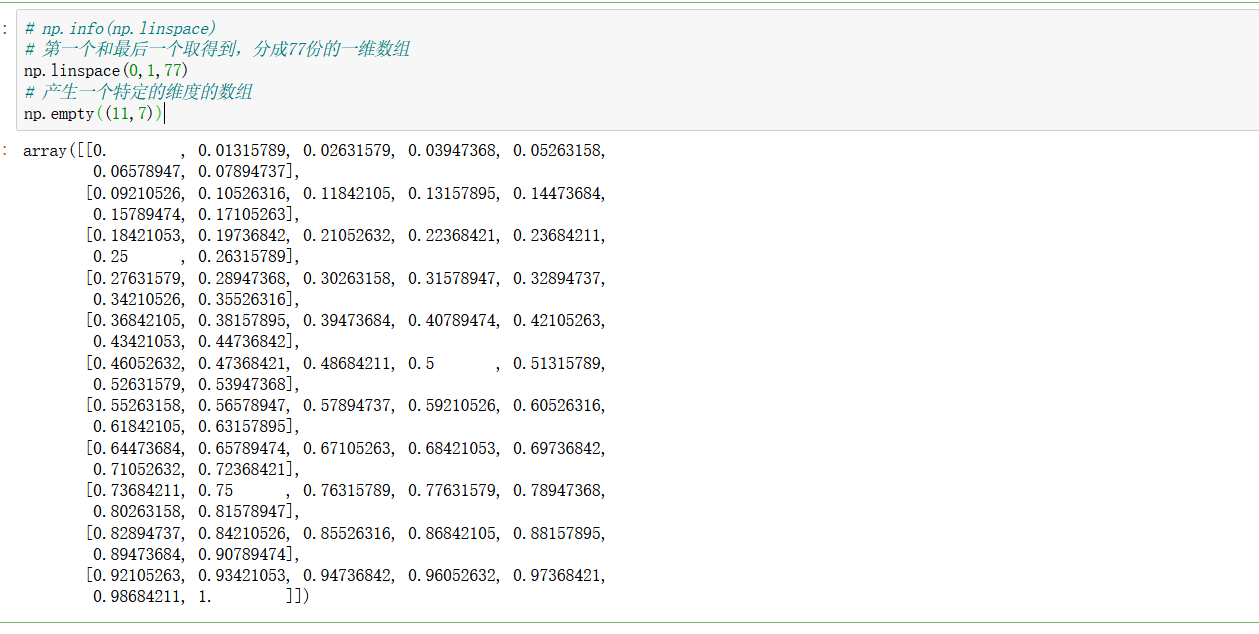
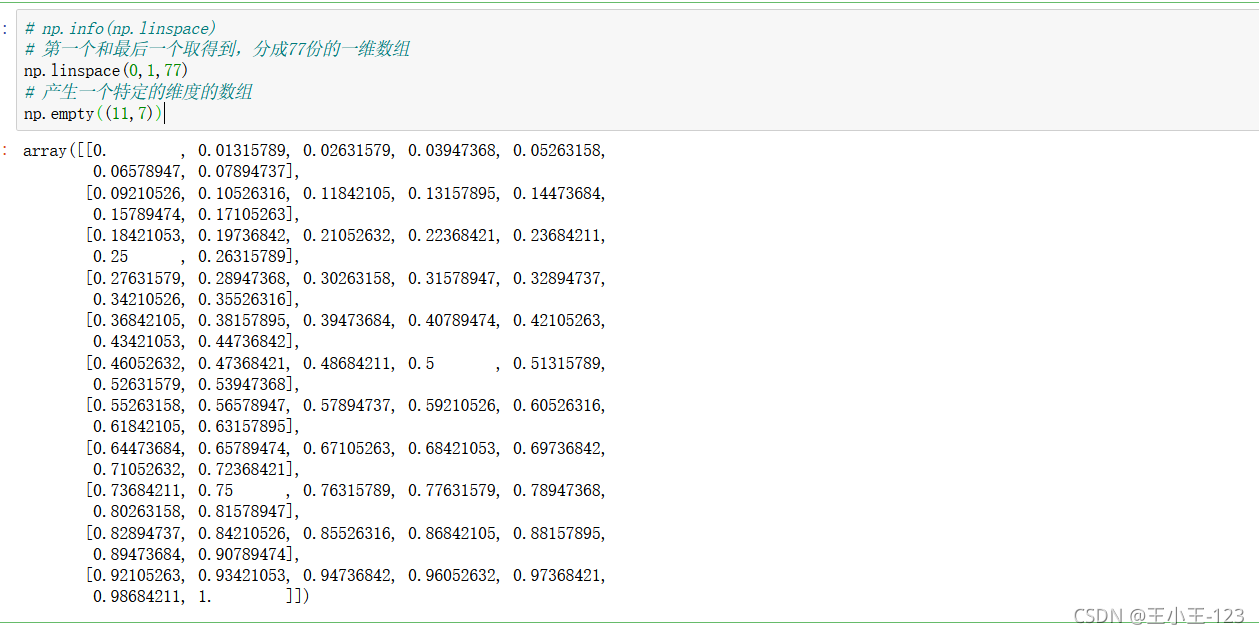
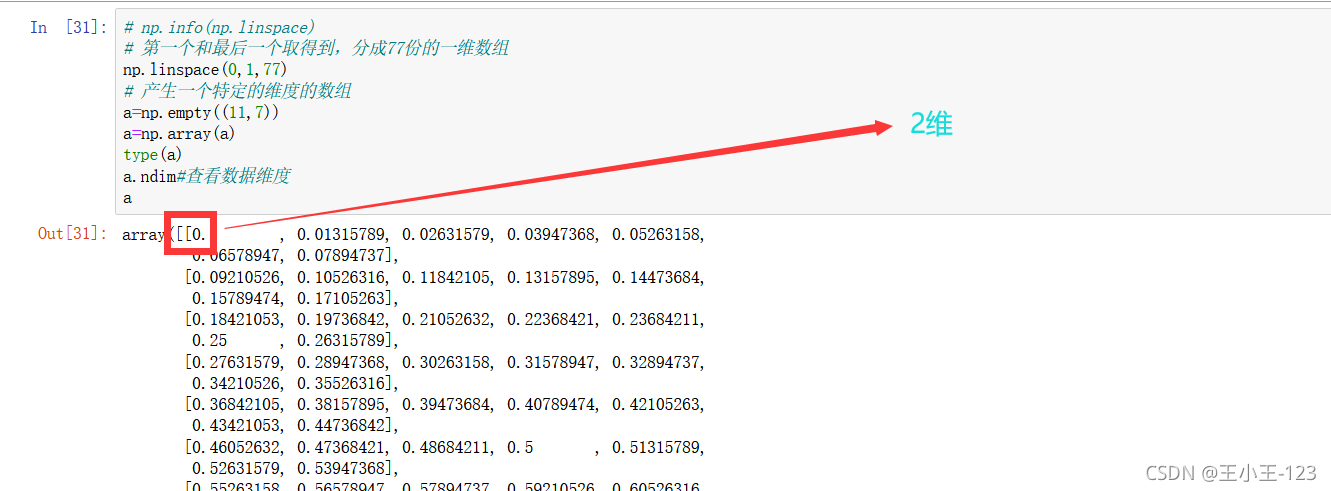
有時候我們需要產生一個特定范圍的的陣列,而且我們希望資料是平均的分配,這個時候我們我們就可以使用numpy的linspace()方法了,它的功能就是產生一個特定平均份數的一維陣列,
np.linspace(start,end,count):注意它會將開始元素和末尾的元素都取到,然后按照count份數進行分割
np.empty(行,列):也就是產生特定的維度,多少行和列的陣列
q = np.array([1,2,3,4],dtype=np.complex128)
print("資料型別",type(q)) #列印陣列資料型別
print("陣列元素資料型別:",q.dtype) #列印陣列元素資料型別
print("陣列元素總數:",q.size) #列印陣列尺寸,即陣列元素總數
print("陣列形狀:",q.shape) #列印陣列形狀
print("陣列的維度數目",q.ndim) #列印陣列的維度數目 初學者總是把這些屬性記成了方法,注意我們的屬性是沒有()的
2.2 Numpy陣列的性能比Python原生資料型別高
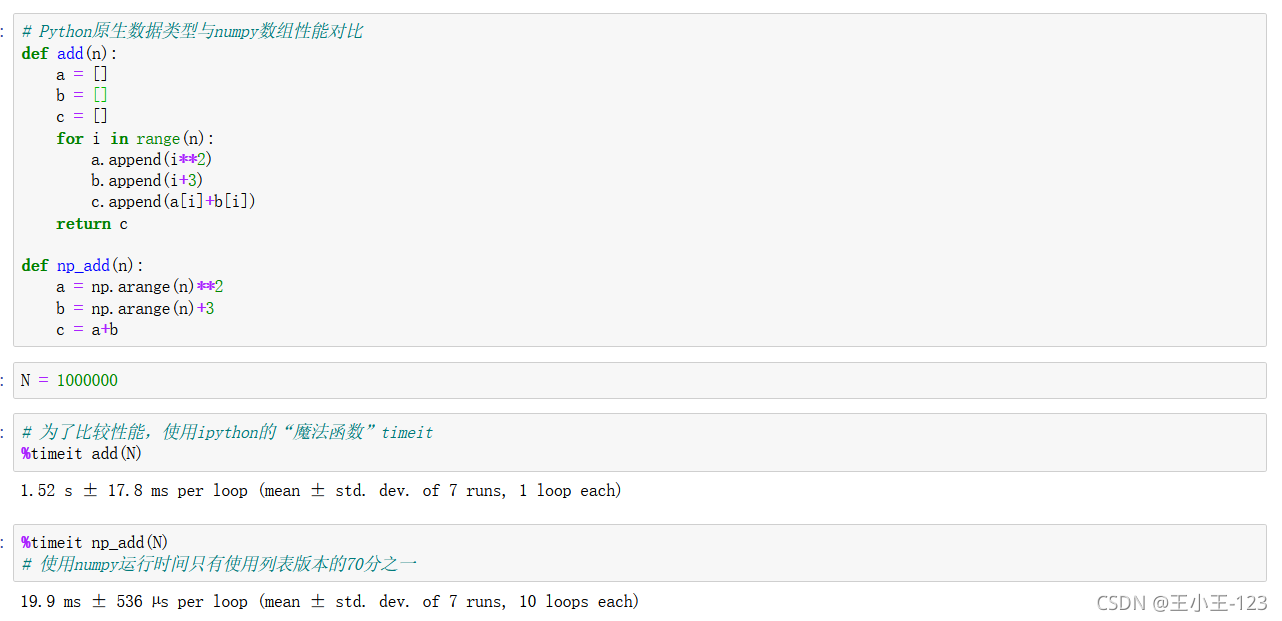
通過這個例子,我們可以看到numpy的效率遠遠高于我們的list串列原生態的執行速度和效率
3 ndarray的屬性和基本操作
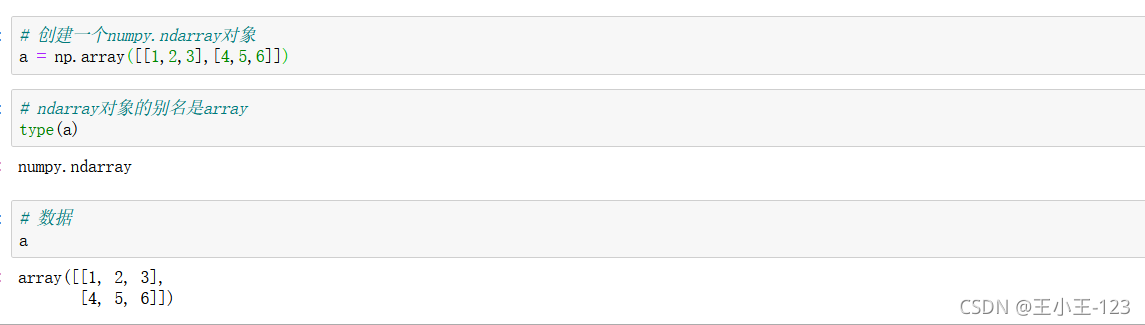
3.1 ndarray的基本屬性
 3.2 ndarray元素型別
3.2 ndarray元素型別
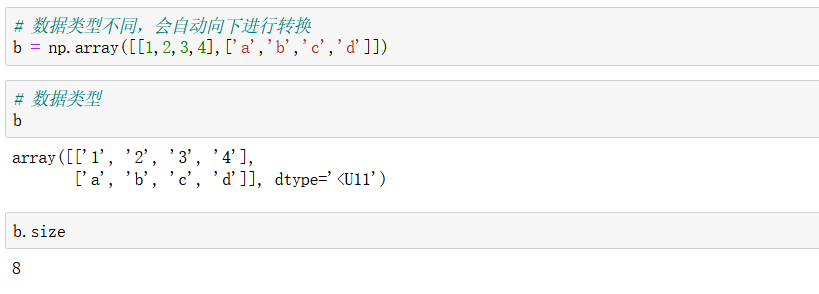
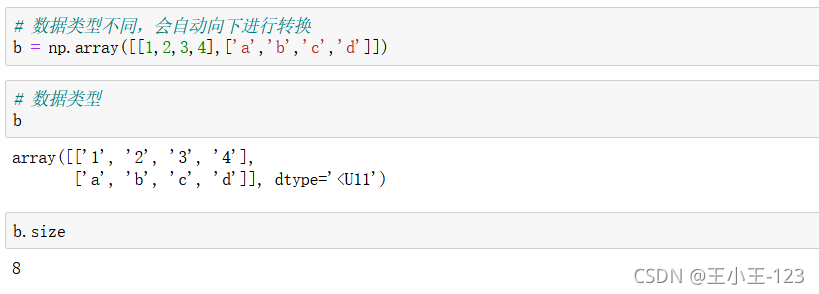
那么有時候我們再想,如果陣列的長度不一致,那么會不會有影響呢?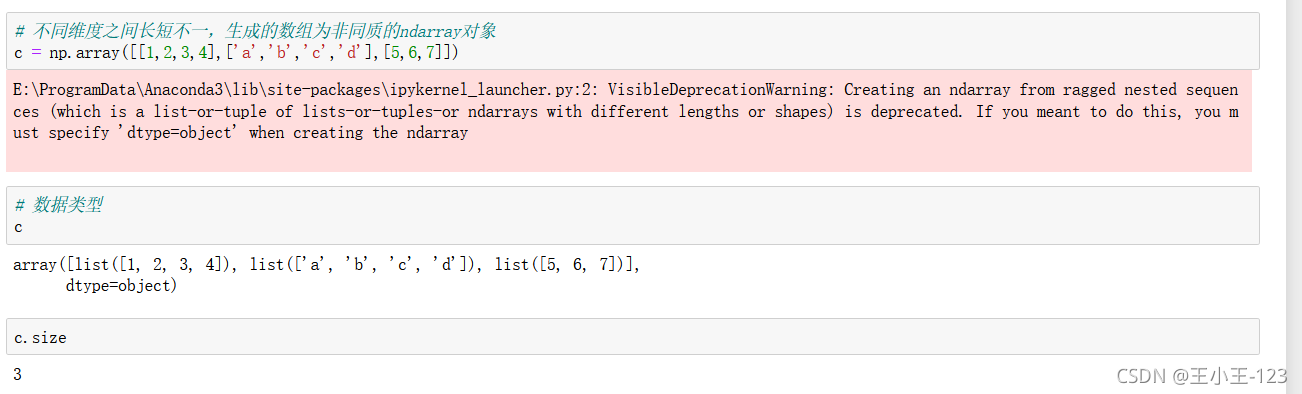
通過例子,我們發現,如果構造的資料長度不一致,不會報錯,但是會發出警告,也就是說這種方法,在Python里面還是支持的,但是我們發現它被單獨的構造為一個list型別了,元素大小也就發生了改變,將一個串列嵌套在一個串列當中,
我們可以看看長度一致的情況:
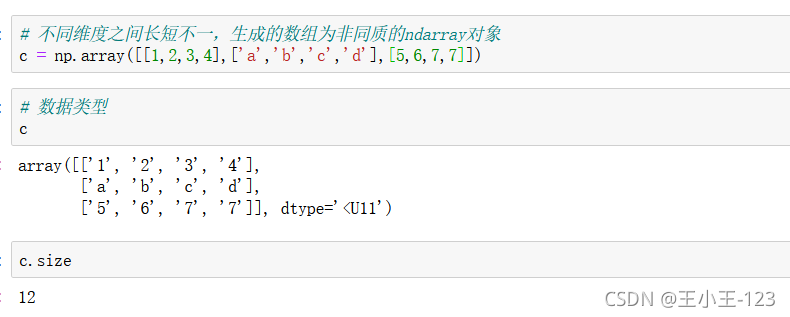
顯然是符合我們的要求的
3.3 創建ndarray的方式
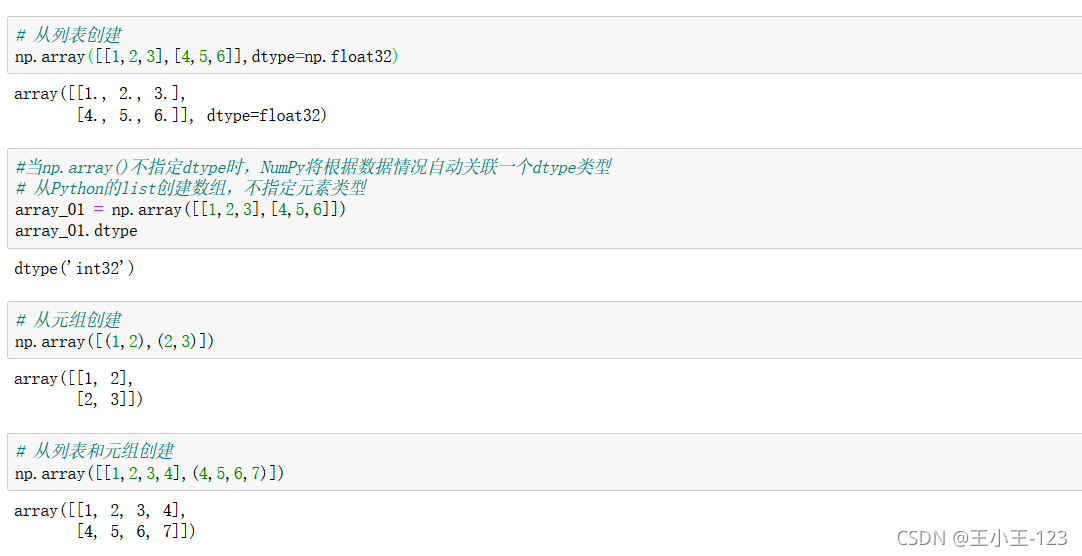
創建的時候可以指定我們的資料型別

np.arange(),回傳的是序列陣列,最后一個取不到,一維的
np.ones(3,4),回傳的是3行4列的全1陣列,如果里面有三個數字,那么第一數字代表里面,有多少個單獨獨立的陣列
np.zeros(陣列,行,列)生成一個多少個獨立陣列,每個獨立陣列里面有多少行,多少列,最后型別是全0陣列,如下:

