
目錄
Scrapy概述:
安裝Scrapy:
創建一個Scrapy爬蟲專案:
1.使用scrapy創建一個工程:
2.創建爬蟲檔案:
Scrapy專案結構:
response的屬性和方法:
Scrapy架構組成:
Scrapy Shell:
安裝:
應用:
Scrapy概述:
Scrapy是一個為了爬取網站資料,提取結構性資料而撰寫的應用框架,可以應用在包括資料挖掘,資訊處理或存盤歷史資料等一系列的程式中,
安裝Scrapy:
pip install scrapy pip install -I cryptography創建一個Scrapy爬蟲專案:
1.使用scrapy創建一個工程:
scrapy startproject scrapy專案名稱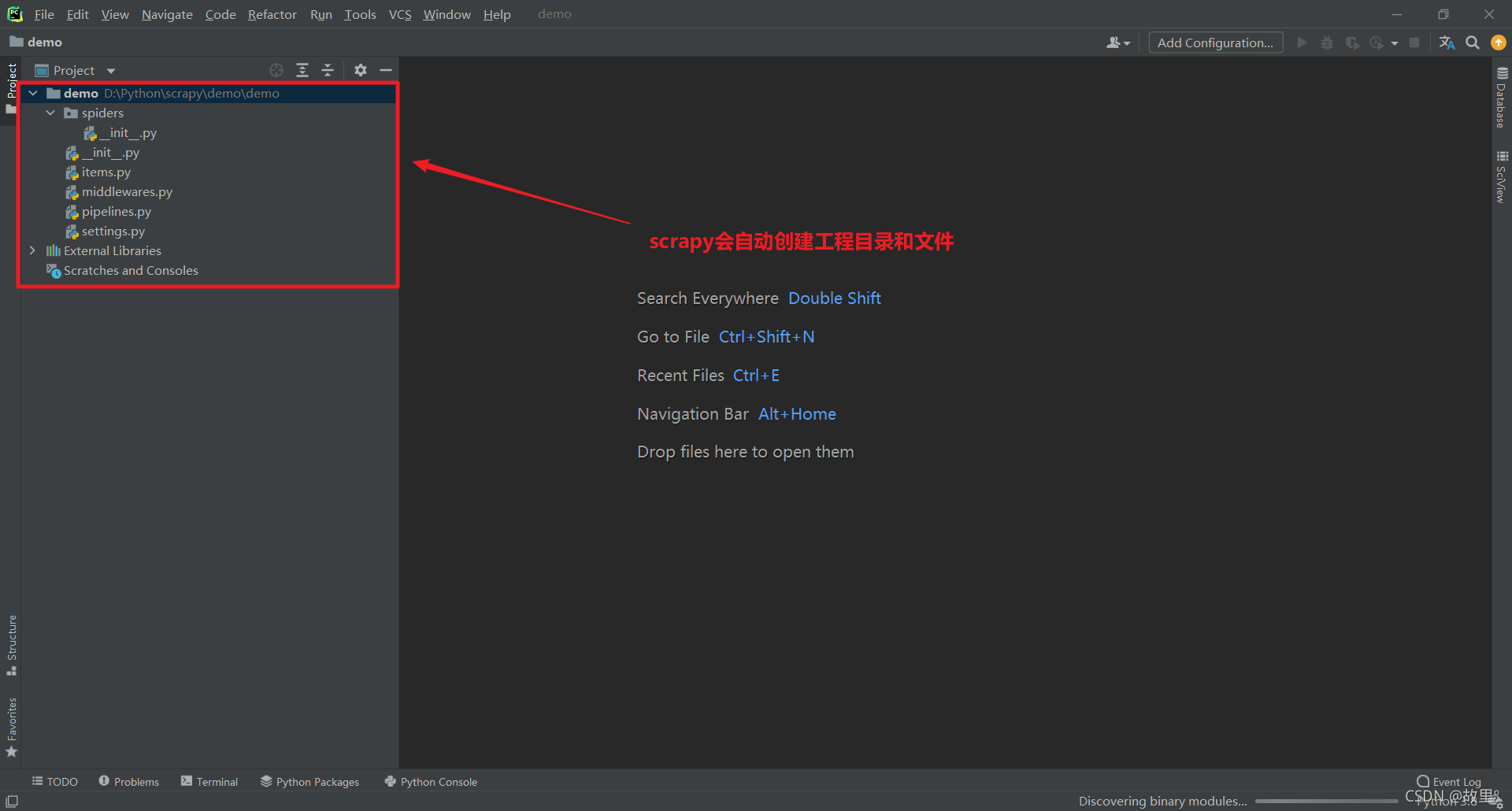
注意:專案的名稱不允許使用數字開頭,也不能包含中文!
