Hello,各位讀者朋友們好啊,我是小張~
這不國慶嘛,就把最近很火的一個韓劇《魷魚游戲》刷了下,這部劇整體劇情來說還是非常不錯的,很值得一看,
作為一個技術博主,當然不能在這兒介紹這部劇的影評,畢竟自己在這方面不是專業的,最關鍵還是自己也寫不出來,,,
本文呢,主要是爬取《魷魚游戲》在豆瓣上的一些影評,對資料做一些簡單的分析,用資料的角度重新審視下這部劇
技術工具
在正文開始之前,先介紹下本篇文章中用到的技術堆疊和工具,本文中涉及到的全部原始碼資料,在公眾號【小張Python】后臺回復關鍵字 211003 即可獲取,
本文用到的技術堆疊和工具如下,歸結為四個方面;
-
語言:Python,Vue ,javascript;
-
存盤:MongoDB;
-
庫:echarts ,Pymongo,WordArt…
-
軟體:Photoshop;
資料采集
本次資料采集的目標網站為 豆瓣 ,但自己的賬號之前被封,所以只能采集到大概二百來條資料,豆瓣有相應的反爬機制,瀏覽10頁以上的評論需要用戶登錄才能進行下一步操作
至于為啥賬號被封,是因為之前自己學爬蟲時不知道在哪里搞的【豆瓣模擬登錄】代碼,當時不知道代碼有沒有問題,愣頭青直接用自己的號試了下,誰知道剛試完就被封了,而且還是永久的那種
