
📢📢📢📣📣📣
🌻🌻🌻Hello,大家好我叫是Dream呀,一個有趣的Python博主,小白一枚,多多關照😜😜😜
🏅🏅🏅CSDN Python領域新星創作者,大二在讀,歡迎大家找我合作學習
💕入門須知:這片樂園從不缺乏天才,努力才是你的最終入場券!🚀🚀🚀
💓最后,愿我們都能在看不到的地方閃閃發光,一起加油進步🍺🍺🍺
🍉🍉🍉“一萬次悲傷,依然會有Dream,我一直在最溫暖的地方等你”,唱的就是我!哈哈哈~🌈🌈🌈
🌟🌟🌟???
前言:
接下來帶著大家用Python爬蟲實作豆瓣電影的爬取,從零開始,跟上節奏,看不懂你來找我~
Python爬蟲實戰??爬取豆瓣電影任意頁數:
- 一、urllib_ajax的get方法 單頁抓取
- 1.頁面分析
- 2.抓取步驟
- (1) url和headers選取
- (2)請求物件的定制
- (3)獲取回應的資料
- (4)資料下載到本地
- 3.具體代碼
- 4.結果展示
- 二、urllib_ajax的get方法 爬取任意頁數爬取
- 1.頁面分析
- 2.抓取步驟
- (1)請求物件的定制
- (2)url拼接
- (3)設定入口
- (4) create_request(page)函式
- (5) get_content(request)函式
- (6) down_load(page,content)函式