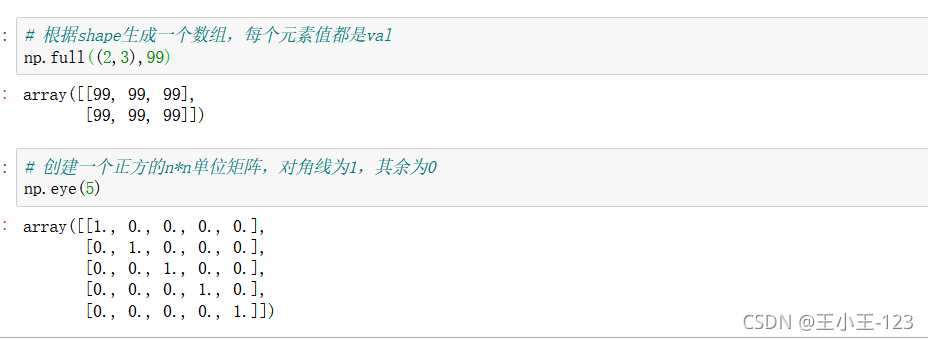
np.full((n,m),value),生成一個特定維度的陣列,且元素由自己定義
np.eye(n),生成一個nxn的單位矩陣
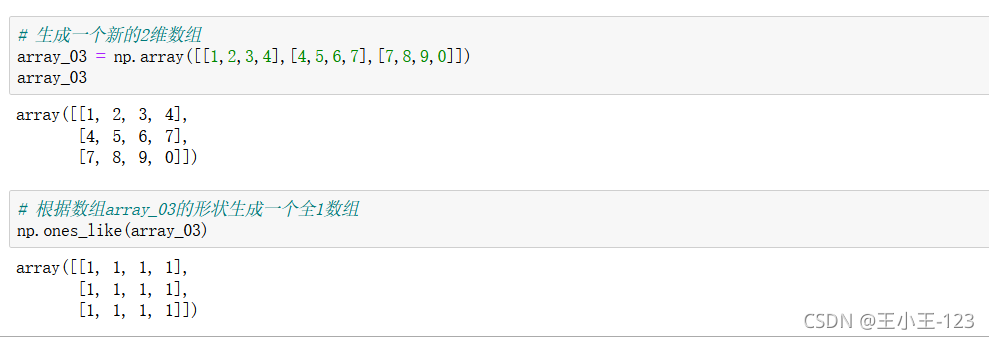
np.ones_like(array),生成一個和目標陣列一樣的全1陣列
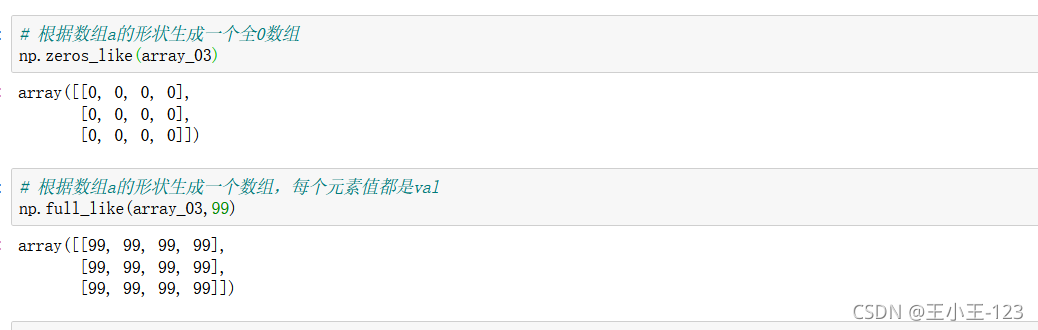
使用np.linspace(),形成新的一維序列陣列
使用np.concatenate((array1,array2),axis=0):按照行進行拼接
np.concatenate((array1,array2),axis=1):按照列進行拼接

如果這里使用橫向連接,那么就會報錯,為了防止報錯,我們可以使用裝置功能
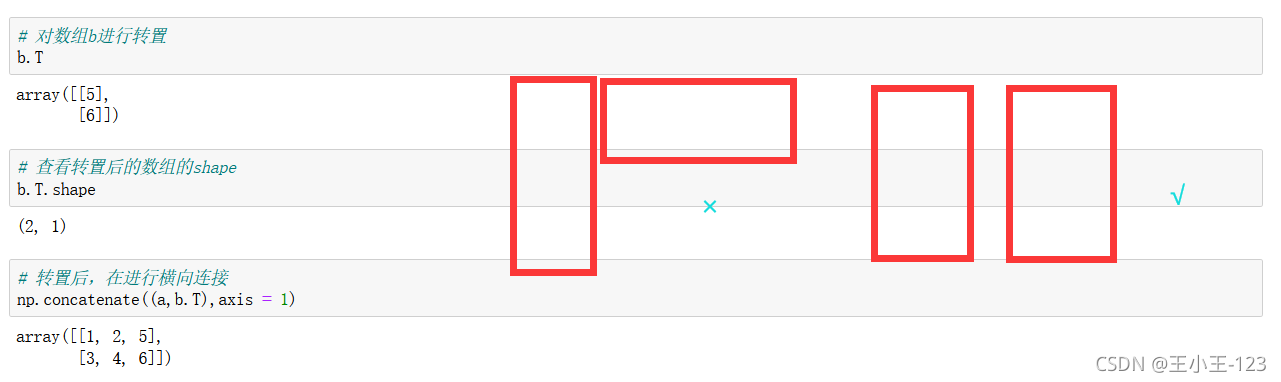
拼接也要注意,是否可以!!!
3.4 ndarray物件的變換
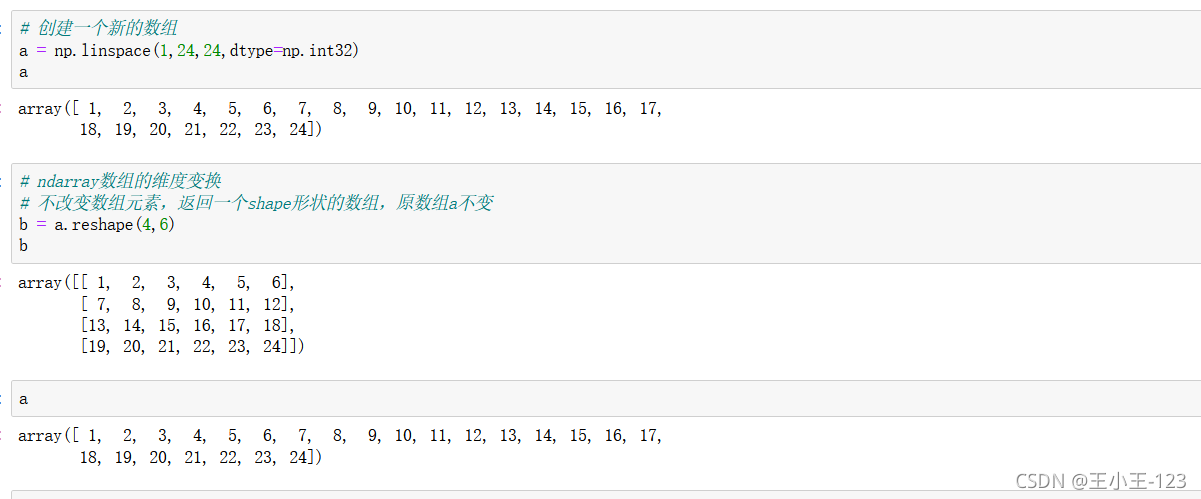
我們可以根據自己需要變換我們的一維陣列,為多維陣列,使用reshape(行,列)

這個方法也可以修改,但是要注意的是:resize(方法)修改的是原陣列,而reshape(方法)并沒有修改原陣列,需要賦值給新的變數,該修改才能生效,
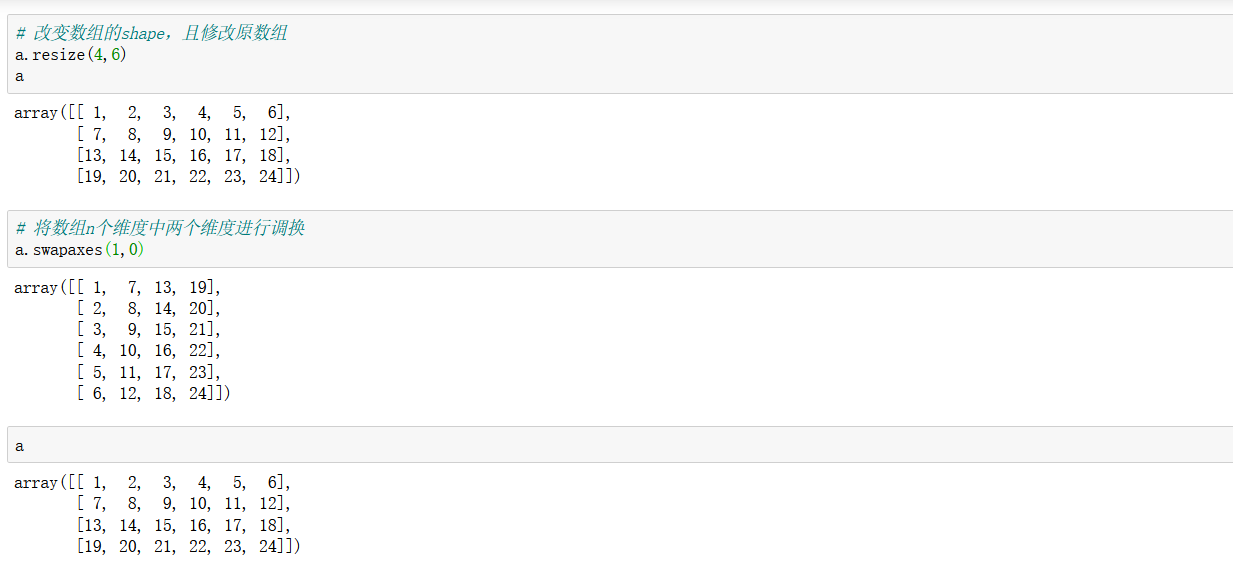
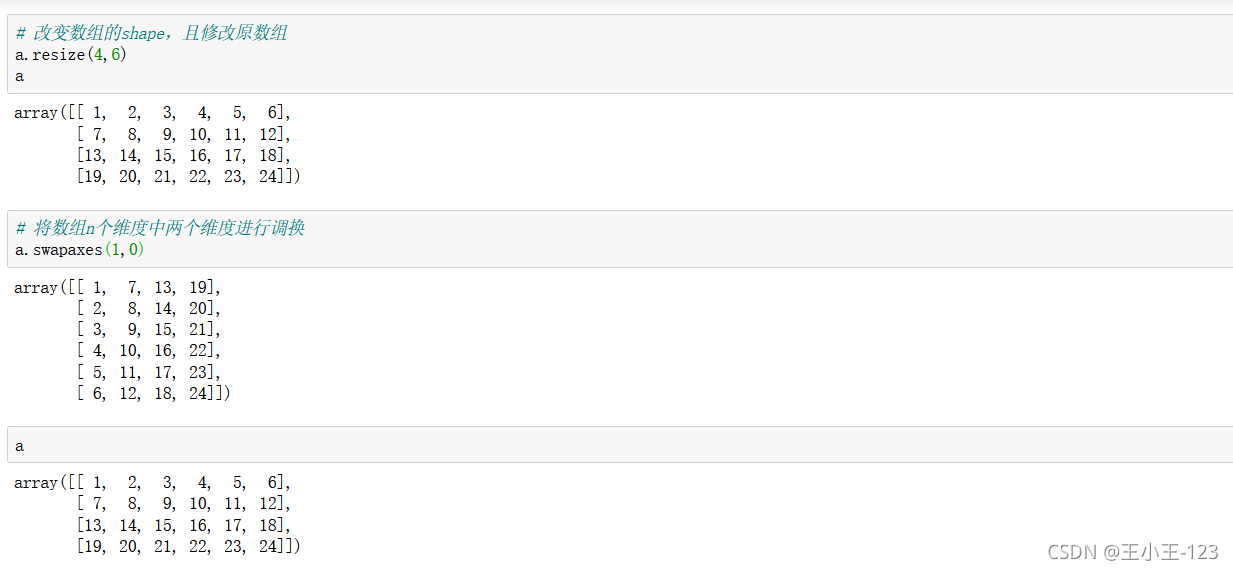
使用swapaxes(1,0)進行維度調換,原來的行數變成現在的列數,不改變原陣列
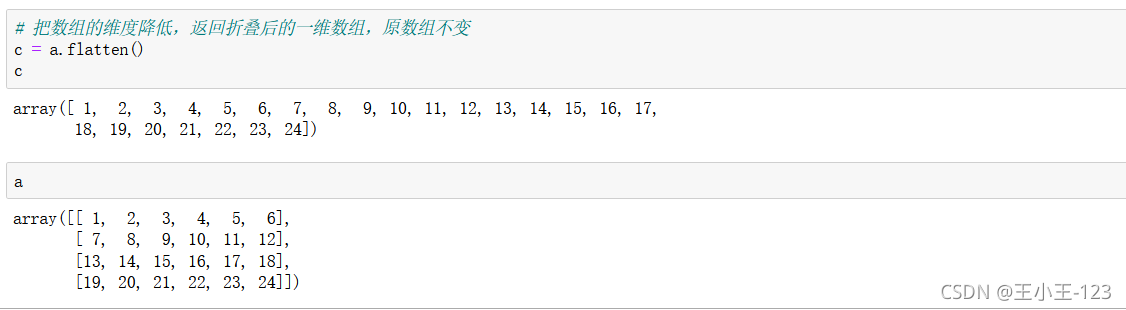
flatten()降維處理,一維,不改變原陣列
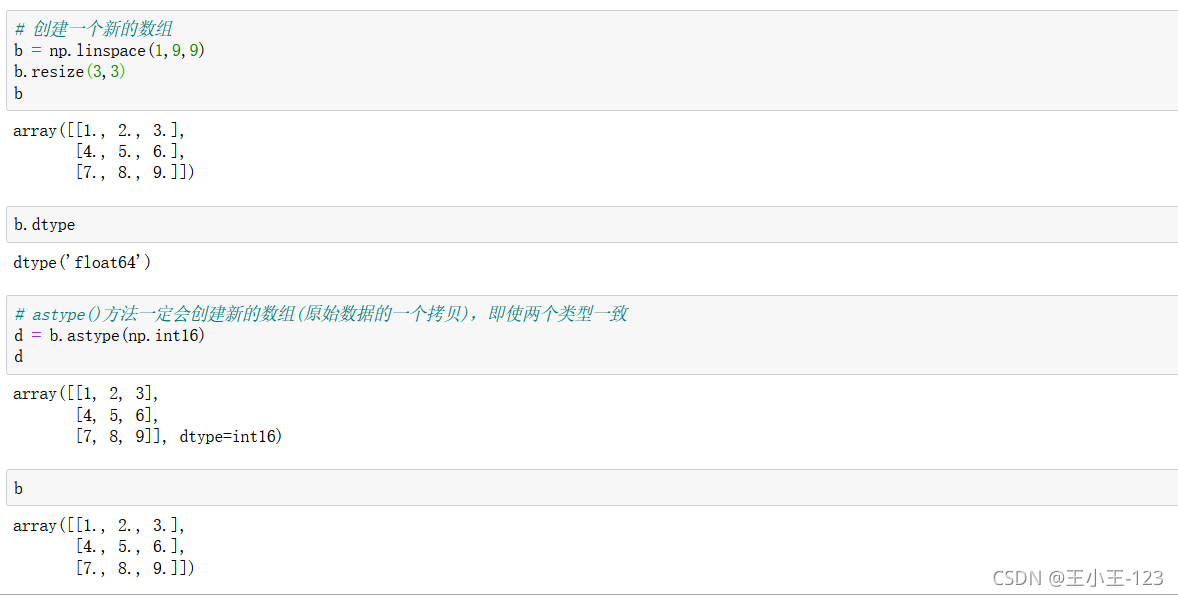
astype(np.int16),或者其他的numpy資料型別,直接拷貝資料型別格式

