目錄指引:
- 前言:
- 鏈表的概念及結構
- 單鏈表的實作
- 一、實作鏈表的函式操作
- 1、實作鏈表的列印函式
- 2、實作得到單鏈表的長度函式
- 3、查找是否包含關鍵字key是否在單鏈表當中
- 4、鏈表頭插法
- 5、鏈表尾插法
- 6、任意位置插入,第一個資料節點為0號下標
- 7、洗掉指定的節點
- 8、洗掉全部指定的節點
- 9、清空全部節點
- 二、鏈表的面試題
- 1.反轉一個單鏈表,
- 2.回傳中間節點,有2個回傳第二個中間的節點
- 3.輸入一個鏈表,輸出該鏈表中倒數第k個結點,
- 4.合并兩個有序鏈表,
- 5.以給定值x為基準將鏈表分割成兩部分,所有小于x的結點排在大于或等于x的結點之前
- 6.在一個排序的鏈表中,存在重復的結點,請洗掉該鏈表中重復的結點,重復的結點不保留,回傳鏈表頭指標,
- 7.鏈表的回文結構,
- 8.給定一個鏈表,判斷鏈表中是否有環,
- 9. 給定一個鏈表,回傳鏈表開始入環的第一個節點, 如果鏈表無環,則回傳 null
- 10. 輸入兩個鏈表,找出它們的第一個公共結點
- 三、面試經常問到的問題:
- 雙向鏈表的認識:
- 一、實作鏈表的函式操作
- 1.雙向鏈表的頭插法
- 2.雙向鏈表的尾插法
- 3.任意位置插入,第一個資料節點為0號下標
- 4.洗掉第一次出現關鍵字為key的節點
- 5.洗掉所有值為key的節點
前言:
(溫馨提示:)本文字數比較多需要慢慢觀看,建議收藏此文有時間慢慢觀看,看完此文你會學習到什么是鏈表,什么是雙向鏈表,單鏈表的增刪查改的基本代碼思路和在線OJ題的基本代碼思路,

鏈表的概念及結構
鏈表是一種物理存盤結構上非連續存盤結構,資料元素的邏輯順序是通過鏈表中的參考鏈接次序實作的,
什么意思呢?
我們都知道順序表是一組陣列,在邏輯上,物理上都是連續的
但是鏈表在邏輯上是連續的,但是在 物理上不一定連續(記憶體可能連續,可能不連續)
像發哥的金鏈子一樣,后面接著前面串起來,

實際中鏈表的結構非常多樣,以下情況組合起來就有8種鏈表結構:
- 單向、雙向
- 帶頭、不帶頭
- 回圈、非回圈
雖然有這么多的鏈表的結構,但是我們重點掌握兩種:
-
無頭單向非回圈鏈表:結構簡單,一般不會單獨用來存資料,實際中更多是作為其他資料結構的子結構,如 哈希桶、圖的鄰接表等等,另外這種結構在筆試面試中出現很多,
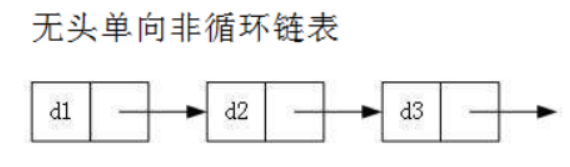
-
無頭雙向鏈表:在Java的集合框架庫中LinkedList底層實作就是無頭雙向回圈鏈表
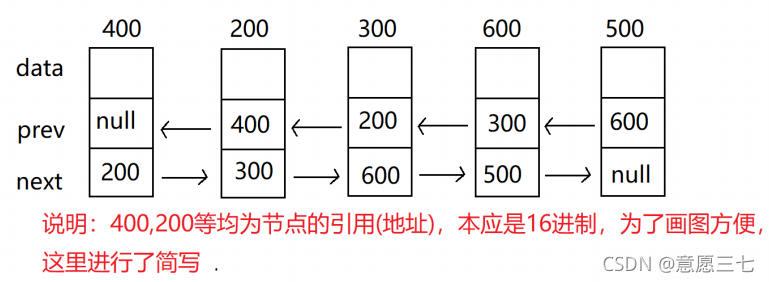
來使用人話說一下什么是鏈表吧:

大家都吃過糖葫蘆,葫蘆都是一個接著一個的,長下面這樣
那鏈表呢?
鏈表是由一個一個 節點構成的 ,每一個節點有兩個域一個叫做數值域,一個叫做next域
data:數值域 里面存盤的是資料
next:參考變數 - 存下一個節點的地址
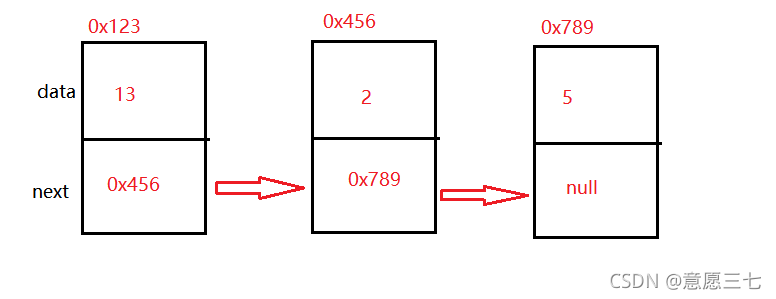
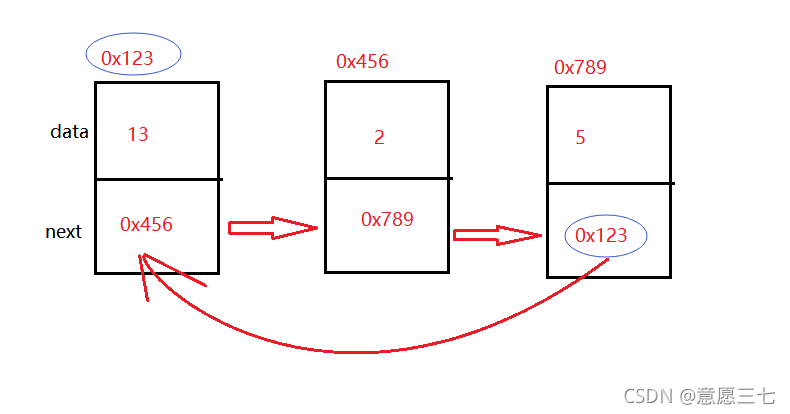
上面的話用下面的圖來展示:
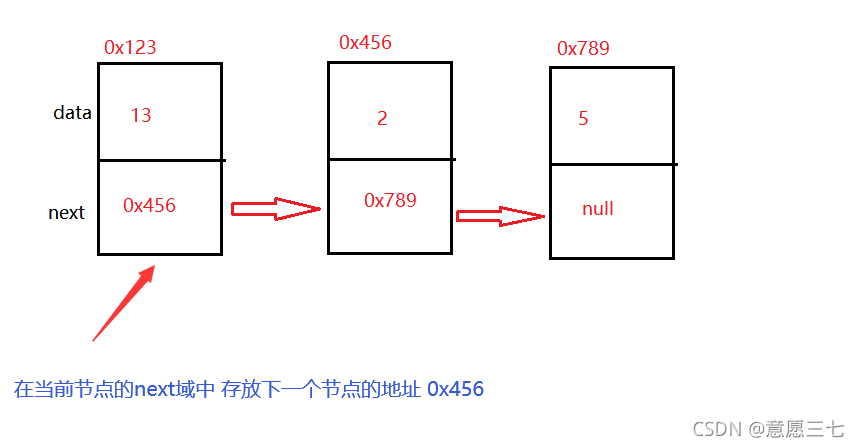
從上圖發現當前節點的next域存放的都是下一個節點的地址
那么最后那個沒有存放下一個的地址叫做什么呢?
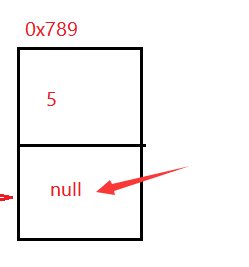
其實這個叫做尾巴節點:當這個next節點域為null的時候
有尾巴節點還會有頭節點:整個鏈表當中的第一個節點叫做頭節點
我們剛剛寫的下面這個就是 不帶頭非回圈的單鏈表
那么就有人會說了,你剛付訓說上面的這個是頭結點啊!!!,怎么說不是帶頭的呢?? 請聽我慢慢道來:

區分帶頭不帶頭,我給你畫個圖就知道了:
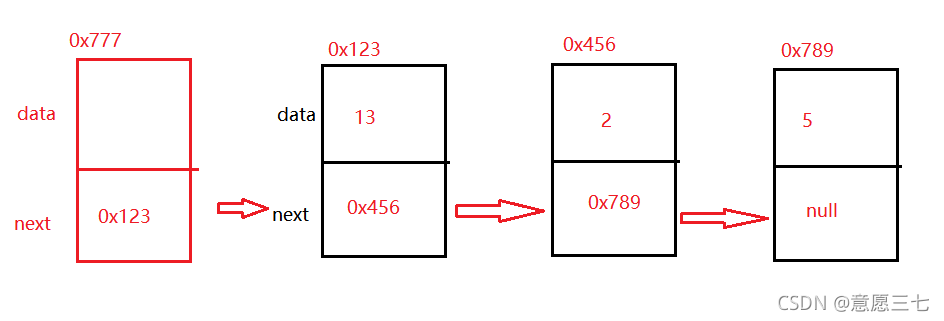
紅色的那個就是頭節點:它里面可以存放一個無效的data,
帶頭:其實就是標識當前鏈表的頭
- 如果不帶頭:這個鏈表的頭節點,在隨時發生改變,
- 如果帶頭:這個鏈表的頭節點不會發生改變,
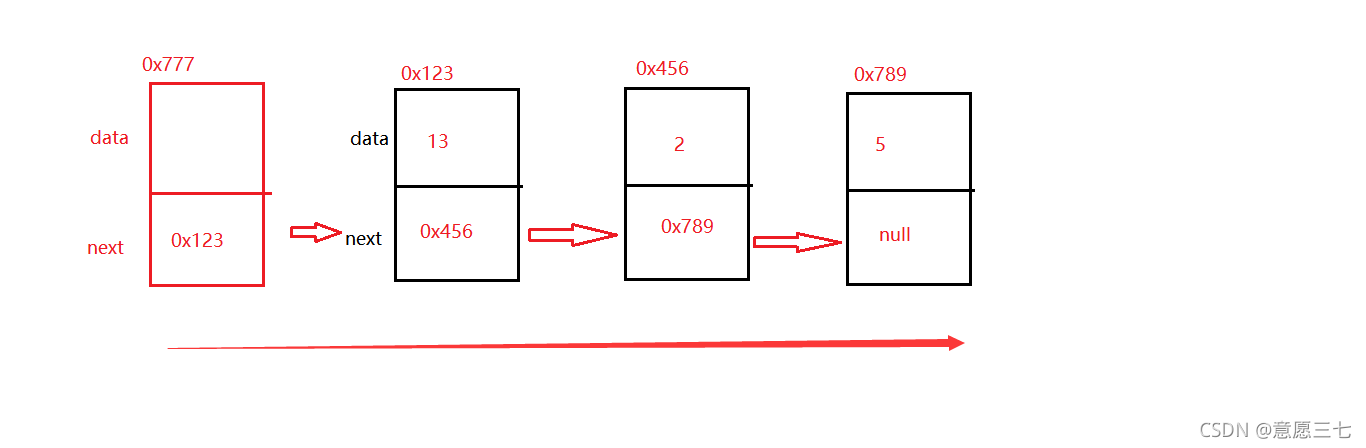
啥是單向?? 往一個方向走就是單向
下圖為:單向帶頭非回圈
什么是回圈的:最后一個節點的next域參考 第一個節點的地址 ,必須是第一個,不可以是第二個,不然不叫回圈了
單向 不帶頭 回圈 【下面的圖】
單鏈表的實作
上面知道了鏈表大概是什么意思,現在我們準備使用代碼來實作一下:
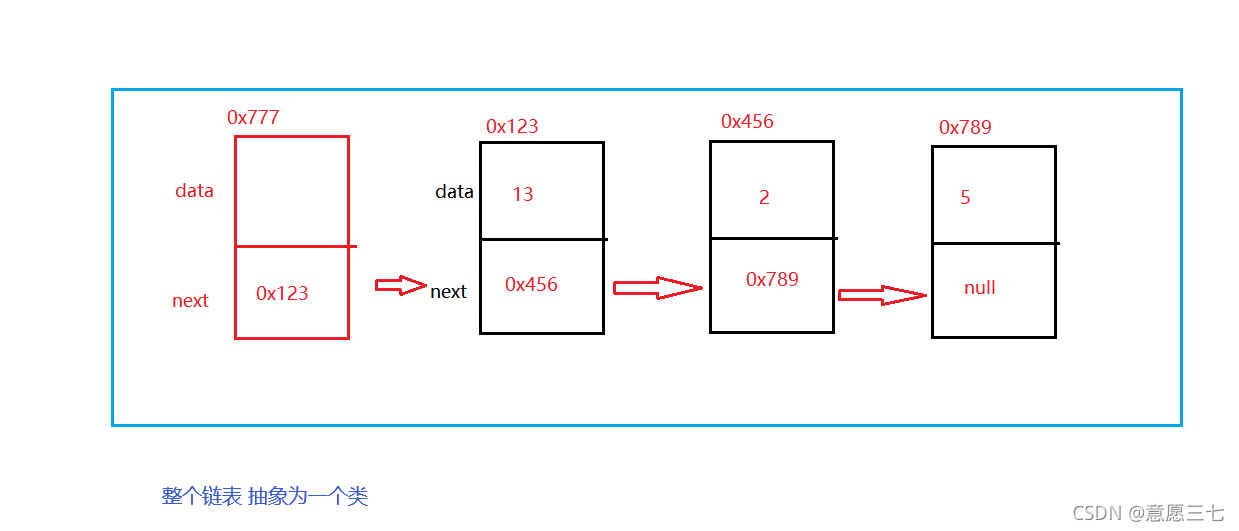
我們把整鏈表抽象為一個類:
把節點抽象為一個類:這個類里面包含data 欄位 和next欄位
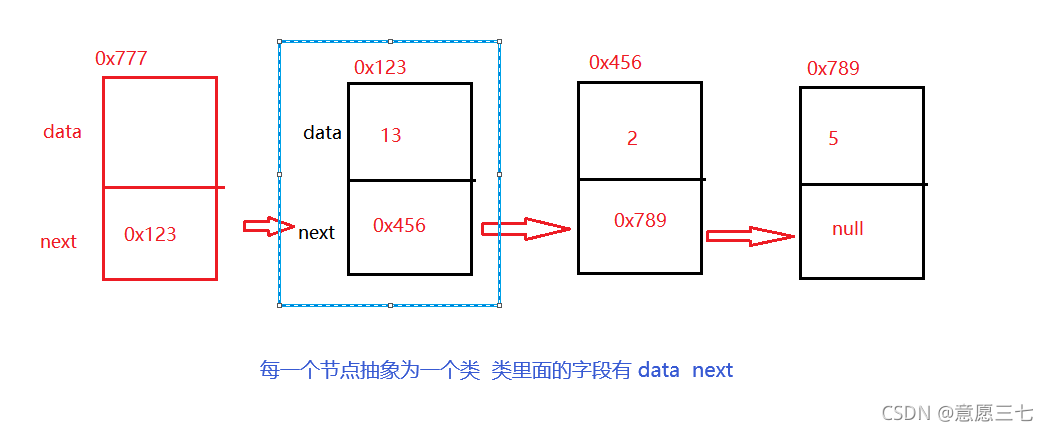
代碼如下:(為了方便 這些類就寫到一個class檔案里面)
先抽象出來節點類:

