大家好,我是小黑,一個在互聯網茍且偷生的農民工,
在JDK1.7中引入了一種新的Fork/Join執行緒池,它可以將一個大的任務拆分成多個小的任務并行執行并匯總執行結果,
Fork/Join采用的是分而治之的基本思想,分而治之就是將一個復雜的任務,按照規定的閾值劃分成多個簡單的小任務,然后將這些小任務的結果再進行匯總回傳,得到最終的任務,
分治法
分治法是計算機領域常用的演算法中的其中一個,主要思想就是將將一個規模為N的問題,分解成K個規模較小的子問題,這些子問題相互獨立且與原問題性質相同;求解出子問題的解,合并得到原問題的解,
解決問題的思路
- 分割原問題;
- 求解子問題;
- 合并子問題的解為原問題的解,
使用場景
二分查找,階乘計算,歸并排序,堆排序、快速排序、傅里葉變換都用了分治法的思想,
ForkJoin并行處理框架
在JDK1.7中推出的ForkJoinPool執行緒池,主要用于ForkJoinTask任務的執行,ForkJoinTask是一個類似執行緒的物體,但是比普通執行緒更輕量,
我們來使用ForkJoin框架完成以下1-10億求和的代碼,
public class ForkJoinMain {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> rootTask = forkJoinPool.submit(new SumForkJoinTask(1L, 10_0000_0000L));
System.out.println("計算結果:" + rootTask.get());
}
}
class SumForkJoinTask extends RecursiveTask<Long> {
private final Long min;
private final Long max;
private Long threshold = 1000L;
public SumForkJoinTask(Long min, Long max) {
this.min = min;
this.max = max;
}
@Override
protected Long compute() {
// 小于閾值時直接計算
if ((max - min) <= threshold) {
long sum = 0;
for (long i = min; i < max; i++) {
sum = sum + i;
}
return sum;
}
// 拆分成小任務
long middle = (max + min) >>> 1;
SumForkJoinTask leftTask = new SumForkJoinTask(min, middle);
leftTask.fork();
SumForkJoinTask rightTask = new SumForkJoinTask(middle, max);
rightTask.fork();
// 匯總結果
return leftTask.join() + rightTask.join();
}
}
上述代碼邏輯可通過下圖更加直觀的理解,
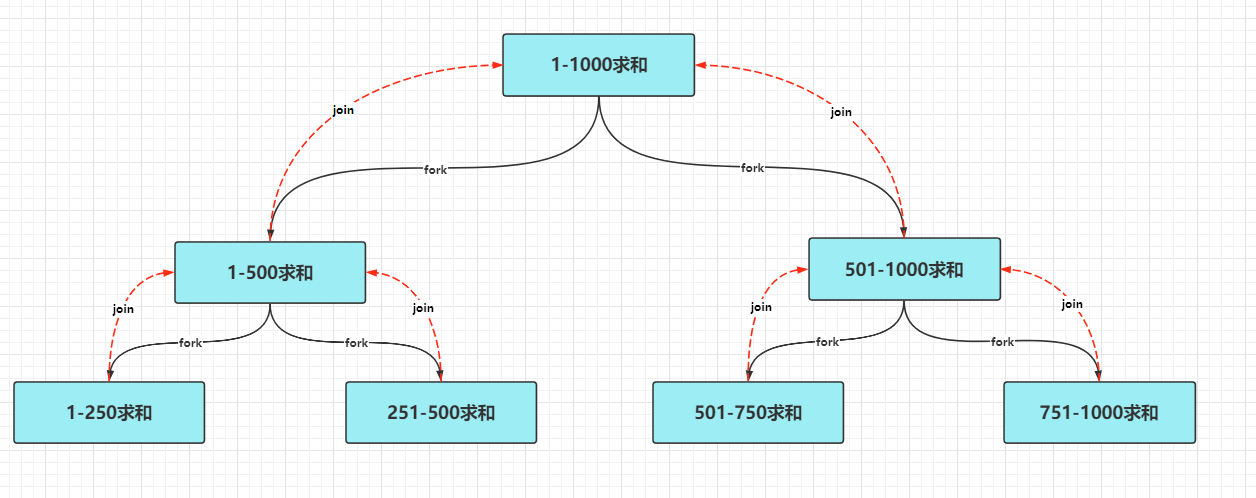
ForkJoin框架實作
在ForkJoin框架中重要的一些介面和類如下圖所示,
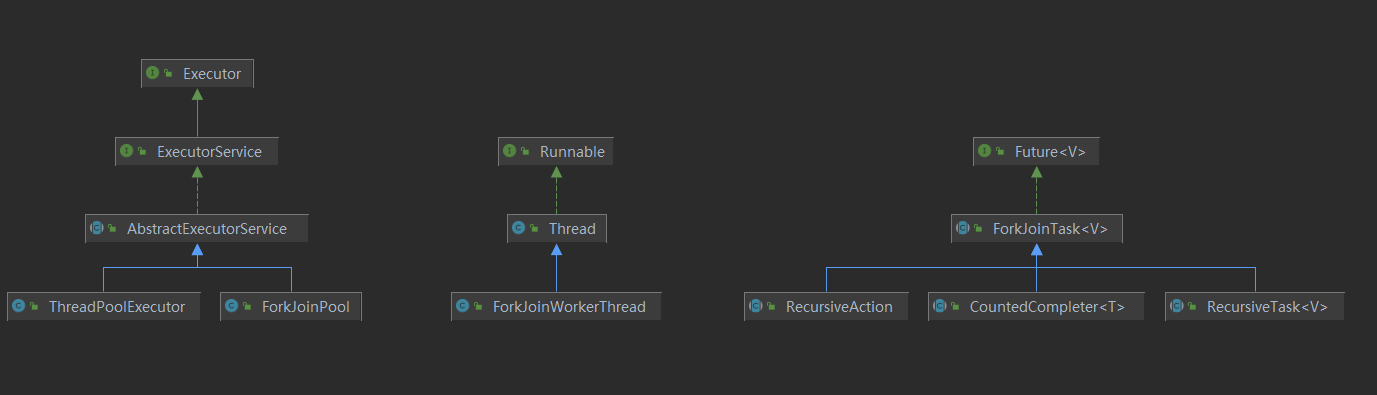
ForkJoinPool
ForkJoinPool是用于運行ForkJoinTasks的執行緒池,實作了Executor介面,
可以通過new ForkJoinPool()直接創建ForkJoinPool物件,
