目錄
- 第 21 天 - 類和物件
- 21.1創建一個類
- 21.2創建物件
- 21.3類建構式
- 21.4物件方法
- 21.5物件默認方法
- 21.6修改類默認值的方法
- 21.7繼承
- 21.8Overriding parent method
- 第 22 天 - 網頁抓取
- 22.1什么是網頁抓取
- 第 23 天 - 虛擬環境
- 23.1設定虛擬環境
- 第 24 天 - 統計
- 24.1統計資料
- 24.2什么是資料?
- 24.3統計模塊
- 24.4NumPy
- 24.5匯入 NumPy
- 24.6使用創建 numpy 陣列
- 24.7創建 float numpy 陣列
- 24.8創建布爾 numpy 陣列
- 24.9使用numpy創建多維陣列
- 24.10將 numpy 陣列轉換為串列
- 24.11從元組創建numpy陣列
- 24.12numpy 陣列的形狀
- 24.13numpy陣列的資料型別
- 24.14numpy 陣列的大小
- 24.15使用numpy進行數學運算
- 24.16添加
- 24.17減法
- 24.18乘法
- 24.19分配
- 24.20模數;找到余數
- 24.21樓層劃分
- 24.22指數
- 24.23檢查資料型別
- 24.24轉換型別
- 24.25多維陣列
- 24.26從 numpy 陣列中獲取專案
- 24.27切片 Numpy 陣列
- 24.28如何反轉行和整個陣列?
- 24.29反轉行列位置
- 24.30如何表示缺失值?
- 24.31生成亂數
- 24.32生成亂數
- 24.33Numpy 和統計
- 24.34numpy中的矩陣
- 24.35numpy numpy.arange()
- 24.36使用 linspace 創建數字序列
- 24.37NumPy 統計函式與示例
- 24.38如何創建重復序列?
- 24.39如何生成亂數?
- 24.40線性代數
- 24.41NumPy 矩陣乘法與 np.matmul()
- 第 25 天 - Pandas
- 25.1安裝pandas
- 匯入pandas
- 25.2使用默認索引創建 Pandas 系列
- 25.3使用自定義索引創建 Pandas 系列
- 25.4從字典創建 Pandas 系列
- 25.5創建一個常量 Pandas 系列
- 25.6使用 Linspace 創建 Pandas 系列
- 25.7資料幀
- 從串列串列創建資料幀
- 25.8使用字典創建 DataFrame
- 25.9從字典串列創建資料幀
- 25.10使用 Pandas 讀取 CSV 檔案
- 25.11資料探索
- 25.12修改資料幀
- 25.13創建資料幀
- 25.14添加新列
- 25.15修改列值
- 25.16格式化 DataFrame 列
- 25.17檢查列值的資料型別
- 25.18布爾索引

你們的三連(點贊,收藏,評論)是我持續輸出的動力,感謝,
在興趣中學習,效益超乎想象,有趣的原始碼與學習經驗,工具安裝包,歡迎加我的微信:bobin1124,一起交流學習與分享,
第 21 天 - 類和物件
Python 是一種面向物件的編程語言,Python 中的一切都是一個物件,有它的屬性和方法,程式中使用的數字、字串、串列、字典、元組、集合等是相應內置類的物件,我們創建類來創建一個物件,一個類就像一個物件建構式,或者是創建物件的“藍圖”,我們實體化一個類來創建一個物件,類定義了物件的屬性和行為,而另一方面,物件代表了類,
從這個挑戰一開始,我們就在不知不覺中處理類和物件,Python 程式中的每個元素都是一個類的物件,讓我們檢查一下python中的所有東西是否都是一個類:
asabeneh @ Asabeneh:~ $ python
Python 3.9,6(默認,2021 年6月 28 日 ,15:26:21)
[鏘 11.0 0.0(鐺- 1100.0,33.8)在 達爾文
式 的“幫助”,“著作權”,“信用” 或 “許可” 的 更多 資訊,
>> > num = 10
>> > type ( num )
< class 'int' >
>> > string = 'string'
>> > 類 'STR' >
>> > 布爾 = 真
>> > 型別(布爾)
<類 '布爾' >
>> > LST = []
>> > 型(LST)
<類 '串列' >
>> > TPL =( )
>> > 型別( tpl )
< class 'tuple' >
>> > SET1 = 集()
>> > 型別(set1)
< class 'set' >
>> > dct = {}
>> > 型別(dct)
< class 'dict' >
21.1創建一個類
要創建一個類,我們需要關鍵字類,后跟名稱和冒號,類名應該是CamelCase,
#語法
類類名:
代碼在這里
例子:
類 人:
通過
列印(人)
< __main__.Person 物件在 0x10804e 510>
21.2創建物件
我們可以通過呼叫類來創建一個物件,
p = 人()
列印( p )
21.3類建構式
在上面的例子中,我們從 Person 類創建了一個物件,然而,沒有建構式的類在實際應用中并沒有真正的用處,讓我們使用建構式使我們的類更有用,與Java或JavaScript中的建構式一樣,Python也有內置的init ()建構式,的初始化建構式有自引數這對類的當前實體的參考
實施例:
class Person :
def __init__ ( self , name ):
# self 允許將引數附加到類
self,姓名 =姓名
p = Person ( 'Asabeneh' )
列印( p . name )
列印( p )
#輸出
阿薩貝內
< __main__.Person 物件在 0x2abf46907e 80>
讓我們向建構式添加更多引數,
class Person :
def __init__ ( self , firstname , lastname , age , country , city ):
self,名字 = 名字
自我,姓氏 = 姓氏
自我,年齡 = 年齡
自我,國家 = 國家
自我,城市 = 城市
p = Person ( 'Asabeneh' , 'Yetayeh' , 250 , 'Finland' , 'Helsinki' )
print ( p . firstname )
print ( p . lastname )
print ( p . age )
print ( p . country )
print ( p .城市)
#輸出
阿薩貝內
耶塔耶
250
芬蘭
赫爾辛基
21.4物件方法
物件可以有方法,方法是屬于物件的函式,
例子:
class Person :
def __init__ ( self , firstname , lastname , age , country , city ):
self,名字 = 名字
自我,姓氏 = 姓氏
自我,年齡 = 年齡
自我,國家 = 國家
自我,city = city
def person_info ( self ):
回傳 f' {自我,名字} {自我,姓氏}是{ self,年齡}歲,他住在{自我,城市},{自我,國家} '
p = 人('Asabeneh' ,'Yetayeh' ,250,'芬蘭','赫爾辛基')
列印(p,person_info())
#輸出
Asabeneh Yetayeh 已經 250 歲了,他住在芬蘭赫爾辛基
21.5物件默認方法
有時,您可能希望為物件方法設定默認值,如果我們在建構式中給引數賦予默認值,就可以避免在不帶引數的情況下呼叫或實體化我們的類時出錯,讓我們看看它的外觀:
例子:
class Person :
def __init__ ( self , firstname = 'Asabeneh' , lastname = 'Yetayeh' , age = 250 , country = 'Finland' , city = 'Helsinki' ):
self,名字 = 名字
自我,姓氏 = 姓氏
自我,年齡 = 年齡
自我,國家 = 國家
自我. 城市 = 城市
def person_info ( self ):
回傳 f' { self . 名字} {自我,姓氏}是{ self,年齡}歲,他住在{自我,城市},{自我,國家} .'
