面試官:今天想跟你聊聊Java記憶體模型,這塊你了解過嗎?
候選者:嗯,我簡單說下我的理解吧,那我就從為什么要有Java記憶體模型開始講起吧
面試官:開始你的表演吧,
候選者:那我先說下背景吧
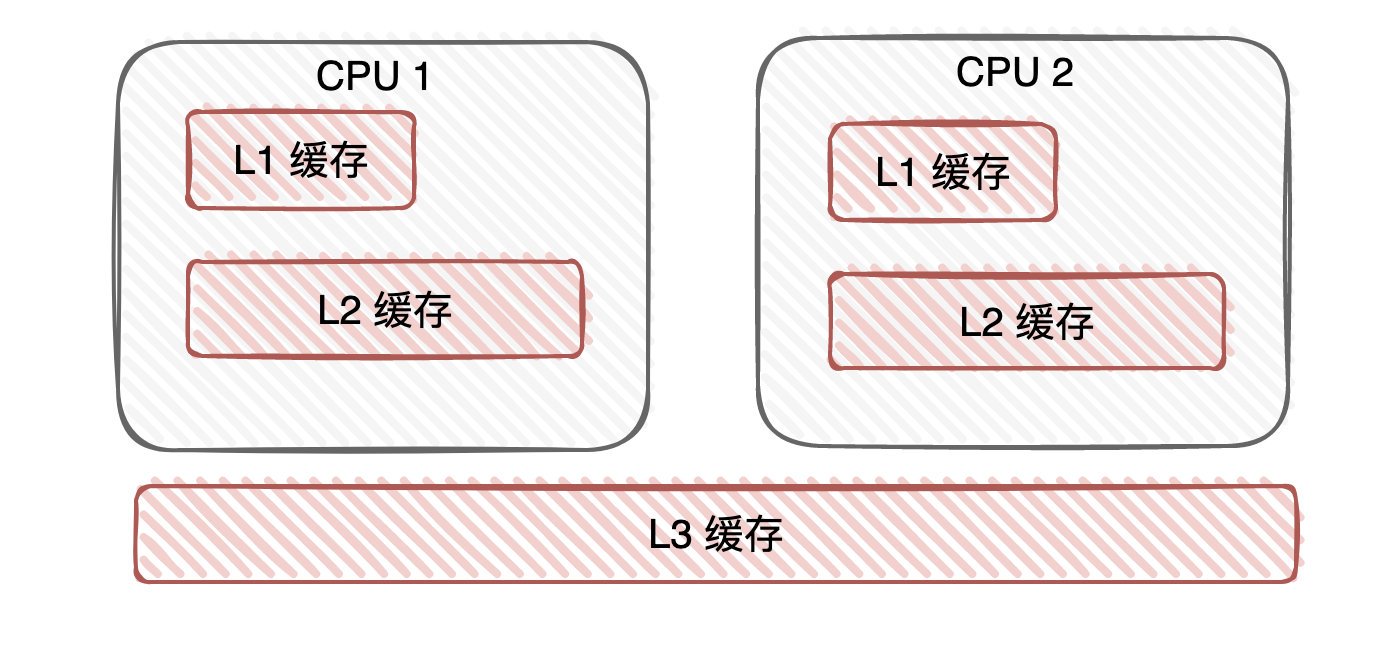
候選者:1. 現有計算機往往是多核的,每個核心下會有高速快取,高速快取的誕生是由于「CPU與記憶體(主存)的速度存在差異」,L1和L2快取一般是「每個核心獨占」一份的,
候選者:2. 為了讓CPU提高運算效率,處理器可能會對輸入的代碼進行「亂序執行」,也就是所謂的「指令重排序」
候選者:3. 一次對數值的修改操作往往是非原子性的(比如i++實際上在計算機執行時就會分成多個指令)
候選者:在永遠單執行緒下,上面所講的均不會存在什么問題,因為單執行緒意味著無并發,并且在單執行緒下,編譯器/runtime/處理器都必須遵守as-if-serial語意,遵守as-if-serial意味著它們不會對「資料依賴關系的操作」做重排序,

候選者:CPU為了效率,有了高速快取、有了指令重排序等等,整塊架構都變得復雜了,我們寫的程式肯定也想要「充分」利用CPU的資源啊!于是乎,我們使用起了多執行緒
候選者:多執行緒在意味著并發,并發就意味著我們需要考慮執行緒安全問題
候選者:1. 快取資料不一致:多個執行緒同時修改「共享變數」,CPU核心下的高速快取是「不共享」的,那多個cache與記憶體之間的資料同步該怎么做?