下面是解釋:
為什么要給data搞個構造方法,因為如果不設定,那么我們不知道節點的next域要存什么地址,為什么不給next賦值呢? 因為next 是一個參考型別,默認是null,這就是我們的節點類 ,
而且當我們實體化物件也發方便:
Node node = new Node(5);
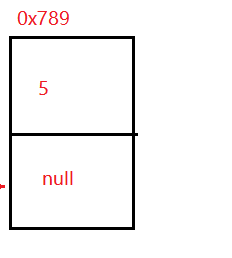

在抽象出來整個鏈表的類:
對于鏈表,我們還需要一個屬性 head,
這東西是一個參考,指向當前鏈表的頭
因為當前是不帶頭的,頭一直發生改變
要一個來一直標識單鏈表的頭結點

接下來我要使用一種窮舉的方式創建一個鏈表,為什么說這句話, 我怕你們說我low
代碼如下:創建一個鏈表

上面代碼什么意思呢?看我慢慢道來:
我們知道鏈表是 當前節點后面跟著一個節點
node1.next = node2;
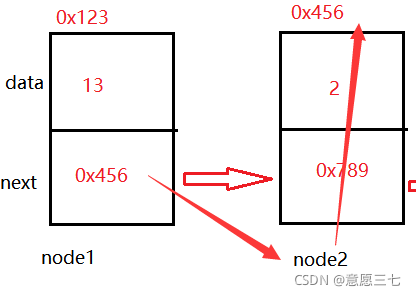
可以看見node2的地址是0x456 ,所以為了成為鏈表node1的next要被node2賦值,這樣才是一個鏈表,
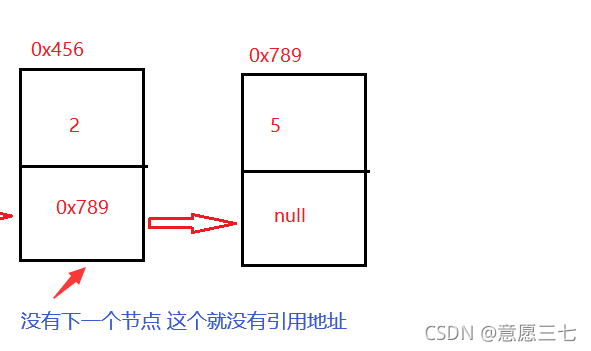
node2.next = node3; 原理也是一樣,只不過是我們的node3 沒有參考,因為它是最后一個節點,后面沒有下一個節點了,而且它是參考型別默認就是null了,所以不需要寫node3的代碼,
this.head = node1;
目前的頭是node1 ,使用head指向node1所指的物件,13就是head
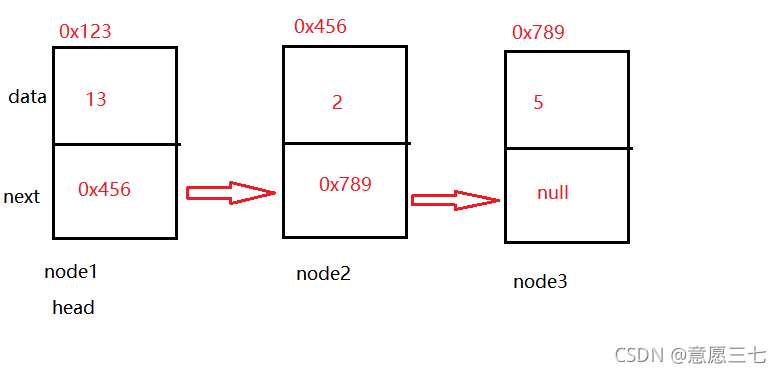
MyLinkedList 全部代碼:
//節點類
class Node{
public int data; //資料域
public Node next; //參考型別
public Node(int data){
this.data = data;
}
}
//鏈表
public class MyLinkedList {
public Node head; //標識單鏈表的頭節點
//窮舉的方式創建鏈表 當然有點low ,此處為了好理解
public void createList(){ //創建鏈表
Node node1 = new Node(13);
Node node2 = new Node(2);
Node node3 = new Node(5);
node1.next =node2;
node2.next =node3;
this.head = node1;
}
}
一、實作鏈表的函式操作
1、實作鏈表的列印函式
如果head不等于null,那么就列印資料,然后讓當前head,等于下一個head.next
public void show(){ //列印鏈表
while(this.head!=null){
System.out.print(this.head.data+" ");
this.head=this.head.next;
}
}
那為什么不可以head.next !=null
因為head.next 等于空那么最后一個資料就沒有列印出來了
不過由此可以推出:
如果把整個鏈表 遍歷完成 那么head==null
如果只是想找到鏈表最后一個節點 那么head.next==null
但是大家發現一個問題了沒,就是head一直在動,那么head又沒有意義了,不是頭節點,所以要一個小弟來代替它,我們把代碼優化一下,定義了一個小弟:
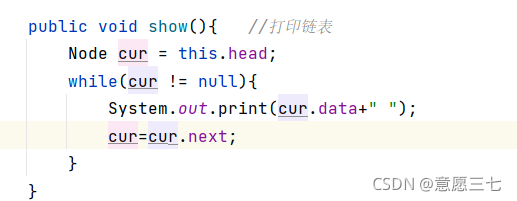
這就是比較完善的代碼了
2、實作得到單鏈表的長度函式
原理很簡單讓cur一直遍歷,如果cur不等于空 ,count++就好啦
public int size(){ //求Node 長度
Node cur =this.head;
int count =0 ;
while(cur!=null){
count++;
cur=cur.next;
}
return count;
}
3、查找是否包含關鍵字key是否在單鏈表當中
原理很簡單讓cur一直遍歷,如果cur的data 等key 就return true
public boolean contains(int key){//查找是否包含關鍵字key是否在單鏈表當中
Node cur= this.head;
while (cur!=null){
if (cur.data == key){
return true;
}
cur = cur.next;
}
return false;
}
4、鏈表頭插法
什么叫做頭插法:
一個新節點,要插到第一個節點前面:把14這個節點插到最前面去,next是下一個結點的地址,head 要改變成為新的node
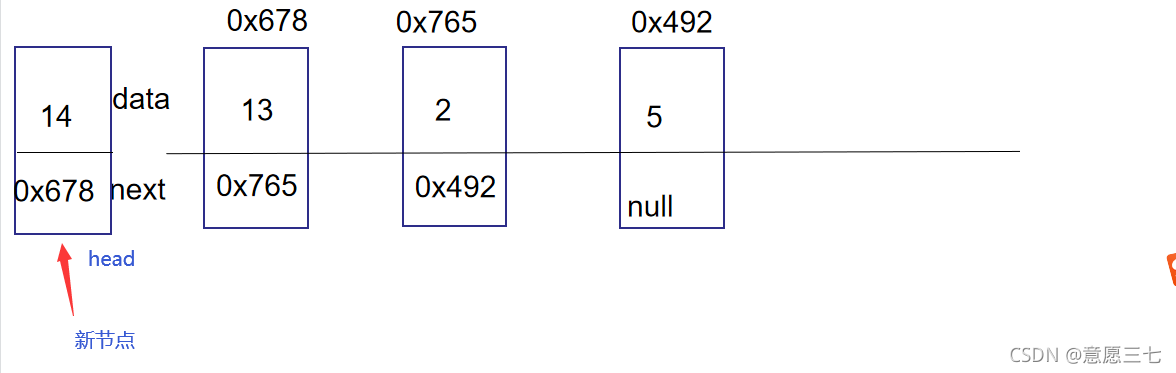
上面所說可以將代碼這樣寫:
node.next =head;
head = node;
這樣第一個14的next域就是下一個元素了
然后在把head參考node;
但是我們不可以
head = node;
node.next =head;
把他們順序顛倒
這樣變成自己參考自己了: 所以在插入一個節點的時候,一定要先綁后面
還有一個情況就是head是null,當前鏈表沒有任何結點,插入的是第一個節點
那么代碼直接: head = node;
public void addFirst(int data){
Node node = new Node(data);
node.next = this.head;
this.head = node;
}
可以使用頭插法加資料,不需要使用以前的窮舉了
因為是頭插法最后一個后插入到第一個去,所以列印是 5 3 1
5、鏈表尾插法
什么叫做尾插法:
一個新節點,要插到最后節點后面:
邏輯實作:找到最后一個節點,然后把最后節點的next域變成新節點的地址,在上面我們說過,想找最后一個節點,只需要判斷head.next == null,就是尾節點了
代碼的實作:
public void addLast(int data){ //尾插法
Node node = new Node(data); //新節點
if (this.head ==null){ //如果是head是null 那么是第一次 直接 head = node
this.head = node;
}else{
Node cur = this.head; //定義一個cur 代替當做head
while (cur.next!=null){ //找到最后一個節點
cur = cur.next; //如果不是最后節點 一直往后走
}
cur.next =node; //當前節點的next 域指向 新節點
}
}
6、任意位置插入,第一個資料節點為0號下標
什么意思呢? 我們需要把新的節點 插入目標節點的后面(下面的紅色是新節點)
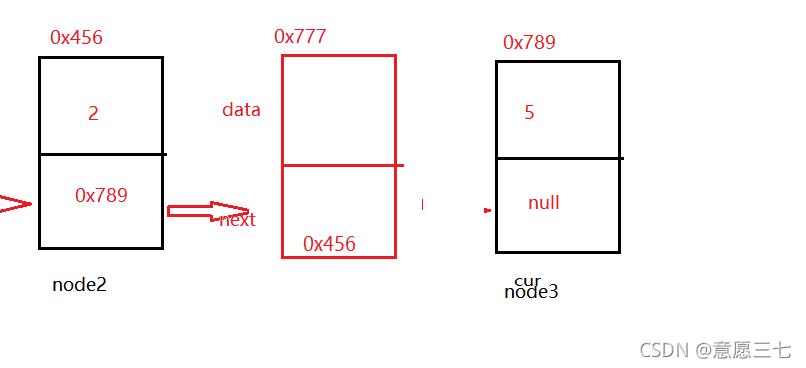
具體實作思路:
如果想實作變成鏈表,我們必須得把 當前節點的next域 變成 后面一個節點的地址
然后把前一個的next域 變成 新節點的地址,這就是 核心思路!!
我們先把代碼放出來,依次決議:
public Node searchPrev(int index){
Node cur = this.head;
int count = 0;
while (count != index -1){ //給個條件 找到前一個就退出
cur = cur.next; //繼續找的條件
count++;
}
return cur; // 回傳前面的一個
}
public void addIndex(int index , int data){ //任意位置插入,第一個資料節點為0號下標
if(index<0 || index >size() ){ //判斷需要放入的位置是否合法
System.out.println("下標不合法");
return;
}
//頭插法
if(index == 0){
addFirst(data);
}
//尾插法
if (index ==size()){
addLast(data);
}
Node cur= searchPrev(index);
//新節點的插入 核心代碼
Node node = new Node(data);
node.next = cur.next;
cur.next =node;
}
大家可以看見上面有 兩個方法,我們先來看一下searchPrev() 這個函式
searchPrev(): 找到需要插入的前一個節點的方法;
為什么需要這個方法呢?
因為我們的這個鏈表不是回圈的鏈表,如果我們找到的不是插入的前一個節點,那么我們就不知道前一個節點的next域是多少,因此不成立鏈表的實作,所以不可以,
好了現在來決議一下這個searchPrev()函式:
public Node searchPrev(int index){ //需要插入的下標
Node cur = this.head; //定義一個cur 代替head
int count = 0; //計數
while (count != index -1){
//給個條件 count不等于index-1 就進入,換句話說就是找到index-1 就退出
cur = cur.next; //繼續找的條件
count++;
}
//退出了 當前cur就是 index -1
return cur; // 回傳前面的一個
}
以上就是這個函式的意思,那我們看看下一個函式addIndex();
public void addIndex(int index , int data){ //任意位置插入,第一個資料節點為0號下標