P1 = 人()
列印(P1,person_info())
P2 = 人('約翰','李四',30,'Nomanland' , “諾曼城市)
列印(P2,person_info())
#輸出
Asabeneh Yetayeh 已經 250 歲了,他住在芬蘭赫爾辛基,
約翰·多伊今年 30 歲,他住在諾曼蘭的諾曼城,
21.6修改類默認值的方法
在下面的例子中,person 類,所有的建構式引數都有默認值,除此之外,我們還有技能引數,我們可以使用方法訪問它,讓我們創建 add_skill 方法來將技能添加到技能串列中,
class Person :
def __init__ ( self , firstname = 'Asabeneh' , lastname = 'Yetayeh' , age = 250 , country = 'Finland' , city = 'Helsinki' ):
self,名字 = 名字
自我,姓氏 = 姓氏
自我,年齡 = 年齡
自我,國家 = 國家
自我. 城市 = 城市
自我,技能 = []
def person_info ( self ):
回傳 f' { self . 名字} {自我,姓氏}是{ self,年齡}歲,他住在{自我,城市},{自我,國家} .'
def add_skill(自我,技能):
自我,技能,追加(技能)
p1 = Person ()
列印( p1 . person_info ())
p1 . add_skill ( 'HTML' )
p1,add_skill ( 'CSS' )
p1,add_skill('的JavaScript' )
P2 = 人('約翰','李四',30,'Nomanland' , “諾曼城市)
列印(P2,person_info())
印刷(P1. 技能)
列印(p2,技能)
#輸出
Asabeneh Yetayeh 已經 250 歲了,他住在芬蘭赫爾辛基,
約翰·多伊今年 30 歲,他住在諾曼蘭的諾曼城,
[ ' HTML '、' CSS '、' JavaScript ' ]
[]
21.7繼承
使用繼承,我們可以重用父類代碼,繼承允許我們定義一個繼承父類的所有方法和屬性的類,父類或超類或基類是提供所有方法和屬性的類,子類是從另一個類或父類繼承的類,讓我們通過繼承person類來創建一個student類,
班級 學生(人):
通過
S1 = 學生('Eyob' ,'Yetayeh' ,30,'芬蘭','赫爾辛基')
S2 = 學生('了Lidiya' ,'Teklemariam' ,28,'芬蘭','埃斯波')
印刷(S1,person_info( ))
s1,add_skill ( 'JavaScript' )
s1,add_skill ( '反應' )
s1,'Python' )
列印( s1 .技能)
列印(S2,person_info())
S2,add_skill ( '組織' )
s2,add_skill ( '營銷' )
s2,add_skill ( '數字營銷' )
列印( s2 . Skill )
輸出
Eyob Yetayeh 30 歲,他住在芬蘭赫爾辛基,
[ ' JavaScript '、' React '、' Python ' ]
Lidiya Teklemariam 28 歲,他住在芬蘭的埃斯波,
[ “組織”、“營銷”、“數字營銷” ]
我們沒有在子類中呼叫init ()建構式,如果我們沒有呼叫它,那么我們仍然可以從父級訪問所有屬性,但是如果我們確實呼叫了建構式,我們就可以通過呼叫super來訪問父屬性,
我們可以向子類添加新方法,也可以通過在子類中創建相同的方法名稱來覆寫父類方法,當我們添加init ()函式時,子類將不再繼承父類的init ()函式,
21.8Overriding parent method
類 學生(人):
高清 __init__(自我,名字= 'Asabeneh' ,姓氏= 'Yetayeh' ,年齡= 250,全國= '芬蘭,城市= '赫爾辛基',性別= '男'):
自我,性別 = 性別
超(),__init__(名字,姓氏,年齡,country , city )
def person_info ( self ):
性別 = 'He' if self,性別 == '男' 否則 '她'
回傳 f' { self . 名字} {自我,姓氏}是{ self,年齡}歲,{性別}生活在{自我,城市} , {自己. 國家} .'
s1 = Student ( 'Eyob' , 'Yetayeh' , 30 , 'Finland' , 'Helsinki' , 'male' )
s2 = Student ( 'Lidiya' , 'Teklemariam' , 28 , 'Finland' , 'Espoo' , 'female' ' )
列印( s1 . person_info ())
s1 . add_skill ( 'JavaScript' )
s1,s1,add_skill('Python的)
印刷(S1,技能)
列印(S2,person_info())
S2,add_skill ( '組織' )
s2,add_skill ( '營銷' )
s2,add_skill ( '數字營銷' )
列印( s2 . Skill )
Eyob Yetayeh 30 歲,他住在芬蘭赫爾辛基,
[ ' JavaScript '、' React '、' Python ' ]
Lidiya Teklemariam 28 歲,她住在芬蘭的埃斯波,
[ “組織”、“營銷”、“數字營銷” ]
我們可以使用 super() 內置函式或父名 Person 來自動繼承其父級的方法和屬性,在上面的例子中,我們Overriding parent method的方法,child 方法有一個不同的特點,它可以識別性別是男性還是女性并指定適當的代詞(他/她)
第 22 天 - 網頁抓取
22.1什么是網頁抓取
互聯網充滿了可用于不同目的的大量資料,為了收集這些資料,我們需要知道如何從網站上抓取資料,
網頁抓取是從網站中提取和收集資料并將其存盤在本地機器或資料庫中的程序,
在本節中,我們將使用 beautifulsoup 和 requests 包來抓取資料,我們使用的包版本是beautifulsoup 4,
要開始抓取網站,您需要請求、beautifoulSoup4和網站,
pip 安裝請求
pip 安裝 beautifulsoup4
要從網站抓取資料,需要對 HTML 標簽和 CSS 選擇器有基本的了解,我們使用 HTML 標簽、類或/和 ID 定位來自網站的內容,讓我們匯入 requests 和 BeautifulSoup 模塊
進口 請求
從 BS4 進口 BeautifulSoup
讓我們為要抓取的網站宣告 url 變數,
來自bs4 的匯入請求
import BeautifulSoup url = 'https://archive.ics.uci.edu/ml/datasets.php'
# 讓我們使用 requests 的 get 方法從 url 中獲取資料
回應 = 請求,get ( url )
# 讓我們檢查狀態
status = response,status_code
print ( status ) # 200 表示獲取成功
200
使用beautifulSoup決議頁面內容
來自bs4 的匯入請求
import BeautifulSoup url = 'https://archive.ics.uci.edu/ml/datasets.php'
回應 = 請求,獲取(網址)
內容 = 回應,content # 我們從網站上獲取所有內容
soup = BeautifulSoup ( content , 'html.parser' ) # beautiful
Soup將有機會決議print ( soup . title ) # <title>UCI Machine Learning Repository: Data Sets</標題>
列印(湯,標題,get_text())#UCI機器學習庫:資料集
列印(湯,體)#給網站上的整個頁面
列印(回應,STATUS_CODE)
桌子 = 湯,find_all ( 'table' , { 'cellpadding' : '3' })
# 我們的目標是 cellpadding 屬性值為 3 的表格
# 我們可以選擇使用 id、class 或 HTML 標簽,更多資訊請查看beautifulsoup doc
table = 表[ 0 ] #,結果是一個串列,我們是從它取出資料
為 TD 在 表,找到('tr'),find_all ( 'td' ):
列印( td . text)
如果你運行這段代碼,你可以看到提取已經完成了一半,
🌕你很特別,每天都在進步,您距離通往偉大的道路只剩下八天了,
🎉 恭喜! 🎉
第 23 天 - 虛擬環境
23.1設定虛擬環境
從專案開始,最好有一個虛擬環境,虛擬環境可以幫助我們創建一個孤立或分離的環境,這將幫助我們避免跨專案的依賴沖突,如果您在終端上撰寫 pip freeze ,您將在計算機上看到所有已安裝的軟體包,如果我們使用 virtualenv,我們將只訪問特定于該專案的包,打開終端并安裝 virtualenv
asabeneh@Asabeneh: ~ $ pip install virtualenv
在 30DaysOfPython 檔案夾中創建一個 flask_project 檔案夾,
安裝 virtualenv 包后,轉到您的專案檔案夾并通過撰寫以下內容創建一個虛擬環境:
對于 Mac/Linux:
asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project \$ virtualenv venv
對于 Windows:
C:\ú SERS \ú SER \ d ocuments \ 3 0DaysOfPython \?F lask_project >蟒-m VENV VENV
我更喜歡將新專案稱為 venv,但可以隨意使用不同的名稱,讓我們檢查 venv 是否是通過使用 ls(或 dir 用于 Windows 命令提示符)命令創建的,
asabeneh@Asabeneh:~ /Desktop/30DaysOfPython/flask_project$ ls
靜脈/
讓我們通過在我們的專案檔案夾中撰寫以下命令來激活虛擬環境,
對于 Mac/Linux:
asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$ source venv/bin/activate
在 Windows 中激活虛擬環境可能非常依賴于 Windows Power shell 和 git bash,
對于 Windows 電源外殼:
C:\ú SERS \ú SER \ d ocuments \ 3 0DaysOfPython \?F lask_project > VENV \ S cripts \一個ctivate
對于 Windows Git bash:
C:\ú SERS \ú SER \ d ocuments \ 3 0DaysOfPython \?F lask_project > VENV \ S cripts \,啟用
撰寫激活命令后,您的專案目錄將以 venv 開頭,請參閱下面的示例,
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$
現在,讓我們通過撰寫 pip freeze 來檢查這個專案中的可用包,您將看不到任何包,
我們將要做一個Flask小專案,所以讓我們將Flask包安裝到這個專案中,
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$ pip install Flask
現在,讓我們撰寫 pip freeze 來查看專案中已安裝包的串列:
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$ pip freeze
點擊==7.0
Flask==1.1.1
它的危險==1.1.0
Jinja2==2.10.3
標記安全==1.1.1
Werkzeug==0.16.0
完成后,您應該使用deactivate 停用活動專案,
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython$ 停用
安裝了使用Flask的必要模塊,現在,您的專案目錄已準備好用于Flask專案,
🎉 恭喜! 🎉
第 24 天 - 統計
24.1統計資料
統計學是研究資料的收集、組織、顯示、分析、解釋和呈現的學科,統計學是數學的一個分支,建議作為資料科學和機器學習的先決條件,統計學是一個非常廣泛的領域,但我們將在本節中只關注最相關的部分,完成此挑戰后,您可以進入 Web 開發、資料分析、機器學習和資料科學路徑,無論您走哪條路,在您職業生涯的某個階段,您都會獲得可以處理的資料,擁有一些統計知識將幫助您根據資料做出決策,資料如他們所說,
24.2什么是資料?