轉換為list型別
3.5 ndarray物件的操作
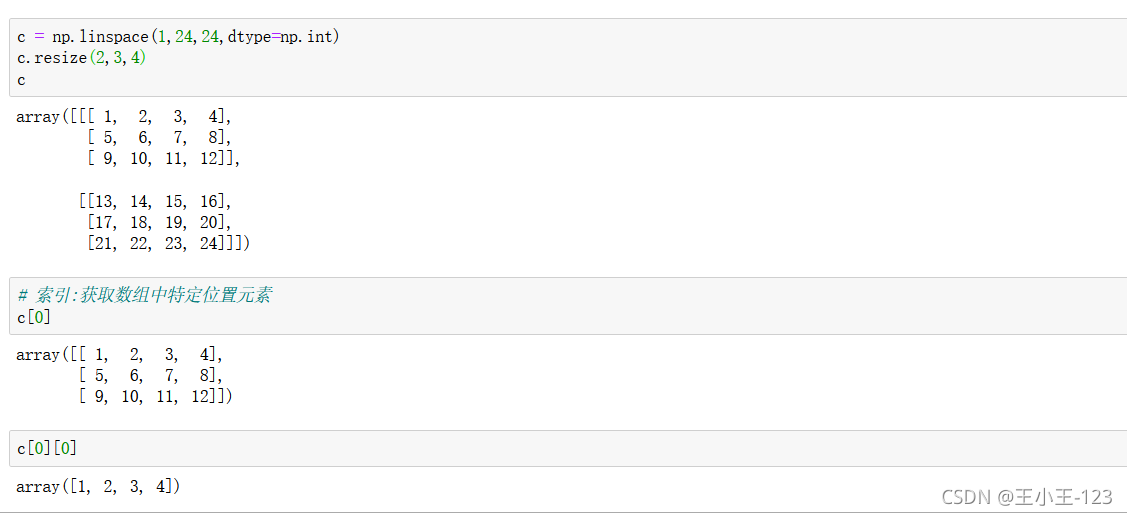
索引和我們Python里面的較為相似,如果里面存在多個獨立陣列,那么第一個索引只取出大的陣列框,然后后面對應的就是行和列
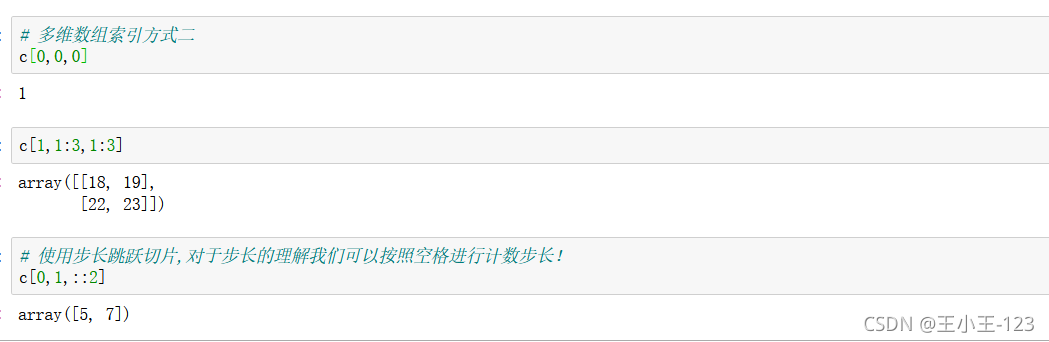
對于步長而言,我們要明確的是,索引從0開始,最后一個索引永遠取不到,其次,不寫出的索引為默認取到,對于步長取索引,我們按照空格方法記憶最好!
4 、Numpy的函式與陣列運算
4.1 陣列與標量之間的運算
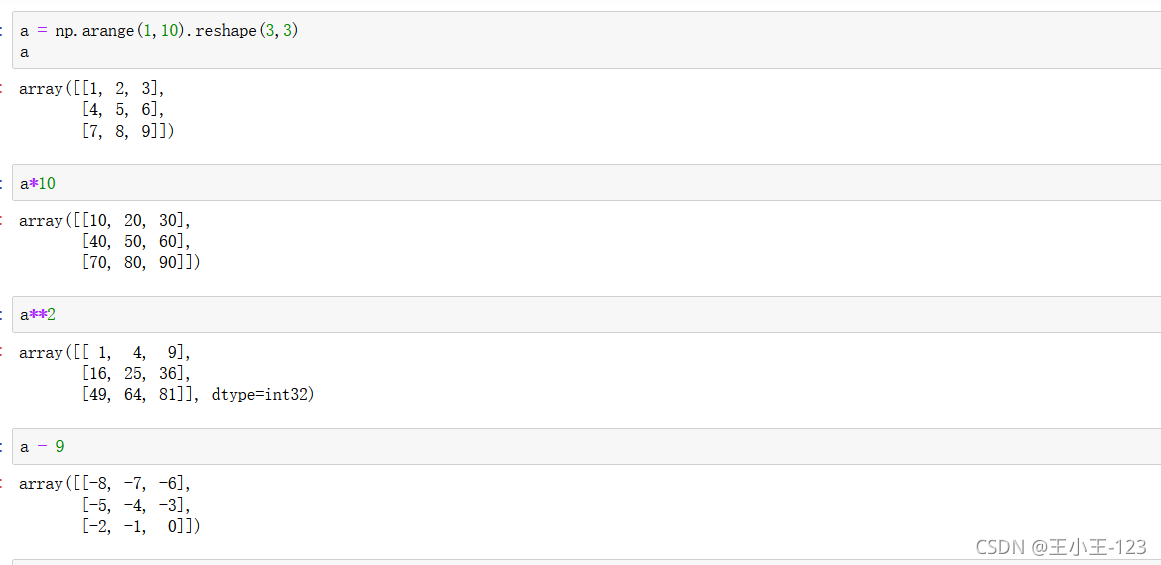
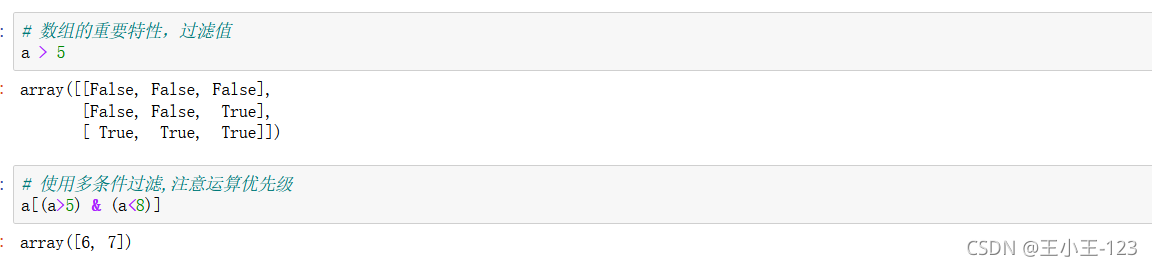
4.2 對陣列的元素進行運算
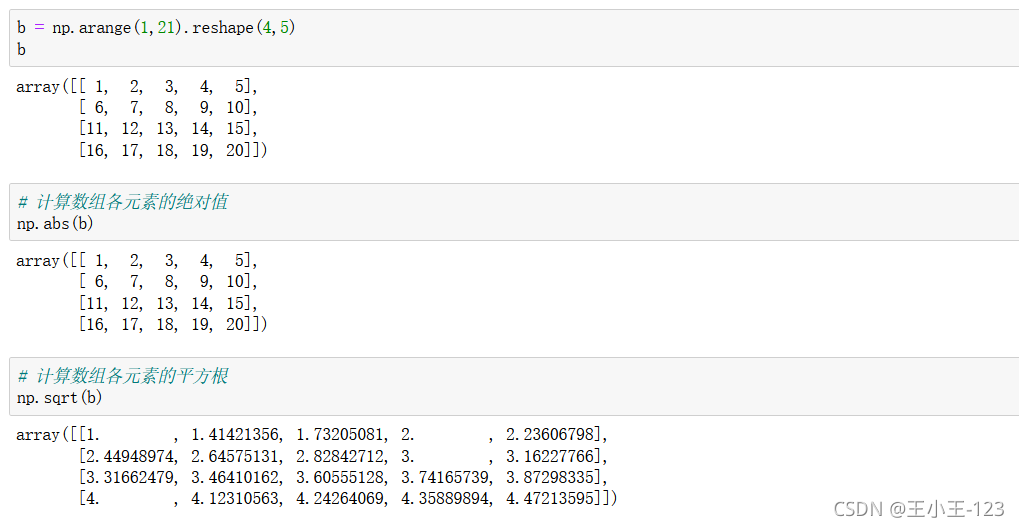
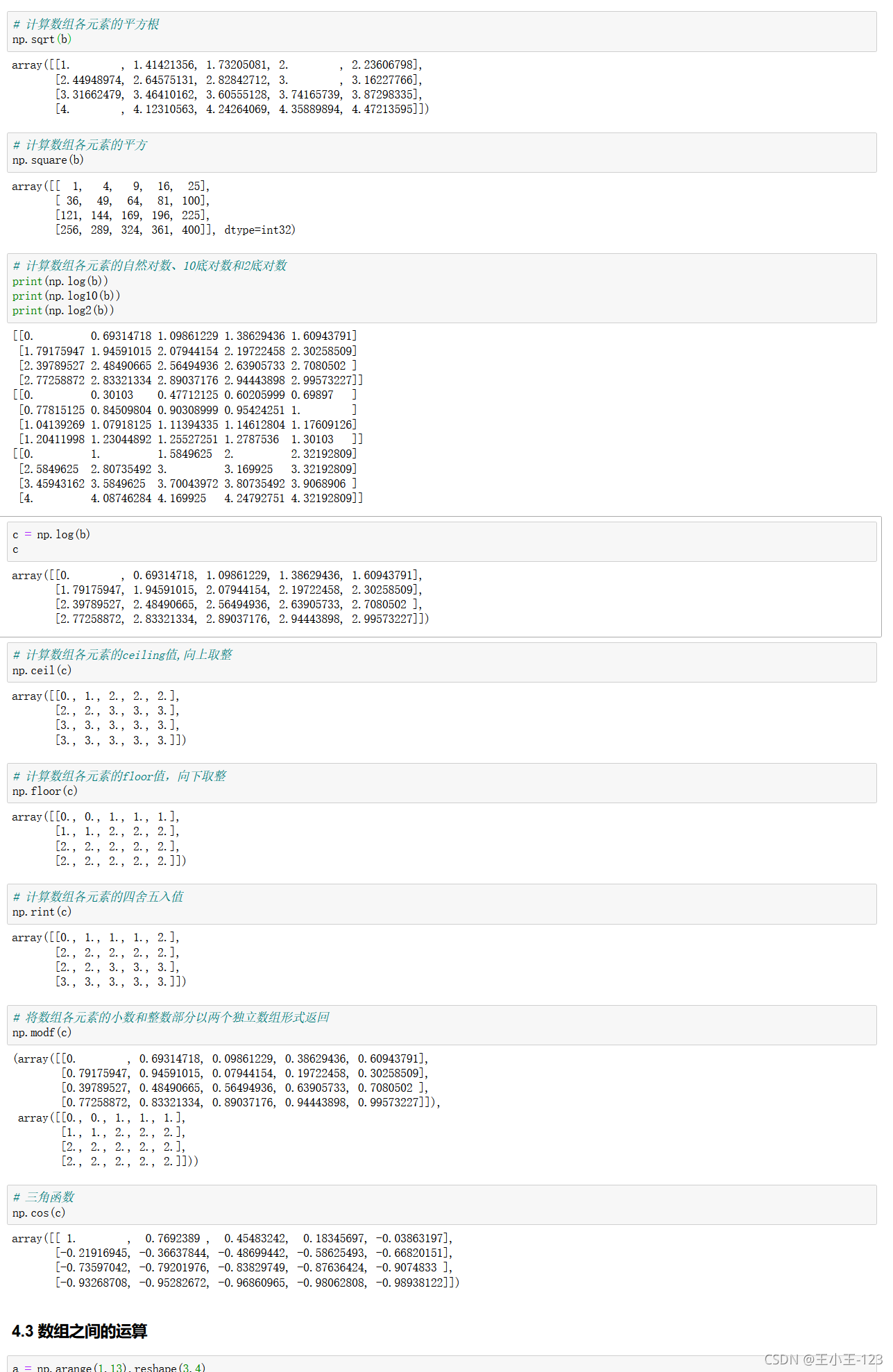
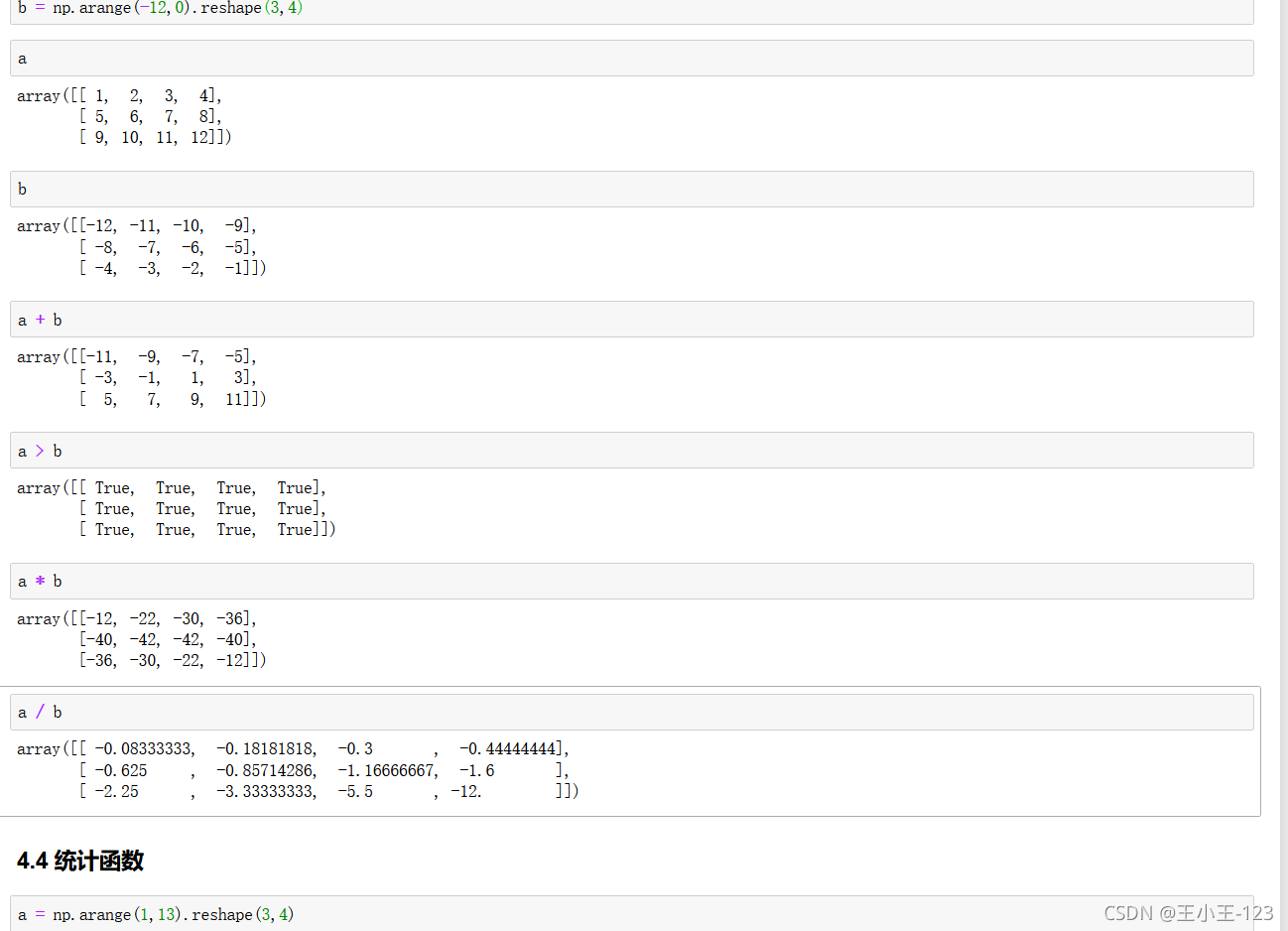
4.3 陣列之間的運算
4.4 統計函式
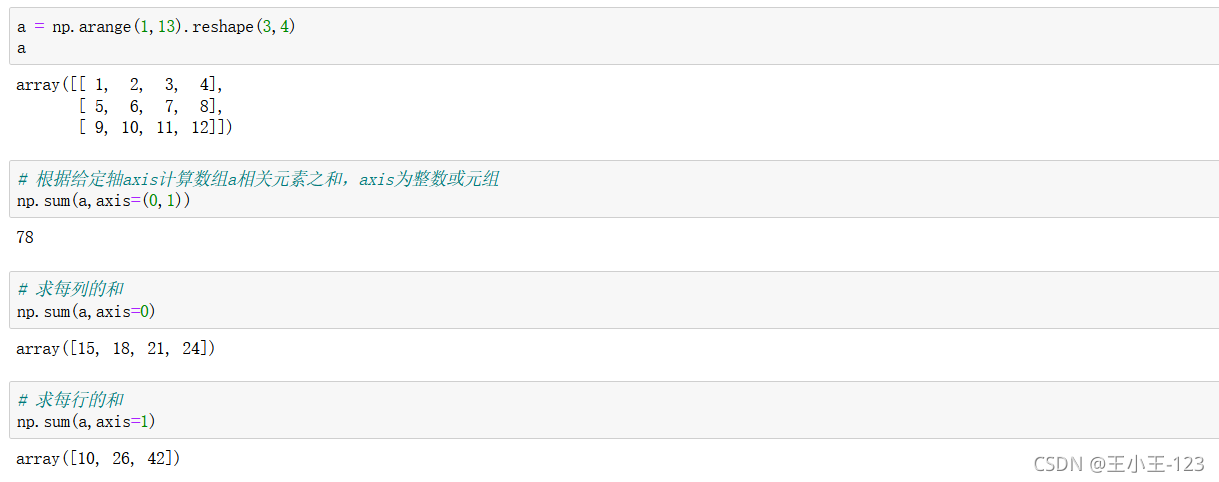
np.sum(array,axis=(0,1))對行和列進行求和,那么就是所有元素相加,如果是1,那么就是行,0就是列
有小伙伴對axis=1,0的具體含義有很多的疑問:這里給出解釋:
注意看,官方對于0和1的解釋是軸,也就是坐標軸,而坐標軸是有方向的,所以千萬不要用行和列的思維去想axis,因為行和列是沒有方向的,這樣想會在遇到不同的例子時感到困惑,
根據官方的說法,1表示橫軸,方向從左到右;0表示縱軸,方向從上到下,當axis=1時,陣列的變化是橫向的,而體現出來的是列的增加或者減少,
其實axis的重點在于方向,而不是行和列,具體到各種用法而言也是如此,當axis=1時,如果是求平均,那么是從左到右橫向求平均;如果是拼接,那么也是左右橫向拼接;如果是drop,那么也是橫向發生變化,體現為列的減少,
當考慮了方向,即axis=1為橫向,axis=0為縱向,而不是行和列,那么所有的例子就都統一了,

