人生苦短,我用Python
- 開發環境搭建
- 安裝 Python
- 驗證是否安裝成功
- 安裝Pycharm
- 配置pycharm
- 編碼規范
- 基本語法規則
- 保留字
- 單行注釋
- 多行注釋
- 行與縮進
- 多行陳述句
- 資料型別
- 空行
- 等待用戶輸入
- print輸出
- 運算子
- 算術運算子
- 邏輯運算子
- 成員運算子
- 身份運算子
- 運算子優先級
- 字串
- 訪問字串中的值
- 字串更新
- 合并連接字串
- 洗掉空白
- startswith()方法
- endswith()方法
- 字串格式化
- 字串運算子
- 串列
- 1.基本語法`[]`創建
- 2. list()創建
- 3. 通過`range()`創建整數串列
- 4. 串列推導式
- 串列元素的增加
- 串列元素的洗掉
- 串列元素的訪問
- 串列元素出現的次數
- 切片(slice)
- 串列的排序
- 串列元素的查找
- 串列的其他方法
- 串列相關的內置函式
- 字典
- 字典的特點
- 定義字典
- 字典基本操作
- 讀取字典的值
- 增加字典的值
- 洗掉單個元素
- 洗掉整個字典
- 修改字典的值
- 字典常用方法
- 資料轉換
- 嵌套
- 字典常用內置函式
- 元組
- 定義元組
- 創建元組
- 訪問元組
- 修改元組
- 洗掉元組
- 元組運算子
- 元組切片取值
- 集合
- {}定義集合
- 使用set函式創建集合
- 集合運算
- 集合的基本操作
- 添加元素(add/update)
- 移除元素(remove/pop)
- 計算集合元素個數
- 清空集合
- 判斷元素是否在集合中存在
- 集合內置方法完整串列
- 條件陳述句
- 代碼執行程序
- 注意
- if
- if...else
- if..elif..else
- 回圈
- for回圈操作串列實體演示
- for回圈用來遍歷整個串列
- for回圈用來修改串列中的元素
- for回圈統計串列中某一元素的個數
- for回圈實作1到9相乘
- 遍歷字串
- 遍歷集合物件
- 遍歷檔案
- 遍歷字典
- 函式
- 定義一個函式
- 函式的引數
- 引數默認值
- 修改引數后影響外部
- 關鍵字引數
- 收集引數
- 分配引數
- 函式的回傳值
- 匿名函式
- 函式的作用域
- 面向對像
- 類
- 構造方法:\__init__
- 給屬性指定默認值
- 直接修改屬性值
- 通過方法修改屬性
- 通過方法對屬性的值進行遞增
- 類的繼承
- 類方法重寫
- 多繼承
- 繼承構造方法
- 多型
- 例外處理
- try/except
- try/except/else
- try/Except/finally
- raise拋出例外
- 日志模塊
- 將日志內容輸出到螢屏
- 將日志內容輸出到檔案
- 定制日志內容(日志級別、日志格式)
- 多模塊記錄日志
- 日志同時輸出螢屏和寫入檔案
- datatime模塊
- datetime的使用方法為:
- 下面講幾種常用的方法
- date
- date類中的常用功能有2種:
- time
- 總結
- OS檔案目錄操作
- os.getcwd()
- os.listdir(path)
- os.mkdir(path)
- os.rmdir(path)
- os.remove(path)
- os.path模塊
- os.path.dirname(path)
- os.path.join(path, name)
- os.path.split(path)
- os.path.splitext(path)
- os.path.getmtime()
- random亂數
- 模塊常用方法
- 有趣好玩的偽裝者模塊:Faker
- 安裝
- 國內源:
- 基本使用
- 常用方法
- 地理資訊類
- 基礎資訊類
- 郵箱資訊類
- 網路基礎資訊類
- 瀏覽器資訊類
- 數字資訊
- 文本加密類
- 時間資訊類
- 發送郵箱件模塊
- 發送郵件步驟
- 郵件發送前的準備作業
- 開啟SMTP
- 生成授權碼
- 方式一:smtplib(不推薦使用)
- 方式二:zmail
- 方式三:yagmail
- POM設計模型
- POM優勢有哪些
- 為什么使用POM設計模式
- 如何設計POM
- 思路決議
- login_page.py檔案
- common.py
- TestCase.py
- 總結
- Python操作Excel
- 需求分析
- 操作流程
- 完整 代碼
- file檔案操作
- 常用的檔案操作模式
- 只讀(r, rb)
- 只寫(w, wb)
- r+ 讀寫
- a+寫讀(追加寫讀)
- 安裝第3方庫
- 在線安裝(推薦安裝方式)
- 離線安裝方式
- Web自動化瀏覽器和驅動的解決辦法
- 谷歌瀏覽器驅動版本對應以及下載:
- edge瀏覽器驅動版本對應以及下載:
- ie瀏覽器驅動官方地址:
- safari瀏覽器官方地址:
- 分享Python自學歷程
- 我的自學歷程
- 三人行必有我師
- 愛上學習
- 樂于分享
- 一起學習
- 說在最后
- 表白python

開發環境搭建
- Pycharm
- Python3
- window10/win7
安裝 Python
-
打開Python官網地址
-
下載 executable installer,x86 表示是 32 位機子的,x86-64 表示 64 位機子的,
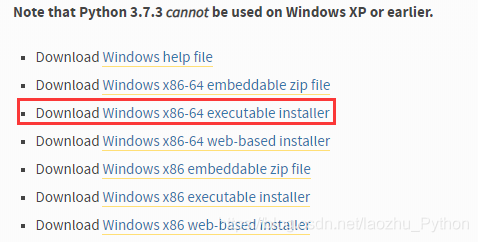
-
開始安裝
- 雙擊下載的安裝包,彈出如下界面
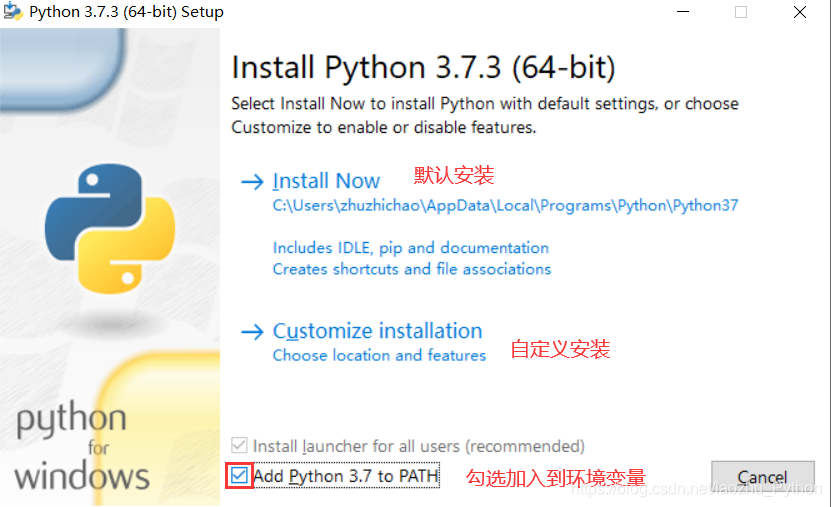
這里要注意的是:
- 將python加入到windows的環境變數中,如果忘記打勾,則需要手工加到環境變數中
- 在這里我選擇的是自定義安裝,點擊“自定義安裝”進行下一步操作
- 自定義安裝
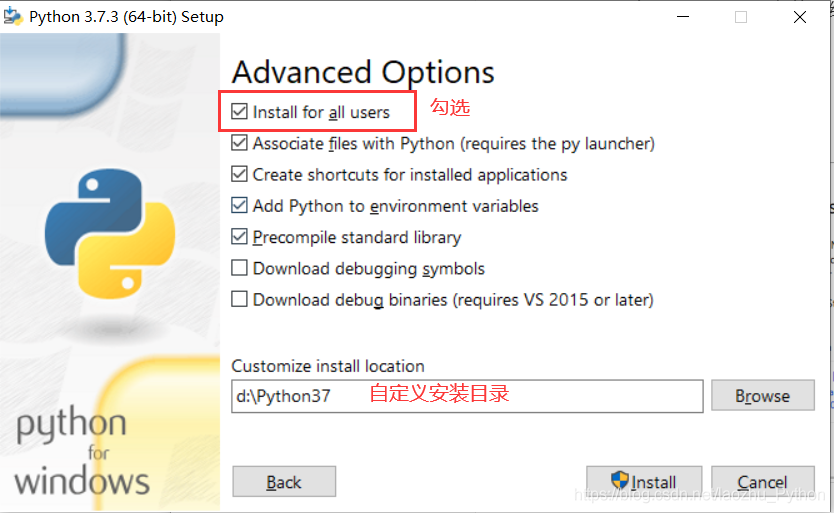
- 等待安裝成功

- 雙擊下載的安裝包,彈出如下界面
驗證是否安裝成功
- 按 Win+R 鍵,輸入 cmd 調出命令提示符,輸入 python:

安裝Pycharm
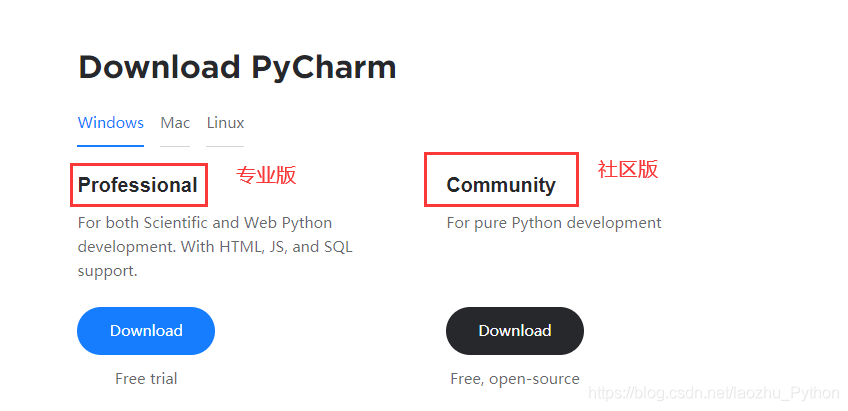
- 打開Pycharm官網下載鏈接
- 選擇下載的版本(當前下載的是Windows下的社區版)
- 專業版收費的,當前下載的社區版免費
配置pycharm
- 外觀配置(推薦使用Darcula)
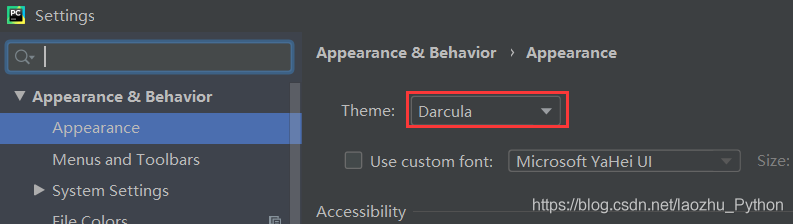
- 配色方案(推薦使用Monokai)
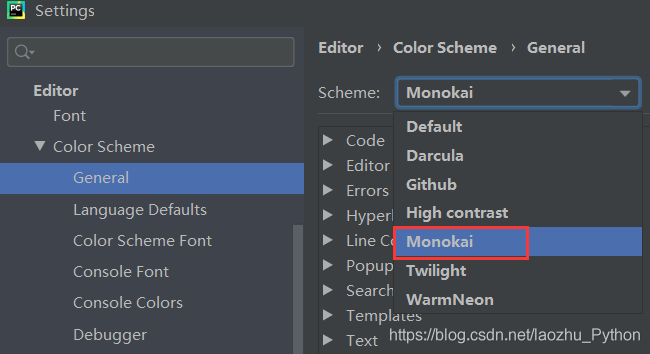
- 代碼編輯區域字體及大設定(推薦使用Consolas)
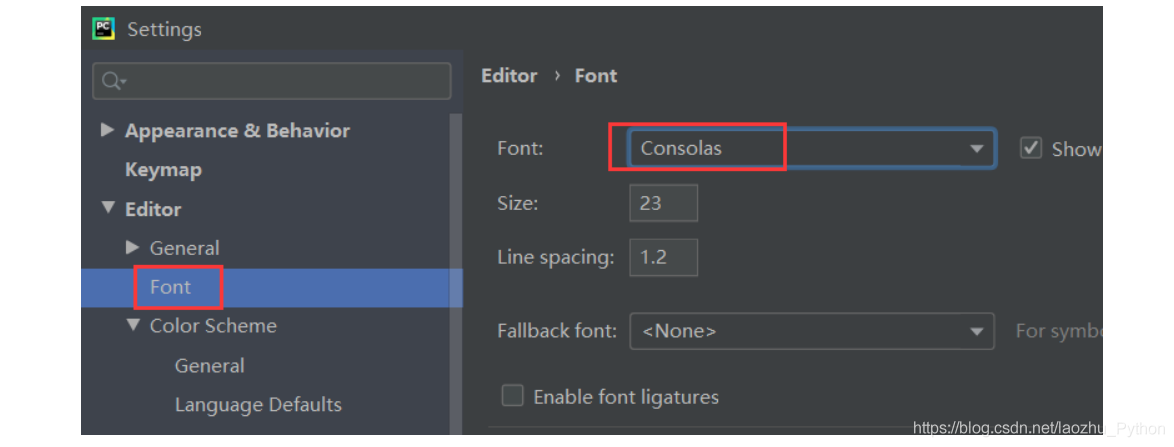
- 控制臺字體選擇及大小設定
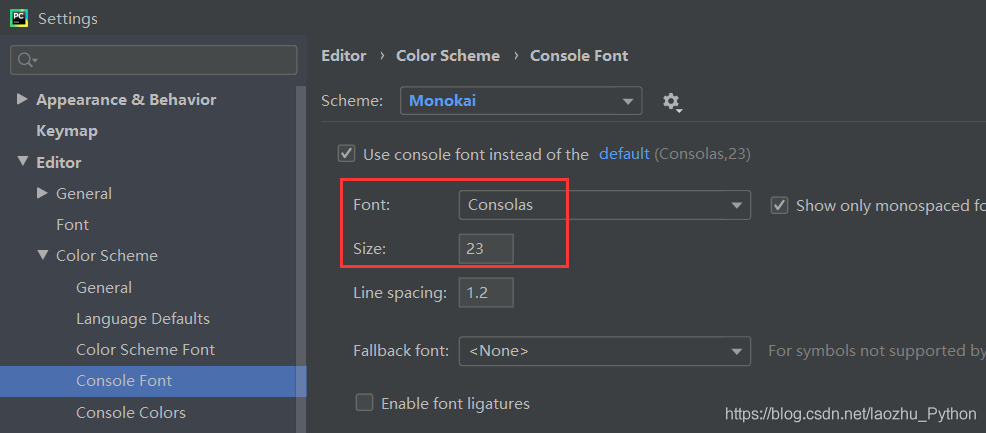
- 檔案模版配置
編碼規范
- 類名采用駝峰命名法,即類名的每個首字母都大寫,如:class HelloWord,類名不使用下劃線
- 函式名只使用小寫字母和下劃線
- 定義類后面包含一個檔案字串且與代碼空一行,字串說明也可以用雙三引號
- 頂級定義之間空兩行
- 兩個類之間使用兩個空行來分隔
- 變數等號兩邊各有一個空格 a = 10
- 函式括號里的引數 = 兩邊不需要空格
- 函式下方需要帶函式說明字串且與代碼空一行
- 默認引數要寫在最后,且逗號后邊空一格
- 函式與函式之間空一行
- if陳述句后的運算子兩邊需要空格
- 變數名,函式名,類名等不要使用拼音
- 注釋要離開代碼兩個空格

基本語法規則
保留字
- 保留字即關鍵字,我們不能把它們用作任何識別符號名稱,
- Python 的標準庫提供了一個 keyword 模塊,可以輸出當前版本的所有關鍵字
import keyword
keyword.kwlist
# 關鍵字串列
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
單行注釋
Python中單行注釋以 # 開頭,實體如下:
# 第一個注釋
print ("Hello, Python!") # 第二個注釋
多行注釋
多行注釋可以用多個 # 號,還有’’'和 “”“xxxx”"":
# 第一個注釋
# 第二個注釋
'''
第三注釋
第四注釋
'''
"""
第五注釋
第六注釋
行與縮進
- python最具特色的就是使用縮進來表示代碼塊,不需要使用大括號 {} ,
- 縮進的空格數是可變的,但是同一個代碼塊的陳述句必須包含相同的縮進空格數,實體如下:
# 正確行與縮進
if True:
print ("True")
else:
print ("False")
# 錯誤的行與縮進
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 縮進不一致,會導致運行錯誤
多行陳述句
- Python 通常是一行寫完一條陳述句,但如果陳述句很長,我們可以使用反斜杠()來實作多行陳述句,例如:
total = item_one + \
item_two + \
item_three
在 [], {}, 或 () 中的多行陳述句,不需要使用反斜杠(),例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
資料型別
-
Python中數字有四種型別:整數、布爾型、浮點數和復數,
int (整數), 如 1, 只有一種整數型別 int,表示為長整型,沒有 python2 中的 Long,
bool (布爾), 如 True和False
float (浮點數), 如 1.23
complex (復數), 如 1 + 2j、 1.1 + 2.2j -
查看型別,用type()方法
-
字串
python中單引號和雙引號使用完全相同
使用三引號(’’'或""")可以指定一個多行字串
空行
def hello():
pass
# 此處為空行
def word():
pass
等待用戶輸入
