🍅 Java學習路線:搬磚工逆襲Java架構師
🍅 簡介:Java領域優質創作者🏆、CSDN哪吒公眾號作者? 、Java架構師奮斗者💪
🍅 掃描主頁左側二維碼,加入群聊,一起學習、一起進步
🍅 歡迎點贊 👍 收藏 ?留言 📝
目錄
一、分庫分表
二、分庫分表的方式
1、垂直分表
2、垂直分庫
3、水平分表
4、水平分庫
三、分庫分表帶來的問題
1、學習成本問題
2、事務問題
3、跨節點join問題
4、跨節點的count、order by、group by以及聚合函式問題
5、資料遷移、容量規劃、擴容問題
6、主鍵ID問題
7、跨分片的排序分頁
四、分庫數量
五、分庫分表第三方解決方案 -- Apache ShardingSphere
六、Apache ShardingSphere的三個核心概念
1、連接
2、增量
3、可插拔
七、Apache ShardingSphere的三款產品
1、ShardingSphere-JDBC
2、Sharding-Proxy
3、ShardingSphere-Sidecar
八、ShardingSphere-JDBC代碼實體
1、ShardingSphere-JDBC 實作水平分表
2、ShardingSphere-JDBC 實作水平分庫
3、配置公共表
九、 什么是讀寫分離
十、配置MySQL主從服務器
1、新增MySQL實體
2、修改主、從庫的組態檔
3、創建用于主從復制的賬號
4、設定從庫向主庫同步資料
十一、Sharding-JDBC實作讀寫分離
一、分庫分表
1、隨著時間和業務發展,資料庫資料量不可控,造成表中資料越來越多,此時再進行CRUD操作的話,會造成很大的性能問題,比如查詢實時資料,表資料達到了千萬級別,要求一分鐘查詢一次,但你一個select就要耗時2兩分鐘才能執行完,這豈不是很尷尬,
2、分庫分表就是為了解決由于資料量過大而導致資料庫性能降低的問題,將原來獨立的資料庫拆分成若干資料庫組成 ,將資料大表拆分成若干資料表組成,使得單一資料庫、單一資料表的資料量變小,從而達到提升資料庫性能的目的,
3、性能解決方案
方案1
通過提升服務器硬體能力來提高資料處理能力,比如增加存盤容量 、CPU等,這種方案成本很高,并且如果瓶頸在MySQL本身那么提高硬體也是有很的,
方案2
把資料分散到不同的資料庫中,使得單一資料庫的資料量變小來緩解單一資料庫的性能問題,從而達到提升資料庫性能的目的,
二、分庫分表的方式
垂直分表、垂直分庫、水平分表、水平分庫,
1、垂直分表
(1)基本概念
將一個表按照欄位分成多個表,每個表存盤其中一部分欄位,
(2)性能提升
- 為了避免IO爭搶并減少鎖表的幾率;
- 充分發揮熱門資料的操作效率,熱門欄位和冷門欄位分開存盤,比如一個產品基本資訊表、一個產品詳細資訊表,大欄位一定要放在冷門欄位的表中,
(3)為什么大欄位IO效率低?
- 資料本身長度過長,需要更長的讀取時間;
- 跨頁,頁是資料庫存盤基本單位,很多查找及定位操作都是以頁為單位,單頁內的資料行越多資料庫整體性能越好,而大欄位占用空間大,單頁存盤資料少,因此IO效率低;
- 資料以行為單位將資料加載到記憶體中,如果欄位長度短,記憶體就可以加載更多的資料,減少磁盤IO,從而提高資料庫性能;
2、垂直分庫
(1)基本概念
垂直分表只解決了單一表資料量大的問題,但沒有將表分布到不同的服務器上,因此每張表還是競爭同一個物理機的CPU、記憶體、網路IO、磁盤,
垂直分庫的意思就是將表進行分類,分別部署在不同的資料庫上面,每個庫放到不同的服務器上,它的核心理念就是專庫專用,
每個微服務使用單獨的資料庫,
(2)性能提升
