文章目錄
- 認識Flask
- Flask
- 了解框架
- 為什么要用Web框架
- Flask框架的誕生
- Flask擴展包
- 安裝環境
- 安裝Flask
- 安裝Flask依賴包
- 視圖
- 從 Hello World 開始
- 擴展
- 請求鉤子
- Flask裝飾器路由的實作:
- Flask-Script擴展命令列
- 模板
- 變數
- 反向路由:
- 自定義錯誤頁面:
- 過濾器:
- 字串操作:
- 自定義過濾器:
- Web表單:
- WTForms支持的HTML標準欄位
- WTForms常用驗證函式
- 在HTML頁面中直接寫form表單:
- 視圖函式中獲取表單資料:
- 控制陳述句
- 常用的幾種控制陳述句:
- 宏、繼承、包含
- 定義宏
- 模板繼承:
- 父模板:base.html
- 子模板:
- 包含(Include)
- Flask中的特殊變數和方法:
- config 物件:
- request 物件:
- 資料庫
- 資料庫安裝
- 資料庫的基本命令
- 使用Flask-SQLAlchemy管理資料庫
- 常用的SQLAlchemy欄位型別
- 常用的SQLAlchemy列選項
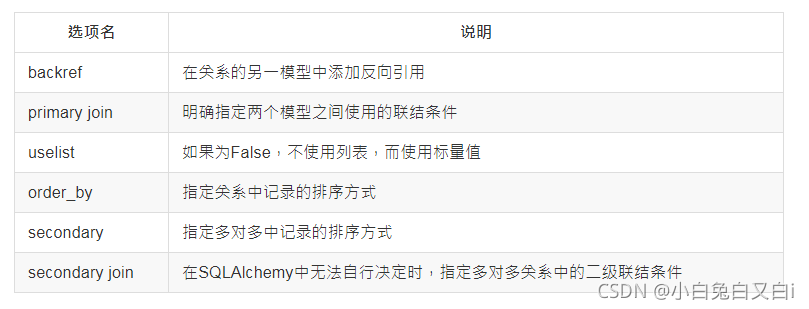
- 常用的SQLAlchemy關系選項
- 資料庫基本操作
- 在視圖函式中定義模型類
- 常用的SQLAlchemy查詢過濾器
- 常用的SQLAlchemy查詢執行器
- 查詢:filter_by精確查詢
- 查詢資料后洗掉
- 更新資料
- 自定義模型類
- 定義模型
- 資料庫遷移
- 創建遷移倉庫
- 創建遷移腳本
- Flask—Mail
- 測驗與部署
- 藍圖Blueprint
- 什么是藍圖?
- 藍圖的運行機制:
- 藍圖的使用:
- 動態路由示例(作者--圖書):
- 單元測驗
- 為什么要測驗?
- 什么是單元測驗?
- 發送郵件測驗:
- 資料庫測驗:
- 部署
- 使用Gunicorn:
- 安裝gunicorn
- 安裝Nginx
- Restful
- REST的特點:
- 如何設計符合RESTful風格的API:
- 一、域名:
- 二、版本:
- 三、路徑:
- 四、使用標準的HTTP方法:
- 五、過濾資訊:
- 六、狀態碼:
- 七、錯誤資訊:
- 八、回應結果:
- 九、使用鏈接關聯相關的資源:
- 十、其他:
- 性能
- 一、不同角度的網站性能
- 二、性能的指標
- 三、性能的優化
- 總結:
認識Flask
Flask
Flask相對于Django而言是輕量級的Web框架,和Django不同,Flask輕巧、簡潔,通過定制第三方擴展來實作具體功能,
可定制性,通過擴展增加其功能,這是Flask最重要的特點,Flask的兩個主要核心應用是Werkzeug和模板引擎Jinja,

了解框架
Flask作為Web框架,它的作用主要是為了開發Web應用程式,那么我們首先來了解下Web應用程式,Web應用程式 (World Wide Web)誕生最初的目的,是為了利用互聯網交流作業檔案,
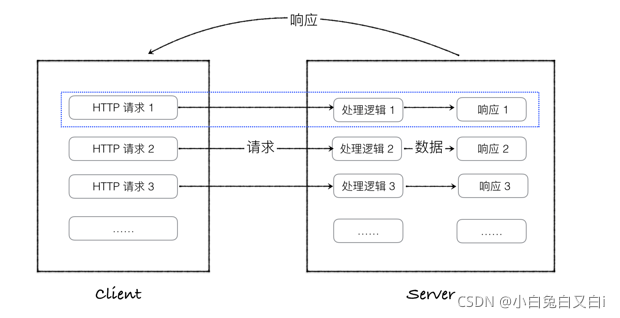
一切從客戶端發起請求開始,
- 所有Flask程式都必須創建一個程式實體, 當客戶端想要獲取資源時,一般會通過瀏覽器發起HTTP請求,
- 此時,Web服務器使用一種名為WEB服務器網關介面的WSGI(Web Server GatewayInterface)協議,把來自客戶端的請求都交給Flask程式實體
- Flask使用Werkzeug來做路由分發(URL請求和視圖函式之間的對應關系),根據每個URL請求,找到具體的視圖函式,
- 在Flask程式中,路由一般是通程序式實體的裝飾器實作,通過呼叫視圖函式,獲取到資料后,把資料傳入HTML模板檔案中,模板引擎負責渲染HTTP回應資料,然后由Flask回傳回應資料給瀏覽器,最后瀏覽器顯示回傳的結果,
為什么要用Web框架
web網站發展至今,特別是服務器端,涉及到的知識、內容,非常廣泛,這對程式員的要求會越來越高,如果采用成熟,穩健的框架,那么一些基礎的作業,比如,網路操作、資料庫訪問、會話管理等都可以讓框架來處理,那么程式開發人員可以把精力放在具體的業務邏輯上面,使用Web框架開發Web應用程式可以降低開發難度,提高開發效率,
總結一句話:避免重復造輪子,
Flask框架的誕生
Flask誕生于2010年,是Armin ronacher(人名)用Python語言基于Werkzeug工具箱撰寫的輕量級Web開發框架,它主要面向需求簡單的小應用,
Flask本身相當于一個內核,其他幾乎所有的功能都要用到擴展(郵件擴展Flask-Mail,用戶認證Flask-Login),都需要用第三方的擴展來實作,比如可以用Flask-extension加入ORM、表單驗證工具,檔案上傳、身份驗證等,Flask沒有默認使用的資料庫,你可以選擇MySQL,也可以用NoSQL,其 WSGI 工具箱采用 Werkzeug(路由模塊) ,模板引擎則使用 Jinja2 ,
可以說Flask框架的核心就是Werkzeug和Jinja2,
Python最出名的框架要數Django,此外還有Flask、Tornado等框架,雖然Flask不是最出名的框架,但是Flask應該算是最靈活的框架之一,這也是Flask受到廣大開發者喜愛的原因,
Flask擴展包
- Flask-SQLalchemy:操作資料庫;
- Flask-migrate:管理遷移資料庫;
- Flask-Mail:郵件;
- Flask-WTF:表單;
- Flask-script:插入腳本;
- Flask-Login:認證用戶狀態;
- Flask-RESTful:開發REST API的工具;
- Flask-Bootstrap:集成前端TwitterBootstrap框架;
- Flask-Moment:本地化日期和時間;
Flask官方檔案:
中文檔案
安裝環境
使用虛擬環境安裝Flask,可以避免包的混亂和版本的沖突,虛擬環境是Python解釋器的副本,在虛擬環境中你可以安裝擴展包,為每個程式單獨創建的虛擬環境,可以保證程式只能訪問虛擬環境中的包,而不會影響系統中安裝的全域Python解釋器,從而保證全域解釋器的整潔,
虛擬環境使用virtualenv創建,可以查看系統是否安裝了virtualenv:
$ virtualenv --version
安裝虛擬環境(須在聯網狀態下)
$ sudo pip install virtualenv
$ sudo pip install virtualenvwrapper
安裝完虛擬環境后,如果提示找不到mkvirtualenv命令,須配置環境變數:
# 1、創建目錄用來存放虛擬環境
mkdir $HOME/.virtualenvs
# 2、打開~/.bashrc檔案,并添加如下:
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
# 3、運行
source ~/.bashrc
創建虛擬環境(ubuntu里須在聯網狀態下)
$ mkvirtualenv Flask_py
進入虛擬環境
$ workon Flask_py
退出虛擬環境
如果所在環境為真實環境,會提示deactivate:未找到命令
$ deactivate Flask_py
安裝Flask
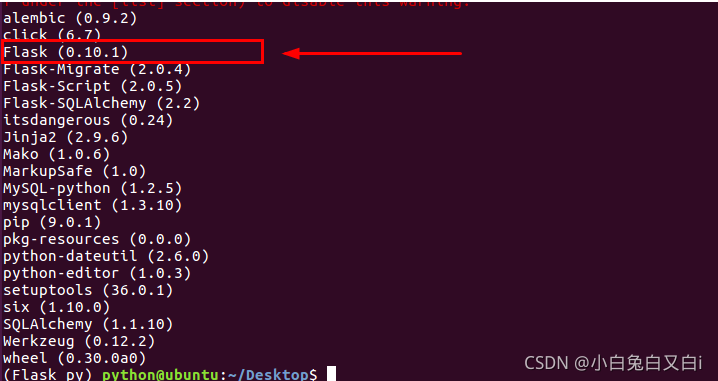
指定Flask版本安裝
$ pip install flask==0.10.1
Mac系統:
$ easy_install flask==0.10.1
安裝Flask依賴包
安裝依賴包(須在虛擬環境中): 依賴就是開發以及程式運行需要使用的環境的集合,包括軟體、插件等,我們一般會把需要使用的依賴給保存在一個檔案中,命名為requirements的txt檔案,如果在其它環境中要運行我們的專案,直接通過指令可以一次性安裝所有依賴,
安裝依賴包(須在虛擬環境中):
$ pip install -r requirements.txt
生成依賴包(須在虛擬環境中):
$ pip freeze > requirements.txt
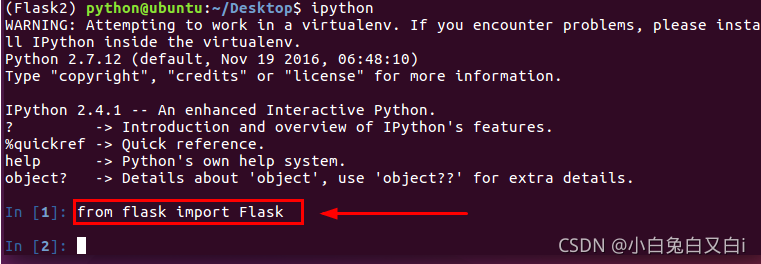
在ipython中測驗安裝是否成功
$ from flask import Flask
視圖
從 Hello World 開始
Flask程式運行程序:
所有Flask程式必須有一個程式實體,
Flask呼叫視圖函式后,會將視圖函式的回傳值作為回應的內容,回傳給客戶端,一般情況下,回應內容主要是字串和狀態碼,
當客戶端想要獲取資源時,一般會通過瀏覽器發起HTTP請求,此時,Web服務器使用WSGI(Web Server Gateway Interface)協議,把來自客戶端的所有請求都交給Flask程式實體,WSGI是為 Python 語言定義的Web服務器和Web應用程式之間的一種簡單而通用的介面,它封裝了接受HTTP請求、決議HTTP請求、發送HTTP,回應等等的這些底層的代碼和操作,使開發者可以高效的撰寫Web應用,
程式實體使用Werkzeug來做路由分發(URL請求和視圖函式之間的對應關系),根據每個URL請求,找到具體的視圖函式, 在Flask程式中,路由的實作一般是通程序式實體的route裝飾器實作,route裝飾器內部會呼叫add_url_route()方法實作路由注冊,
呼叫視圖函式,獲取回應資料后,把資料傳入HTML模板檔案中,模板引擎負責渲染回應資料,然后由Flask回傳回應資料給瀏覽器,最后瀏覽器處理回傳的結果顯示給客戶端,
示例:
新建檔案hello.py:
# 匯入Flask類
from flask import Flask
#Flask類接收一個引數__name__
app = Flask(__name__)
# 裝飾器的作用是將路由映射到視圖函式index
@app.route('/')
def index():
return 'Hello World'
# Flask應用程式實體的run方法啟動WEB服務器
if __name__ == '__main__':