input("請輸入你的名字")
print輸出
x = "a"
y = "b"
# 換行輸出
print( x )
print( y )
print('---------')
# 不換行輸出
print( x, end=" " )
print( y, end=" " )
print()
運算子
本章節主要說明Python的運算子,舉個簡單的例子 1 +2 = 3 , 例子中,1 和 1、2 被稱為運算元,"+" 稱為運算子,
Python語言支持以下型別的運算子:
- 算術運算子
- 比較(關系)運算子
- 賦值運算子
- 邏輯運算子
- 成員運算子
- 身份運算子
- 運算子優先級
算術運算子
以下假設變數:a=10,b=20
| 運算子 | 描述 | 實體 |
|---|---|---|
| + | 加: 兩個物件相加 | a + b 輸出結果 30 |
| - | 減 - 得到負數或是一個數減去另一個數 | a - b 輸出結果 -10 |
| * | 乘: 兩個數相乘 | a * b 輸出結果 200 |
| 回傳一個被重復若干次的字串,如:HI*3 | HI,HI,HI | |
| / | 除: x除以y(即兩個數的商) | b / a 輸出結果 2 |
| % | 取模:返商的余數 | b % a 輸出結果 0 |
| ** | 冪:回傳x的y次冪 | a**b 為10的20次方,輸出結果100000000000000000000 |
| // | 取整除: 回傳商的整數部分 | 9//2 輸出結果 4 , 9.0//2.0 輸出結果 4.0 |
注:加號也可用作連接符,但兩邊必須是同型別的才可以,否則會報錯,如:23+ “Python” ,數字23和字串型別不一致
比較運算子
以下假設變數a為10,變數b為20
| 運算子 | 描述 | 實體 |
|---|---|---|
| == | 等于:比較物件是否相等 | (a == b) 回傳 False |
| != | 不等于:比較兩個物件是否不相等 | (a != b) 回傳 True |
| > | 大于:回傳x是否大于y | (a > b) 回傳 False |
| < | 小于:回傳x是否小于y | (a < b) 回傳 True, |
| >= | 大于等于:回傳x是否大于等于y | (a >= b) 回傳 False |
| <= | 小于等于:回傳x是否小于等于y | (a <= b) 回傳 True |
注:所有比較運算子回傳1表示真,回傳0表示假,這分別與特殊的變數True和False等價,注意True和False第一個字母是大寫
賦值運算子
以下假設變數a為10,變數b為20
| 運算子 | 描述 | 實體 |
|---|---|---|
| = | 簡單的賦值運算子 | c = a + b 將 a + b 的運算結果賦值為 c |
| += | 加法賦值運算子 | c += a 等效于 c = c + a |
| -= | 減法賦值運算子 | c -= a 等效于 c = c - a |
| *= | 乘法賦值運算子 | c *= a 等效于 c = c * a |
| /= | 除法賦值運算子 | c /= a 等效于 c = c / a |
| %= | 取模賦值運算子 | c %= a 等效于 c = c % a |
| **= | 冪賦值運算子 | c **= a 等效于 c = c ** a |
| //= | 取整除賦值運算子 | c //= a 等效于 c = c // a |
邏輯運算子
Python語言支持邏輯運算子,以下假設變數 a 為 10, b為 20:
| 運算子 | 邏輯運算式 | 描述 | 實體 |
|---|---|---|---|
| and | x and y | 布爾"與":如果 x 為 False,x and y 回傳 False,否則它回傳 y 的計算值 | (a and b) 回傳 20 |
| or | x or y | 布爾"或" :如果 x 是非 0,它回傳 x 的值,否則它回傳 y 的計算值 | (a or b) 回傳 10 |
| not | not x | 布爾"非":如果 x 為 True,回傳 False ,如果 x 為 False它回傳 True | not(a and b) 回傳 False |
成員運算子
| 運算子 | 描述 | 實體 |
|---|---|---|
| in | 如果在指定的序列中找到值回傳 True,否則回傳 False | x 在 y 序列中 , 如果 x 在 y 序列中回傳 True |
| not in | 如果在指定的序列中沒有找到值回傳 True,否則回傳 False | x 不在 y 序列中 , 如果 x 不在 y 序列中回傳 True |
身份運算子
身份運算子用于比較兩個物件的存盤單元
| 運算子 | 描述 | 實體 |
|---|---|---|
| is | is 是判斷兩個識別符號是不是參考自一個物件 | x is y, 類似 id(x) == id(y) , 如果參考的是同一個物件則回傳 True,否則回傳 False |
| is not | is not 是判斷兩個識別符號是不是參考自不同物件 | x is not y , 類似 id(a) != id(b),如果參考的不是同一個物件則回傳結果 True,否則回傳 False, |
運算子優先級
以下表格列出了從最高到最低優先級的所有運算子:
| 運算子 | 描述 |
|---|---|
| ** | 指數 (最高優先級) |
| ~ + - | 按位翻轉, 一元加號和減號 (最后兩個的方法名為 +@ 和 -@) |
| * / % // | 乘,商,取余和取整除 |
| + - | 加法減法 |
| >> << | 右移,左移運算子 |
| & | 位 ‘AND’ |
| ^ | | 位運算子 |
| <= < > >= | 比較運算子 |
| <> == != | 等于運算子 |
| = %= /= //= -= += *= **= | 賦值運算子 |
| is is not | 身份運算子 |
| in not in | 成員運算子 |
| not or and | 邏輯運算子 |

字串
- 字串是由數字,字母、下劃線組成的一串字符
- 創建字串,可以使用單引號(’’)和雙引號("")
# -*- coding: utf-8 -*-
# @Author : 碼上開始
var1 = 'Hello World!'
var2 = "Hello World!"
訪問字串中的值
- Python 訪問子字串,可以使用方括號 [] 來截取字串
# -*- coding: utf-8 -*-
# @Author : 碼上開始
var = “Hello World”
print(var[0])
#運行結果H
字串更新
# -*- coding: utf-8 -*-
# @Author : 碼上開始
print(var1[0:6] + “Python”)
#運行結果:Hello Python
另一種寫法:
print(var1[:6] + “Python”)
#運行結果:Hello Python
合并連接字串
- 使用+號連接字符
- +兩邊型別必須一致
#-*- coding: utf-8 -*-
#@Author : 碼上開始
first_word = “碼上”
last_word = “開始”
print(first_word + last_word)
#運行結果為:碼上開始
洗掉空白
- ” Python”和”Python ”表面上看兩個字串是一樣的,但實際代碼中是認為不相同的
- 因為后面的字串符有空白,那么如何去掉空白?
# -*- coding: utf-8 -*-
# @Author : 碼上開始
language = "Python "
language.rstrip() # 洗掉右邊空格
language = " Python"
language.lstrip() # 洗掉左邊空格
language = " Python " #
language.strip() # 洗掉左右空白
startswith()方法
# str傳入的是字串
str.startswith(str, beg=0,end=len(string))
-
方法用于檢查字串是否是以指定子字串開頭,如果是則回傳 True,否則回傳 False,
-
如果引數 beg 和 end 指定值,則在指定范圍內檢查,
# -*- coding: utf-8 -*-
# @Author : 碼上開始
str = "this is string example....wow!!!"
# 默認從坐標0開始匹配this這個字符
print str.startswith( 'this' )
# 指定下標從2到4匹配is
print str.startswith( 'is', 2, 4 )
# 同上
print str.startswith( 'this', 2, 4 )
# 運行結果
True
True
False
傳入的值為元組時
- 元組中只要任一元素匹配則回傳True,反之為False
# -*- coding: utf-8 -*-
# @Author : 碼上開始
string = "Postman"
# 元組中只要任一元素匹配則回傳True,反之為False
print(string.startswith(("P", "man"),0))
# 雖然元組元素Po/man都存在字符中,但不匹配開始的下標,所以仍回傳值Flase
print(string.startswith(("Po", "man"),1))
endswith()方法
# 語法
str.endswith(string,[, start[, end]])
-
Python endswith() 方法用于判斷字串是否以指定后綴結尾,如果以指定后綴結尾回傳True,否則回傳False,
-
可選引數"start"與"end"為檢索字串的開始與結束位置,
# -*- coding: utf-8 -*-
# @Author : 碼上開始
string = "this is string example....wow!!!";
str = "wow!!!"