候選者:2. CPU指令重排序在多執行緒下會導致代碼在非預期下執行,最侄訓導致結果存在錯誤的情況,
候選者:針對于「快取不一致」問題,CPU也有其解決辦法,常被大家所認識的有兩種:
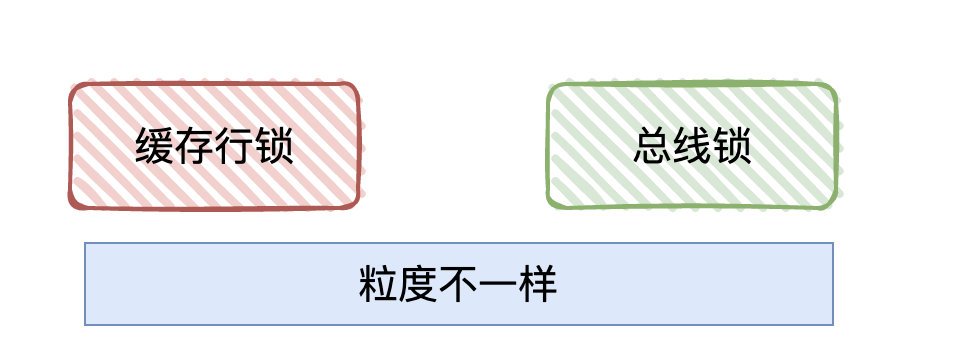
候選者:1.使用「總線鎖」:某個核心在修改資料的程序中,其他核心均無法修改記憶體中的資料,(類似于獨占記憶體的概念,只要有CPU在修改,那別的CPU就得等待當前CPU釋放)
候選者:2.快取一致性協議(MESI協議,其實協議有很多,只是舉個大家都可能見過的),MESI拆開英文是(Modified (修改狀態)、Exclusive (獨占狀態)、Share(共享狀態)、Invalid(無效狀態))
候選者:快取一致性協議我認為可以理解為「快取鎖」,它針對的是「快取行」(Cache line) 進行"加鎖",所謂「快取行」其實就是 高速快取 存盤的最小單位,
面試官:嗯...
候選者:MESI協議的原理大概就是:當每個CPU讀取共享變數之前,會先識別資料的「物件狀態」(是修改、還是共享、還是獨占、還是無效),
候選者:如果是獨占,說明當前CPU將要得到的變數資料是最新的,沒有被其他CPU所同時讀取
候選者:如果是共享,說明當前CPU將要得到的變數資料還是最新的,有其他的CPU在同時讀取,但還沒被修改
候選者:如果是修改,說明當前CPU正在修改該變數的值,同時會向其他CPU發送該資料狀態為invalid(無效)的通知,得到其他CPU回應后(其他CPU將資料狀態從共享(share)變成invalid(無效)),會當前CPU將高速快取的資料寫到主存,并把自己的狀態從modify(修改)變成exclusive(獨占)
候選者:如果是無效,說明當前資料是被改過了,需要從主存重新讀取最新的資料,

候選者:其實MESI協議做的就是判斷「物件狀態」,根據「物件狀態」做不同的策略,關鍵就在于某個CPU在對資料進行修改時,需要「同步」通知其他CPU,表示這個資料被我修改了,你們不能用了,
候選者:比較于「總線鎖」,MESI協議的"鎖粒度"更小了,性能那肯定會更高咯
面試官:但據我了解,CPU還有優化,你還知道嗎?