資料是為某種目的(通常是分析)收集和翻譯的任何字符集,它可以是任何字符,包括文本和數字、圖片、聲音或視頻,如果資料沒有放在背景關系中,它對人或計算機沒有任何意義,為了讓資料有意義,我們需要使用不同的工具處理資料,
資料分析、資料科學或機器學習的作業流程始于資料,可以從某個資料源提供資料,也可以創建資料,有結構化和非結構化資料,
可以以小格式或大格式找到資料,我們將獲得的大多數資料型別已在檔案處理部分中介紹,
24.3統計模塊
Python統計模塊提供了計算數值資料的數理統計的函式,該模塊無意成為第三方庫(如 NumPy、SciPy)或面向專業統計學家(如 Minitab、SAS 和 Matlab)的專有全功能統計軟體包的競爭對手,它針對圖形和科學計算器的級別,
24.4NumPy
在第一部分中,我們將 Python 本身定義為一種出色的通用編程語言,但在其他流行庫(numpy、scipy、matplotlib、pandas 等)的幫助下,它成為了一個強大的科學計算環境,
NumPy 是 Python 科學計算的核心庫,它提供了一個高性能的多維陣列物件,以及用于處理陣列的工具,
到目前為止,我們一直在使用 vscode,但從現在開始我會推薦使用 Jupyter Notebook,要訪問 jupyter notebook,讓我們安裝anaconda,如果您使用的是 anaconda,則大多數常用軟體包都已包含在內,如果您安裝了 anaconda,則您沒有安裝軟體包,
asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython$ pip install numpy
24.5匯入 NumPy
如果您支持 jupyter notebook,則可以使用Jupyter notebook
# 如何匯入 numpy
import numpy as np
# 如何檢查 numpy 包的版本
print ( 'numpy:' , np . __version__ )
# 檢查可用方法
print ( dir ( np ))
24.6使用創建 numpy 陣列
創建 int numpy 陣列
# 創建 python 串列
python_list = [ 1 , 2 , 3 , 4 , 5 ]
# 檢查資料型別
print ( 'Type:' , type ( python_list )) # <class 'list'>
#
print ( python_list ) # [1, 2, 3, 4, 5]
二維串列 = [[ 0 , 1 , 2 ], [ 3 , 4 , 5 ], [ 6 , 7 , 8 ]]
列印(二維串列) # [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
# 從 python 串列創建 Numpy(Numerical Python) 陣列
numpy_array_from_list = np,array ( python_list )
print ( type ( numpy_array_from_list )) # <class 'numpy.ndarray'>
print ( numpy_array_from_list ) # array([1, 2, 3, 4, 5])
24.7創建 float numpy 陣列
使用浮點資料型別引數從串列創建浮點 numpy 陣列
# Python 串列
python_list = [ 1 , 2 , 3 , 4 , 5 ]
numy_array_from_list2 = np,陣列(python_list,D型細胞=浮動)
列印(numy_array_from_list2)#陣列([1,2,3,4,5])
24.8創建布爾 numpy 陣列
從串列創建一個布林值 numpy 陣列
numpy_bool_array = np,陣列([ 0 , 1 , - 1 , 0 , 0 ], dtype = bool )
列印( numpy_bool_array ) # 陣列([假, 真, 真, 假, 假])
24.9使用numpy創建多維陣列
一個 numpy 陣列可能有一個或多個行和列
two_Dimension_list = [[ 0 , 1 , 2 ], [ 3 , 4 , 5 ], [ 6 , 7 , 8 ]]
numpy_two_dimensional_list = np,陣列(二維串列)
列印(型別(numpy_two_dimensional_list))
列印(numpy_two_dimensional_list)
<類’ numpy.ndarray ’ >
[[0 1 2]
[3 4 5]
[6 7 8]]
24.10將 numpy 陣列轉換為串列
# 我們總是可以使用 tolist() 將陣列轉換回 Python 串列,
np_to_list = numpy_array_from_list,tolist()
列印(型別(np_to_list))
列印('一個維陣列:',np_to_list)
列印('二維陣列:',numpy_two_dimensional_list,tolist())
<類'串列' >
一維陣列:[1, 2, 3, 4, 5]
二維陣列:[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
24.11從元組創建numpy陣列
# Numpy array from tuple
# 在 Python 中創建元組
python_tuple = ( 1 , 2 , 3 , 4 , 5 )
print ( type ( python_tuple )) # <class 'tuple'>
print ( 'python_tuple: ' , python_tuple ) # python_tuple: ( 1, 2, 3, 4, 5)
numpy_array_from_tuple = np,array ( python_tuple )
print ( type ( numpy_array_from_tuple )) # <class 'numpy.ndarray'>
print ( 'numpy_array_from_tuple: ' , numpy_array_from_tuple ) # numpy_array_from_tuple: [1 2 3 4 5]
24.12numpy 陣列的形狀
shape 方法以元組的形式提供陣列的形狀,第一個是行,第二個是列,如果陣列只是一維,則回傳陣列的大小,
數字 = np,陣列([ 1,2,3,4,5 ])
列印(NUMS)
列印('NUMS的形狀:',NUMS,形狀)
列印(numpy_two_dimensional_list)
列印('numpy_two_dimensional_list的形狀:',numpy_two_dimensional_list,形狀)
three_by_four_array = NP,陣列([[ 0, 1 , 2 , 3 ],
[ 4 , 5 , 6 , 7 ],
[ 8,9,10,11 ]])
列印(three_by_four_array,形狀)
[1 2 3 4 5]
數字的形狀:(5,)
[[0 1 2]
[3 4 5]
[6 7 8]]
numpy_two_dimensional_list 的形狀:(3, 3)
(3, 4)
24.13numpy陣列的資料型別
資料型別型別:str、int、float、complex、bool、list、None
int_lists = [ - 3 , - 2 , - 1 , 0 , 1 , 2 , 3 ]
int_array = np . 陣列(int_lists)
float_array = np,陣列(int_lists,D型細胞=浮動)
列印(INT_ARRAY)
列印(INT_ARRAY,D型細胞)
列印(float_array)
列印(float_array,D型)
[-3 -2 -1 0 1 2 3]
int64
[-3,-2. -1. 0. 1. 2. 3.]