- 解決業務層面的耦合,業務清晰
- 能對不同業務的資料進行分級管理、維護、監控、擴展等
- 高并發場景下,垂直分庫一定程式上提升IO、減少資料庫連接數、降低單機硬體資源的瓶頸
3、水平分表
(1)基本概念
水平分表是在同一個資料庫內,把同一個表的資料按一定規則拆到多個表中,
(2)性能提升
- 優化單一表資料量過大而產生的性能問題
- 避免IO爭搶并減少鎖表的幾率
單一資料庫內的水平分表,解決了單一表資料量過大的問題,分出來的小表只包含一部分資料,從而使單表查詢的速度更快,效率更好,
(3)水平分表的方式
① Hash取模分表
資料庫分表一般都是采用這種方式,比如一個position表,根據positionId%4,并按照結果分成4張表,
優點:
資料分片較為平均,不容易出現熱點和并發訪問的瓶頸,
缺點:
容易產生跨分片查詢的復雜問題,
② 數值Range分表
按照時間區間或ID區間進行切分,
優點:
- 單表大小可控
- 易于擴展
- 有效避免跨分片查詢的問題
缺點:
熱點資料成為性能瓶頸,
例如按時間分片,有些分片存盤在最近時間段的表內,可能被頻繁的讀寫操作,而歷史資料表則訪問較少,
③ 一致性Hash演算法
較為復雜,小編暫時不做介紹,有興趣的可以自行百度,
4、水平分庫
(1)基本概念
水平分庫是把同一個表的資料按一定規則拆到不同的資料庫中,每個庫可以放在不同的服務器上,
(2)性能提升
- 解決了單庫資料量大,高并發的瓶頸
- 提高了系統的穩定性和可用性
(3)何時使用
當一個應用難以再進行垂直切分,或垂直切分后資料量行數巨大,存在單庫讀寫存盤的性能瓶頸,這時候就可以考慮使用水平分庫了,
(4)使用弊端
但水平分庫的弊端也很明顯,需要確定你所需要的資料在哪一個庫中,因此大大提高了系統的復雜度,
5、小總結
- 垂直分表:熱門資料、冷門資料分開存盤,大欄位放在冷門資料表中,
- 垂直分庫:按業務拆分,放到不同的庫中,這些庫分別部署在不同的服務器,解決單一服務器性能的瓶頸,同時提升整體架構的業務清晰度,
- 水平分表:解決單一表資料量過大的問題
- 水平分庫:把一個表的資料分別分到不同的庫中,這些庫分別部署在不同的服務器,解決單一服務器資料量過大的問題
三、分庫分表帶來的問題
1、學習成本問題
大多數初級開發者都不會分庫分表,如果使用不得到,還不如直接使用單一資料庫了,
2、事務問題
(1)解決方案1:使用分布式事務
① 優點
由資料庫管理,簡單有效,
② 缺點
性能代價高,特別是shard越來越多時,
(2)解決方案2:由應用程式和資料庫共同控制
① 原理
將一個分布式的大事務分解成單個資料庫的小事務,并通過應用程式來控制各個小事務,
② 優點
性能更佳
③ 缺點
需要應用程式在事務控制上做靈活設計,如果使用Spring的事務管理機制,改動起來面臨一定困難,
3、跨節點join問題
解決方式是分兩次查詢,
4、跨節點的count、order by、group by以及聚合函式問題
與join的解決方案類似,分別在各個節點得到結果然后再合并,和join的差別在于,各節點的查詢可以并行執行,因此很多時候它的速度會比單一大表快很多,但是,如果結果集很大,對應用程式記憶體的消耗也是一個問題,
5、資料遷移、容量規劃、擴容問題
6、主鍵ID問題
因為分表的原因,主鍵自增策略wufa實作,
解決方案1:UUID
使用UUID作為主鍵是最簡單的方案,但是缺點是UUID非常的長,會占用大量存盤空間,在進行連表查詢的問題上也存在性能問題,
解決方案2:多維護一個Sequence表
建立一個新表,欄位包含table_name和next_id,
看見表結構之后,秒懂吧?