print(string.endswith(str))
print(string.endswith(str,20))
str1 = "is"
print(string.endswith(str1, 2, 4))
print(string.endswith(str1, 2, 6))
# 運行結果
True
True
True
False
字串格式化
- **%格式化:**占位符%,搭配%符號一起使用
- 傳整數時:%d
- 傳字串時:%s
- 傳浮點數時:%f
# -*- coding: utf-8 -*-#
@Author : 碼上開始
age = 29
print("my age is %d" %age)
#my age is 29
name = "makes"print("my name is %s" %name)
#my name is makes
print("%f" %2.3)#2.300000
-
**format()格式化:**占位符{},搭配format()函式一起使用
-
位置映射
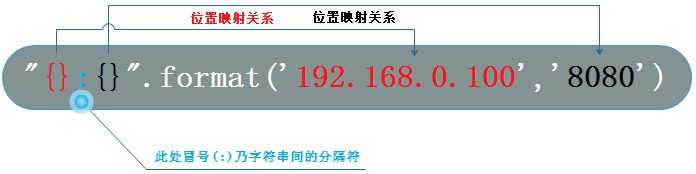
-
print("{}:{}".format('192.168.0.100',8888))#192.168.0.100:8888
-
關鍵字映射
-
print("{server}{1}:{0}".format(8888,'192.168.1.100',server='Web Server Info :')) #Web Server Info :192.168.1.100:8888

-
字串運算子
下表實體變數 a 值為字串 “Hello”,b 變數值為 “Python”:
| 運算子 | 描述 | 實體 |
|---|---|---|
| + | 字串連接 | a + b ‘HelloPython’ |
| * | 重復輸出字串 | a * 2 ‘HelloHello’ |
| [] | 通過索引獲取字串中字符 | a[1] ‘e’ |
| [ : ] | 截取字串中的一部分 | a[1:4] ‘ell’ |
| in | 成員運算子 - 如果字串中包含給定的字符回傳 True | “H” in a True |
| not in | 成員運算子 - 如果字串中不包含給定的字符回傳 True | “M” not in a True |
| r/R | 原始字串 - 原始字串:所有的字串都是直接按照字面的意思來使用,沒有轉義特殊或不能列印的字符, 原始字串除在字串的第一個引號前加上字母"r"(可以大小寫)以外,與普通字串有著幾乎完全相同的語法, | >>>print r’\n’ \n >>> print R’\n’ \n |

串列
- 串列:用于存盤任意數目、任意型別的資料集合,
1.基本語法[]創建
a = [1, 'jack', True, 100]
b = []
2. list()創建
使用list()可以將任何可迭代的資料轉化成串列
a = list() # 創建一個空串列
b = list(range(5)) # [0, 1, 2, 3, 4]
c = list('nice') # ['n', 'i', 'c', 'e']
3. 通過range()創建整數串列
range()
可以幫助我們非常方便的創建整數串列,這在開發中及其有用,語法格式為:`range([start,]end[,step])
start引數:可選,表示起始數字,默認是0,
end引數:必選,表示結尾數字,
step引數:可選,表示步長,默認為1,
python3中range()回傳的是一個range物件,而不是串列,我們需要通過list()方法將其轉換成串列物件,
a = list(range(-3, 2, 1)) # [-3, -2, -1, 0, 1]
b = list(range(2, -3, -1)) # [2, 1, 0, -1, -2]
4. 串列推導式
a = [i * 2 for i in range(5) if i % 2 == 0] # [0, 4, 8]
points = [(x, y) for x in range(0, 2) for y in range(1, 3)]
print(points) # [(0, 1), (0, 2), (1, 1), (1, 2)]
串列元素的增加
當串列增加和洗掉元素時,串列會自動進行記憶體管理,大大減少了程式員的負擔,但這個特點涉及串列元素的大量移動,效率較低,除非必要,我們一般只在串列的尾部添加元素或洗掉元素,這會大大提高串列的操作效率,
append()
>>>a = [20,40]
>>>a.append(80)
>>>a
[20,40,80]
+運算子
并不是真正的尾部添加元素,而是創建新的串列物件;將原串列的元素和新串列的元素依次復制到新的串列物件中,這樣,會涉及大量的復制操作,對于操作大量元素不建議使用,
>>> a = [3, 1, 4]
>>> b = [4, 2]
>>> a + b
[3, 1, 4, 4, 2]
extend()
將目標串列的所有元素添加到本串列的尾部,屬于原地操作,不創建新的串列物件,
>>> a = [3, 2]
>>> a.extend([4, 6])
>>> a
[3, 2, 4, 6]
insert()
使用insert()方法可以將指定的元素插入到串列物件的任意指定位置,這樣會讓插入位置后面所有的元素進行移動,會影響處理速度,涉及大量元素時,盡量避免使用,類似發生這種移動的函式還有:remove()、pop()、del(),它們在洗掉非尾部元素時也會發生操作位置后面元素的移動,
>>> a = [2, 5, 8]
>>> a.insert(1, 'jack')
>>> a
[2, 'jack', 5, 8]
- 乘法
使用乘法擴展串列,生成一個新串列,新串列元素時原串列元素的多次重復,
>>> a = [4, 5]
>>> a * 3
[4, 5, 4, 5, 4, 5]
適用于乘法操作的,還有:字串、元組,
串列元素的洗掉
del()
洗掉串列指定位置的元素,
>>> a = [2, 3, 5, 7, 8]
>>> del a[1]
>>> a
[2, 5, 7, 8]
pop()
洗掉并回傳指定位置元素,如果未指定位置則默認操作串列最后一個元素,
>>> a = [3, 6, 7, 8, 2]
>>> b = a.pop()
>>> b
2
>>> c = a.pop(1)
>>> c
6
remove()
洗掉首次出現的指定元素,若不存在該元素拋出例外,
>>> a=[10,20,30,40,50,20,30,20,30]
>>> a.remove(20)
>>> a
[10, 30, 40, 50, 20, 30, 20, 30]
clear()
清空一個串列,
a = [3, 6, 7, 8, 2]
a.clear()
print(a) # []
串列元素的訪問
- 通過索引直接訪問元素
>>> a = [2, 4, 6]
>>> a[1]
4
index()獲得指定元素在串列中首次出現的索引
index()可以獲取指定元素首次出現的索引位置,語法是:index(value,[start,[end]]),其中,start和end指定了搜索的范圍,
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
>>> a.index(20)
1
>>> a.index(20, 3)
5
>>> a.index(20, 6, 8)
7
串列元素出現的次數
回傳指定元素在串列中出現的次數,
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
>>> a.count(20)
3
切片(slice)
[起始偏移量start:終止偏移量end[:步長step]]
-
三個量為正數的情況下
| 操作和說明 | 示例 | 結果 |
| ---------------------------------------------------- | ------------------------------------- | -------------- |
|[:]提取整個串列 |[10, 20, 30][:]|[10, 20, 30]|
|[start:]從start索引開始到結尾 |[10, 20, 30][1:]|[20, 30]|
|[:end]從頭開始到 end-1 |[10, 20, 30][:2]|[10, 20]|
|[start:end]從 start 到 end-1 |[10, 20, 30, 40][1:3]|[20, 30]|
|[start:end:step]從 start 提取到 end-1,步長是step |[10, 20, 30, 40, 50, 60, 70][1:6:2]|[20, 40, 60]| -
三個量為負數的情況
| 示例 | 說明 | 結果 |
| ------------------------------------- | ---------------------- | ------------------------ |
|[10, 20, 30, 40, 50, 60, 70][-3:]| 倒數三個 |[50, 60, 70]|
|[10, 20, 30, 40, 50, 60, 70][-5:-3]| 倒數第五個至倒數第四個 |[30, 40]|
|[10,20,30,40,50,60,70][::-1]| 逆序 |[70,60,50,40,30,20,10]|
t1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
print(t1[100:]) # []
print(t1[0:-1]) # [11, 22, 33, 44, 55, 66, 77, 88]
print(t1[1:5:-1]) # []
print(t1[-1:-5:-1]) # [99, 88, 77, 66]
print(t1[-5:-1:-1]) # []
print(t1[5:-1:-1]) # []
print(t1[::-1]) # [99, 88, 77, 66, 55, 44, 33, 22, 11]
# 注意以下兩個
print(t1[3::-1]) # [44, 33, 22, 11]
print(t1[3::1]) # [44, 55, 66, 77, 88, 99]
123456789101112131415161718
串列的排序
- 修改原串列,不創建新串列的排序
a = [3, 2, 8, 4, 6]
print(id(a)) # 2180873605704
a.sort() # 默認升序
print(a) # [2, 3, 4, 6, 8]
print(id(a)) # 2180873605704
a.sort(reverse=True)
print(a) # [8, 6, 4, 3, 2]
12345678
# 將序列的所有元素隨機排序
import random
b = [3, 2, 8, 4, 6]
random.shuffle(b)
print(b) # [4, 3, 6, 2, 8]
12345
- 創建新串列的排序
通過內置函式sorted()進行排序,這個方法回傳新串列,不對原串列做修改,
a = [3, 2, 8, 4, 6]
b = sorted(a) # 默認升序
c = sorted(a, reverse=True) # 降序
print(b) # [2, 3, 4, 6, 8]
print(c) # [8, 6, 4, 3, 2]
12345
- 冒泡排序
list1 = [34,54,6,5,65,100,4,19,50,3]
#冒泡排序,以升序為例
#外層回圈:控制比較的輪數
for i in range(len(list1) - 1):
#內層回圈:控制每一輪比較的次數,兼顧參與比較的下標
for j in range(len(list1) - 1 - i):
#比較:只要符合條件則交換位置,
# 如果下標小的元素 > 下標大的元素,則交換位置
if list1[j] < list1[j + 1]:
list1[j],list1[j + 1] = list1[j + 1],list1[j]
print(list1)
- 選擇排序
li = [17, 4, 77, 2, 32, 56, 23]
# 外層回圈:控制比較的輪數
for i in range(len(li) - 1):
# 內層回圈:控制每一輪比較的次數
for j in range(i + 1, len(li)):
# 如果下標小的元素>下標大的元素,則交換位置
if li[i] > li[j]:
li[i], li[j] = li[j], li[i]
print(li)
串列元素的查找
- 順序查找
# 順序查找
# 1.需求:查找指定元素在串列中的位置
list1 = [5, 6, 5, 6, 24, 17, 56, 4]
key = 6
for i in range(len(list1)):
if key == list1[i]:
print("%d在串列中的位置為:%d" % (key,i))
# 2.需求:模擬系統的index功能,只需要查找元素在串列中第一次出現的下標,如果查找不到,列印not found
# 串列.index(元素),回傳指定元素在串列中第一次出現的下標
list1 = [5, 6, 5, 6, 24, 17, 56, 4]
key = 10
for i in range(len(list1)):
if key == list1[i]:
print("%d在串列中的位置為:%d" % (key,i))
break
else:
print("not found")
# 3.需求:查找一個數字串列中的最大值以及對應的下標
num_list = [34, 6, 546, 5, 100, 16, 77]
max_value = num_list[0]
max_index = 0
for i in range(1, len(num_list)):
if num_list[i] > max_value:
max_value = num_list[i]
max_index = i
print("最大值%d在串列中的位置為:%d" % (max_value,max_index))
# 4.需求:查找一個數字串列中的第二大值以及對應的下標
num_list = [34, 6, 546, 5, 100, 546, 546, 16, 77]
# 備份
new_list = num_list.copy()
# 升序排序
for i in range(len(new_list) - 1):
for j in range(len(new_list) - 1 - i):
if new_list[j] > new_list[j + 1]:
new_list[j],new_list[j + 1] = new_list[j + 1],new_list[j]
print(new_list)
# 獲取最大值
max_value = new_list[-1]
# 統計最大值的個數
max_count = new_list.count(max_value)
# 獲取第二大值
second_value = new_list[-(max_count + 1)]
# 查找在串列中的位置:順序查找
for i in range(len(num_list)):
if second_value == num_list[i]:
print("第二大值%d在串列中的下表為:%d" % (second_value,i))
- 二分法查找
# 二分法查找的前提:有序
li = [45, 65, 7, 67, 100, 5, 3, 2, 35]
# 升序
new_li = sorted(li)
key = 100
# 定義變數,表示索引的最小值和最大值
left = 0
right = len(new_li) - 1
# left和right會一直改變
# 在改變程序中,直到left==right
while left <= right:
# 計算中間下標
middle = (left + right) // 2
# 比較
if new_li[middle] < key:
# 重置left的值
left = middle + 1
elif new_li[middle] > key:
# 重置right的值
right = middle - 1
else:
print(f'key的索引為{li.index(new_li[middle])}')
break
else:
print('查找的key不存在')
串列的其他方法
reverse()
用于串列中資料的逆序排列,
a = [3, 2, 8, 4, 6]
a.reverse()
print(a) # [6, 4, 8, 2, 3]
copy()
復制串列,屬于淺拷貝,
a = [3, 6, 7, 8, 2]
b = a.copy()
print(b) # [3, 6, 7, 8, 2]
串列相關的內置函式
max()和min()
回傳串列中的最大值和最小值
a = [3, 2, 8, 4, 6]
print(max(a)) # 8
print(min(a)) # 2
sum()
對數值型串列的所有元素進行求和操作,對非數值型串列運算則會報錯,
a = [3, 2, 8, 4, 6]
print(sum(a)) # 23
字典
字典的特點
- 字典中的元素是key: value的形式存盤資料,即鍵值對
- 字典是無序資料,即沒有索引值
- key是唯一的,如果key重復, 則覆寫前面的值,支持資料型別有:int,float, bool, str, 元組(不能為串列)
- value支持任何資料型別,就是說字典的值可以進行:增刪改的操作
- 字典不支持加號拼接和乘號多次輸出

定義字典
- 定義空字典: dict = { }
- 定義非空字典 dict = {key1: value1,key2: value2}
字典基本操作
- 描述中統一字典名為:dict,鍵為:key,值為:value,根據實際情況進行調整
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
讀取字典的值
- 語法:dict[key]
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
print(dict["CSDN"])
# 運行結果
碼上開始
增加字典的值
- 語法:dict[key]=value
- key為不存在的,如果是存在的則是修改當前key的值
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
dict["age"] = 35