浮動64
24.14numpy 陣列的大小
在 numpy 中要知道 numpy 陣列串列中的專案數,我們使用 size
numpy_array_from_list = np,陣列([ 1 , 2 , 3 , 4 , 5 ])
two_dimensional_list = np,陣列([[ 0 , 1 , 2 ],
[ 3 , 4 , 5 ],
[ 6 , 7 , 8 ]])
print ( 'The size:' , numpy_array_from_list . size ) # 5
print ( 'The size:' , two_dimensional_list . size ) # 3
尺寸:5
尺寸:9
24.15使用numpy進行數學運算
NumPy 陣列并不完全像 python 串列,要在 Python 串列中進行數學運算,我們必須遍歷專案,但 numpy 可以允許在不回圈的情況下進行任何數學運算,數學運算:
- 加法 (+)
- 減法 (-)
- 乘法 (*)
- 分配 (/)
- 模塊 (%)
- 樓層劃分(//)
- 指數(**)
24.16添加
# 數學運算
# 加法
numpy_array_from_list = np . 陣列([ 1 , 2 , 3 , 4 , 5 ])
列印( '原始陣列: ' , numpy_array_from_list )
ten_plus_original = numpy_array_from_list + 10
列印( ten_plus_original )
原始陣列:[1 2 3 4 5]
[11 12 13 14 15]
24.17減法
# 減法
numpy_array_from_list = np . 陣列([ 1 , 2 , 3 , 4 , 5 ])
列印( '原始陣列: ' , numpy_array_from_list )
ten_minus_original = numpy_array_from_list - 10
列印( ten_minus_original )
原始陣列:[1 2 3 4 5]
[-9 -8 -7 -6 -5]
24.18乘法
numpy_array_from_list = np . 陣列([ 1 , 2 , 3 , 4 , 5 ])
列印( '原始陣列: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list * 10
列印( ten_times_original )
原始陣列:[1 2 3 4 5]
[10 20 30 40 50]
24.19分配
# 除法
numpy_array_from_list = np . 陣列([ 1 , 2 , 3 , 4 , 5 ])
列印( '原始陣列: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list / 10
列印( ten_times_original )
原始陣列:[1 2 3 4 5]
[0.1 0.2 0.3 0.4 0.5]
24.20模數;找到余數
numpy_array_from_list = np,陣列([ 1 , 2 , 3 , 4 , 5 ])
列印( '原始陣列: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list % 3
列印( ten_times_original )
原始陣列:[1 2 3 4 5]
[1 2 0 1 2]
24.21樓層劃分
# 樓層除法:沒有余數的除法結果
numpy_array_from_list = np . 陣列([ 1 , 2 , 3 , 4 , 5 ])
列印( '原始陣列: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list // 10
列印( ten_times_original )
24.22指數
# Exponential 是找到某個數字的另一個冪:
numpy_array_from_list = np,陣列([ 1 , 2 , 3 , 4 , 5 ])
列印( '原始陣列: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list ** 2
列印( ten_times_original )
原始陣列:[1 2 3 4 5]
[ 1 4 9 16 25]
24.23檢查資料型別
#Int, 浮點數
numpy_int_arr = np . 陣列([ 1 , 2 , 3 , 4 ])
numpy_float_arr = np,陣列([ 1.1 , 2.0 , 3.2 ])
numpy_bool_arr = np,陣列([ - 3 , - 2 , 0 , 1 , 2 , 3 ], dtype = 'bool' )
列印(numpy_int_arr,D型細胞)
列印(numpy_float_arr,D型細胞)
列印(numpy_bool_arr,D型)
int64
浮動64
布林值
24.24轉換型別
我們可以轉換numpy陣列的資料型別
1.整數到浮動
numpy_int_arr = np,陣列([ 1 , 2 , 3 , 4 ], dtype = 'float' )
numpy_int_arr
array([1., 2., 3., 4.])
2.浮動到整數
numpy_int_arr = np,陣列([ 1. , 2. , 3. , 4. ], dtype = 'int' )
numpy_int_arr
陣列([1, 2, 3, 4])
3.整數或布林值
NP,陣列([ - 3 , - 2 , 0 , 1 , 2 , 3 ], dtype = 'bool' )
陣列([真,真,假,真,真,真])
4.整數到 str
numpy_float_list,astype ( 'int' ),astype('str')
陣列([ ’ 1 ’ , ’ 2 ’ , ’ 3 ’ ], dtype= ’ <U21 ’ )
24.25多維陣列
# 2 維陣列
two_dimension_array = np . array ([( 1 , 2 , 3 ),( 4 , 5 , 6 ), ( 7 , 8 , 9 )])
print ( type ( two_dimension_array ))
print ( two_dimension_array )
print ( 'Shape: ' , two_dimension_array . shape )
列印( '大小:',two_dimension_array,尺寸)
的列印('資料型別:',two_dimension_array,D型)
<類’ numpy.ndarray ’ >
[[1 2 3]
[4 5 6]
[7 8 9]]
形狀:(3, 3)
尺寸:9
資料型別:int64
24.26從 numpy 陣列中獲取專案
# 2 維陣列
two_dimension_array = np . 陣列([[ 1,2,3 ],[ 4,5,6 ],[ 7,8,9 ]])
FIRST_ROW = two_dimension_array [ 0 ]
second_row = two_dimension_array [ 1 ]
third_row = two_dimension_array [ 2 ]
列印(“第一行:' , first_row )
列印('第二行:',second_row)
列印('第三行:',third_row)
第一行:[1 2 3]
第二行:[4 5 6]
第三行:[7 8 9]
first_column = two_dimension_array [:, 0 ]
second_column = two_dimension_array [:, 1 ]
third_column = two_dimension_array [:, 2 ]
print ( 'First column:' , first_column )
print ( 'Second column:' , second_column )
print ( '第三列: ' , third_column )
列印( two_dimension_array )
第一列:[1 4 7]
第二列:[2 5 8]
第三列:[3 6 9]
[[1 2 3]
[4 5 6]
[7 8 9]]
24.27切片 Numpy 陣列
在 numpy 中切片類似于在 python list 中切片
two_dimension_array = np,陣列([[ 1 , 2 , 3 ],[ 4 , 5 , 6 ], [ 7 , 8 , 9 ]])
first_two_rows_and_columns = two_dimension_array [ 0 : 2 , 0 : 2 ]
列印( first_two_rows_and_columns )
[[1 2]
[4 5]]
24.28如何反轉行和整個陣列?
二維陣列[::]
陣列([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
24.29反轉行列位置
two_dimension_array = np,陣列([[ 1 , 2 , 3 ],[ 4 , 5 , 6 ], [ 7 , 8 , 9 ]])
two_dimension_array [:: - 1 ,:: - 1 ]
陣列([[9, 8, 7],
[6, 5, 4],
[3, 2, 1]])
24.30如何表示缺失值?
