高效學習NumPy基礎
- 創建陣列
- numpy.array(object, dtype,copy, order, subox, ndmin)
- numpy.arange(start, stop, step, dtype)
- numpy.linspace(start, stop, num)
- numpy.logspase(start,stop,num)
- numpy.zeros(shape,dtype,order)
- numpy.eye(N,M, K,dtype,order)
- numpy.diag(V,K)
- numpy.ones(shape,dtype, order)
- 陣列物件的屬性
- 陣列資料型別
- 基本資料型別
- 型別轉換
- 創建資料型別
- 查看資料型別
- 自定義陣列資料
- 生成亂數
- random模塊的常用亂數生成函式
- 通過索引訪問陣列
- 一維陣列的索引
- 多維陣列的索引
- 使用整數函式和布林值索引訪問多維陣列
- 變換陣列的形態
- reshape()改變陣列形狀
- ravel()展平陣列
- flatten()展平陣列
- hstack()橫向合并陣列
- vstack()縱向合并陣列
- concatenate()合并陣列
- hsplit()橫向分割陣列
- vsplit()縱向分割陣列
- split()分割陣列
- 創建NumPy矩陣
- 矩陣創建
- 矩陣運算
- 矩陣屬性
- ufunc函式
- 常用的函式
- 常用的ufunc函式運算
- 廣播機制
- 檔案操作
- 資料存盤
- 檔案讀取
- txt格式保存與讀取
- genfromtxt函式讀取資料
- 排序
- sort函式 無回傳值 直接對原始資料修改
- argsort函式
- lexsort函式
- 去重與生成重復資料
- 常用的統計函式
NumPy提供了兩種基本物件:ndarray和ufunc,ndarray稱為陣列,而ufunc則是對陣列進行處理的函式,
創建陣列
numpy.array(object, dtype,copy, order, subox, ndmin)
用于創建NumPy陣列
import numpy as np
"""
array(object, dtype=None, copy=True, order='K', subox=False, ndmin=0)
引數說明:
object : 陣列,公開陣列介面的任何物件,__array__方法回傳陣列的物件,或任何(嵌套)序列,
dtype : 資料型別,陣列所需的資料型別,如果沒有給出,那么型別將被確定為保持序列中的物件所需的最小型別,此引數只能用于“upcast”陣列,對于向下轉換,請使用.astype(t)方法,
copy : 如果為True(默認值),則復制物件,否則,只有當__array__回傳副本,obj是嵌套序列,或者需要副本來滿足任何其他要求(dtype,順序等)時,才會進行復制,
order : 英文字母,引數可寫{'K','A','C','F'},指定陣列的記憶體布局,如果object不是陣列,則新創建的陣列將按C順序排列(行主要),除非指定了'F',在這種情況下,它將采用Fortran順序(專業列),如果object是一個陣列,則以下成立,當copy=False出于其他原因而復制時,結果copy=True與對A的一些例外情況相同,請參閱“注釋”部分,默認順序為“K”,
subok : boolean值,如果為True,則子類將被傳遞,否則回傳的陣列將被強制為基類陣列(默認),
ndmin : int值,指定結果陣列應具有的最小維數,根據需要,將根據需要預先設定形狀,
滿足要求的陣列物件
"""
# 創建一個陣列 主要引數 object、dtype、ndmin,
a1 = np.array([1,2,3])
a2 = np.array([1,2,3], dtype=float)
a3 = np.array([1,2,3], ndmin=2)
print(a1)
print(a2)
print(a3)
運行結果:
[1 2 3]
[1. 2. 3.]
[[1 2 3]]
numpy.arange(start, stop, step, dtype)
在給定間隔內回傳均勻間隔的值,左閉右開區間 [起始值,終止值)
import numpy as np
# 用array(range(10)) 生成0-9的的int型別陣列
a1 = np.array(range(10))
"""
numpy.arange(start, stop, step, dtype=None)
參數說明:
start 起始值
stop 終止值 生成的范圍到終止值-1 例如(0,10) 生成0~9
step 步長
dtype 資料型別
"""
# a1和a2的效果一樣
a2 = np.arange(10)
a3 = np.arange(0, 10)
a4 = np.arange(0, 10, 2)
a5 = np.arange(0, 10, 2, float)
print(a1)
print(a2)
print(a3)
print(a4)
print(a5)
運行結果:
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 2 4 6 8]
[0. 2. 4. 6. 8.]