if(index<0 || index >size() ){ //判斷需要放入的位置是否合法
System.out.println("下標不合法");
return;
}
//頭插法
if(index == 0){ //如果index等于0 就是頭插法
addFirst(data);
}
//尾插法
if (index ==size()){ //size是個函式 上面寫過,
//如果index等于size 就是全部長度,也就是尾插法
addLast(data);
}
Node cur= searchPrev(index); //前一個節點
//新節點的插入 核心代碼
Node node = new Node(data); //這個是新節點
//核心代碼
node.next = cur.next;
cur.next =node;
}
怎么理解核心代碼呢?
看下面的圖:可以看出 現在cur的next 等于node2
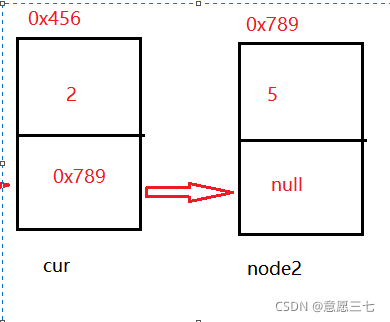
那么 node.next = cur.next; 這個代碼的意思就是把 0x789給了新節點
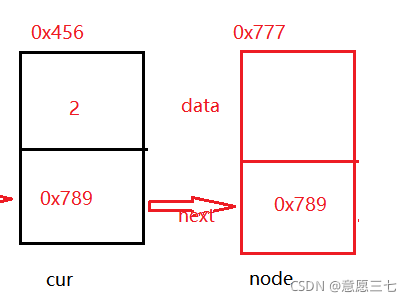
就意味著是新節點 指向剛剛那個0x789 node2
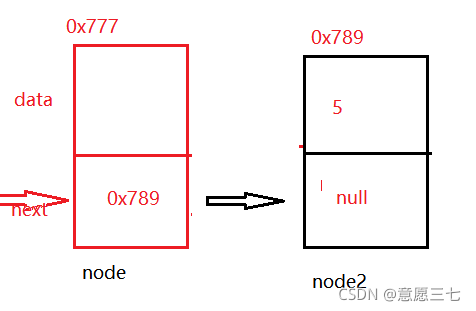
那么竟然新節點已經指向node2 那 cur 是不是應該指向 新節點呢?
所以 cur.next =node;
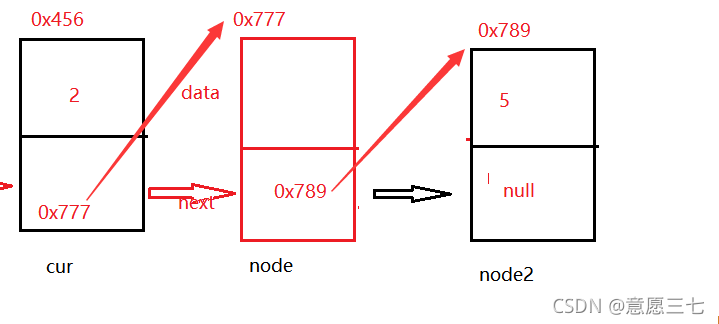
所以這才是一個完美的鏈表插入!!!
7、洗掉指定的節點
洗掉結點原理就是讓那個節點不被參考,這樣就會被JVM自動回收(當沒有被參考時會被自動回收),我們可以讓被洗掉的節點不被參考,讓被洗掉前面的節點參考被洗掉后面的那個節點,這樣洗掉的節點在中間沒有被參考就會自己被回收,達到洗掉的效果,
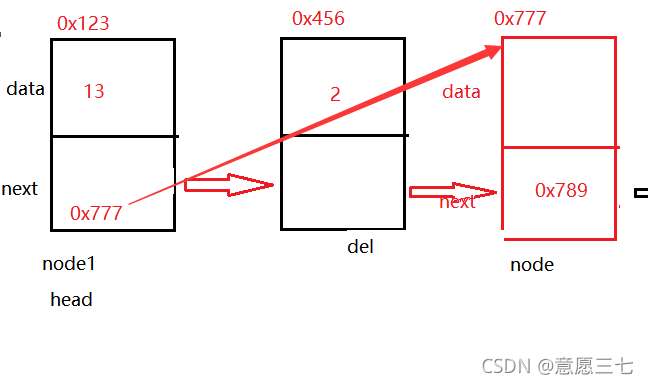
代碼送上:
public Node searchPrevNode(int val){
Node cur = this.head;
while (cur.next!=null){
if (cur.next.data==val){
return cur;
}
cur = cur.next;
}
return null;
}
public void remove(int val){ //洗掉第一次出現的關鍵字為key的節點
if (this.head == null){
return;
}
if (this.head.data==val){
this.head =this.head.next;
return;
}
Node cur = searchPrevNode(val);
if (cur==null){
System.out.println("沒有要洗掉的節點");
return;
}
Node del = cur.next;
cur.next =del.next;
}
讓我們依次決議:searchPrevNode();
public Node searchPrevNode(int val){
Node cur = this.head; //定義一個head
while (cur.next!=null){//回圈節點
if (cur.next.data==val){
//如果下一個結點的值 等于要洗掉的值 那么就回傳前一個值
return cur;
}
cur = cur.next; //讓條件繼續
}
return null; //找不到回傳null
}
上面代碼核心是: 為什么要找到前面的節點?
if (cur.next.data==val){
//如果下一個結點的值 等于要洗掉的值 那么就回傳前一個值
return cur;
}
上面我們說過,找到要洗掉結點的 前面節點,讓前面的節點不要參考被洗掉的節點,就可以達到洗掉的效果
決議:remove()
public void remove(int val){ //洗掉第一次出現的關鍵字為key的節點
if (this.head == null){ //如果沒有節點要洗掉
return;
}
if (this.head.data==val){ //如果洗掉第一個結點
this.head =this.head.next; //讓當前結點被下一個節點參考
return;
}
Node cur = searchPrevNode(val);
if (cur==null){ //上面函式可能回傳null
System.out.println("沒有要洗掉的節點");
return;
}
Node del = cur.next; //被洗掉節點 就是cur的next域
cur.next =del.next; //讓cur的next等于del.next
//del.next 是要洗掉的節點下一個地址
}
來看看較難理解的代碼:
if (this.head.data==val){ //如果洗掉第一個結點
this.head =this.head.next; //讓當前結點被下一個節點參考
return;
}
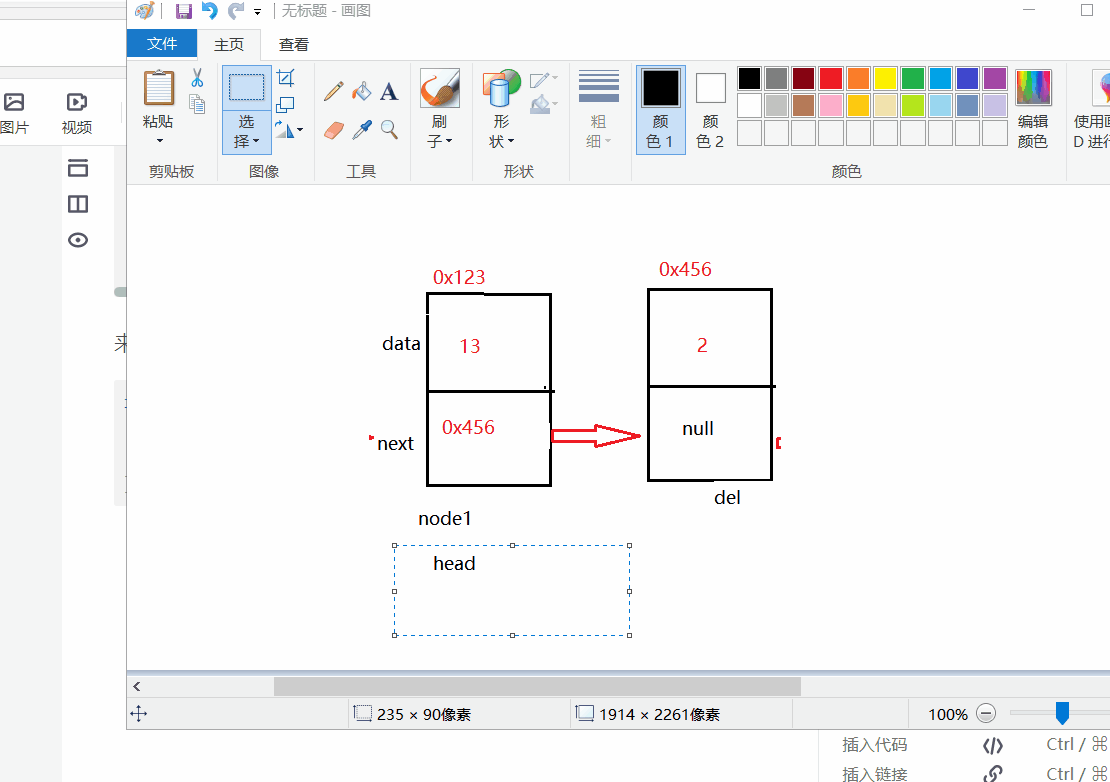
head.next == 0x456 ,所以head指向0x456
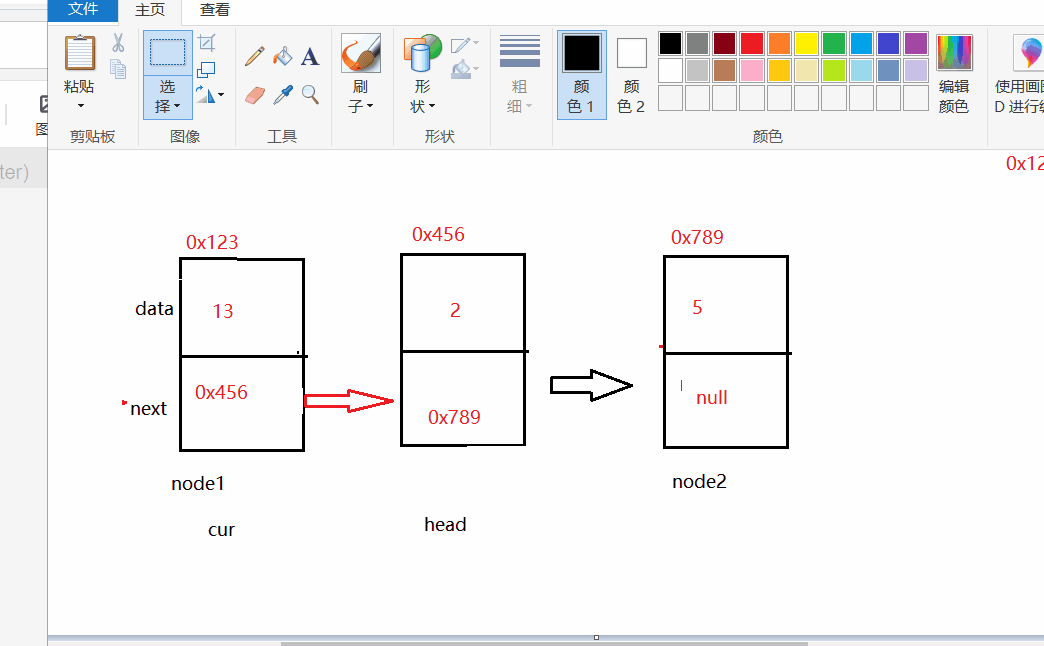
二:
Node del = cur.next; //被洗掉節點 就是cur的next域
cur.next =del.next; //讓cur的next等于del.next
//del.next 是要洗掉的節點下一個地址
8、洗掉全部指定的節點
洗掉全部指定的結點也是和洗掉差不多一樣的原理,把要洗掉的那個節點不被參考即可:
比如下面要洗掉 【2】 這個結點:下面的做法就是讓prev的next域等于 cur的next域,這樣prev的next域,就沒有參考cur ,而是參考cur.next域(就是【5】這個節點)
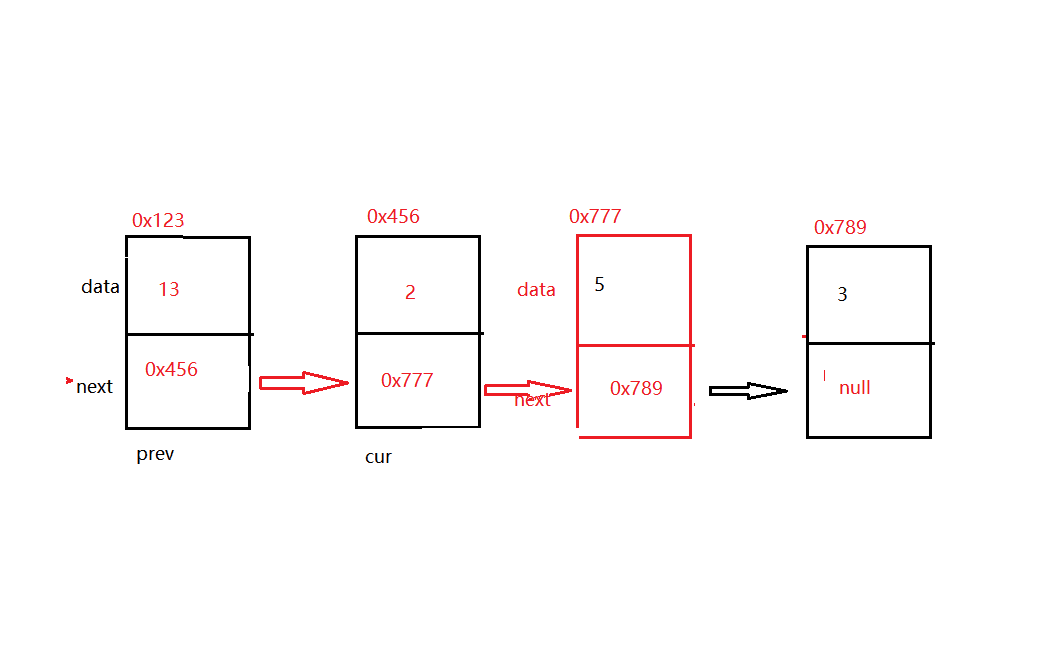
public void removeAllKey(int key){ //洗掉給定的所有值
if(this.head==null)return; //判斷如果head是空 證明沒有節點,直接return
Node prev = this.head; //定義一個前驅 方便操作
Node cur = this.head.next; //定義一個cur 從第二個節點開始
while (cur!=null){ //條件是cur不等于空 就進去執行代碼
if(cur.data == key){ //如果當前cur等于要洗掉的
prev.next=cur.next; //把前驅的參考指向第二個節點的next域(也就是cur的下一個結點)
cur = cur.next; //cur往后走一步
}else{ //如果不是要洗掉的節點
prev=cur; //讓前驅等于下一個
cur = cur.next; //讓cur等于下一個
}
}
if (this.head.data==key){ //最后判斷第一個是不是要洗掉的節點
this.head = this.head.next; //當前的head參考下一個
}
}
9、清空全部節點
清空節點原理很簡單:就是讓當前的節點的next不參考后面的域,然后依次置空即可, 當然我們可以暴力點直接head等于null,那么這樣后面的節點依次就沒有被參考,就會被JVM回收掉,下面這圖就是介紹上面所說的:
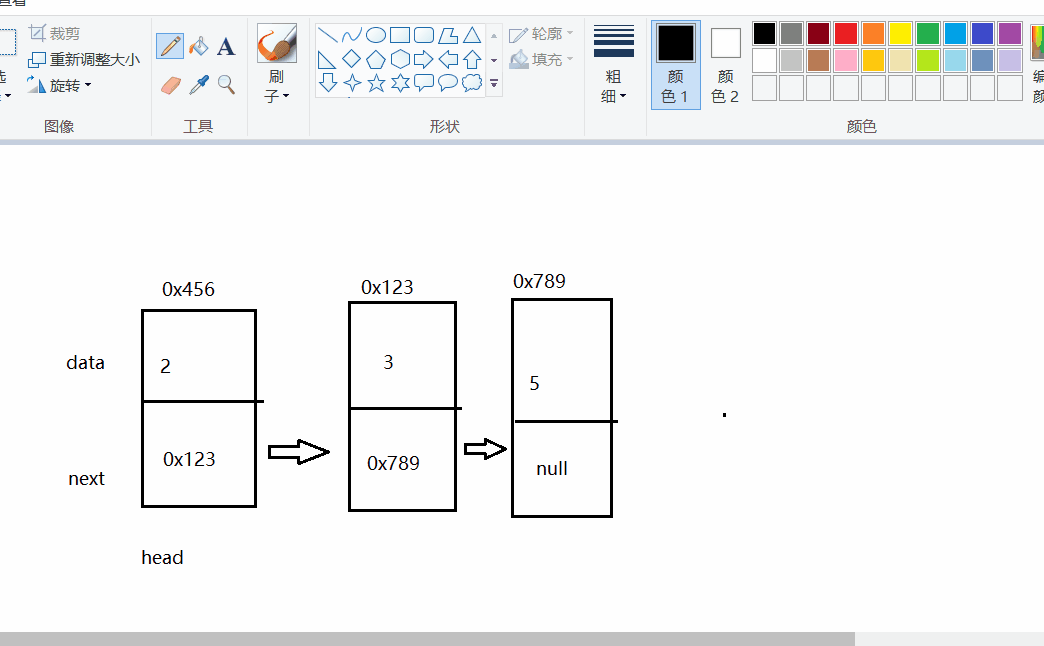
public void clear(){//洗掉所有節點
while (this.head!=null){ //當不等于空進入
Node curNext = this.head.next; //把下一個地址保存
this.head.next = null; //把下一個的地址置空
this.head = curNext; //把當前節點不被參考
}
}
那么我們怎么證明已經把它給"干掉了呢"?
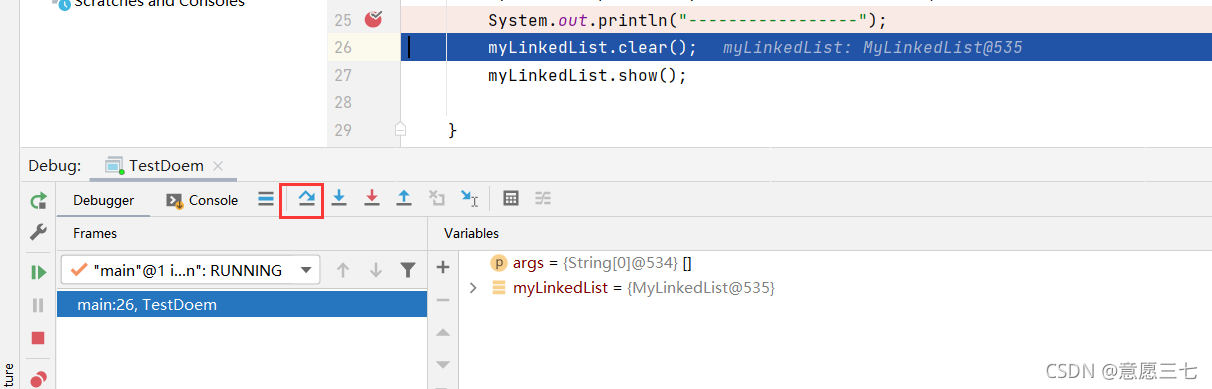
1、打個斷點除錯起來
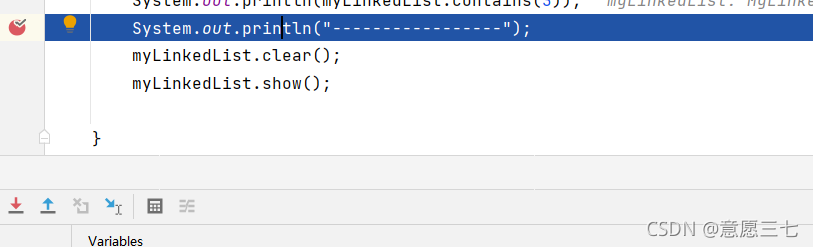
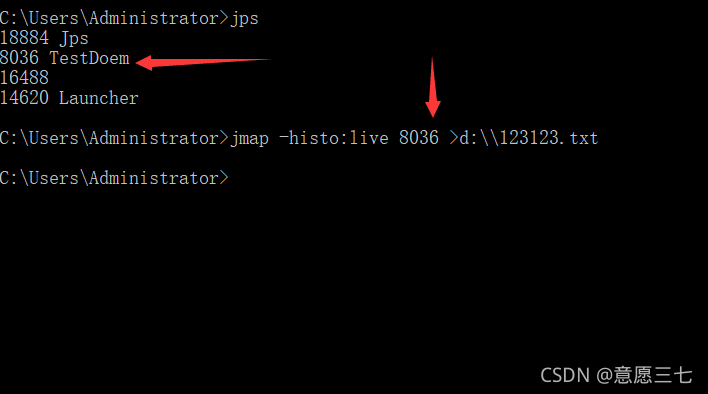
2.打開cdm 輸入 jps 查看當前java行程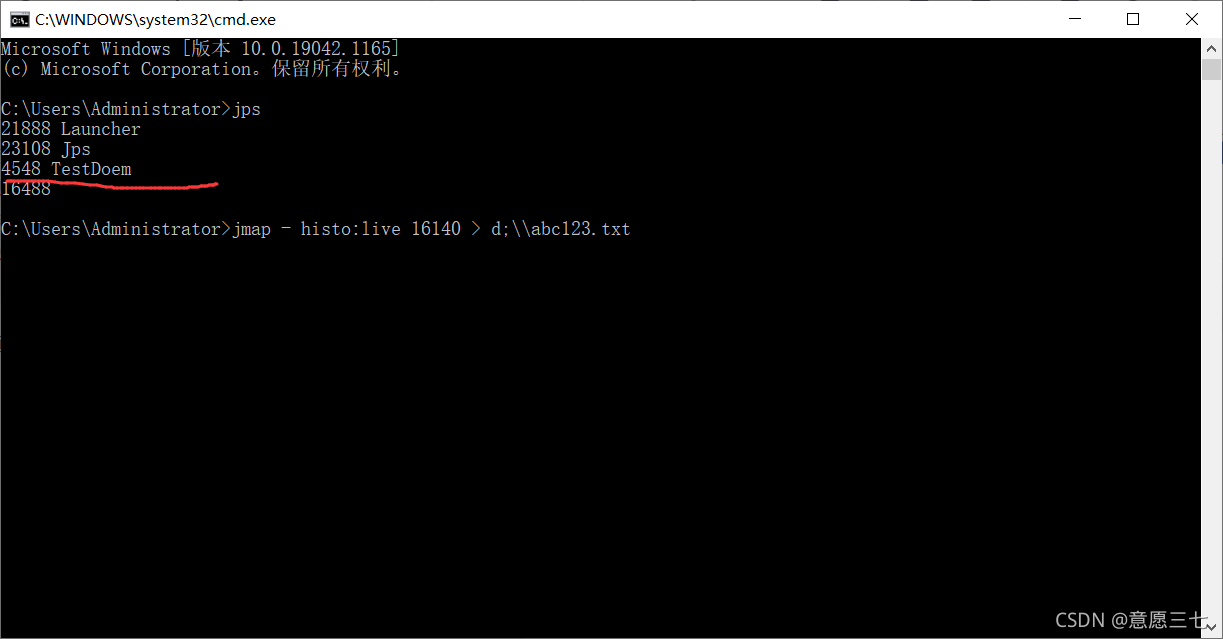
然后輸入:
jmap - histo:live 4548
(jmap是JDK自帶的工具軟體,主要用于列印指定Java行程(或核心檔案、遠程除錯服務器)的共享物件記憶體映射或堆記憶體細節)
意思是:這些東西會查出很多資訊,列印到你的cmd中 但是這樣不方便 我們可以重新重定向一下,把查出資訊放在d盤下123123.txt 檔案 方便閱讀
jmap -histo:live 4548>d:\123123.txt
注意圖上的箭頭所指向的要是一樣 比如我上面是4548 live后面也是4548,然后按回車,發現它在一閃一閃,我們去idea執行下一步操作
然后去找到檔案打開即可:
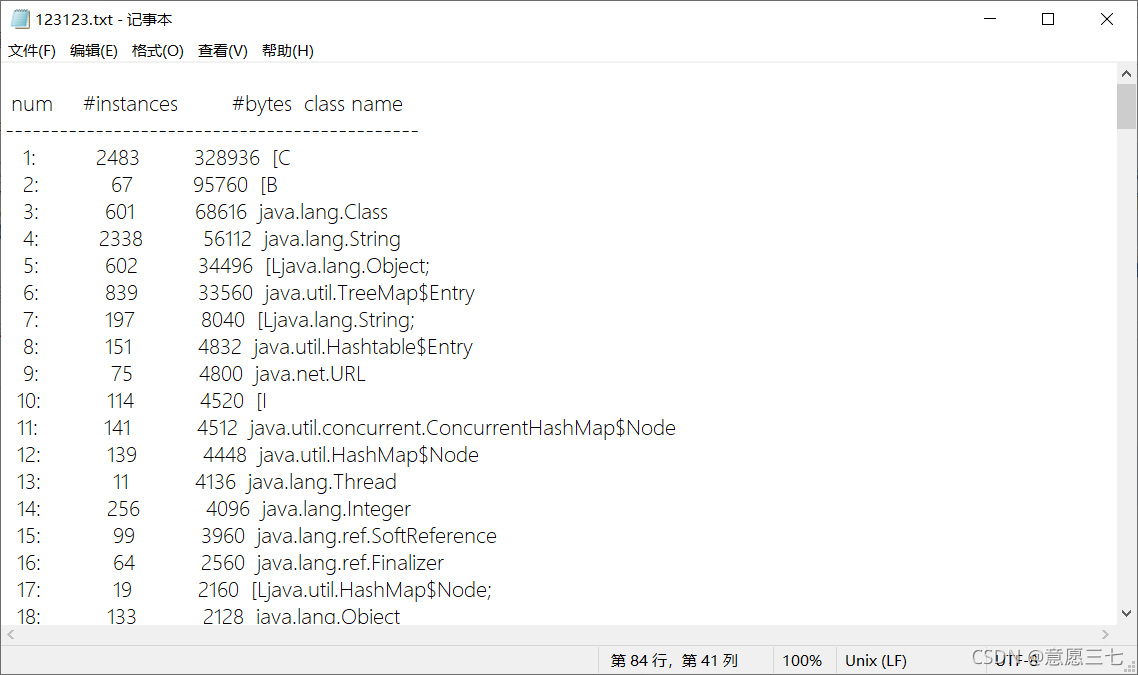
ctrl+f 找一下 節點 (我的節點叫做Node)這里是有4個
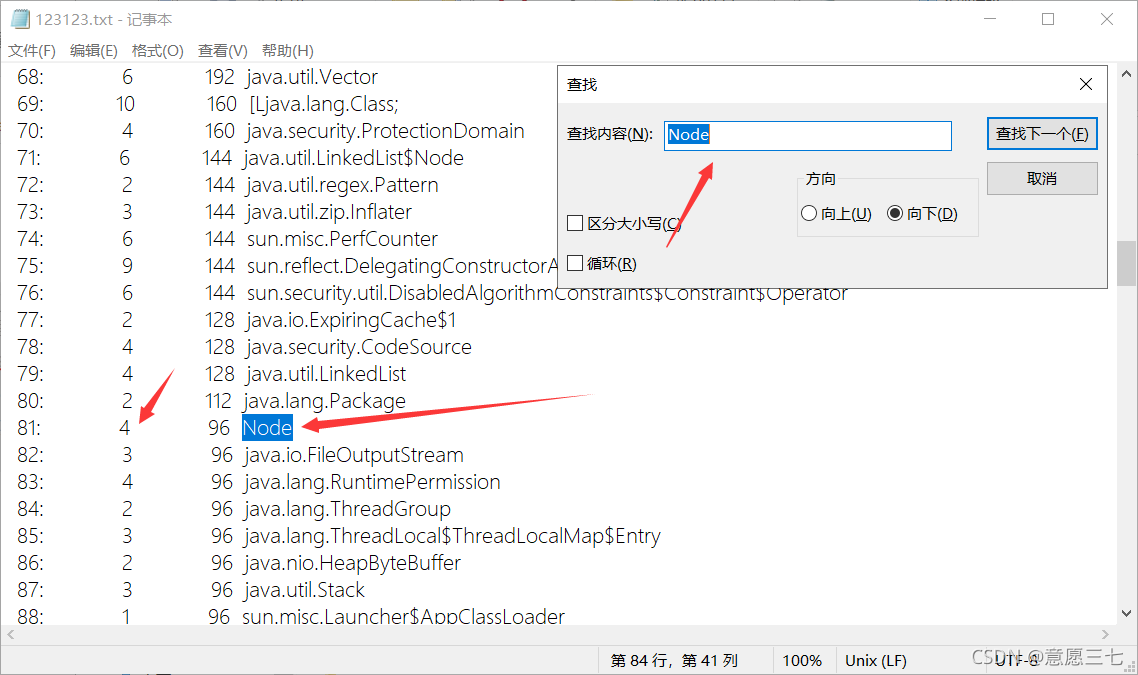
我的程式里面也剛剛好是4個
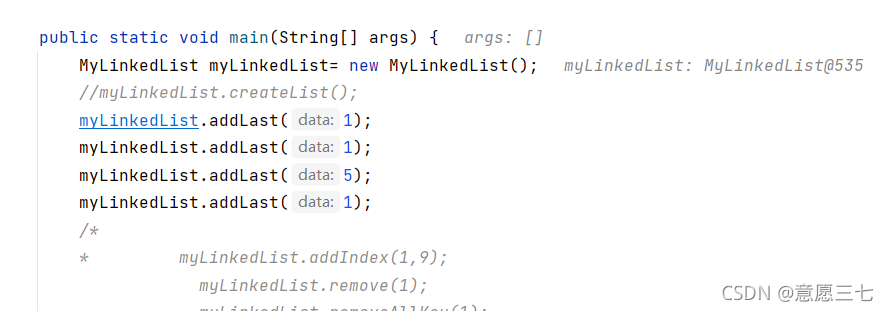
這個時候我們關閉程式,呼叫一下clear()方法,,先調研方法