print(dict)
# 運行結果
{'CSDN': '碼上開始', 'name': '老豬', 'age': 35}
洗掉單個元素
- 語法:del dict[key]
- 也可以使用dict.pop()
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
del dict["name"]
# dict.pop("name")
print(dict)
# 運行結果
{'CSDN': '碼上開始'}
洗掉整個字典
- 語法:dict.clear()
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
dict.clear()
print(dict)
# 運行結果
{}
修改字典的值
- dict[key]=value
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
dict["CSDN"]="烏托邦"
print(dict)
# 運行結果
{'CSDN': '烏托邦', 'name': '老豬'}
字典常用方法
-
dict.keys()—獲取字典里所有的鍵
-
常搭配for回圈使用
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
for key in dict.keys():
print(key)
# 運行結果
CSDN
name
- dict.values()—獲取字典里所有的鍵
- 常搭配for回圈使用
# -*- coding: utf-8 -*-
# @Author : 碼上開始
dict = {"CSDN": "碼上開始", "name": "老豬"}
for value in dict.values():
print(value)
# 運行結果
碼上開始
老豬
- dict.itmes()—獲取字典里的所有鍵和值
- 常搭配for回圈使用
# -*- coding: utf-8 -*-# @Author : 碼上開始dict = {"CSDN": "碼上開始", "name": "老豬"}for key, value in dict.items(): print("key值:", key) print("value:", value) # 運行結果key值: CSDNvalue: 碼上開始key值: namevalue: 老豬
資料轉換
-
將串列或元組轉成字典
-
語法:dict(list/tuple)
# -*- coding: utf-8 -*-# @Author : 碼上開始tuple = (("CSDN, "碼上開始"), ("name", "老豬"))# list = [["CSDN", "碼上開始"], ["name", "老豬"]]print(dict(tuple))# 運行結果{'CSDN': '碼上開始', 'name': '老豬'}
嵌套
- 有時候,需要將一系列字典存盤在串列中,或將串列作為值存盤在字典中,這稱為嵌套
- 可以在串列中嵌套字典、在字典中嵌套串列甚至在字典中嵌套字典
# -*- coding: utf-8 -*-# @Author : 碼上開始words = {"name": {"CSDN": "碼上開始"}}print(words["name"]["CSDN"])# 運行結果碼上開始
字典常用內置函式
- len(dict):計算字典元素個數,即鍵的總數
- type():回傳輸入的變數型別,如果變數是字典就回傳字典型別
元組
-
Python 的元組與串列類似,不同之處在于元組的元素不能修改
-
元組與串列類似,下標索引從 0 /-1開始,可以進行截取,組合等
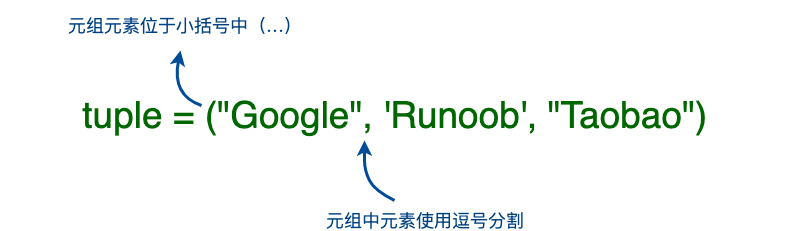
定義元組
- 元組使用小括號 ( )
- 元組創建很簡單,只需要在括號中添加元素,并使用逗號隔開即可
- 元組中只包含一個元素時,需要在元素后面添加逗號
創建元組
- 創建空元組
# -*- coding: utf-8 -*-
# @Author : 碼上開始
songs = ()
- 創建非空元組
# -*- coding: utf-8 -*-
# @Author : 碼上開始
songs = ("千里之外", "東風破", "比我幸福")
訪問元組
- 通過下標取值
- 取值方式同串列
# -*- coding: utf-8 -*-
# @Author : 碼上開始
songs = ("千里之外", "東風破", "比我幸福")
print(songs[0])
# 運行
千里之外
修改元組
- 元組中的元素值是不允許修改的,但我們可以對元組進行連接組合
- 只有一個元素時,需要加逗號
# -*- coding: utf-8 -*-
# @Author : 碼上開始
songs = ("千里之外", "東風破")
singers = ("周杰倫",)
starts = songs + singers
print(starts)
洗掉元組
- 元組中的元素值是不允許洗掉的
- 但我們可以使用del陳述句來洗掉整個元組
# -*- coding: utf-8 -*-
# @Author : 碼上開始
songs = ("千里之外", "東風破")
del songs
# 運行報錯,提示變數沒有定義
print(songs)
元組運算子
- 與字串一樣,元組之間可以使用 + 號和 * 號進行運算
- 可以組合和復制,運算后會生成一個新的元組
| Python 運算式 | 結果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 計算元素個數 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 連接 |
| (‘Hi!’,) * 4 | (‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’) | 復制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print (x,) | 1 2 3 | 迭代 |
元組切片取值
-
因為元組也是一個序列,所以我們可以訪問元組中的指定位置的元素
-
也可以截取索引中的一段元素
-
操作方式和串列一樣
tup = ('Google', 'Runoob', 'Taobao', 'Wiki', 'Weibo','Weixin')
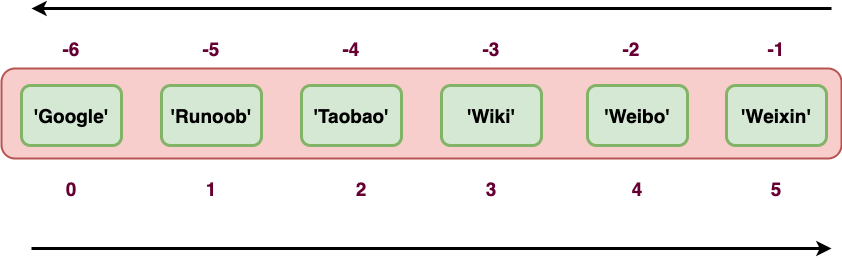
| Python 運算式 | 結果 | 描述 |
|---|---|---|
| tup[1] | ‘Runoob’ | 讀取第二個元素 |
| tup[-2] | ‘Weibo’ | 反向讀取,讀取倒數第二個元素 |
| tup[1:] | (‘Runoob’, ‘Taobao’, ‘Wiki’, ‘Weibo’, ‘Weixin’) | 截取元素,從第二個開始后的所有元素, |
| tup[1:4] | (‘Runoob’, ‘Taobao’, ‘Wiki’) | 截取元素,從第二個開始到第四個元素(索引為 3), |
集合
- 集合(set)是一個無序的不重復元素序列,
- 可以使用大括號 { } 或者 set() 函式創建集合,注意:創建一個空集合必須用 set() 而不是 { },因為 { } 是用來創建一個空字典,
{}定義集合
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "碼上開始"
# 重復的元素,列印結果中只會顯一個
fruit = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
# 列印結果
{'pear', 'orange', 'apple', 'banana'}
使用set函式創建集合
# -*- coding:utf-8 -*-
# @Author: "碼上開始"
fruit = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
new_set = set(fruit)
# 重復的元素,列印結果中只會顯一個
print(new_set)
# 結果
{'banana', 'apple', 'orange', 'pear'}
集合運算
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "碼上開始"
a = set('abracadabra') # {'r', 'a', 'd', 'c', 'b'}
b = set('alacazam') # {'m', 'a', 'z', 'c', 'l'}
# a包含b不包含的元素
c = a - b
print(c)
# 結果
{'b', 'r', 'd'}
# 集合a或b中包含的所有元素
c = a | b
print(c)
# 結果
{'m', 'a', 'r', 'l', 'd', 'z', 'b', 'c'}
# 集合a和b中都包含了的元素
c = a & b
print(c)
# 結果
{'c', 'a'}
# 不同時包含于a和b的元素
c = a ^ b
print(c)
# 結果
{'r', 'm', 'z', 'b', 'd', 'l'}
集合的基本操作
添加元素(add/update)
- 如果添加元素如果存在,則不進行任何操作
- 可添加元素,也可以串列、元組、字典等
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "碼上開始"
num = {1, 2, 3}
num.add(4)
print(num)
# 結果
{1, 2, 3, 4}
# -*- coding:utf-8 -*-
# @Author: "碼上開始"
# 如果添加為串列等,則要用update方法
num = {1, 2, 3}
list = [4, 5]
num.update(list)
print(num)
# 結果
{1, 2, 3, 4, 5}
移除元素(remove/pop)
# -*- coding:utf-8 -*-
# @Author: "碼上開始"
num = {1, 2, 3}
num.remove(1)
print(num)
# 結果
{2, 3}
# -*- coding:utf-8 -*-
# @Author: "碼上開始"
# 隨機洗掉集合中的元素
num = {1, 2, 3}
num.pop()
print(num)
# 結果
{2, 3}
計算集合元素個數
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "碼上開始"
num = {1, 2, 3}
print(len(num))
# 結果
3
清空集合
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "碼上開始"
num ={1, 2, 3}
num.clear()
print(num)
# 結果
set()
判斷元素是否在集合中存在
判斷元素 x 是否在集合中,存在回傳 True,不存在回傳 False
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "碼上開始"
num ={1, 2, 3}
if 1 in num:
print("存在集合中")
集合內置方法完整串列
| 方法 | 描述 |
|---|---|
| add() | 為集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷貝一個集合 |
| difference() | 回傳多個集合的差集 |
| difference_update() | 移除集合中的元素,該元素在指定的集合也存在, |
| discard() | 洗掉集合中指定的元素 |
| intersection() | 回傳集合的交集 |
| intersection_update() | 回傳集合的交集, |
| isdisjoint() | 判斷兩個集合是否包含相同的元素,如果沒有回傳 True,否則回傳 False, |
| issubset() | 判斷指定集合是否為該方法引數集合的子集, |
| issuperset() | 判斷該方法的引數集合是否為指定集合的子集 |
| pop() | 隨機移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 回傳兩個集合中不重復的元素集合, |
| symmetric_difference_update() | 移除當前集合中在另外一個指定集合相同的元素,并將另外一個指定集合中不同的元素插入到當前集合中, |
| union() | 回傳兩個集合的并集 |
| update() | 給集合添加元素 |
條件陳述句
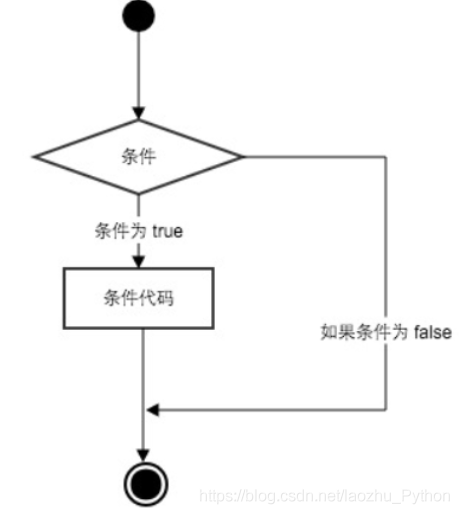
-
每條if陳述句的核心都是一個值為True或False的運算式,這種運算式被稱為條件測驗,
-
Python 根據條件測驗的值為True還是False來決定是否執行if陳述句中的代碼,
-
如果條件測驗的值為True, Python就執行緊跟在if陳述句后面的代碼.
-
Python程式語言指定任何非0和非空(null)值為True,0 或者 null為False,
可以通過下圖來簡單了解條件陳述句的執行程序:
代碼執行程序
- 如果條件為ture,一直執行if下的代碼,直到條件為False
- 如果條件false直接執行else陳述句,如果沒有else則不執行操作

注意
- 1、每個條件后面要使用冒號 : 表示接下來是滿足條件后要執行的陳述句塊,
- 2、使用縮進來劃分陳述句塊,相同縮進數的陳述句在一起組成一個陳述句塊,
if
score = 90
if score >= 90:
print("成績優秀")
if…else
score = 80
if score >= 90:
print("成績優秀")
else:
print("成績中等")
if…elif…else
score = 60
if score >= 90:
print("成績優秀")
elif score > 60 :
print("成績剛剛及格")
else:
print("你沒及格喔,加油!")
回圈
? for回圈是在python開發中用的很多的一種回圈型別, 需要熟練掌握,
for回圈的使用場景
- for回圈用于重復執行具體次數操作
- for回圈主要用來遍歷、回圈、串列、集合、字典,檔案、甚至是自定義類或函式,
for回圈操作串列實體演示
- 使用for回圈經常結合if陳述句使用,對串列進行遍歷元素、修改元素、洗掉元素、統計串列中元素的個數,
for回圈用來遍歷整個串列
#for回圈主要用來遍歷、回圈、序列、集合、字典
Fruits = ['apple','orange','banana','grape']
for fruit in Fruits:
print(fruit)
print("結束遍歷")
結果演示:
apple
orange
banana
grape
結速遍歷
for回圈用來修改串列中的元素
#for回圈主要用來遍歷、回圈、序列、集合、字典
#把banana改為Apple
Fruits=['apple','orange','banana','grape']
for i in range(len(Fruits)):
if Fruits[i] == 'banana':
Fruits[i] ='apple'
print(Fruits)
結果演示:['apple', 'orange', 'apple', 'grape']
- for回圈用來洗掉串列中的元素
Fruits=['apple','orange','banana','grape']
for i in Fruits:
if i == 'banana':
Fruits.remove(i)
print(Fruits)
結果演示:['apple', 'orange', 'grape']
for回圈統計串列中某一元素的個數
#統計apple的個數
Fruits = ['apple','orange','banana','grape','apple']
count = 0
for i in Fruits:
if i=='apple':
count+=1
print("Fruits串列中apple的個數="+str(count)+"個")
結果演示:Fruits串列中apple的個數=2個
注:串列某一資料統計還可以使用Fruit.count(object)
for回圈實作1到9相乘
sum=1
for i in list(range(1,10)):
sum *= i
print("1*2...*9=" + str(sum))
結果演示:1*2...*10=362880
遍歷字串
for str in 'abc':
print(str)
結果演示:
a
b
c
遍歷集合物件
for str in {'a',2,'bc'}:
print(str)
結果演示:
a
2
bc
遍歷檔案
for content in open("D:\\test.txt"):
print(content)
結果演示:
朝辭白帝彩云間,千里江陵一榷訓,
兩岸猿聲啼不住,輕舟已過萬重山,
遍歷字典
for key,value in {"name":'碼上開始',"age":22}.items():
print("鍵---"+key)
print("值---"+str(value))
結果演示:
鍵---name
值---碼上開始
鍵---age
值---22
函式
- 函式是組織好的,可重復使用的,用來實作單一,或相關聯功能的代碼段,
- 函式能提高應用的模塊性,和代碼的重復利用率,你已經知道Python提供了許多內建函式,比如print(),但你也可以自己創建函式,這被叫做用戶自定義函式,
定義一個函式
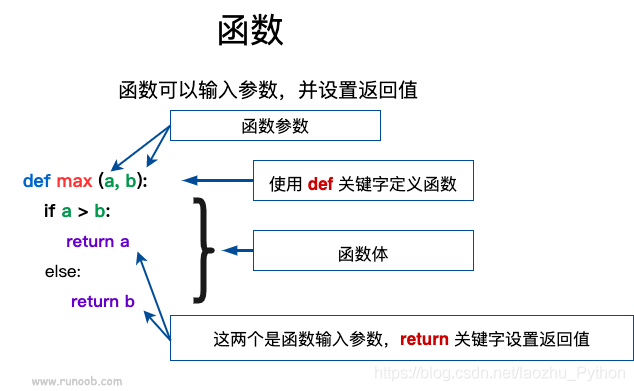
你可以定義一個由自己想要功能的函式,以下是簡單的規則:
- 函式代碼塊以 def 關鍵詞開頭,后接函式識別符號名稱和圓括號 (),
- 任何傳入引數和自變數必須放在圓括號中間,圓括號之間可以用于定義引數,
- 函式的第一行陳述句可以選擇性地使用檔案字串—用于存放函式說明,
- 函式內容以冒號起始,并且縮進,
- return [運算式] 結束函式,選擇性地回傳一個值給呼叫方,不帶運算式的return相當于回傳 None
#! /usr/bin/python3
# @Author : 碼上開始
def example():
'''
一個簡單的函式
'''
print("Hello World !")
example()
列印結果:
Hello World !