numpy.linspace(start, stop, num)
用于回傳間隔類均勻分布的數值序列,閉區間 [起始值,終止值]
import numpy as np
"""
numpy.linspace(start, stop, num)
引數說明:
start 起始值
stop 終止值
num 數量 默認值為50
"""
a1 = np.linspace(0,10)
a2 = np.linspace(0,10, 5)
print(a1)
print(a2)
運行結果:
[ 0. 0.20408163 0.40816327 0.6122449 0.81632653 1.02040816
1.2244898 1.42857143 1.63265306 1.83673469 2.04081633 2.24489796
2.44897959 2.65306122 2.85714286 3.06122449 3.26530612 3.46938776
3.67346939 3.87755102 4.08163265 4.28571429 4.48979592 4.69387755
4.89795918 5.10204082 5.30612245 5.51020408 5.71428571 5.91836735
6.12244898 6.32653061 6.53061224 6.73469388 6.93877551 7.14285714
7.34693878 7.55102041 7.75510204 7.95918367 8.16326531 8.36734694
8.57142857 8.7755102 8.97959184 9.18367347 9.3877551 9.59183673
9.79591837 10. ]
[ 0. 2.5 5. 7.5 10. ]
numpy.logspase(start,stop,num)
用于回傳間隔類均勻分布的等比數列,閉區間 [起始值,終止值]
"""
numpy.logspace(start, stop, num)
引數說明:
start 起始值
stop 終止值
num 數量 默認值為50
"""
a1 = np.logspace(0,2)
a2 = np.logspace(0,2, 5)
print(a1)
print(a2)
運行結果:
[ 1. 1.09854114 1.20679264 1.32571137 1.45634848
1.59985872 1.75751062 1.93069773 2.12095089 2.32995181
2.55954792 2.8117687 3.0888436 3.39322177 3.72759372
4.09491506 4.49843267 4.94171336 5.42867544 5.96362332
6.55128557 7.19685673 7.90604321 8.68511374 9.54095476
10.48113134 11.51395399 12.64855217 13.89495494 15.26417967
16.76832937 18.42069969 20.23589648 22.22996483 24.42053095
26.82695795 29.47051703 32.37457543 35.56480306 39.06939937
42.9193426 47.14866363 51.79474679 56.89866029 62.50551925
68.6648845 75.43120063 82.86427729 91.0298178 100. ]
[ 1. 3.16227766 10. 31.6227766 100. ]
numpy.zeros(shape,dtype,order)
用于創建值全部為0的陣列,即創建的陣列元素全部為0
"""
numpy.zeros(shape, dtype, order)
引數說明:
shape 陣列的維度
dtype 資料型別
order 指定陣列的記憶體布局
"""
a1 = np.zeros((5,5), dtype=int)
a2 = np.zeros((5,5), dtype=float)
print(a1)
print(a2)
運行結果:
[[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]]
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
numpy.eye(N,M, K,dtype,order)
用于生成主對角線為1,其余元素為0的陣列
"""
numpy.eye(N,M, K,dtype,order)
引數說明:
N 陣列的行數
M 陣列的列數 不寫默認為N
K 對角線的索引:0(默認值)指的是主對角線,正值指的是上對角線,負值指的是下對角線,
dtype 資料型別
order 指定陣列的記憶體布局
"""
a1 = np.eye(5, dtype=int)
a2 = np.eye(2, 3, dtype=int)
a3 = np.eye(5, 5, 0, dtype=int)
a4 = np.eye(5, 5, 1, dtype=int)
a5 = np.eye(5, 5, -1, dtype=int)
print(a1)
print(a2)
print(a3)
print(a4)
print(a5)
運行結果:
[[1 0 0 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]]
[[1 0 0]
[0 1 0]]
[[1 0 0 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]]
[[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]
[0 0 0 0 0]]
[[0 0 0 0 0]
[1 0 0 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]]
numpy.diag(V,K)
除了對角線以外的其他元素為0, 對角線上的元素可以是0或其他值
"""
numpy.diag(V, K)
引數說明:
V 如果是2D陣列,回傳k位置的對角線,
如果是1D陣列,回傳一個v作為k位置對角線的2維陣列,
K 對角線的位置,大于零位于對角線上面,小于零則在下面,
"""