然后執行上面的操作 (注意數字)
這個時候我們去檔案搜索一下,發現沒有第一次的node節點了
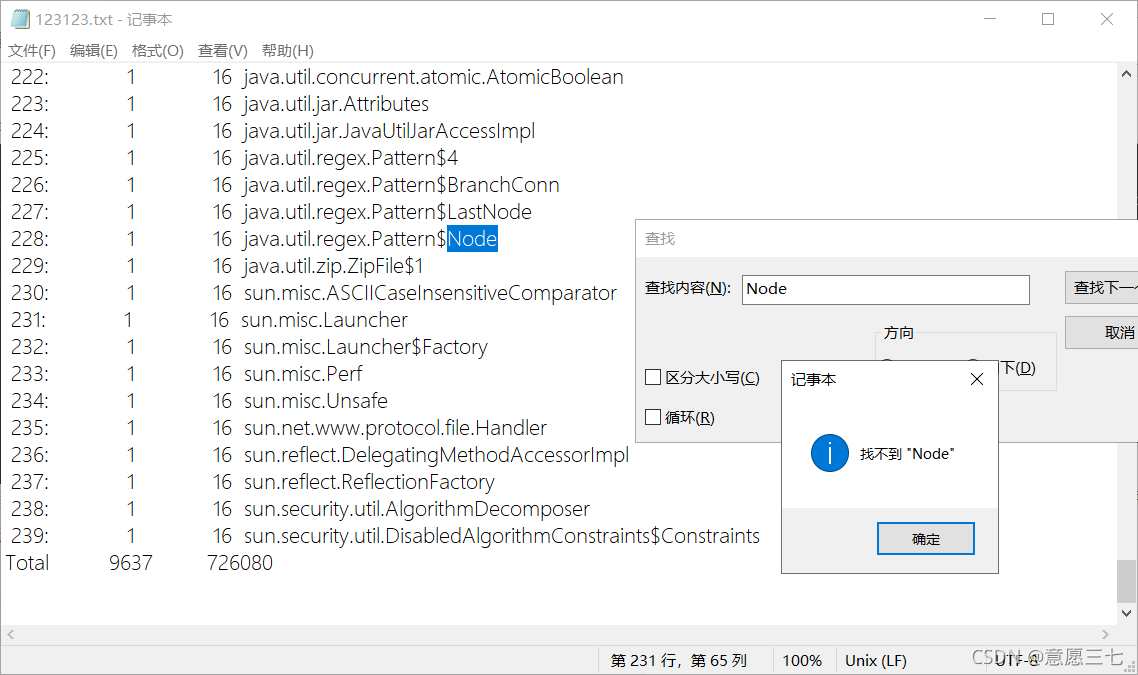
證明成功了我們!
二、鏈表的面試題
1.反轉一個單鏈表,
OJ鏈接
上面這個題,很多同學會搞不清楚,會逆置資料,其實注意是錯誤的
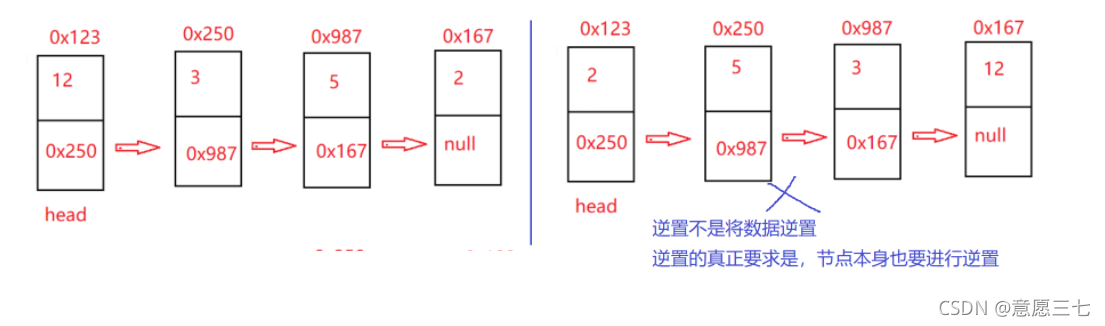
正確的應該是這樣的:最后一個到前面來了,參考的next域也需要改變
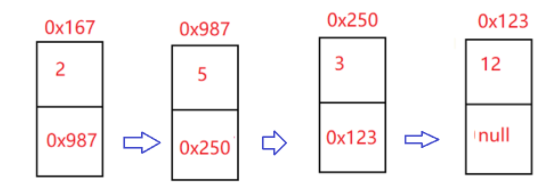
思路:我們可以使用頭插法,先把第一個節點的next域改變成null,這樣第一個節點就是最后一個節點了,然后想辦法讓后面節點的next域等于前面的節點,也就是相當等于反過來了,
public Node reverseList() { //反轉一個單鏈表
if(head==null) return null; //如果沒有回傳null
if(head.next==null) return head; //如果就一個 回傳這個一個節點
Node cur = this.head; //定義一個頭
Node prev = null; //前驅為空(為了讓第一個節點變成最后一個節點 )
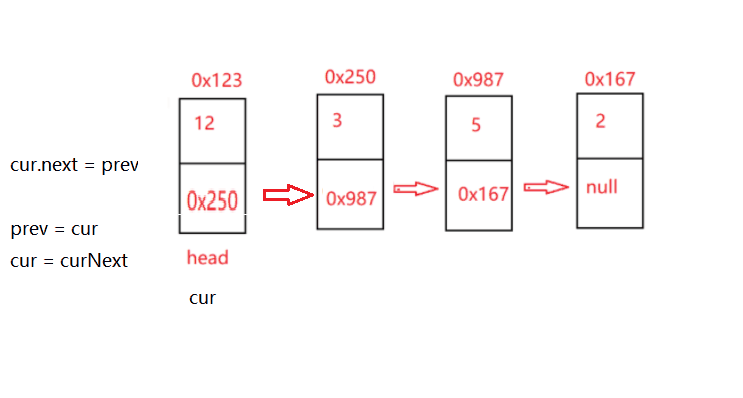
while(cur!=null){ //遍歷
Node curNext = cur.next; //因為要替換前一個節點 所以要保留后面的節點
cur.next = prev; //第一個的節點next域為null 變成最后一個
prev = cur; //前驅等于當前節點
cur = curNext; //當前節點去下一個節點
}
return prev; //回傳最頭的節點
}
列印的話 函式也得變一下,要從新的頭列印 不可使用以前的函式
/從指定位置開始列印
public void show2(Node newHead){
Node cur = newHead;
while(cur != null){
System.out.print(cur.data+" ");
cur=cur.next;
}
}
2.回傳中間節點,有2個回傳第二個中間的節點
oj鏈接