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode){
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
通過查看構造方法原始碼我們可以發現,在創建ForkJoinPool時,有以下4個引數:
- parallelism:期望并發數,默認會使用
Runtime.getRuntime().availableProcessors()的值 - factory:創建
ForkJoin作業執行緒的工廠,默認為defaultForkJoinWorkerThreadFactory - handler:執行任務時遇到不可恢復的錯誤時的處理程式,默認為
null - asyncMode:作業執行緒獲取任務使用FIFO模式還是LIFO模式,默認為LIFO
ForkJoinTask
ForkJoinTask是一個對于在ForkJoinPool中運行任務的抽象類定義,
可以通過少量的執行緒處理大量任務和子任務,ForkJoinTask實作了Future介面,主要通過fork()方法安排異步任務執行,通過join()方法等待任務執行的結果,
想要使用ForkJoinTask通過少量的執行緒處理大量任務,需要接受一些限制,
- 拆分的任務中避免同步方法或同步代碼塊;
- 在細分的任務中避免執行阻塞I/O操作,理想情況下基于完全獨立于其他正在運行的任務訪問的變數;
- 不允許在細分任務中拋出受檢例外,
因為ForkJoinTask是抽象類不能被實體化,所以在使用時JDK為我們提供了三種特定型別的ForkJoinTask父類供我們自定義時繼承使用,
- RecursiveAction:子任務不回傳結果
- RecursiveTask:子任務回傳結果
- CountedCompleter:在任務完成執行后會觸發執行
ForkJoinWorkerThread
ForkJoinPool中用于執行ForkJoinTask的執行緒,
ForkJoinPool既然實作了Executor介面,那么它和我們常用的ThreadPoolExecutor之前又有什么差異呢?
如果們使用ThreadPoolExecutor來完成分治法的邏輯,那么每個子任務都需要創建一個執行緒,當子任務的數量很大的情況下,可能會達到上萬個,那么使用ThreadPoolExecutor創建出上萬個執行緒,這顯然是不可行、不合理的;
而ForkJoinPool在處理任務時,并不會按照任務開啟執行緒,只會按照指定的期望并行數量創建執行緒,在每個執行緒作業時,如果需要繼續拆分子任務,則會將當前任務放入ForkJoinWorkerThread的任務佇列中,遞回處理直到最外層的任務,
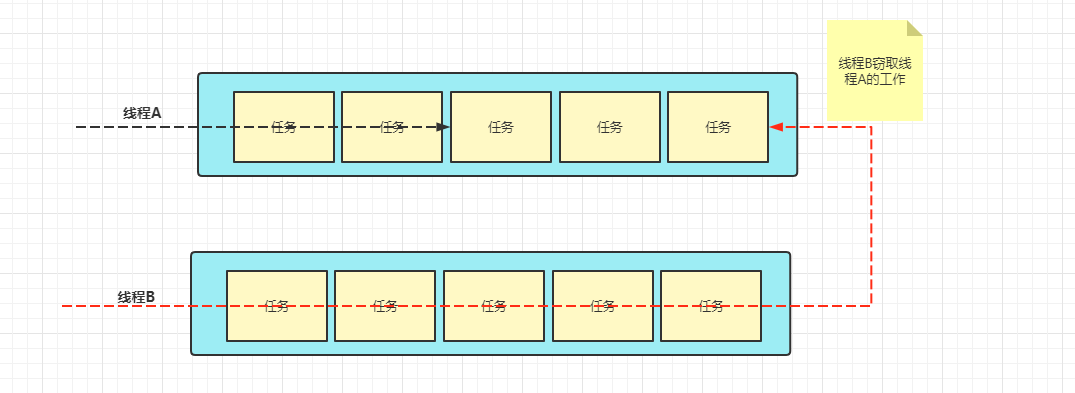
作業竊取演算法
ForkJoinPool的各個作業執行緒都會維護一個各自的任務佇列,減少執行緒之間對于任務的競爭;
每個執行緒都會先保證將自己佇列中的任務執行完,當自己的任務執行完之后,會去看其他執行緒的任務佇列中是否有未處理完的任務,如果有則會幫助其他執行緒執行;
為了減少在幫助其他執行緒執行任務時發生競爭,會使用雙端佇列來存放任務,被竊取的任務只會從佇列的頭部獲取任務,而正常處理的執行緒每次都是從佇列的尾部獲取任務,
優點
充分利用了執行緒資源,避免資源的浪費,并且減少了執行緒間的競爭,
缺點
需要給每個執行緒開辟一個佇列空間;在作業佇列中只有一個任務時同樣會存在執行緒競爭,
最后
如果覺得文章對你有點幫助,不妨掃碼點個關注,我是小黑,下期見~

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/300893.html
標籤:其他