對于這些方法,熟悉和掌握是兩回事,熟能生巧.......
4.5 隨機函式
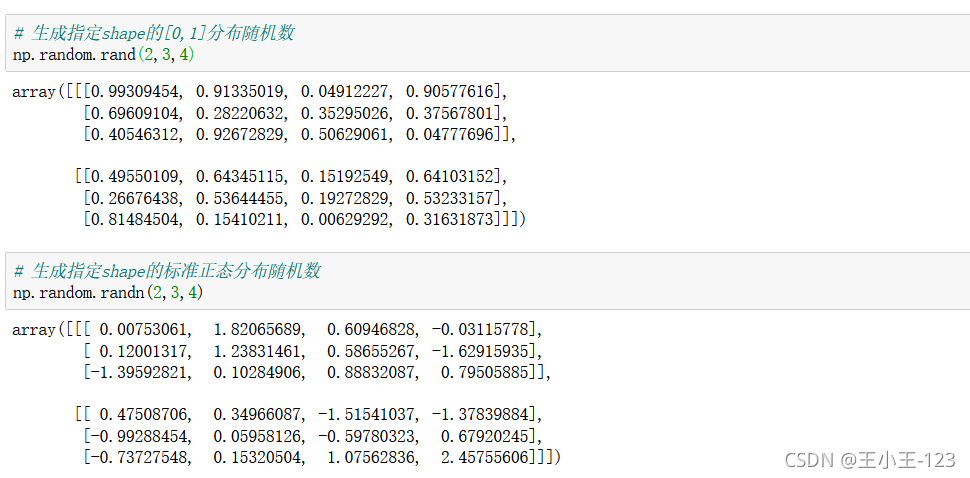
仔細觀察這兩個方法:
np.random.rand()是產生0,1的分布亂數
np.random.randn()產生的是標準正態分布亂數
有n的是正態分布亂數,沒有的是0,1的亂數

隨機種子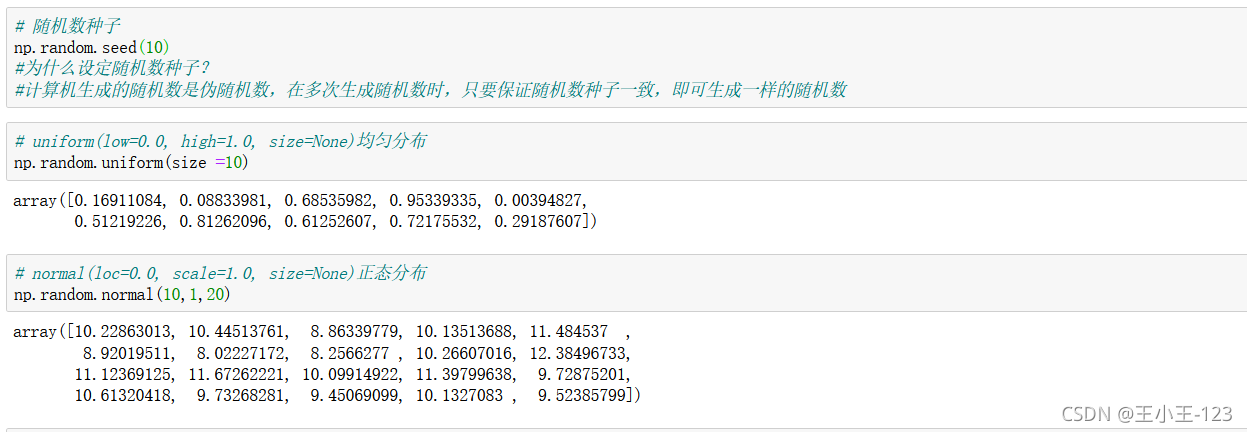

陣列打亂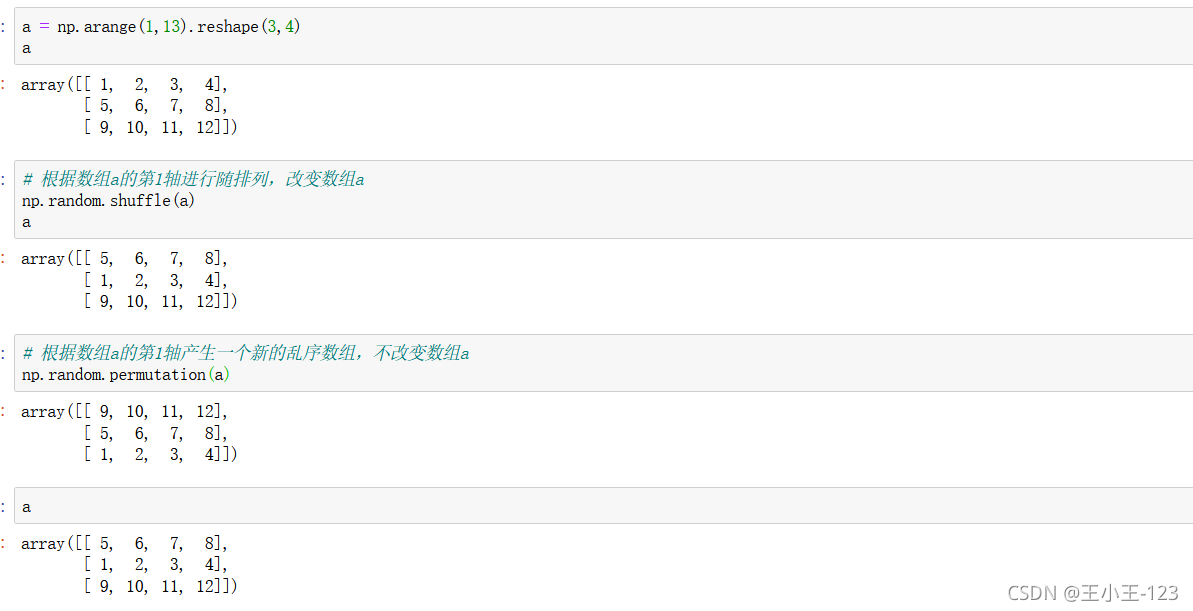


5 、Numpy資料的存取
5.1 csv資料檔案的存取
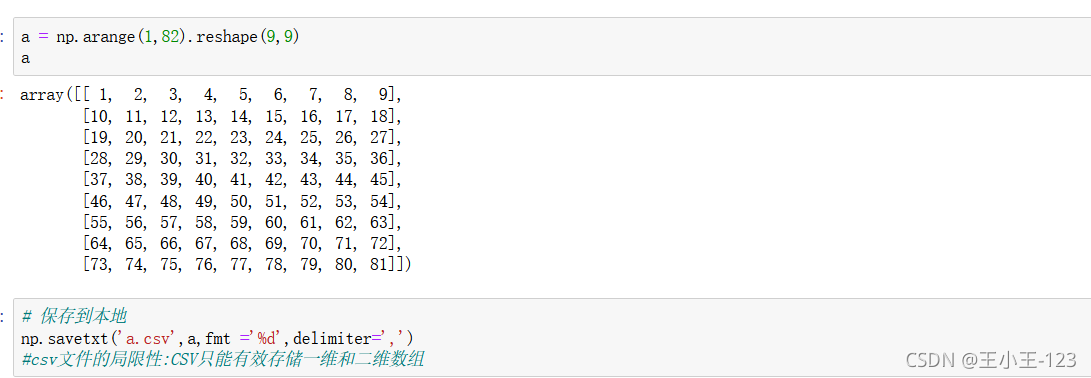
![]()
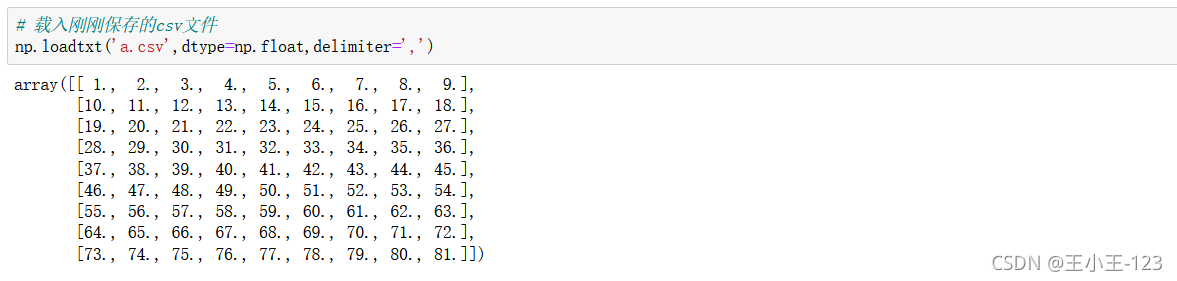
一般在numpy里面對于資料保存和載入,沒有經常性的要求,因為在pandas里面提供了大量的方法,為我們載入和保存,
Pandas簡介
Python Data Analysis Library 或 pandas 是基于NumPy 的一種工具,該工具是為了解決資料分析任務而創建的,Pandas 納入了大量庫和一些標準的資料模型,提供了高效地操作大型資料集所需的工具,pandas提供了大量能使我們快速便捷地處理資料的函式和方法,你很快就會發現,它是使Python成為強大而高效的資料分析環境的重要因素之一,
Series:一維陣列,與Numpy中的一維array類似,二者與Python基本的資料結構List也很相近,其區別是:List中的元素可以是不同的資料型別,而Array和Series中則只允許存盤相同的資料型別,這樣可以更有效的使用記憶體,提高運算效率,
Time- Series:以時間為索引的Series,
DataFrame:二維的表格型資料結構,很多功能與R中的data.frame類似,可以將DataFrame理解為Series的容器,以下的內容主要以DataFrame為主,
Panel :三維的陣列,可以理解為DataFrame的容器,
Pandas 有兩種自己獨有的基本資料結構,讀者應該注意的是,它固然有著兩種資料結構,因為它依然是 Python 的一個庫,所以,Python 中有的資料型別在這里依然適用,也同樣還可以使用類自己定義資料型別,只不過,Pandas 里面又定義了兩種資料型別:Series 和 DataFrame,它們讓資料操作更簡單了,
Pandas操作集合
1 、pandas資料結構之Series
1.1 創建Series
# 匯入pandas和numpy
!pip install numpy
!pip install pandas
import pandas as pd
import numpy as np1.1.1 從ndarray創建Series
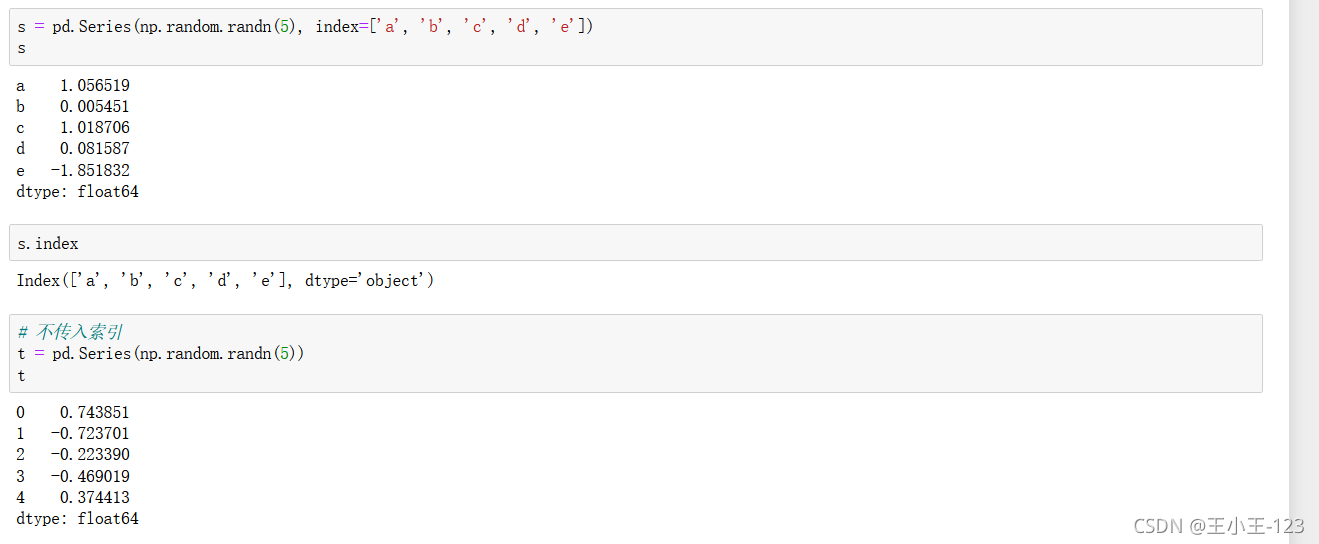
pd.Series():創建一個資料表,里面的index提供了索引的方法,給出的是一個串列的型別,
同時也可以使用index取出標簽索引
1.1.2 從字典或串列創建Series
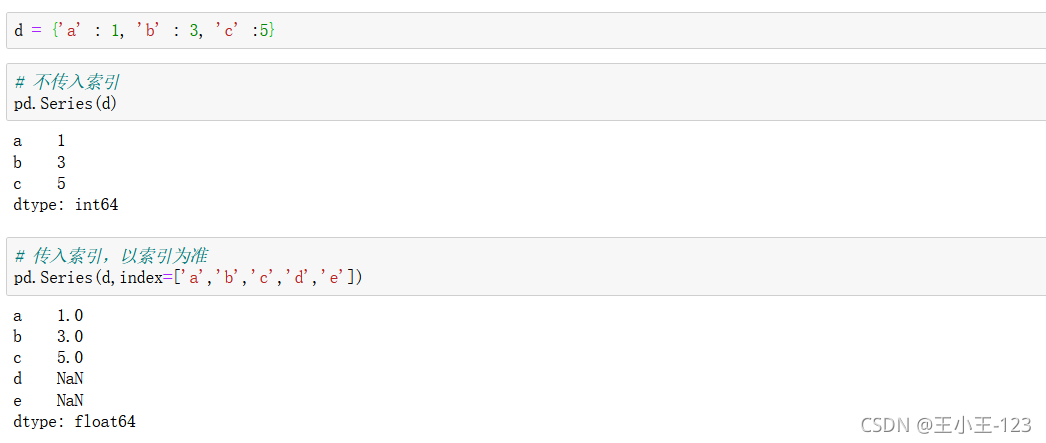
Series提供了字典的型別,進行組合,就算是我們有缺失的鍵值對,但是我們可以自己定義標簽index
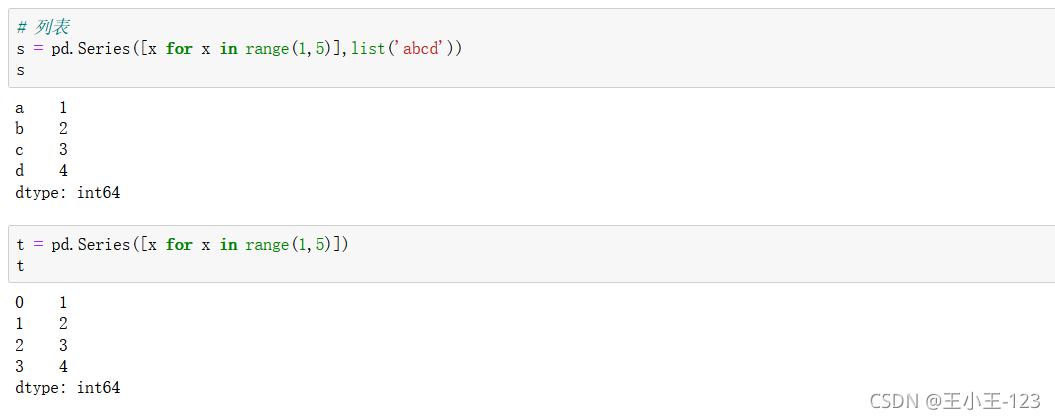
串列也可以完成,這在我們進行爬蟲的時候,我們可以用串列容器進行,存盤
1.1.3 從標量創建
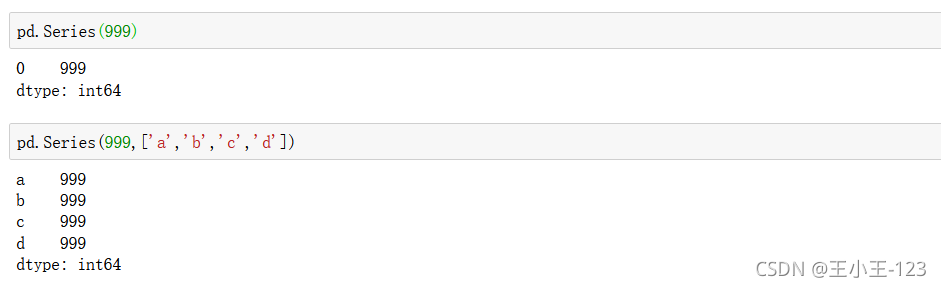
創建的是一樣的值,我們可以根據自己的需要進行
1.2 對Series的操作
1.2.1 Series和ndarray相似的操作
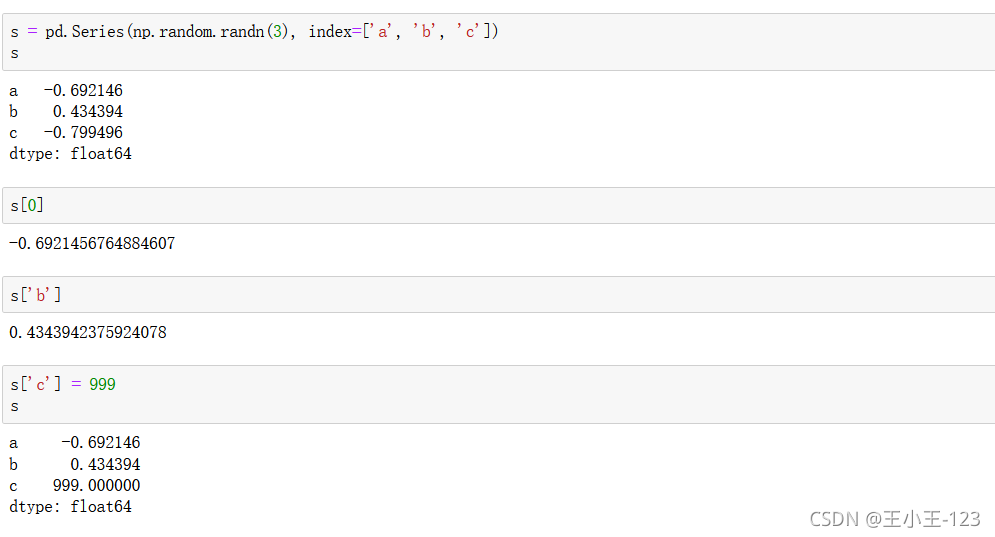
按照索引進行取值和修改
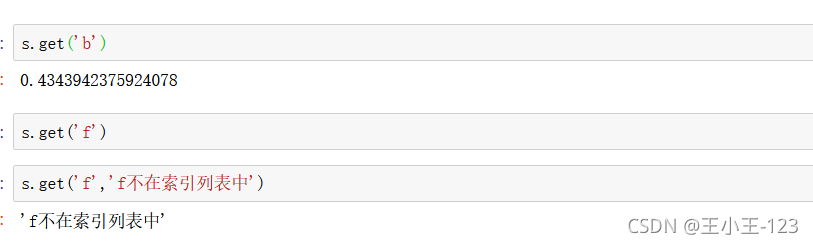
get()方法,如果存在這樣的鍵值對,那么就可以取出來,但是如果不存在,就會使用后面的那個默認值
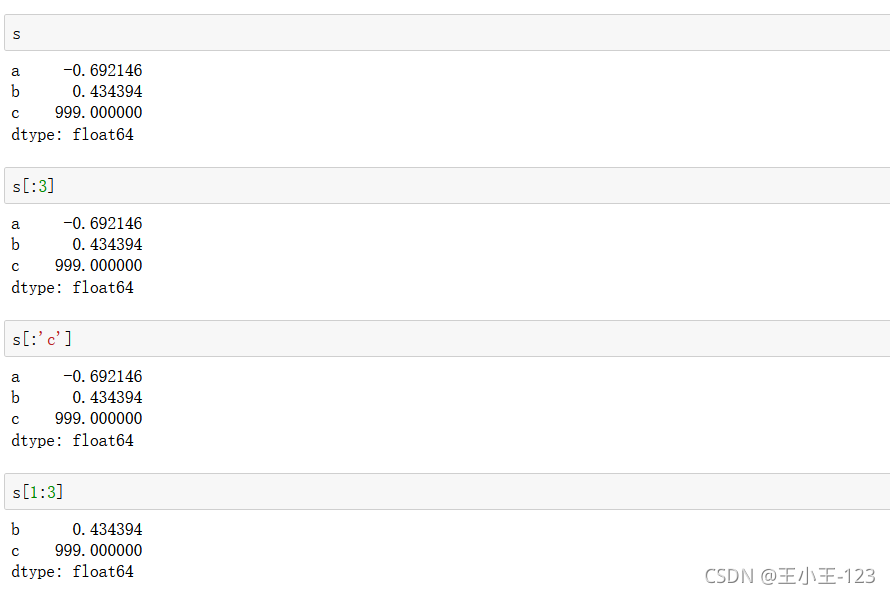
索引切片和我們之前介紹的Python內置方法也是一樣,和numpy里面的思想也差不多,這里就不多多贅述了,