a1 = np.diag([1,2,3,4])
a2 = np.diag([1,2,3,4,5], 0)
a3 = np.diag([1,2,3,4,5], 1)
a4 = np.diag([1,2,3,4,5], -1)
print(a1)
print(a2)
print(a3)
print(a4)
運行結果:
[[1 0 0 0]
[0 2 0 0]
[0 0 3 0]
[0 0 0 4]]
[[1 0 0 0 0]
[0 2 0 0 0]
[0 0 3 0 0]
[0 0 0 4 0]
[0 0 0 0 5]]
[[0 1 0 0 0 0]
[0 0 2 0 0 0]
[0 0 0 3 0 0]
[0 0 0 0 4 0]
[0 0 0 0 0 5]
[0 0 0 0 0 0]]
[[0 0 0 0 0 0]
[1 0 0 0 0 0]
[0 2 0 0 0 0]
[0 0 3 0 0 0]
[0 0 0 4 0 0]
[0 0 0 0 5 0]]
numpy.ones(shape,dtype, order)
用于創建元素全部為1的陣列
"""
numpy.ones(shape, dtype, order)
引數說明:
shape 陣列的維度
dtype 資料型別
order 指定陣列的記憶體布局
"""
a1 = np.ones((3,4), dtype=int)
a2 = np.ones((4,4), dtype=float)
print(a1)
print(a2)
運行結果:
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
陣列物件的屬性
| 屬性 | 說明 |
|---|---|
| ndarray.ndim | 秩,即軸的數量或維度的數量 |
| ndarray.shape | 陣列的維度,對于矩陣,n 行 m 列 |
| ndarray.size | 陣列元素的總個數,相當于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 物件的元素型別 |
| ndarray.itemsize | ndarray 物件中每個元素的大小,以位元組為單位 |
| ndarray.flags | ndarray 物件的記憶體資訊 |
| ndarray.real | ndarray元素的實部 |
| ndarray.imag | ndarray 元素的虛部 |
| ndarray.data | 包含實際陣列元素的緩沖區,由于一般通過陣列的索引獲取元素,所以通常不需要使用這個屬性, |
import numpy as np
"""
陣列物件的屬性
ndarray.ndim 秩,即軸的數量或維度的數量
ndarray.shape 陣列的維度,對于矩陣,n 行 m 列
ndarray.size 陣列元素的總個數,相當于 .shape 中 n*m 的值
ndarray.dtype ndarray 物件的元素型別
ndarray.itemsize ndarray 物件中每個元素的大小,以位元組為單位
ndarray.flags ndarray 物件的記憶體資訊
ndarray.real ndarray元素的實部
ndarray.imag ndarray 元素的虛部
ndarray.data 包含實際陣列元素的緩沖區,由于一般通過陣列的索引獲取元素,所以通常不需要使用這個屬性,
"""
a1 = np.array([[1,2,3], [4,5,6], [7,8,9]])
print("ndim:", a1.ndim)
print("shape:", a1.shape)
print("size:", a1.size)
print("dtype:", a1.dtype)
print("itemsize:", a1.itemsize)
"""
C_CONTIGUOUS (C) 資料是在一個單一的C風格的連續段中
F_CONTIGUOUS (F) 資料是在一個單一的Fortran風格的連續段中
OWNDATA (O) 陣列擁有它所使用的記憶體或從另一個物件中借用它
WRITEABLE (W) 資料區域可以被寫入,將該值設定為 False,則資料為只讀
ALIGNED (A) 資料和所有元素都適當地對齊到硬體上
UPDATEIFCOPY (U) 這個陣列是其它陣列的一個副本,當這個陣列被釋放時,原陣列的內容將被更新
"""
print("flags:", a1.flags)
print("real:", a1.real)
print("imag:", a1.imag)
print("data:", a1.data)
運行結果:
ndim: 2
shape: (3, 3)
size: 9
dtype: int32
itemsize: 4
flags: C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
real: [[1 2 3]
[4 5 6]
[7 8 9]]
imag: [[0 0 0]
[0 0 0]
[0 0 0]]
data: <memory at 0x000001D1BDE91860>
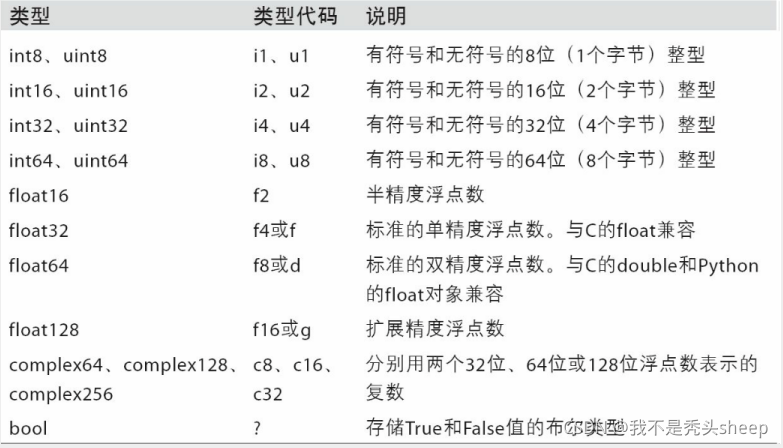
陣列資料型別
基本資料型別
轉載至https://www.cnblogs.com/mengxiaoleng/p/11616270.html

型別轉換
語法:numpy.資料型別(object)
# 整型轉換為浮點型
print("整型轉換為浮點型:", np.float64(66))
# 浮點型轉換為整型
print("浮點型轉換為整型:", np.int8(66.66))
# 整型轉換為布爾型 0為False 其他數為True
print("整型轉換為布爾型:", np.bool(0))
# 布爾型轉浮點型 True為1.0 False為0.0
print("布爾型轉浮點型:", np.float64(True))
"""
運行結果:
整型轉換為浮點型: 66.0
浮點型轉換為整型: 66
整型轉換為布爾型: False
布爾型轉浮點型: 1.0
"""
創建資料型別
語法:numpy.dtype([(name, dtype, [size]),(name, dtype)…])
"""
創建一個資料型別,存盤圖書資訊
需求:
1.能存盤50個字符的字串 記錄書名
2.用一個64位的整數 記錄庫存
3.用一個64位的單精度浮點數 記錄價格
"""