app.run()
查看視圖函式中的路由:
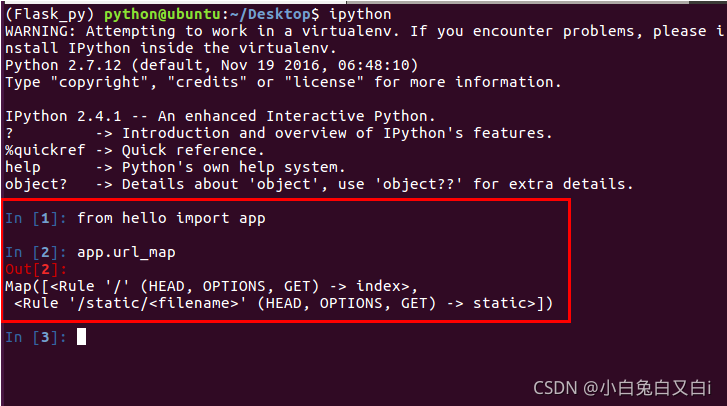
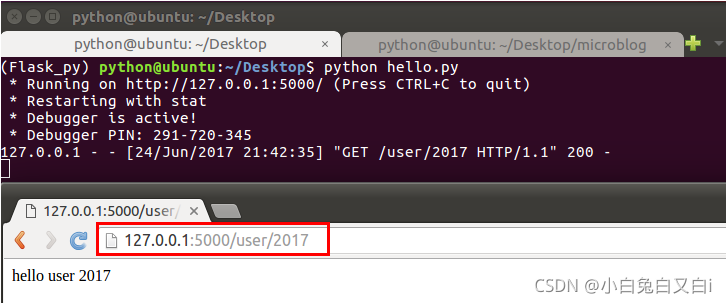
給路由傳參示例:
有時我們需要將同一類URL映射到同一個視圖函式處理,比如:使用同一個視圖函式 來顯示不同用戶的個人資訊,
# 路由傳遞的引數默認當做string處理,這里指定int,尖括號中冒號后面的內容是動態的
@app.route('/user/<int:id>')
def hello_itcast(id):
return 'hello itcast %d' %id
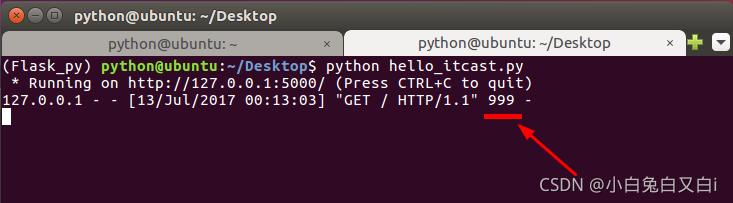
回傳狀態碼示例:
return后面可以自主定義狀態碼(即使這個狀態碼不存在),當客戶端的請求已經處理完成,由視圖函式決定回傳給客戶端一個狀態碼,告知客戶端這次請求的處理結果,
@app.route('/')
def hello_itcast():
return 'hello itcast',999
abort函式:
如果在視圖函式執行程序中,出現了例外錯誤,我們可以使用abort函式立即終止視圖函式的執行,通過abort函式,可以向前端回傳一個http標準中存在的錯誤狀態碼,表示出現的錯誤資訊,
使用abort拋出一個http標準中不存在的自定義的狀態碼,沒有實際意義,如果abort函式被觸發,其后面的陳述句將不會執行,其類似于python中raise,
from flask import Flask,abort
@app.route('/')
def hello_itcast():
abort(404)
return 'hello itcast',999
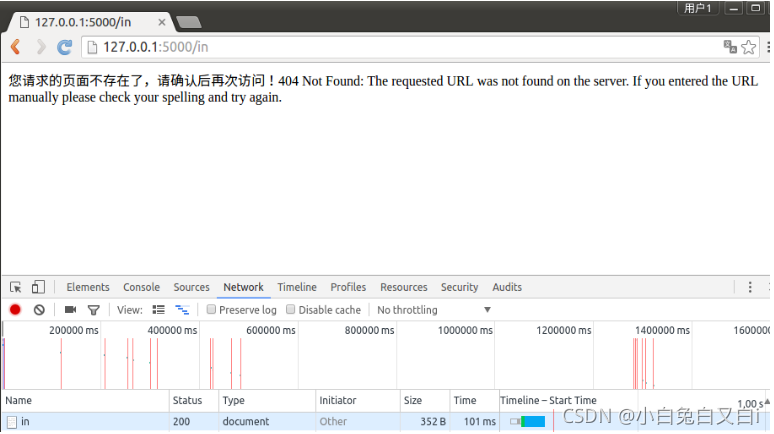
捕獲例外:
在Flask中通過裝飾器來實作捕獲例外,errorhandler()接收的引數為例外狀態碼,視圖函式的引數,回傳的是錯誤資訊,
@app.errorhandler(404)
def error(e):
return '您請求的頁面不存在了,請確認后再次訪問!%s'%e
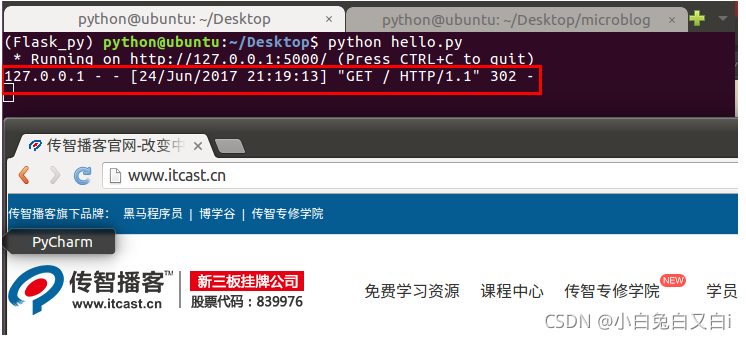
重定向redirect示例
from flask import redirect
@app.route('/')
def hello_itcast():
return redirect('http://www.itcast.cn')
正則URL示例:
正則URL是為了匹配指定的URL,而匹配指定的URL則可以達到限制訪問,以及優化訪問路徑的目的,
from flask import Flask
from werkzeug.routing import BaseConverter
class Regex_url(BaseConverter):
def __init__(self,url_map,*args):
super(Regex_url,self).__init__(url_map)
self.regex = args[0]
app = Flask(__name__)
app.url_map.converters['re'] = Regex_url
@app.route('/user/<re("[a-z]{3}"):id>')
def hello_itcast(id):
return 'hello %s' %id
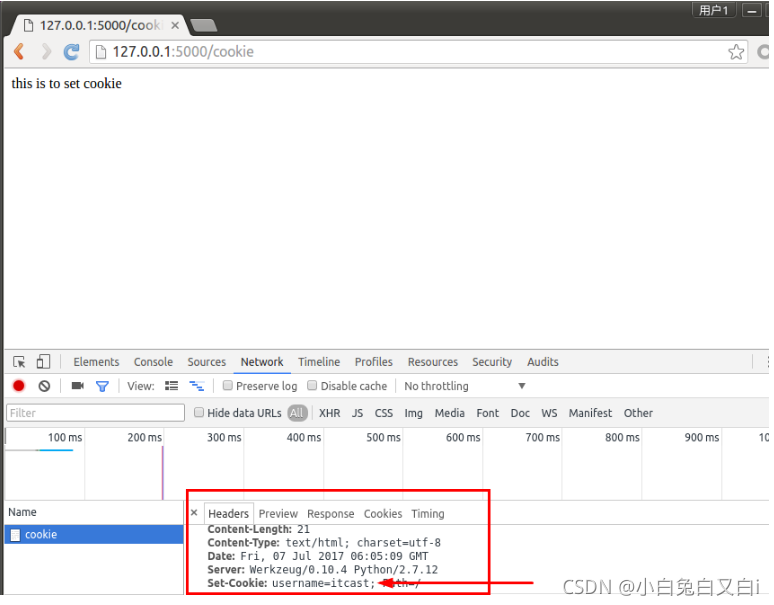
設定cookie和獲取cookie
from flask import Flask,make_response
@app.route('/cookie')
def set_cookie():
resp = make_response('this is to set cookie')
resp.set_cookie('username', 'itcast')
return resp
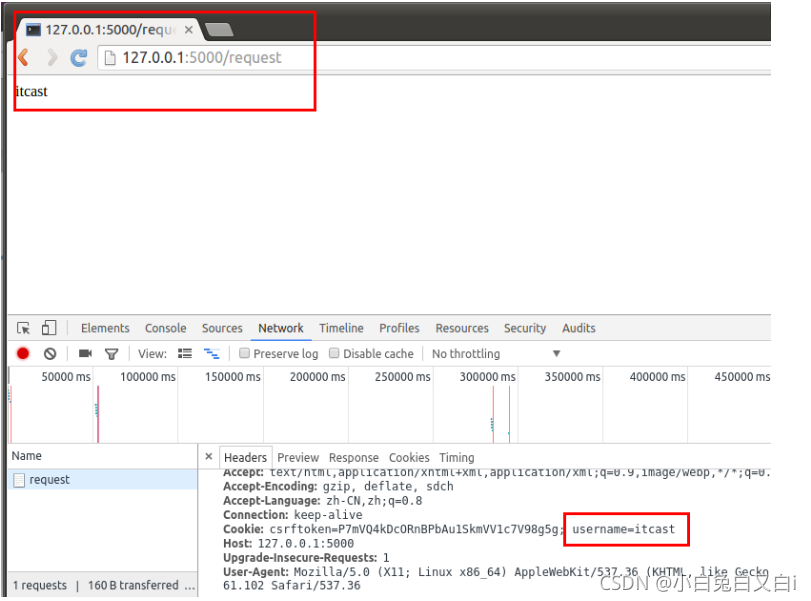
from flask import Flask,request
#獲取cookie
@app.route('/request')
def resp_cookie():
resp = request.cookies.get('username')
return resp
擴展
背景關系:相當于一個容器,保存了Flask程式運行程序中的一些資訊,
Flask中有兩種背景關系,請求背景關系和應用背景關系,
請求背景關系(request context)
request和session都屬于請求背景關系物件,
request:封裝了HTTP請求的內容,針對的是http請求,舉例:user = request.args.get(‘user’),獲取的是get請求的引數,
session:用來記錄請求會話中的資訊,針對的是用戶資訊,舉例:session[‘name’] = user.id,可以記錄用戶資訊,還可以通過session.get(‘name’)獲取用戶資訊,
應用背景關系(application context)
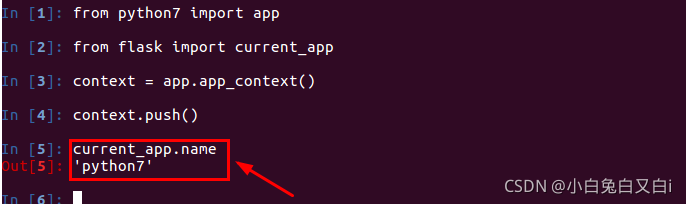
current_app和g都屬于應用背景關系物件,
current_app:表示當前運行程式檔案的程式實體,我們可以通過current_app.name列印出當前應用程式實體的名字,
g:處理請求時,用于臨時存盤的物件,每次請求都會重設這個變數,比如:我們可以獲取一些臨時請求的用戶資訊,
- 當呼叫app = Flask(name)的時候,創建了程式應用物件app;
- request 在每次http請求發生時,WSGI
server呼叫Flask.call();然后在Flask內部創建的request物件; - app的生命周期大于request和g,一個app存活期間,可能發生多次http請求,所以就會有多個request和g,
- 最終傳入視圖函式,通過return、redirect或render_template生成response物件,回傳給客戶端,
區別: 請求背景關系:保存了客戶端和服務器互動的資料, 應用背景關系:在flask程式運行程序中,保存的一些配置資訊,比如程式檔案名、資料庫的連接、用戶資訊等,
請求鉤子
在客戶端和服務器互動的程序中,有些準備作業或掃尾作業需要處理,比如:在請求開始時,建立資料庫連接;在請求結束時,指定資料的互動格式,為了讓每個視圖函式避免撰寫重復功能的代碼,Flask提供了通用設施的功能,即請求鉤子,
請求鉤子是通過裝飾器的形式實作,Flask支持如下四種請求鉤子:
before_first_request:在處理第一個請求前運行,
before_request:在每次請求前運行,
after_request:如果沒有未處理的例外拋出,在每次請求后運行,
teardown_request:在每次請求后運行,即使有未處理的例外拋出,
Flask裝飾器路由的實作:
Flask有兩大核心:Werkzeug和Jinja2,Werkzeug實作路由、除錯和Web服務器網關介面,Jinja2實作了模板,
Werkzeug是一個遵循WSGI協議的python函式庫,其內部實作了很多Web框架底層的東西,比如request和response物件;與WSGI規范的兼容;支持Unicode;支持基本的會話管理和簽名Cookie;集成URL請求路由等,
Werkzeug庫的routing模塊負責實作URL決議,不同的URL對應不同的視圖函式,routing模塊會對請求資訊的URL進行決議,匹配到URL對應的視圖函式,以此生成一個回應資訊,
routing模塊內部有Rule類(用來構造不同的URL模式的物件)、Map類(存盤所有的URL規則)、MapAdapter類(負責具體URL匹配的作業);
Flask-Script擴展命令列
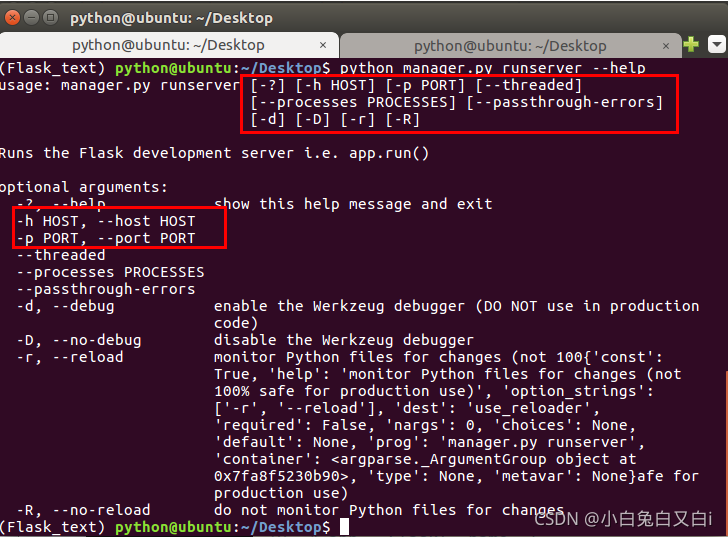
通過使用Flask-Script擴展,我們可以在Flask服務器啟動的時候,通過命令列的方式傳入引數,而不僅僅通過app.run()方法中傳參,比如我們可以通過python hello.py runserver --host ip地址,告訴服務器在哪個網路介面監聽來自客戶端的連接,默認情況下,服務器只監聽來自服務器所在計算機發起的連接,即localhost連接,
我們可以通過python hello.py runserver --help來查看引數,
from flask import Flask
from flask_script import Manager
app = Flask(__name__)
manager = Manager(app)
@app.route('/')
def index():
return '床前明月光'
if __name__ == "__main__":
manager.run()
模板
在前面的示例中,視圖函式的主要作用是生成請求的回應,這是最簡單的請求,實際上,視圖函式有兩個作用:處理業務邏輯和回傳回應內容,在大型應用中,把業務邏輯和表現內容放在一起,會增加代碼的復雜度和維護成本,本節學到的模板,它的作用即是承擔視圖函式的另一個作用,即回傳回應內容,
模板其實是一個包含回應文本的檔案,其中用占位符(變數)表示動態部分,告訴模板引擎其具體值需要從使用的資料中獲取,使用真實值替換變數,再回傳最終得到的字串,這個程序稱為“渲染”,
Flask使用Jinja2這個模板引擎來渲染模板,Jinja2能識別所有型別的變數,包括{}, Jinja2模板引擎,Flask提供的render_template函式封裝了該模板引擎,render_template函式的第一個引數是模板的檔案名,后面的引數都是鍵值對,表示模板中變數對應的真實值,
Jinja2官方檔案(http://docs.jinkan.org/docs/jinja2/)
我們先來認識下模板的基本語法:
{% if user %}
{{ user }}
{% else %}
hello!