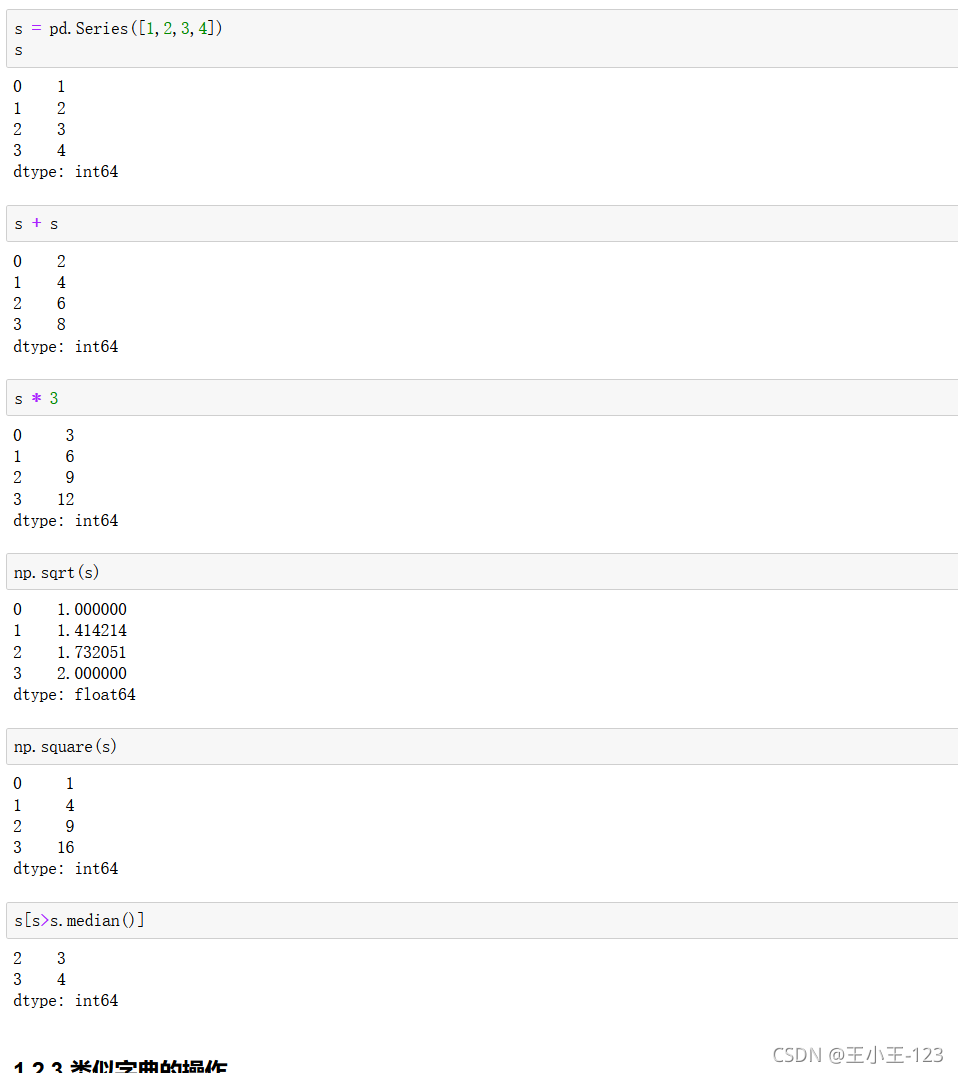
1.2.2 向量化運算
1.2.3 類似字典的操作
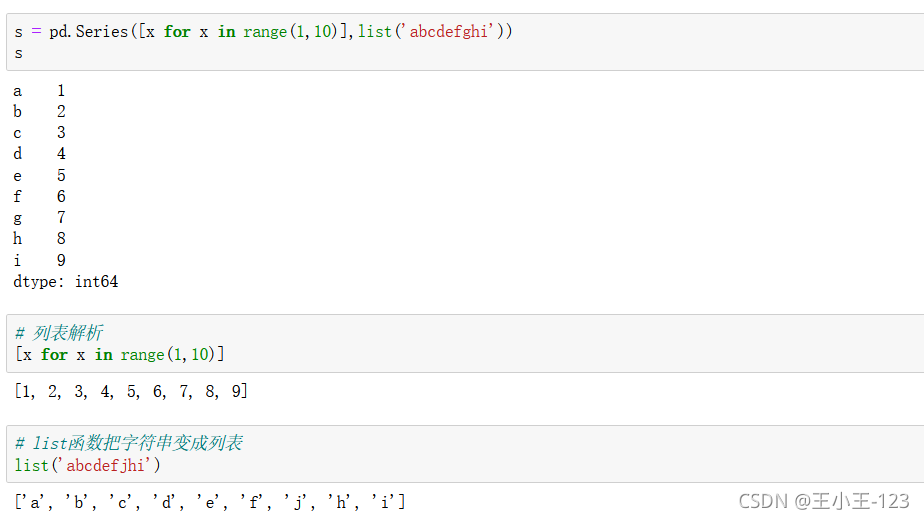
我們發現串列決議原來如此的強大,為我們減輕很多的麻煩,其實如果你熟練掌握Python的基礎語法,這一點你也是可以理解的
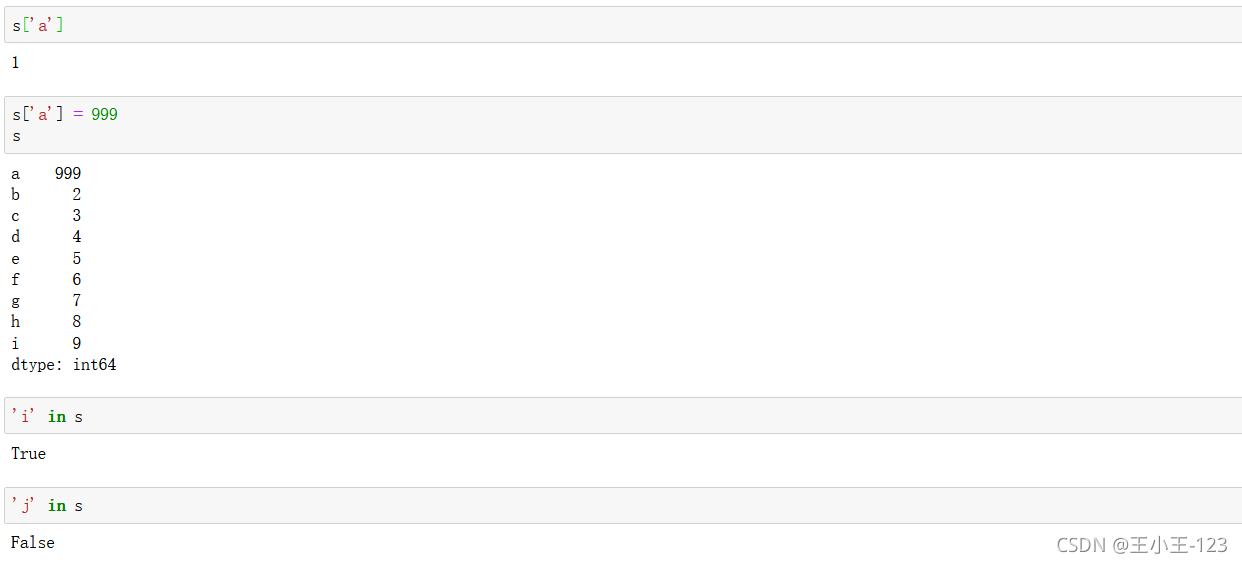
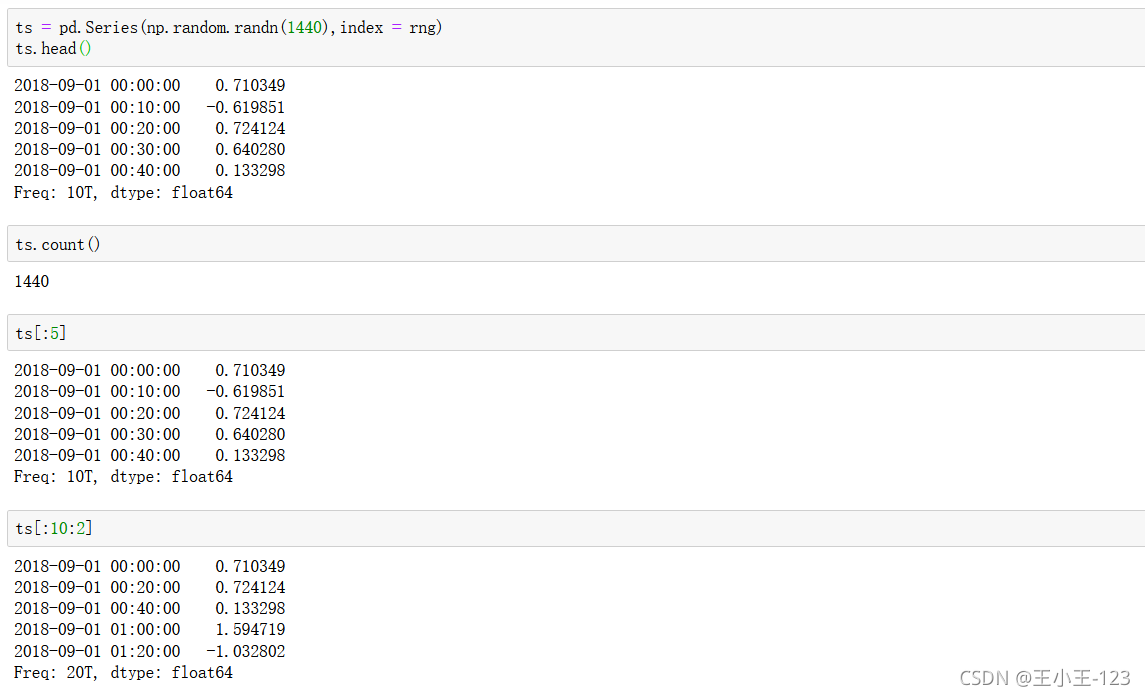
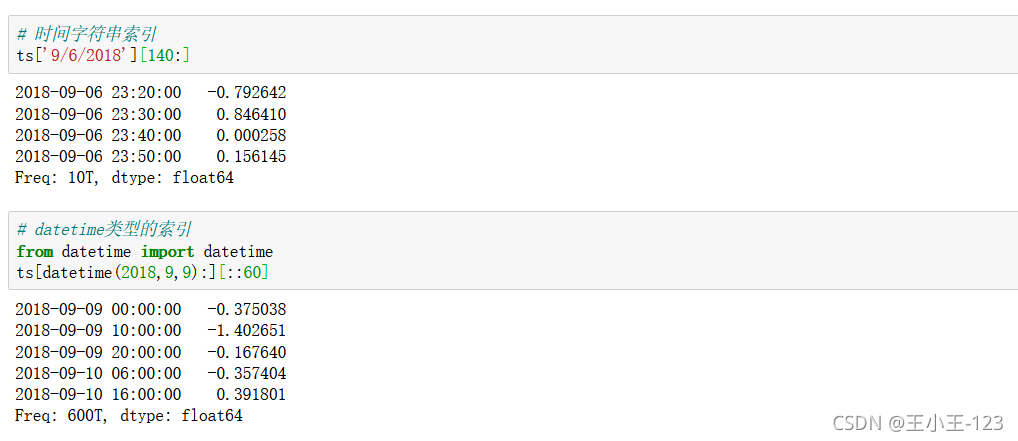
1.2.4 時間序列操作
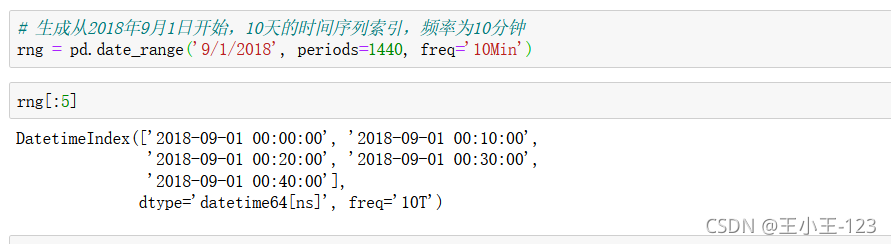 pd.date_range():
pd.date_range():
pd.date_range(
start=None,#開始時間
end=None,#截止時間
periods=None,#總長度
freq=None,#時間間隔
tz=None,#時區
normalize=False,#是否標準化到midnight
name=None,#date名稱
closed=None,#首尾是否在內
**kwargs,
)
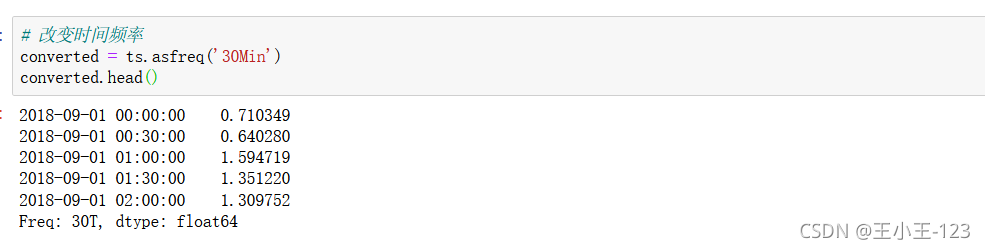
asfreq("時間頻率"):改變時間頻率
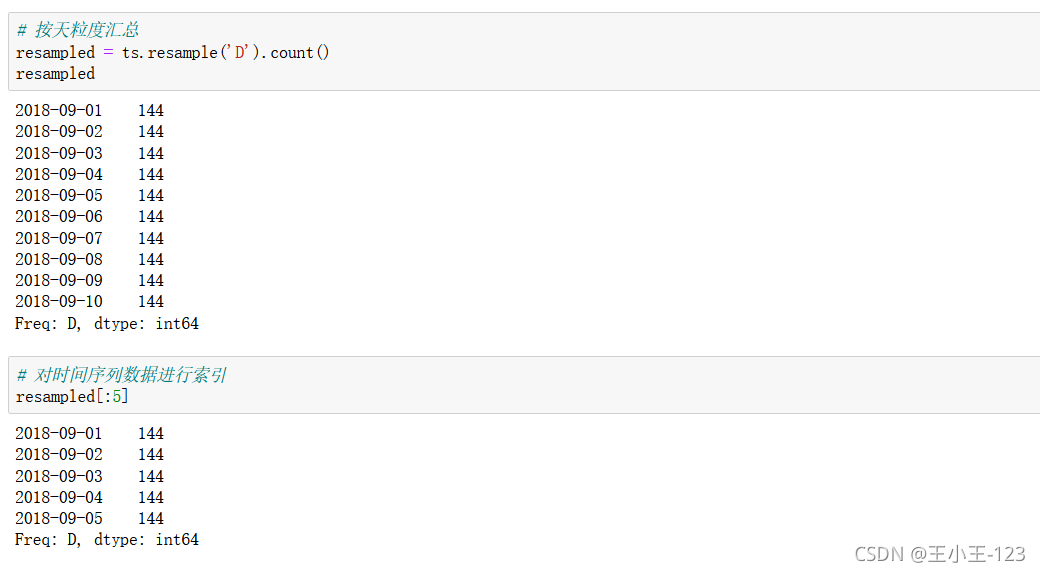
索引思想依然一致
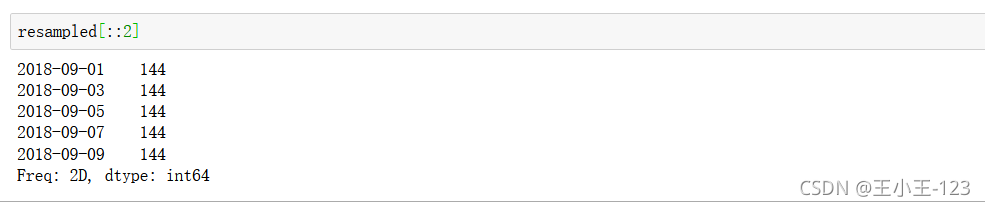
按照步長進行索引的搜尋
2、pandas資料結構之DataFrame
2.1 DataFrame的創建
2.1.1 從Series or dicts創建
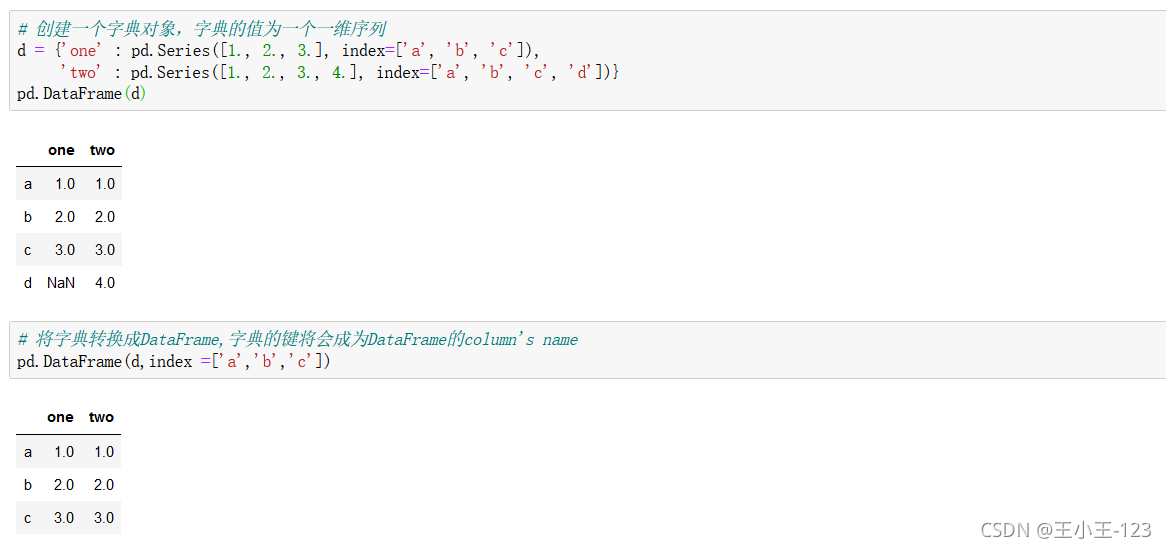
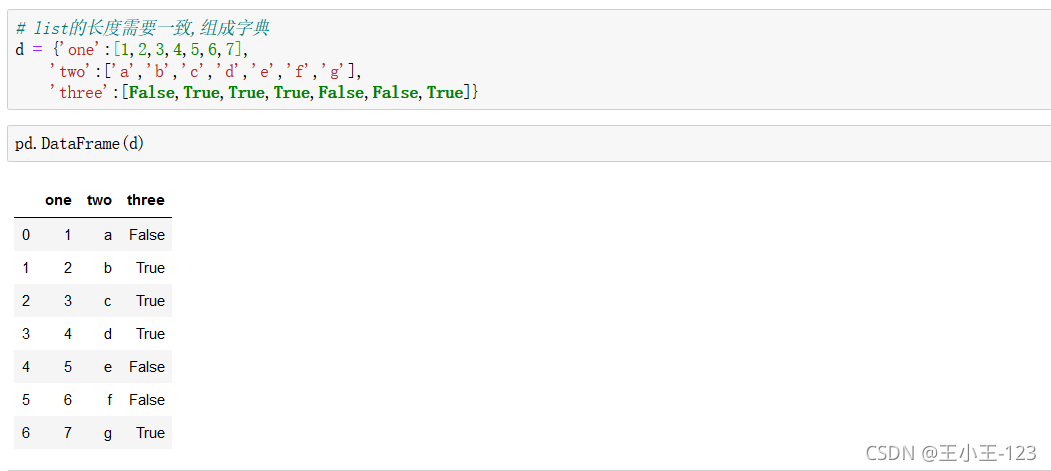
通過字典進行構造,這也滿足了,我們如何把字典型別轉換為dataframe型別,最后保存在我們需要的資料表型別里面
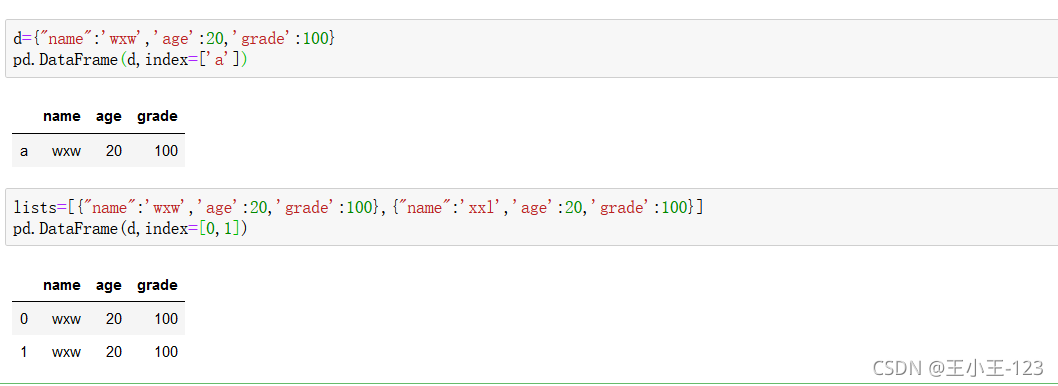
說實話,在我們的日常資料處理里面,我們一般是把字典嵌套在串列里面,那么我們就可以把串列放入這個里面,最后轉換為dataframe型別存盤
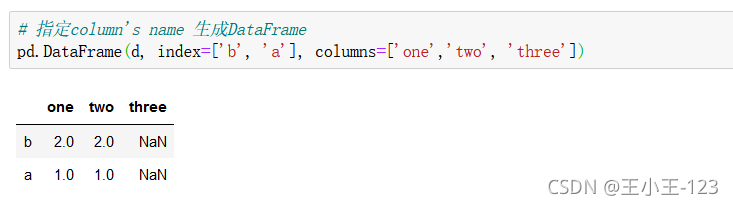
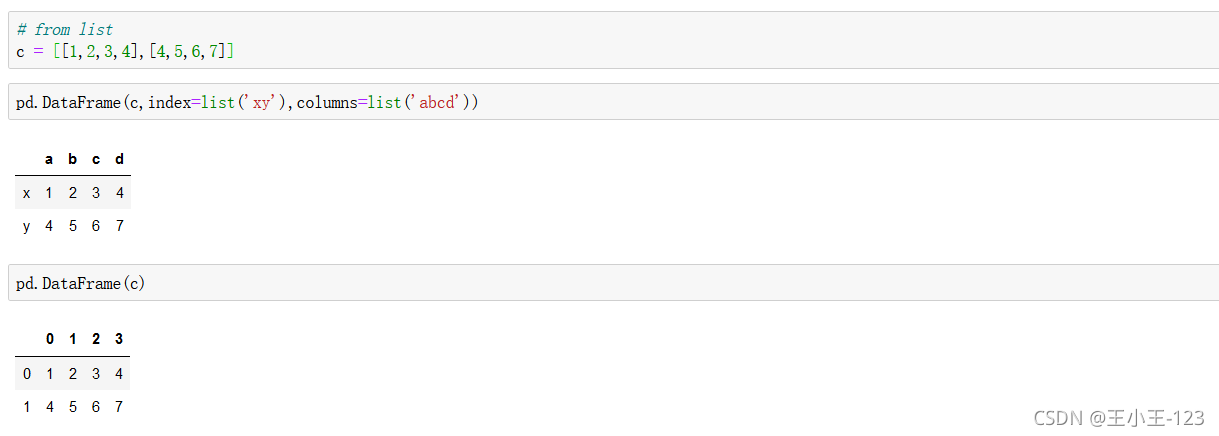
2.1.2 從ndarrays或lists的字典創建
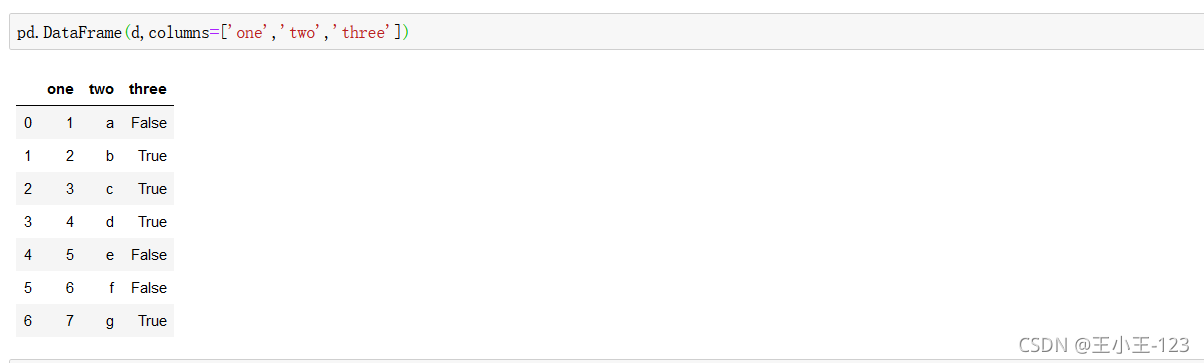
不加index,默認數字序列