三引號中間的內容屬于函式的注釋檔案,注釋的作用是告訴別人或以后查看代碼知道能快速知道這段干嘛是做什么的,
函式還可以嵌套,也就是函式里面有函式
#! /usr/bin/python3
# @Author : 碼上開始
def exapmle(name):
def go(name):
print('我最棒:' + name)
go(name)
example('小明')
列印結果:
我最棒:小明
函式的引數
形參和實參
#! /usr/bin/python3
# @Author : 碼上開始
def example(username):
print("Hello World ! My name is " + str(username))
example("小明")
example("小花")
列印結果:
Hello World ! My name is 小明
Hello World ! My name is 小花
?這是一個帶引數的函式,在函式example中,username就是一個形參,也就是形式引數,是用來接收呼叫函式時傳入的引數,你傳的是啥它就是啥,傳人它就是人,傳鬼它就是鬼的那種,
?實參就是實際引數,在呼叫函式的時候,傳遞是小明,那么小明就是實參,傳遞的是小花,那么小花也是實參,實參傳遞給函式后,會賦值給函式中的形參,然后我們就可以在函式中使用到外部傳入的資料了,
引數默認值
寫Java的時候最痛恨的就是方法不能設定默認值,使得必須得多載才行,
python允許我們給函式的形參設定一個默認值,不傳引數呼叫的話,就統一默認是這個值,
#! /usr/bin/python3
# @Author : 碼上開始
def welcome(username = '奧特曼'):
print("Hello World ! My name is " + str(username))
welcome("小明")
welcome()
列印結果:
Hello World ! My name is 小明
Hello World ! My name is 奧特曼
修改引數后影響外部
?在函式中修改引數內容會不會影響到外部,這個問題取決于實參的型別是不是可變的,可不可變就是可不可以修改,
字串就是一種不可變的型別,
比如:
name = “小明”
name = “小花”
請問,我是把"小明"修改成了"小花"嗎? 答案是 非也,
?實際上我是把"小花"這個字串賦值給了name,讓name指向了這個新字串,替換掉了原來的"小明",原來的"小明"仍然是"小明",沒有受到一點改變,
?在python中,不可變型別有:整數、字串、元組,可變型別有:串列、字典,如果傳遞的引數包含可變型別,并且在函式中對引數進行了修改,那么就會影響到外部的值,
#! /usr/bin/python3
# @Author : 碼上開始
def change(lis):
lis[1] = '小明他二舅'
names = ['小明','小花','小紅']
change(names)
print(names)
列印結果:
[‘小明’, ‘小明他二舅’, ‘小紅’]
如果我們不希望出現這種事情,那么就將物件復制一份再傳遞給函式,
#! /usr/bin/python3
# @Author : 碼上開始
def change(lis):
lis[1] = '小明他大爺'
names = ['小明','小花','小紅']
change(names[:])
print(names)
列印結果:[‘小明’, ‘小花’, ‘小紅’]
?我們用切片的方法拷貝了一份names,函式中盡管修改了引數,也不過是修改的是副本,不會影響到原始的names,
關鍵字引數
關鍵字引數讓你可以不用考慮函式的引數位置,你需以鍵值對的形式指定引數的對應形參,
#! /usr/bin/python3
# @Author : 碼上開始
def welcome(name,address):
print(f"你好 {name} , 歡迎來到 {address} !")
welcome(address='長沙',name='小強')
列印結果:你好 小強 , 歡迎來到 長沙 !
收集引數
?有時候我們需要允許用戶提供任意數量的引數,函式的形參可以帶個星號來接收,不管呼叫函式的時候傳遞了多少實參,都將被收集到形參這個變數當中,形參的型別是元組,
#! /usr/bin/python3
# @Author : 碼上開始
def welcome(*names):
print(names)
welcome('樂迪','天天','酷飛','小黑')
列印結果:(‘樂迪’, ‘天天’, ‘酷飛’, ‘小黑’)
還有一種是帶兩個星號的形參,用于接收鍵值對形式的實參,匯入到函式中的型別是字典,
#! /usr/bin/python3
# @Author : 碼上開始
def welcome(**names):
print(names)
welcome(name='小明',age=20,sex='男')
列印結果:{‘name’: ‘小明’, ‘age’: 20, ‘sex’: ‘男’}
分配引數
分配引數是收集引數的相反操作,可使得一個元組或字典變數自動分配給函式中的形參,
#! /usr/bin/python3
# @Author : 碼上開始
def welcome(name,address):
print(f"你好 {name} , 歡迎來到 {address} !")
a = ('小明','廣州')
welcome(*a)
列印結果:你好 小明 , 歡迎來到 廣州 !
我們改成字典的方式:
#! /usr/bin/python3
# @Author : 碼上開始
def welcome(name,address):
print(f"你好 {name} , 歡迎來到 {address} !")
a = {'address':'山東','name':'小紅'}
welcome(**a)
列印結果:你好 小紅 , 歡迎來到 山東 !
函式的回傳值
首先說明,所有的函式都是有回傳值的,如果編程人員沒有指定回傳值,那么默認會回傳None,對標其他語言中的null,
一個簡單的函式回傳值的例子:
#! /usr/bin/python3
# @Author : 碼上開始
def get_full_name(first_name,last_name):
return first_name + last_name
r = get_full_name('王','大拿')
print(r)
列印結果:王大拿
然而python中的函式還可以回傳多個值,回傳出的值被裝載到元組中:
#! /usr/bin/python3
# @Author : 碼上開始
def func(num):
return num**2,num**3,num**4
result = func(2)
print(result)
列印結果:(4, 8, 16)
??在python中函式定義的時候沒有回傳值的簽名,導致我們無法提前知道函式的回傳值是什么型別,回傳的什么完全看函式中的return的是什么,特別是邏輯代碼比較多的函式,比如里面有多個if判斷,有可能這個判斷return出來的是布林值,另一個判斷return出來的是串列,還一個判斷啥也不return,你呼叫的時候你都搞不清楚該怎么處理這個函式的回傳值,在這一點來說,Java完勝,
所以在無規則限制的情況下,代碼寫的健不健壯,好不好用,主要取決于編程人員的素質,
匿名函式
??匿名函式就是不用走正常函式定義的流程,可以直接定義一個簡單的函式并把函式本身賦值給一個變數,使得這個變數可以像函式一樣被呼叫,在python中可以用lambda關鍵字來申明定義一個匿名函式,
我們把王大錘的例子改一下:
# -*- coding: utf-8 -*-
# @Author : 一凡
get_full_name = lambda first_name,last_name : first_name + last_name
r = get_full_name('王','大錘')
print(r)
列印結果:王大錘
函式的作用域
訪問全域作用域
??python每呼叫一個函式,都會創建一個新命名空間,也就是區域命名空間,函式中的變數就叫做區域變數,與外部的全域命名空間不會相互干擾,
這是常規狀態,當然也會有非常規需求的時候,所以python給我們提供了globals()函式,讓我們可以在區域作用域中訪問到全域的變數,
#! /usr/bin/python3
# @Author : 碼上開始
def func():
a = globals()
print(a['name'])
name = '小明'
func()
列印結果:小明
globals()函式只能讓我們訪問到全域變數,但是是無法進行修改的,如果我們要修改全域變數,需要用到global關鍵字將全域變數引入進來,
#! /usr/bin/python3
# @Author : 碼上開始
def func():
global name
name = '小花'
name = '小明'
func()
print(name)
列印結果:小花
面向對像
類

-
類顧名思義,就是一類事物、或者叫做實體,它用來描述具有共同特征的一類事物
-
我們在Python中宣告類的關鍵詞是class,類還有功能和屬性,屬性就是這類事物的特征,而功能就是它能做什么,也是就是方法或者函式
-
比如把人為一類,人的名字,年齡,身高,膚色是屬性,人可以跑,跳這種為方法
定義類:
class 類名(object):
def function1(self):
pass
def function2(self):
pass
.....
構造方法:_init_
- 類中的函式稱為方法;你前面學到的有關函式的一切都適用于方法,就目前而言,唯一重要的差別是呼叫方法的方式,
- _init_ 是一個特殊的方法(注:兩邊為雙下劃線),每當你根據類創建新實體時,Python都會自動運行它,如何理解呢?
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Test():
def __init__(self):
print("我是構造方法, 實體化對像后就會自動呼叫")
def test01(self):
print("該方法沒有執行")
test = Test()
# 運行結果
我是構造方法, 實體化對像后就會自動呼叫
給屬性指定默認值
- 類中的每個屬性都必須有初始值,哪怕這個值是0或空字串
- 假設購買手機預算3500
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Phone(object):
def __init__(self):
self.phone_money = 3500
def money(self):
print("手機價格是:", self.phone_money)
# 實體化對像
test = Phone()
test.money()
# 運行結果
手機價格是: 3500
直接修改屬性值
我提高了手機購買預算,價格為6000,通過直接修改默認價格的方法修改
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Phone(object):
def __init__(self):
self.phone_money = 3500
def money(self):
print("手機價格是:", self.phone_money)
# 實體化對像
test = Phone()
# 直接修改價格--對像名.屬性名
test.phone_money= 6500
test.money()
通過方法修改屬性
- 當然也可以通過修改方法方法,將money作為引數傳入,修改屬性的值
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Phone(object):
def money(self, m):
self.mobile_money = m
print("手機價格是:", self.mobile_money)
# 實體化對像
test = Phone()
test.money(5000)
test.money(6000)
# 運行結果
手機價格是: 5000
手機價格是: 6000
通過方法對屬性的值進行遞增
- 手機預算價格為3500,但我想買個更好的手機,預算價格提高2500
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Phone(object):
def __init__(self):
self.phone_money = 3500
def update(self,money):
self.phone_money += money
print("手機價格是:", self.phone_money)
# 實體化對像
test = Phone()
test.update(2500)
# 運行結果
手機價格是:6000
類的繼承
- 繼承特性:子類繼承父類后,自動擁有了父類里的方法
- 可以只繼承一個父類,也可以繼承多個父類
- 比如:以前的非智能手機為父類,現在的是智能手機是子類
- 智能手機擁有非智能機的通話功能和發短信等功能,這就是繼承
- 繼承后就可以呼叫父類里的方法
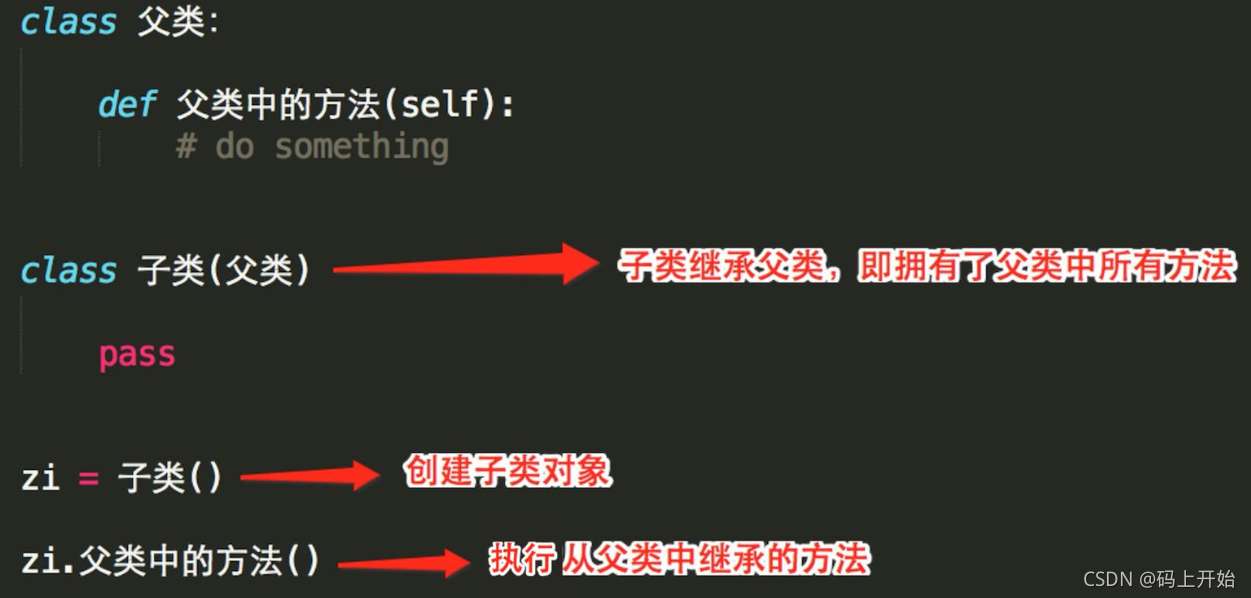
實體:
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Mobile:
'''創建父類手機'''
def call(self):
print("可以撥打電話")
# 創建智能手機子類,且繼承父類
class Smartphone(Mobile):
'''創建智能手機子類'''
pass
# 子類實體
phone = Smartphone()
# 子類呼叫父類方法
phone.call()
類方法重寫
-
子類和父類中擁有方法名相同的方法,說明子類重寫了父類的方法
-
重寫的作用:父類中已經有了這個方法,但子類想修改里面的內容,直接修改父類是不好的,就需要用到重寫
實體:
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Mobile:
'''創建父類手機'''
def call(self):
print("可以撥打電話")
# 創建智能手機子類,且繼承父類
class Smartphone(Mobile):
'''創建智能手機子類'''
def call(self):
print("不僅可以打電話,還能發送微信語音")
# 子類實體
phone = Smartphone()
# 呼叫自己方法,重寫父類call方法
phone.call()
多繼承
- 多繼承可以讓子類物件,同時具有多個父類的屬性和方法
# -*- coding: utf-8 -*-
# @Author : 碼上開始
class Mobile:
'''創建父類手機'''
def call(self):
print("可以撥打電話")
class Music():
movie = "可以看電影"
def music(self):
print("可以播放音樂")
# 繼承了多個父類
class Smartphone(Mobile, Music):
pass
# 子類實體
phone = Smartphone()
# 呼叫父類方法
phone.call()
phone.music()
# 呼叫類中屬性
print(phone.movie)
繼承構造方法
- 子類自動呼叫父類的構造方法
class Father():
def __init__(self):
print("自動呼叫父類構造方法")
def hello(self):
print("hello, 碼上開始")
class Son(Father):
pass
son = Son()
son.hello()
多型
-
以封裝和繼承為前提,不同的子類對像呼叫相同的方法,產生不同的執行結果
-
在定義變數時,不需要提前指定資料型別,變數的資料類會根據你賦值的資料來決定
a= 1當前為整數型別
a="hello"當前為字串型別
# @Time : 2021/1/9 16:11
# @Author : 碼上開始
class WeChatPay():
def payfor(self):
print("微信支付")
class ALiPay():
def payfor(self):
print("支付寶支付")
class StartPay():
def start(self, pay_method):
pay_method.payfor()
wx = WeChatPay()
zfb = ALiPay()
zf = StartPay()
# 傳入微信實體對像
zf.start(wx)
# 傳入支付寶實體對像
zf.start(zfb)
例外處理

- 本文實體分析了Python中的例外處理try/except/finally/raise用法,分享給大家供大家參考,具體如下:
- 例外發生在程式執行的程序中,如果python無法正常處理程式就會發生例外,導致整個程式終止執行,python中使用try/except陳述句可以捕獲例外,
try/except
- 例外的種類有很多,在不確定可能發生的例外型別時可以使用Exception捕獲所有例外:
try:
pass
except Exception as e:
print(e)
try/except/else
- 在try陳述句后也可以跟一個else陳述句,這樣當try陳述句塊正常執行沒有發生例外,則將執行else陳述句后的內容:
try:
pass
except Exception as e:
print("No exception")
else:
print("我列印的是else")
try/Except/finally
- 在try陳述句后邊跟一個finally陳述句,則不管try陳述句塊有沒有發生例外,都會在執行try之后執行finally陳述句后的內容:
try:
pass
except Exception as e:
print("Exception: ", e)
finally:
print("try is done")
raise拋出例外
使用raise來拋出一個例外:
a = 0
if a == 0:
raise Exception("a must not be zero")
最好指出例外的具體型別,如:
a = 0
if a == 0:
raise ZeroDivisionError(``"a must not be zero"``)
日志模塊
? python中的logging模塊用于記錄日志,用戶可以根據程式實作需要自定義日志輸出位置、日志級別以及日志格式,
將日志內容輸出到螢屏
一個最簡單的logging模塊使用樣例,直接列印顯示日志內容到螢屏,
import logging
logging.critical("critical log")
logging.error("error log")
logging.warning("warning log")
logging.info("info log")
logging.debug("debug log")
輸出結果如下:
CRITICAL:root:critical log
ERROR:root:error log
WARNING:root:warning log
說明:默認情況下python的logging模塊將日志列印到標準輸出,并且只顯示大于等于warning級別的日志(critical > error > warning > info > debug),
將日志內容輸出到檔案
? 將日志事件記錄到檔案是一種非常常見的情況,方便出現問題時快速定位問題,在logging模塊默認配置條件下,記錄日志內容,代碼如下:
import logging
logging.basicConfig(filename='example.log',level=logging.DEBUG)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
輸出結果如下:
D:\pycharm\work>type example.log
DEBUG:root:This message should go to the log file
INFO:root:So should this
WARNING:root:And this, too
說明:type為dos視窗下查看檔案內容命令
定制日志內容(日志級別、日志格式)
根據程式運行對日志記錄的要求,通常需要自定義日志顯示格式、輸出位置以及日志顯示級別,可以通過logging.basicConfig()定制滿足自己要求的日志輸出格式,
import logging
logging.basicConfig(format='[%(asctime)s %(filename)s line:%(lineno)d] %(levelname)s: %(message)s',
level=logging.DEBUG, filename="log.txt", filemode="w")
logging.debug('This message should appear on the console')
logging.info('So should this')
logging.warning('And this, too')