在這里也給大家提個醒在以后做爬蟲時,模擬登錄時盡量用一些測驗賬號,能不用自己的號就別用,
這次資料采集也比較簡單,就是更改圖2 中 url 上的 start 引數,以 offset 為 20 的規則 作為下一頁 url 的拼接;

拿到 請求連接之后,用 requests 的 get 請求,再對獲取到的 html 資料做個決議,就能獲取到我們需要的資料了;采集核心代碼貼在下方
for offset in range(0,220,20):
url = "https://movie.douban.com/subject/34812928/comments?start={}&limit=20&status=P&sort=new_score".format(offset)
res = requests.get(url,headers= headers)
# print(res.text)
soup = BeautifulSoup(res.text,'lxml')
time.sleep(2)
for comment_item in soup.select("#comments > .comment-item"):
try:
data_item = []
avatar = comment_item.select(".avatar a img")[0].get("src")
name = comment_item.select(".comment h3 .comment-info a")[0]
rate = comment_item.select(".comment h3 .comment-info span:nth-child(3)")[0]
date = comment_item.select(".comment h3 .comment-info span:nth-child(4)")[0]
comment = comment_item.select(".comment .comment-content span")[0]
# comment_item.get("div img").ge
data_item.append(avatar)
data_item.append(str(name.string).strip("\t"))
data_item.append(str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"))
data_item.append(str(date.string).replace('\n','').strip('\t'))
data_item.append(str(comment.string).strip("\t").strip("\n"))