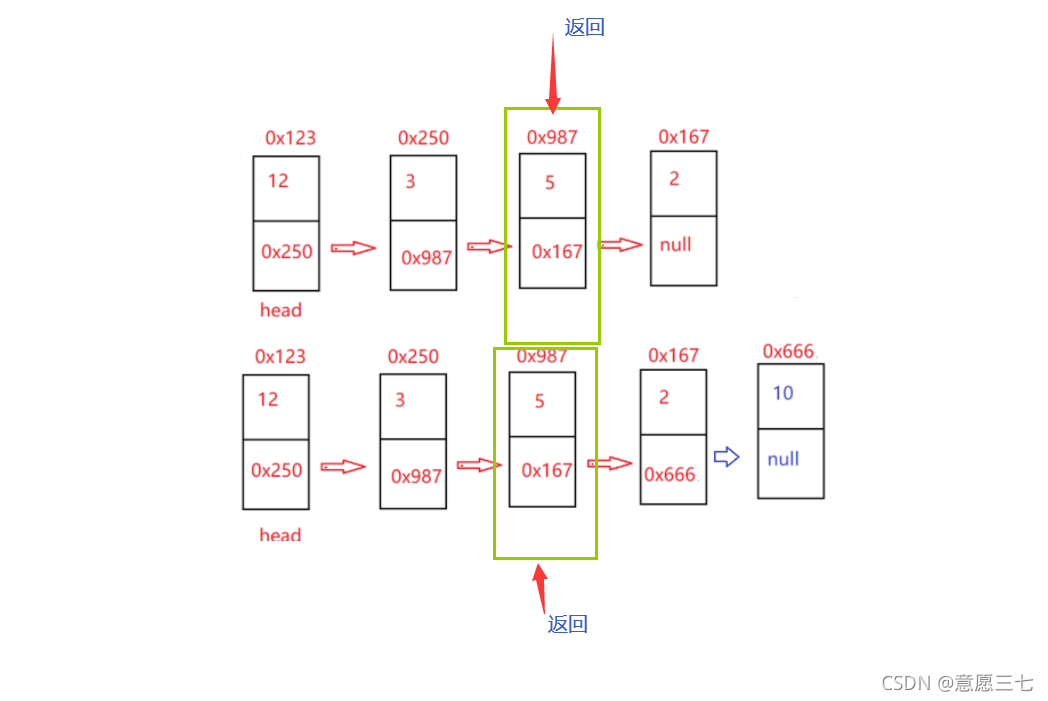
思路:使用快慢指標fast走2步,slow走1步,當fast等于null那么是4個節點,fast.next等于null 那么是5個節點
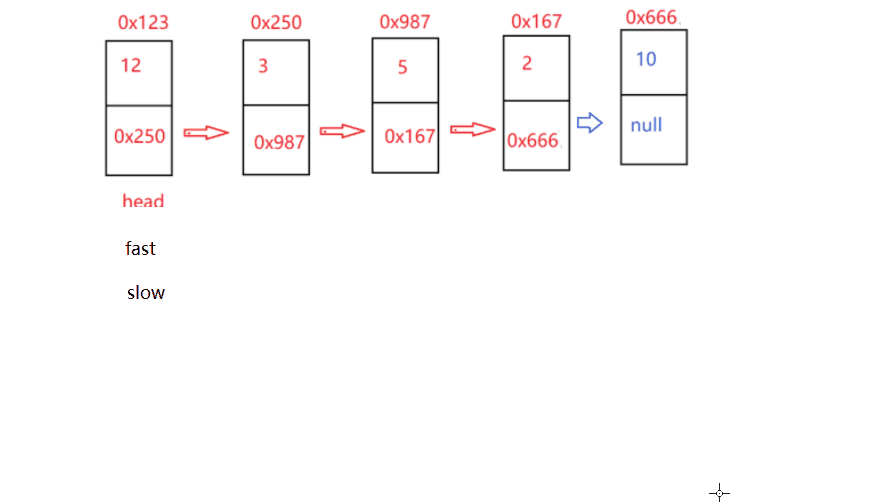
public Node middleNode() {
if(head==null) return head; //當頭節點等于空 回傳null
Node fast = head; //快指標 在頭部
Node slow =head; //慢指標 在頭部
while(fast!=null && fast.next!=null){ //往前走的條件
fast = fast.next.next; //快的走2步
slow = slow.next; //慢的走一步
}
return slow; //慢的肯定在中間
}
3.輸入一個鏈表,輸出該鏈表中倒數第k個結點,
OJ鏈接
原理很簡單 :快慢指標即可 ,先快指標走k-1步,然后慢指標一起走,為什么可以:假設找倒數第二個節點 fast先走 k-1步(也就是一步),然后一起走,當fast.next等于null 回傳slow