2.創建爬蟲檔案:
注意:要在spiders檔案夾中去創建爬蟲檔案!
cd 專案名稱\專案名稱\spiders修改君子協定:
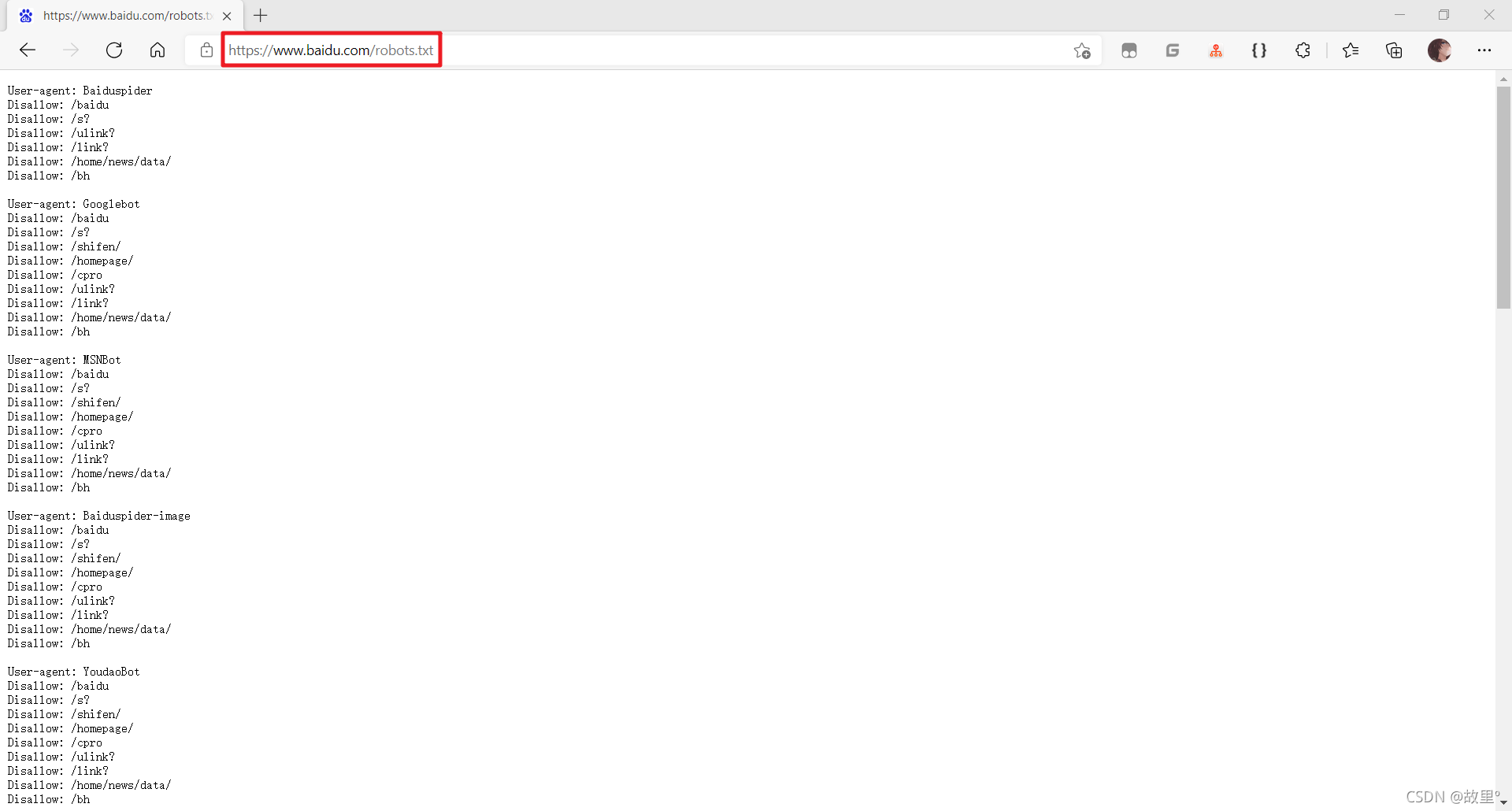
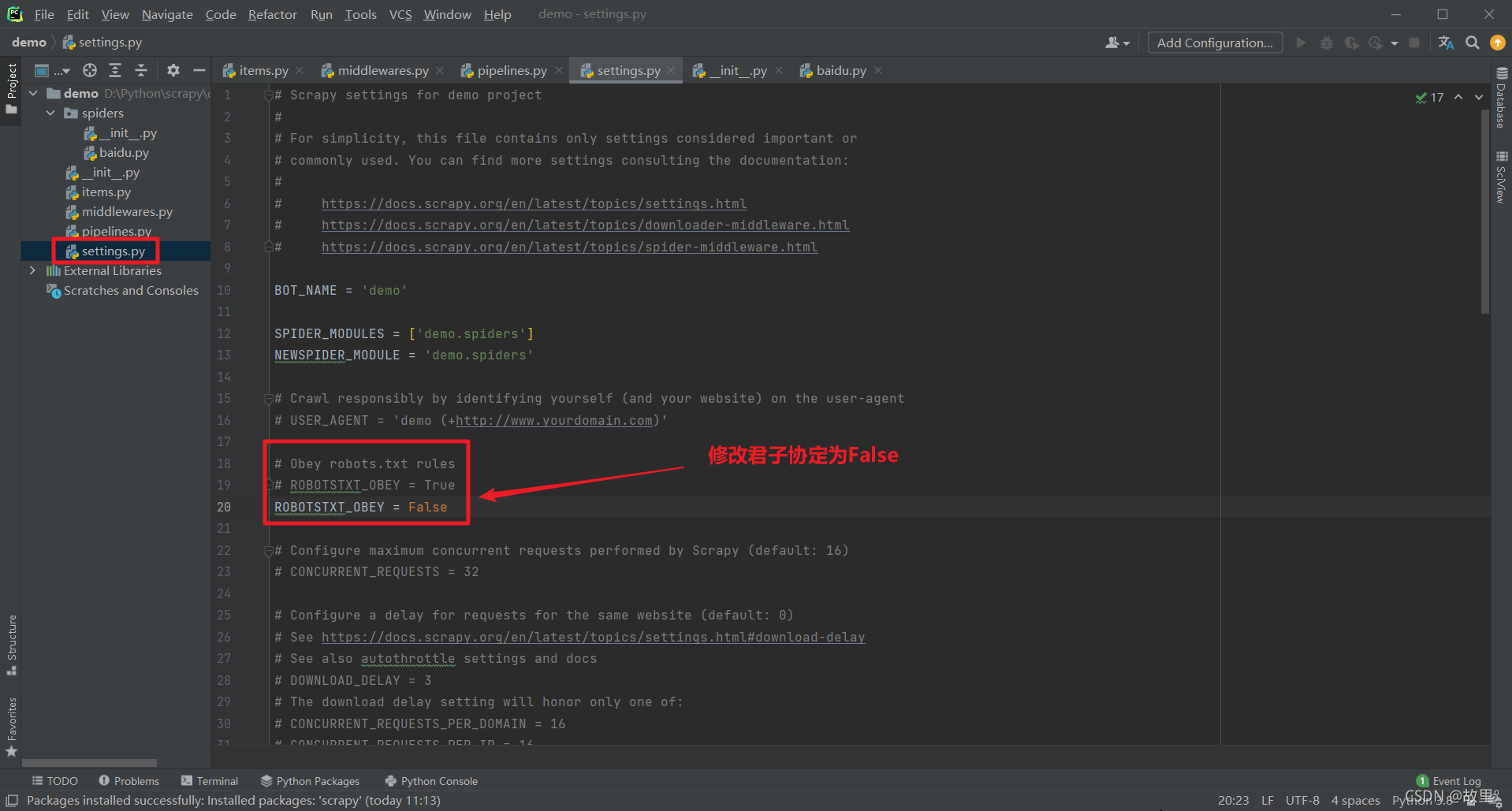
創建爬蟲檔案:
scrapy genspider 爬蟲檔案的名字 要爬取的網頁import scrapy
class BaiduSpider(scrapy.Spider):
# 爬蟲的名字 用于運行爬蟲的時候 url使用指:
name = 'baidu'
# 允許訪問的域名:
allowed_domains = ['https://www.baidu.com']
# 起始的url地址 指的是第一次要訪問的域名
# start_urls是在allowed_domains的前面添加一個http://,在allowed_domains后面添加一個/