- 3.具體代碼
- 4.結果展示
- 三、最后充電???
- 往期文章推薦:
一、urllib_ajax的get方法 單頁抓取
1.頁面分析
要爬取豆瓣電影,我們第一步當然是先百度:豆瓣電影,進入官網,昂昂Duang~
我們打開相應的豆瓣電影頁面:豆瓣電影動作片排行榜
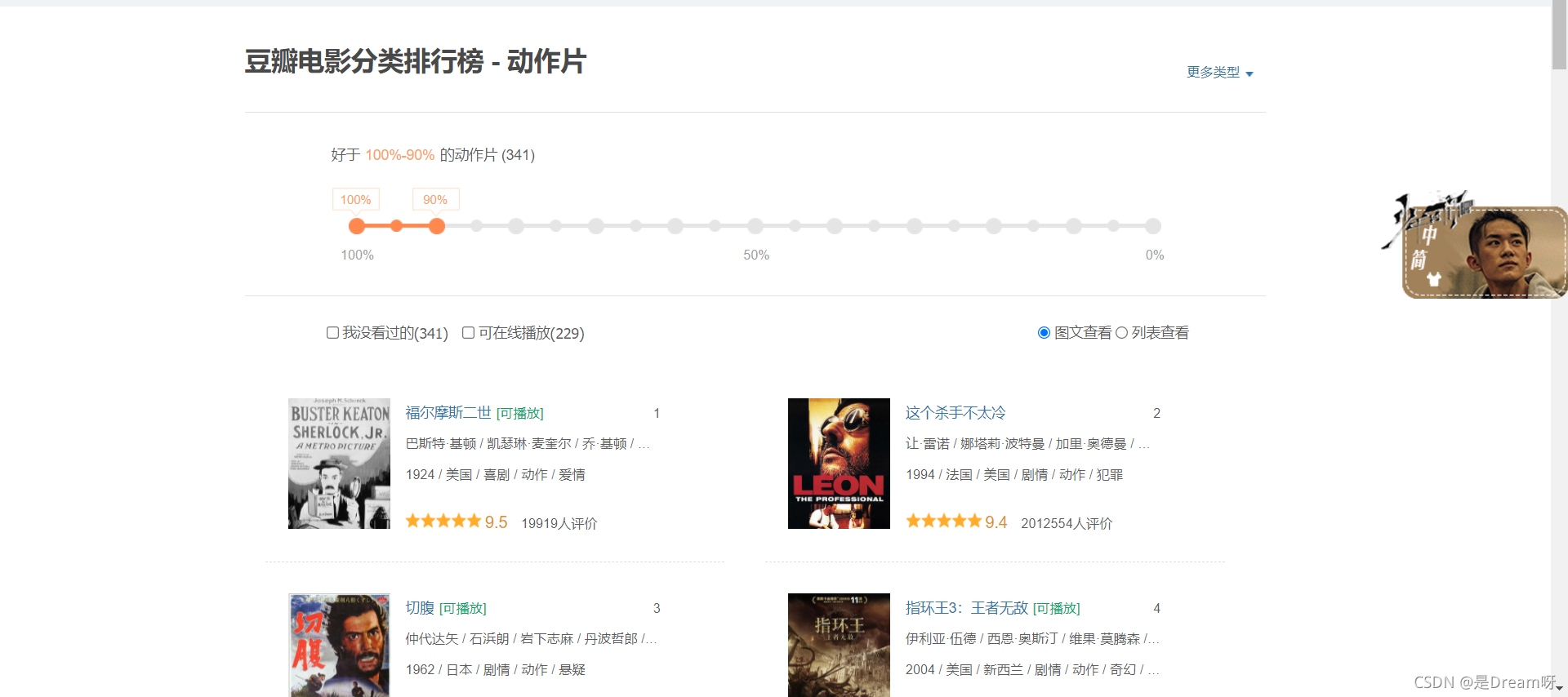
然后單擊滑鼠右鍵,在界面下方找到檢查,單擊進去:
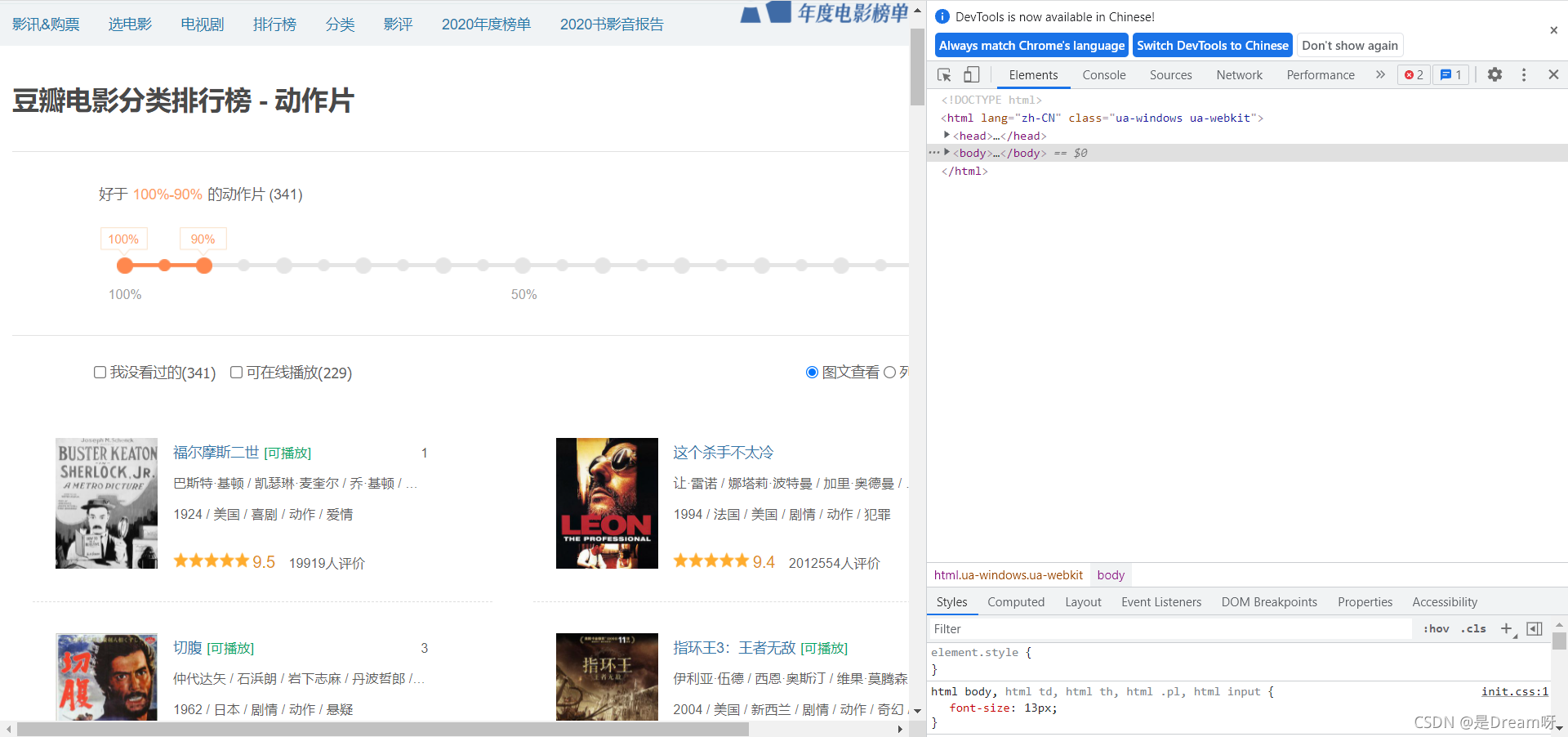
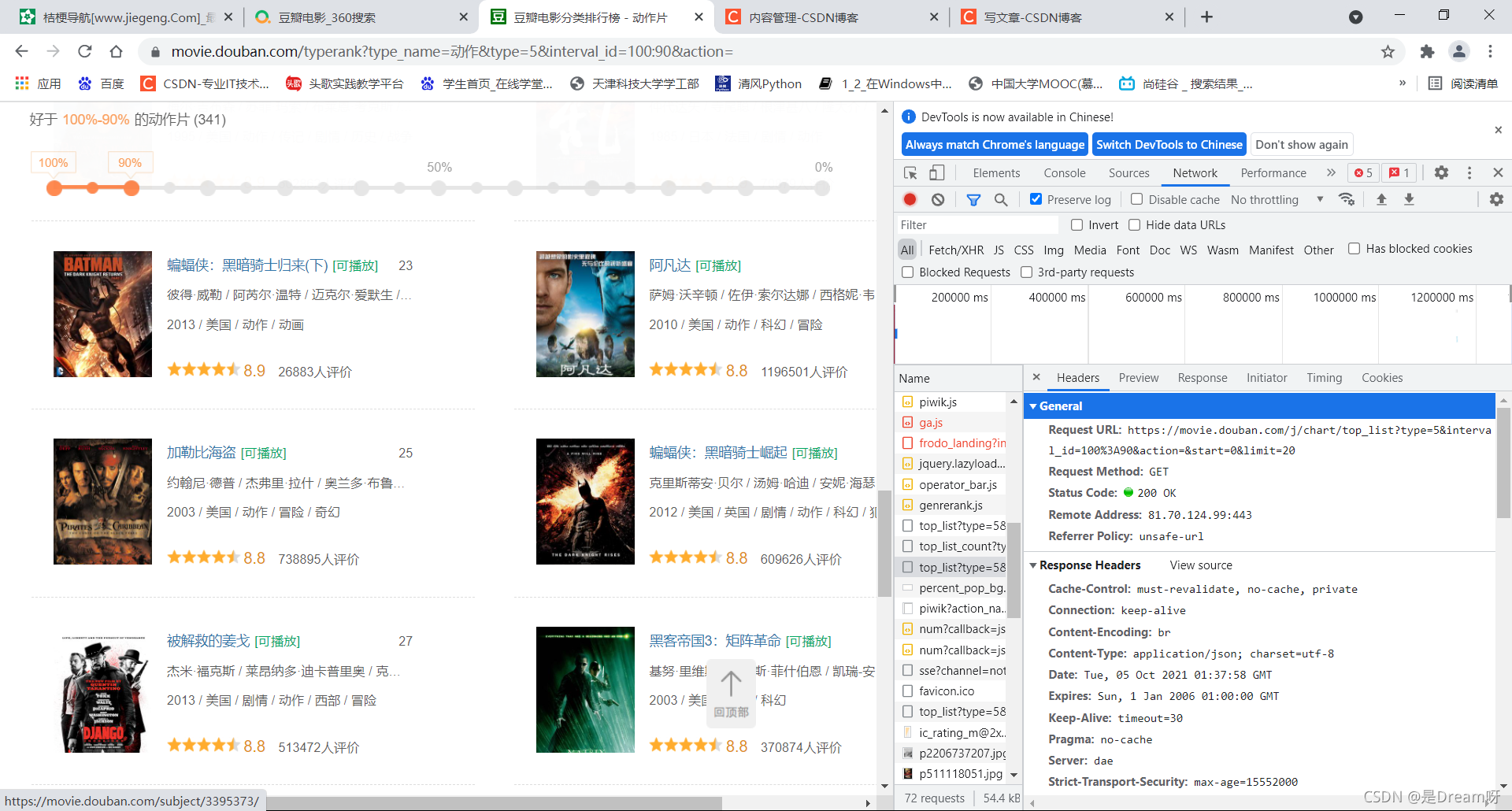