為什么呢? 比如我們跑步你一直差我k-1的距離,等我到了你是不是還差k-1的距離, 假如你要找倒數第3個格子,你比我差2格,對于節點來說,是不是意味著到了終點,后面還有2個格子,加上終點的格子 一共有3個,所以就是這個原理
public Node findKthToTail(int k) { //倒數第k個節點
if(head==null) return null; //如果的是第一個節點是null 回傳null
if(k < 0){ //k不可以小于0 不然是負數
return null; //回傳是null
}
Node fast = head; //快指標
Node slow = head; //慢指標
while(k-1 !=0){ //讓快指標先走 k-1步
if(fast.next!=null){ //如果條件不成立 證明k大于我們的節點長度
fast = fast.next;
k--;
}else{
return null;
}
}
while(fast.next != null){ // 然后一起走
fast = fast.next;
slow = slow.next;
}
return slow;
}
4.合并兩個有序鏈表,
OJ鏈接
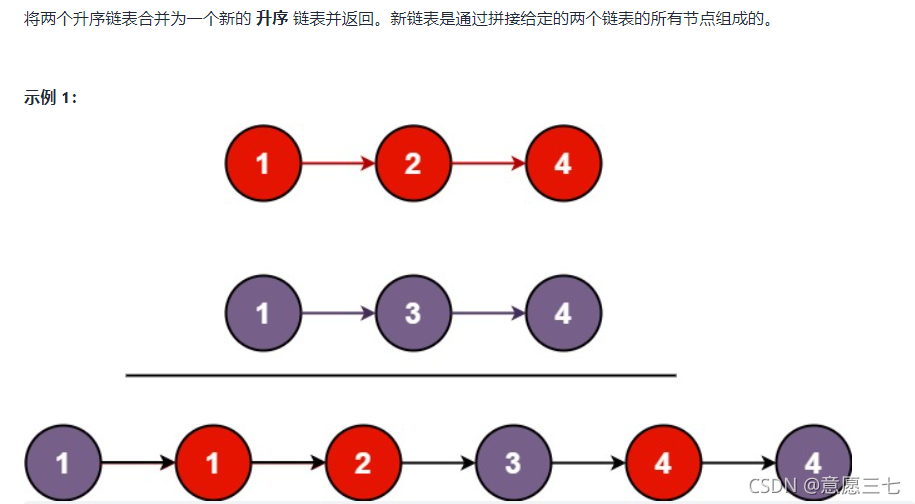
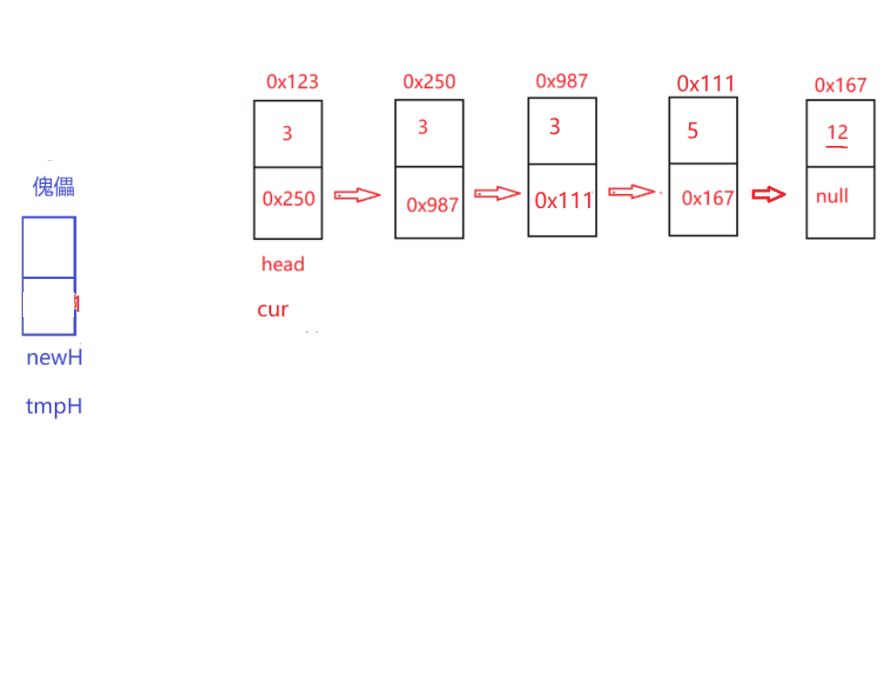
原理:定義一個新無用的節點,然后讓鏈表A 和鏈表B的值去比較,誰小就放在無用節的next域,每放好一次鏈表向后走,傀儡結點參考傀儡節點的next域,往后面走,然后在回圈拿新值去比較,最后當鏈表A為空,就然傀儡節點的next等于鏈表B(前面全部參考完了,后面的可以直接等于鏈表B 因為鏈表B本身就是一個有序的),反之一樣 ,最后回傳傀儡節點的next,因為next域是第一個節點
public Node mergeTwoLists(Node headA, Node headB) { //合并有序的節點
if(headA==null)return headB; //如果headA是慷訓傳headB
if(headB==null)return headA;
if(headA==null && headB ==null)return null; //全部null回傳null
Node newHead = new Node(-1); //定義傀儡節點(無用節點)
Node tmp = newHead; //定義一個標記 參考下一個節點地址
while(headA!=null && headB!=null){ //條件
if(headA.data< headB.data){ //比較他們的值大小
tmp.next = headA; //傀儡節點的下一個是headA
headA = headA.next; //讓headA在往后去一個節點
}else{
tmp.next = headB;
headB = headB.next;
}
tmp = tmp.next; //假設傀儡節點已經是1 后面是其他數字, 應該要去下一個節點,繼續參考其他的
}
if(headA==null){ //如果鏈表A 全部跑完了
tmp.next = headB; //傀儡節點 只直接參考headB的全部
}
if(headB==null){
tmp.next = headA;
}
return newHead.next; //回傳的是傀儡節點的下一個域 因為當前節點是沒有用的
}
5.以給定值x為基準將鏈表分割成兩部分,所有小于x的結點排在大于或等于x的結點之前
OJ鏈接
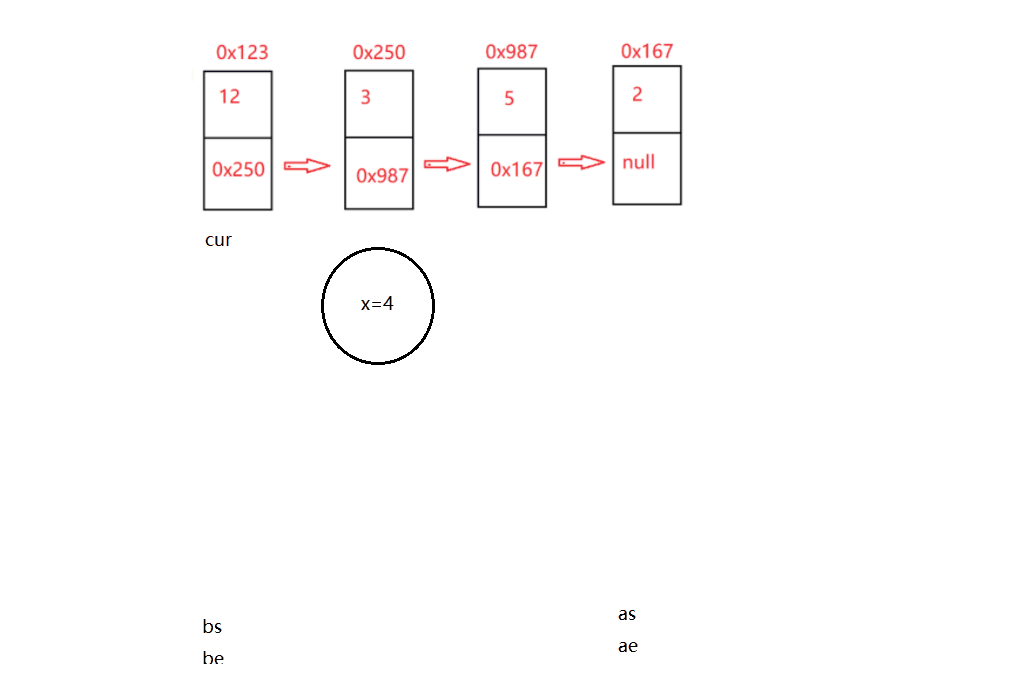
什么意思呢?如果給了個x=4;鏈表比4小的一邊,比4大的在一邊,而且以前的順序不可以改變
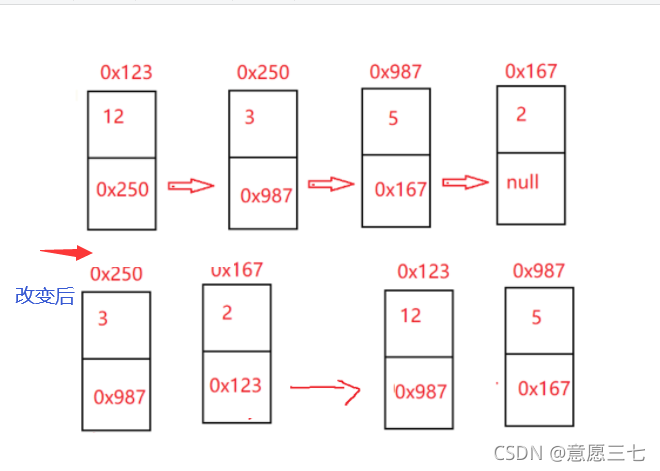
代碼思路:和x值比較如果大于等于X的放一邊,反之放另外一邊,怎么取分邊界呢,我們可以定義4個參考,bs be,as se, s是開始,e是結尾,最后排序好在讓next等于下一個的頭,
public Node partition(ListNode pHead , int x) {
// write code here
// write code here
Node cur = pHead ; //定義一個代替頭
Node bs = null; //小于x的bstar 開始的頭節點
Node be = null; //小于x的bend 結束的尾節點
Node as = null;
Node ae = null;
while(cur!=null){ //遍歷cur
if(cur.data<x){ //如果當前的data大于 x
if(bs==null){ //判斷是不是為空
bs = cur; //頭尾都是開始
be = cur; //頭尾都是開始
}else{
be.next = cur; //尾插法
be = be.next; //尾往后走
}
}else{
if(as==null){
as = cur;
ae = cur;
}else{
ae.next =cur;
ae = ae.next;
}
}
cur = cur.next; //cur 往后走
}
if(bs==null){ //如果第一段頭是空
return as; //回傳下一段的頭節點
}
be.next = as ; //第一段的尾巴 鏈接第二段的頭
if(as!=null){ //第二段的頭不等于空
ae.next = null; //第二段(也就是最后的尾等于空)
}
return bs ; //回傳第一段的頭
}
6.在一個排序的鏈表中,存在重復的結點,請洗掉該鏈表中重復的結點,重復的結點不保留,回傳鏈表頭指標,
OJ鏈接