輸出結果如下:
```python
D:\pycharm\work>type log.txt
[2020-02-02 10:31:42,994 json_pro.py line:5] DEBUG: This message should appear on the console
[2020-02-02 10:31:42,995 json_pro.py line:6] INFO: So should this
[2020-02-02 10:31:42,995 json_pro.py line:7] WARNING: And this, too
通過修改logging.basicConfig()函式中引數取值來定制日志顯示,函式引數定義及含義如下:
filename 指定日志寫入檔案名,
filemode 檔案打開方式,默認值為"a"
format 設定日志顯示格式
dateft 設定日期時間格式
level 設定顯示日志級別
stream 指定stream創建StreamHandler,可以指定輸出到sys.stderr,sys.stdout或者檔案,默認為sys.stderr,
format引數用到的格式化字串如下:
%(asctime)s 字串形式的當前時間,默認格式是 “2003-07-08 16:49:45,896”,逗號后面的是毫秒
%(filename)s 呼叫日志輸出函式的模塊的檔案名
%(levelname)s 文本形式的日志級別
%(funcName)s 呼叫日志輸出函式的函式名
%(lineno)d 呼叫日志輸出函式的陳述句所在的代碼行
%(message)s 用戶輸出的訊息
%(module)s 呼叫日志輸出函式的模塊名
多模塊記錄日志
如果開發的程式包含多個模塊,就需要考慮日志間的記錄方式,基本樣例如下:
主程式檔案:
import logging
import mylib
def main():
logging.basicConfig(format='[%(asctime)s %(filename)s line:%(lineno)d] %(levelname)s: %(message)s',
level=logging.DEBUG, filename="log.txt", filemode="w")
logging.info('Started')
mylib.do_something()
logging.info('Finished')
if __name__ == '__main__':
main()
日志同時輸出螢屏和寫入檔案
logging模塊可以通過FileHander和StreamHandler分別制定向檔案和螢屏輸出,
import logging
logger = logging.getLogger() # 不加名稱設定root logger
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s: - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S')
# 使用FileHandler輸出到檔案
fh = logging.FileHandler('log.txt')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# 使用StreamHandler輸出到螢屏
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# 添加兩個Handler
logger.addHandler(ch)
logger.addHandler(fh)
logger.info('this is info message')
logger.warning('this is warn message')
控制臺輸出如下:
[2020-02-02 10:58:16 json_pro.py line:22] INFO: this is info message
[2020-02-02 10:58:16 json_pro.py line:23] WARNING: this is warn message
日志檔案內容如下:
D:\pycharm\work>type log.txt
[2020-02-02 10:58:55 json_pro.py line:22] INFO: this is info message
[2020-02-02 10:58:55 json_pro.py line:23] WARNING: this is warn message
datatime模塊
??當我們在Python中需要使用到時間的時候,有兩個關于時間的模塊,分別是time和datetime,time模塊偏底層,在部分函式運行的時候可能會出現不同的結果,而datetime模塊提供了高級API,使用起來更為方便,我們通常在使用的時候會涉及到包含時間和日期的datetime、只包含日期的date以及只包含時間的time,本節我們就對這三種方法進行學習,
datetime的使用方法為:
datetime.dateto,e(year, month, day, hour``=``0``, minute``=``0``, second``=``0``, microsecond``=``0``, tzinfo``=``None``, ``*``, fold``=``0``)
? 其中year,month和day是不能缺少的,tzinfo為時區引數,可以為None或其他引數,其余引數的范圍如下:
? MINYEAR <= year <= MAXYEAR,
? 1 <= month <= 12,
? 1 <= day <= number of days in the given month and year,
? 0 <= hour < 24,
? 0 <= minute < 60,
? 0 <= second < 60,
? 0 <= microsecond < 1000000,
? fold in [0, 1].
下面講幾種常用的方法
- datetime.datetime.now()
? 回傳當前的日期和時間
? 代碼如下:
#! /usr/bin/python3
# @公眾號 : 碼上開始
import datetime
# 回傳當前日期及時間
now_time = datetime.datetime.now()
print(now_time)
? 輸出結果為:
2020``-``02``-``01` `19``:``18``:``59.926474
- date()
? 回傳當前時間的日期
? 代碼如下:
#! /usr/bin/python3
# @公眾號 : 碼上開始
import datetime
#回傳當前日期及時間``
now_time= datetime.datetime.now()
#輸出當前的日期
print(now_time.date())
? 輸出結果:
2020``-``02``-``01
- time()
? 回傳當前的時間物件
? 代碼如下:
#! /usr/bin/python3
# @公眾號 : 碼上開始
import datetime
#回傳當前日期及時間
now_time = datetime.datetime.now()
#輸出當前的時間
print(now.time())
? 輸出結果為:
19``:``22``:``10.948940
date
? date物件是日期的專屬物件,語法格式如下:
datetime.date(year,month,day),引數分別代表年月日,
date類中的常用功能有2種:
- datetime.date.today()
? 這種用法直接回傳了當前的日期,代碼如下:
#! /usr/bin/python3
# @公眾號 : 碼上開始
import datetime
#回傳當前日期
now_time = datetime.date.today()
print(now_time)
? 輸出結果為:
2020``-``02``-``01
- datetime.date.fromtimestamp()
? 這種方式回傳與時間戳對應的日期,代碼如下:
#! /usr/bin/python3
# @公眾號 : 碼上開始
import datetime
import time
c = time.time()
#回傳當前的時間戳
print('當前的時間戳為:' ,c)
now_time = datetime.date.fromtimestamp(c)
#與時間戳對應的日期
print('當前時間戳對應的日期為:', now_time)
? 輸出結果為:
當前的時間戳為: ``1580556848.3161435``當前時間戳對應的日期為: ``2020``-``02``-``01
? 在這個例題中我們先引入了time模塊中的方法,time模塊中的time.time()能回傳當前時間戳,然后我們使用上面的方法可以回傳與時間戳對應的日期,
time
? time類中包含了一整天的資訊,語法結構如下:
datetime.time(hour,moniute,second,microsecond,tzinfo``=``None``)
? 最后一個時區可以省略,看下面例子:
#! /usr/bin/python3
# @公眾號 : 碼上開始
import datetime
now_time = datetime.time(19, 42, 34, 12)
print(now_time)
? 輸出結果為:
19:42:34.000012
總結
? 由于datetime模塊中封裝了time模塊,所以我們使用datetime模塊可以保證資料更為精確,在使用程序中也可以穿插著time模塊中的部分功能,例如暫停time.sleep()等方法,
OS檔案目錄操作
- 為什么要學習os模塊?
??做為一名優秀的軟體測驗工程師,我們是要撰寫大量的python自動化代碼和生成測驗報告,我們需要訪問和處理檔案,如何能方便快捷的處理這些檔案呢? - 能處理作業中什么樣的問題?
??在自動化測驗中,經常需要查找操作檔案,比如說查找組態檔(從而讀取組態檔的資訊),查找測驗報告(從而發送測驗報告郵件),經常要對大量檔案和大量路徑進行操作,這就依賴于os模塊,所以今天整理下比較常用的幾個方法,
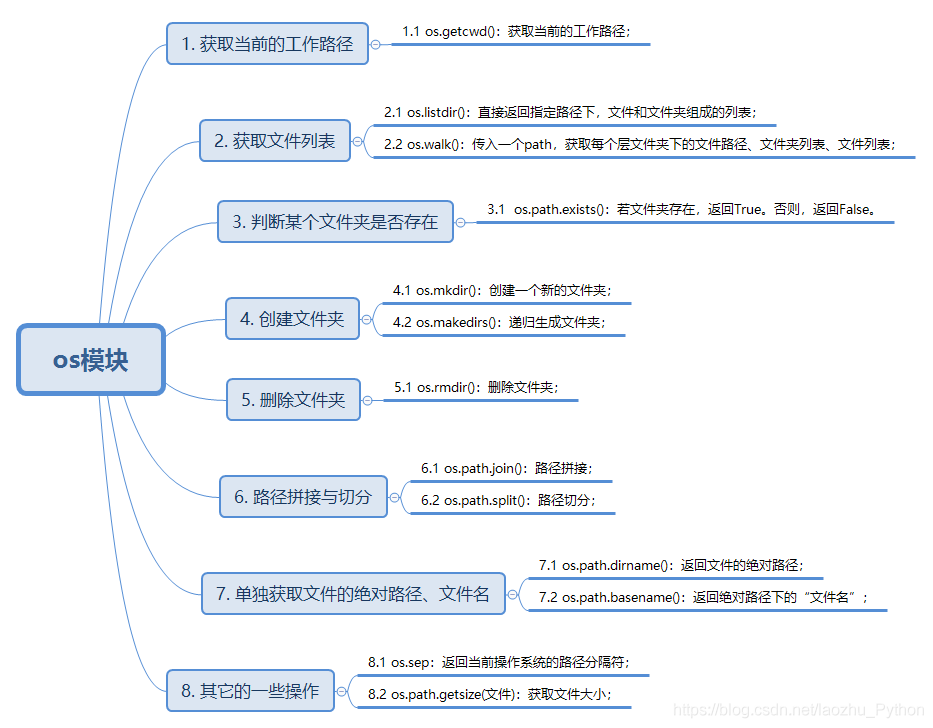
os.getcwd()
- 得到當前作業目錄,即當前python腳本目錄路徑
#! /usr/bin/python3
# @Author : 碼上開始
import os
# 查看當前路徑檔案路徑
print(os.getcwd())
# 運行結果
E:\study
os.listdir(path)
- 回傳指定目錄下的所有文 件和目錄名
#! /usr/bin/python3
# @Author : 碼上開始
import os
# 當前路徑有哪些檔案,回傳的路徑有哪些檔案
print(os.listdir(os.getcwd()))
# 運行結果
['day1.py', 'day2.py', 'day3.py', 'day4.py', 'day5.py']
os.mkdir(path)
- Python的
mkdir()方法使用數字模式模式創建一個名為path的目錄,默認模式為0777(八進制)
#! /usr/bin/python3
# @Author : 碼上開始
import os
os.mkdir("E:/study/hello")
os.rmdir(path)
- 洗掉目錄(洗掉path指定的空目錄,如果目錄非空,則拋出一個OSError例外,)
#! /usr/bin/python3
# @Author : 碼上開始
import os
os.rmdir("E:/study/hello")
os.remove(path)
- 用于洗掉指定路徑的檔案,如果指定的路徑是一個目錄,將拋出OSError,
#! /usr/bin/python3
# @Author : 碼上開始
import os
os.rmdir("E:/study/hello/day6.py")
os.path模塊
os.path.dirname(path)
- 去掉檔案名,回傳目錄回傳檔案路徑
#! /usr/bin/python3
# @Author : 碼上開始
import os
print(os.path.dirname("E:/study/day5.py"))
#運行結果
E:/study
os.path.join(path, name)
- 連接目錄與檔案名和目錄(只是起到連接作用,不會生成這個檔案)
#! /usr/bin/python3
# @Author : 碼上開始
import os
print(os.path.join("E:/study/", 'day6.py'))
#運行結果
E:/study/day6.py
os.path.split(path)
- 回傳目錄名和檔案名(回傳結果為一個元組)
#! /usr/bin/python3
# @Author : 碼上開始
import os
print(os.path.split("E:\study\day4.py"))
# 運行結果
('E:\\study', 'day4.py')
os.path.splitext(path)
- 分割路徑,回傳路徑名和檔案擴展名的元組(回傳結果為一個元組)
#! /usr/bin/python3
# @Author : 碼上開始
import os
print(os.path.splitext("E:\study\day4.py"))
# 運行結果
('E:\\study\\day4', '.py')
os.path.getmtime()
- 回傳檔案的最近修改時間(單位為秒)
- 該用法用于查找最新測驗報告
#! /usr/bin/python3
# @Author : 碼上開始
import os
print(os.path.getmtime("E:/study/old.html"))
print(os.path.getmtime("E:/study/new.html"))
# 運行結果
1597062314.1353853
1597062332.269248
random亂數
- 模塊是python自帶模塊,用于生成亂數,軟體測驗中使用場景可生成隨機手機號用于測驗作業中,
模塊常用方法
- random()函式,生成0到1的隨機小數
#! /usr/bin/python3
# @Author : 碼上開始
import random
num = random.random()
print(num)
# 運行結果
0.5234072981721078
- uniform(a,b)生成a到b的隨機小數
#! /usr/bin/python3
# @Author : 碼上開始
import random
num = random.uniform(1, 10)
print(num)
#運行結果
2.1220664313759947
- randint(a, b)生成一個a到b的隨即整數
#! /usr/bin/python3
# @Author : 碼上開始
import random
num = random.randint(1, 10)
print(num)
# 運行結果
6
- choice() 隨機回傳一個串列里面的元素
#! /usr/bin/python3
# @Author : 碼上開始
import random
num = random.choice(["135", "138", "186"])
print(num)
# 運行結果
135
- shuffle()將串列的元素隨機打亂
#! /usr/bin/python3
# @Author : 碼上開始
import random
list = [1, 2, 3, 4]
random.shuffle(list)
print("隨機排序串列 : ", list)
random.shuffle(list)
print("隨機排序串列 : ", list)
# 運行結果
隨機排序串列 : [2, 4, 1, 3]
隨機排序串列 : [3, 1, 2, 4]
- sample(, k)從串列中隨機抽取k個元素
#! /usr/bin/python3
# @Author : 碼上開始
import random
num = random.sample(["135", "138", "186"], 2)
print(num)
# 運行結果
['186', '135']
有趣好玩的偽裝者模塊:Faker
?在軟體需求、開發、測驗程序中,有時候需要使用一些測驗資料,針對這種情況,我們一般要么使用已有的系統資料,要么需要手動制造一些資料,
?在手動制造資料的程序中,可能需要花費大量精力和作業量,現在好了,有一個Python包能夠協助你完成這方面的作業,
1.什么是Faker
?Faker是一個Python包,開源的GITHUB專案,主要用來創建偽資料,使用Faker包,無需再手動生成或者手寫亂數來生成資料,只需要呼叫Faker提供的方法,即可完成資料的生成,
專案地址:https://github.com/joke2k/faker
安裝
pip install Faker
如果下載速度比較慢的話,可以使用國內鏡像源來下載
國內源:
例如:pip3 install -i https://pypi.doubanio.com/simple/ faker
- 清華:https://pypi.tuna.tsinghua.edu.cn/simple
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中國科技大學 https://pypi.mirrors.ustc.edu.cn/simple/
- 華中理工大學:http://pypi.hustunique.com/
- 山東理工大學:http://pypi.sdutlinux.org/
- 豆瓣:http://pypi.douban.com/simple/
基本使用
from faker import Faker
#創建物件,默認生成的資料為為英文,使用zh_CN指定為中文
fake = Faker('zh_CN')
print(fake.name())#隨機生成姓名
print(fake.address())#隨機生成地址
print(fake.phone_number())#隨機生成電話號碼
print(fake.pystr())#隨機生成字串
print(fake.email())#隨機生成郵箱地址
for i in range(10):
print(fake.name())#隨機生成10個姓名
輸出:
徐博
云南省玉市璧山梧州路p座 523028
13039830591
RPHadhNxNMISoBTbQbQn
yili@taogang.net
張淑英
葉燕
陳琳
王俊
胡秀榮
阮淑英
徐娟
黃冬梅
梁麗華
袁琴
常用方法
地理資訊類
- city_suffix():市,縣
- country():國家
- country_code():國家編碼
- district():區
- geo_coordinate():地理坐標
- latitude():地理坐標(緯度)
- longitude():地理坐標(經度)
- postcode():郵編
- province():省份
- address():詳細地址
- street_address():街道地址
- street_name():街道名
- street_suffix():街、路
基礎資訊類
- ssn():生成身份證號
- bs():隨機公司服務名
- company():隨機公司名(長)
- company_prefix():隨機公司名(短)
- company_suffix():公司性質,如‘資訊有限公司’
- fake.credit_card_expire(start=‘now’, end=’+10y’, date_format=’%m/%y’):- - 隨機信用卡到期日如’03/30’
- credit_card_full():生成完整信用卡資訊
- credit_card_number():信用卡號
- credit_card_provider():信用卡型別
- credit_card_security_code():信用卡安全碼
- job():隨機職位
- first_name_female():女性名
- first_name_male():男性名
- name():隨機生成全名
- name_female():男性全名
- name_male():女性全名
- phone_number():隨機生成手機號
- phonenumber_prefix():隨機生成手機號段,如139
郵箱資訊類
- ascii_company_email():隨機ASCII公司郵箱名
- ascii_email():隨機ASCII郵箱:
- company_email():
- email():
- safe_email():安全郵箱
網路基礎資訊類
- domain_name():生成域名
- domain_word():域詞(即,不包含后綴)
- ipv4():隨機IP4地址
- ipv6():隨機IP6地址
- mac_address():隨機MAC地址
- tld():網址域名后綴(.com,.net.cn,等等,不包括.)