列印( two_dimension_array )
two_dimension_array [ 1 , 1 ] = 55
two_dimension_array [ 1 , 2 ] = 44
列印( two_dimension_array )
[[1 2 3]
[4 5 6]
[7 8 9]]
[[ 1 2 3]
[ 4 55 44]
[ 7 8 9]]
# Numpy
Zeroes # numpy.zeros(shape, dtype=float, order='C')
numpy_zeroes = np . 零(( 3 , 3 ), dtype = int , order = 'C' )
numpy_zeroes
陣列([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
# Numpy
歸零 numpy_ones = np . 個(( 3 , 3 ), dtype = int , order = 'C' )
列印( numpy_ones )
[[1 1 1]
[1 1 1]
[1 1 1]]
兩個 = numpy_ones * 2
# 重塑
# numpy.reshape(), numpy.flatten()
first_shape = np . 陣列([(1,2,3),(4,5,6)])
列印(first_shape)
重構 = first_shape,重塑(3,2)
列印(重塑)
[[1 2 3]
[4 5 6]]
[[1 2]
[3 4]
[5 6]]
扁平 = 重塑,flatten ()
扁平化
陣列([1, 2, 3, 4, 5, 6])
## 水平堆疊
np_list_one = np . 陣列([ 1 , 2 , 3 ])
np_list_two = np . 陣列([ 4 , 5 , 6 ])
列印(np_list_one + np_list_two)
列印('水平附加:',NP,hstack((np_list_one,np_list_two)))
[5 7 9]
水平追加:[1 2 3 4 5 6]
##垂直疊
列印(‘垂直附加:’,NP,vstack((np_list_one,np_list_two)))
垂直附加:[[1 2 3]
[4 5 6]]
24.31生成亂數
# 生成一個隨機浮點數
random_float = np . 隨機的,隨機()
random_float
0.018929887384753874
# 生成一個隨機浮點數
random_floats = np . 隨機的,隨機( 5 )
random_floats
陣列([0.26392192, 0.35842215, 0.87908478, 0.41902195, 0.78926418])
# 生成 0 到 10 之間的隨機整數
random_int = np,隨機的,randint ( 0 , 11 )
random_int
4
# 生成一個 2 到 11 之間的隨機整數,并創建一個
單行 陣列random_int = np . 隨機的,randint ( 2 , 10 , size = 4 )
random_int
陣列([8, 8, 8, 2])
# 生成 0 到 10 之間的隨機整數
random_int = np . 隨機的,randint ( 2 , 10 , size = ( 3 , 3 ))
random_int
陣列([[3, 5, 3],
[7, 3, 6],
[2, 3, 3]])
24.32生成亂數
# np.random.normal(mu, sigma, size)
normal_array = np . 隨機的,正常( 79 , 15 , 80 )
normal_array
陣列([ 89.49990595, 82.06056961, 107.21445842, 38.69307086,
47.85259157、93.07381061、76.40724259、78.55675184、
72.17358173、47.9888899、65.10370622、76.29696568、
95.58234254、68.14897213、38.75862686、122.5587927、
67.0762565、95.73990864、81.97454563、92.54264805、
59.37035153、77.76828101、52.30752166、64.43109931、
62.63695351、90.04616138、75.70009094、49.87586877、
80.22002414、68.56708848、76.27791052、67.24343975、
81.86363935、78.22703433、102.85737041、65.15700341、
84.87033426、76.7569997、64.61321853、67.37244562、
74.4068773、58.65119655、71.66488727、53.42458179、
70.26872028、60.96588544、83.56129414、72.14255326、
81.00787609、71.81264853、72.64168853、86.56608717、
94.94667321、82.32676973、70.5165446、85.43061003、
72.45526212、87.34681775、87.69911217、103.02831489、
75.28598596、67.17806893、92.41274447、101.06662611、
87.70013935、70.73980645、46.40368207、50.17947092、
61.75618542、90.26191397、78.63968639、70.84550744、
88.91826581、103.91474733、66.3064638、79.49726264、
70.81087439, 83.90130623, 87.58555972, 59.95462521])
24.33Numpy 和統計
匯入 matplotlib,pyplot as plt
將 seaborn 作為 sns
sns匯入,設定()
plt,hist ( normal_array , color = "grey" , bins = 50 )
(陣列([2., 0., 0., 0., 1., 2., 2., 0., 2., 0., 0., 1., 2., 2., 1., 4 ., 3.,
4., 2., 7., 2., 2., 5., 4., 2., 4., 3., 2., 1., 5., 3., 0., 3., 2. ,
1., 0., 0., 1., 3., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1.]),
陣列([ 38.69307086, 40.37038529, 42.04769973, 43.72501417,
45.4023286、47.07964304、48.75695748、50.43427191、
52.11158635、53.78890079、55.46621523、57.14352966、
58.8208441、60.49815854、62.17547297、63.85278741、
65.53010185、67.20741628、68.88473072、70.56204516、
72.23935959、73.91667403、75.59398847、77.27130291、
78.94861734、80.62593178、82.30324622、83.98056065、
85.65787509、87.33518953、89.01250396、90.6898184、
92.36713284、94.04444727、95.72176171、97.39907615、
99.07639058、100.75370502、102.43101946、104.1083339、
105.78564833、107.46296277、109.14027721、110.81759164、
112.49490608、114.17222052、115.84953495、117.52684939、
119.20416383, 120.88147826, 122.5587927 ]),
< 50 個 Patch 物件的串列> )
24.34numpy中的矩陣
Four_by_four_matrix = np . 矩陣(NP,者((4,4),D型細胞=浮動))
Four_by_four_matrix
矩陣([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
NP,asarray(four_by_four_matrix)[ 2 ] = 2個
four_by_four_matrix
矩陣([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[1., 1., 1., 1.]])
24.35numpy numpy.arange()
有時,您希望創建在定義的間隔內均勻分布的值,例如,您想創建從 1 到 10 的值;你可以使用 numpy.arange() 函式
# 使用 range(starting, stop, step) 創建串列
lst = range ( 0 , 11 , 2 )
lst
范圍( 0 , 11 , 2 )
for l in lst :
列印( l )
2
4
6
8
10
# 類似于范圍 arange numpy.arange(start, stop, step)
whole_numbers = np . 范圍( 0 , 20 , 1 )
整數
陣列([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])
natural_numbers = np,arange ( 1 , 20 , 1 )
natural_numbers
奇數 = np,arange ( 1 , 20 , 2 )
奇數
陣列([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
even_numbers = np,arange ( 2 , 20 , 2 )
even_numbers
陣列([ 2, 4, 6, 8, 10, 12, 14, 16, 18])
24.36使用 linspace 創建數字序列
# numpy.linspace()
# numpy.logspace() in Python with Example
# 例如,它可以用來創建從 1 到 5 的 10 個均勻間隔的值,
NP,linspace ( 1.0 , 5.0 , num = 10 )
陣列([1., 1.44444444, 1.88888889, 2.33333333, 2.77777778,
3.22222222, 3.66666667, 4.11111111, 4.55555556, 5.])
# 不包括區間
np 中的最后一個值,linspace ( 1.0 , 5.0 , num = 5 ,端點= False )
array([1. , 1.8, 2.6, 3.4, 4.2])
# LogSpace
# LogSpace 回傳對數刻度上的偶數間隔數,Logspace 具有與 np.linspace 相同的引數,
# 句法:
# numpy.logspace(開始,停止,數量,端點)
NP,日志空間( 2 , 4.0 , num = 4 )
陣列([ 100. , 464.15888336, 2154.43469003, 10000. ])
# 檢查陣列的大小
x = np . 陣列([ 1,2,3 ],D型細胞= NP,complex128)
X
陣列([1.+0.j, 2.+0.j, 3.+0.j])
×,專案大小
16
# 在 Python 中索引和切片 NumPy 陣列
np_list = np . 陣列([( 1 , 2 , 3 ), ( 4 , 5 , 6 )])
np_list
陣列([[1, 2, 3],
[4, 5, 6]])
列印('第一行:',np_list [ 0 ])
列印('第二行:',np_list [ 1 ])
第一行:[1 2 3]
第二行:[4 5 6]
列印('第一列:',np_list[ :,0 ])
列印('第二列:',np_list[ :,1 ])
列印('第三列:',np_list[ :,2 ])
第一列:[1 4]
第二列:[2 5]
第三列:[3 6]
24.37NumPy 統計函式與示例
NumPy 具有非常有用的統計函式,用于從陣列中的給定元素中查找最小值、最大值、平均值、中位數、百分位數、標準偏差和方差等,函式解釋如下 - 統計函式 Numpy 配備了如下所列的穩健統計函式
- Numpy 函式
- 最小 np.min()
- 最大 np.max()
- 平均 np.mean()
- 中位數 np.median()
- 差異
- 百分位
- 標準差 np.std()
np_normal_dis = np,隨機的,正常(5,0.5,100)
np_normal_dis
##最小值,最大值,平均值,中位數,SD
列印('分鐘:',two_dimension_array,分鐘())
的列印('最大:',two_dimension_array,最大())
的列印(“平均: ' two_dimension_array,意思是())
#列印('中位數”,two_dimension_array.median())
列印('SD:', two_dimension_array,標準())
min: 1
max: 55
mean: 14.777777777777779
sd: 18.913709183069525
最小值: 1
最大值: 55
平均值: 14.777777777777779 標準
差: 18.913709183069525
列印(two_dimension_array)
列印('列具有最小:',NP,阿明(two_dimension_array,軸= 0))
的列印('列具有最大:',NP,AMAX(two_dimension_array,軸= 0))
的列印(“===行==”)
列印('行用最小的:',NP,阿明(two_dimension_array,軸= 1))
的列印('行用最大:',NP,AMAX(two_dimension_array,軸= 1))
[[ 1 2 3]
[ 4 55 44]
[ 7 8 9]]
Column with minimum: [1 2 3]
Column with maximum: [ 7 55 44]
=== Row ==
Row with minimum: [1 4 7]
Row with maximum: [ 3 55 9]
24.38如何創建重復序列?
a = [ 1 , 2 , 3 ]
#整個重復的'A'兩次
列印('平鋪:',NP,瓷磚(一,2))
#重復的'A'兩次各元件
列印('重復:',NP,重復(一,2))
Tile: [1 2 3 1 2 3]
Repeat: [1 1 2 2 3 3]
24.39如何生成亂數?