<ul>
{% for index in indexs %}
<li> {{ index }} </li>
{% endfor %}
</ul>
通過修改一下前面的示例,來學習下模板的簡單使用:
@app.route('/')
def hello_itcast():
return render_template('index.html')
@app.route('/user/<name>')
def hello_user(name):
return render_template('index.html',name=name)
變數
在模板中{{ variable }}結構表示變數,是一種特殊的占位符,告訴模板引擎這個位置的值,從渲染模板時使用的資料中獲取;Jinja2除了能識別基本型別的變數,還能識別{};
<p>{{mydict['key']}}</p>
<p>{{mylist[1]}}</p>
<p>{{mylist[myvariable]}}</p>
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def index():
mydict = {'key':'silence is gold'}
mylist = ['Speech', 'is','silver']
myintvar = 0
return render_template('vars.html',
mydict=mydict,
mylist=mylist,
myintvar=myintvar
)
if __name__ == '__main__':
app.run(debug=True)
反向路由:
Flask提供了url_for()輔助函式,可以使用程式URL映射中保存的資訊生成URL;url_for()接收視圖函式名作為引數,回傳對應的URL;
如呼叫url_for(‘index’,_external=True)回傳的是絕對地址,在下面這個示例中是http://127.0.0.1:5000/index,
@app.route('/index')
def index():
return render_template('index.html')
@app.route('/user/')
def redirect():
return url_for('index',_external=True)
自定義錯誤頁面:
from flask import Flask,render_template
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
過濾器:
過濾器的本質就是函式,有時候我們不僅僅只是需要輸出變數的值,我們還需要修改變數的顯示,甚至格式化、運算等等,這就用到了過濾器,
過濾器的使用方式為:變數名 | 過濾器, 過濾器名寫在變數名后面,中間用 | 分隔,如:{{variable | capitalize}},這個過濾器的作用:把變數variable的值的首字母轉換為大寫,其他字母轉換為小寫, 其他常用過濾器如下:
字串操作:
safe:禁用轉義;
<p>{{ '<em>hello</em>' | safe }}</p>
capitalize:把變數值的首字母轉成大寫,其余字母轉小寫;
<p>{{ 'hello' | capitalize }}</p>
lower:把值轉成小寫;
<p>{{ 'HELLO' | lower }}</p>
upper:把值轉成大寫;
<p>{{ 'hello' | upper }}</p>
title:把值中的每個單詞的首字母都轉成大寫;
<p>{{ 'hello' | title }}</p>
trim:把值的首尾空格去掉;
<p>{{ ' hello world ' | trim }}</p>
reverse:字串反轉;
<p>{{ 'olleh' | reverse }}</p>
format:格式化輸出;
<p>{{ '%s is %d' | format('name',17) }}</p>
striptags:渲染之前把值中所有的HTML標簽都刪掉;
<p>{{ '<em>hello</em>' | striptags }}</p>
串列操作
first:取第一個元素
<p>{{ [1,2,3,4,5,6] | first }}</p>
last:取最后一個元素
<p>{{ [1,2,3,4,5,6] | last }}</p>
length:獲取串列長度
<p>{{ [1,2,3,4,5,6] | length }}</p>
sum:串列求和
<p>{{ [1,2,3,4,5,6] | sum }}</p>
sort:串列排序
<p>{{ [6,2,3,1,5,4] | sort }}</p>
陳述句塊過濾(不常用):
{% filter upper %}
this is a Flask Jinja2 introduction
{% endfilter %}
自定義過濾器:
過濾器的本質是函式,當模板內置的過濾器不能滿足需求,可以自定義過濾器,自定義過濾器有兩種實作方式:一種是通過Flask應用物件的add_template_filter方法,還可以通過裝飾器來實作自定義過濾器,
自定義的過濾器名稱如果和內置的過濾器重名,會覆寫內置的過濾器,
**實作方式一:**通過呼叫應用程式實體的add_template_filter方法實作自定義過濾器,該方法第一個引數是函式名,第二個引數是自定義的過濾器名稱,
def filter_double_sort(ls):
return ls[::2]
app.add_template_filter(filter_double_sort,'double_2')
**實作方式二:**用裝飾器來實作自定義過濾器,裝飾器傳入的引數是自定義的過濾器名稱,
@app.template_filter('db3')
def filter_double_sort(ls):
return ls[::-3]
Web表單:
web表單是web應用程式的基本功能,
它是HTML頁面中負責資料采集的部件,表單有三個部分組成:表單標簽、表單域、表單按鈕,表單允許用戶輸入資料,負責HTML頁面資料采集,通過表單將用戶輸入的資料提交給服務器,
在Flask中,為了處理web表單,我們一般使用Flask-WTF擴展,它封裝了WTForms,并且它有驗證表單資料的功能,
WTForms支持的HTML標準欄位

WTForms常用驗證函式
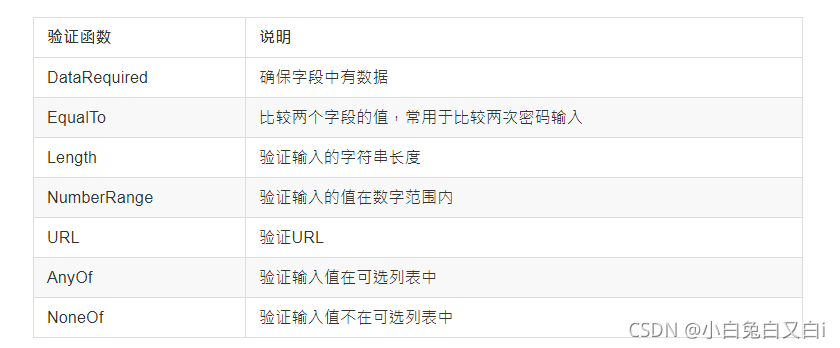
使用Flask-WTF需要配置引數SECRET_KEY,
CSRF_ENABLED是為了CSRF(跨站請求偽造)保護, SECRET_KEY用來生成加密令牌,當CSRF激活的時候,該設定會根據設定的密匙生成加密令牌,
在HTML頁面中直接寫form表單:
#模板檔案
<form method='post'>
<input type="text" name="username" placeholder='Username'>
<input type="password" name="password" placeholder='password'>
<input type="submit">
</form>
視圖函式中獲取表單資料:
from flask import Flask,render_template,request
@app.route('/login',methods=['GET','POST'])
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
print username,password
return render_template('login.html',method=request.method)
使用Flask-WTF實作表單,
配置引數:
app.config['SECRET_KEY'] = 'silents is gold'
模板頁面:
<form method="post">
#設定csrf_token
{{ form.csrf_token() }}
{{ form.us.label }}
<p>{{ form.us }}</p>
{{ form.ps.label }}
<p>{{ form.ps }}</p>
{{ form.ps2.label }}
<p>{{ form.ps2 }}</p>
<p>{{ form.submit() }}</p>
{% for x in get_flashed_messages() %}
{{ x }}
{% endfor %}
</form>
視圖函式:
#coding=utf-8
from flask import Flask,render_template,\
redirect,url_for,session,request,flash
#匯入wtf擴展的表單類
from flask_wtf import FlaskForm
#匯入自定義表單需要的欄位
from wtforms import SubmitField,StringField,PasswordField
#匯入wtf擴展提供的表單驗證器
from wtforms.validators import DataRequired,EqualTo
app = Flask(__name__)
app.config['SECRET_KEY']='1'
#自定義表單類,文本欄位、密碼欄位、提交按鈕
class Login(Form):
us = StringField(label=u'用戶:',validators=[DataRequired()])
ps = PasswordField(label=u'密碼',validators=[DataRequired(),EqualTo('ps2','err')])
ps2 = PasswordField(label=u'確認密碼',validators=[DataRequired()])
submit = SubmitField(u'提交')
@app.route('/login')
def login():
return render_template('login.html')
#定義根路由視圖函式,生成表單物件,獲取表單資料,進行表單資料驗證
@app.route('/',methods=['GET','POST'])
def index():
form = Login()
if form.validate_on_submit():
name = form.us.data
pswd = form.ps.data
pswd2 = form.ps2.data
print name,pswd,pswd2
return redirect(url_for('login'))
else:
if request.method=='POST':
flash(u'資訊有誤,請重新輸入!')