book_type = np.dtype([("name", np.str_, 50), ("count", np.int64), ("price", np.float64)])
print("資料型別為:", book_type)
運行結果:
資料型別為: [('name', '<U50'), ('count', '<i8'), ('price', '<f8')]
查看資料型別
語法:直接當作字典訪問或numpy.dtype()
# 直接訪問
print("圖書名字的資料型別:", book_type["name"])
# numpy.dtype()
print("圖書數量的資料型別:", np.dtype(book_type["count"]))
運行結果:
圖書名字的資料型別: <U50
圖書數量的資料型別: int64
自定義陣列資料
在使用array函式創建陣列時,自定義陣列資料,可以預先自定資料型別,而默認是浮點型,
items = np.array([("華為應用開發中級", 88, 79.00), ("Python語言程式設計", 50, 49.80)], dtype=book_type)
print("自定義資料為:", items)
運行結果:
自定義資料為: [('華為應用開發中級', 88, 79. ) ('Python語言程式設計', 50, 49.8)]
生成亂數
# rand函式生成的均勻分布的亂數 引數:size
a1 = np.random.rand(1, 2)
a2 = np.random.rand(1, 2, 3, 4)
print("rand函式生成的均勻分布的亂數:")
print(a1)
print(a2)
print("-"*50)
# randn函式生成具有標準正態分布的亂數 引數:size
a3 = np.random.randn(1, 2)
a4 = np.random.randn(1, 2, 3, 4)
print("randn函式生成具有標準正態分布的亂數:")
print(a3)
print(a4)
print("-"*50)
# randint函式生成[low, high)區間的隨機整數 引數:low, high, size, dtype
a5 = np.random.randint(1, 10, [1, 2], dtype="short")
a6 = np.random.randint(1, 10, [1, 2, 3], dtype="long")
print("randint函式生成[low, high)區間的隨機整數:")
print(a5, a5.dtype)
print(a6, a6.dtype)
print("-"*50)
# random_sample函式生成隨機浮點數,在半開區間 [0.0, 1.0) 引數: size
a7 = np.random.random_sample([1, 2])
a8 = np.random.random_sample([1, 2, 3])
print("random_sample函式生成隨機浮點數:")
print(a7)
print(a8)
運行結果:
rand函式生成的均勻分布的亂數:
[[0.37825834 0.36723038]]
[[[[0.71418784 0.73996675 0.15419813 0.99419331]
[0.58614779 0.73066644 0.49114029 0.80010252]
[0.33072697 0.48593358 0.73750939 0.6098291 ]]
[[0.18201681 0.34509901 0.07229337 0.89061953]
[0.41669819 0.59503481 0.73802839 0.40802414]
[0.185528 0.73147802 0.46253263 0.25485796]]]]
--------------------------------------------------
randn函式生成具有標準正態分布的亂數:
[[1.01330053 0.59629841]]
[[[[-1.23013022 -0.54980997 -0.86341347 -0.14536862]
[-0.54584678 -0.22382106 -1.71041033 0.91828566]
[-0.2115877 -0.53002694 0.04532693 -0.7821888 ]]
[[-0.39234029 -0.82818071 -0.06566115 0.63458322]
[ 0.51276787 -2.08087158 0.47010658 1.85817864]
[ 1.09909745 0.24666559 -0.72258201 -0.64547011]]]]
--------------------------------------------------
randint函式生成[low, high)區間的隨機整數:
[[5 6]] int16
[[[5 2 1]
[9 1 9]]] int32
--------------------------------------------------
random_sample函式生成隨機浮點數:
[[0.97716236 0.89218794]]
[[[0.53794987 0.11502953 0.32427659]
[0.51851268 0.631096 0.49160983]]]
random模塊的常用亂數生成函式
| 函式 | 說明 |
|---|---|
| seed | 確定亂數生成種子 |
| permutation | 回傳一個序列的隨機排列或回傳一個隨機排列的范圍 |
| shuffle | 對一個序列進行隨機排序 |
| binomial | 生成二項分布的亂數 |
| normal | 生成正態(高斯)分布的亂數 |
| beta | 生成beta分布的亂數 |
| chisquare | 生成卡方分布的亂數 |
| gamma | 生成gamma分布的亂數 |
| uniform | 生成在[0,1]中均勻分布的亂數 |
通過索引訪問陣列
一維陣列的索引
# 定義陣列
a = np.arange(10)
# 獲取某個元素
print("獲取某個元素:", a[3])
# 切片(跟串列切片是一樣的)
print("取前五個元素:", a[:6], a[:-4], a[0: 6])
# 設定步長 取 1 3 5 7
print("設定步長:", a[1: 8: 2])