data_json ={
'avatar':avatar,
'name': str(name.string).strip("\t"),
'rate': str(rate.get("class")[0]).strip("allstar").strip('\t').strip("\n"),
'date' : str(date.string).replace('\n','').replace('\t','').strip(' '),
'comment': str(comment.string).strip("\t").strip("\n")
}
if not (collection.find_one({'avatar':avatar})):
print("data _json is {}".format(data_json))
collection.insert_one(data_json)
f.write('\t'.join(data_item))
f.write("\n")
except Exception as e:
print(e)
continue
豆瓣爬取時需要記得加上 cookie 和 User-Agent,否則不會有資料為空,
為了后面資料可視化提取方便,本文用的是 Mongodb 作為資料存盤,共有211 條資料,主要采集的資料欄位為 avatar,name、rate、date、comment,分別表示用戶頭像、用戶名字、星級、日期,評論;結果見圖3;
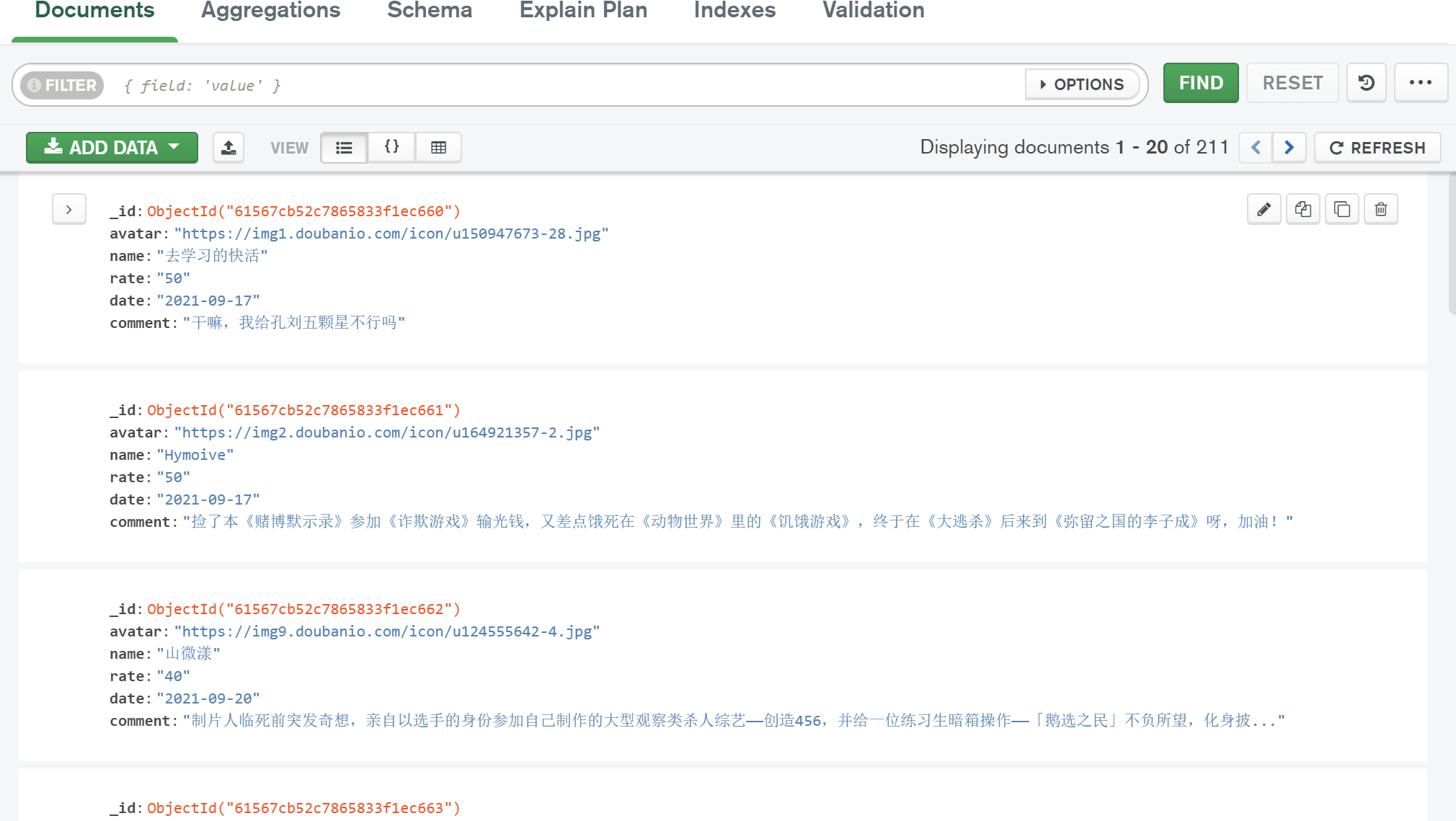
關于 Python 怎么使用 MongoDB,可以參考舊聞 【】
資料可視化
可視化部分之前打算用 Python + Pyecharts 來實作,但 Python 圖表中的互動效果不是很好,索性就直接用原生 Echarts + Vue 組合來實作,而且,這樣的話,將所有圖表放在一個網頁中也比較方便
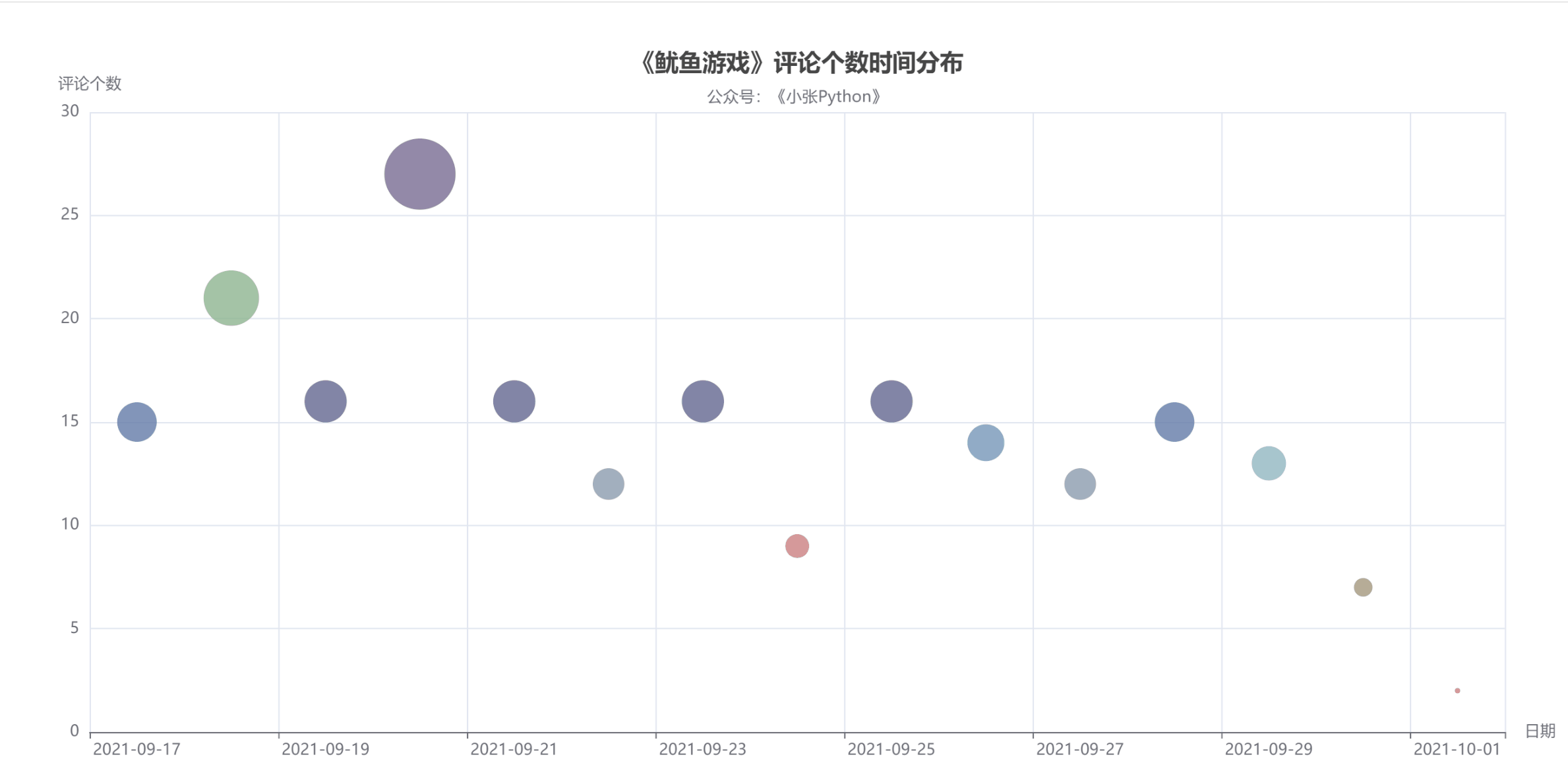
首先是對評論時間與評論數量做了一個圖表預覽,根據這些資料的評論時間作為一個散點圖分布,看一下用戶評論主要的時間分布
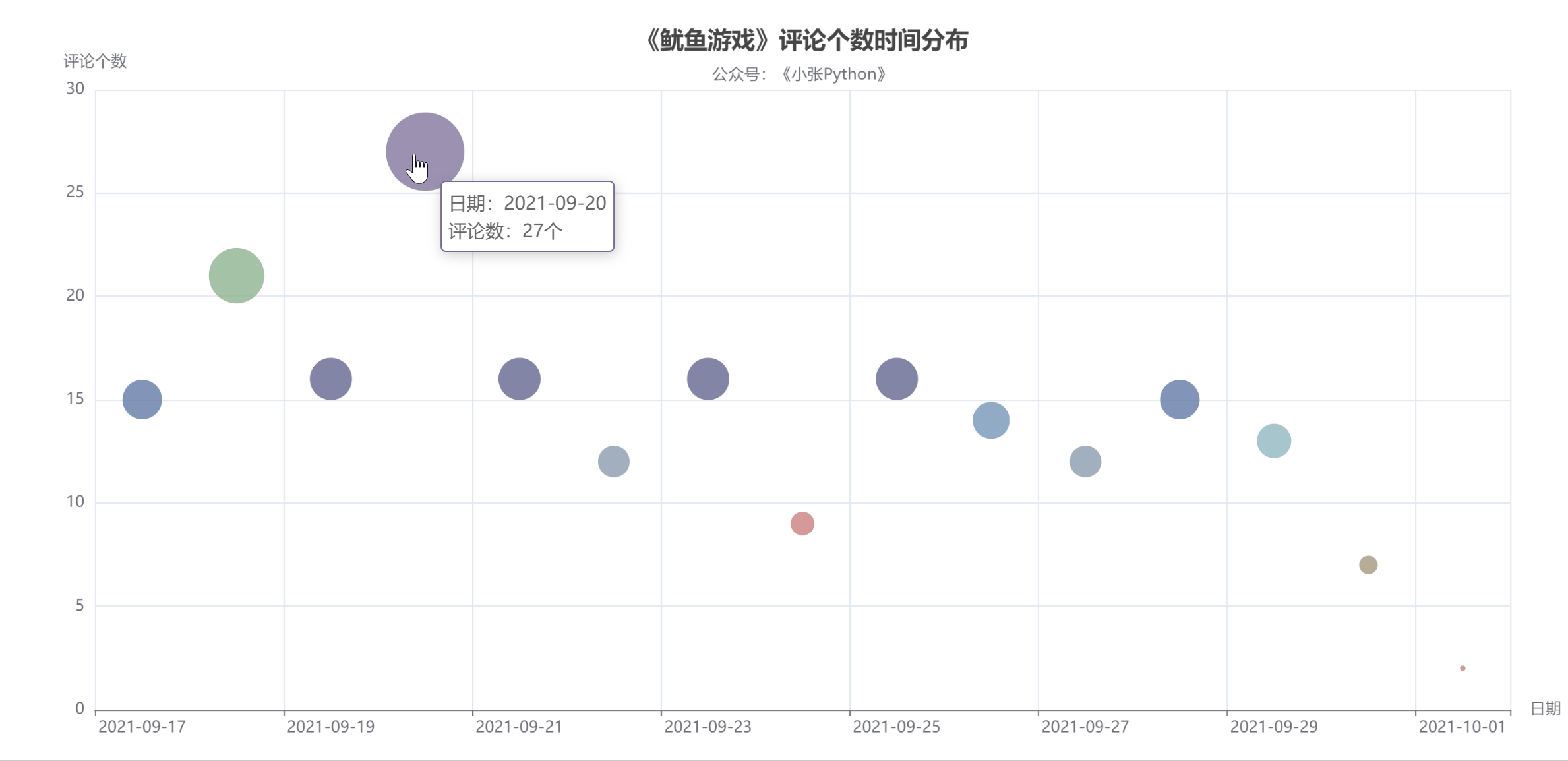
圖4中點的大小和顏色代表當天評論數量,而評論數量也可以側面反應該劇當天的熱度,
可以 了解到,《魷魚游戲》影評從 9 月17 日開始增長,在 20 號數量達到頂峰,21 榷訓落;在21日-29日評論數量來回震蕩,相差不大;
直到國慶 10月1日最少,猜測可能是一方面是國慶假期大家都出去玩的緣故,另一方面是隨著時間推移,這個劇的熱度也就降下來了