大概意思就是記錄分表后的每張表的下一個ID是多少,缺點很明顯,就是每次插入資料都要訪問這張表獲取插入資料的id,該表很容易稱為系統性能的瓶頸,同時它也存在單點問題,一旦該表資料庫失效,整個系統都無法正常作業,此時可能通過主備機同步機制,解決單點問題,
解決方案3:Twitter的分布式自增ID演算法Snowflake
snowflake的結構如下(每部分用-分開):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位為未使用,接下來的41位為毫秒級時間(41位的長度可以使用69年),然后是5位datacenterId和5位workerId(10位的長度最多支持部署1024個節點) ,最后12位是毫秒內的計數(12位的計數順序號支持每個節點每毫秒產生4096個ID序號)
一共加起來剛好64位,為一個Long型,(轉換成字串后長度最多19)
snowflake生成的ID整體上按照時間自增排序,并且整個分布式系統內不會產生ID碰撞(由datacenter和workerId作區分),并且效率較高,經測驗snowflake每秒能夠產生26萬個ID,
7、跨分片的排序分頁
在不同的分片節點中將資料進行排序,并將結果機型匯總,再次排序,
四、分庫數量
分庫數量首先和單庫處理能力息息相關,比如MySQL單庫超過5000萬記錄,Oracle單庫超過1億條記錄,資料庫壓力就很大了,
在滿足上述前提下,如果分庫數量少,達不到分散存盤和減輕DB性能壓力的目的;如果分庫數量多,跨庫訪問也是個問題,如果是并發模式,要消耗寶貴的執行緒資源,如果是串行,偶數,執行時間急劇增加,
分庫數量還會直接影響硬體的投入,所以要分多少個庫,要進行綜合評估,一般初次分庫建議分為4-8個庫,
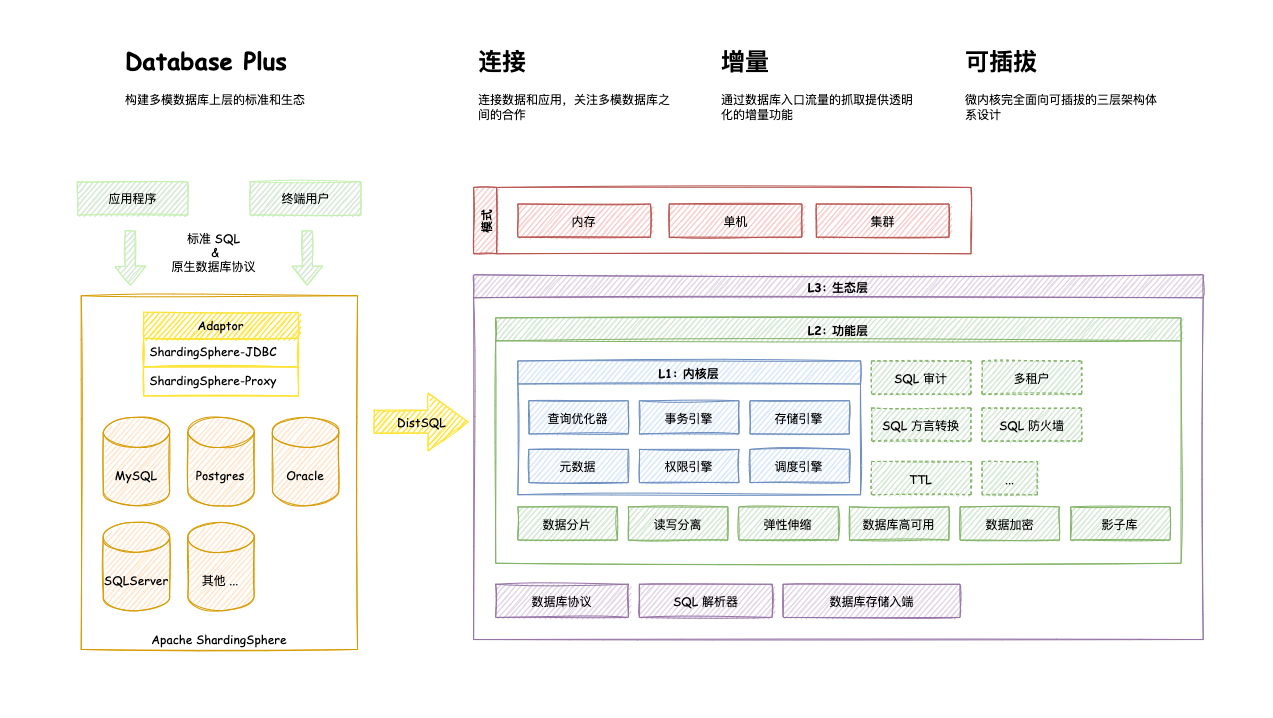
五、分庫分表第三方解決方案 -- Apache ShardingSphere
Apache ShardingSphere是一套來源的分布式資料庫中間件解決方案組成的生態圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(規劃中)這三款相互獨立,卻又能夠混合部署配合使用的產品組成,它們均提供標準化的資料分片、分布式事務和資料庫治理功能,可適用于如Java同構、異構語言、云原生等各種多樣化的應用場景,
ShardingShpere定位為關系型資料庫中間件,旨在充分合理地在分布式場景下利用關系型資料庫的計算和存盤能力,而并非實作一個全新的關系型資料庫,它通過關注不變,進而抓住事物本質,
Apache ShardingSphere 5.x版本開始致力于可插拔式架構,專案的功能組件能夠靈活的以可插拔的方式進行擴展,目前,資料分片、讀寫分離、資料加密、影子庫壓測等功能,以及MySQL、postgresql、SQLServer、Oracle等SQL與協議的支持,均通過插件的方式織入專案,開發者能夠像使用積木一樣定制資料自己的獨特系統,Apache ShardingSphere 目前已提供數十個SPI作為系統的擴展點,仍在不斷增加中,
Apache ShardingSphere 產品定位為Database Plus,旨在構建多模資料庫上層的標準和生態,它關注如何充分合理地利用資料庫的計算和存盤能力,而非實作一個全新的資料庫,Apache ShardingSphere站在資料庫的上層視角,關注它們之間的協作多于資料庫本身,
六、Apache ShardingSphere的三個核心概念
1、連接
通過對資料庫協議、SQL方言以及資料庫存盤的靈活適配,快速的連接應用與多模式的異構資料庫,
2、增量
獲取資料庫的訪問流量,并提供流量重定向(資料分片、讀寫分離、影子庫)、流量變形(資料加密、資料脫敏)、流量鑒權(安全、審計、權限)、流量治理(熔斷、限流)以及流量分析(服務質量分析、可觀察性)等透明化增量功能,
3、可插拔
專案采用微內核 + 3層可插拔模式,使內核、功能組件以及生態對接完全能夠靈活的方式進行可插拔式擴展,開發者能夠像使用積木一樣定制資料自己的獨特系統,
七、Apache ShardingSphere的三款產品
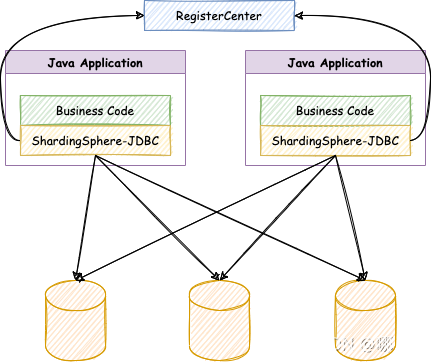
1、ShardingSphere-JDBC