print form.validate_on_submit()
return render_template('index.html',form=form)
if __name__ == '__main__':
app.run(debug=True)
控制陳述句
常用的幾種控制陳述句:
模板中的if控制陳述句
@app.route('/user')
def user():
user = 'dongGe'
return render_template('user.html',user=user)
<html>
<head>
{% if user %}
<title> hello {{user}} </title>
{% else %}
<title> welcome to flask </title>
{% endif %}
</head>
<body>
<h1>hello world</h1>
</body>
</html>
模板中的for回圈陳述句
@app.route('/loop')
def loop():
fruit = ['apple','orange','pear','grape']
return render_template('loop.html',fruit=fruit)
<html>
<head>
{% if user %}
<title> hello {{user}} </title>
{% else %}
<title> welcome to flask </title>
{% endif %}
</head>
<body>
<h1>hello world</h1>
<ul>
{% for index in fruit %}
<li>{{ index }}</li>
{% endfor %}
</ul>
</body>
</html>
宏、繼承、包含
類似于python中的函式,宏的作用就是在模板中重復利用代碼,避免代碼冗余,
Jinja2支持宏,還可以匯入宏,需要在多處重復使用的模板代碼片段可以寫入單獨的檔案,再包含在所有模板中,以避免重復,
定義宏
{% macro input() %}
<input type="text"
name="username"
value=""
size="30"/>
{% endmacro %}
呼叫宏
{{ input() }}
定義帶引數的宏
{% macro input(name,value='',type='text',size=20) %}
<input type="{{ type }}"
name="{{ name }}"
value="{{ value }}"
size="{{ size }}"/>
{% endmacro %}
呼叫宏,并傳遞引數
{{ input(value='name',type='password',size=40)}}
把宏單獨抽取出來,封裝成html檔案,其它模板中匯入使用
檔案名可以自定義macro.html
{% macro function() %}
<input type="text" name="username" placeholde="Username">
<input type="password" name="password" placeholde="Password">
<input type="submit">
{% endmacro %}
在其它模板檔案中先匯入,再呼叫
{% import 'macro.html' as func %}
{% func.function() %}
模板繼承:
模板繼承是為了重用模板中的公共內容,一般Web開發中,繼承主要使用在網站的頂部選單、底部,這些內容可以定義在父模板中,子模板直接繼承,而不需要重復書寫,
{% block top %}``{% endblock %}標簽定義的內容,相當于在父模板中挖個坑,當子模板繼承父模板時,可以進行填充,
子模板使用extends指令宣告這個模板繼承自哪?父模板中定義的塊在子模板中被重新定義,在子模板中呼叫父模板的內容可以使用super(),
父模板:base.html
{% block top %}
頂部選單
{% endblock top %}
{% block content %}
{% endblock content %}
{% block bottom %}
底部
{% endblock bottom %}
子模板:
{% extends 'base.html' %}
{% block content %}
需要填充的內容
{% endblock content %}
- 模板繼承使用時注意點:
- 不支持多繼承,
- 為了便于閱讀,在子模板中使用extends時,盡量寫在模板的第一行,
- 不能在一個模板檔案中定義多個相同名字的block標簽,
- 當在頁面中使用多個block標簽時,建議給結束標簽起個名字,當多個block嵌套時,閱讀性更好,
包含(Include)
Jinja2模板中,除了宏和繼承,還支持一種代碼重用的功能,叫包含(Include),它的功能是將另一個模板整個加載到當前模板中,并直接渲染,
示例:
include的使用
{\% include 'hello.html' %}
包含在使用時,如果包含的模板檔案不存在時,程式會拋出TemplateNotFound例外,可以加上ignore missing關鍵字,如果包含的模板檔案不存在,會忽略這條include陳述句,
示例:
include的使用加上關鍵字ignore missing
{\% include 'hello.html' ignore missing %}
宏、繼承、包含:
- 宏(Macro)、繼承(Block)、包含(include)均能實作代碼的復用,
- 繼承(Block)的本質是代碼替換,一般用來實作多個頁面中重復不變的區域,
- 宏(Macro)的功能類似函式,可以傳入引數,需要定義、呼叫,
- 包含(include)是直接將目標模板檔案整個渲染出來,
Flask中的特殊變數和方法:
在Flask中,有一些特殊的變數和方法是可以在模板檔案中直接訪問的,
config 物件:
config 物件就是Flask的config物件,也就是 app.config 物件,
{{ config.SQLALCHEMY_DATABASE_URI }}
request 物件:
就是 Flask 中表示當前請求的 request 物件,request物件中保存了一次HTTP請求的一切資訊,
request常用的屬性如下:
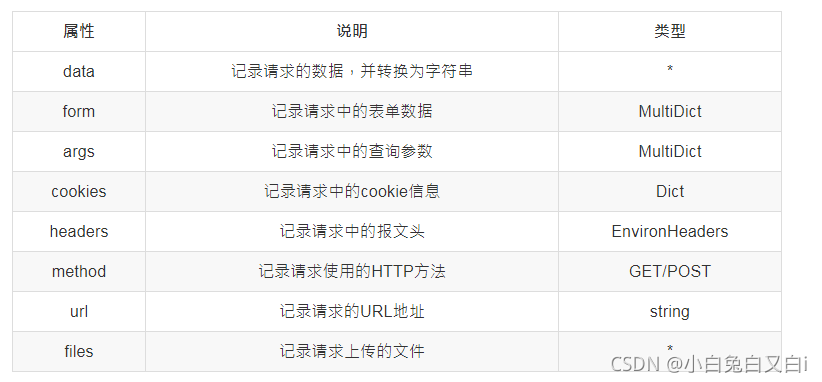
{{ request.url }}
url_for 方法:
url_for() 會回傳傳入的路由函式對應的URL,所謂路由函式就是被 app.route() 路由裝飾器裝飾的函式,如果我們定義的路由函式是帶有引數的,則可以將這些引數作為命名引數傳入,
{{ url_for('index') }}
{{ url_for('post', post_id=1024) }}
get_flashed_messages方法:
回傳之前在Flask中通過 flash() 傳入的資訊串列,把字串物件表示的訊息加入到一個訊息佇列中,然后通過呼叫 get_flashed_messages() 方法取出,
{% for message in get_flashed_messages() %}
{{ message }}
{% endfor %}
資料庫
資料庫的設定
Web應用中普遍使用的是關系模型的資料庫,關系型資料庫把所有的資料都存盤在表中,表用來給應用的物體建模,表的列數是固定的,行數是可變的,它使用結構化的查詢語言,關系型資料庫的列定義了表中表示的物體的資料屬性,比如:商品表里有name、price、number等,
Flask本身不限定資料庫的選擇,你可以選擇SQL或NOSQL的任何一種,也可以選擇更方便的SQLALchemy,類似于Django的ORM,SQLALchemy實際上是對資料庫的抽象,讓開發者不用直接和SQL陳述句打交道,而是通過Python物件來操作資料庫,在舍棄一些性能開銷的同時,換來的是開發效率的較大提升,
SQLAlchemy是一個關系型資料庫框架,它提供了高層的ORM和底層的原生資料庫的操作,flask-sqlalchemy是一個簡化了SQLAlchemy操作的flask擴展,
資料庫安裝
安裝服務端
sudo apt-get install mysql-server
安裝客戶端
sudo apt-get install mysql-client
sudo apt-get install libmysqlclient-dev
資料庫的基本命令
登錄資料庫
mysql -u root -p
創建資料庫,并設定編碼
create database <資料庫名> charset=utf8;
顯示所有資料庫
show databases;
在Flask中使用mysql資料庫,需要安裝一個flask-sqlalchemy的擴展,
pip install flask-sqlalchemy
要連接mysql資料庫,仍需要安裝flask-mysqldb
pip install flask-mysqldb
使用Flask-SQLAlchemy管理資料庫
使用Flask-SQLAlchemy擴展操作資料庫,首先需要建立資料庫連接,資料庫連接通過URL指定,而且程式使用的資料庫必須保存到Flask配置物件的SQLALCHEMY_DATABASE_URI鍵中,
對比下Django和Flask中的資料庫設定:
Django的資料庫設定:
Flask的資料庫設定:
app.config[‘SQLALCHEMY_DATABASE_URI’] ='mysql://root:mysql@127.0.0.1:3
常用的SQLAlchemy欄位型別
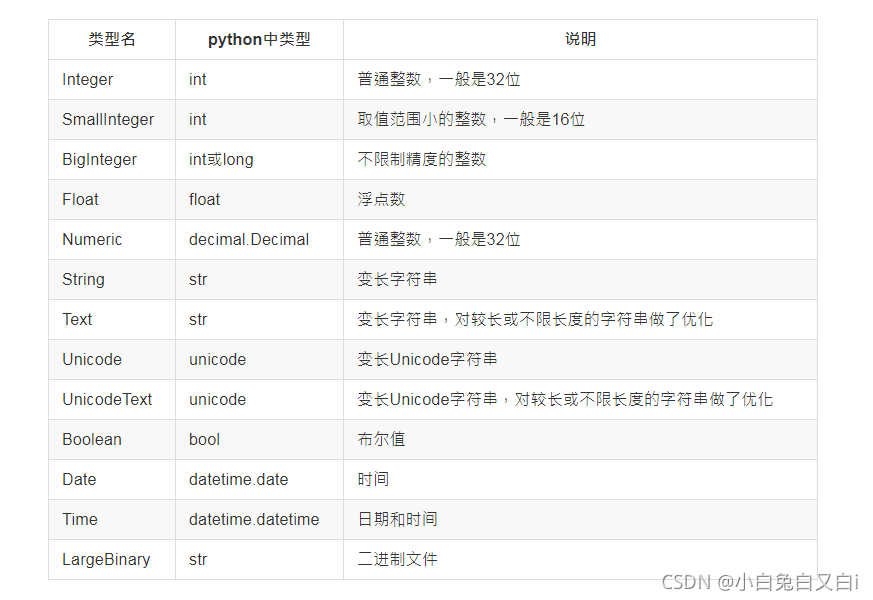
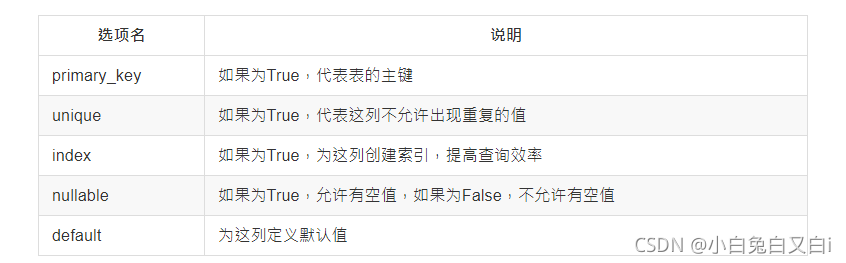
常用的SQLAlchemy列選項
常用的SQLAlchemy關系選項
資料庫基本操作
在Flask-SQLAlchemy中,插入、修改、洗掉操作,均由資料庫會話管理,會話用db.session表示,在準備把資料寫入資料庫前,要先將資料添加到會話中然后呼叫commit()方法提交會話,
資料庫會話是為了保證資料的一致性,避免因部分更新導致資料不一致,提交操作把會話物件全部寫入資料庫,如果寫入程序發生錯誤,整個會話都會失效,
資料庫會話也可以回滾,通過db.session.rollback()方法,實作會話提交資料前的狀態,
在Flask-SQLAlchemy中,查詢操作是通過query物件操作資料,最基本的查詢是回傳表中所有資料,可以通過過濾器進行更精確的資料庫查詢,
將資料添加到會話中示例:
user = User(name='python')
db.session.add(user)
db.session.commit()
在視圖函式中定義模型類
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
#設定連接資料庫的URL
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/Flask_test'
#設定每次請求結束后會自動提交資料庫中的改動
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#查詢時會顯示原始SQL陳述句
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
class Role(db.Model):
# 定義表名
__tablename__ = 'roles'
# 定義列物件
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
us = db.relationship('User', backref='role')
#repr()方法顯示一個可讀字串
def __repr__(self):
return 'Role:%s'% self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True, index=True)
email = db.Column(db.String(64),unique=True)
pswd = db.Column(db.String(64))
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
def __repr__(self):
return 'User:%s'%self.name
if __name__ == '__main__':
db.drop_all()
db.create_all()
ro1 = Role(name='admin')
ro2 = Role(name='user')
db.session.add_all([ro1,ro2])
db.session.commit()
us1 = User(name='wang',email='wang@163.com',pswd='123456',role_id=ro1.id)
us2 = User(name='zhang',email='zhang@189.com',pswd='201512',role_id=ro2.id)
us3 = User(name='chen',email='chen@126.com',pswd='987654',role_id=ro2.id)
us4 = User(name='zhou',email='zhou@163.com',pswd='456789',role_id=ro1.id)
db.session.add_all([us1,us2,us3,us4])
db.session.commit()
app.run(debug=True)
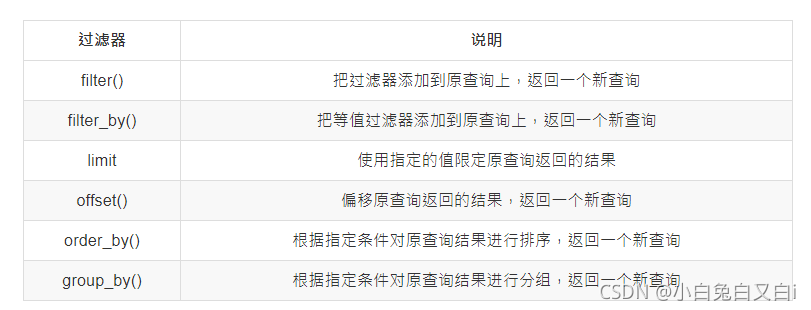
常用的SQLAlchemy查詢過濾器
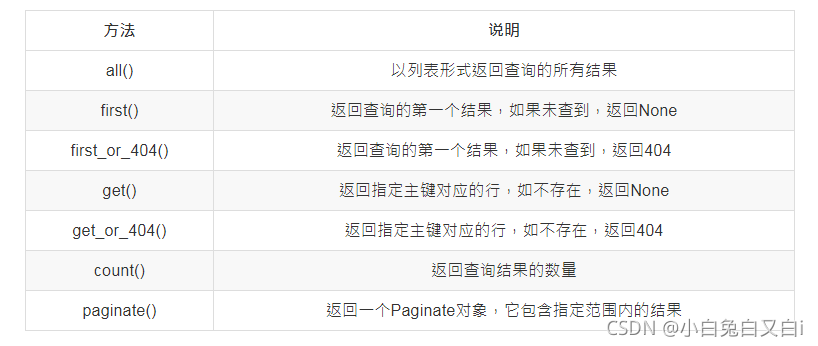
常用的SQLAlchemy查詢執行器
創建表:
db.create_all()
洗掉表
db.drop_all()
插入一條資料
ro1 = Role(name='admin')
db.session.add(ro1)
db.session.commit()
#再次插入一條資料
ro2 = Role(name='user')
db.session.add(ro2)
db.session.commit()
一次插入多條資料
us1 = User(name='wang',email='wang@163.com',pswd='123456',role_id=ro1.id)
us2 = User(name='zhang',email='zhang@189.com',pswd='201512',role_id=ro2.id)