候選者:嗯,還是了解那么一點點的,
候選者:從前面講到的,可以發現的是:當CPU修改資料時,需要「同步」告訴其他的CPU,等待其他CPU回應接收到invalid(無效)后,它才能將高速快取資料寫到主存,
候選者:同步,意味著等待,等待意味著什么都干不了,CPU肯定不樂意啊,所以又優化了一把,
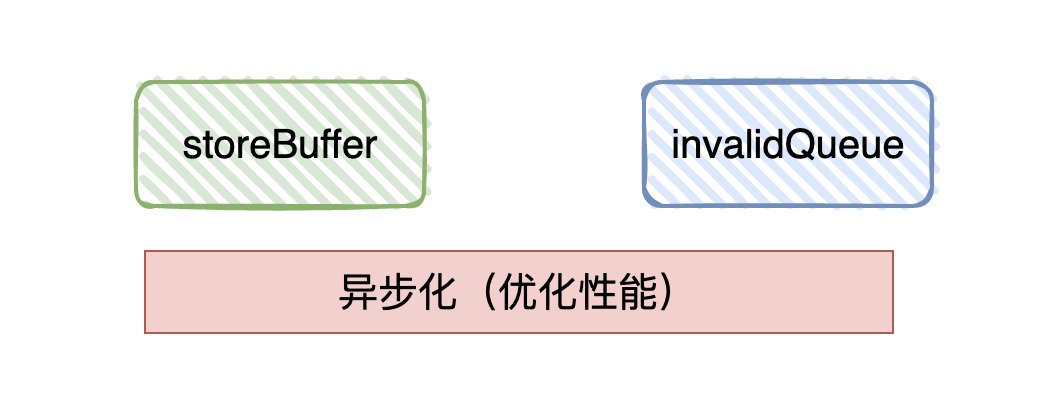
候選者:優化思路就是從「同步」變成「異步」,
候選者:在修改時會「同步」告訴其他CPU,而現在則把最新修改的值寫到「store buffer」中,并通知其他CPU記得要改狀態,隨后CPU就直接回傳干其他事了,等到收到其它CPU發過來的回應訊息,再將資料更新到高速快取中,
候選者:其他CPU接收到invalid(無效)通知時,也會把接收到的訊息放入「invalid queue」中,只要寫到「invalid queue」就會直接回傳告訴修改資料的CPU已經將狀態置為「invalid」
候選者:而異步又會帶來新問題:那我現在CPU修改完A值,寫到「store buffer」了,CPU就可以干其他事了,那如果該CPU又接收指令需要修改A值,但上一次修改的值還在「store buffer」中呢,沒修改至高速快取呢,
候選者:所以CPU在讀取的時候,需要去「store buffer」看看存不存在,存在則直接取,不存在才讀主存的資料,【Store Forwarding】
候選者:好了,解決掉第一個異步帶來的問題了,(相同的核心對資料進行讀寫,由于異步,很可能會導致第二次讀取的還是舊值,所以首先讀「store buffer」,
面試官:還有其他?
候選者:那當然啊,那「異步化」會導致相同核心讀寫共享變數有問題,那當然也會導致「不同」核心讀寫共享變數有問題啊
候選者:CPU1修改了A值,已把修改后值寫到「store buffer」并通知CPU2對該值進行invalid(無效)操作,而CPU2可能還沒收到invalid(無效)通知,就去做了其他的操作,導致CPU2讀到的還是舊值,
候選者:即便CPU2收到了invalid(無效)通知,但CPU1的值還沒寫到主存,那CPU2再次向主存讀取的時候,還是舊值...
候選者:變數之間很多時候是具有「相關性」(a=1;b=0;b=a),這對于CPU又是無感知的...