定位為輕量級Java框架,在java的JDBC層提供額外服務,它使用客戶端直接連接資料庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強型的JDBC驅動,完全兼容JDBC和各種ORM框架,
適用于任何基于JDBC的ORM框架,如mybatis、hibernate、JPA、Spring JDBC Template或直接使用JDBC,
支持任意實作JDBC規范的資料庫,目前支持MySQL、Oracle、SQLServer、PostgreSQL,
支持任何第三方的資料庫連接池,如Druid、DBCP、C3P0、BoneCP、HikariCP等,
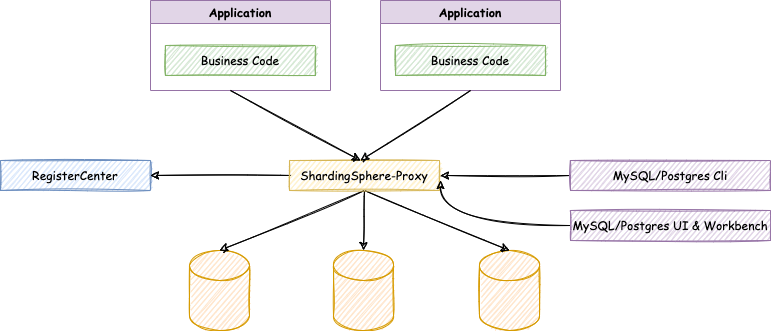
2、Sharding-Proxy
定位為透明化的資料庫代理端,提供封裝了資料庫二進制協議的服務端版本,用于完成對異構語言的支持,目前支持MySQL和PostgreSQL,它可以兼容Navicat、DBeaver等資料庫第三方客戶端,
3、ShardingSphere-Sidecar
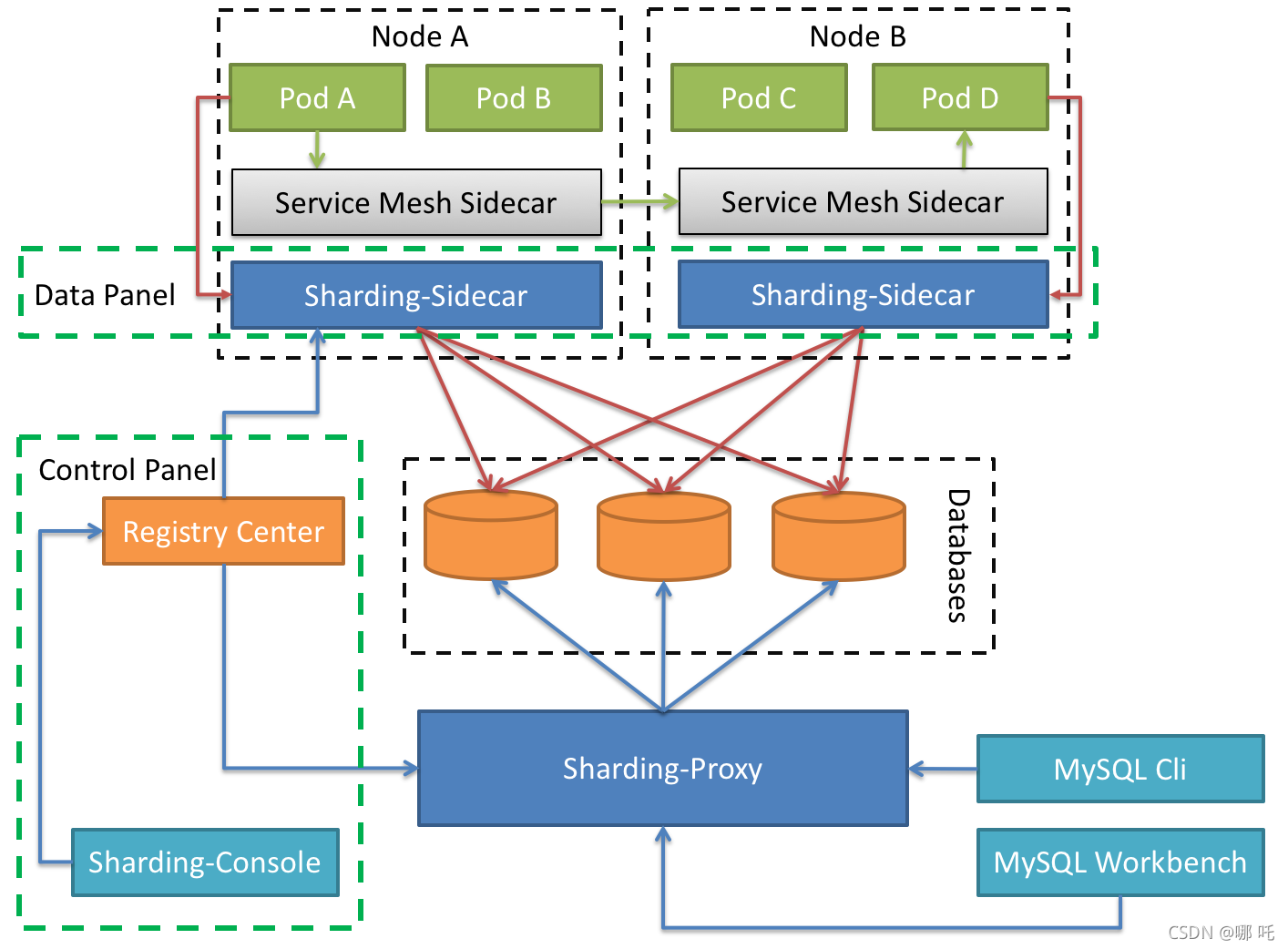
定位為kubernetes的云原生資料庫代理,以sidecar的形式代理所有對資料庫的訪問,通過無中心、零侵入的方案提供與資料庫互動的嚙合層,即Database Mesh,又可稱資料庫網格,
Database Mesh 的關注重點在于如何將分布式的資料訪問應用與資料庫有機串聯起來,它更加關注的是互動,是將雜亂無章的應用與資料庫之間的互動進行有效地梳理, 使用 Database Mesh,訪問資料庫的應用和資料庫終將形成一個巨大的網格體系,應用和資料庫只需在網格體系中對號入座即可,它們都是被嚙合層所治理的物件,
八、ShardingSphere-JDBC代碼實體
1、ShardingSphere-JDBC 實作水平分表
(1)pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.guor</groupId>
<artifactId>shardingjdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>shardingjdbc</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
(2)application.properties
ShardingSphere-JDBC 的簡單配置,參照ShardingSphere官方檔案即可,
# shardingjdbc分片策略
# 配置資料源,給資料源起名稱,
# 水平分庫,配置兩個資料源
spring.shardingsphere.datasource.names=g1
# 一個物體類對應兩張表,覆寫
spring.main.allow-bean-definition-overriding=true
#配置第一個資料源具體內容,包含連接池,驅動,地址,用戶名和密碼
spring.shardingsphere.datasource.g1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.g1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.g1.url=jdbc:mysql://localhost:3306/guor?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.g1.username=root
spring.shardingsphere.datasource.g1.password=root
#指定資料庫分布情況,資料庫里面表分布情況
spring.shardingsphere.sharding.tables.course.actual-data-nodes=g1.student_$->{1..2}
# 指定student表里面主鍵id 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# 指定表分片策略 約定id值偶數添加到student_1表,如果cid是奇數添加到student_2表
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{id % 2 + 1}