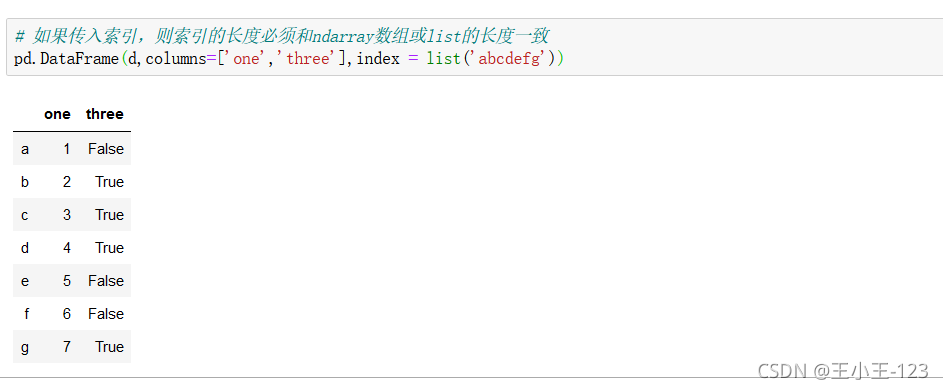
行標簽,column如果和字典的鍵不對應,那么就會為空,這個是需要注意的
2.1.3 從結構化或成對的array/list創建
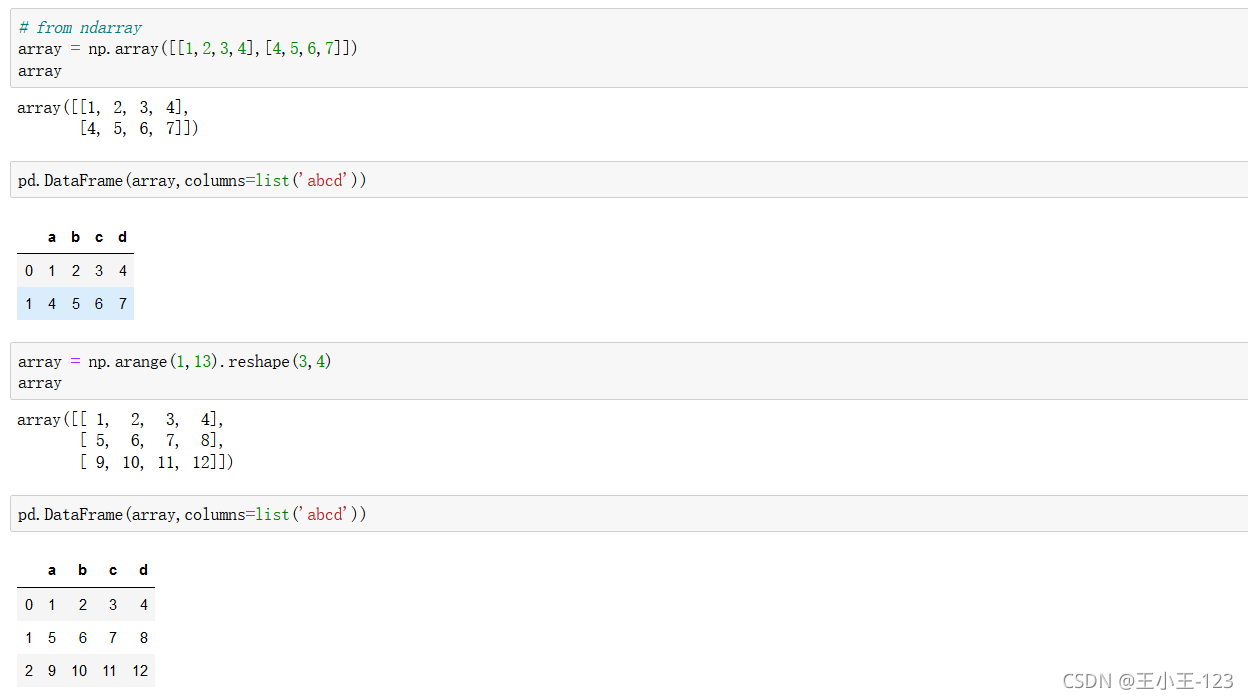
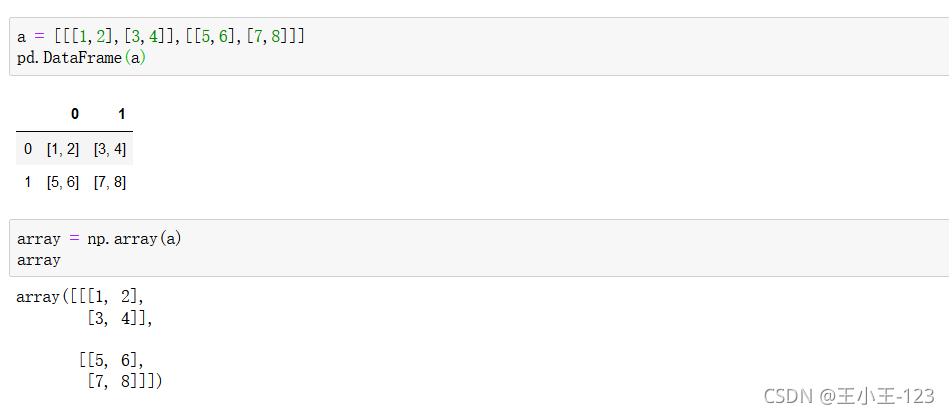 三維陣列進行,資料表展示,就是這樣的
三維陣列進行,資料表展示,就是這樣的
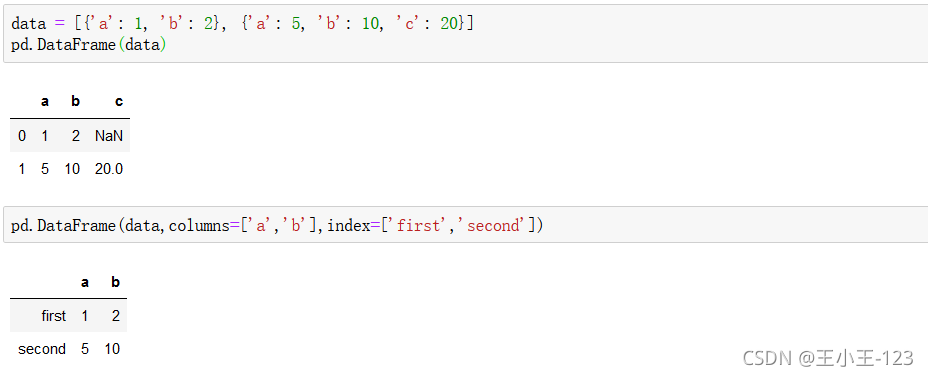
2.1.3 從字典的串列創建
2.2 變數選擇、添加和洗掉
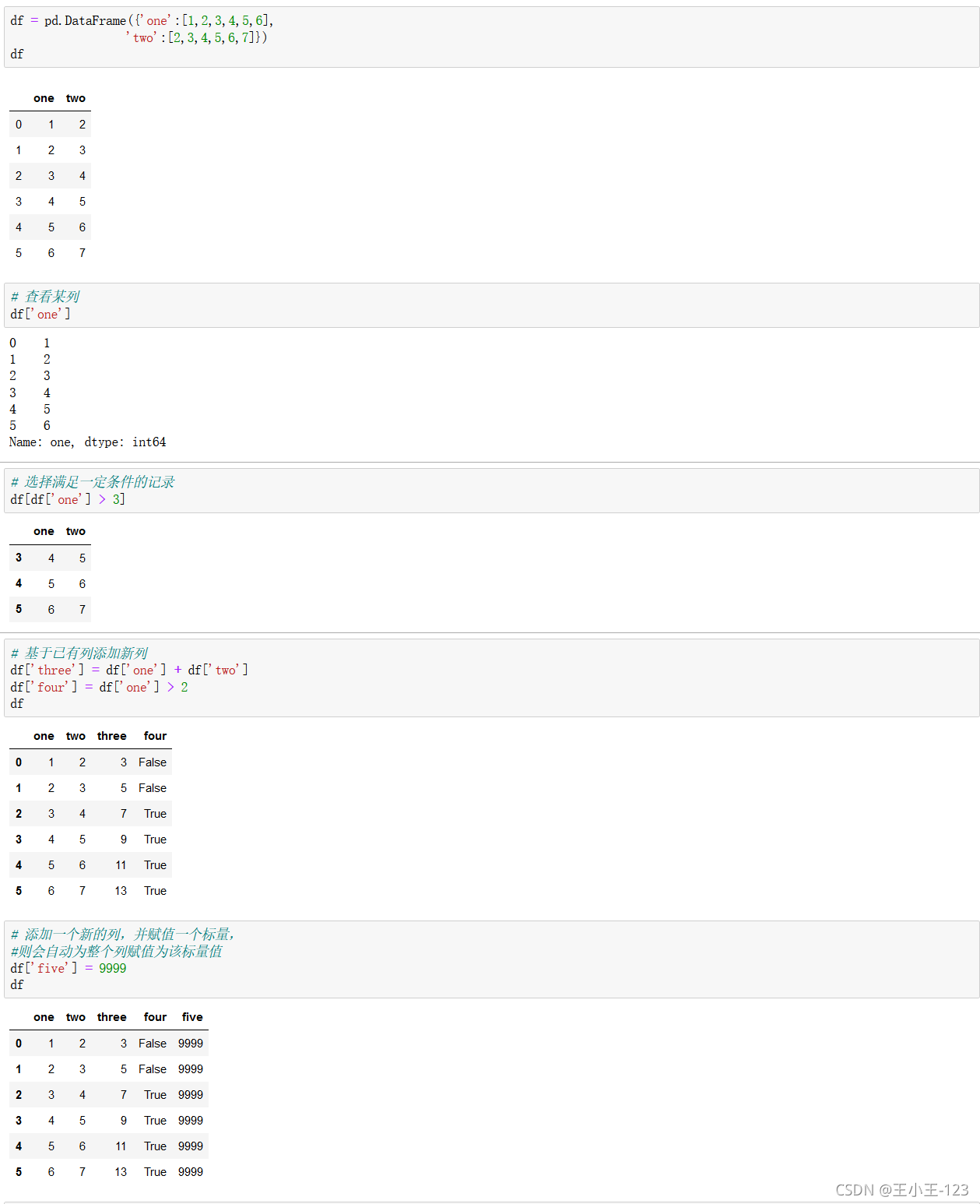
這里交代了資料表里面一般拼接,增加和賦值操作
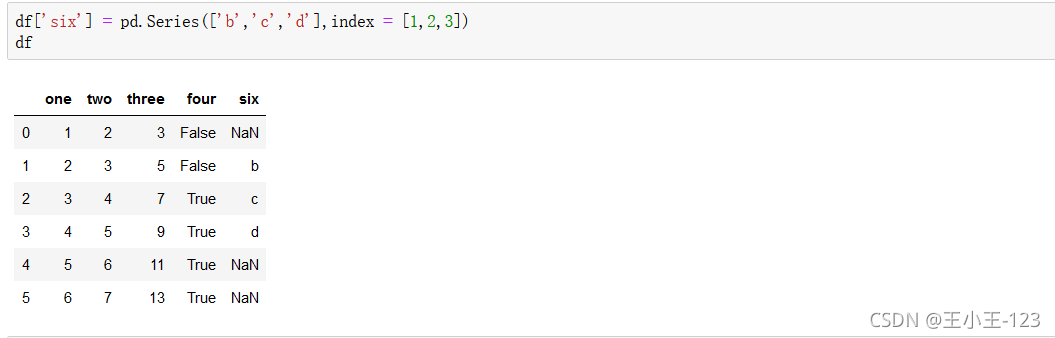
df['欄位']=pd.Series([填充欄位],index=[列標簽]),可以達到對資料表的增加,在特定的列索引上面添加資料
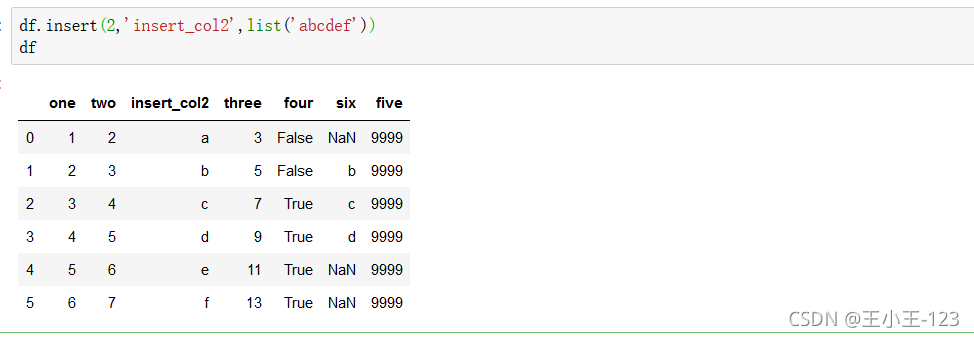
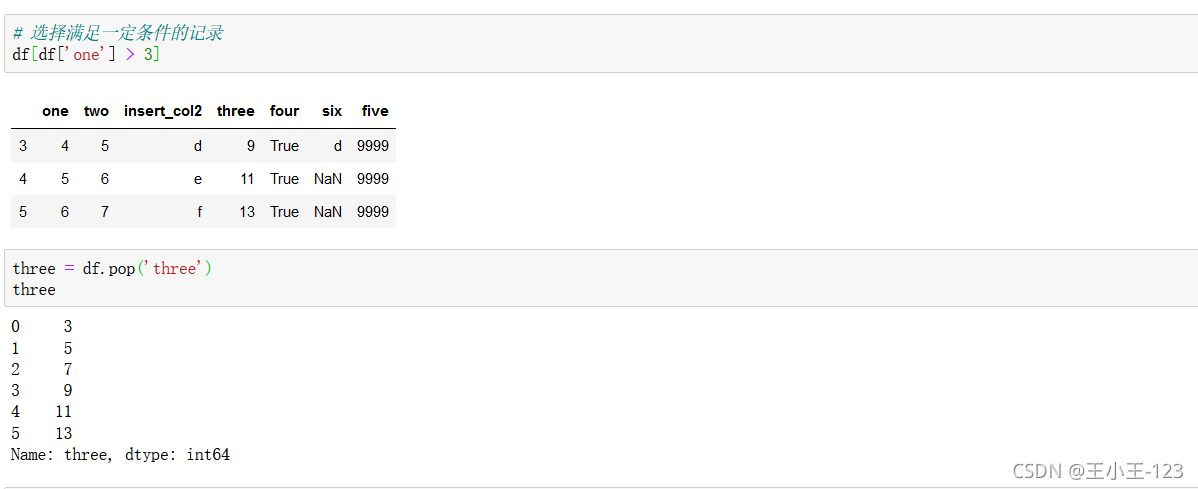
洗掉并顯示值,該列資料
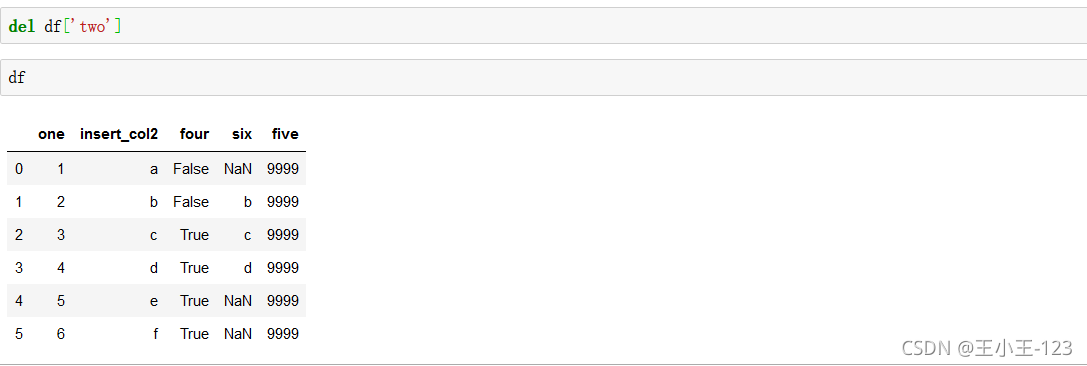 對某一列洗掉操作
對某一列洗掉操作
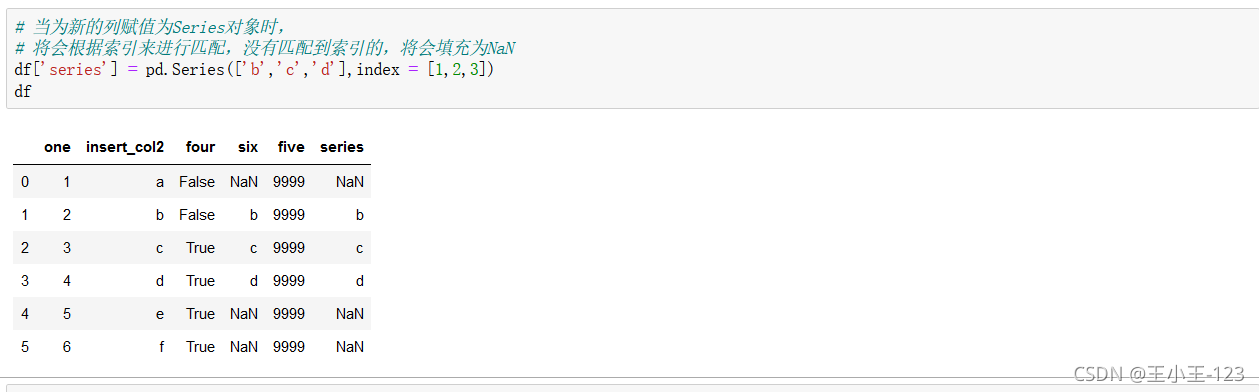
會根據索引來進行匹配,沒有匹配到索引的,將會填充為NaN
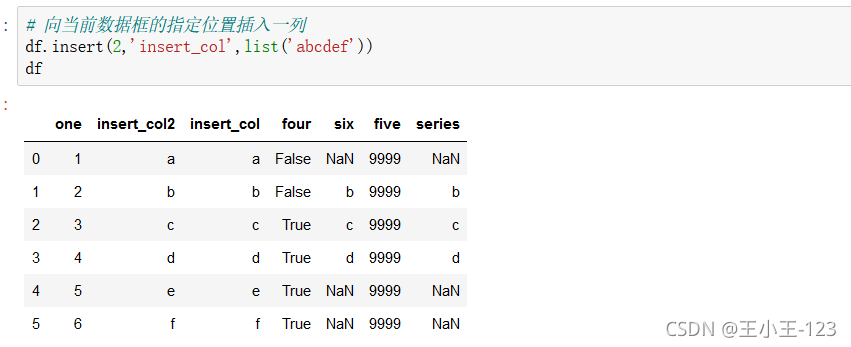
3、 資料匯出
為了演示資料的匯出,這里我們引入一個新的第三方庫tushare,通過這個庫,我們可以輕松的獲取金融相關資料,如股票資料,
以下為tushare庫的介紹, 其官方檔案地址為:http://tushare.org/index.html TuShare是一個免費、開源的python財經資料介面包,主要實作對股票等金融資料從資料采集、清洗加工 到 資料存盤的程序,能夠為金融分析人員提供快速、整潔、和多樣的便于分析的資料,為他們在資料獲取方面極大地減輕作業量,使他們更加專注于策略和模型的研究與實作上,
考慮到Python pandas包在金融量化分析中體現出的優勢,TuShare回傳的絕大部資料格式都是pandas DataFrame型別,非常便于用pandas/NumPy/Matplotlib進行資料分析和可視化,
當然,如果您習慣了用Excel或者關系型資料庫做分析,您也可以通過TuShare的資料存盤功能,將資料全部保存到本地后進行分析,
我們先獲取2017年,第二季度全部股票的業績報告,盈利能力,營運能力資料,然后分別用不同方式保存它們,
!pip install wheel
!pip install lxml
!pip install tushare
!pip install beautifulsoup4
!pip install requests
!pip install pandas
import tushare as ts
# 業績報告
report = ts.get_report_data(2017,2)
# 盈利能力
profit = ts.get_profit_data(2017,2)
# 營運能力
operation = ts.get_operation_data(2017,2)
3.1 匯出到本地檔案
3.1.1 匯出為文本檔案
report.to_csv('./report.csv',index = False,encoding = 'utf-8')
profit.to_csv('./profit.csv',index = False,encoding = 'utf-8')
operation.to_csv('./operation.csv',index = False,encoding = 'utf-8')3.1.2 匯出為Excel檔案
# 可以分別匯出到不同的Excel作業簿;
!pip install openpyxl
report.to_excel('./report.xlsx',index =False)
profit.to_excel('./profit.xlsx',index = False)
operation.to_excel('./operation.xlsx',index =False)在pandas里面提供了大量的資料載入和資料匯出的方法
#先打開一個Excel作業簿,然后分別寫入三個表格,然后關掉Excel作業簿
writer = pd.ExcelWriter('./finance.xlsx')
report.to_excel(writer,sheet_name='report',index = False)
profit.to_excel(writer,sheet_name='profit',index = False)
operation.to_excel(writer,sheet_name='operation',index = False)
# 檔案寫入完畢后關掉Excel作業簿
writer.close()3.1.3 匯出為Json檔案
# 匯出為json檔案
report.to_json('./report.json')3.1.4 匯出為hdf檔案
# 匯出為hdf檔案
!pip install tables
from warnings import filterwarnings
filterwarnings('ignore')
report.to_hdf('./report.hdf','report')
# ImportError: HDFStore requires PyTables, "No module named 'tables'" problem importing3.2 將資料存盤到資料庫
import sqlite3
# 創建連接
sqlite_con = sqlite3.connect('./pandas.db')
# 寫入資料
report.to_sql('report',sqlite_con,if_exists ='replace',index =False)
profit.to_sql('profit',sqlite_con,if_exists ='replace',index =False)
operation.to_sql('operation',sqlite_con,if_exists ='replace',index =False)3.3 資料匯入
3.3.1 從本地檔案
# 從文本檔案
# 推薦使用相對路徑
pd.read_csv('./report.csv').head(3)
#從Excel檔案
# 如果不是被迫選擇Excel檔案格式,一般不推薦使用Excel檔案格式,速度很慢
!pip install xlrd
pd.read_excel('./report.xlsx').head()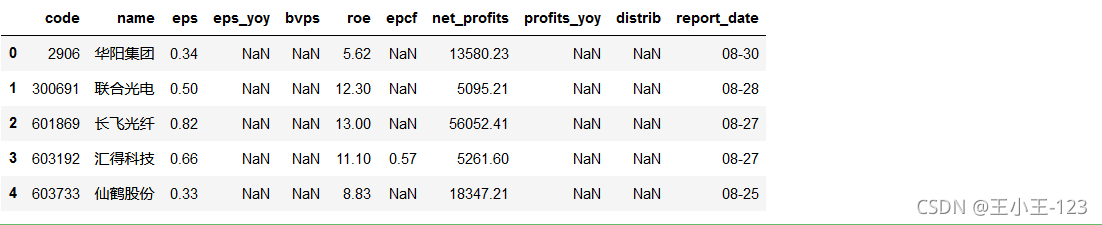
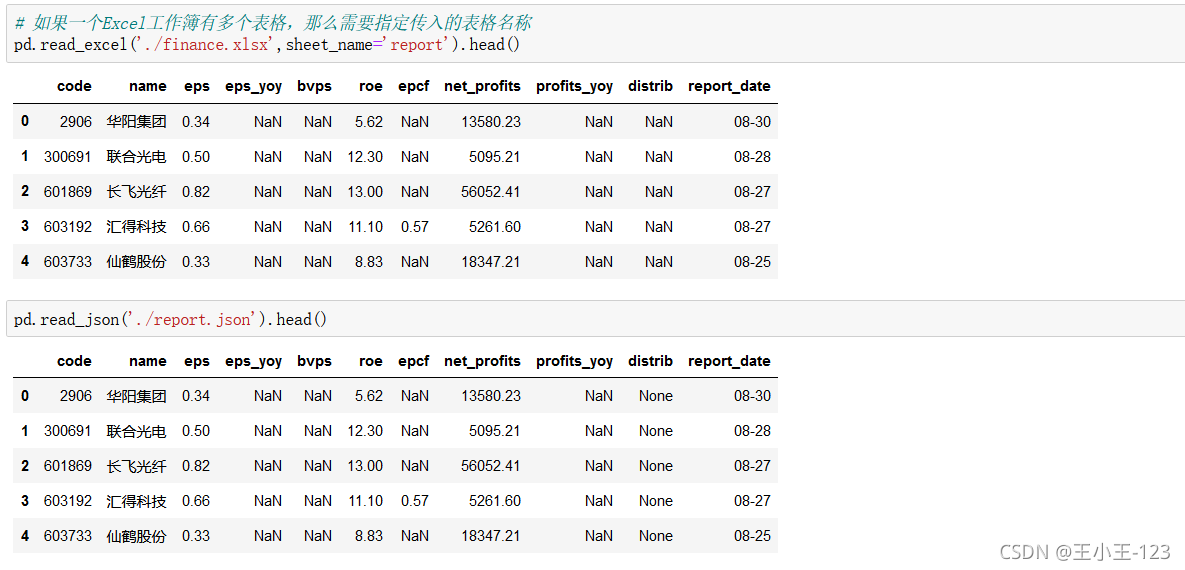
4 、分組計算與匯總
如果說,資料的匯入和匯出是資料的前提,那么資料的處理分析那么就是資料的精華