start_urls = ['https://www.baidu.com/']
# 是執行了start_urls之后,執行的方法,方法中的response 就是回傳的那個物件
# 相當于 response = urllib.request.urlopen()
# response = request.get()
def parse(self, response):
print('------------------\n'
'------------------\n'
'------Hello-------\n'
'------World-------\n'
'------------------\n'
'------------------\n')
pass
執行爬蟲檔案:
scrapy crawl 爬蟲檔案檔案名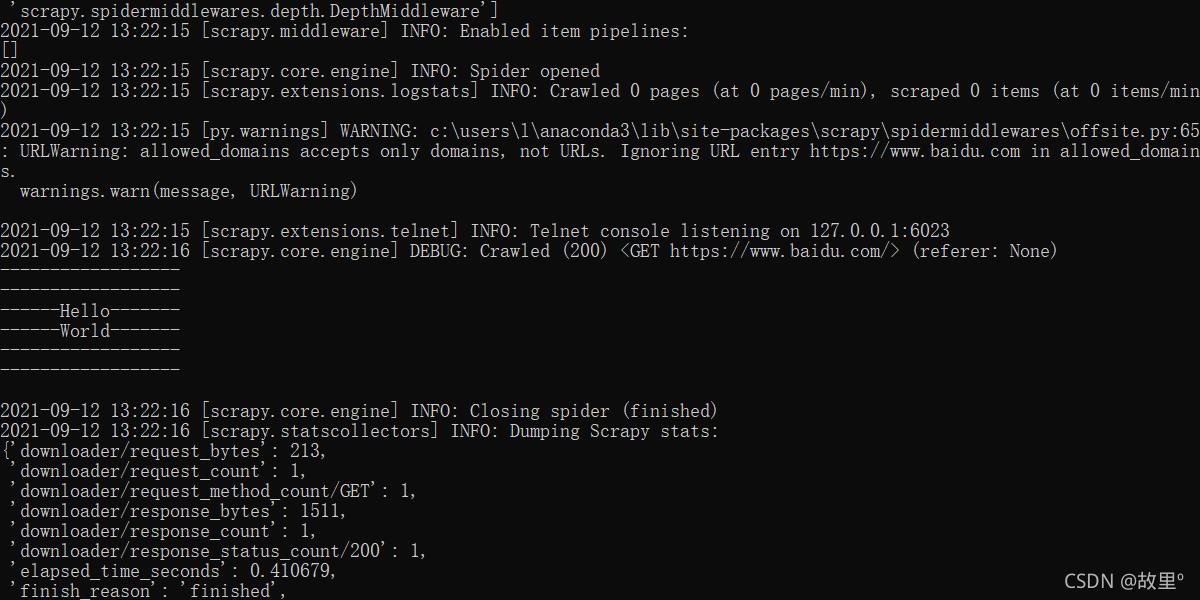
Scrapy專案結構:
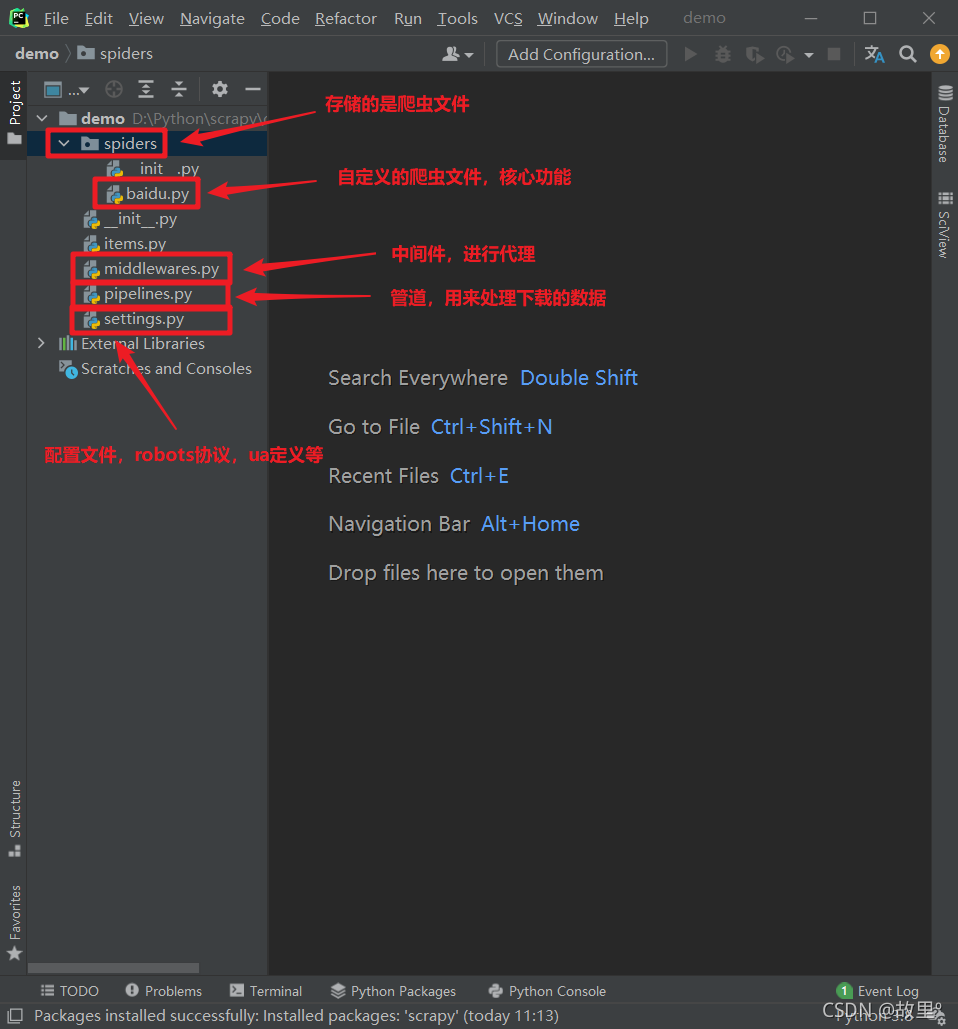
response的屬性和方法:

| response.text | 獲取的是回應的字串 |
| response.body | 獲取的是二進制資料 |
| response.xpath | 可以直接是xpath方法來決議response中的內容 |
| response.extract() | 提取selector物件的data屬性值 |
| response.extract_first() | 提取selector串列的第一個資料 |
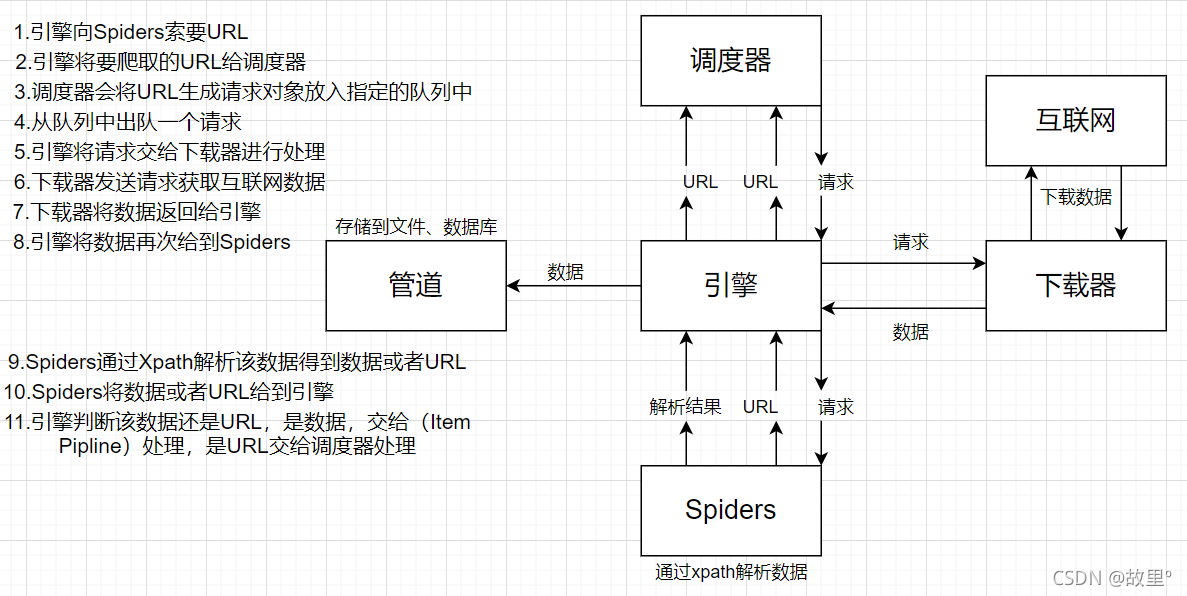
Scrapy架構組成:
- 引擎:自動運行,無需關注,會自動組織所有的請求物件,分發給下載器,
- 下載器:從引擎處獲取請求物件后,請求資料,
- Spiders:Spider類定義了如何爬取某個(某些)網站,包括爬取的動作(例如:是否跟進連接)以及如何從網頁的內容中提取結構化資料(爬取item),Sprider就是定義爬取的動作及分析某個網頁(或者有些網頁)的地方,
- 調度器:有自己的調度規則,無需關注,
- 管道(Item pipeIine):最終處理資料的管道,會預留介面進行資料處理,當Item正在Spider中被收集之后,它將會被傳遞到Item Pipline,一些組件會按照一定的順序執行對Item的處理,每個Item PipLine組件是實作了簡單方法的Python類,他們接收到Item并通過它執行一些行為,同時也決定此Item是否繼續通過pipiline或者是丟棄不再進行處理,
以下是item pipline的一些典型應用:
- 清理HTML資料
- 驗證爬取的資料(檢查item包含某些欄位)
- 查重(并丟棄)
- 將爬取的結果保存到資料庫中
Scrapy Shell:
Scrapy終端,是一個互動終端,可以在未啟動Spider的情況下嘗試及除錯爬蟲代碼,其本意是用來測驗和提取資料的代碼,不過可以被作為正常的Python終端,在上面測驗任何的Python代碼,
該終端用來測驗XPath或CSS運算式,查看他們的作業方式及從網頁中提取資料,在撰寫您的Spider時,該終端提供了互動性測驗您的運算式代碼的功能,免去了每次修改后運行Spider的麻煩,
一旦熟悉Scrapy終端后,就能發現其在開發和除錯Spider時發揮的巨大作用,
安裝:
pip install ipython
如果安裝了IPython,Scrapy終端將會使用IPython(代替標準Python終端),IPython終端與其他相比較更為強大,提供智能化的自動補全,高亮輸出,及其他特性,