- uri():隨機URI地址
- uri_extension():網址檔案后綴
- uri_page():網址檔案(不包含后綴)
- uri_path():網址檔案路徑(不包含檔案名)
- url():隨機URL地址
- user_name():隨機用戶名
- image_url():隨機URL地址
瀏覽器資訊類
- chrome():隨機生成Chrome的瀏覽器user_agent資訊
- firefox():隨機生成FireFox的瀏覽器user_agent資訊
- internet_explorer():隨機生成IE的瀏覽器- user_agent資訊
- opera():隨機生成Opera的瀏覽器user_agent資訊
- safari():隨機生成Safari的瀏覽器user_agent資訊
- linux_platform_token():隨機Linux資訊
- user_agent():隨機user_agent資訊
數字資訊
- numerify():三位亂數字
- random_digit():0~9亂數
- random_digit_not_null():1~9的亂數
- random_int():亂數字,默認0~9999,可以通過設定min,max來設定
- random_number():亂數字,引數digits設定生成的數字位數
- pyfloat():left_digits=5 #生成的整數位數, right_digits=2 #生成的小數位數, - - positive=True #是否只有正數
- pyint():隨機Int數字(參考random_int()引數)
- pydecimal():隨機Decimal數字(參考pyfloat引數)
文本加密類
- pystr():隨機字串
- random_element():隨機字母
- random_letter():隨機字母
- paragraph():隨機生成一個段落
- paragraphs():隨機生成多個段落
- sentence():隨機生成一句話
- sentences():隨機生成多句話,與段落類似
- text():隨機生成一篇文章
- word():隨機生成詞語
- words():隨機生成多個詞語,用法與段落,句子,類似
- binary():隨機生成二進制編碼
- boolean():True/False
- language_code():隨機生成兩位語言編碼
- locale():隨機生成語言/國際 資訊
- md5():隨機生成MD5
- null_boolean():NULL/True/False
- password():隨機生成密碼,可選引數:length:密碼長度;special_chars:是否能使用特殊字符;- - digits:是否包含數字;upper_case:是否包含大寫字母;lower_case:是否包含小寫字母
- sha1():隨機SHA1
- sha256():隨機SHA256
- uuid4():隨機UUID
時間資訊類
- date():隨機日期
- date_between():隨機生成指定范圍內日期,引數:start_date,end_date
- date_between_dates():隨機生成指定范圍內日期,用法同上
- date_object():隨機生產從1970-1-1到指定日期的隨機日期,
- date_time():隨機生成指定時間(1970年1月1日至今)
- date_time_ad():生成公元1年到現在的隨機時間
- date_time_between():用法同dates
- future_date():未來日期
- future_datetime():未來時間
- month():隨機月份
- month_name():隨機月份(英文)
- past_date():隨機生成已經過去的日期
- past_datetime():隨機生成已經過去的時間
- time():隨機24小時時間
- timedelta():隨機獲取時間差
- time_object():隨機24小時時間,time物件
- time_series():隨機TimeSeries物件
- timezone():隨機時區
- unix_time():隨機Unix時間
- year():隨機年份
發送郵箱件模塊
- 發送郵件,我們在平時作業中經用到,做為測驗人員,在自動化測驗中用的也比較多,需要發送郵件給某領導
- SMTP是Python默認的郵件模塊,可以發送純文本、富文本、HTML 等格式的郵件
發送郵件步驟

郵件發送前的準備作業
- 開啟郵箱SMTP服務和獲取授權碼
- 登錄 QQ 郵箱為例,我們需要開啟 SMTP 服務,登錄郵箱依次點擊設定-賬戶
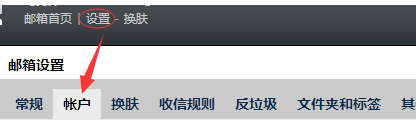
開啟SMTP

生成授權碼
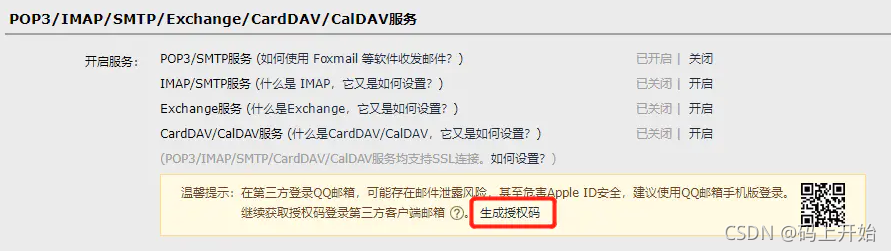
注:
需要開啟POP3/SMTP服務
授權碼做為郵箱密碼
方式一:smtplib(不推薦使用)
- smtplib是 Python 自帶的依賴庫,可以直接匯入使用,通過郵箱賬號、授權碼、郵箱服務器地址初始化一個 SMTP 實體,然后進行連接,初學者感覺這個會挺復雜,請繼續往下看
方式二:zmail
-
由于SMPT太過于麻煩復雜,所以就用zamil發送郵件試試,
-
zmail模塊只支持Python3模塊,該模塊為第3方模塊,需自行安裝(pip install zmail)
-
使用 Zmail 發送接收郵件方便快捷,不需手動添加服務器地址、埠以及適合的協議,可以輕松創建 MIME 物件和頭檔案
-
注意:Zmail 僅支持 Python3,不支持 Python2
#!/usr/bin/python3
import zmail
def send_mail():
# 定義郵件
mail = {"subject": "介面測驗報告",# 任一填寫
'content_text': '手機號歸屬地_API自動化測驗報告',# 任一填寫
# 多個附件使用串列
"attachments": "E:/report/result.html"
}
# 自定義服務器
server = zmail.server("發送人郵箱.com",
"QQ郵箱是用授權碼",
smtp_host="smtp.qq.com",
smtp_port = 465)
# 發送郵件
server.send_mail("收件人QQ郵箱", mail)
try:
send_mail()
except FileNotFoundError:
print("未找到檔案")
else:
print("發送成功")
方式三:yagmail
-
他們都說yagmail 只需要三行代碼,就可以實作發送郵件,爽歪歪!
-
相比 zmail,yagmail 實作發送郵件的方式更加簡潔優雅
-
首先,安裝依賴庫(pip install yagmail)
發送郵件有三個步驟:
1、連接服器(類似你先要登錄郵箱)
2、編輯郵件內容和主題
3、發送郵件
#!/usr/bin/python3
import yagmail
# 定義用戶名、授權碼、服務器地址且連接服務器
mail_server = yagmail.SMTP(user='發件人郵箱', passwd='授權碼', host='smtp.qq.com')
# 發送物件串列
Email_to = ['收件人郵箱']
subject = '任一填寫'
Email_text = "任一填寫內容"
# 多個附件用逗號隔開
attachments = ['html報告目錄地址']
# 發送郵件
mail_server.send(Email_to, subject, Email_text, attachments)
POM設計模型
?Page Object Model (POM) 直譯為“頁面物件模型”,這種設計模式旨在為每個待測驗的頁面創建一個頁面物件(class),將那些繁瑣的定位操作封裝到這個頁面物件中,只對外提供必要的操作介面,是一種封裝思想,
POM優勢有哪些
- 讓UI自動化更早介入專案中,可專案開發完再進行元素定位的適配與除錯
- POM 將頁面元素定位和業務操作流程分開,分離了測驗物件和測驗腳本
- 如果UI頁面元素更改,測驗腳本不需要更改,只需要更改頁面物件中的某些代碼就可以
- POM能讓我們的測驗代碼變得可讀性更好,高可維護性,高復用性
- 可多人共同維護開發腳本,利于團隊協作
為什么使用POM設計模式
- 少數的自動化測驗用例維護起來看起來是很容易的,但隨著時間的遷移,測驗套件將持續的增長,腳本也將變得越來越臃腫龐大,
- 如果變成我們需要維護10個頁面,100個頁面,甚至1000個呢?而且頁面元素很多是公用的,那頁面元素的任何改變都會讓我們的腳本維護變得繁瑣復雜,而且變得耗時易出錯,
如何設計POM
思路決議
- 需要一個檔案用于管理頁面元素,如login_page.py
- 封裝一個公用的操作方法
- 最后需要一個檔案用于撰寫測驗用例
login_page.py檔案
- 該檔案用于管理登錄頁面所有的元素,操作這些元素的方法
#! /usr/bin/python3
#-*- coding:utf-8 -*-
'''管理登錄頁面所有的元素,操作這些元素的方法'''
from selenium.webdriver.common.by import By
class LoginPage:
username_input = (By.XPATH,'//*[@id="name"]') #登錄頁面的用戶名輸入框
password_input = (By.XPATH,'//*[@id="password"]') #登錄頁面的密碼輸入框
login_button = (By.XPATH,'//*[@id="submit"]') #登錄按鈕
common.py
- 該檔案有用于封裝一些共用的操作方法
#! /usr/bin/python3
#-*- coding:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
'''封裝一些常用公共方法'''
class InitBrowser():
'''瀏覽器常用操作封裝'''
def __init__(self):
self.driver = webdriver.Firefox() # 啟動谷歌瀏覽器
self.driver.get('https://sso.kuaidi100.com/sso/authorize.do') # 打開網站
def wait_element_visible(self, locate):
ele = WebDriverWait(self.driver, 10).until(EC.visibility_of_element_located(locate)) #等待元素出現再去操作
print('等待元素出現')
return ele
def click_until_visible(self, locate):
self.wait_element_visible(locate).click()
def send_keys_until_visible(self, locate, value):
self.wait_element_visible(locate).send_keys(value)
TestCase.py
- 該檔案用于管理測驗用例
#! /usr/bin/python3
#-*- coding:utf-8 -*-
'''管理測驗用例'''
import unittest
from common import InitBrowser
# 匯入Pages檔案下的login_page檔案中的LoginPage類
from Pages.login_page import LoginPage
class TestCases(unittest.TestCase, InitBrowser, LoginPage):
def setUp(self) -> None:
'''前置操作初始化:打開瀏覽器,連接資料庫,初始化資料'''
InitBrowser.__init__(self)
def testcase01(self):
'''測驗用例'''
self.send_keys_until_visible(LoginPage.username_input, "賬號")
self.send_keys_until_visible(LoginPage.password_input, "密碼")
self.click_until_visible(LoginPage.login_button)
def tearDown(self) -> None:
'''后置操作:關閉瀏覽器,關閉資料庫連接,清理測驗資料'''
self.driver.quit()
if __name__=='__main__':
unittest.main()
總結
- 當我們再次使用登錄時,只需要修改login_page.py里的定位元素方法和值就可以了
- 以上代碼當然還有很多不足的地方,比如賬號密碼沒有提出來,小伙伴可自行嘗試
Python操作Excel
| id | url | boke |
|---|---|---|
| 1 | https://blog.csdn.net/laozhu_Python | 騎著烏龜找豬 |
| 2 | https://www.cnblogs.com/zzpython | 碼上開始 |
需求分析
- 方便讀取資料,將每一行資料結合標題生成字典:{“id”: 1, “url”: “https://blog.csdn.net/laozhu_Pythonrl”, “boke”: “騎著烏龜找豬”}
- 然后將生成的資料存放在一個串列中[{“id”: 1, “url”: “https://blog.csdn.net/laozhu_Pythonrl”, “boke”: “騎著烏龜找豬”}]
操作流程
-
處理一個表格,首先要知道路徑,所以我們需要知道檔案路徑然后打開這張表
#! /usr/bin/python3 # @Time : 2020/8/5 13:30 # @Author : 碼上開始 import xlrd # 定義檔案路徑 path = "E:/data.xls" # 然后打開一個表 data = xlrd.open_workbook(path) -
打開表之后,通過獲取表對像來操作這個表,相當于我們用滑鼠選中這個Sheet1就能操作這個表里內容了,明白了嗎?