按照不同的欄位進行分組聚合統計,count()計數,sum()求和
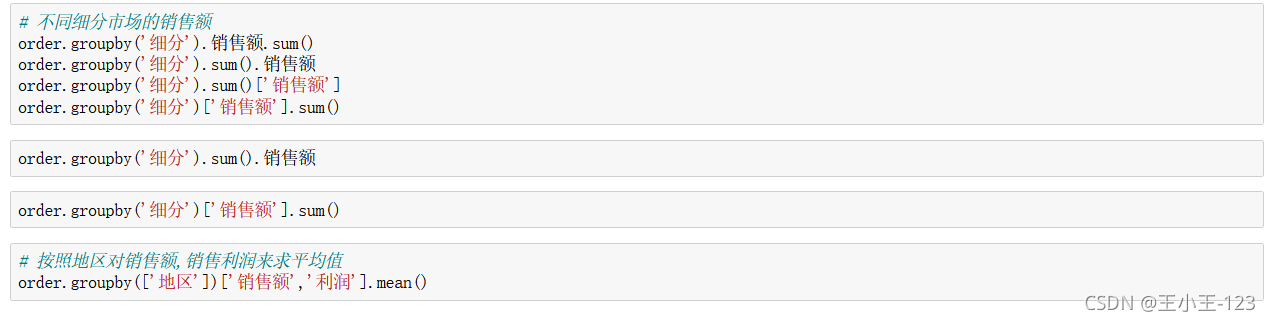
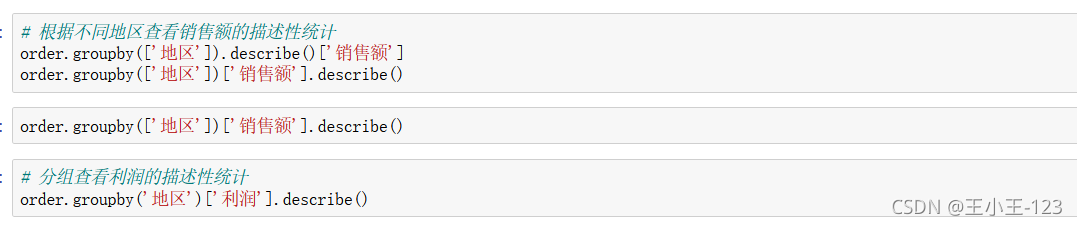