代碼思路:定義一個傀儡節點,最后回傳傀儡節點的next域,當前的節點的val值和下一個對比 是否是一樣的,如果是一樣的則跳過,如果不是一樣的,那么傀儡節點的next等于它,依次回圈, 最后的節點next域等于null;、
public ListNode deleteDuplication(ListNode pHead) {
ListNode newHead = new ListNode(-1); //定義一個頭節點
ListNode tmp = newHead; //傀儡節點
ListNode cur = pHead; //當前頭
while(cur!=null){ //cur 不等于空
if(cur.next!=null && cur.val == cur.next.val){ //cur在走的程序中有可能是相同的
while(cur.next!=null && cur.val == cur.next.val){
cur = cur.next;
}//走到相同的最后一個
cur = cur.next; //在走一個就不是相同的
}else{ //如果不是相同的
tmp.next = cur; //傀儡節點的next等于下一個
tmp = tmp.next; //傀儡節點往后走
cur = cur.next; //cur往后走
}
}
tmp.next = null; //最后的節點的next域等于空
return newHead.next; //回傳傀儡節點
}
7.鏈表的回文結構,
OJ鏈接
代碼思路: 判斷回文 我們可以先找中間結點,然后翻轉,依次判斷是否是回文
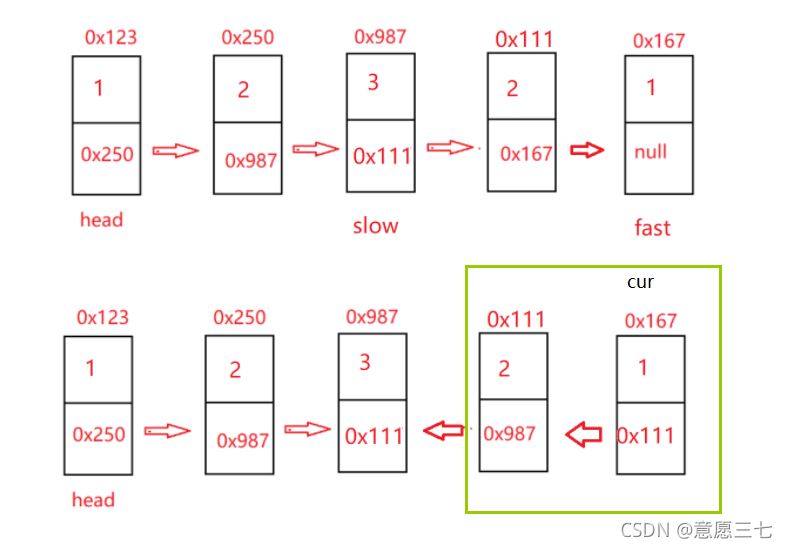
public boolean chkPalindrome(ListNode head) {
// write code here
if (head ==null){ //判斷有沒有節點
return true;
}
if (head.next ==null){ //只有一個節點的情況
return true;
}
//找中間節點 定義快慢指標
ListNode fast = head;
ListNode slow = head;
while(fast!= null && fast.next!=null){
fast = fast.next.next;
slow = slow.next;
}
//進行翻轉
ListNode cur = slow.next;
while (cur!= null){
ListNode curNext = cur.next;
cur.next = slow;
slow = cur;
cur = curNext;
}
//判斷回文
while (slow!= head){
if (slow.val != head.val){
return false;
}
if (head.next ==slow){ //如果是偶數
return true;
}
slow =slow.next; //個往下一步走
head = head.next;
}
return true;
}
8.給定一個鏈表,判斷鏈表中是否有環,
OJ鏈接
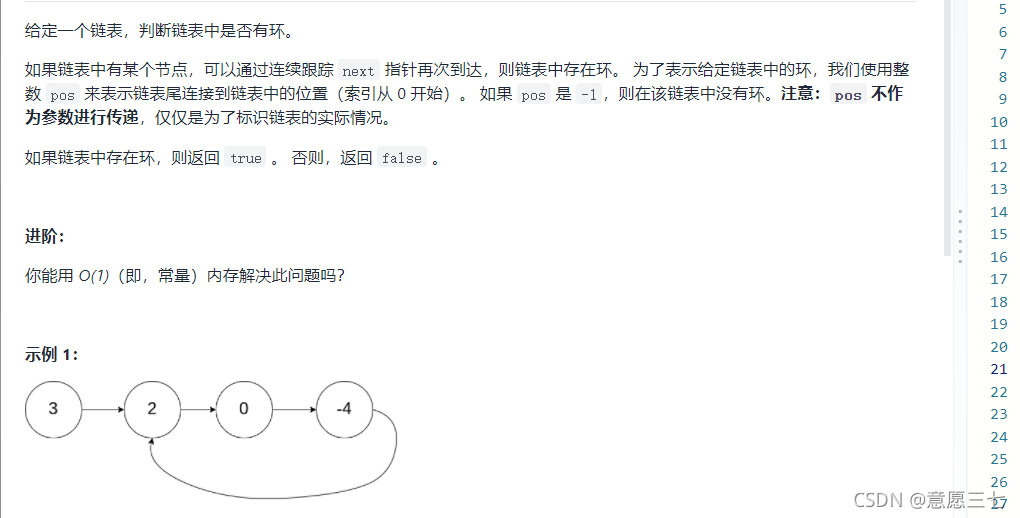
代碼思路:很簡單判斷有沒有可以使用快慢指標:fast指標走兩步,慢指標走一步,每次走完判斷一下即可:

代碼:
public boolean hasCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(fast!=null && fast.next!=null){
fast = fast.next.next; //快的走兩步
slow = slow.next; //慢的走一步
if(slow==fast){ //每次判斷一下
return true;
}
}
return false;
}
9. 給定一個鏈表,回傳鏈表開始入環的第一個節點, 如果鏈表無環,則回傳 null
代碼原理:/兩個指標,從頭結點和相遇結點,各走一步,直到相遇,相遇點即為環入口
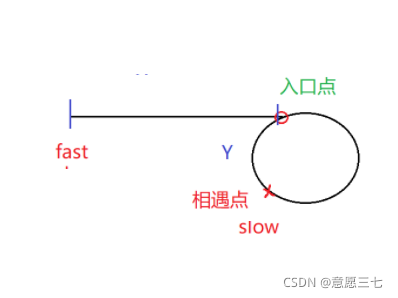
public ListNode detectCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(fast!= null && fast.next !=null){
fast = fast.next.next;
slow = slow.next;
if(slow==fast){
break;
}
}
if(fast ==null ||fast.next ==null){
return null;
}
//找入環第一個結點
slow = head;
while(fast!=slow){
fast = fast.next;
slow = slow.next;
}
return slow;
}
10. 輸入兩個鏈表,找出它們的第一個公共結點
在線OJ
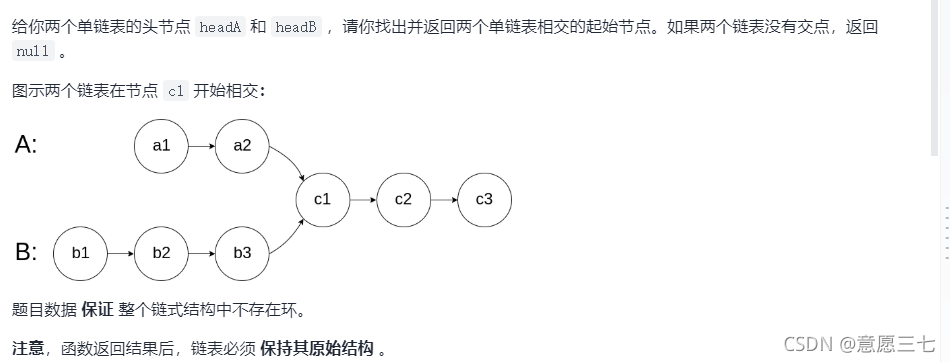
代碼思路:既然有2個鏈表,我們可以讓他們達到相同的位置,在讓他們一起一步一步的往下走,最后他們相等則發回地址:
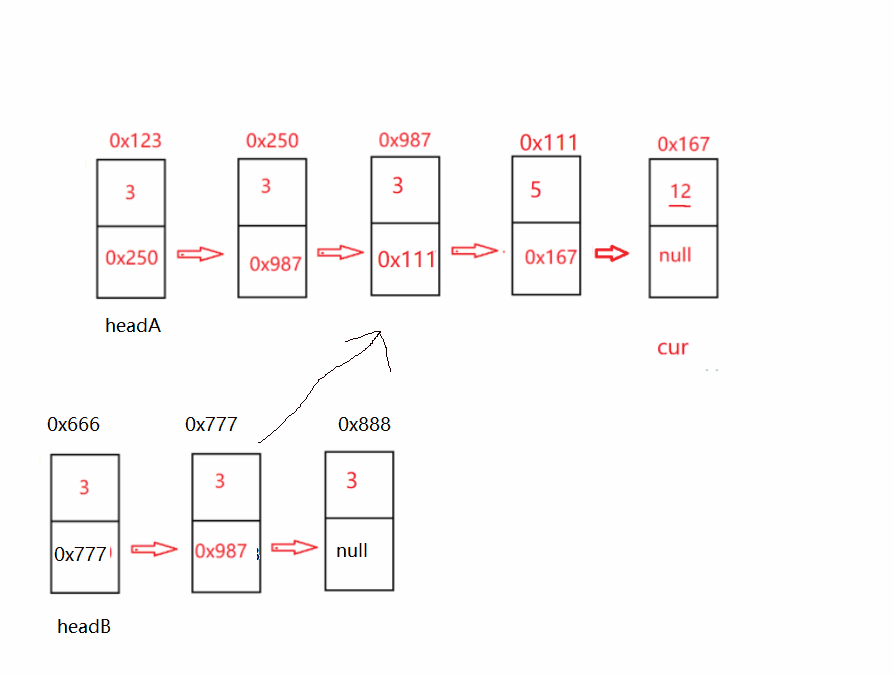
代碼如下:
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if(headA == null){
return null;
}
if(headB == null){
return null;
}
//求長度
int lenA = 0;
int lenB = 0;
ListNode pl= headA; //假設pl 是最長的鏈表
ListNode ps= headB;
while(pl!=null){
lenA++; //計算長度差值
pl = pl.next;
}
while(ps!=null){
lenB++;
ps = ps.next;
}
pl = headA ; //上面走完已經是null 我們回到原來位置
ps = headB ;
int len = lenA - lenB; //差值步
if(len<0){
pl = headB;
ps = headA;
len = lenB-lenA; //重新 不然會是負數
}
while (len!= 0 ){ //走差值步
pl = pl.next;
len--;
}
while (pl!=ps){ //一起向后走
pl = pl.next;
ps = ps.next;
}
return pl; //回傳
}
三、面試經常問到的問題:
順序表+單鏈表
1.陣列和鏈表的區別
2.順序表的和鏈表的區別
3.ArrayList和LinkedList的區別
對于上面的問題,我們有個技巧:從他們的共性出發,
1.怎么組織資料的?
- 對于順序表來說,底層是一個陣列組成的,對于鏈表來說,每個資料是由節點組織的鏈表來說,是由節點和節點的指向之間進行組織的,
2.增刪查改
- 順序表不適合插入和洗掉,(因為每次需要移動元素),但是適合查找,為什么,只要給陣列一個下標,可以立馬找到這個資料,
- 鏈表適合插入洗掉,每次插入洗掉順序,只需要修改指向即可,
3.ArrayLinst 和LinkedList是什么:
- 這2個類是Java當中的集合類,他們就是封裝好的順序表和鏈表,
- 強調一點:LinkedList底層是一個雙向鏈表!(接下來學習雙向鏈表)