us3 = User(name='chen',email='chen@126.com',pswd='987654',role_id=ro2.id)
us4 = User(name='zhou',email='zhou@163.com',pswd='456789',role_id=ro1.id)
db.session.add_all([us1,us2,us3,us4])
db.session.commit()
查詢:filter_by精確查詢
回傳名字等于wang的所有人
User.query.filter_by(name='wang').all()

first()回傳查詢到的第一個物件
User.query.first()
all()回傳查詢到的所有物件
User.query.all()

filter模糊查詢,回傳名字結尾字符為g的所有資料,
User.query.filter(User.name.endswith('g')).all()

get(),引數為主鍵,如果主鍵不存在沒有回傳內容
User.query.get()
邏輯非,回傳名字不等于wang的所有資料,
User.query.filter(User.name!='wang').all()

邏輯與,需要匯入and,回傳and()條件滿足的所有資料,
from sqlalchemy import and_
User.query.filter(and_(User.name!='wang',User.email.endswith('163.com'))).all()
and_
邏輯或,需要匯入or_
from sqlalchemy import or_
User.query.filter(or_(User.name!='wang',User.email.endswith('163.com'))).all()
or_
not_ 相當于取反
from sqlalchemy import not_
User.query.filter(not_(User.name=='chen')).all()
not_

查詢資料后洗掉
user = User.query.first()
db.session.delete(user)
db.session.commit()
User.query.all()
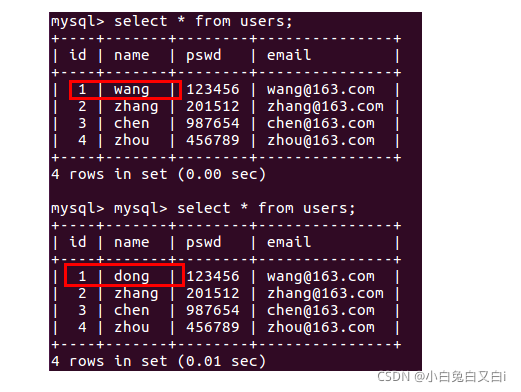
更新資料
user = User.query.first()
user.name = 'dong'
db.session.commit()
User.query.first()
使用update
User.query.filter_by(name='zhang').update({'name':'li'})

關聯查詢示例:角色和用戶的關系是一對多的關系,一個角色可以有多個用戶,一個用戶只能屬于一個角色,
查詢角色的所有用戶:
#查詢roles表id為1的角色
ro1 = Role.query.get(1)
#查詢該角色的所有用戶
ro1.us

查詢用戶所屬角色:
#查詢users表id為3的用戶
us1 = User.query.get(3)
#查詢用戶屬于什么角色
us1.role

自定義模型類
定義模型
模型表示程式使用的資料物體,在Flask-SQLAlchemy中,模型一般是Python類,繼承自db.Model,db是SQLAlchemy類的實體,代表程式使用的資料庫,
類中的屬性對應資料庫表中的列,id為主鍵,是由Flask-SQLAlchemy管理,db.Column類建構式的第一個引數是資料庫列和模型屬性型別,
如下示例:定義了兩個模型類,作者和書名,
#coding=utf-8
from flask import Flask,render_template,redirect,url_for
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
#設定連接資料
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test1'
#設定每次請求結束后會自動提交資料庫中的改動
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
#設定成 True,SQLAlchemy 將會追蹤物件的修改并且發送信號,這需要額外的記憶體, 如果不必要的可以禁用它,
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#實體化SQLAlchemy物件
db = SQLAlchemy(app)
#定義模型類-作者
class Author(db.Model):
__tablename__ = 'author'
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(32),unique=True)
email = db.Column(db.String(64))
au_book = db.relationship('Book',backref='author')
def __str__(self):
return 'Author:%s' %self.name
#定義模型類-書名
class Book(db.Model):
__tablename__ = 'books'
id = db.Column(db.Integer,primary_key=True)
info = db.Column(db.String(32),unique=True)
leader = db.Column(db.String(32))
au_book = db.Column(db.Integer,db.ForeignKey('author.id'))
def __str__(self):
return 'Book:%s,%s'%(self.info,self.lead)
創建表 db.create_all()
生成表

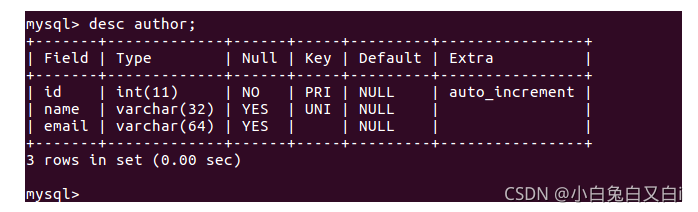
查看author表結構 desc author
查看author
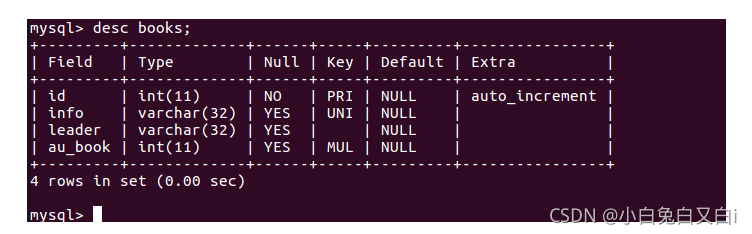
查看books表結構 desc books
#coding=utf-8
from flask import Flask,render_template,url_for,redirect,request
from flask_sqlalchemy import SQLAlchemy
from flask_wtf import FlaskForm
from wtforms.validators import DataRequired
from wtforms import StringField,SubmitField
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@localhost/test1'
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
app.config['SECRET_KEY']='s'
db = SQLAlchemy(app)
#創建表單類,用來添加資訊
class Append(Form):
au_info = StringField(validators=[DataRequired()])
bk_info = StringField(validators=[DataRequired()])
submit = SubmitField(u'添加')
@app.route('/',methods=['GET','POST'])
def index():
#查詢所有作者和書名資訊
author = Author.query.all()
book = Book.query.all()
#創建表單物件
form = Append()
if form.validate_on_submit():
#獲取表單輸入資料
wtf_au = form.au_info.data
wtf_bk = form.bk_info.data
#把表單資料存入模型類
db_au = Author(name=wtf_au)
db_bk = Book(info=wtf_bk)
#提交會話
db.session.add_all([db_au,db_bk])
db.session.commit()
#添加資料后,再次查詢所有作者和書名資訊
author = Author.query.all()
book = Book.query.all()
return render_template('index.html',author=author,book=book,form=form)
else:
if request.method=='GET':
render_template('index.html', author=author, book=book,form=form)
return render_template('index.html',author=author,book=book,form=form)
#洗掉作者
@app.route('/delete_author<id>')
def delete_author(id):
#精確查詢需要洗掉的作者id
au = Author.query.filter_by(id=id).first()
db.session.delete(au)
#直接重定向到index視圖函式
return redirect(url_for('index'))
#洗掉書名
@app.route('/delete_book<id>')
def delete_book(id):
#精確查詢需要洗掉的書名id
bk = Book.query.filter_by(id=id).first()
db.session.delete(bk)
#直接重定向到index視圖函式
return redirect(url_for('index'))
if __name__ == '__main__':
db.drop_all()
db.create_all()
#生成資料
au_xi = Author(name='我吃西紅柿',email='xihongshi@163.com')
au_qian = Author(name='蕭潛',email='xiaoqian@126.com')
au_san = Author(name='唐家三少',email='sanshao@163.com')
bk_xi = Book(info='吞噬星空',lead='羅峰')
bk_xi2 = Book(info='寸芒',lead='李楊')
bk_qian = Book(info='飄渺之旅',lead='李強')
bk_san = Book(info='冰火魔廚',lead='融念冰')
#把資料提交給用戶會話
db.session.add_all([au_xi,au_qian,au_san,bk_xi,bk_xi2,bk_qian,bk_san])
#提交會話
db.session.commit()
app.run(debug=True)
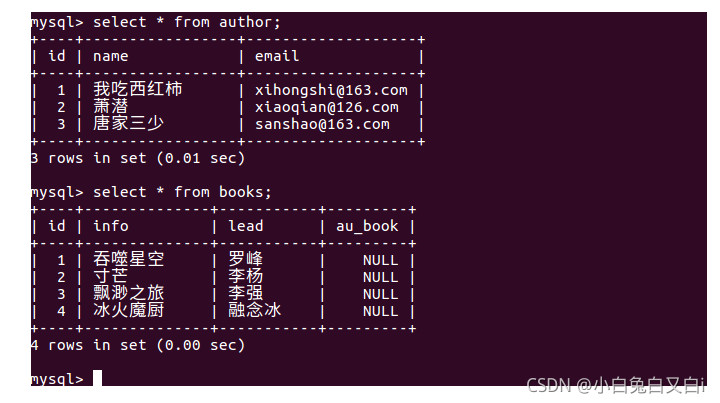
生成資料后,查看資料:
模板頁面示例:
<h1>玄幻系列</h1>
<form method="post">
{{ form.csrf_token }}
<p>作者:{{ form.au_info }}</p>
<p>書名:{{ form.bk_info }}</p>
<p>{{ form.submit }}</p>
</form>
<ul>
<li>{% for x in author %}</li>
<li>{{ x }}</li><a href='/delete_author{{ x.id }}'>洗掉</a>
<li>{% endfor %}</li>
</ul>
<hr>
<ul>
<li>{% for x in book %}</li>
<li>{{ x }}</li><a href='/delete_book{{ x.id }}'>洗掉</a>
<li>{% endfor %}</li>
</ul>
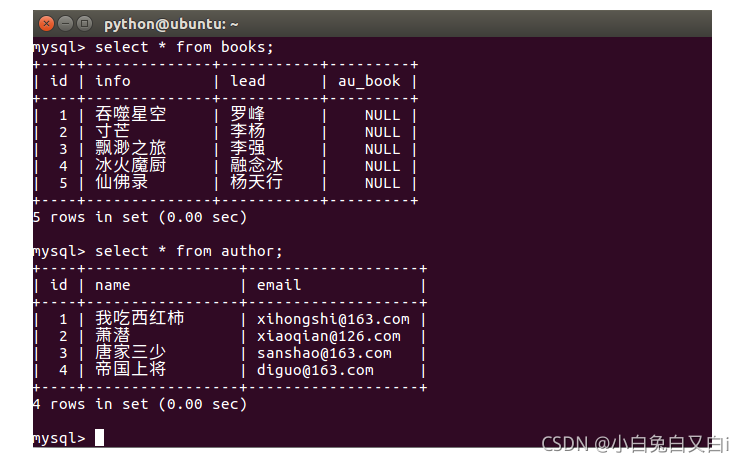
添加資料后,查看資料:
資料庫遷移
在開發程序中,需要修改資料庫模型,而且還要在修改之后更新資料庫,最直接的方式就是洗掉舊表,但這樣會丟失資料,
更好的解決辦法是使用資料庫遷移框架,它可以追蹤資料庫模式的變化,然后把變動應用到資料庫中,
在Flask中可以使用Flask-Migrate擴展,來實作資料遷移,并且集成到Flask-Script中,所有操作通過命令就能完成,
為了匯出資料庫遷移命令,Flask-Migrate提供了一個MigrateCommand類,可以附加到flask-script的manager物件上,
首先要在虛擬環境中安裝Flask-Migrate,
pip install flask-migrate
檔案:database.py
#coding=utf-8
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate,MigrateCommand
from flask_script import Shell,Manager
app = Flask(__name__)
manager = Manager(app)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/Flask_test'
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
db = SQLAlchemy(app)
#第一個引數是Flask的實體,第二個引數是Sqlalchemy資料庫實體
migrate = Migrate(app,db)
#manager是Flask-Script的實體,這條陳述句在flask-Script中添加一個db命令
manager.add_command('db',MigrateCommand)
#定義模型Role
class Role(db.Model):
# 定義表名
__tablename__ = 'roles'
# 定義列物件
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return 'Role:'.format(self.name)
#定義用戶
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return 'User:'.format(self.username)
if __name__ == '__main__':
manager.run()
創建遷移倉庫
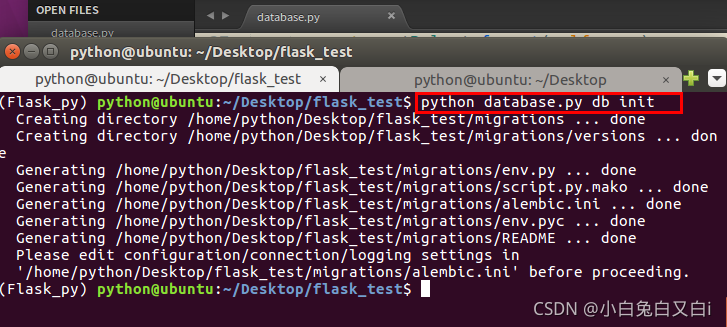
#這個命令會創建migrations檔案夾,所有遷移檔案都放在里面,