# 反向設定步長 取7 5 3 1
print("反向設定步長", a[7: 0: -2])
運行結果:
獲取某個元素: 3
取前五個元素: [0 1 2 3 4 5] [0 1 2 3 4 5] [0 1 2 3 4 5]
設定步長: [1 3 5 7]
反向設定步長 [7 5 3 1]
多維陣列的索引
# 定義多維陣列
a = np.array([[1,2,3,4,5], [4,5,6,7,8], [7,8,9,10,11]])
# 取第1行第2 3個 注意下標都是從0開始的 即第2行的第3 4個
print("取第1行第2 3個:", a[1, 2: 4])
# 取第0和1行 第1~4列的元素 即取第一第二行的第二個元素到最后一個元素
print("取第0和1行 第2~5列的元素:", a[:2, 1:])
# 取所有行的第3列
print("取所有行的第3列", a[:, 2])
運行結果:
取第1行第2 3個: [6 7]
取第0和1行 第2~5列的元素: [[2 3 4 5]
[5 6 7 8]]
取所有行的第3列 [3 6 9]
使用整數函式和布林值索引訪問多維陣列
# 定義多維陣列
a = np.array([[1,2,3,4,5], [4,5,6,7,8], [7,8,9,10,11]])
# 從兩個序列的對應位置去除兩個整數來組成下標 [0,1] [2,2] [2,3]
print("索引結果為:", a[(0,2,2), (1,2,3)])
# 取第一第二行的0,1,2列元素
print("取第一第二行的0,1,2列元素:", a[1:, (0, 1 ,2)])
# 生成一個布爾陣列
bools = np.array([0, 1, 1], dtype=np.bool)
# 取第一第二行的4列元素
print("取第一第二行的4列元素:", a[bools, 3])
運行結果:
索引結果為: [ 2 9 10]
取第一第二行的0,1,2列元素: [[4 5 6]
[7 8 9]]
取第一第二行的3,4列元素: [ 7 10]
變換陣列的形態
reshape()改變陣列形狀
# 創建一個陣列
a1 = np.arange(12)
print("原資料:", a1, a1.shape)
# 改變陣列的形狀 (不改變原物件, 生成新的物件需要接識訓傳值)
a2 = a1.reshape(3, 4)
print("改變陣列的形狀:", a2, a2.shape)
運行結果:
原資料: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
改變陣列的形狀: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
ravel()展平陣列
# 創建一個陣列
a1 = np.arange(12)
print("原資料:", a1, a1.shape)
# 改變陣列的形狀 (不改變原物件, 生成新的物件需要接識訓傳值)
a2 = a1.reshape(3, 4)
print("改變陣列的形狀:", a2, a2.shape)
# ravel函式展平陣列 (改變原物件, 不需要接識訓傳值)
a1.ravel()
print("ravel函式展平陣列后:", a1, a1.shape)
運行結果:
原資料: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
改變陣列的形狀: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
ravel函式展平陣列: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
flatten()展平陣列
# 創建一個shape為(3, 4)的陣列
a1 = np.arange(12).reshape(3, 4)
print("原資料:", a, a.shape)
# flatten函式展平陣列
a2 = a1.flatten() # 橫向展平
print("橫向展平:", a2, a2.shape)
a3 = a1.flatten('F') # 縱向展平
print("縱向展平:", a3, a3.shape)
運行結果:
原資料: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
橫向展平: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
縱向展平: [ 0 4 8 1 5 9 2 6 10 3 7 11] (12,)
hstack()橫向合并陣列
# 創建兩個陣列
a1 = np.arange(12).reshape(3, 4)
a2 = a1 * 2
print("陣列1:", a1, a1.shape)
print("陣列2:", a2, a2.shape)
# hstack橫向合并
print("hstack橫向合并:", np.hstack((a1, a2)))
運行結果:
陣列1: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
陣列2: [[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]] (3, 4)
hstack橫向合并: [[ 0 1 2 3 0 2 4 6]
[ 4 5 6 7 8 10 12 14]
[ 8 9 10 11 16 18 20 22]]
vstack()縱向合并陣列
# 創建兩個陣列
a1 = np.arange(12).reshape(3, 4)
a2 = a1 * 2
print("陣列1:", a1, a1.shape)
print("陣列2:", a2, a2.shape)
# vstack縱向合并
print("vstack縱向合并:", np.vstack((a1, a2)))
運行結果:
陣列1: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
陣列2: [[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]] (3, 4)
vstack縱向合并: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]]
concatenate()合并陣列