雙向鏈表的認識:
雙向鏈表:
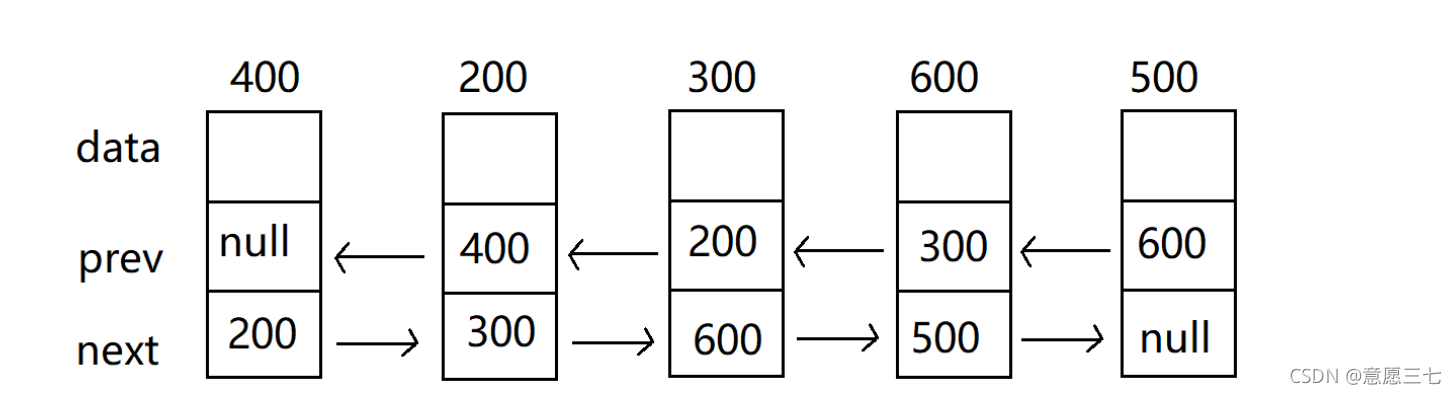
和單向鏈表不同,雙向鏈表多了一個prev域(前驅)
雙向鏈表有什么用?
1.參考了前驅域,解決了單鏈表只能單向訪問的痛點
2.對于雙向鏈表來說,第一個節點和最后一個節點要注意:第一個節點的前驅是null,最后一個節點的后繼是null
雙向鏈表有head 和 last 保持當前節點的頭節點和尾巴節點
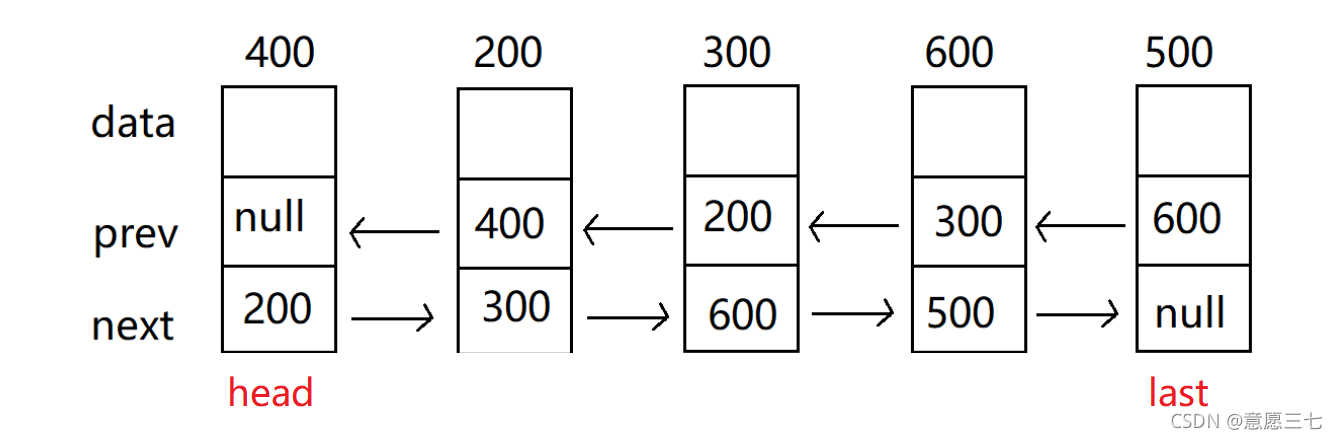
有last的好處: 如果需要插入一個資料,我們可以直接插入在last后面即last.next==node,然后把node的前驅改成last,節省步驟,
接下來創建我們的雙向鏈表吧:
class ListNodeD {
public int data; //資料域
public ListNodeD prev; //前驅域
public ListNodeD next; //尾巴域
public ListNodeD(int data) {
this.data = data; //建構式給data賦值
}
}
一、實作鏈表的函式操作
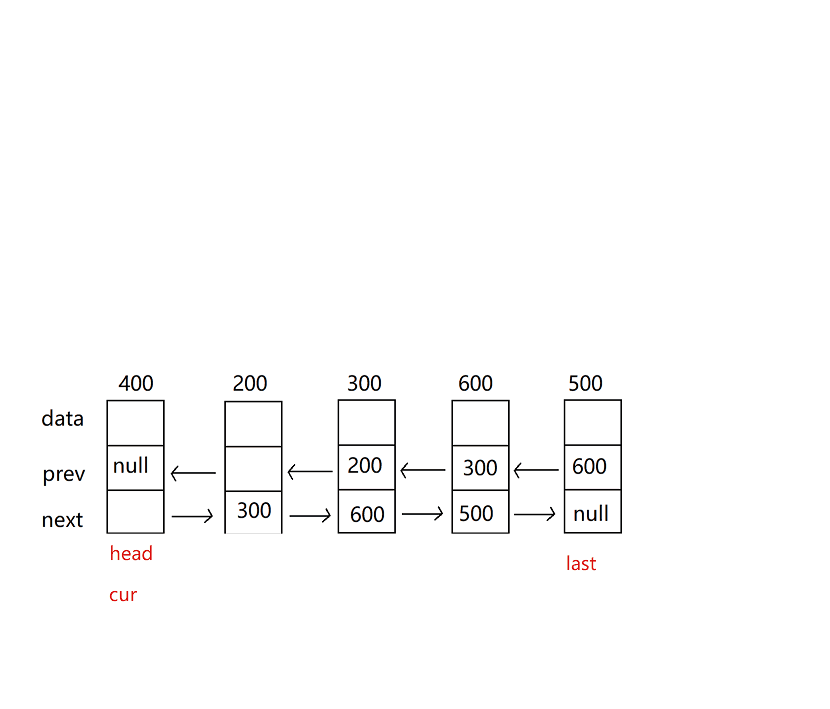
1.雙向鏈表的頭插法
代碼思路:和單鏈表的差不多,不過需要注意我們有了prev這個域,
核心代碼:可對比下圖
node.next = this.head;
this.head.prev = node;
head = node;
//頭插法
public void addFirst(int data) {
ListNodeD node = new ListNodeD(data);
if(head == null){
this.head = node;
}else{
//按照上面的圖來
node.next = this.head;
this.head.prev = node;
head = node;
}
}
2.雙向鏈表的尾插法
代碼思路:和單鏈表的差不多,不過需要注意我們有了prev這個域,
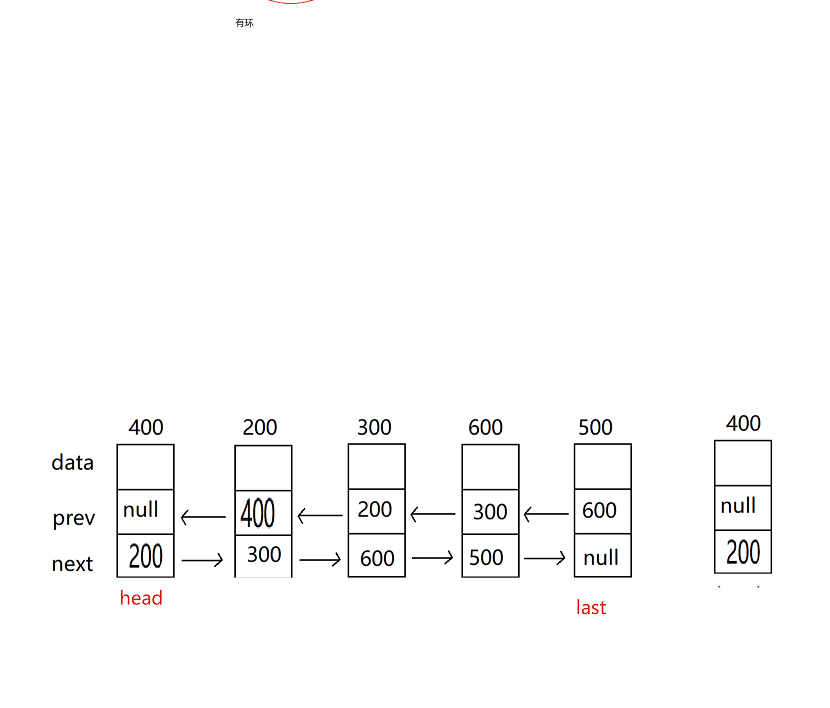
//尾插法
public void addLast(int data) {
ListNodeD node = new ListNodeD(data);
if (this.head==null){
this.last = node;
this.head = node;
}else{
last.next = node;
node.prev =last;
last =node;
}
}
3.任意位置插入,第一個資料節點為0號下標
代碼思路:找到要插入的位置 不需要向單鏈表一樣找前一個,注意插入合法性
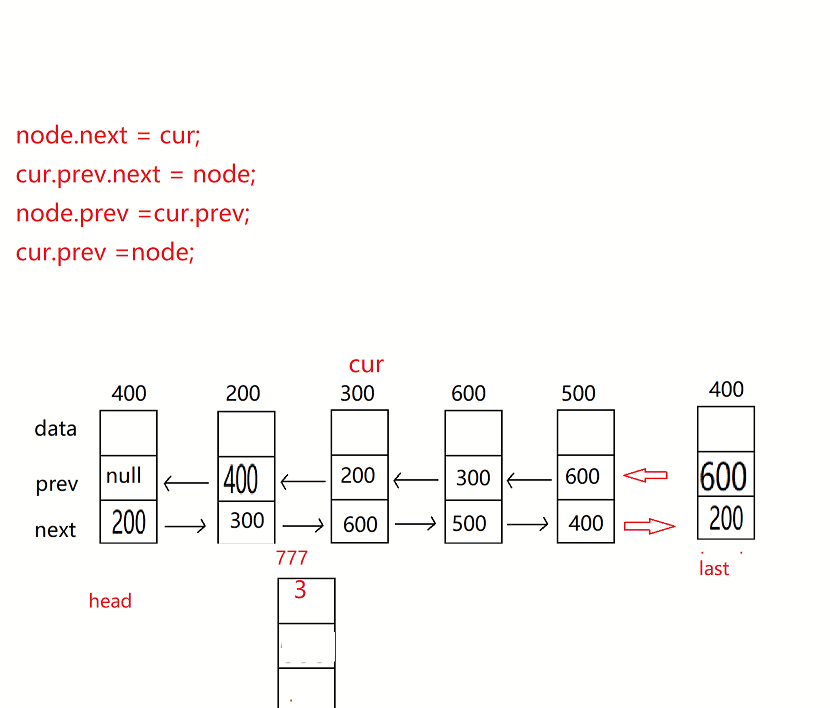
//找位置
public ListNodeD findIndex(int index){
ListNodeD cur = this.head;
while(index!= 0){
cur =cur.next;
index--;
}
return cur;
}
//任意位置插入,第一個資料節點為0號下標
public void addIndex(int index,int data) {
if (index==0){
addFirst(data);
return;
}
if (index==size()){
addLast(data);
return;
}
if(index < 0 || index>size() ){
System.out.println("index位置不合法");
return;
}else{
ListNodeD cur = findIndex(index);
ListNodeD node = new ListNodeD(data);
node.next = cur;
cur.prev.next = node;
node.prev =cur.prev;
cur.prev =node;
}
}
4.洗掉第一次出現關鍵字為key的節點
代碼思路;思路很簡單 就是利用好JVM回識訓制,因為是雙向鏈表我們需要考慮的域比較多,我們洗掉的情況也需要考慮的比較多,分為頭節點洗掉,中間其他節點洗掉,和最后的尾巴節點洗掉,這個鏈表 沒有什么多技巧只有多畫圖…

public void remove(int key) {
if(this.head==null){
return;
}
ListNodeD cur = this.head; //定義一個 cur
while (cur!=null){ //回圈遍歷
if (cur.data==key){ //判斷是否等于要洗掉的
//判斷是不是頭節點
if(cur==this.head){ //當cur是頭節點
this.head = this.head.next; //讓頭節點等于下一個節點
if(this.head == null){ //如果當前的頭節點是null(證明只有一個節點)
this.last = null; //那么把last也給那1個節點
}else{
this.head.prev = null; //(不只一個 但是是第一個節點)把當前前驅置空
}
}else{
cur.prev.next = cur.next; //把當前的前一個節點的next 賦值為cur 的后面那個地址 這樣cur 不被參考
//尾巴節點
if (cur.next == null){ //是尾巴節點 (證明是洗掉最后一個)
this.last = cur.prev; // 那么把前面一個給賦值變成last
}else{ //中間節點
cur.next.prev = cur.prev; //把前驅也改變為 已經被洗掉的前驅
}
}
return;
}else{
cur = cur.next;
}
}
}
5.洗掉所有值為key的節點
代碼思路:可以使用上面的洗掉 只需要把上面的代碼稍微修改修改:
public void removeAllKey(int key) {
if(this.head==null){
return;
}
ListNodeD cur = this.head; //定義一個 cur
while (cur!=null){ //回圈遍歷
if (cur.data==key){ //判斷是否等于要洗掉的
//判斷是不是頭節點
if(cur==this.head){ //當cur是頭節點
this.head = this.head.next; //讓頭節點等于下一個節點
if(this.head == null){ //如果當前的頭節點是null(證明只有一個節點)
this.last = null; //那么把last也給那1個節點
}else{
this.head.prev = null; //(不只一個 但是是第一個節點)把當前前驅置空
}
}else{
cur.prev.next = cur.next; //把當前的前一個節點的next 賦值為cur 的后面那個地址 這樣cur 不被參考
//尾巴節點
if (cur.next == null){ //是尾巴節點 (證明是洗掉最后一個)
this.last = cur.prev; // 那么把前面一個給賦值變成last
}else{ //中間節點
cur.next.prev = cur.prev; //把前驅也改變為 已經被洗掉的前驅
}
}
cur = cur.next;
}else{
cur = cur.next;
}
}
和上面的代碼不一樣,在這里沒有呢return 出去,而是繼續下去一直回圈,直到cur等于null

好了以上就是基本的一些鏈表知識點,希望可以對你有一些幫助,喜歡此文可以收藏點贊感謝感謝!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299176.html
標籤:java
上一篇:我看了1000+招聘啟事,原來大廠偏愛這種程式員……
下一篇:【 JavaSE 】 深入陣列