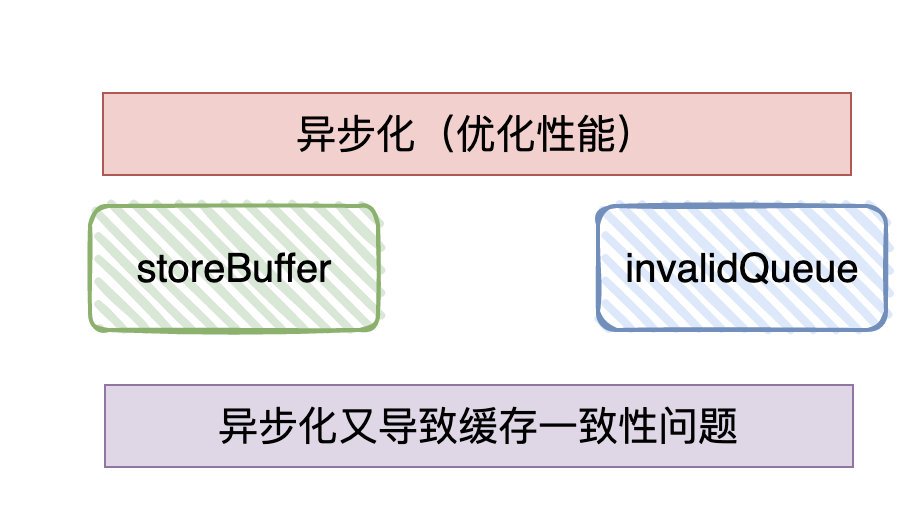
候選者:總體而言,由于CPU對「快取一致性協議」進行的異步優化「store buffer」「invalid queue」,很可能導致后面的指令很可能查不到前面指令的執行結果(各個指令的執行順序非代碼執行順序),這種現象很多時候被稱作「CPU亂序執行」
候選者:為了解決亂序問題(也可以理解為可見性問題,修改完沒有及時同步到其他的CPU),又引出了「記憶體屏障」的概念,
面試官:嗯...
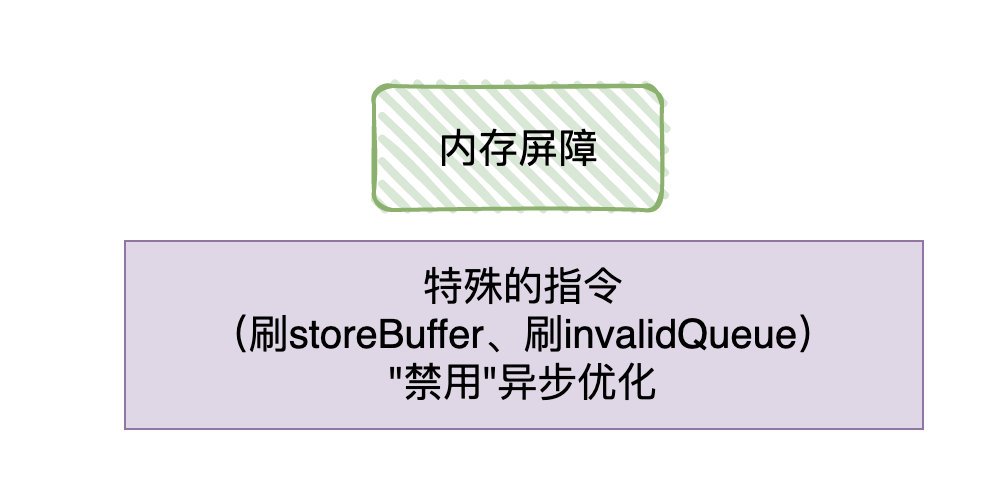
候選者:「記憶體屏障」其實就是為了解決「異步優化」導致「CPU亂序執行」/「快取不及時可見」的問題,那怎么解決的呢?嗯,就是把「異步優化」給”禁用“掉(:
候選者:記憶體屏障可以分為三種型別:寫屏障,讀屏障以及全能屏障(包含了讀寫屏障),屏障可以簡單理解為:在操作資料的時候,往資料插入一條"特殊的指令",只要遇到這條指令,那前面的操作都得「完成」,
候選者:那寫屏障就可以這樣理解:CPU當發現寫屏障的指令時,會把該指令「之前」存在于「store Buffer」所有寫指令刷入高速快取,
候選者:通過這種方式就可以讓CPU修改的資料可以馬上暴露給其他CPU,達到「寫操作」可見性的效果,
候選者:那讀屏障也是類似的:CPU當發現讀屏障的指令時,會把該指令「之前」存在于「invalid queue」所有的指令都處理掉
候選者:通過這種方式就可以確保當前CPU的快取狀態是準確的,達到「讀操作」一定是讀取最新的效果,
候選者:由于不同CPU架構的快取體系不一樣、快取一致性協議不一樣、重排序的策略不一樣、所提供的記憶體屏障指令也有差異,為了簡化Java開發人員的作業,Java封裝了一套規范,這套規范就是「Java記憶體模型」
候選者:再詳細地說,「Java記憶體模型」希望 屏蔽各種硬體和作業系統的訪問差異,保證了Java程式在各種平臺下對記憶體的訪問都能得到一致效果,目的是解決多執行緒存在的原子性、可見性(快取一致性)以及有序性問題,

面試官:那要不簡單聊聊Java記憶體模型的規范和內容吧?
候選者:不了,怕一聊就是一個下午,下次吧?
本文總結:
- 并發問題產生的三大根源是「可見性」「有序性」「原子性」
- 可見性:CPU架構下存在高速快取,每個核心下的L1/L2高速快取不共享(不可見)