# 創建兩個陣列
a1 = np.arange(12).reshape(3, 4)
a2 = a1 * 2
print("陣列1:", a1, a1.shape)
print("陣列2:", a2, a2.shape)
# concatenate橫向合并 (axis默認為0)
print("concatenate縱向合并:", np.concatenate((a1, a2), axis=0))
# concatenate橫向合并
print("concatenate橫向合并:", np.concatenate((a1, a2), axis=1))
運行結果:
陣列1: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
陣列2: [[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]] (3, 4)
concatenate縱向合并: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]]
concatenate橫向合并: [[ 0 1 2 3 0 2 4 6]
[ 4 5 6 7 8 10 12 14]
[ 8 9 10 11 16 18 20 22]]
hsplit()橫向分割陣列
# 創建一個陣列
a = np.arange(16).reshape(4, 4)
print("原陣列:", a, a.shape)
# 橫向分割
print("橫向分割:", np.hsplit(a, 2))
運行結果:
原陣列: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]] (4, 4)
橫向分割: [array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]]), array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])]
vsplit()縱向分割陣列
# 創建一個陣列
a = np.arange(16).reshape(4, 4)
print("原陣列:", a, a.shape)
# 縱向分割
print("縱向分割:", np.vsplit(a, 2))
運行結果:
原陣列: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]] (4, 4)
縱向分割: [array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
split()分割陣列
# 創建一個陣列
a = np.arange(16).reshape(4, 4)
print("原陣列:", a, a.shape)
# 縱向分割 (axis默認為0)
print("縱向分割:", np.split(a, 2, axis=0))
# 橫向分割
print("橫向分割:", np.split(a, 2, axis=1))
運行結果:
原陣列: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]] (4, 4)
縱向分割: [array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
橫向分割: [array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]]), array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])]
創建NumPy矩陣
矩陣創建
# mat創建矩陣 使用分號分隔資料
m1 = np.mat("1 2 3; 4 5 6; 7 8 9")
print(m1, m1.shape)
# matrix創建矩陣
m2 = np.matrix([[1,2,3], [4,5,6], [7,8,9]])
print(m2, m2.shape)
# 創建一個全為0和一個全為1的陣列
a1 = np.zeros([3, 3])
a2 = np.ones([3, 3])
# # bmat將多個小矩陣(陣列)合并成一個大矩陣
print("bmat將多個小矩陣合并成一個大矩陣:\n", np.bmat("a1 a2;a2 a1"))
運行結果:
[[1 2 3]
[4 5 6]
[7 8 9]] (3, 3)
[[1 2 3]
[4 5 6]
[7 8 9]] (3, 3)
bmat將多個小矩陣合并成一個大矩陣:
[[0. 0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1. 1.]
[1. 1. 1. 0. 0. 0.]
[1. 1. 1. 0. 0. 0.]
[1. 1. 1. 0. 0. 0.]]
矩陣運算
# 創建兩個矩陣
m1 = np.mat("1 2 3; 4 5 6; 7 8 9")
m2 = m1 * 2
print("矩陣1:", m1, m1.shape)
print("矩陣2:", m2, m2.shape)
# 矩陣相加
print("矩陣相加:", m1 + m2)
# 矩陣相減
print("矩陣相減:", m1 - m2)
# 矩陣相除
print("矩陣相除:", (m2+1) / (m1+1))
# 矩陣相乘
print("矩陣相乘:", m1 * m2)
print("矩陣相乘:", np.multiply(m1, m2))
運行結果:
矩陣1: [[1 2 3]
[4 5 6]
[7 8 9]] (3, 3)
矩陣2: [[ 2 4 6]
[ 8 10 12]
[14 16 18]] (3, 3)
矩陣相加: [[ 3 6 9]
[12 15 18]
[21 24 27]]
矩陣相減: [[-1 -2 -3]
[-4 -5 -6]
[-7 -8 -9]]
矩陣相除: [[1.5 1.66666667 1.75 ]
[1.8 1.83333333 1.85714286]
[1.875 1.88888889 1.9 ]]
矩陣相乘: [[ 60 72 84]
[132 162 192]
[204 252 300]]
矩陣相乘: [[ 2 8 18]
[ 32 50 72]
[ 98 128 162]]
矩陣屬性
| 屬性 | 說明 |
|---|---|