按照不同的欄位分別分組聚合,然后進行統計分析,輸出需要顯示的指標變數的值
注意這里的describe()用于描述性分析,直接可以使用該方法
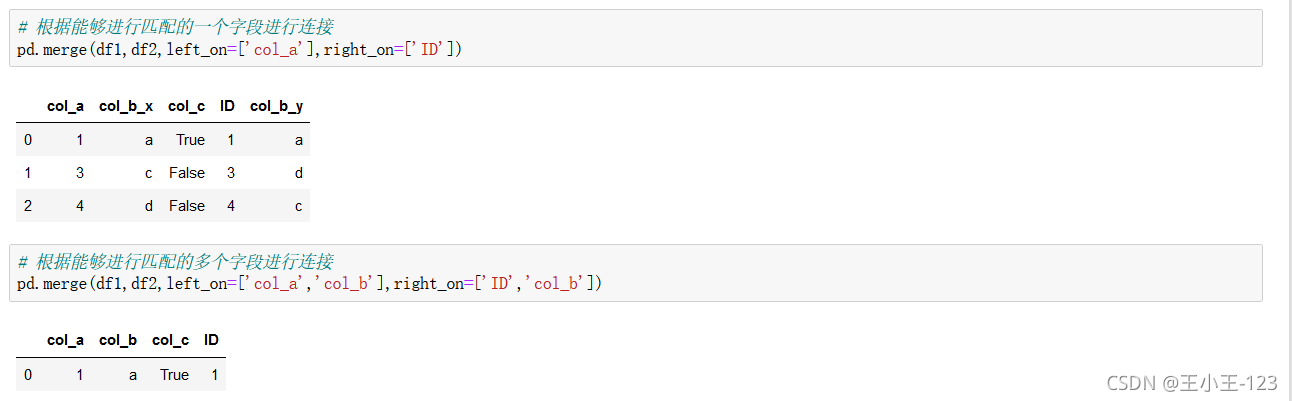
5、資料融合
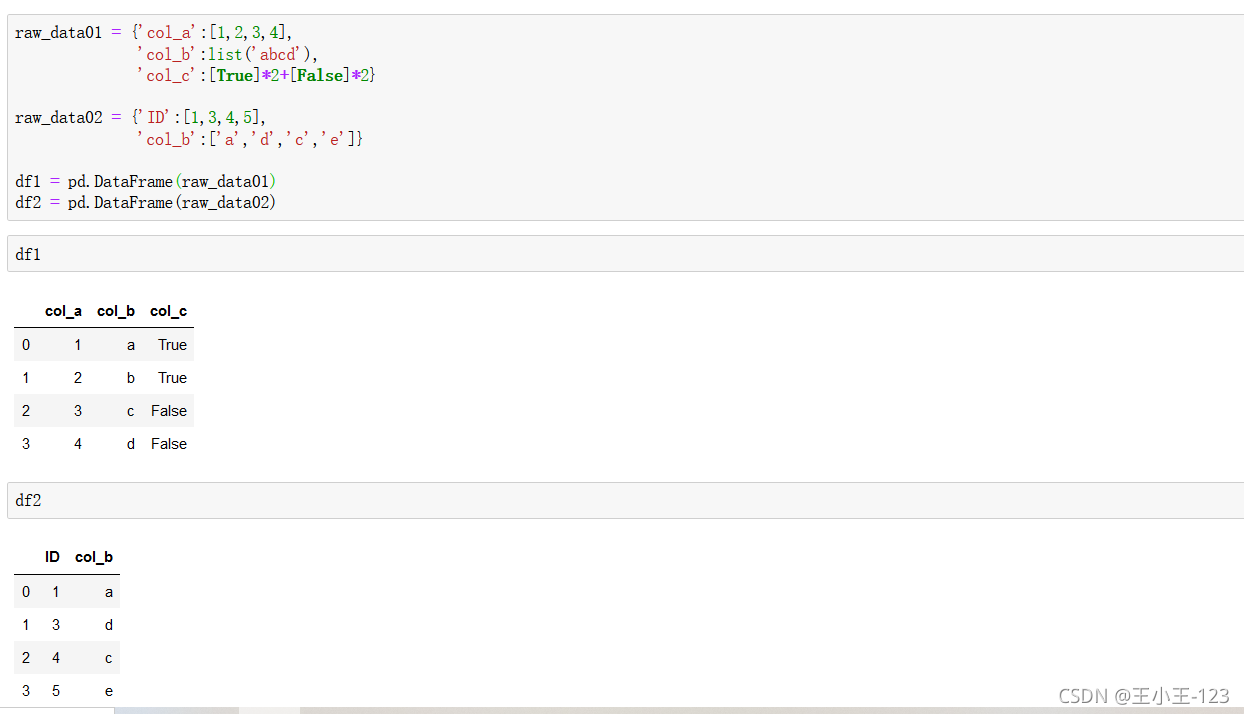
構造兩個臨時資料表,用于我們后面的操作
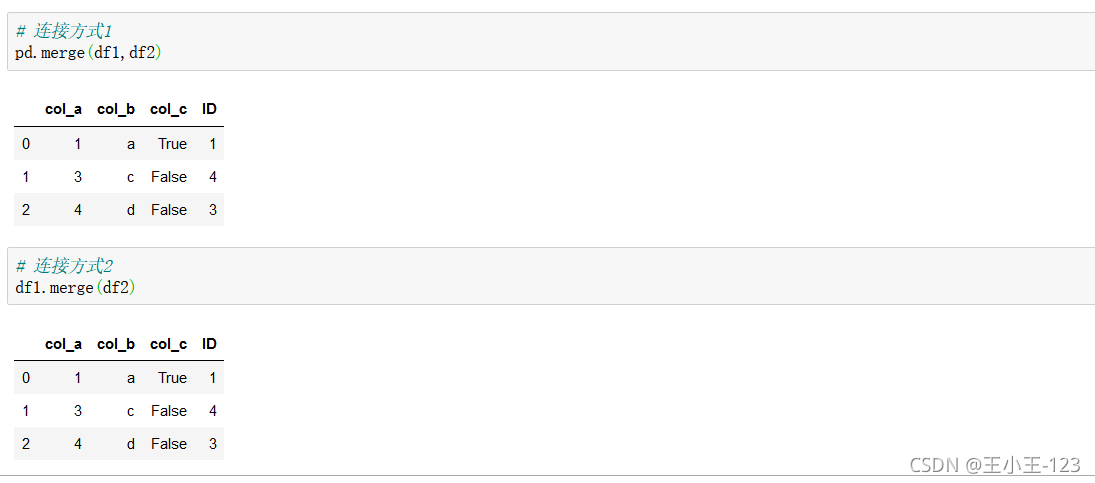
直接進行連接

Pandas高級操作補充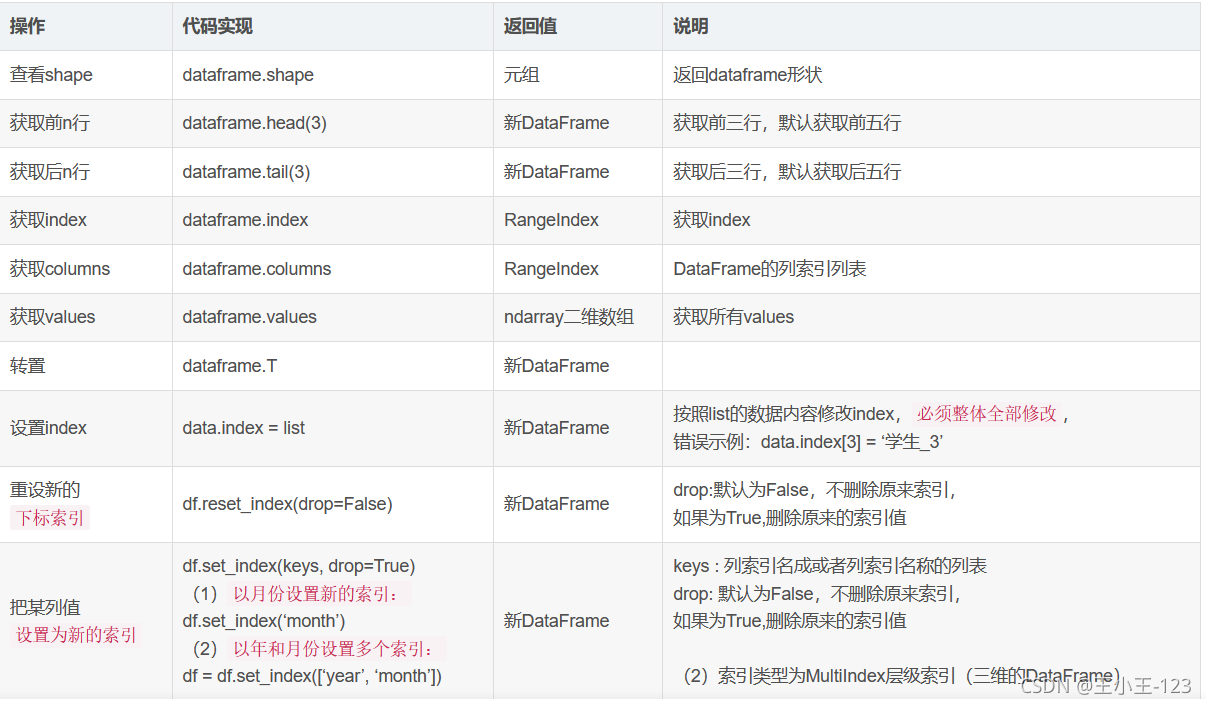
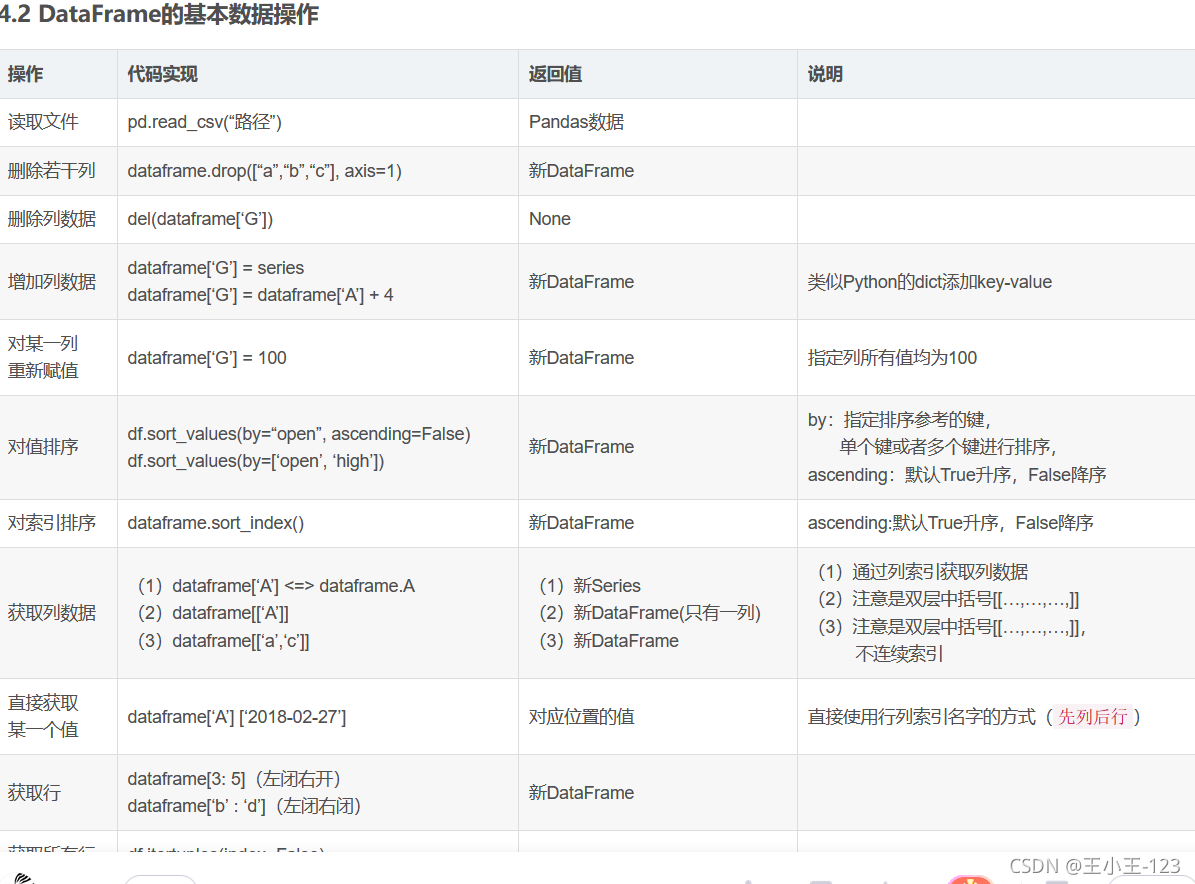
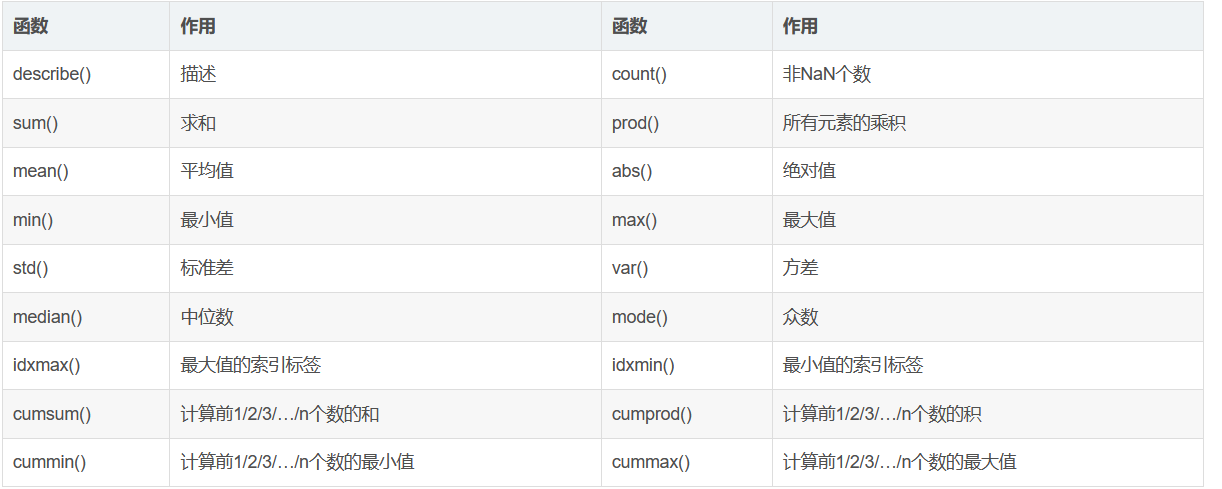
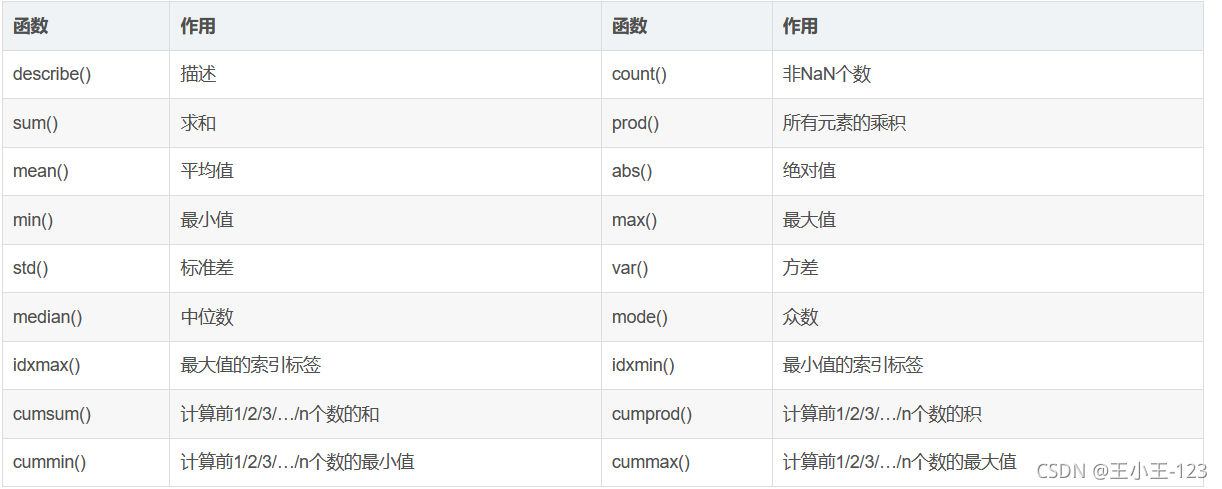
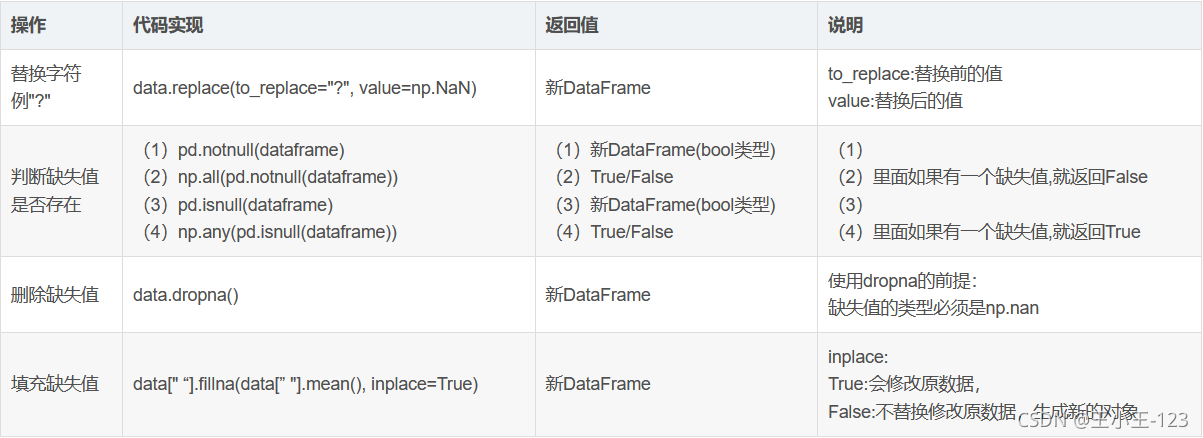
對于pandas的高級操作,無非是進行資料增刪改查,也就是分組聚合,排序處理等,在處理數也可以使用其他的工具,例如:MySQL資料庫的分析,也還是不錯的!!!

看了這么久的文章,也要休息一下喲,加油加油加油!!!
如果你喜歡博主的文章,記得點贊收藏,謝謝!!!
每文一語
時間的速度永遠比流水的速度要快
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/298672.html
標籤:python