# [0,1)
one_random_num = np之間的一個亂數,隨機的,隨機()
one_random_in = np,隨機
列印(one_random_num)
0.6149403282678213
0.4763968133790438
0.4763968133790438
# 形狀為 2,3 的 [0,1) 之間的亂數
r = np . 隨機的,隨機( size = [ 2 , 3 ])
列印( r )
[[0.13031737 0.4429537 0.1129527 ]
[0.76811539 0.88256594 0.6754075 ]]
列印( np . random . choice ([ 'a' , 'e' , 'i' , 'o' , 'u' ], size = 10 ))
['u' 'o' 'o' 'i' 'e' 'e' 'u' 'o' 'u' 'a']
[ 'i' 'u' 'e' 'o' 'a' 'i' 'e' 'u' 'o' 'i' ]
['iueoaieuoi']
## 形狀 2, 2 的 [0, 1] 之間的亂數
rand = np . 隨機的,蘭特( 2 , 2 )
蘭特
array([[0.97992598, 0.79642484],
[0.65263629, 0.55763145]])
rand2 = np,隨機的,randn ( 2 , 2 )
rand2
array([[ 1.65593322, -0.52326621],
[ 0.39071179, -2.03649407]])
# 形狀為 2,5 的 [0, 10) 之間的隨機整數
rand_int = np . 隨機的,randint ( 0 , 10 , size = [ 5 , 3 ])
rand_int
array([[0, 7, 5],
[4, 1, 4],
[3, 5, 3],
[4, 3, 8],
[4, 6, 7]])
從 scipy 匯入 統計
np_normal_dis = np,隨機的,正常(5,0.5,1000)#平均值,標準偏差,樣本數
np_normal_dis
##最小值,最大值,平均值,中位數,SD
列印('分鐘:',NP,分鐘(np_normal_dis))
列印('最大:',np . max ( np_normal_dis ))
print ( 'mean: ' , np .均值(np_normal_dis))
列印('中位數:',NP,中值(np_normal_dis))
列印('模式:',統計資訊,模式(np_normal_dis))
列印('SD:',NP,STD(np_normal_dis))
分鐘:3.557811005458804
最大:6.876317743643499
平均值:5.035832048106663
中位數:5.020161980441937
模式:模式結果(模式=陣列([3.55781101]),計數=陣列([1]))
標準差:0.489682424165213
PLT,hist ( np_normal_dis , color = "grey" , bins = 21 )
plt,顯示()
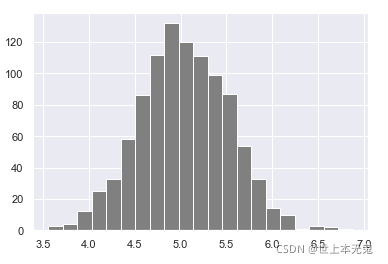
# numpy.dot(): Python 中使用 Numpy 的
Dot Product
# Dot Product # Numpy 是強大的矩陣計算庫,例如,您可以使用 np.dot 計算點積
# 句法
# numpy.dot(x, y, out=None)
24.40線性代數
點積
## 線性代數
### 點積:兩個陣列的乘積
f = np,陣列([ 1 , 2 , 3 ])
g = np,陣列([ 4 , 5 , 3 ])
### 1*4+2*5 + 3*6
np . 點( f , g ) # 23
24.41NumPy 矩陣乘法與 np.matmul()
### Matmul:兩個陣列的矩陣乘積
h = [[ 1 , 2 ],[ 3 , 4 ]]
i = [[ 5 , 6 ],[ 7 , 8 ]]
### 1*5+2*7 = 19
納米,matmul ( h , i )
陣列([[19, 22],
[43, 50]])
##行列式2*2矩陣
###5*8-7*6np.linalg.det(i)
NP,linalg,檢測( i )
-1.999999999999999
Z = np,零(( 8 , 8 ))
Z [ 1 :: 2 ,:: 2 ] = 1
Z [:: 2 , 1 :: 2 ] = 1
Z
array([[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.]])
new_list = [ x + 2 for x in range ( 0 , 11 )]
新串列
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
[ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 ]
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
np_arr = np,陣列(范圍( 0 , 11 ))
np_arr + 2
陣列([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
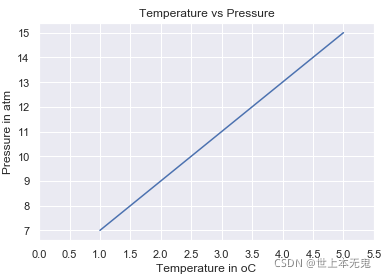
對于具有線性關系的量,我們使用線性方程,讓我們看看下面的例子:
溫度 = np,陣列([ 1 , 2 , 3 , 4 , 5 ])
pressure = temp * 2 + 5
pressure
陣列([ 7, 9, 11, 13, 15])
PLT,繪圖(溫度,壓力)
plt,xlabel('攝氏溫度')
plt,ylabel('atm 中的壓力')
plt,標題('溫度與壓力')
plt,xticks(NP,人氣指數(0,6,步驟= 0.5))
PLT,顯示()
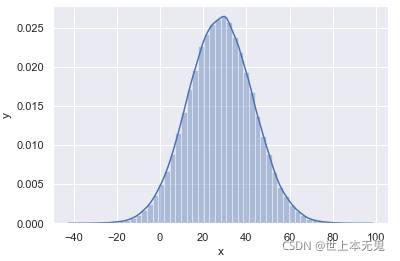
使用 numpy 繪制高斯正態分布,如下所示,numpy 可以生成亂數,要創建隨機樣本,我們需要均值(mu)、sigma(標準差)、資料點數,
mu = 28
西格瑪 = 15 個
樣本 = 100000
x = np,隨機的,正常(mu , sigma ,樣本)
ax = sns,分布圖( x );
斧頭,設定( xlabel = "x" , ylabel = 'y' )
plt,顯示()
總而言之,與 python 串列的主要區別是:
- 陣列支持向量化操作,而串列不支持,
- 一旦創建了陣列,就不能更改其大小,您將不得不創建一個新陣列或覆寫現有陣列,
- 每個陣列都有一個且只有一個 dtype,其中的所有專案都應該是那個 dtype,
- 等效的 numpy 陣列比 Python 串列占用的空間少得多,
- numpy 陣列支持布爾索引,
第 25 天 - Pandas
Pandas 是一種開源、高性能、易于使用的 Python 編程語言的資料結構和資料分析工具,Pandas 添加了資料結構和工具,旨在處理類似表格的資料,即Series和Data Frames,Pandas 提供了用于資料操作的工具:
- 重塑
- 合并
- 排序
- 切片
- 聚合
- 插補,如果您使用的是 anaconda,則無需安裝 pandas,