| T | 回傳自身的轉置 |
| H | 回傳自身的共軛轉置 |
| I | 回傳自身的逆矩陣 |
| A | 回傳自身資料的二維陣列的一個視圖(沒做任何復制) |
# 創建矩陣
m = np.mat("1 2 3; 4 5 6; 7 8 9")
# 轉置
print("轉置:", m.T)
# 共軛轉置
print("共軛轉置:", m.H)
# 逆矩陣
print("逆矩陣:", m.I)
# 二維陣列的視圖
print("二維陣列的視圖:", m.A)
運行結果:
轉置: [[1 4 7]
[2 5 8]
[3 6 9]]
共軛轉置: [[1 4 7]
[2 5 8]
[3 6 9]]
逆矩陣: [[-4.50359963e+15 9.00719925e+15 -4.50359963e+15]
[ 9.00719925e+15 -1.80143985e+16 9.00719925e+15]
[-4.50359963e+15 9.00719925e+15 -4.50359963e+15]]
二維陣列的視圖: [[1 2 3]
[4 5 6]
[7 8 9]]
ufunc函式
常用的函式
大多數ufunc函式都是用C語言實作的,因此ufunc函式比math庫中的函式效率高,
| 函式 | 使用方法 |
|---|---|
| sqrt() | 計算序列化資料的平方根 |
| sin()、cos() | 三角函式 |
| abs() | 計算序列化資料的絕對值 |
| dot() | 矩陣運算 |
| log()、logl()、log2() | 對數函式 |
| exp() | 指數函式 |
| cumsum()、cumproduct() | 累計求和、求積 |
| sum() | 對一個序列化資料進行求和 |
| mean() | 計算均值 |
| median() | 計算中位數 |
| std() | 計算標準差 |
| var() | 計算方差 |
| corrcoef() | 計算相關系數 |
常用的ufunc函式運算
進行運算的兩個陣列的形狀必須相同
# 創建兩個陣列
a = np.array([1, 2, 3])
b = np.array([2, 4, 6])
# 四則運算
print("陣列相加:", a + b)
print("陣列相減:", a - b)
print("陣列相乘:", a * b)
print("陣列相除:", a / b)
print("陣列冪運算:", a ** b)
# 比較運算
print("比較結果:", a < b)
print("比較結果:", a > b)
print("比較結果:", a == b)
print("比較結果:", a <= b)
print("比較結果:", a >= b)
print("比較結果:", a != b)
運行結果:
陣列相加: [3 6 9]
陣列相減: [-1 -2 -3]
陣列相乘: [ 2 8 18]
陣列相除: [0.5 0.5 0.5]
陣列冪運算: [ 1 16 729]
比較結果: [ True True True]
比較結果: [False False False]
比較結果: [False False False]
比較結果: [ True True True]
比較結果: [False False False]
比較結果: [ True True True]
廣播機制
- ufunc通用函式,能夠對array中所有元素進行操作的函式
- Broadcasting指對不同形狀的array之間執行算術運算的方式
- 不同形狀的陣列運算時,Numpy則會執行廣播機制
- numpy能夠運用向量化運算處理整個陣列,所以速度比較快
檔案操作
資料存盤
# 創建陣列
a = np.arange(100).reshape(10, 10)
b = a * 2
# 二進制資料保存 np.save(file, arr, allow_pickle=True, fix_imports=True)
np.save("save01", a)
# 多個陣列保存
np.savez("save02", a, b)
運行結果:
檔案讀取
# 讀取單個陣列
a = np.load("save01.npy")
print("讀取單個陣列", a)
# 讀取多個陣列
data = np.load("save02.npz")
# arr_下標 固定格式
print("a:", data['arr_0'])
print("b:", data['arr_1'])
運行結果:
讀取單個陣列 [[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]
a: [[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]
b: [[ 0 2 4 6 8 10 12 14 16 18]
[ 20 22 24 26 28 30 32 34 36 38]
[ 40 42 44 46 48 50 52 54 56 58]
[ 60 62 64 66 68 70 72 74 76 78]
[ 80 82 84 86 88 90 92 94 96 98]
[100 102 104 106 108 110 112 114 116 118]
[120 122 124 126 128 130 132 134 136 138]
[140 142 144 146 148 150 152 154 156 158]
[160 162 164 166 168 170 172 174 176 178]
[180 182 184 186 188 190 192 194 196 198]]
txt格式保存與讀取
# 創建陣列
a = np.arange(16).reshape(4, 4)
# txt格式資料保存 np.savetxt(file, arr, fmt="%.18e", delimiter=" ", newline="\n", header="", footer="", comments="# ")
np.savetxt("save03.txt", a, fmt="%d", delimiter=",", newline="\n")
# 讀取txt檔案
data = np.loadtxt("save03.txt", delimiter=",")
print(data)
運行結果:
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