- 有序性:主要有三方面可能導致打破
- 編譯器優化導致重排序(編譯器可以在不改變單執行緒程式語意的情況下,可以對代碼陳述句順序進行調整重新排序)
- 指令集并行重排序(CPU原生就有可能將指令進行重排)
- 記憶體系統重排序(CPU架構下很可能有store buffer /invalid queue 緩沖區,這種「異步」很可能會導致指令重排)
- 原子性:Java的一條陳述句往往需要多條 CPU 指令完成(i++),由于作業系統的執行緒切換很可能導致 i++ 操作未完成,其他執行緒“中途”操作了共享變數 i ,導致最終結果并非我們所期待的,
- 在CPU層級下,為了解決「快取一致性」問題,有相關的“鎖”來保證,比如“總線鎖”和“快取鎖”,
- 總線鎖是鎖總線,對共享變數的修改在相同的時刻只允許一個CPU操作,
- 快取鎖是鎖快取行(cache line),其中比較出名的是MESI協議,對快取行標記狀態,通過“同步通知”的方式,來實作(快取行)資料的可見性和有序性
- 但“同步通知”會影響性能,所以會有記憶體緩沖區(store buffer/invalid queue)來實作「異步」進而提高CPU的作業效率
- 引入了記憶體緩沖區后,又會存在「可見性」和「有序性」的問題,平日大多數情況下是可以享受「異步」帶來的好處的,但少數情況下,需要強「可見性」和「有序性」,只能"禁用"快取的優化,
- “禁用”快取優化在CPU層面下有「記憶體屏障」,讀屏障/寫屏障/全能屏障,本質上是插入一條"屏障指令",使得緩沖區(store buffer/invalid queue)在屏障指令之前的操作均已被處理,進而達到 讀寫 在CPU層面上是可見和有序的,
- 不同的CPU實作的架構和優化均不一樣,Java為了屏蔽硬體和作業系統訪問記憶體的各種差異,提出了「Java記憶體模型」的規范,保證了Java程式在各種平臺下對記憶體的訪問都能得到一致效果

歡迎關注我的微信公眾號【Java3y】來聊聊Java面試,對線面試官系列持續更新中!
【對線面試官-移動端】系列 一周兩篇持續更新中!
【對線面試官-電腦端】系列 一周兩篇持續更新中!
原創不易!!求三連!!
更多的文章可往:文章的目錄導航轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/315857.html
標籤:Java