# 打開sql輸出日志
spring.shardingsphere.props.sql.show=true(3)student
package com.guor.shardingjdbc.bean;
import lombok.Data;
import java.util.Date;
@Data
public class Student {
private Long id;
private String name;
private Integer age;
private Integer sex;
private String address;
private String phone;
private Date create_time;
private Date update_time;
private String deleted;
private String teacher_id;
}
(4)mapper
由于使用的是mybatis_plus,所以單表的CRUD繼承BaseMapper即可,
package com.guor.shardingjdbc.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.guor.shardingjdbc.bean.Student;
import org.springframework.stereotype.Repository;
@Repository
public interface StudentMapper extends BaseMapper<Student> {
}
(5)啟動類
package com.guor.shardingjdbc;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.guor.shardingjdbc.mapper")
public class ShardingjdbcApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingjdbcApplication.class, args);
}
}
(6)test
package com.guor.shardingjdbc;
import com.guor.shardingjdbc.bean.Student;
import com.guor.shardingjdbc.mapper.StudentMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
@SpringBootTest
class ShardingjdbcApplicationTests {
@Autowired
private StudentMapper studentMapper;
@Test
void addStudent() {
Student student = new Student();
student.setName("哪吒");
student.setAge(18);
student.setCreate_time(new Date());
student.setPhone("10086");
studentMapper.insert(student);
}
}
(7)sql建表陳述句
-- guor.student_1 definition
CREATE TABLE `student_1` (
`id` bigint(20) DEFAULT NULL,
`name` varchar(100) NOT NULL,
`age` int(10) NOT NULL,
`sex` int(11) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`phone` varchar(100) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
`update_time` timestamp NULL DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
`teacher_id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;(8)水平分表 -> 插入資料庫

2、ShardingSphere-JDBC 實作水平分庫