25.1安裝pandas
對于 Mac:
pip 安裝 conda
conda 安裝 pandas
對于 Windows:
pip 安裝 conda
pip 安裝 熊貓
Pandas 資料結構基于Series和DataFrames,
一個系列是一列和一個資料幀是一個多維表的集合組成系列,為了創建一個pandas系列,我們應該使用numpy來創建一個一維陣列或一個python串列,讓我們看一個系列的例子:
命名pandas系列
國家系列
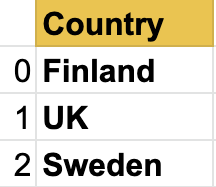
城市系列
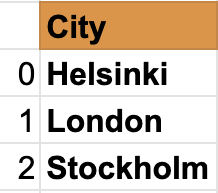
如您所見,pandas 系列只是一列資料,如果我們想要多列,我們使用資料框,下面的示例顯示了 Pandas DataFrames,
讓我們看看一個 Pandas 資料框的例子:
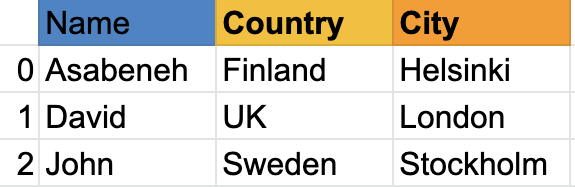
資料框是行和列的集合,看下表;它比上面的例子有更多的列:
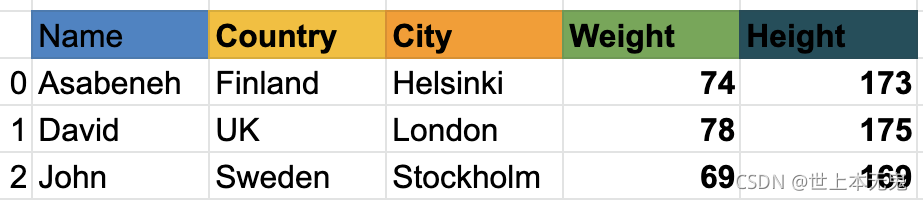
接下來,我們將看到如何匯入pandas以及如何使用pandas創建Series和DataFrames
匯入pandas
import pandas as pd # 將pandas 匯入為pd
import numpy as np # 將numpy 匯入為np
25.2使用默認索引創建 Pandas 系列
nums = [ 1 , 2 , 3 , 4 , 5 ]
s = pd,系列( nums )
列印( s )
0 1
1 2
2 3
3 4
4 5
資料型別:int64
25.3使用自定義索引創建 Pandas 系列
nums = [ 1 , 2 , 3 , 4 , 5 ]
s = pd,系列( nums , index = [ 1 , 2 , 3 , 4 , 5 ])
列印( s )
1 1
2 2
3 3
4 4
5 5
資料型別:int64
水果 = [ 'Orange' , 'Banana' , 'Mango' ]
水果 = pd . 系列(水果,指數= [ 1,2,3 ])
列印(水果)
1 橙色
2 香蕉
3 芒果
資料型別:物件
25.4從字典創建 Pandas 系列
dct = { 'name' : 'Asabeneh' , 'country' : '芬蘭' , 'city' : '赫爾辛基' }
s = pd,系列( dct )
列印( s )
姓名 Asabeneh
國家芬蘭
赫爾辛基市
資料型別:物件
25.5創建一個常量 Pandas 系列
s = pd,系列( 10 , index = [ 1 , 2 , 3 ])
列印( s )
1 10
2 10
3 10
資料型別:int64
25.6使用 Linspace 創建 Pandas 系列
s = pd,系列( np . linspace ( 5 , 20 , 10 )) # linspace(starting, end, items)
列印( s )
0 5.000000
1 6.666667
2 8.333333
3 10.000000
4 11.666667
5 13.333333
6 15.000000
7 16.666667
8 18.333333
9 20.000000
資料型別:float64
25.7資料幀
Pandas 資料框可以用不同的方式創建,
從串列串列創建資料幀
資料 = [
[ “阿薩本尼”、“芬蘭”、“赫爾辛克” ]、
[ '大衛','英國','倫敦' ],
[ “約翰”、“瑞典”、“斯德哥爾摩” ]
]
df = pd,DataFrame ( data , columns = [ 'Names' , 'Country' , 'City' ])
列印( df )
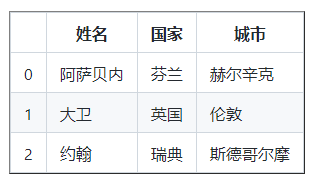
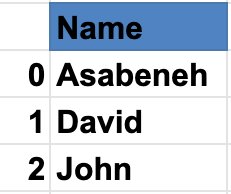
25.8使用字典創建 DataFrame
data = { 'Name' : [ 'Asabeneh' , 'David' , 'John' ], '國家' :[
'芬蘭' , '英國' , '瑞典' ], '城市' : [ '赫爾斯基' , '倫敦' , '斯德哥爾摩' ]}
df = pd . DataFrame(資料)
列印(df)
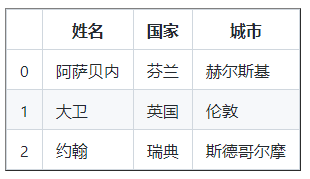
25.9從字典串列創建資料幀
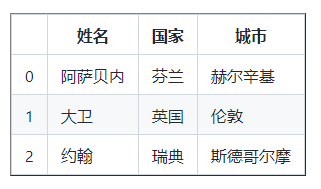
資料 = [
{ '姓名' : 'Asabeneh' , '國家' : '芬蘭' , '城市' : '赫爾辛基' },
{ '姓名':'大衛','國家':'英國','城市':'倫敦' },
{ '姓名':'約翰','國家':'瑞典','城市':'斯德哥爾摩' }]
df = pd . DataFrame(資料)
列印(df)
25.10使用 Pandas 讀取 CSV 檔案
要下載 CSV 檔案,本例中需要什么,控制臺/命令列就足夠了:
curl -O https://raw.githubusercontent.com/Asabeneh/30-Days-Of-Python/master/data/weight-height.csv
將下載的檔案放在您的作業目錄中,
將 Pandas 匯入為 pd
df = pd,read_csv ( 'weight-height.csv' )
列印( df )
25.11資料探索
讓我們使用 head() 僅讀取前 5 行
print ( df . head ()) # 給五行我們可以通過將引數傳遞給 head() 方法來增加行數
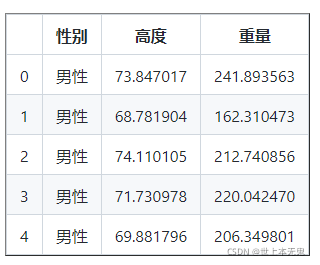
讓我們還使用 tail() 方法探索資料幀的最后記錄,
列印(DF,尾()) #尾巴給最后的五排,我們可以通過傳遞引數尾法提高行
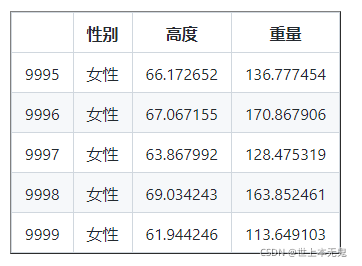
如您所見,csv 檔案有三行:性別、身高和體重,如果 DataFrame 有很長的行,就很難知道所有的列,因此,我們應該使用一種方法來知道列,我們不知道行數,讓我們使用形狀肉類,
print ( df . shape ) # 如你所見 10000 行和三列
(10000, 3)
讓我們使用列獲取所有列,
列印(df,列)
Index(['Gender', 'Height', 'Weight'], dtype='object')
現在,讓我們使用列鍵獲取特定列
heights = df [ 'Height' ] # 這是一個系列
列印(高度)
0 73.847017
1 68.781904
2 74.110105
3 71.730978
4 69.881796
...
9995 66.172652
9996 67.067155
9997 63.867992
9998 69.034243
9999 61.944246
名稱:高度,長度:10000,資料型別:float64
weights = df [ 'Weight' ] # 這是一個系列
列印(重量)
0 241.893563
1 162.310473
2 212.740856
3 220.042470
4 206.349801
...