然后在其中找到network,點擊并順勢進行網頁重繪獲取新的資料:
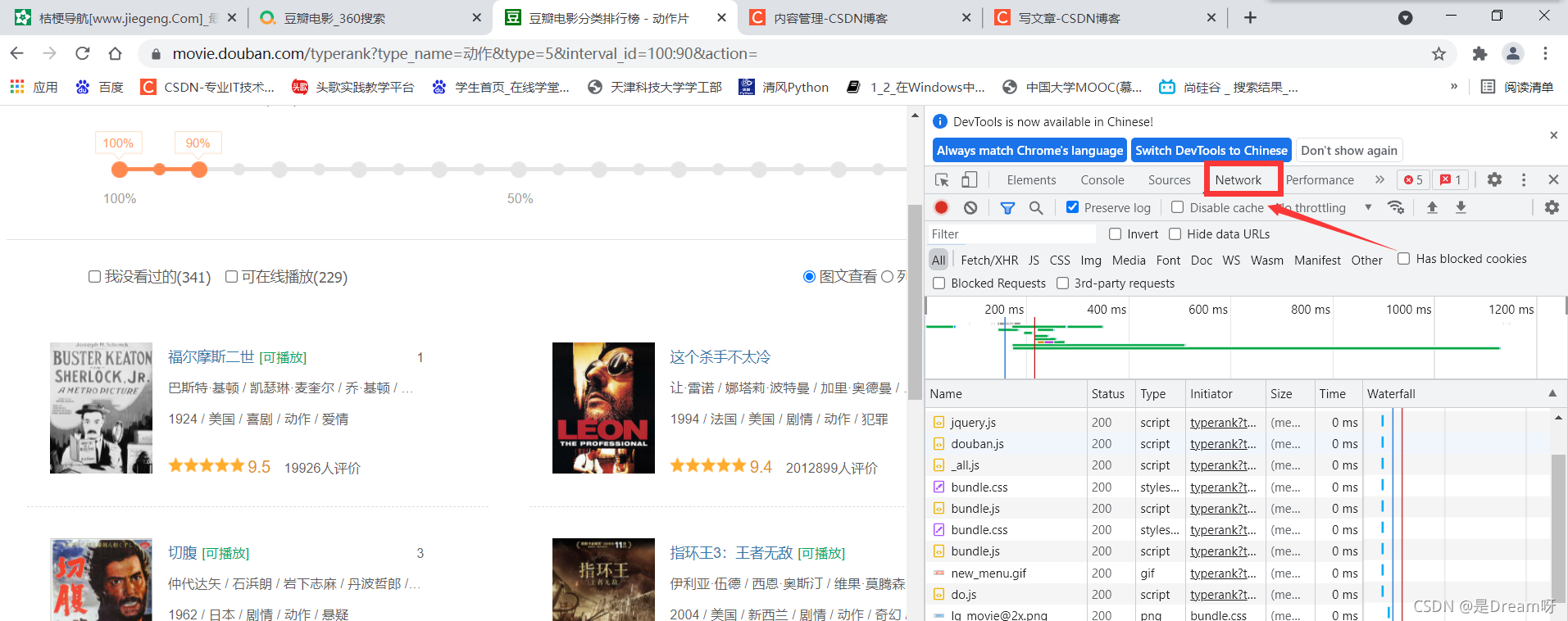
進行分析其中的資料:首先排除js和png、jpg檔案,在此基礎上,我們發現了這個檔案:
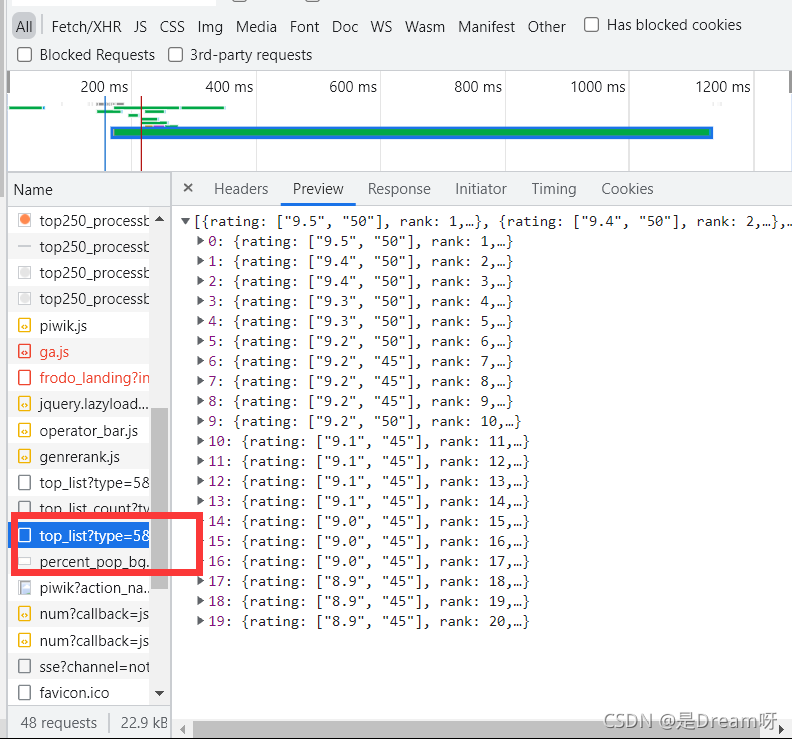
點開發現,確實是我們所需要的資料:
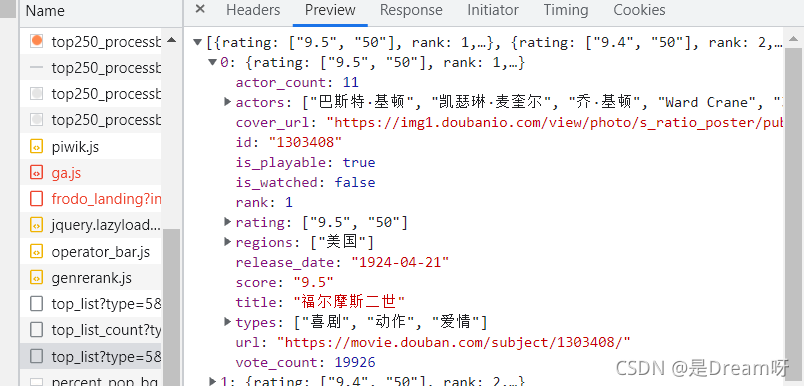
進而我們在headers中找到它的url:

2.抓取步驟
(1) url和headers選取
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
(2)請求物件的定制
request = urllib.request.Request(url=url,headers=headers)
(3)獲取回應的資料
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
(4)資料下載到本地
open方法默認情況下使用的是gbk的編碼,如果我們想要保存漢字,那么使用
open方法中制定編碼格式為utf-8 ,encoding=utf-8
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
完全等價:
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
3.具體代碼
# -*-coding:utf-8 -*-
# @Author:到點了,心疼徐哥哥
# 奧利給干!!!
# get請求,獲取第一頁資料,并保存起來
import urllib.request
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
# (1)請求物件的定制
request = urllib.request.Request(url=url,headers=headers)
# (2)獲取回應的資料
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
# (3)資料下載到本地
# open方法默認情況下使用的是gbk的編碼,如果我們想要保存漢字,那么使用
# open方法中制定編碼格式為utf-8
# encoding=utf-8
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
# 完全等價
with open('douban1.json','w',encoding='utf-8') as fp:
fp.write(content)
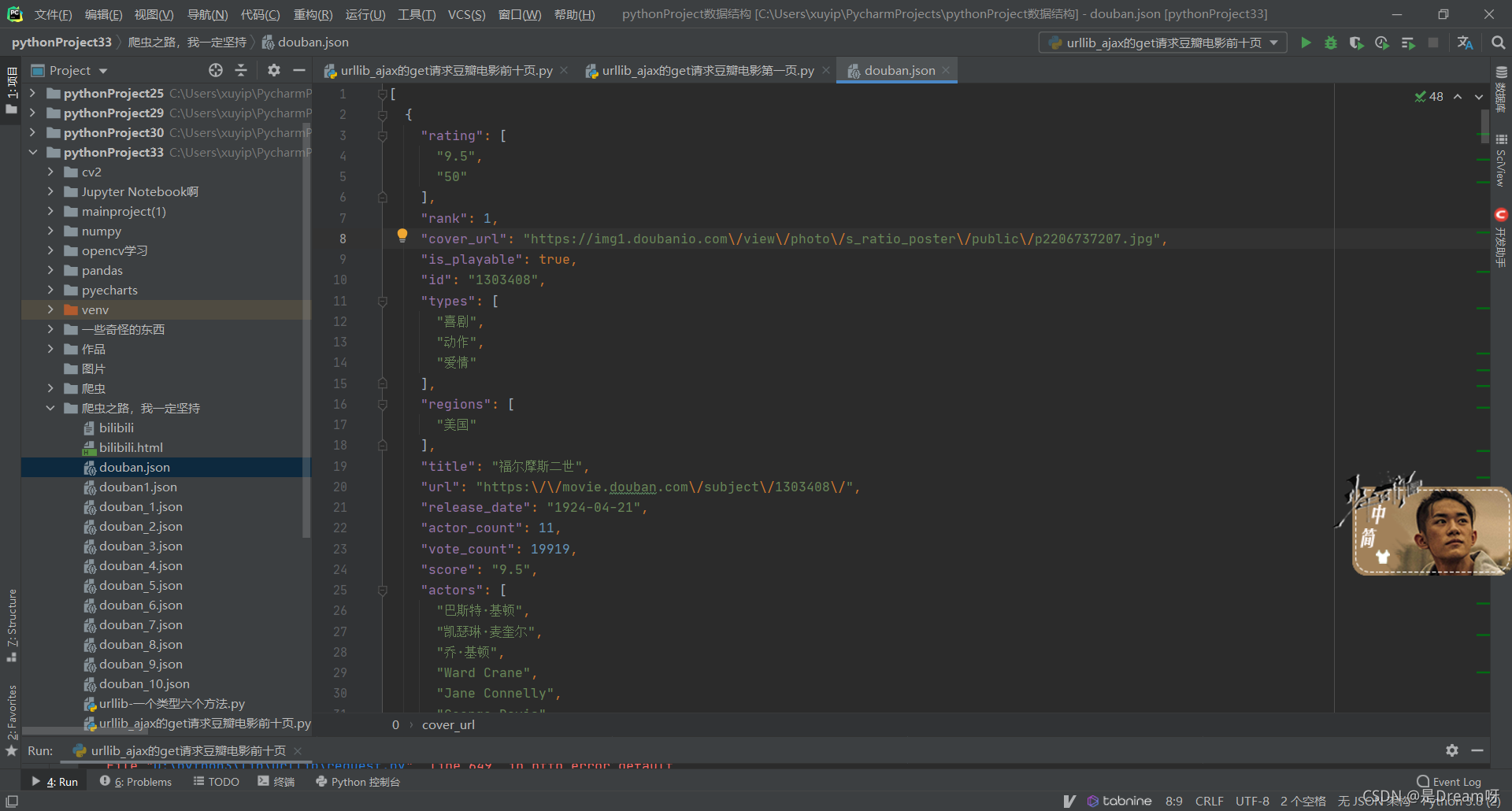
4.結果展示
保存為json資料,你會發現此時你的資料是一行的,顯得十分難看,只需要按住 ctrl + alt +l 就可以將資料變為規范的一行行資料,不過此鍵會和電腦QQ鎖定鍵重合,所以說一般進行此操作先把QQ退掉,或者有能力的同學可以更改鍵位選擇,將其換位其他鍵位的組合,
二、urllib_ajax的get方法 爬取任意頁數爬取
1.頁面分析
在此頁面中,用滑鼠逐漸向下滑動,你會發現會新增加一些近乎一樣的頁面資料,其實每次頁面顯示二十部電影,當你繼續往下滑動時,又會出現二十部電影,我們分別將其對應的url取下來單獨進行分析:
 第一頁:
第一頁:
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
第二頁:
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
第三頁:
https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20
可以發現:每次的start都不同
設page為n,則:start=(n-1)*20
2.抓取步驟
(1)請求物件的定制
resquest = urllib.request.Request(url=url,headers=headers)
(2)url拼接
應用urllib.parse進行拼接:
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=unwatched&'