應用:
直接在CMD中啟動后,會自動打開IPython終端:
scrapy shell URL地址(爬取指定目標地址)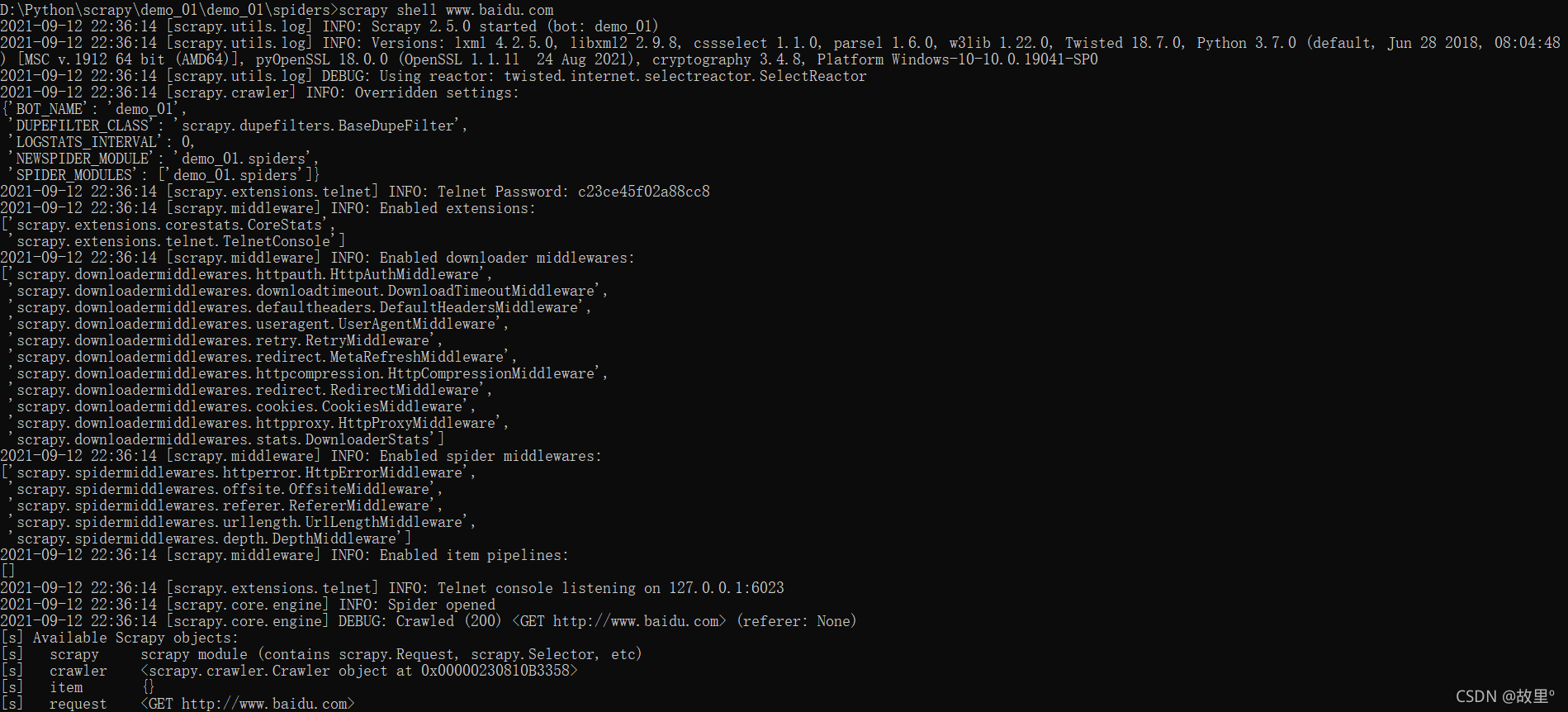

啟動IPthon終端:

| scrapy shell www.daidu.com |
| scrapy shell https://www.baidu.com |
| scrapy shell "https://www.baidu.com" |
| scrapy shell "www.baidu.com" |
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299986.html
標籤:python
上一篇:2021-09-13開啟編程