9995 136.777454
9996 170.867906
9997 128.475319
9998 163.852461
9999 113.649103
名稱:重量,長度:10000,dtype:float64
列印(len(高度)== len(權重))
True
describe() 方法提供資料集的描述性統計值,
print ( heights . describe ()) # 給出高度資料的統計資訊
數 10000.000000
平均 66.367560
標準 3.847528
分鐘 54.263133
25% 63.505620
50% 66.318070
75% 69.174262
最大 78.998742
名稱:高度,資料型別:float64
列印(權重,描述())
數 10000.000000
平均 161.440357
標準 32.108439
最低 64.700127
25% 135.818051
50% 161.212928
75% 187.169525
最大 269.989699
名稱:重量,資料型別:float64
print ( df . describe ()) # describe 還可以給出來自資料幀的統計資訊
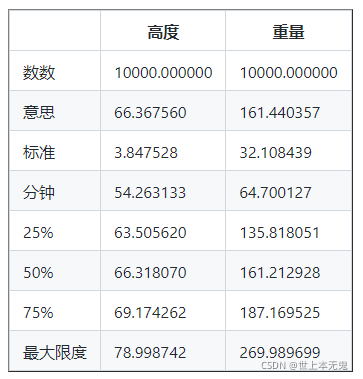
與 describe() 類似,info() 方法也提供有關資料集的資訊,
25.12修改資料幀
修改DataFrame: * 我們可以創建一個新的DataFrame * 我們可以創建一個新列并將其添加到DataFrame, * 我們可以從DataFrame 中洗掉現有列, * 我們可以修改DataFrame 中的現有列, * 我們可以更改 DataFrame 中列值的資料型別
25.13創建資料幀
與往常一樣,首先我們匯入必要的包,現在,讓我們匯入 pandas 和 numpy,這兩個最好的朋友,
將Pandas 匯入為 pd
將 numpy 匯入為 np
資料 = [
{ “姓名”:“阿薩本尼”,“國家”:“芬蘭”,“城市”:“赫爾辛基” },
{ “姓名”:“大衛”,“國家”:“英國”,“城市”:“倫敦” },
{ “姓名”:“約翰”,“國家”:“瑞典”,“城市”:“斯德哥爾摩” }]
df = pd . DataFrame(資料)
列印(df)
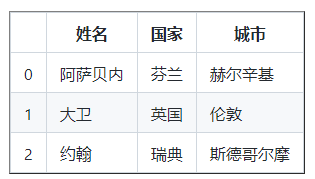
向 DataFrame 添加列就像向字典添加鍵,
首先讓我們使用前面的示例來創建一個 DataFrame,創建 DataFrame 后,我們將開始修改列和列值,
25.14添加新列
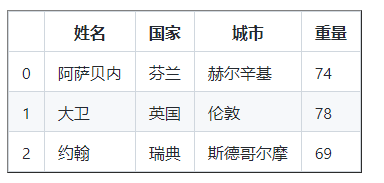
讓我們在 DataFrame 中添加一個權重列
權重 = [ 74 , 78 , 69 ]
df [ 'Weight' ] = 權重
df
讓我們在 DataFrame 中添加一個高度列
高度 = [ 173 , 175 , 169 ]
df [ '高度' ] = 高度
列印( df )
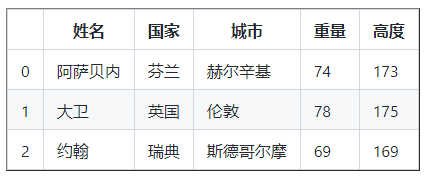
正如您在上面的 DataFrame 中看到的,我們確實添加了新的列,重量和高度,讓我們通過使用他們的體重和身高計算他們的 BMI 來添加一個額外的列,稱為 BMI(身體質量指數),BMI 是質量除以身高的平方(以米為單位)- 體重/身高 * 身高,
如您所見,高度以厘米為單位,因此我們應該將其更改為米,讓我們修改高度行,
25.15修改列值
df [ '高度' ] = df [ '高度' ] * 0.01
df
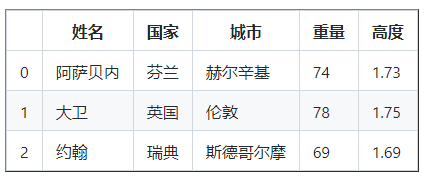
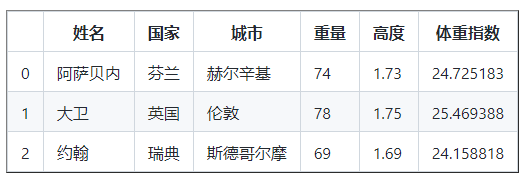
# 使用函式使我們的代碼更簡潔,但是你可以不用一個來計算 bmi
def calculate_bmi ():
weights = df [ 'Weight' ]
heights = df [ 'Height' ]
bmi = []
for w , h in zip ( weights ,高度):
b = w / ( h * h )
bmi,追加( b )
回傳 體重指數
bmi = calculate_bmi ()
df [ 'BMI' ] = bmi
df
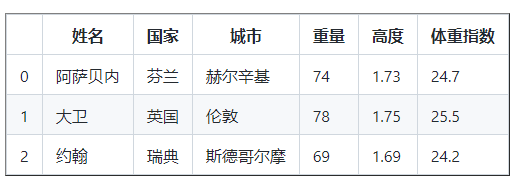
25.16格式化 DataFrame 列
DataFrame 的 BMI 列值是浮點數,小數點后有許多有效數字,讓我們將其更改為一位有效數字,
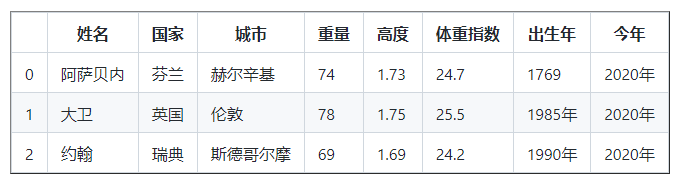
df [ 'BMI' ] = round ( df [ 'BMI' ], 1 )
列印( df )
DataFrame 中的資訊似憾訓沒有完成,讓我們添加出生年份和當前年份列,
birth_year = [ '1769' , '1985' , '1990' ]
current_year = pd,系列( 2020 , index = [ 0 , 1 , 2 ])
df [ 'Birth Year' ] = birth_year
df [ 'Current Year' ] = current_year
df
25.17檢查列值的資料型別
列印(DF,重量,D型)
資料型別(' int64 ')
df [ '出生年份' ],dtype # 它給出字串物件,我們應該將其更改為數字
df [ '出生年份' ] = df [ '出生年份' ],astype ( 'int' )
print ( df [ 'Birth Year' ]. dtype ) # 現在檢查資料型別
資料型別(' int32 ')
現在與當年相同:
df [ '當年' ] = df [ '當年' ],astype ( 'int' )
df [ '本年' ],資料型別
資料型別(' int32 ')
現在,出生年份和當前年份的列值為整數,我們可以計算年齡,
年齡 = df [ '本年' ] - df [ '出生年份' ]
年齡
0 251
1 35
2 30
dtype: int32
df [ '年齡' ] = 年齡
列印(df)
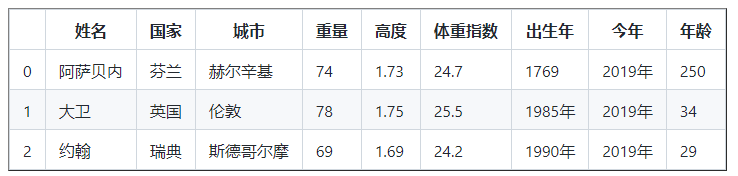
第一排的人迄今活了251歲,一個人不可能活這么久,要么是打字錯誤,要么是資料被煮熟了,因此,讓我們用列的平均值填充該資料,而不包括例外值,
平均值 = (35 + 30)/ 2
mean = ( 35 + 30 ) / 2
print ( 'Mean: ' , mean ) #在輸出中添加一些描述很好,所以我們知道什么是什么
平均值:32.5
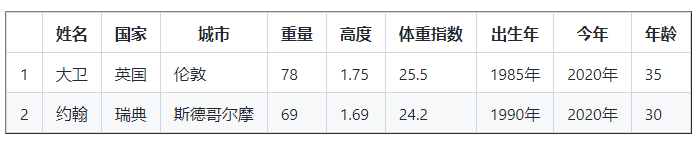
25.18布爾索引
列印( df [ df [ '年齡' ] > 120 ])

列印( df [ df [ '年齡' ] < 120 ])
初學者挑戰學習Python編程30天還有最后一節續集就要結束了,感興趣了解下面的學習內容,記得關注我,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305461.html
標籤:python
上一篇:僅需10道題輕松掌握Python字串方法 | Python技能樹征題
下一篇:numpy學習總結