data={
'start':(page - 1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = url + data
(3)設定入口
if __name__=='__main__':
start_page = int(input('請輸入起始的頁碼'))
end_page = int(input('請輸入結束的頁面'))
for page in range(start_page,end_page+1):
- 獲取請求
- 回應請求
- 保存資料
request = create_request(page)
# 獲取回應的資料
content = get_content(request)
down_load(page,content)
(4) create_request(page)函式
def create_request(page):
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=unwatched&'
data={
'start':(page - 1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = url + data
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
resquest = urllib.request.Request(url=url,headers=headers)
return resquest
(5) get_content(request)函式
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
(6) down_load(page,content)函式
def down_load(page,content):
# with open('douban_'+str(page)+'.json','w',encoding='utf-8') as fp:
# fp.write(content)
fp = open('douban_'+str(page)+'.json','w',encoding='utf-8')
fp.write(content)
3.具體代碼
# -*-coding:utf-8 -*-
# @Author:到點了,心疼徐哥哥
# 奧利給干!!!
import urllib.request
import urllib.parse
def create_request(page):
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=unwatched&'
data={
'start':(page - 1)*20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = url + data
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
resquest = urllib.request.Request(url=url,headers=headers)
return resquest
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
# with open('douban_'+str(page)+'.json','w',encoding='utf-8') as fp:
# fp.write(content)
fp = open('douban_'+str(page)+'.json','w',encoding='utf-8')
fp.write(content)
if __name__=='__main__':
start_page = int(input('請輸入起始的頁碼'))
end_page = int(input('請輸入結束的頁面'))
for page in range(start_page,end_page+1):
request = create_request(page)
# 獲取回應的資料
content = get_content(request)
down_load(page,content)
4.結果展示
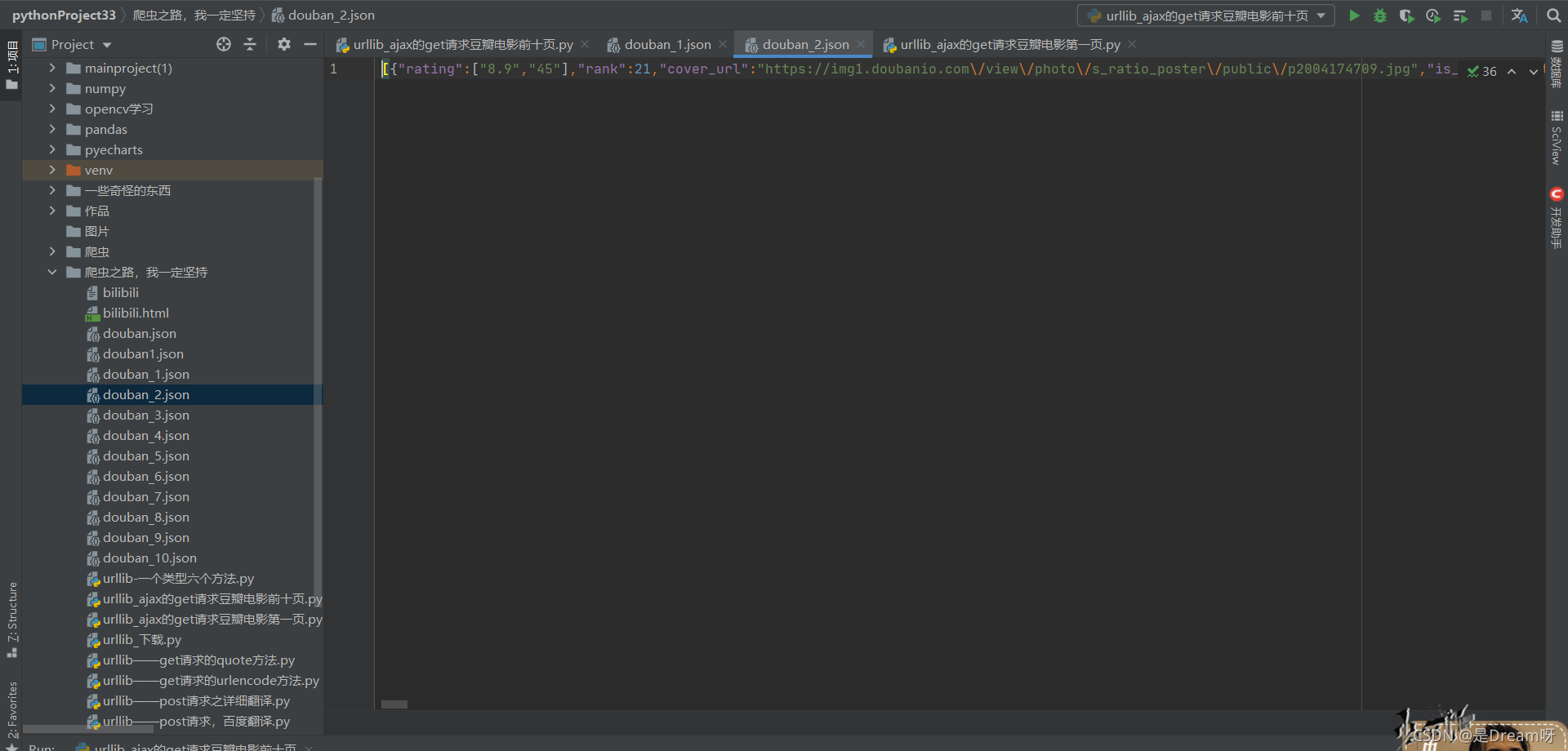
將其轉化為更規范的形式:ctrl+alt+l
三、最后充電???
當經過一系列操作之后,你已經爬取到了豆瓣電影的資料,當你滿心歡喜的回去重新進一次豆瓣電影官網時,卻突然發現進不去了,需要你先登錄!
豆瓣:你禮貌嗎,休想白嫖!
哈哈哈,你已經被豆瓣拉入黑名單了喲~人家的防范意識還是很高的!

畢竟一朝被爬取,次次防爬蟲!
好噠,那我們拜了個拜,下期再見!
往期文章推薦:
還看不懂Python OpenCV?不,我不允許!隔壁大爺都說看得懂!??環境配置+問題分析+視頻影像入門??萬字只為你~
Python OpenCV實戰畫圖——這次一定能行!爆肝萬字,建議點贊收藏~??????
??大家中秋節快樂??接下來請欣賞Python Opencv實戰之影像閾值和模糊處理,萬字實戰,收藏起來吧~
Python爬蟲?? Urllib用法合集——?一鍵輕松入門爬蟲?
🌲🌲🌲 好啦,這就是今天要分享給大家的全部內容了
??????如果你喜歡的話,就不要吝惜你的一鍵三連了~


轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/305693.html
標籤:python
上一篇:Python游戲開發,pyqt5模塊,Python實作AI的俄羅斯方塊小游戲,看你能過幾關?
下一篇:Python資料分析筆記(上)