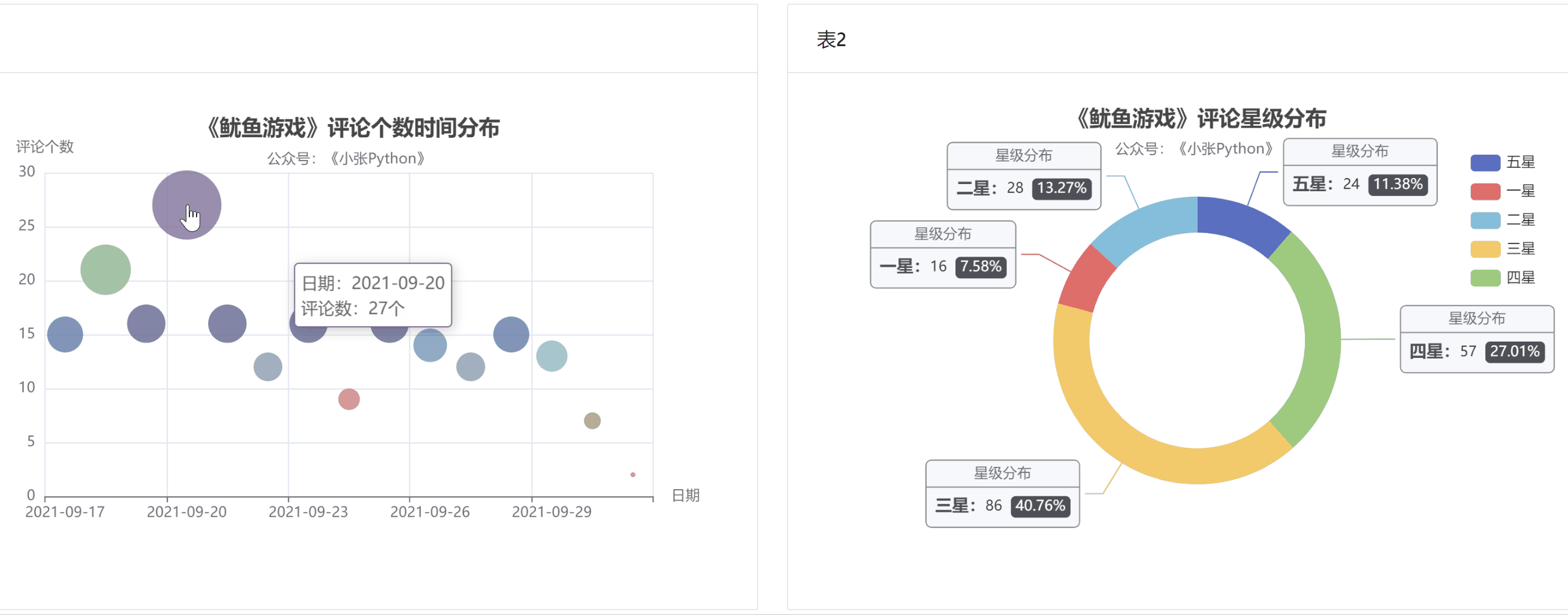
為了了解大家對《魷魚游戲》的評價,我對這二百條資料對這個劇的【評分星級】繪制了一個餅圖,最終效果見 圖5
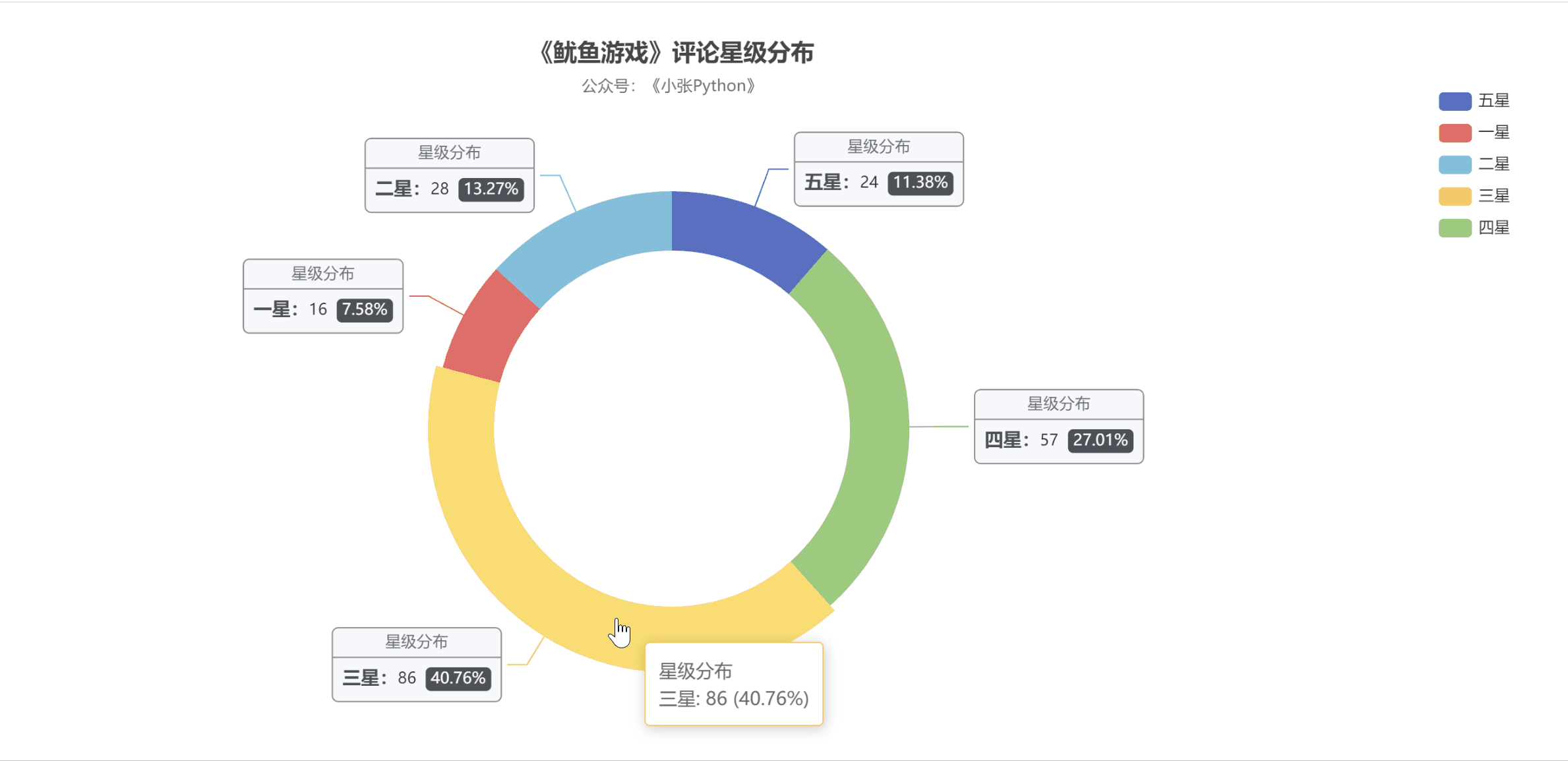
說實話圖5 的結果讓我有些意外,至少對于我而言這部劇質量說實話還是蠻高的,繪圖之前以為【五星】的占比應該是最大的,其次是【四星】,再然后是【三星】;
現在【三星】和【五星】的占比恰恰相反,猜測可能是這部劇的情節比較殘忍,會引起人的不適,所以高分占比不高;
為了方便,最后我將上面兩張圖表放置在一個網頁上,效果見圖6 和 圖7 兩種不同布局
垂直布局
水平布局
詞云可視化
本次采集的資料資訊有限能分析的資料維度不多,關于資料圖表方面的分析基本就到這里了,下面是對采集到的評論做了幾張詞云圖

從圖8來看,去除現實中常用到的還是、就是等口頭語,人性 是影評中頻率最高的一個詞,而這個詞確實符合《魷魚游戲》這部劇的主題,從第一集開始到結束都是在刨析人性,賭徒們的”貪婪、賭性成癮“,貴賓們的”弱肉強食“
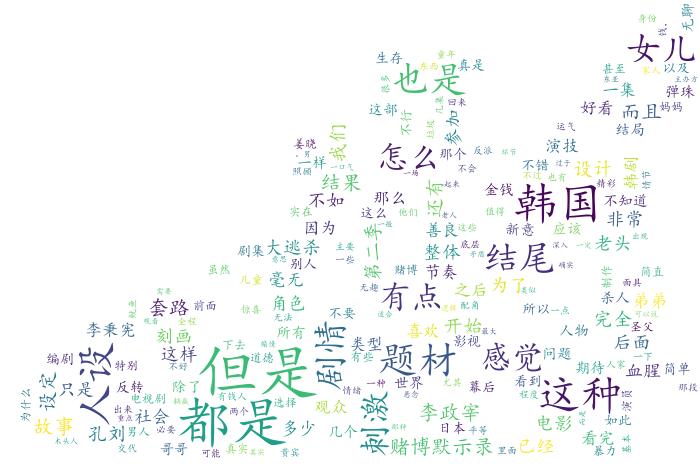
對比上張詞云圖,圖9凸顯的資訊相對就多了些,例如韓國、人設、刺激、劇情、賭博默示錄、題材等都與劇情有關,除了這幾個資訊之外,李政宰、孔劉、李秉憲 等幾個主演也被提到
最后,我將采集到的用戶頭像做了兩張圖片墻作為文章的結尾
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-4FFnW1hq-1633259077053)(E:\Writing\Common\小案例\《魷魚游戲》影評\mask1_wall.jpg)]

圖10,圖11 照片墻的輪廓采用的是劇中的兩個人物截圖,一個是123木頭人 ,另外一個是男一在玩游戲二的一個鏡頭:

關于照片墻制作方法,可參考舊聞:
小結
本文中涉及到的全部原始碼和資料獲取方式:關注微信公號:【小張Python】,在后臺回復關鍵字 211003 即可獲取,
好了,以上就是本篇文章的全部內容了,本文分析到的東西并不多,主要是介紹了 Python 在資料采集和可視化方面的一些應用,
如果內容對你有所幫助的話,希望給文章 點個贊 鼓勵一下我,當然也更歡迎讀者朋友們將文章 分享 給更多的人!
最后感謝大家的閱讀,我們下期見~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305463.html
標籤:python
上一篇:numpy學習總結