首先要建一個新庫,guor1庫,然后建兩個與上述一樣的student_1和student_2表,
(1)添加application.properties
# shardingjdbc分片策略
# 配置資料源,給資料源起名稱,
# 水平分庫,配置兩個資料源
spring.shardingsphere.datasource.names=ds1,ds2
# 一個物體類對應兩張表,覆寫
spring.main.allow-bean-definition-overriding=true
#配置第一個資料源具體內容,包含連接池,驅動,地址,用戶名和密碼
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/guor?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
#配置第二個資料源具體內容,包含連接池,驅動,地址,用戶名和密碼
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/guor1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=root
#指定資料庫分布情況,資料庫里面表分布情況
spring.shardingsphere.sharding.tables.course.actual-data-nodes=ds$->{1..2}.course_$->{1..2}
# 指定student表里面主鍵id 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.student.key-generator.column=id
spring.shardingsphere.sharding.tables.student.key-generator.type=SNOWFLAKE
# 指定表分片策略 約定id值偶數添加到student_1表,如果cid是奇數添加到student_2表
spring.shardingsphere.sharding.tables.student.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.student.table-strategy.inline.algorithm-expression=student_$->{id % 2 + 1}
# 指定資料庫分片策略 約定user_id是偶數添加ds1,是奇數添加ds2
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=teacher_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{teacher_id % 2 + 1}
spring.shardingsphere.sharding.tables.student.database-strategy.inline..sharding-column=teacher_id
spring.shardingsphere.sharding.tables.student.database-strategy.inline.algorithm-expression=ds$->{teacher_id % 2 + 1}
# 打開sql輸出日志
spring.shardingsphere.props.sql.show=true(2)測驗
package com.guor.shardingjdbc;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.guor.shardingjdbc.bean.Student;
import com.guor.shardingjdbc.mapper.StudentMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Date;
@SpringBootTest
class ShardingjdbcApplicationTests {
@Autowired
private StudentMapper studentMapper;
//測驗水平分庫
@Test
void addStudentDb() {
Student student = new Student();