genfromtxt函式讀取資料
genfromtxt函式和loadtxt函式相似,genfromtxt函式是面向結構化和缺失資料,通常使用的三個引數,fname檔案路徑,delimiter分隔符,names列標題
# 使用genfromtxt函式讀取資料
data = np.genfromtxt("save03.txt", delimiter=",")
print(data)
運行結果:
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
排序
sort函式 無回傳值 直接對原始資料修改
# 設定亂數種子
np.random.seed(11)
# 隨機生成一維陣列
a = np.random.randint(1, 10, size=10)
print("排序前:", a)
a.sort()
print("排序后:", a)
# 隨機生成二維陣列
b = np.random.randint(1, 10, size=(3, 3))
# 縱向排序
b.sort(axis=0)
print("縱向排序", b)
# 橫向排序
b.sort(axis=1)
print("橫向排序", b)
運行結果:
排序前: [1 2 8 2 8 3 9 1 1 5]
排序后: [1 1 1 2 2 3 5 8 8 9]
縱向排序 [[2 2 5]
[3 8 6]
[6 9 9]]
橫向排序 [[2 2 5]
[3 6 8]
[6 9 9]]
argsort函式
# 隨機生成一維陣列
a = np.random.randint(1, 10, size=10)
print("排序前:", a)
# 回傳值為重新排序后,原值的下標
print("排序后回傳下標:", a.argsort())
運行結果:
排序前: [4 2 1 4 9 8 2 5 9 3]
排序后回傳下標: [2 1 6 9 0 3 7 5 4 8]
lexsort函式
# 創建三個陣列
a = np.array([5, 7, 8, 2])
b = np.array([30, 50, 20, 80])
c = np.array([900, 400, 600, 200])
# 進行lexsort排序 只接收一個引數
d = np.lexsort((a, b , c))
# 多個鍵值排序時,按照最后一個傳入的資料排序
print("排序后回傳下標:", d)
print("排序后的陣列為:", list(zip(a[d], b[d], c[d])))
運行結果:
排序后回傳下標: [3 1 2 0]
排序后的陣列為: [(2, 80, 200), (7, 50, 400), (8, 20, 600), (5, 30, 900)]
去重與生成重復資料
# 隨機生成一維陣列
a = np.random.randint(1, 5, size=10)
print("一維陣列a:", a)
# 去重
print("去重后:", np.unique(a))
# 生成[0, 1, 2, 3, 4]
b = np.arange(5)
# np.tile(arr, times)
print("使用tile函式對b重復3次后:", np.tile(b, 3))
# 創建一個二維陣列
c = np.random.randint(0, 10, size=(2, 3))
print("二維陣列c:", c)
# np.repeat(arr, times, axis=None)
print("縱向重復資料:", np.repeat(c, 2, axis=0))
print("橫向重復資料:", np.repeat(c, 2, axis=1))
運行結果:
一維陣列a: [3 2 4 2 3 1 4 2 2 3]
去重后: [1 2 3 4]
使用tile函式對b重復3次后: [0 1 2 3 4 0 1 2 3 4 0 1 2 3 4]
二維陣列c: [[6 9 1]
[1 6 5]]
縱向重復資料: [[6 9 1]
[6 9 1]
[1 6 5]
[1 6 5]]
橫向重復資料: [[6 6 9 9 1 1]
[1 1 6 6 5 5]]
常用的統計函式
a = np.arange(1,17).reshape(4, 4)
print("陣列a:", a)
print("求和:", np.sum(a))
print("縱向求和:", np.sum(a, axis=0))
print("橫向求和:", np.sum(a, axis=1))
print("平均值", np.mean(a))
print("縱向平均值:", np.mean(a, axis=0))
print("橫向平均值:", np.mean(a, axis=1))
print("標準差:", np.std(a))
print("方差:", np.var(a))
print("最大值:", np.max(a))
print("最小值:", np.min(a))
print("最小索引", np.argmin(a))
print("最大索引", np.argmax(a))
print("計算索引元素的累計和:", np.cumsum(a))
print("計算索引元素的累計積:", np.cumprod(a))
運行結果:
陣列a: [[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
求和: 136
縱向求和: [28 32 36 40]
橫向求和: [10 26 42 58]
平均值 8.5
縱向平均值: [ 7. 8. 9. 10.]
橫向平均值: [ 2.5 6.5 10.5 14.5]
標準差: 4.6097722286464435
方差: 21.25
最大值: 16
最小值: 1
最小索引 0
最大索引 15
計算索引元素的累計和: [ 1 3 6 10 15 21 28 36 45 55 66 78 91 105 120 136]
計算索引元素的累計積: [ 1 2 6 24 120 720
5040 40320 362880 3628800 39916800 479001600
1932053504 1278945280 2004310016 2004189184]
恭喜你已經掌握了NumPy的精髓~

碼字不易,請給博主一個小小的贊吧~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305462.html
標籤:python