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-B6qQlNjD-1596861991692)(C:\Users\zhuzhichao\AppData\Roaming\Typora\typora-user-images\image-20200808095941112.png)]](https://img.uj5u.com/2021/09/09/2630570912231033.png)
#! /usr/bin/python3
# @Author : 碼上開始
import xlrd
# 定義檔案路徑
path = "E:/data.xls"
# 然后打開一個表
data = xlrd.open_workbook(path)
# 通過表名獲取表物件,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
- 獲取表對像后,我們需要這個表格行和列數,才方便查找資料
#! /usr/bin/python3
# @Author : 碼上開始
import xlrd
# 打開需要操作的表
path = "E:/data.xls"
data = xlrd.open_workbook(path)
# 通過下標獲取表物件,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
# 列數
cols = sheet1.ncols
# 行數
rows = sheet1.nrows
- id/url/boke我們每一行資料都需要用這個,所以我們需要提出來進行回圈操作
#! /usr/bin/python3
# @Author : 碼上開始
import xlrd
# 打開需要操作的表
path = "E:/data.xls"
data = xlrd.open_workbook(path)
# 通過下標獲取表物件,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
# 列數
cols = sheet1.ncols
# 行數
rows = sheet1.nrows
# 定義空串列和字典用于存放資料
list = [ ]
# 獲取第一行的值
one_value = sheet1.row_values(0)
# 通過列印來檢查是不是獲取到表里第一行的值
print(one_value)
完整 代碼
#! /usr/bin/python3
# @Author : 碼上開始
import xlrd
# 打開需要操作的表
path = "E:/data.xls"
data = xlrd.open_workbook(path)
# 通過下標獲取表物件,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
# 列數
cols = sheet1.ncols
# 行數
rows = sheet1.nrows
# 定義空串列和字典用于存放資料
list = [ ]
# 獲取第一行的值
one_value = sheet1.row_values(0)
# 列印結果是:["id", "url", "boke"]
print(one_value)
# 代碼最重要的一段
# 外回圈行數(我們從excel表里第2行開始,即下標從1開始,括號里即(1, 3)總回圈次數兩次
for i in range(1, rows):
# 定義一個字典存放每一行的資料
dict = { }
# 列的資料則是從0開始(就是第1列)結束是我們或取的列值即:(0, 3)
for y in range(0, cols):
# 第一次回圈字典是這樣寫入的:dict["id"] = 1
# 然后依次把數字套進去
dict[one_value[y]] = sheet1.row_values(i)[y]
# 然后將字典資料存放在串列中
list.append(dict)
print(list)
運行結果
[{'id': '1', 'url': 'https://blog.csdn.net/laozhu_Python', 'boke': '騎著烏龜找豬'}, {'id': '2', 'url': 'https://www.cnblogs.com/zzpython/', 'boke': '碼上開始'}]
file檔案操作
?實際作業中,我們經常需要用Python讀取文txt檔案中的資料. 我們使用open()函式來打開一個檔案, 獲取到檔案句柄. 然后通過檔案句柄就可以進行各種各樣的操作了. 根據打開方式的不同能夠執行的操作也會有相應的差異
常用的檔案操作模式
- 打開檔案的方式: r, w, a, r+, w+, a+, rb, wb, ab, r+b, w+b, a+b 默認使用的是r(只讀)模式
只讀(r, rb)
#! /usr/bin/python3
# @公眾號 : 碼上開始
file = open("E:\\study\\good.txt", "r", encoding="utf-8")
line = file.read()
print(line)
# open模式打開檔案一定要記得關閉操作
file.close()
# 運行結果
好好學習
公眾號:碼上開始
- read() 將檔案中的內容全部讀取出來. 弊端: 占記憶體. 如果檔案過大.容易導致記憶體崩潰
- 需要注意encoding表示編碼集. 根據檔案的實際保存編碼進行獲取資料, 對于我們而言. 更多的是utf-8
- rb. 讀取出來的資料是bytes型別, 在rb模式下. 不能選擇encoding字符集
只寫(w, wb)
- 寫的時候注意. 如果沒有檔案. 則會創建檔案
- 如果檔案存在. 則將原件中原來的內容洗掉, 再寫入新內容
#! /usr/bin/python3
# @公眾號 : 碼上開始
f = open("study.txt", mode="w", encoding="utf-8")
f.write("好好學習Python")
# 重繪. 養成好習慣
f.flush()
f.close()
r+ 讀寫
- 對于讀寫模式. 必須是先讀. 因為默認游標是在開頭的. 準備讀取的. 當讀完了之后再進行
寫入. 我們以后使用頻率最?的模式就是r+ - 所以記住: r+模式下. 必須是先讀取. 然后再寫入
#! /usr/bin/python3
# @公眾號 : 碼上開始
file = open("study.txt", mode="r+", encoding="utf-8")
# 先讀取
content = file.read()
# 再寫入
file.write("好好學, 天天向上")
print(content)
# 重繪. 養成好習慣
f.flush()
file.close()
# 運行結果
好好學, 天天向上
a+寫讀(追加寫讀)
- 打開一個檔案用于讀寫,如果該檔案已存在,檔案指標將會放在檔案的結尾,檔案打開時會是追加模式,如果該檔案不存在,創建新檔案用于讀寫,
- 檔案指標將會放在檔案的結尾所以該示例找不到內容,列印沒任何結果
#! /usr/bin/python3
# @公眾號 : 碼上開始
file = open("study.txt", mode="a+", encoding="utf-8")
# 先讀取
content = file.read()
# 再寫入
file.write("好好學習")
file.write("天天向上")
# 重繪. 養成好習慣
f.flush()
print(file.readline())
file.close()
安裝第3方庫
學Python的小伙伴都知道,Python學習程序中需要裝不少的第3方的庫,今天就和大家一起分享下第3方庫的安裝方法
在線安裝(推薦安裝方式)
- 點開Pycharm–file–Project–選擇Project Interpreter
通過Terminal安裝(Pycharm版本為社區版,版本不同可能存在位置差異,請查行查找)
- Python目錄安裝
打開安裝目錄–右鍵空白處–選擇powershell輸入–pip install xlwrd–回車
等待完裝完畢
離線安裝方式
在線安裝模式經常會出現安裝失敗的情況,這時候可以進行離線安裝方式
有時候在線安裝第三方模塊的時,會因為網路原因總是裝不上,那怎么辦呢?那就手動安裝
- 下載所需要的模塊包(離線安裝出現的機率相對較少所以基本可以忽略,大家知道有這種方式就可以)
- 解壓該檔案
- 將檔案名改短,然后放入非C盤且放在根目錄
- 打開cmd---->E:---->cd xlrd---->python setup.py install
- 等待完裝完畢
- 匯入模塊 import xlrd,運行如果沒報錯就說明安裝正常
Web自動化瀏覽器和驅動的解決辦法
??在我學習Ui自動化時,總會遇到瀏覽器驅動版本問題,小伙伴也是一頭霧水也找不到下載的地方,今天給大家整理
| chromedriver版本 | 支持的chrome版本 |
|---|---|
| v2.46 | v72-74 |
| v2.45 | v70-72 |
| v2.44 | v69-71 |
| v2.43 | v69-71 |
| v2.42 | v68-70 |
| v2.41 | v67-69 |
| v2.40 | v66-68 |
| v2.39 | v66-68 |
| v2.38 | v65-67 |
| v2.37 | v64-66 |
| v2.36 | v63-65 |
| v2.35 | v62-64 |
| v2.34 | v61-63 |
| v2.33 | v60-62 |
| v2.32 | v59-61 |
| v2.31 | v58-60 |
| v2.30 | v58-60 |
==============================================================================
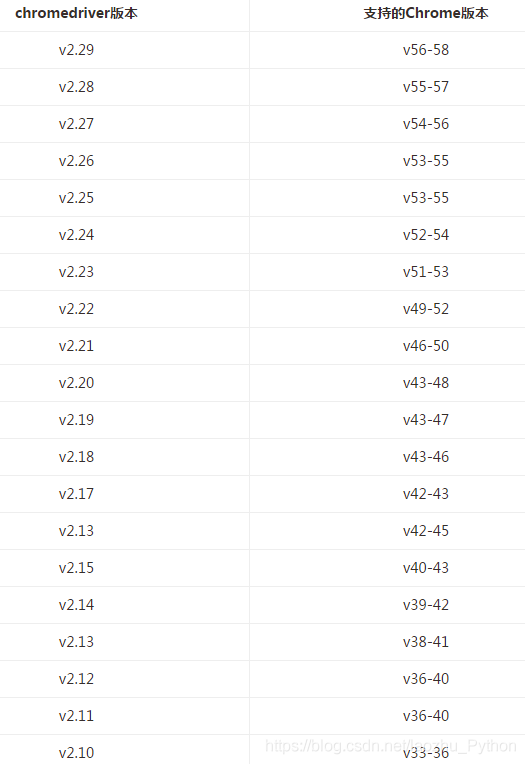
谷歌瀏覽器驅動版本對應以及下載:
- 點擊下載chrome的webdriver:http://chromedriver.storage.googleapis.com/index.html
- 點擊下載chrome的歷史版本:https://www.chromedownloads.net/
- 點擊進入谷歌官方版本對應頁面:https://sites.google.com/a/chromium.org/chromedriver/downloads
edge瀏覽器驅動版本對應以及下載:
點擊進入微軟edge瀏覽器wendriver版
- 本對應下載頁面:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/#downloads
ie瀏覽器驅動官方地址:
- 點擊進入ie瀏覽器driver下載:http://selenium-release.storage.googleapis.com/index.html
- 點擊進入ie瀏覽器官方github:https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver
safari瀏覽器官方地址:
- 點擊進入safari瀏覽器官方地址:https://developer.apple.com/safari/download/
分享Python自學歷程
??其實關于編程這事兒沒有接觸的那么早,大一的時候沒什么關注點,有一門課是vb,一天天的,就抄抄作業啥的就完事兒了,當時也覺的自己不是學編程的料,想著以后估摸也不會干開發相關的作業,

我的自學歷程
- 陰差陽錯的進入到了軟體測驗行業,入行比較早,懵懵懂懂,也沒想著會學習編程,總覺的自己不是覺這塊的料,后來因為專案的一些需求,慢慢接觸了編程.
三人行必有我師
-
為什么是名師指路,因為確實需要老師來指點你的學習,關于這個老師,沒有一個確切的點,父母可為師,同學也可以為師,甚至比自己年紀小、資歷少的人也可以為師,
-
重要的是在我們迷茫的時候有一個人帶來幫助和指點,所以我覺得,這一點是無比重要的,我們需要的是方向,而不是事事都給你解決掉的人,就好像是父親,他會給你指明方向,會罵你,但是不管如何都不會替你做你應該做的事
愛上學習
-
其實這件事對于我來說是順其自然的,由于我個人沒有那么衰,相信在此的各位也都是積極向上的,愛上學習這件事是很容易的,尤其是最近疫情期間在家一直躺到想起床學習,
-
最重要的,是我們要正視學習和娛樂,我們所謂的放松不是打一把游戲就算了,要知道職業選手一天要打十幾個小時的游戲,換成我們這些普通人同樣也hold不住,所以學習同樣是一種放松,正確的看待游戲和學習
-
在這里我覺得很有必要的是要有求知欲,這不是說我想有就能有的,這真的是要自己去探索,有一張圖很好,貼在這里一下,做一個分享

樂于分享
??大概自學的同學,都是看視頻或著看博客來學的,總會感覺到講師有多么的厲害,其實這最能體現的就是,把一個東西教給別人的時候,能學習到更多的東西,能夠檢查自己學習是否全面,是否掌握,這個時候,不僅他人能夠受益,自己識訓也會很大,要樂于把自己學會的東西分享出去,有了反饋之后一定會有不一樣的感受
一起學習
??自學最大挑戰,就是堅持不下去,所以,可以找同學一起學習,當然,也可以發帖找人一起打卡,每天分享心得,這樣,有了反饋,有人一起,學習的效率就會更高,當然也就會更優秀,聽過一句話,一個人可以走的很快,一群人會走的很遠,找個伙伴可能會體會到不一樣的感覺,奧利給!!!
說在最后
??其實學習這件事很容易,不局限于編程,學習是一件持久的事情,從始至終,有句話說得好,“知之者不如好之者,好之者不如樂之者”,我們要愛上學習,

表白python
??作為一名軟體測驗工程師,我是很喜歡Python的,每當解決了作業中的問題,會覺的很高興,幫助我實作了我想要的功能,大大提高了我的作業效率,
??撰寫代碼時的優雅是無與倫比的,我喜歡他那多樣化的撰寫方式,深深地使我折服,那流暢的語言,是你與計算機獨特的交流方式,和計算機共同構建著這獨一無二的藝術品,外部功能的完善,內部代碼的優雅,巧奪天工都不足以來形容,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/298671.html
標籤:python