student.setName("哪吒");
student.setAge(28);
student.setCreate_time(new Date());
student.setPhone("110");
student.setTeacher_id(101);
studentMapper.insert(student);
}
@Test
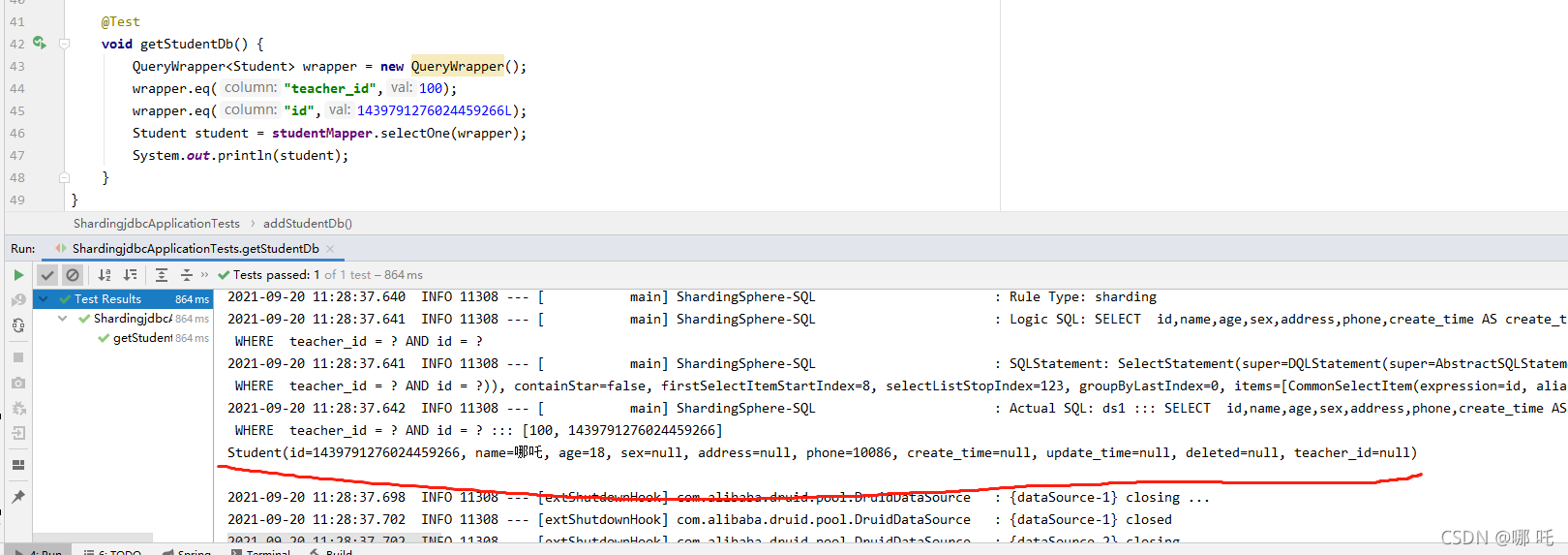
void getStudentDb() {
QueryWrapper<Student> wrapper = new QueryWrapper();
wrapper.eq("teacher_id",100);
wrapper.eq("id",1439791276024459266L);
Student student = studentMapper.selectOne(wrapper);
System.out.println(student);
}
}
(3)執行結果
水平分庫 -> 插入資料庫

水平分庫 -> 查詢資料庫
3、配置公共表
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=t_udict
spring.shardingsphere.sharding.tables.t_udict.key-generator.column=dictid
spring.shardingsphere.sharding.tables.t_udict.key-generator.type=SNOWFLAKE九、 什么是讀寫分離
為了確保資料庫產品的穩定性,很多資料庫擁有雙機熱備功能,
第一臺資料庫服務器對外提供增刪改業務的生產資料;
第二臺資料庫服務器,主要進行讀的操作;
Sharding-JDBC通過sql陳述句語意分析,實作讀寫分離程序,不會做資料同步,
十、配置MySQL主從服務器
1、新增MySQL實體
復制原有 mysql 如: D:\mysql-5.7.25( 作為主庫 ) -> D:\mysql-5.7.25-s1( 作為從庫 ) ,并修改以 下從庫的 my.ini:
[mysqld]
# 設定 3307 埠
port = 3307
# 設定 mysql 的安裝目錄
basedir = D : \mysql‐5.7.25‐s1
# 設定 mysql 資料庫的資料的存放目錄
datadir = D : \mysql‐5.7.25‐s1\data
然后將從庫安裝為 windows 服務,注意組態檔位置:
D:\mysql‐5.7.25‐s1\b in >mysqld install mysqls1
‐‐defaults‐file = "D:\mysql‐5.7.25‐s1\my.ini"
洗掉服務命令
sc delete 服務名稱
由于從庫是從主庫復制過來的,因此里面的資料完全一致,可使用原來的賬號、密碼登錄,
2、修改主、從庫的組態檔
新增內容如下:
主庫 my,ini
[mysqld]
# 開啟日志
log‐bin = mysql‐bin
# 設定服務 id ,主從不能一致
server‐id = 1
# 設定需要同步的資料庫
binlog‐do‐db = user_db
# 屏蔽系統庫同步
binlog‐ignore‐db = mysql
binlog‐ignore‐db = information_schema
binlog‐ignore‐db = performance_schema
從庫 my.ini
[mysqld]
# 開啟日志
log‐bin = mysql‐bin
# 設定服務 id ,主從不能一致
server‐id = 2
# 設定需要同步的資料庫
replicate_wild_do_table = user_db.%
# 屏蔽系統庫同步
replicate_wild_ignore_table = mysql.%
replicate_wild_ignore_table = information_schema.%
replicate_wild_ignore_table = performance_schema.%
重啟主庫和從庫
3、創建用于主從復制的賬號
# 切換至主庫 bin 目錄,登錄主庫
mysql ‐h localhost ‐uroot ‐p