python database.py db init
創建遷移腳本
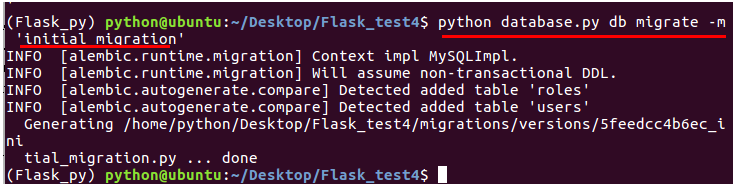
自動創建遷移腳本有兩個函式,upgrade()函式把遷移中的改動應用到資料庫中,downgrade()函式則將改動洗掉,自動創建的遷移腳本會根據模型定義和資料庫當前狀態的差異,生成upgrade()和downgrade()函式的內容,對比不一定完全正確,有可能會遺漏一些細節,需要進行檢查
#創建自動遷移腳本
python database.py db migrate -m 'initial migration'
更新資料庫
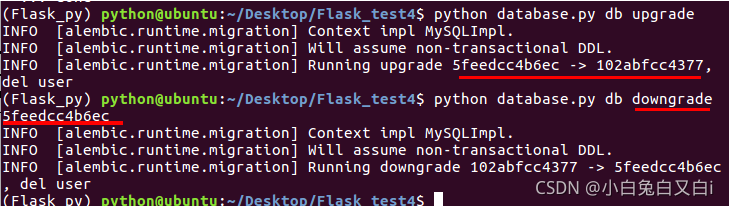
python database.py db upgrade
回退資料庫
回退資料庫時,需要指定回退版本號,由于版本號是隨機字串,為避免出錯,建議先使用python database.py db history命令查看歷史版本的具體版本號,然后復制具體版本號執行回退,
python database.py db downgrade 版本號
Flask—Mail
在開發程序中,很多應用程式都需要通過郵件提醒用戶,Flask的擴展包Flask-Mail通過包裝了Python內置的smtplib包,可以用在Flask程式中發送郵件,
Flask-Mail連接到簡單郵件協議(Simple Mail Transfer Protocol,SMTP)服務器,并把郵件交給服務器發送,
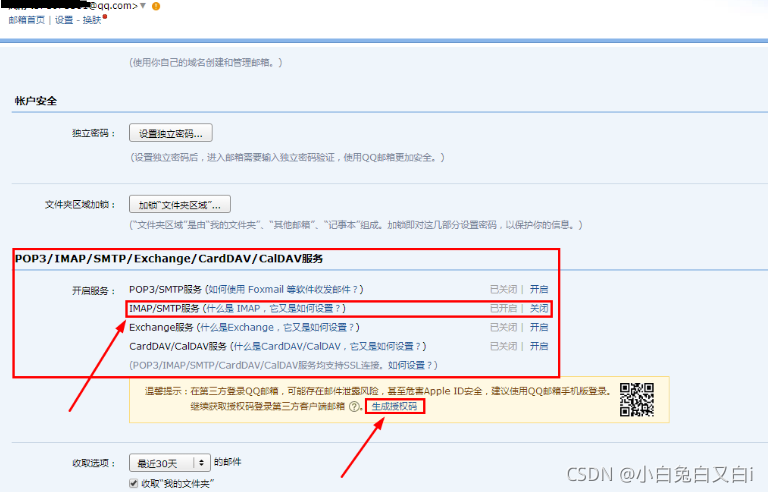
如下示例,通過開啟QQ郵箱SMTP服務設定,發送郵件,
from flask import Flask
from flask_mail import Mail, Message
app = Flask(__name__)
#配置郵件:服務器/埠/傳輸層安全協議/郵箱名/密碼
app.config.update(
DEBUG = True,
MAIL_SERVER='smtp.qq.com',
MAIL_PROT=465,
MAIL_USE_TLS = True,
MAIL_USERNAME = '371673381@qq.com',
MAIL_PASSWORD = 'goyubxohbtzfbidd',
)
mail = Mail(app)
@app.route('/')
def index():
# sender 發送方,recipients 接收方串列
msg = Message("This is a test ",sender='371673381@qq.com', recipients=['shengjun@itcast.cn','371673381@qq.com'])
#郵件內容
msg.body = "Flask test mail"
#發送郵件
mail.send(msg)
print "Mail sent"
return "Sent Succeed"
if __name__ == "__main__":
app.run()
測驗與部署
藍圖Blueprint
為什么學習藍圖?
我們學習Flask框架,是從寫單個檔案,執行hello world開始的,我們在這單個檔案中可以定義路由、視圖函式、定義模型等等,但這顯然存在一個問題:隨著業務代碼的增加,將所有代碼都放在單個程式檔案中,是非常不合適的,這不僅會讓代碼閱讀變得困難,而且會給后期維護帶來麻煩,
如下示例:我們在一個檔案中寫入多個路由,這會使代碼維護變得困難,
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'index'
@app.route('/list')
def list():
return 'list'
@app.route('/detail')
def detail():
return 'detail'
@app.route('/')
def admin_home():
return 'admin_home'
@app.route('/new')
def new():
return 'new'
@app.route('/edit')
def edit():
return 'edit'
問題:一個程式執行檔案中,功能代碼過多,就是讓代碼模塊化,根據具體不同功能模塊的實作,劃分成不同的分類,降低各功能模塊之間的耦合度,python中的模塊制作和匯入就是基于實作功能模塊的封裝的需求,
嘗試用模塊匯入的方式解決: 我們把上述一個py檔案的多個路由視圖函式給拆成兩個檔案:app.py和admin.py檔案,app.py檔案作為程式啟動檔案,因為admin檔案沒有應用程式實體app,在admin檔案中要使用app.route路由裝飾器,需要把app.py檔案的app匯入到admin.py檔案中,
# 檔案app.py
from flask import Flask
# 匯入admin中的內容
from admin import *
app = Flask(__name__)
@app.route('/')
def index():
return 'index'
@app.route('/list')
def list():
return 'list'
@app.route('/detail')
def detail():
return 'detail'
if __name__ == '__main__':
app.run()
# 檔案admin.py
from app import app
@app.route('/')
def admin_home():
return 'admin_home'
@app.route('/new')
def new():
return 'new'
@app.route('/edit')
def edit():
return 'edit'
啟動app.py檔案后,我們發現admin.py檔案中的路由都無法訪問, ==也就是說,python中的模塊化雖然能把代碼給拆分開,但不能解決路由映射的問題, ==
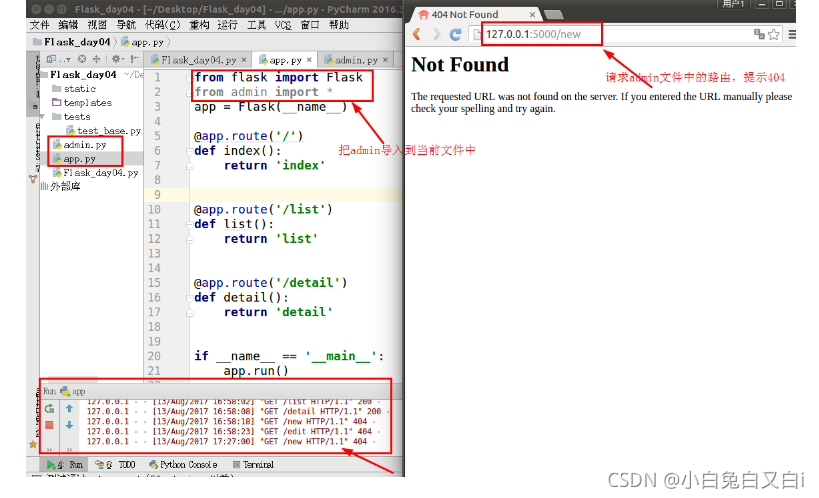
什么是藍圖?
藍圖:用于實作單個應用的視圖、模板、靜態檔案的集合,
藍圖就是模塊化處理的類,
簡單來說,藍圖就是一個存盤操作路由映射方法的容器,主要用來實作客戶端請求和URL相互關聯的功能, 在Flask中,使用藍圖可以幫助我們實作模塊化應用的功能,
藍圖的運行機制:
藍圖是保存了一組將來可以在應用物件上執行的操作,注冊路由就是一種操作,當在程式實體上呼叫route裝飾器注冊路由時,這個操作將修改物件的url_map路由映射串列,當我們在藍圖物件上呼叫route裝飾器注冊路由時,它只是在內部的一個延遲操作記錄串列defered_functions中添加了一個項,當執行應用物件的 register_blueprint() 方法時,應用物件從藍圖物件的 defered_functions 串列中取出每一項,即呼叫應用物件的 add_url_rule() 方法,這將會修改程式實體的路由映射串列,
藍圖的使用:
一、創建藍圖物件,
#Blueprint必須指定兩個引數,admin表示藍圖的名稱,__name__表示藍圖所在模塊
admin = Blueprint('admin',__name__)
二、注冊藍圖路由,
@admin.route('/')
def admin_index():
return 'admin_index'
三、在程式實體中注冊該藍圖,
app.register_blueprint(admin,url_prefix='/admin')
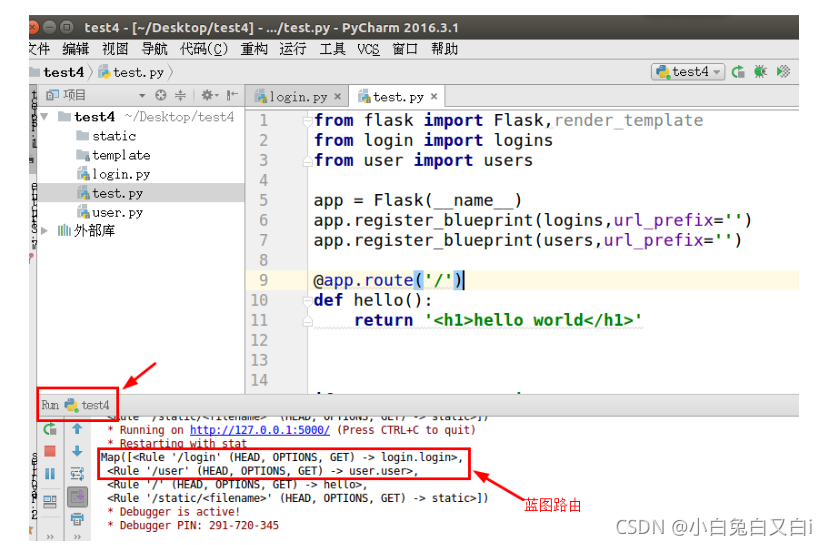
程式執行檔案/test4/test.py
from flask import Flask
#匯入藍圖物件
from login import logins
from user import users
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
#注冊藍圖,第一個引數logins是藍圖物件,url_prefix引數默認值是根路由,如果指定,會在藍圖注冊的路由url中添加前綴,
app.register_blueprint(logins,url_prefix='')
app.register_blueprint(users,url_prefix='')
if __name__ == '__main__':
app.run(debug=True)
創建藍圖:/test4/user.py
from flask import Blueprint,render_template
#創建藍圖,第一個引數指定了藍圖的名字,
users = Blueprint('user',__name__)
@users.route('/user')
def user():
return render_template('user.html')
創建藍圖:/test4/login.py
from flask import Blueprint,render_template
#創建藍圖
logins = Blueprint('login',__name__)
@logins.route('/login')
def login():
return render_template('login.html')
運行/test4/test.py檔案
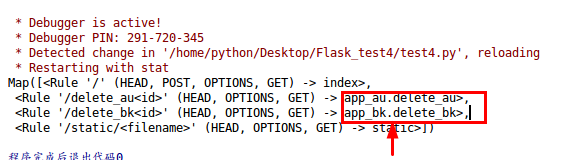
動態路由示例(作者–圖書):
檔案目錄:Flask_test4/delete.py
from flask import Blueprint,redirect,url_for
app_au = Blueprint('app_au',__name__)
app_bk = Blueprint('app_bk',__name__)
from test4 import *
@app_au.route('/delete_au<id>')
def delete_au(id):
del_au = Author.query.filter_by(id=id).first()
db.session.delete(del_au)
db.session.commit()
return redirect(url_for('index'))
@app_bk.route('/delete_bk<id>')
def delete_bk(id):
del_bk = Book.query.filter_by(id=id).first()
db.session.delete(del_bk)
db.session.commit()
return redirect(url_for('index'))
檔案目錄:Flask_test4/test4.py
#coding=utf-8
#目的:創建兩個模型型別,實作資料庫的連接和資料的操作
from flask import Flask,render_template,request,redirect,url_for
from flask_sqlalchemy import SQLAlchemy
from flask_wtf import FlaskForm
from wtforms import StringField,SubmitField
from wtforms.validators import DataRequired
#匯入delete檔案中的藍圖物件
from delete import app_au,app_bk
app = Flask(__name__)
#對資料庫連接的基本設定
app.config['SQLALCHEMY_DATABASE_URI']='mysql://root:mysql@localhost/test0'
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#把應用程式的實體和SQLAlchemy進行關聯
db = SQLAlchemy(app)
app.config['SECRET_KEY'] = 'a'
#自定義表單,實作資料的輸入保存操作
class Append(FlaskForm):
author = StringField(validators=[DataRequired()])
book = StringField(validators=[DataRequired()])
submit = SubmitField(u'提交')
#自定義模型類
class Author(db.Model):
__tablename__ = 'authors'
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(32),unique=True)
def __repr__(self):
return 'author:%s'%self.name
class Book(db.Model):
__tablename__ = 'books'
id = db.Column(db.Integer,primary_key=True)
info = db.Column(db.String(32),unique=True)
def __repr__(self):
return 'book:%s'%self.info
@app.route('/',methods=['GET','POST'])
def index():
au = Author.query.all()
bk = Book.query.all()
form = Append()
if form.validate_on_submit():
#從表單中獲取資料
wtf_au = form.author.data
wtf_bk = form.book.data
#把資料存入模型類中
db_au = Author(name=wtf_au)
db_bk = Book(info=wtf_bk)
#添加到資料庫操作
db.session.add_all([db_au,db_bk])
db.session.commit()
au = Author.query.all()
bk = Book.query.all()
return render_template('index.html',au=au,bk=bk,form=form)
if request.method == 'GET':
return render_template('index.html',au=au,bk=bk,form=form)
#注冊藍圖
app.register_blueprint(app_au)
app.register_blueprint(app_bk)
if __name__ == '__main__':
print app.url_map
app.run(debug=True)
查看藍圖路由:藍圖路由可以分為兩塊,".“前面的是藍圖名稱,”."后面的是視圖函式名,
單元測驗
為什么要測驗?