# 授權主備復制專用賬號
GRANT REPLICATION SLAVE ON *.* TO 'db_sync' @ '%' IDENTIFIED BY 'db_sync' ;
# 重繪權限
FLUSH PRIVILEGES;
# 確認位點 記錄下檔案名以及位點
show master status;
4、設定從庫向主庫同步資料
#切換至從庫bin目錄,登錄從庫
mysql ‐h localhost ‐P3307 ‐uroot ‐p
# 先停止同步
STOP SLAVE;
# 修改從庫指向到主庫,使用上一步記錄的檔案名以及位點
CHANGE MASTER TO
master_host = 'localhost' ,
master_user = 'db_sync' ,
master_password = 'db_sync' ,
master_log_file = 'mysql‐bin.000002' ,
master_log_pos = 154 ;
# 啟動同步
START SLAVE;
# 查看從庫狀態 Slave_IO_Runing 和 Slave_SQL_Runing 都為 Yes 說明同步成功,如果不為 Yes ,請檢查
error_log ,然后
排查相關例外,
show slave status
# 注意 如果之前此從庫已有主庫指向 需要先執行以下命令清空
STOP SLAVE IO_THREAD FOR CHANNEL '' ;
reset slave all;
十一、Sharding-JDBC實作讀寫分離
Sharding-JDBC無法實作主從資料庫同步,主從資料庫同步是由MySQL資料庫實作的,而Sharding-JDBC實作的是增刪改時選擇操作主庫,查資料時操作從庫,
# 增加資料源s0,使用上面主從同步配置的從庫,
spring.shardingsphere.datasource.names = m0,m1,m2,s0
...
spring.shardingsphere.datasource.s0.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.s0.driver‐class‐name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.s0.url =jdbc:mysql://localhost:3307/user_db?useUnicode=true
spring.shardingsphere.datasource.s0.username = root
spring.shardingsphere.datasource.s0.password = root
....
# 主庫從庫邏輯資料源定義 ds0為user_db
spring.shardingsphere.sharding.master‐slave‐rules.ds0.master‐data‐source‐name=m0
spring.shardingsphere.sharding.master‐slave‐rules.ds0.slave‐data‐source‐names=s0
# t_user分表策略,固定分配至ds0的t_user真實表
spring.shardingsphere.sharding.tables.t_user.actual‐data‐nodes = ds0.t_user🍅 Java學習路線:搬磚工逆襲Java架構師
🍅 簡介:Java領域優質創作者🏆、CSDN哪吒公眾號作者? 、Java架構師奮斗者💪
🍅 掃描主頁左側二維碼,加入群聊,一起學習、一起進步
🍅 歡迎點贊 👍 收藏 ?留言 📝
往期精彩內容
????????連續面試失敗后,我總結了57道面試真題??,如果時光可以倒流...(附答案,建議收藏)
【搬磚工逆襲Java架構師 1】MySql基礎知識總結(2021版)
【搬磚工逆襲Java架構師 2】MySql基礎知識總結(SQL優化篇)
【搬磚工逆襲Java架構師 3】Linux基礎知識總結(2021版)
【搬磚工逆襲Java架構師 4】Redis基礎知識總結(2021版)
【搬磚工逆襲Java架構師 5】阿里Sentinel知識體系總結(2021版)
【搬磚工逆襲Java架構師 6】Spring Security知識體系總結
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/302227.html
標籤:java