Web程式開發程序一般包括以下幾個階段:[需求分析,設計階段,實作階段,測驗階段],其中測驗階段通過人工或自動來運行測驗某個系統的功能,目的是檢驗其是否滿足需求,并得出特定的結果,以達到弄清楚預期結果和實際結果之間的差別的最終目的,
測驗的分類:
測驗從軟體開發程序可以分為:單元測驗、集成測驗、系統測驗等,在眾多的測驗中,與程式開發人員最密切的就是單元測驗,因為單元測驗是由開發人員進行的,而其他測驗都由專業的測驗人員來完成,所以我們主要學習單元測驗,
什么是單元測驗?
程式開發程序中,寫代碼是為了實作需求,當我們的代碼通過了編譯,只是說明它的語法正確,功能能否實作則不能保證, 因此,當我們的某些功能代碼完成后,為了檢驗其是否滿足程式的需求,可以通過撰寫測驗代碼,模擬程式運行的程序,檢驗功能代碼是否符合預期,
單元測驗就是開發者撰寫一小段代碼,檢驗目標代碼的功能是否符合預期,通常情況下,單元測驗主要面向一些功能單一的模塊進行,
舉個例子:一部手機有許多零部件組成,在正式組裝一部手機前,手機內部的各個零部件,CPU、記憶體、電池、攝像頭等,都要進行測驗,這就是單元測驗,
在Web開發程序中,單元測驗實際上就是一些“斷言”(assert)代碼,
斷言就是判斷一個函式或物件的一個方法所產生的結果是否符合你期望的那個結果, python中assert斷言是宣告布林值為真的判定,如果運算式為假會發生例外,單元測驗中,一般使用assert來斷言結果,
斷言方法的使用:
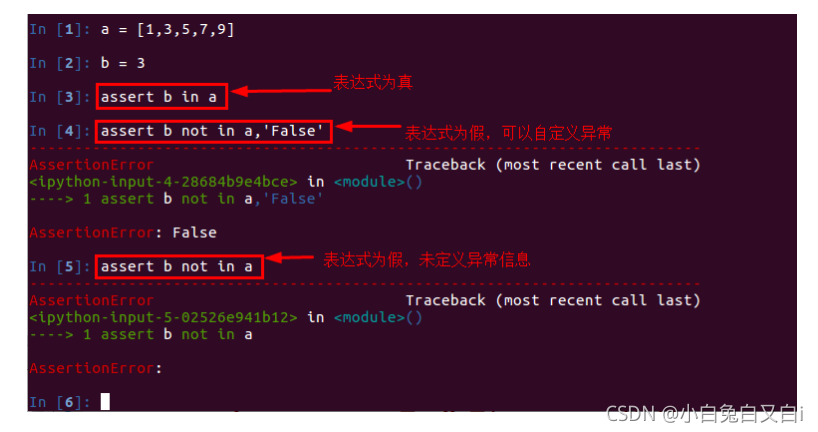
斷言陳述句類似于:
if not expression:
raise AssertionError
常用的斷言方法:
assertEqual 如果兩個值相等,則pass
assertNotEqual 如果兩個值不相等,則pass
assertTrue 判斷bool值為True,則pass
assertFalse 判斷bool值為False,則pass
assertIsNone 不存在,則pass
assertIsNotNone 存在,則pass
如何測驗?
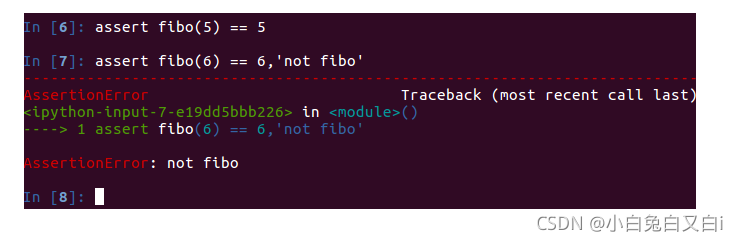
簡單的測驗用例:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,
def fibo(x):
if x == 0:
resp = 0
elif x == 1:
resp = 1
else:
return fibo(x-1) + fibo(x-2)
return resp
assert fibo(5) == 5
單元測驗的基本寫法:
首先,定義一個類,繼承自unittest.TestCase
import unittest
class TestClass(unitest.TestCase):
pass
其次,在測驗類中,定義兩個測驗方法
import unittest
class TestClass(unittest.TestCase):
#該方法會首先執行,方法名為固定寫法
def setUp(self):
pass
#該方法會在測驗代碼執行完后執行,方法名為固定寫法
def tearDown(self):
pass
最后,在測驗類中,撰寫測驗代碼
import unittest
class TestClass(unittest.TestCase):
#該方法會首先執行,相當于做測驗前的準備作業
def setUp(self):
pass
#該方法會在測驗代碼執行完后執行,相當于做測驗后的掃尾作業
def tearDown(self):
pass
#測驗代碼
def test_app_exists(self):
pass
發送郵件測驗:
#coding=utf-8
import unittest
from Flask_day04 import app
class TestCase(unittest.TestCase):
# 創建測驗環境,在測驗代碼執行前執行
def setUp(self):
self.app = app
# 激活測驗標志
app.config['TESTING'] = True
self.client = self.app.test_client()
# 在測驗代碼執行完成后執行
def tearDown(self):
pass
# 測驗代碼
def test_email(self):
resp = self.client.get('/')
print resp.data
self.assertEqual(resp.data,'Sent Succeed')
資料庫測驗:
#coding=utf-8
import unittest
from author_book import *
#自定義測驗類,setUp方法和tearDown方法會分別在測驗前后執行,以test_開頭的函式就是具體的測驗代碼,
class DatabaseTest(unittest.TestCase):
def setUp(self):
app.config['TESTING'] = True
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@localhost/test0'
self.app = app
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
#測驗代碼
def test_append_data(self):
au = Author(name='itcast')
bk = Book(info='python')
db.session.add_all([au,bk])
db.session.commit()
author = Author.query.filter_by(name='itcast').first()
book = Book.query.filter_by(info='python').first()
#斷言資料存在
self.assertIsNotNone(author)
self.assertIsNotNone(book)
部署
當我們執行下面的hello.py時,使用的flask自帶的服務器,完成了web服務的啟動,在生產環境中,flask自帶的服務器,無法滿足性能要求,我們這里采用Gunicorn做wsgi容器,來部署flask程式,Gunicorn(綠色獨角獸)是一個Python WSGI的HTTP服務器,從Ruby的獨角獸(Unicorn )專案移植,該Gunicorn服務器與各種Web框架兼容,實作非常簡單,輕量級的資源消耗,Gunicorn直接用命令啟動,不需要撰寫組態檔,相對uWSGI要容易很多,
區分幾個概念:
WSGI:全稱是Web Server Gateway Interface(web服務器網關介面),它是一種規范,它是web服務器和web應用程式之間的介面,它的作用就像是橋梁,連接在web服務器和web應用框架之間,
uwsgi:是一種傳輸協議,用于定義傳輸資訊的型別,
uWSGI:是實作了uwsgi協議WSGI的web服務器,
我們的部署方式: nginx + gunicorn + flask
# hello.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return '<h1>hello world</h1>'
if __name__ == '__main__':
app.run(debug=True)
使用Gunicorn:
web開發中,部署方式大致類似,簡單來說,前端代理使用Nginx主要是為了實作分流、轉發、負載均衡,以及分擔服務器的壓力,Nginx部署簡單,記憶體消耗少,成本低,Nginx既可以做正向代理,也可以做反向代理,
正向代理:請求經過代理服務器從局域網發出,然后到達互聯網上的服務器,
特點:服務端并不知道真正的客戶端是誰,
反向代理:請求從互聯網發出,先進入代理服務器,再轉發給局域網內的服務器,
特點:客戶端并不知道真正的服務端是誰,
區別:正向代理的物件是客戶端,反向代理的物件是服務端,
安裝gunicorn
pip install gunicorn
查看命令列選項: 安裝gunicorn成功后,通過命令列的方式可以查看gunicorn的使用資訊,
$gunicorn -h
直接運行:
#直接運行,默認啟動的127.0.0.1::8000
gunicorn 運行檔案名稱:Flask程式實體名
指定行程和埠號: -w: 表示行程(worker), -b:表示系結ip地址和埠號(bind),
$gunicorn -w 4 -b 127.0.0.1:5001 運行檔案名稱:Flask程式實體名
安裝Nginx
$ sudo apt-get install nginx
Nginx配置:
默認安裝到/usr/local/nginx/目錄,進入目錄,
啟動nginx:
#啟動
sudo sbin/nginx
#查看
ps aux | grep nginx
#停止
sudo sbin/nginx -s stop
打開/usr/local/nginx/conf/nginx.conf檔案
erver {
# 監聽80埠
listen 80;
# 本機
server_name localhost;
# 默認請求的url
location / {
#請求轉發到gunicorn服務器
proxy_pass http://127.0.0.1:5001;
#設定請求頭,并將頭資訊傳遞給服務器端
proxy_set_header Host $host;
}
}
Restful
2000年,Roy Thomas Fielding博士在他的博士論文《Architectural Styles and the Design of Network-based Software Architectures》中提出了幾種軟體應用的架構風格,REST作為其中的一種架構風格在這篇論文中進行了概括性的介紹,
REST:Representational State Transfer的縮寫,翻譯:“具象狀態傳輸”,一般解釋為“表現層狀態轉換”,
REST是設計風格而不是標準,是指客戶端和服務器的互動形式,我們需要關注的重點是如何設計REST風格的網路介面,
REST的特點:
具象的,一般指表現層,要表現的物件就是資源,比如,客戶端訪問服務器,獲取的資料就是資源,比如文字、圖片、音視頻等,
表現:資源的表現形式,txt格式、html格式、json格式、jpg格式等,瀏覽器通過URL確定資源的位置,但是需要在HTTP請求頭中,用Accept和Content-Type欄位指定,這兩個欄位是對資源表現的描述,
狀態轉換:客戶端和服務器互動的程序,在這個程序中,一定會有資料和狀態的轉化,這種轉化叫做狀態轉換,其中,GET表示獲取資源,POST表示新建資源,PUT表示更新資源,DELETE表示洗掉資源,HTTP協議中最常用的就是這四種操作方式,
RESTful架構:
- 每個URL代表一種資源;
- 客戶端和服務器之間,傳遞這種資源的某種表現層;
- 客戶端通過四個http動詞,對服務器資源進行操作,實作表現層狀態轉換,
如何設計符合RESTful風格的API:
一、域名:
將api部署在專用域名下:
http://api.example.com
或者將api放在主域名下:
http://www.example.com/api/
二、版本:
將API的版本號放在url中,
http://www.example.com/app/1.0/info
http://www.example.com/app/1.2/info
三、路徑:
路徑表示API的具體網址,每個網址代表一種資源, 資源作為網址,網址中不能有動詞只能有名詞,一般名詞要與資料庫的表名對應,而且名詞要使用復數,
錯誤示例:
http://www.example.com/getGoods
http://www.example.com/listOrders
正確示例:
#獲取單個商品
http://www.example.com/app/goods/1
#獲取所有商品
http://www.example.com/app/goods
四、使用標準的HTTP方法:
對于資源的具體操作型別,由HTTP動詞表示, 常用的HTTP動詞有四個,
GET SELECT :從服務器獲取資源,
POST CREATE :在服務器新建資源,
PUT UPDATE :在服務器更新資源,
DELETE DELETE :從服務器洗掉資源,
示例:
#獲取指定商品的資訊`
GET http://www.example.com/goods/ID
#新建商品的資訊
POST http://www.example.com/goods
#更新指定商品的資訊
PUT http://www.example.com/goods/ID
#洗掉指定商品的資訊
DELETE http://www.example.com/goods/ID
五、過濾資訊:
如果資源資料較多,服務器不能將所有資料一次全部回傳給客戶端,API應該提供引數,過濾回傳結果, 實體:
#指定回傳資料的數量
http://www.example.com/goods?limit=10
#指定回傳資料的開始位置
http://www.example.com/goods?offset=10
#指定第幾頁,以及每頁資料的數量
http://www.example.com/goods?page=2&per_page=20
六、狀態碼:
服務器向用戶回傳的狀態碼和提示資訊,常用的有:
200 OK :服務器成功回傳用戶請求的資料
201 CREATED :用戶新建或修改資料成功,
202 Accepted:表示請求已進入后臺排隊,
400 INVALID REQUEST :用戶發出的請求有錯誤,
401 Unauthorized :用戶沒有權限,
403 Forbidden :訪問被禁止,
404 NOT FOUND :請求針對的是不存在的記錄,
406 Not Acceptable :用戶請求的的格式不正確,
500 INTERNAL SERVER ERROR :服務器發生錯誤,
七、錯誤資訊:
一般來說,服務器回傳的錯誤資訊,以鍵值對的形式回傳,
{
error:'Invalid API KEY'
}
八、回應結果:
針對不同結果,服務器向客戶端回傳的結果應符合以下規范,
#回傳商品串列
GET http://www.example.com/goods
#回傳單個商品
GET http://www.example.com/goods/cup
#回傳新生成的商品
POST http://www.example.com/goods
#回傳一個空檔案
DELETE http://www.example.com/goods
九、使用鏈接關聯相關的資源:
在回傳回應結果時提供鏈接其他API的方法,使客戶端很方便的獲取相關聯的資訊,
十、其他:
服務器回傳的資料格式,應該盡量使用JSON,避免使用XML,
性能
一、不同角度的網站性能
普通用戶認為的網站性能
網站性能對于普通用戶來說,最直接的體現就是回應時間,用戶在瀏覽器上直觀感受到的網站回應速度,即從客戶端發送請求,到服務器回傳回應內容的時間,
做為網站開發人員來說,網站性能通常會和普通的用戶理解的不一樣,
普通用戶感受到的網站性能,并不只是由網站服務器決定的,它還包括客戶端計算機和服務器通信的時間,網站服務器處理回應的時間,客戶端瀏覽器構造請求決議回應資料的時間,甚至,不同的計算機性能、不同瀏覽器決議HTML的速度、不同網路運營商提供的網路帶寬房屋的差異,這些都會導致用戶感受到回應時間,可能大于網站服務器處理請求的時間,
開發人員認為的網站性能
開發人員關注的主要是服務器應用程式本身,以及相關配套系統的性能,包括并發處理能力、系統穩定性、回應延遲等技術指標,
對性能優化的主要手段,包括使用快取加速資料讀取,使用集群提高資料吞吐能力,使用異步訊息加快請求回應,使用代碼改善程式性能,
運維人員認為的網站性能
運維人員關注的主要是服務器基礎設施和資源利用率,如服務器硬體的配置、網路運營商的帶寬、資料中心的網路架構等,主要優化手段有使用高性價比的服務器、建設優化骨干網路、利用虛擬化技術優化資源利用等,
二、性能的指標
從開發人員的角度,網站性能的指標主要有并發數和回應時間,
并發數
并發數是指系統能夠處理請求的數量,對于網站服務器而言,并發數也就是網站并發用戶數,指同時提交請求的用戶數目,
與并發數相對應的還有網站在線用戶數(登錄用戶數)和網站用戶數(一般指注冊用戶數),他們的關系一般是:網站用戶數>網站用戶在線數>網站用戶并發數
回應時間
回應時間是最重要的性能指標,直接反映了系統的快慢,
常見的系統操作回應時間
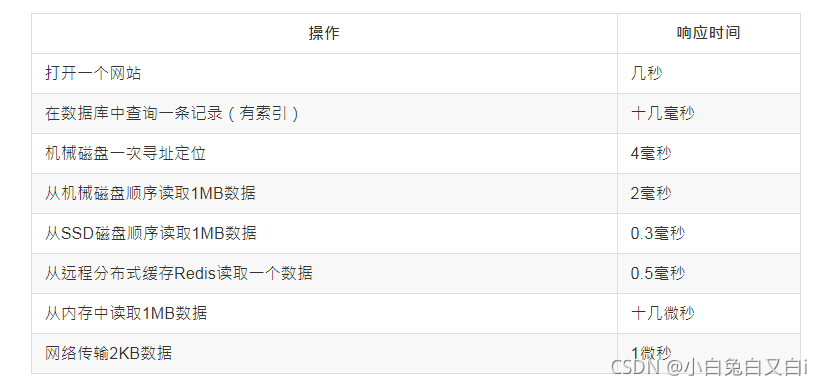
三、性能的優化
對于開發人員來說,網站性能優化一般包括Web前端性能優化、應用服務器性能優化、存盤服務器性能優化三類,
Web前端性能優化
1、減少http請求 http協議是無狀態的應用層協議,意味著每次http請求都需要建立通信鏈路、進行資料傳輸,而在服務器端,每個http請求都需要啟動獨立的執行緒去處理,減少http請求的數目可有效提高訪問性能,
減少http的主要手段是合并CSS、合并javascript、合并圖片,
2、使用瀏覽器快取 對一個網站而言,CSS、javascript、logo、圖示,這些靜態資源檔案更新的頻率都比較低,而這些檔案又幾乎是每次http請求都需要的,如果將這些檔案快取在瀏覽器中,可以極好的改善性能,通過設定http頭中的cache-control和expires的屬性,可設定瀏覽器快取,快取時間可以自定義,
3、啟用壓縮 在服務器端對檔案進行壓縮,在瀏覽器端對檔案解壓縮,可有效減少通信傳輸的資料量,如果可以的話,盡可能的將外部的腳本、樣式進行合并,多個合為一個,文本檔案的壓縮效率可達到80%以上,因此HTML、CSS、javascript檔案啟用GZip壓縮可達到較好的效果,但是壓縮對服務器和瀏覽器產生一定的壓力,在網路帶寬良好,而服務器資源不足的情況下要綜合考慮,
4、CSS放在頁面最上部,javascript放在頁面最下面 瀏覽器會在下載完成全部CSS之后才對整個頁面進行渲染,因此最好的做法是將CSS放在頁面最上面,讓瀏覽器盡快下載CSS, Javascript則相反,瀏覽器在加載javascript后立即執行,有可能會阻塞整個頁面,造成頁面顯示緩慢,因此javascript最好放在頁面最下面,
應用服務器優化
應用服務器也就是處理網站業務的服務器,網站的業務代碼都部署在這里,主要優化方案有快取、異步、集群等,
1、合理使用快取
當網站遇到性能瓶頸時,第一個解決方案一般是快取,在整個網站應用中,快取幾乎無處不在,無論是客戶端,還是應用服務器,或是資料庫服務器,在客戶端和服務器的互動中,無論是資料、檔案都可以快取,合理使用快取對網站性能優化非常重要,
快取一般用來存放那些讀寫次數比較高,變化較少的資料,比如網站首頁的資訊、商品的資訊等,應用程式讀取資料時,一般是先從快取中讀取,如果讀取不到或資料已失效,再訪問磁盤資料庫,并將資料再次寫入快取,
快取的基本原理是將資料存盤在相對有較高訪問速度的存盤介質中,比如記憶體,一方面快取訪問速度快,另一方面,如果快取的資料是需要經過計算處理得到的,那使用快取還可以減少服務器處理資料的計算時間,
使用快取并不是沒有缺陷:記憶體資源是比較寶貴的,不可能將所有資料都快取,一般頻繁修改的資料不建議使用快取,這會導致資料不一致,
網站資料快取一般遵循二八定律,即80%的訪問都在20%的資料上,所以,一般將這20%的資料快取,可以起到改善系統性能,提高服務器讀取效率,
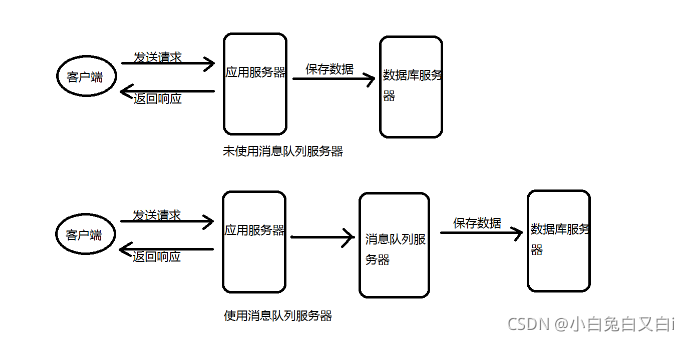
2、異步操作
使用訊息佇列將呼叫異步化,可以改善網站系統的性能,
在不使用訊息佇列的情況下,用戶的請求直接寫入資料庫,在高并發的情況下,會對資料庫造成非常大的壓力,也會延遲回應時間,
在使用訊息佇列后,用戶請求的資料會發送給訊息佇列服務器,訊息佇列服務器會開啟行程,將資料異步寫入資料庫,訊息佇列服務器的處理速度遠超過資料庫,因此用戶的回應延遲可得到改善,
訊息佇列可以將短時間內的高并發產生的事務訊息,存盤在訊息佇列中,從而提高網站的并發處理能力,在電商網站的促銷活動中,合理使用訊息佇列,可以抵御短時間內用戶高并發的沖擊,
3、使用集群
在網站高并發訪問的情況下,使用負載均衡技術,可以為一個應用構建由多臺服務器組成的服務器集群,將并發訪問請求,分發到多臺服務器上處理,避免單一服務器因負載過大,而導致回應延遲,
4、代碼優化
網站的業務邏輯代碼主要部署在應用服務器上,需要處理復雜的并發事務,合理優化業務代碼,也可以改善網站性能,
任何web網站都會遇到多用戶的并發訪問,大型網站的并發用戶會達到數萬,每個用戶請求都會創建一個獨立的系統行程去處理,由于執行緒比行程更輕量,占用資源更少,所以,目前主流的web應用服務器都采用多執行緒的方式,處理并發用戶的請求,因此,網站開發多數都是多執行緒編程,
使用多執行緒的另一個原因是服務器有多個CPU,現在手機都到了8核CPU的時代,一般的服務器至少是16核CPU,要想最大限度的使用這些CPU,必須啟動多執行緒,
那么,啟動多少執行緒合適呢?
啟動執行緒數和CPU內核數量成正比,和IO等待時間成正比,如果都是計算型的任務,那么執行緒數最多不要超過CPU內核數,因為啟動再多,CPU也來不及呼叫,如果任務是等待讀寫磁盤、網路回應,那么多啟動執行緒會提高任務并發度,提高服務器性能,
或者用個簡化的公式來描述:
啟動執行緒數 = (任務執行時間/(任務執行事件 - IO等待時間)) * CPU內核數
5、存盤優化
資料的讀寫是網站處理并發訪問的另一瓶頸,使用快取雖然可以解決一部分資料讀寫壓力,但很多時候,磁盤仍然是系統最嚴重的瓶頸,而且磁盤是網站最重要的資產,磁盤的可用性和容錯性也至關重要,
機械硬碟和固態硬碟 機械硬碟是目前最常用的硬碟,通過馬達帶動磁頭到指定磁盤的位置訪問資料,每次訪問資料都需要移動磁頭,在讀取連續資料和隨機訪問上,磁頭移動的次數相差巨大,因此機械硬碟的性能表現差別巨大,讀寫效率較低,而在網站應用中,大多數資料的訪問都是隨機的,在這種情況下,固態硬碟具有更高的性能,但目前固態硬碟在工藝上、資料可靠性上還有待提升,因此固態硬碟的使用尚未普及,從發展趨勢看,取代機械硬碟應該是遲早的事情,
總結:
網站性能優化是在用戶高并發訪問,網站遇到問題時的解決方案,所以網站性能優化的主要內容是改善高并發用戶訪問情況下的網站回應速度,
網站性能優化的最終目的是改善用戶的體驗,但性能優化本身也是需要綜合考慮的,比如說,性能提高一倍,服務器數量也要增加一倍,這樣的優化是否可以考慮?
技術是由業務驅動的,離開業務的支撐,任何性能優化都是空中樓閣,
今天咱們就先學習到這里啦!有什么問題可關注我且私聊我啦!
非常感謝大家的閱讀!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/299987.html
標籤:python